
An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification

Abstract
:1. Introduction
2. Related Work
2.1. Conventional Machine Learning Algorithms
2.2. Deep Learning-Based Methods
3. Materials and Methods
3.1. Dataset Description
3.2. Image Preprocessing
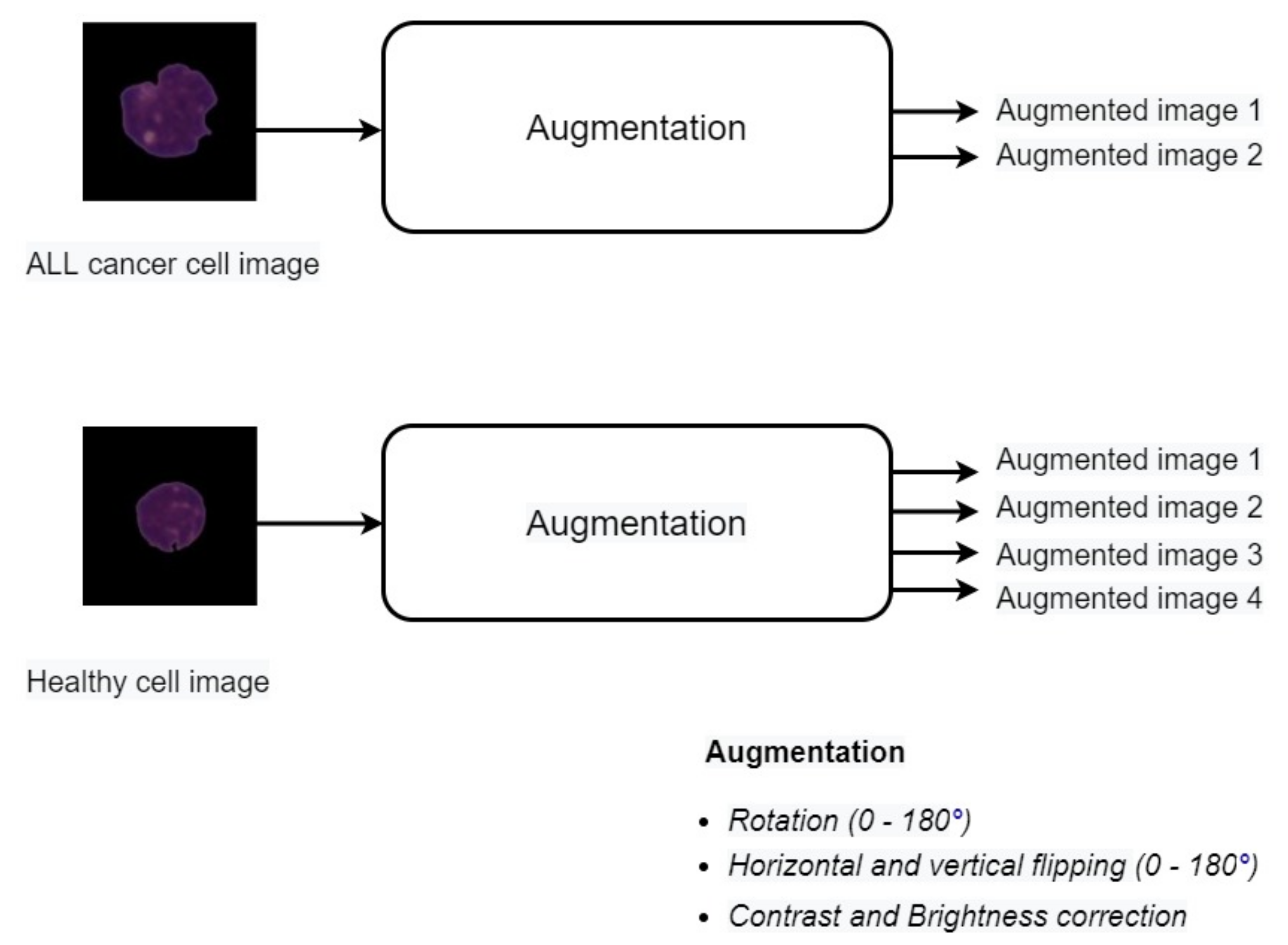
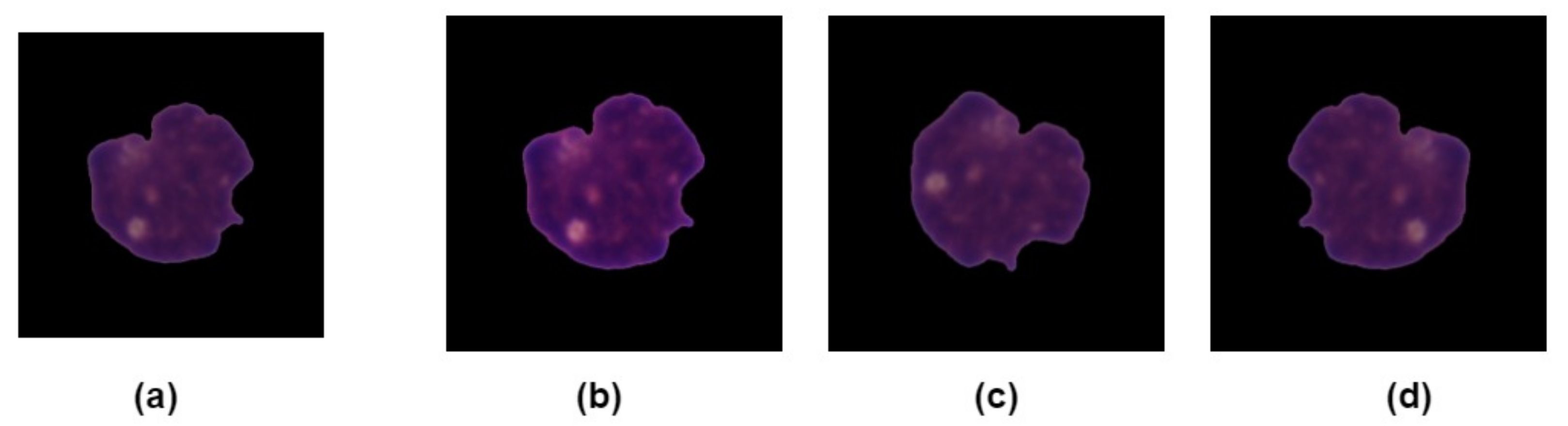
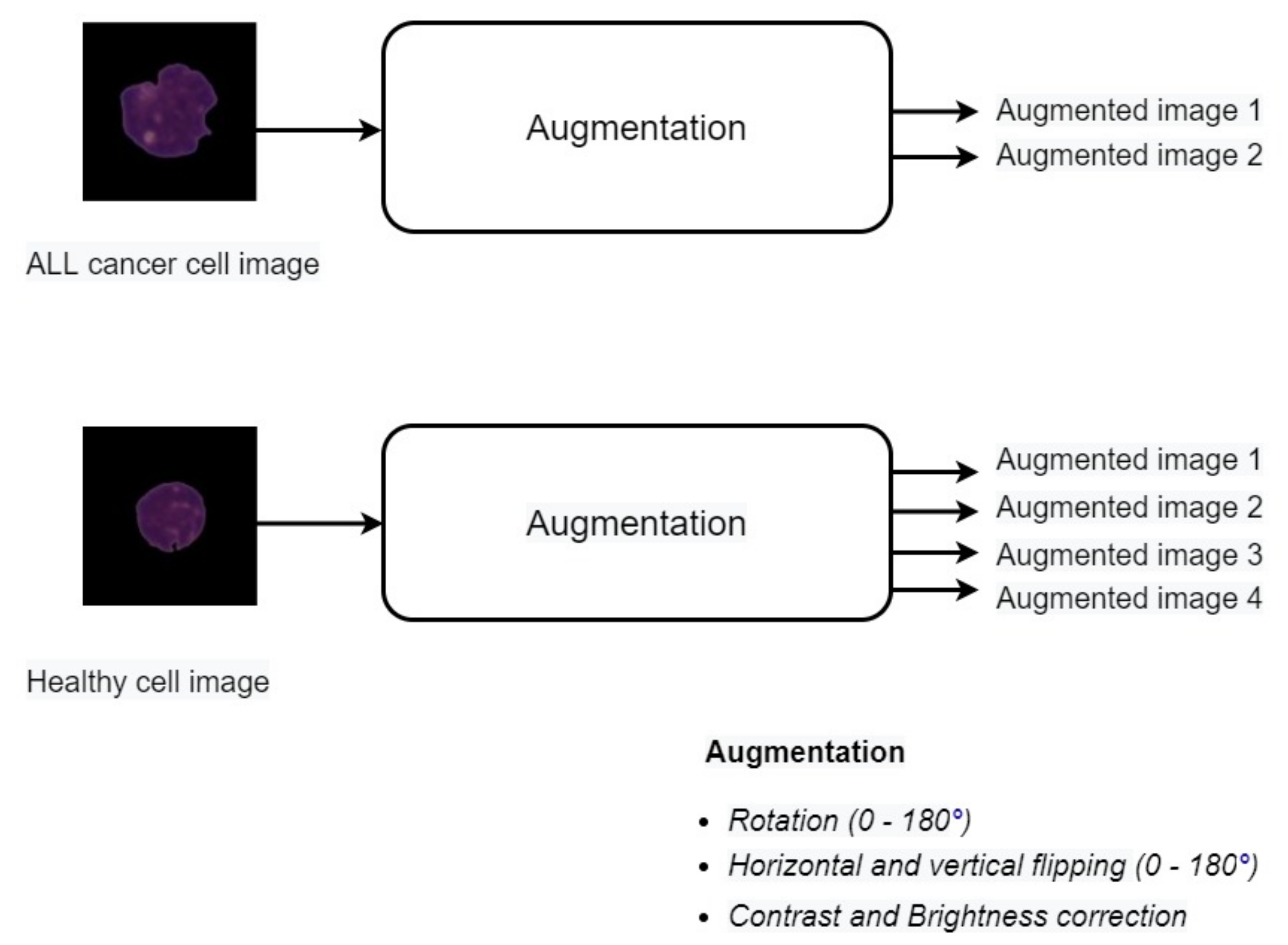
3.3. Data Augmentation
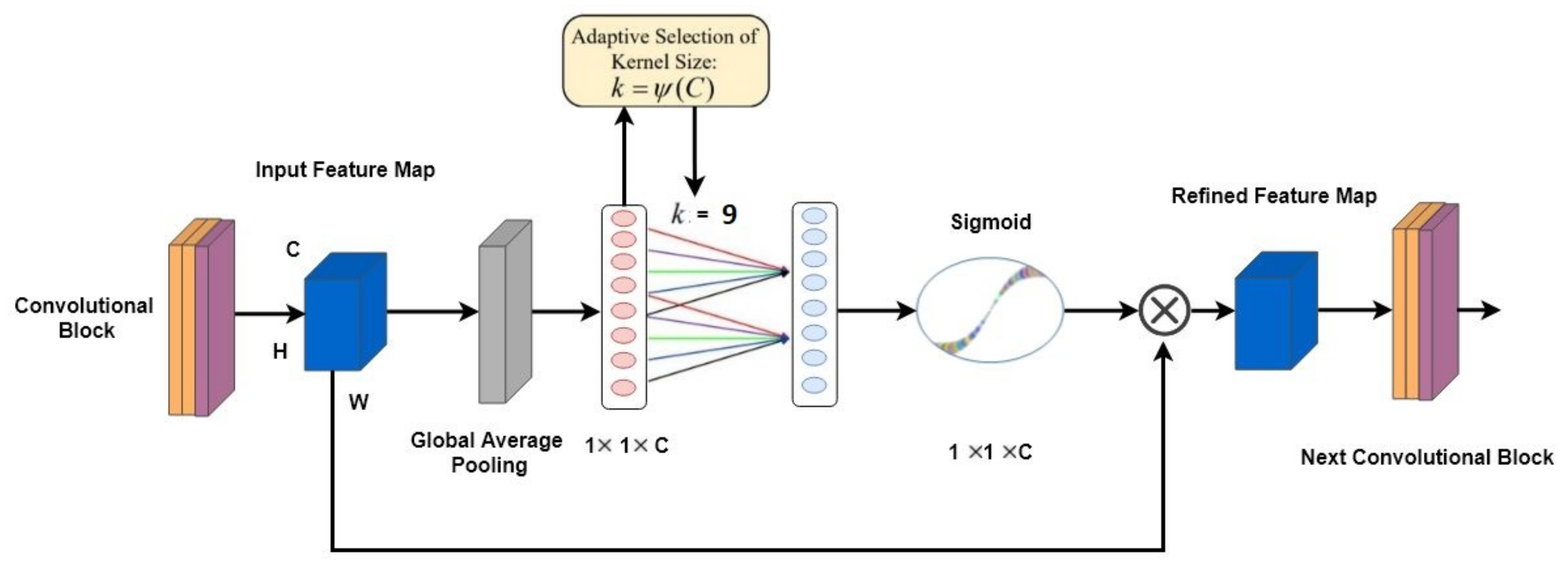
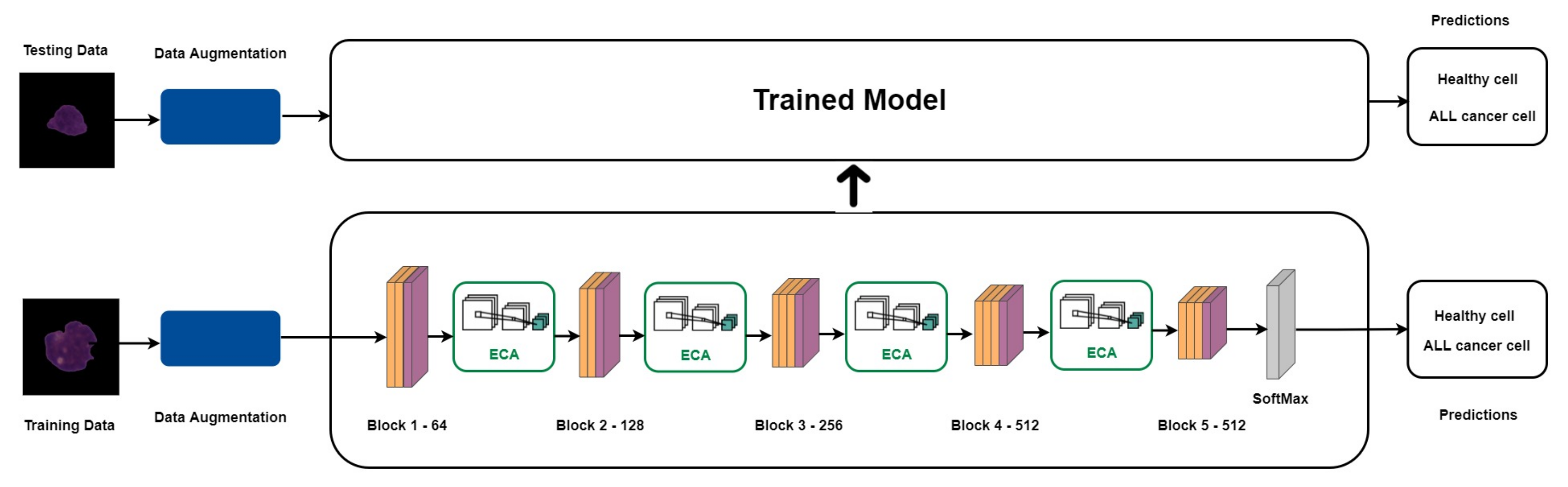
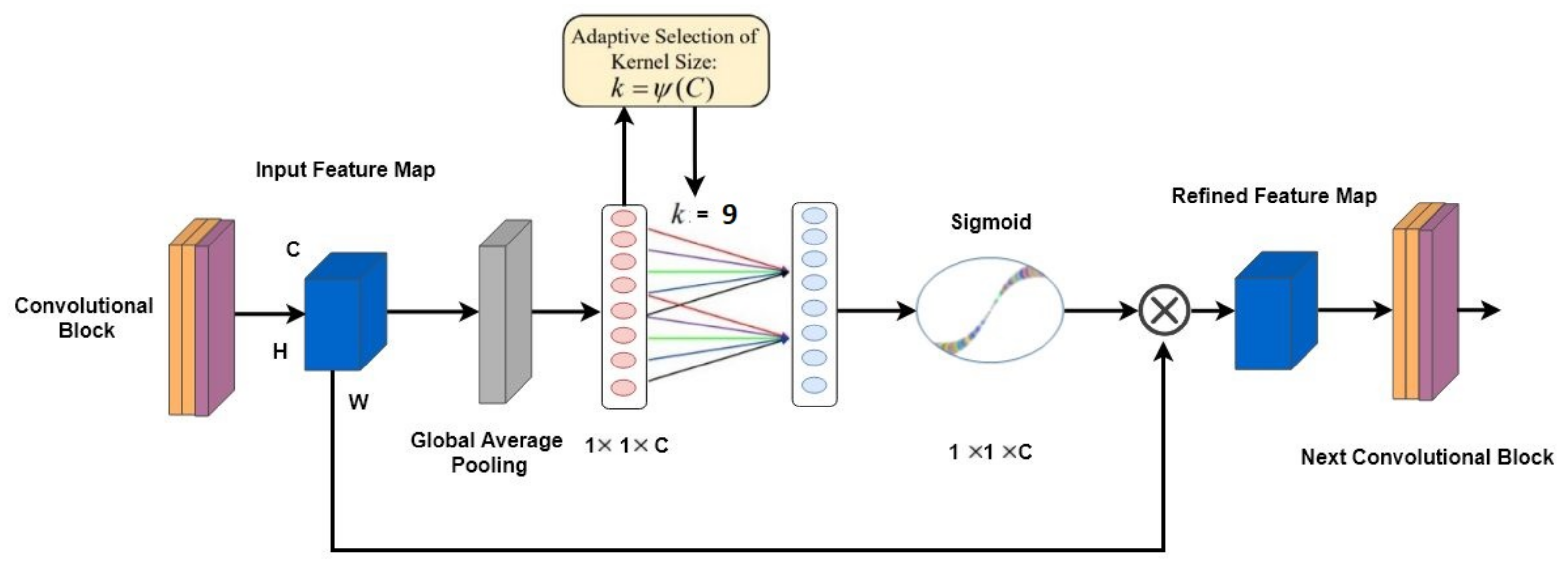
3.4. ECA-Net Based on VGG16
The Overall Architecture
3.5. Experimental Setting
3.6. Evaluation Metrics
4. Results
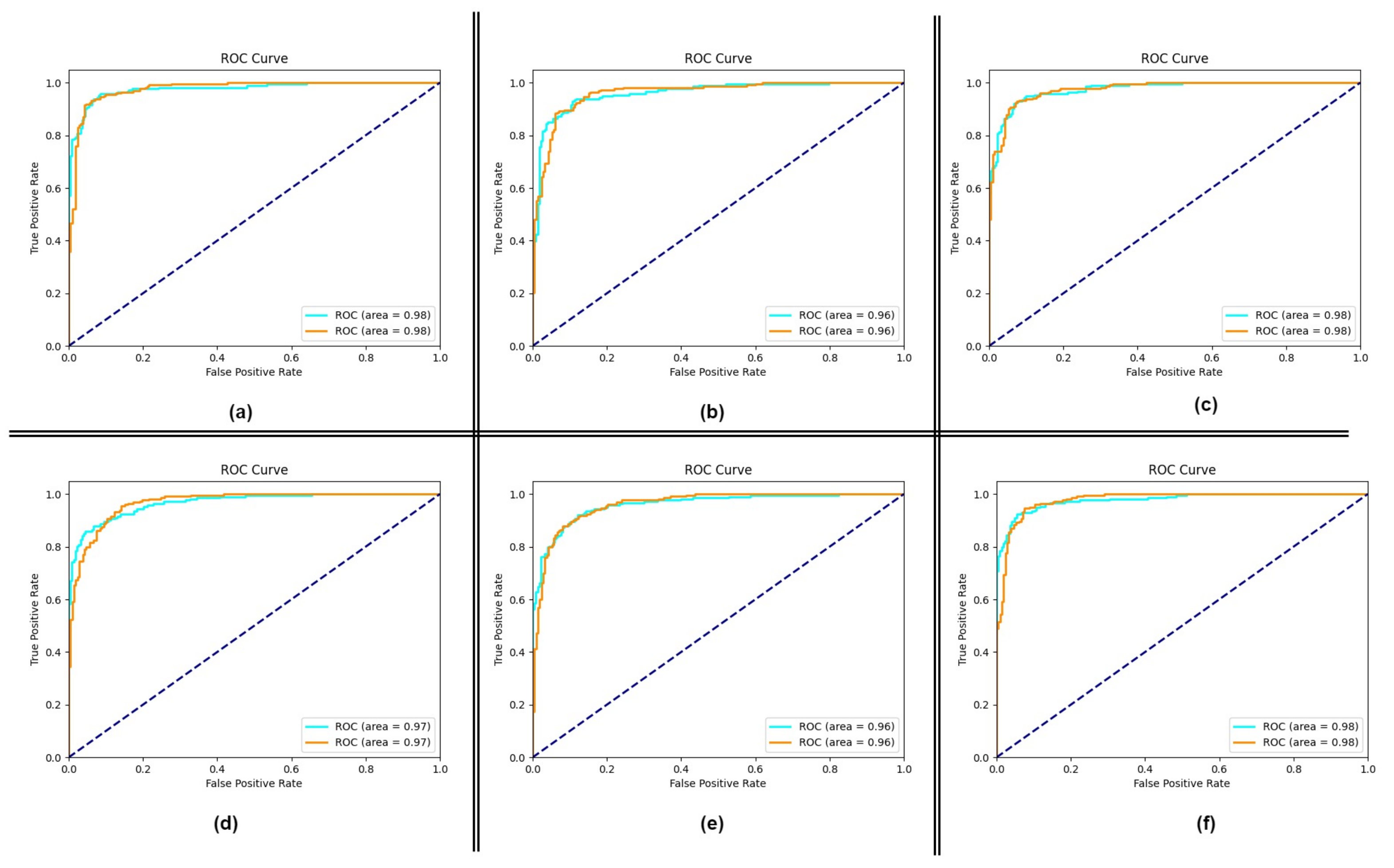
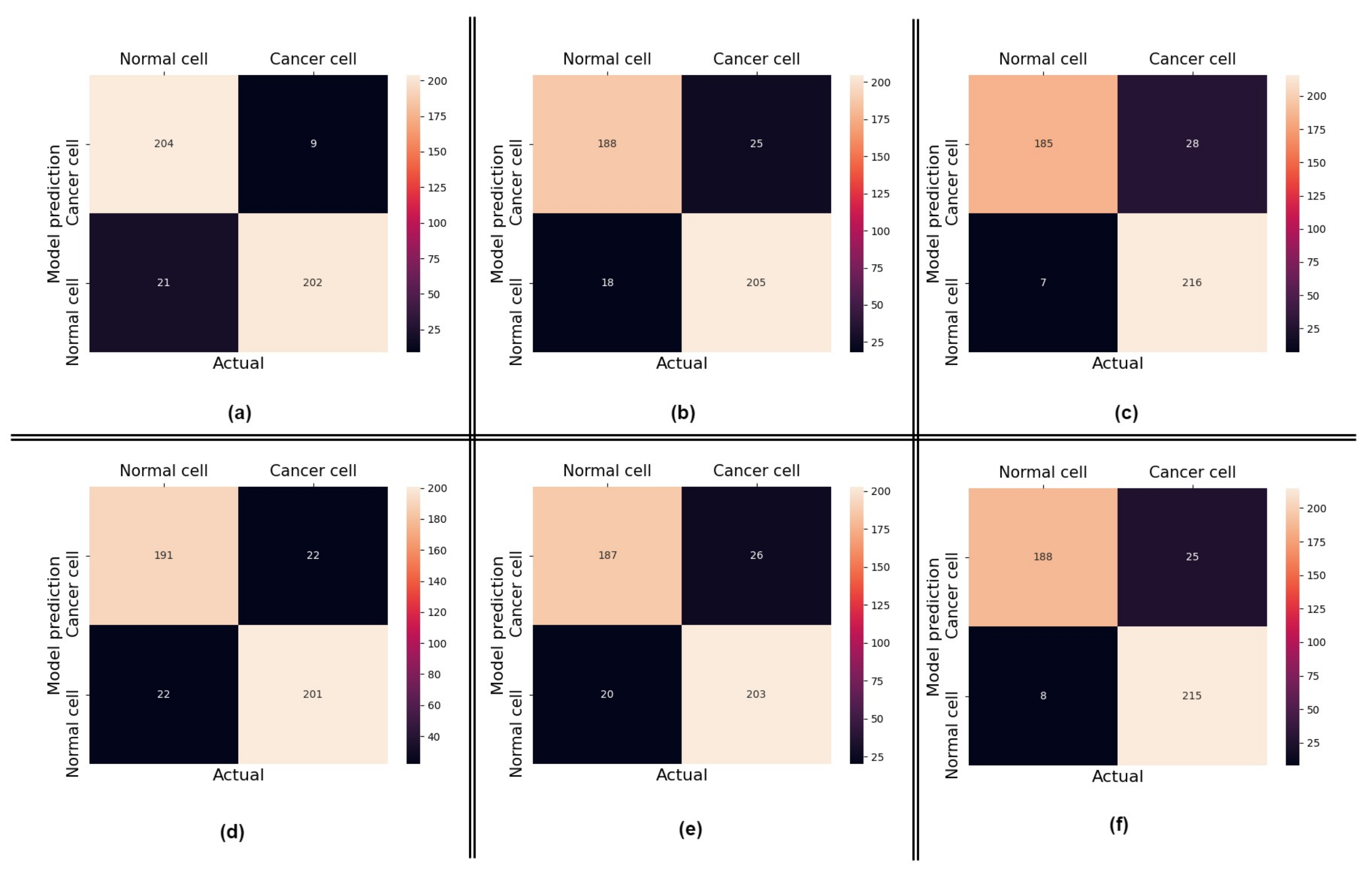
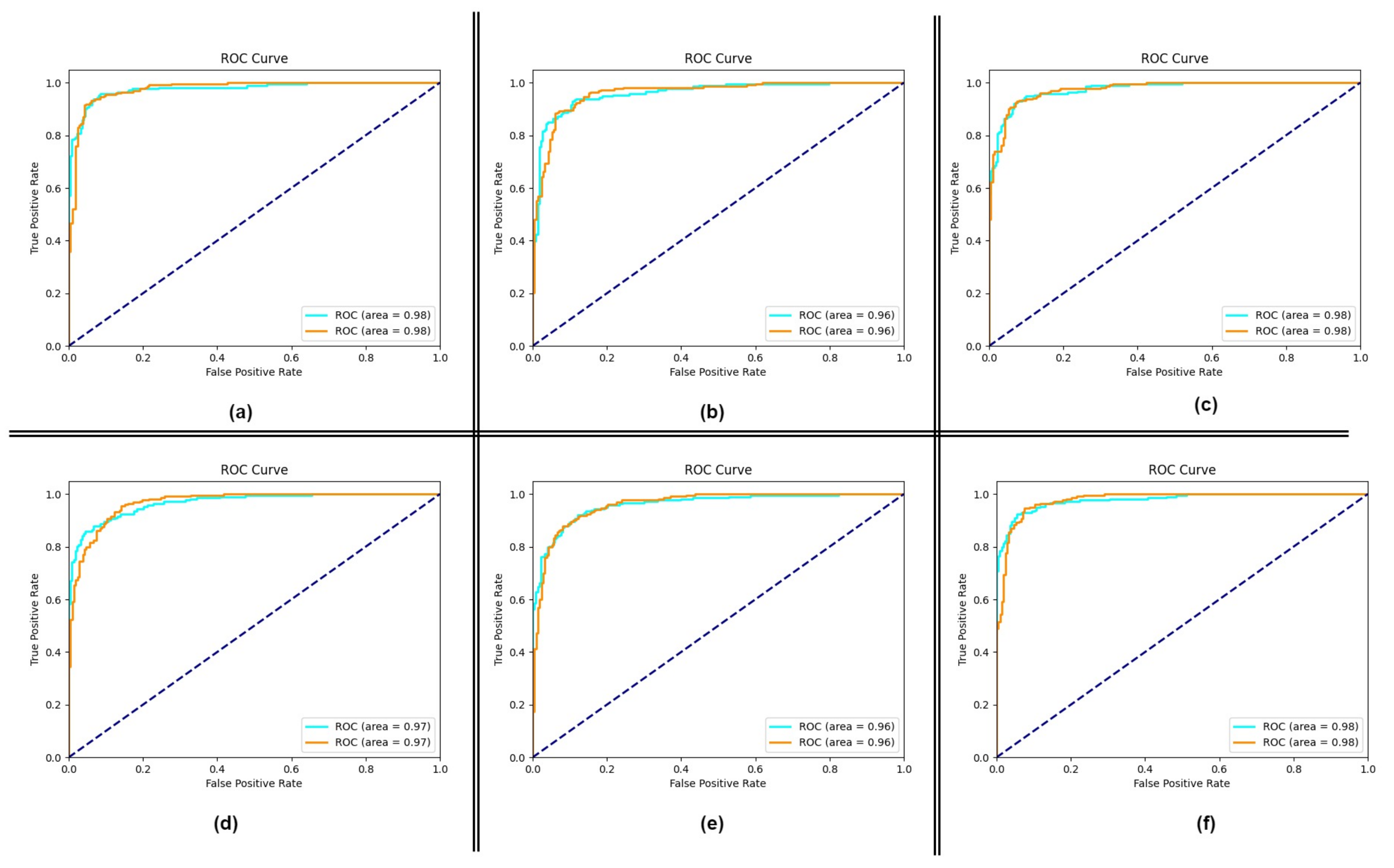
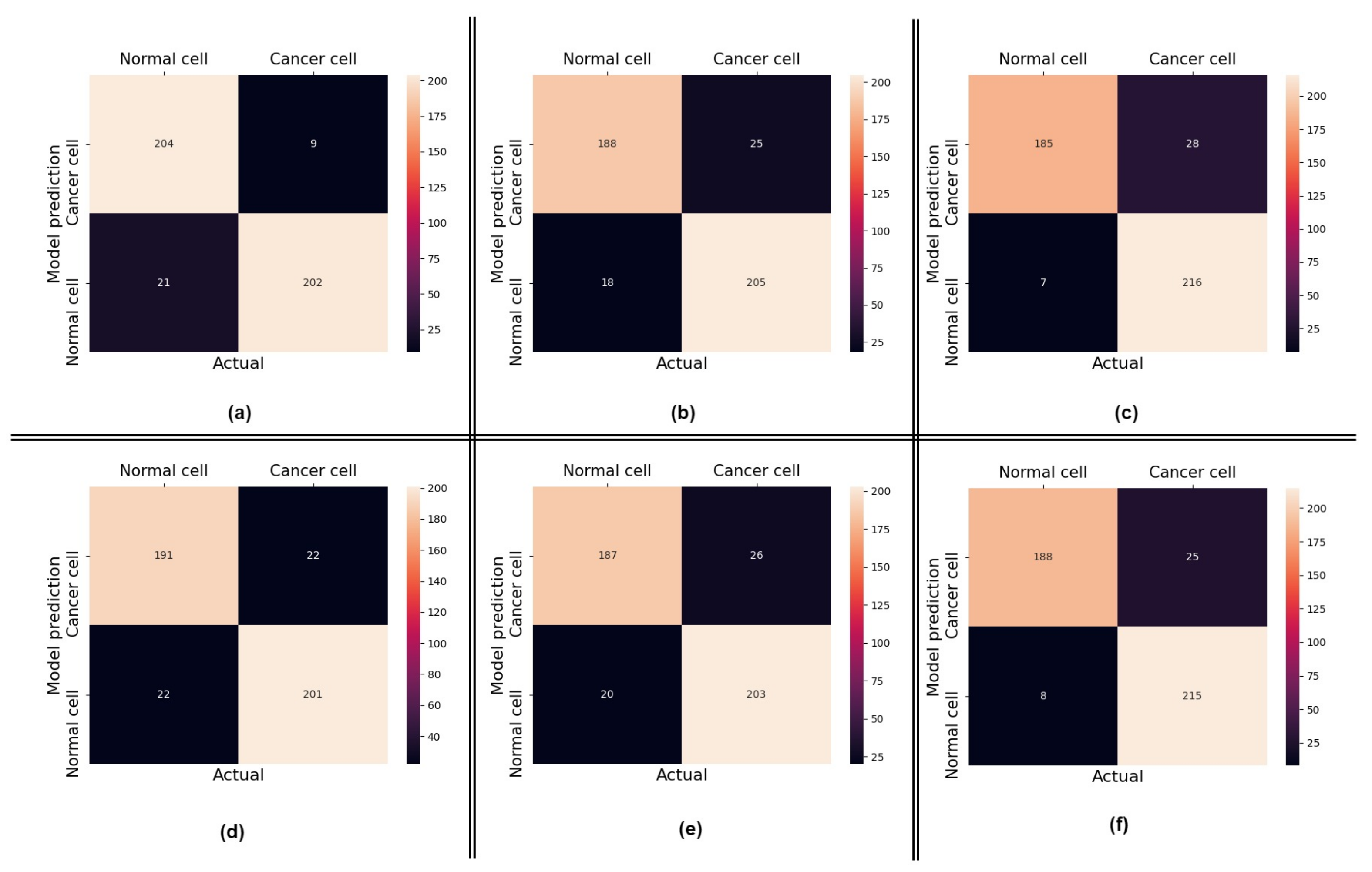
4.1. Performance of the Proposed Method
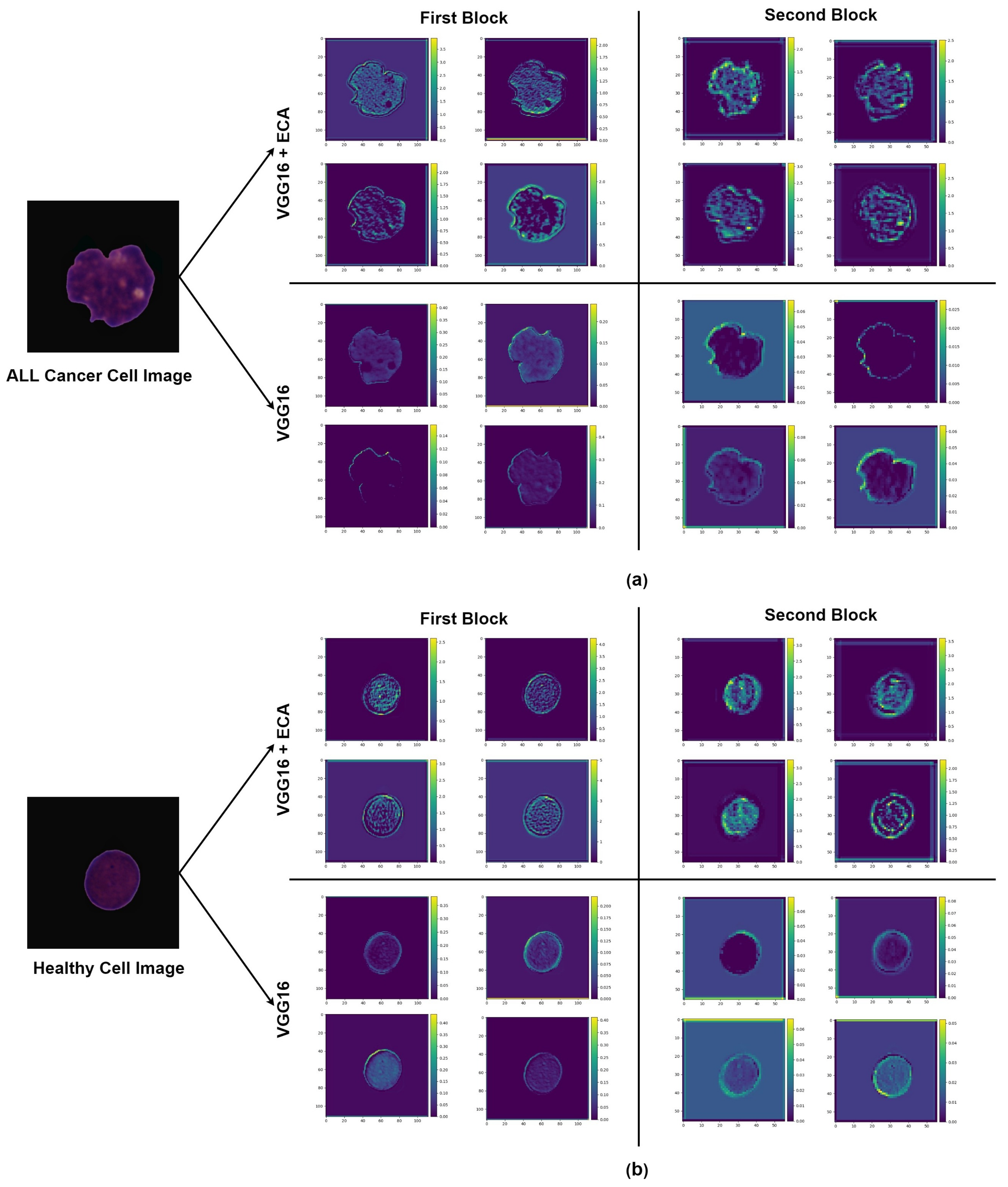
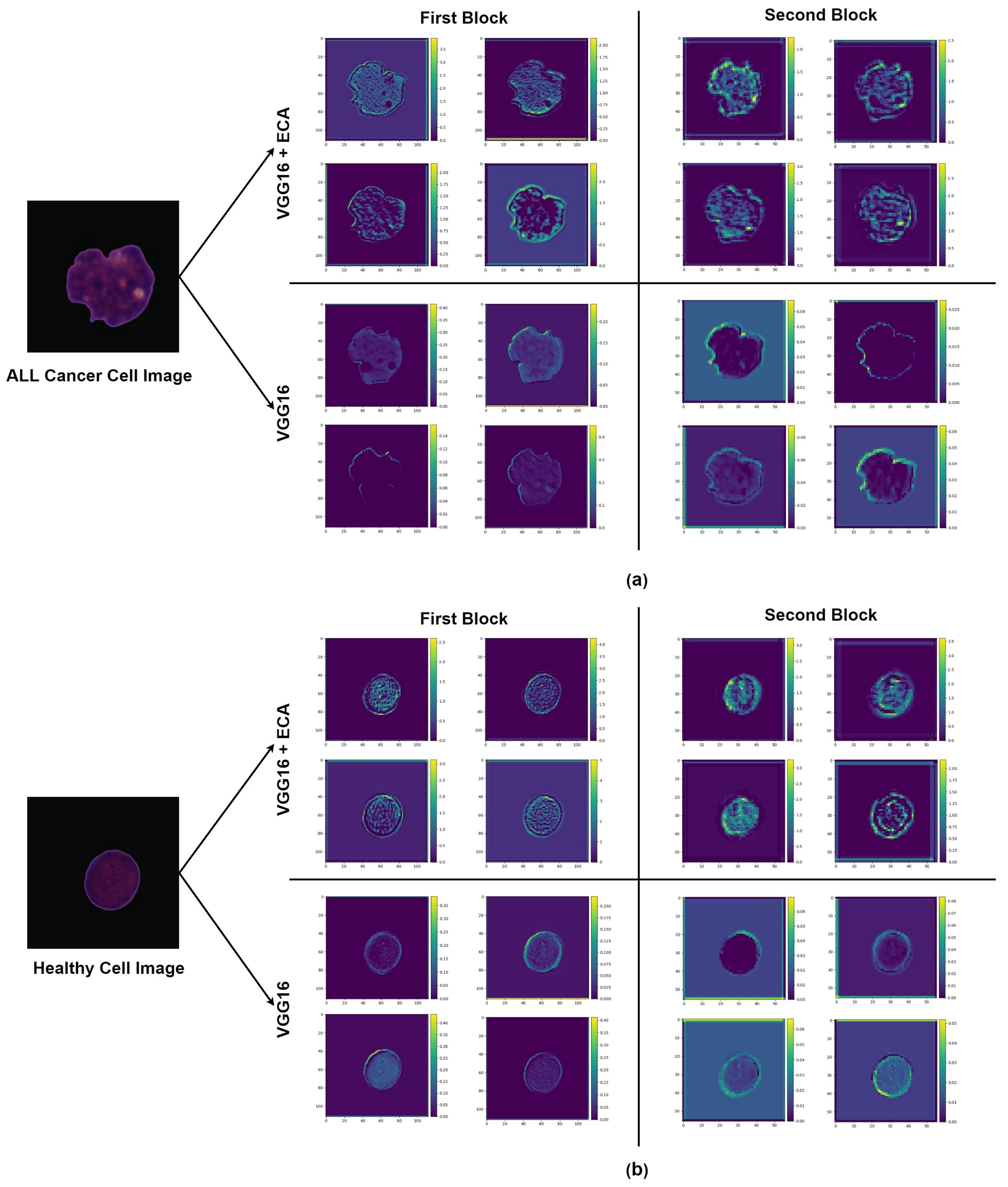
4.2. Impact of Using Attention
4.3. Comparisons with Other Approaches
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Laosai, J.; Chamnongthai, K. Classification of acute leukemia using medical-knowledge-based morphology and CD marker. Biomed. Signal Process. Control 2018, 44, 127–137. [Google Scholar] [CrossRef]
- Vogado, L.H.; Veras, R.M.; Araujo, F.H.; Silva, R.R.; Aires, K.R. Leukemia diagnosis in blood slides using transfer learning in CNNs and SVM for classification. Eng. Appl. Artif. Intell. 2018, 72, 415–422. [Google Scholar] [CrossRef]
- American Society of Hematology. Hematology. Available online: https://www.hematology.org (accessed on 24 April 2021).
- Key Statistics for Acute Lymphocytic Leukemia. American Cancer Society. Available online: https://www.cancer.org/cancer/acute-lymphocytic-leukemia/about/key-statistics.html (accessed on 24 April 2021).
- Curesearch for Childrens Cancer Research. Curesearch. Available online: https://curesearch.org/Acute-Lymphoblastic-Leukemia-in-Children (accessed on 20 April 2021).
- Mohamed, M.; Far, B.; Guaily, A. An efficient technique for white blood cells nuclei automatic segmentation. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; pp. 220–225. [Google Scholar]
