
Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean



Abstract
:1. Introduction
2. Previous Studies
3. Fine-Grained NER Model
4. Evaluation
4.1. Datasets and and Experimental Settings
4.2. Implementation
4.3. Experimental Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Mai, K.; Pham, T.H.; Nguyen, M.T.; Nguyen, T.D.; Bollegala, D.; Sasano, R.; Sekine, S. An empirical study on fine-grained named entity recognition. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 711–722. [Google Scholar]
- Peters, E.M.; Neumann, M.; Iyyer, M.; Gradner, M. Deep contexualized word representation. In Proceedings of the NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Sekine, S.; Grishman, R.; Shinnou, H. A decision tree method for finding and classifying names in Japanese texts. In Proceedings of the 6th Workshop on Vary Large Corpora, Montreal, QC, Canada, 15–16 August 1998; pp. 171–178. [Google Scholar]
- Borthwick, A.; Sterling, J.; Agichtein, E.; Grishman, R. NYU: Description of the MENE named entity system as used in MUC-7. In Proceedings of the Seventh Message Understanding Conference, Fairfaxm VA, USA, 29 April–1 May 1998. [Google Scholar]
- Cohen, W.W.; Sarawagi, S. Exploiting dictionaries in named entity extraction: Combining semi-markov extraction processes and data integration methods. In Proceedings of the KDD 2004, Seattle, WA, USA, 22–25 August 2004; pp. 89–98. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. J. Linguist. Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the NAACL-HLT 2016, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 40, 357–370. [Google Scholar] [CrossRef]
- Ling, X.; Weld, D.S. Fined-Grained Entity Recognition. In Proceedings of the 26th AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 94–100. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstmcnns-crf. In Proceedings of the Association Computational Linguistics, Berlin, Germany, 18–24 May 2016; pp. 1064–1074. [Google Scholar]
- Dogan, C.; Dutra, A.; Gara, A.; Gemma, A.; Shi, L.; Sigamani, M.; Walters, E. Fine-grained named entity recognition using elmo and wikidata. arXiv 2019, arXiv:1904.10503. [Google Scholar]
- Man, X.; Yang, P. Fine-grained Chinese Named Entity Recognition in Entertainment News Using Adversarial Multi-task Learning. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 1671–1675. [Google Scholar]