- Amin, M.M.; Kermani, S.; Talebi, A.; Oghli, M.G. Recognition of acute lymphoblastic leukemia cells in microscopic images using k-means clustering and support vector machine classifier. J. Med. Signals Sens. 2015, 5, 49. [Google Scholar]
- Duggal, R.; Gupta, A.; Gupta, R. Segmentation of overlapping/touching white blood cell nuclei using artificial neural networks. CME Series on Hemato-Oncopathology; All India Institute of Medical Sciences (AIIMS): New Delhi, India, 2016. [Google Scholar]
- Duggal, R.; Gupta, A.; Gupta, R.; Mallick, P. SD-layer: Stain deconvolutional layer for CNNs in medical microscopic imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 435–443. [Google Scholar]
- Duggal, R.; Gupta, A.; Gupta, R.; Wadhwa, M.; Ahuja, C. Overlapping cell nuclei segmentation in microscopic images using deep belief networks. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, Guwahati, India, 18–22 December 2016; pp. 1–8. [Google Scholar]
- Gupta, A.; Duggal, R.; Gehlot, S.; Gupta, R.; Mangal, A.; Kumar, L.; Thakkar, N.; Satpathy, D. GCTI-SN: Geometry-inspired chemical and tissue invariant stain normalization of microscopic medical images. Med. Image Anal. 2020, 65, 101788. [Google Scholar] [CrossRef]
- Gupta, R.; Mallick, P.; Duggal, R.; Gupta, A.; Sharma, O. Stain color normalization and segmentation of plasma cells in microscopic images as a prelude to development of computer assisted automated disease diagnostic tool in multiple myeloma. Clin. Lymphoma Myeloma Leuk. 2017, 17, e99. [Google Scholar] [CrossRef]
- Bayramoglu, N.; Heikkilä, J. Transfer learning for cell nuclei classification in histopathology images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 532–539. [Google Scholar]
- Gao, Z.; Wang, L.; Zhou, L.; Zhang, J. HEp-2 cell image classification with deep convolutional neural networks. IEEE J. Biomed. Health Inform. 2016, 21, 416–428. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Zhang, M.; Zhou, Z.; Chu, J.; Cao, F. Automatic detection and classification of leukocytes using convolutional neural networks. Med. Biol. Eng. Comput. 2017, 55, 1287–1301. [Google Scholar] [CrossRef]