- Zhu, H.; He, C.; Fang, Y.; Xiao, W. Fine Grained Named Entity Recognition via Seq2seq Framework. IEEE Access 2020, 8, 53953–53961. [Google Scholar] [CrossRef]
- Kato, T.; Abe, K.; Ouchi, H.; Miyawaki, S.; Suzuki, J.; Inui, K. Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition. In Proceedings of the Association Computational Linguistics, Virtual, 5–10 July 2020; pp. 222–229. [Google Scholar]
- Liu, J.; Xia, C.; Yan, H.; Xu, W. Innovative Deep Neural Network Modeling for Fine-Grained Chinese Entity Recognition. Electronics 2020, 9, 1001. [Google Scholar] [CrossRef]
- Yao, L.; Huang, H.; Wang, K.-W.; Chen, S.-H.; Xiong, Q. Fine-Grained Mechanical Chinese Named Entity Recognition Based on ALBERT-AttBiLSTM-CRF and Transfer Learning. Symmetry 2020, 12, 1986. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. A Multimodal Approach for Early Detection of Cognitive Impairment from Tweets. In Human Interaction, Emerging Technologies and Future Systems V. IHIET 2021. Lecture Notes in Networks and Systems; Ahram, T., Taiar, R., Eds.; Springer: Cham, Switzerland, 2021; Volume 319. [Google Scholar] [CrossRef]
- Cui, L.; Zhang, Y. Hierarchically-refined label attention network for sequence labeling. In Proceedings of the EMNLP, Hong Kong, China, 3–7 November 2019; pp. 4113–4126. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training text encoders as discriminators rather than generators. In Proceedings of the ICLR, Virtual, 26 April–1 May 2020; pp. 1–14. [Google Scholar]
- Kim, H.; Kim, H. Integrated Model for Morphological Analysis and Named Entity Recognition Based on Label Attention Networks in Korean. Appl. Sci. 2020, 10, 3740. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A lite BERT for self-supervised learning of language representations. In Proceedings of the ICLR, Virtual, 26 April–1 May 2020. [Google Scholar]
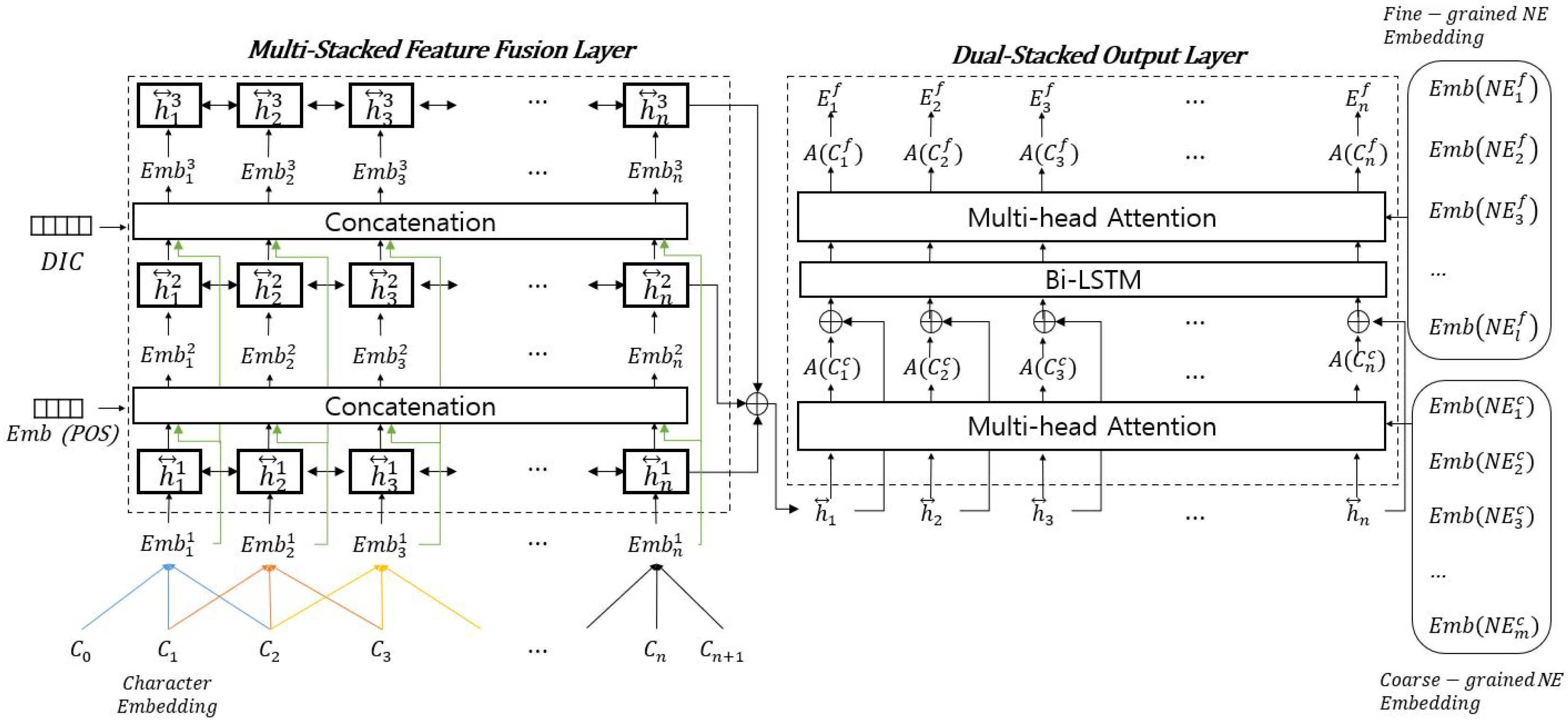

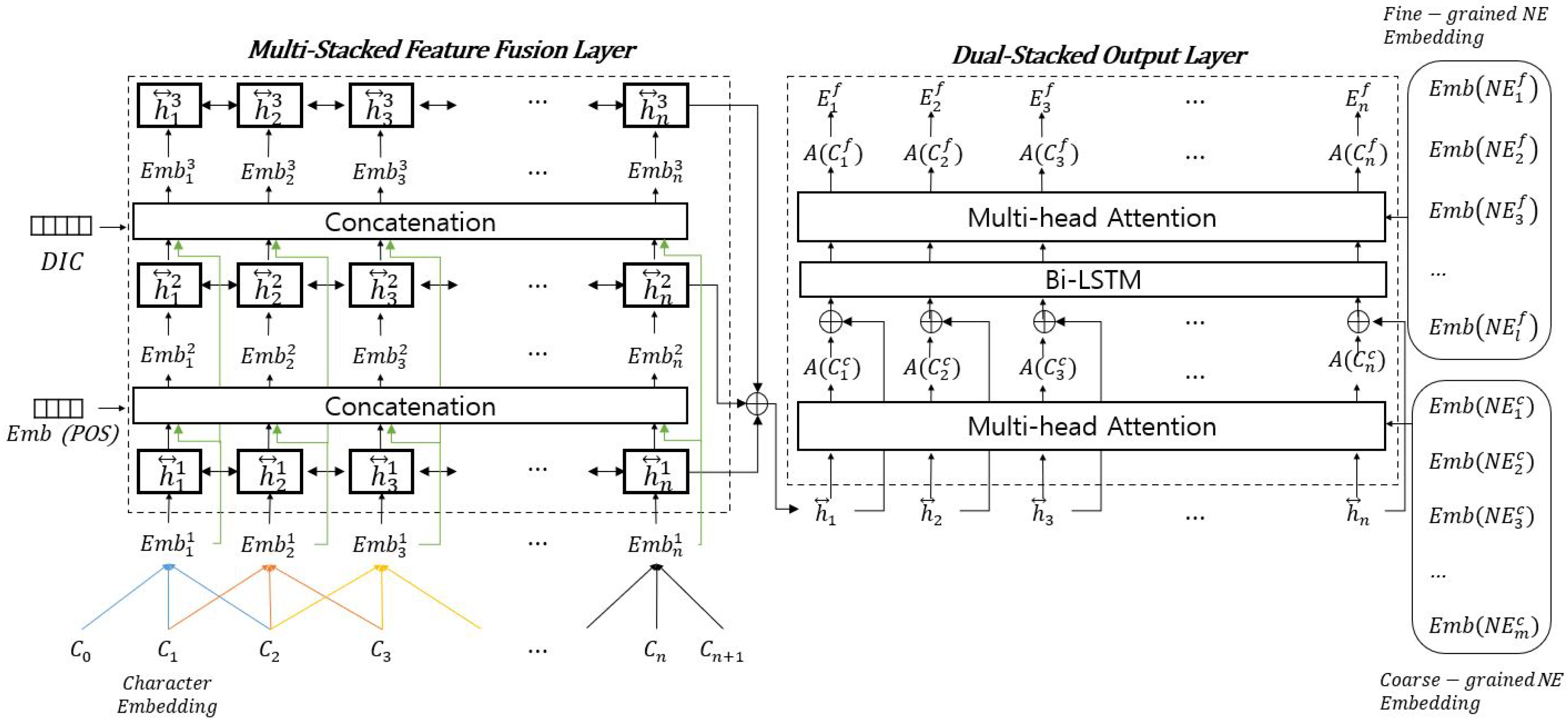{kind=link}
| Coarse-Grained NE | Fine-Grained NE | ||
|---|---|---|---|
| Class | Example | Class | Example |
| Location | USA, Washington, D.C., Memorial park | Country Province Gangwon-do | Korea City Seoul |
| Date | Thanksgiving day, 24 April 2020 | Year Duration | 2020 2019–2021 |
| NE Tag | Description |
|---|---|
| B-(PER|LOC|ORG|...) | Beginning character of an NE with the category following “B-” |