- Joshi, M.D.; Karode, A.H.; Suralkar, S. White blood cells segmentation and classification to detect acute leukemia. Int. J. Emerg. Trends Technol. Comput. Sci. (IJETTCS) 2013, 2, 147–151. [Google Scholar]
- Mohapatra, S.; Patra, D.; Satpathy, S. An ensemble classifier system for early diagnosis of acute lymphoblastic leukemia in blood microscopic images. Neural Comput. Appl. 2014, 24, 1887–1904. [Google Scholar] [CrossRef]
- Putzu, L.; Caocci, G.; Di Ruberto, C. Leucocyte classification for leukaemia detection using image processing techniques. Artif. Intell. Med. 2014, 62, 179–191. [Google Scholar] [CrossRef] [Green Version]
- Singhal, V.; Singh, P. Local binary pattern for automatic detection of acute lymphoblastic leukemia. In Proceedings of the 2014 Twentieth National Conference on Communications (NCC), Kanpur, India, 28 February–2 March 2014; pp. 1–5. [Google Scholar]
- Patel, N.; Mishra, A. Automated leukaemia detection using microscopic images. Procedia Comput. Sci. 2015, 58, 635–642. [Google Scholar] [CrossRef] [Green Version]
- Karthikeyan, T.; Poornima, N. Microscopic image segmentation using fuzzy c means for leukemia diagnosis. Int. J. Adv. Res. Sci. Eng. Technol. 2017, 4, 3136–3142. [Google Scholar]
- Mohamed, H.; Omar, R.; Saeed, N.; Essam, A.; Ayman, N.; Mohiy, T.; AbdelRaouf, A. Automated detection of white blood cells cancer diseases. In Proceedings of the 2018 First International Workshop on Deep and Representation Learning (IWDRL), Cairo, Egypt, 29 March 2018; pp. 48–54. [Google Scholar]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Yan, Z.; Zhan, Y.; Peng, Z.; Liao, S.; Shinagawa, Y.; Metaxas, D.N.; Zhou, X.S. Bodypart recognition using multi-stage deep learning. In Proceedings of the International Conference on Information Processing in Medical Imaging, Sabhal Mor Ostaig/Isle of Skye, UK, 28 June–3 July 2015; pp. 449–461. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Yang, X.; Kwitt, R.; Styner, M.; Niethammer, M. Quicksilver: Fast predictive image registration–a deep learning approach. NeuroImage 2017, 158, 378–396. [Google Scholar] [CrossRef] [PubMed]
- Stefano, A.; Comelli, A. Customized Efficient Neural Network for COVID-19 Infected Region Identification in CT Images. J. Imaging 2021, 7, 131. [Google Scholar] [CrossRef]
- Comelli, A.; Dahiya, N.; Stefano, A.; Vernuccio, F.; Portoghese, M.; Cutaia, G.; Bruno, A.; Salvaggio, G.; Yezzi, A. Deep learning-based methods for prostate segmentation in magnetic resonance imaging. Appl. Sci. 2021, 11, 782. [Google Scholar] [CrossRef] [PubMed]
- Rehman, A.; Abbas, N.; Saba, T.; Rahman, S.I.u.; Mehmood, Z.; Kolivand, H. Classification of acute lymphoblastic leukemia using deep learning. Microsc. Res. Tech. 2018, 81, 1310–1317. [Google Scholar] [CrossRef]
- Shafique, S.; Tehsin, S. Acute lymphoblastic leukemia detection and classification of its subtypes using pretrained deep convolutional neural networks. Technol. Cancer Res. Treat. 2018, 17, 1533033818802789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Habibzadeh, M.; Jannesari, M.; Rezaei, Z.; Baharvand, H.; Totonchi, M. Automatic white blood cell classification using pre-trained deep learning models: Resnet and inception. In Proceedings of the Tenth International Conference on Machine Vision (ICMV 2017), International Society for Optics and Photonics, Vienna, Austria, 13–15 November 2017; Volume 10696, p. 1069612. [Google Scholar]
- Ahmed, N.; Yigit, A.; Isik, Z.; Alpkocak, A. Identification of leukemia subtypes from microscopic images using convolutional neural network. Diagnostics 2019, 9, 104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Wang, J.; Zhou, M.; Li, Q.; Wang, Y. Spectral-spatial feature-based neural network method for acute lymphoblastic leukemia cell identification via microscopic hyperspectral imaging technology. Biomed. Opt. Express 2017, 8, 3017–3028. [Google Scholar] [CrossRef] [Green Version]
- Pansombut, T.; Wikaisuksakul, S.; Khongkraphan, K.; Phon-On, A. Convolutional neural networks for recognition of lymphoblast cell images. Comput. Intell. Neurosci. 2019, 2019. [Google Scholar] [CrossRef]