| I-(PER|LOC|ORG|...) | Inner character of an NE with the category following “I-” |
| O | Character out of any NE boundary |
| Coarse-Grained NE Tag | Description | Percent |
|---|---|---|
| QT | Quantity | 15.9% |
| DT | Date | 14.0% |
| OG | Organization | 12.6% |
| TR | Theroy | 8.7% |
| CV | Civilization | 8.2% |
| Fine-Grained NE Tag | Description | Percent |
| TR-Technology | The technology of Theory | 7.6% |
| DT-Year | The Year of Date | 5.3% |
| DT-Month | The month of Date | 4.8% |
| PS-Name | The name of Person | 4.7% |
| OG-Business | The business of Organization | 3.9% |
| Parameter | Value |
|---|---|
| The dimension of character embedding | 50 |
| The dimension of POS embedding | 16 |
| The dimension of hidden node in the feature fusion layer | 128 |
| The dimension of hidden node in the output layer | 256 |
| The dimension of Coarse-grained NE embedding | 768 |
| The dimension of Fine-grained NE embedding | 512 |
| Batch size | 64 |
| Learning rate | 0.001 |
| Epoch | 100 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| 1-In+1-Out | 0.783 | 0.681 | 0.728 |
| 3-In+1-Out | 0.831 | 0.730 | 0.777 |
| 3-In(H)+1-Out | 0.844 | 0.752 | 0.795 |
| 1-In+2-Out | 0.808 | 0.701 | 0.750 |
| 3-In+2-Out | 0.849 | 0.760 | 0.801 |
| 3-In(H)+2-Out | 0.865 | 0.769 | 0.814 |
| Task | Model | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Fine-grained NER | KoELECTRA-NER | 0.855 | 0.757 | 0.802 |
| 3-In(H)+2-Out | 0.865 | 0.769 | 0.814 | |
| Coarse-grained NER | Bi-LSTM-LAN | 0.855 | 0.813 | 0.833 |
| KoELECTRA-NER | 0.879 | 0.838 | 0.857 | |
| 3-In(H)-1-Out | 0.861 | 0.831 | 0.845 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Kim, H. Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean. Appl. Sci. 2021, 11, 10795. https://doi.org/10.3390/app112210795
Kim H, Kim H. Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean. Applied Sciences. 2021; 11(22):10795. https://doi.org/10.3390/app112210795
Chicago/Turabian StyleKim, Hongjin, and Harksoo Kim. 2021. "Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean" Applied Sciences 11, no. 22: 10795. https://doi.org/10.3390/app112210795
APA StyleKim, H., & Kim, H. (2021). Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean. Applied Sciences, 11(22), 10795. https://doi.org/10.3390/app112210795