- Gehlot, S.; Gupta, A.; Gupta, R. SDCT-AuxNetθ: DCT augmented stain deconvolutional CNN with auxiliary classifier for cancer diagnosis. Med. Image Anal. 2020, 61, 101661. [Google Scholar] [CrossRef] [PubMed]
- Kasani, P.H.; Park, S.W.; Jang, J.W. An Aggregated-Based Deep Learning Method for Leukemic B-lymphoblast Classification. Diagnostics 2020, 10, 1064. [Google Scholar] [CrossRef] [PubMed]
- Kassani, S.H.; Kassani, P.H.; Wesolowski, M.J.; Schneider, K.A.; Deters, R. A hybrid deep learning architecture for leukemic B-lymphoblast classification. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 16–18 October 2019; pp. 271–276. [Google Scholar]
- Kant, S.; Kumar, P.; Gupta, A.; Gupta, R. Leukonet: Dct-based cnn architecture for the classification of normal versus leukemic blasts in b-all cancer. arXiv 2018, arXiv:1810.07961. [Google Scholar]
- Labati, R.D.; Piuri, V.; Scotti, F. All-IDB: The acute lymphoblastic leukemia image database for image processing. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2045–2048. [Google Scholar]
- Iqbal, S.; Ghani, M.U.; Saba, T.; Rehman, A. Brain tumor segmentation in multi-spectral MRI using convolutional neural networks (CNN). Microsc. Res. Tech. 2018, 81, 419–427. [Google Scholar] [CrossRef] [PubMed]
- Cireşan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. High-performance neural networks for visual object classification. arXiv 2011, arXiv:1102.0183. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–27 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xiao, F.; Kuang, R.; Ou, Z.; Xiong, B. DeepMEN: Multi-model Ensemble Network for B-Lymphoblast Cell Classification. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 83–93. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Qilong, W.; Banggu, W.; Pengfei, Z.; Peihua, L.; Wangmeng, Z.; Qinghua, H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Pan, Y.; Liu, M.; Xia, Y.; Shen, D. Neighborhood-correction algorithm for classification of normal and malignant cells. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 73–82. [Google Scholar]
- Verma, E.; Singh, V. ISBI Challenge 2019: Convolution Neural Networks for B-ALL Cell Classification. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 131–139. [Google Scholar]
- Shi, T.; Wu, L.; Zhong, C.; Wang, R.; Zheng, W. Ensemble Convolutional Neural Networks for Cell Classification in Microscopic Images. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 43–51. [Google Scholar]
- Liu, Y.; Long, F. Acute lymphoblastic leukemia cells image analysis with deep bagging ensemble learning. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 113–121. [Google Scholar]
- Shah, S.; Nawaz, W.; Jalil, B.; Khan, H.A. Classification of normal and leukemic blast cells in B-ALL cancer using a combination of convolutional and recurrent neural networks. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 23–31. [Google Scholar]
- Ding, Y.; Yang, Y.; Cui, Y. Deep learning for classifying of white blood cancer. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 33–41. [Google Scholar]
- Xie, X.; Li, Y.; Zhang, M.; Wu, Y.; Shen, L. Multi-streams and Multi-features for Cell Classification. In Proceedings of the ISBI 2019 C-NMC Challenge: Classification in Cancer Cell Imaging, Venicee, Italy, 8–11 April 2019; pp. 95–102. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cancer Cell Images | ||
| Fold | No. of Subjects | No. of Images |
| 1 | 8 | 1119 |
| 2 | 7 | 1100 |
| 3 | 4 | 1200 |
| 4 | 7 | 1218 |
| 5 | 8 | 1203 |
| 6 | 7 | 1209 |
| Total | 41 | 7049 |
| Normal Cell Images | ||
| Fold | No. of Subjects | No. of Images |
| 1 | 3 | 562 |
| 2 | 4 | 473 |
| 3 | 4 | 538 |
| 4 | 3 | 541 |
| 5 | 3 | 524 |
| 6 | 3 | 538 |
| Total | 20 | 3176 |
| Testing Data | ||
| Class | Subjects | No. of Images |
| Healthy | 6 | 213 |
| Cancer | 6 | 223 |
| Total | 12 | 436 |
| Cancer Cell Images | ||
| Fold | Before Augmentation | After Augmentation |
| 1 | 1119 | 2238 |
| 2 | 1100 | 2200 |
| 3 | 1200 | 2400 |
| 4 | 1248 | 2436 |
| 5 | 1203 | 2406 |
| 6 | 1209 | 2418 |
| Total | 7049 | 14,098 |
| Normal Cell Images | ||
| Fold | Before Augmentation | After Augmentation |
| 1 | 562 | 2248 |
| 2 | 473 | 1892 |
| 3 | 538 | 2152 |
| 4 | 541 | 2164 |
| 5 | 524 | 2096 |
| 6 | 538 | 2152 |
| Total | 3176 | 12,704 |
| Layer Name | Input Shape | Output Shape | Stride | Conv Kernel Size |
|---|---|---|---|---|
| Conv1-1-64 | 224 × 224 × 3 | 224 × 224 × 64 | 1 | 3 × 3 |
| Conv1-1-64 | 224 × 224 × 64 | 224 × 224 × 64 | 1 | 3 × 3 |
| Maxpool-1 | 224 × 224 × 64 | 112 × 112 × 64 | 2 | 2 × 2 |
| Conv2-1-128 | 112 × 112 × 64 | 112 × 112 × 128 | 1 | 3 × 3 |
| Conv2-1-128 | 112 × 112 × 128 | 112 × 112 × 128 | 1 | 3 × 3 |
| Maxpool-2 | 112 × 112 × 128 | 56 × 56 × 128 | 2 | 2 × 2 |
| Conv3-1-256 | 56 × 56 × 128 | 56 × 56 × 256 | 1 | 3 × 3 |
| Conv3-1-256 | 56 × 56 × 256 | 56 × 56 × 256 | 1 | 3 × 3 |
| Maxpool-3 | 56 × 56 × 256 | 28 × 28 × 256 | 2 | 2 × 2 |
| Conv4-1-512 | 28 × 28 × 256 | 28 × 28 × 512 | 1 | 3 × 3 |
| Conv4-1-512 | 28 × 28 × 512 | 28 × 28 × 512 | 1 | 3 × 3 |
| Maxpool-4 | 28 × 28 × 512 | 14 × 14 × 512 | 2 | 2 × 2 |
| Conv5-1-512 | 14 × 14 × 512 | 14 × 14 × 512 | 1 | 3 × 3 |
| Conv5-1-512 | 14 × 14 × 512 | 14 × 14 × 512 | 1 | 3 × 3 |
| Maxpool-4 | 14 × 14 × 512 | 7 × 7 × 512 | 2 | 2 × 2 |
| Fully connected-1 | 1 × 1 × 25,088 | 1 × 1 × 4096 | 1 | 1 × 1 |
| Fully connected-2 | 1 × 1 × 4096 | 1 × 1 × 4096 | 1 | 1 × 1 |
| Fully connected-3 | 1 × 1 × 4096 | 1 × 1 × 1000 | 1 | 1 × 1 |
| Methods | Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Fold-6 | Mean | Std |
|---|---|---|---|---|---|---|---|---|
| VGG16 + Attention | 0.931 | 0.901 | 0.919 | 0.899 | 0.894 | 0.924 | 0.911 | 0.013 |
| VGG16 | 0.862 | 0.837 | 0.841 | 0.823 | 0.818 | 0.855 | 0.839 | 0.015 |
| Folds | Accuracy | Sensitivity (Recall) | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|
| Fold-1 | 0.931 | 0.906 | 0.957 | 0.957 | 0.930 |
| Fold-2 | 0.901 | 0.912 | 0.891 | 0.882 | 0.891 |
| Fold-3 | 0.919 | 0.963 | 0.885 | 0.868 | 0.913 |
| Fold-4 | 0.899 | 0.896 | 0.901 | 0.901 | 0.898 |
| Fold-5 | 0.894 | 0.903 | 0.886 | 0.877 | 0.889 |
| Fold-6 | 0.924 | 0.959 | 0.895 | 0.882 | 0.918 |
| Folds | Accuracy | Sensitivity (Recall) | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|
| Fold-1 | 0.862 | 0.873 | 0.852 | 0.840 | 0.856 |
| Fold-2 | 0.837 | 0.831 | 0.842 | 0.825 | 0.832 |
| Fold-3 | 0.841 | 0.839 | 0.843 | 0.835 | 0.836 |
| Fold-4 | 0.823 | 0.820 | 0.825 | 0.816 | 0.817 |
| Fold-5 | 0.818 | 0.813 | 0.824 | 0.816 | 0.814 |
| Fold-6 | 0.855 | 0.871 | 0.841 | 0.826 | 0.847 |
| Methods | Accuracy | Year |
|---|---|---|
| NASNet-Large with VGG19 [36] | 0.965 | 2020 |
| Hybrid model (VGG16 + MobileNet) [37] | 0.961 | 2019 |
| LeukoNet [38] | 0.896 | 2018 |
| Proposed Method | 0.911 | 2021 |
| Methods | F1-Score |
|---|---|
| SDCT-AuxNet [35] | 0.948 |
| Neighborhood-correction algorithm (NCA) [54] | 0.910 |
| Ensemble model based on MobileNetV2 [55] | 0.894 |
| Deep Multi-model Ensemble Network (DeepMEN) [50] | 0.885 |
| Ensemble CNN based on SENet and PNASNet [56] | 0.879 |
| Deep Bagging Ensemble Learning [57] | 0.876 |
| LSTM-DENSE [58] | 0.866 |
| Ensemble CNN model [59] | 0.855 |
| Multi-stream model [60] | 0.848 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zakir Ullah, M.; Zheng, Y.; Song, J.; Aslam, S.; Xu, C.; Kiazolu, G.D.; Wang, L. An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification. Appl. Sci. 2021, 11, 10662. https://doi.org/10.3390/app112210662
Zakir Ullah M, Zheng Y, Song J, Aslam S, Xu C, Kiazolu GD, Wang L. An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification. Applied Sciences. 2021; 11(22):10662. https://doi.org/10.3390/app112210662
Chicago/Turabian StyleZakir Ullah, Muhammad, Yuanjie Zheng, Jingqi Song, Sehrish Aslam, Chenxi Xu, Gogo Dauda Kiazolu, and Liping Wang. 2021. "An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification" Applied Sciences 11, no. 22: 10662. https://doi.org/10.3390/app112210662
APA StyleZakir Ullah, M., Zheng, Y., Song, J., Aslam, S., Xu, C., Kiazolu, G. D., & Wang, L. (2021). An Attention-Based Convolutional Neural Network for Acute Lymphoblastic Leukemia Classification. Applied Sciences, 11(22), 10662. https://doi.org/10.3390/app112210662