
Offline Joint Network and Computational Resource Allocation for Energy-Efficient 5G and beyond Networks

 ,
,  ,
,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
1.1. Related Work
1.2. Research Gap
1.3. Our Contributions
- We formulate a concrete joint user association, traffic routing, and VNF placement optimization problem targeting at the overall E2E network performance optimization, with minimal assumptions, that accounts for both communication and computation resources in all segments of a mobile network (i.e., AN, edge, and core) and explicitly account for the AN segment, typically ignored in the literature.
- Due to the NP-hardness of the resulting problem, we also propose a heuristic algorithm, evaluate its performance via simulations and demonstrate its superior performance compared with other State-of-the-Art (SoA) algorithms. The proposed solutions can be applied for internode network optimization, in conjunction with approaches targeting intranode optimization for maximum performance.
- Expanding upon our previous work in [29], we also describe the proposed orchestration solution, which, integrated with the proposed algorithm, enables the automated and optimized provisioning and configuration of heterogeneous computational and network resources across all network segments, targeting the orchestration of virtualized services according to the expected performance requirements and the specified SFC.
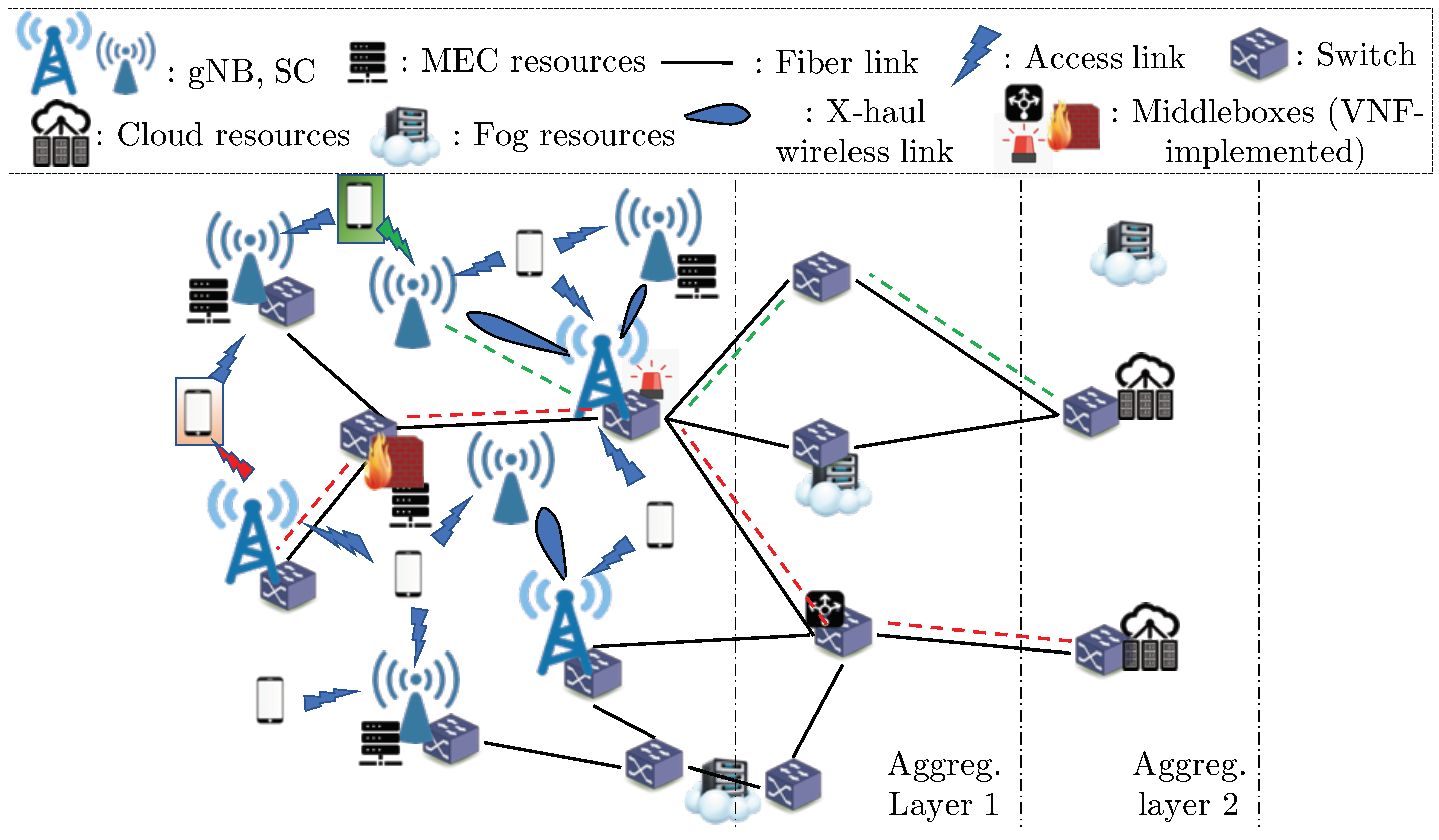
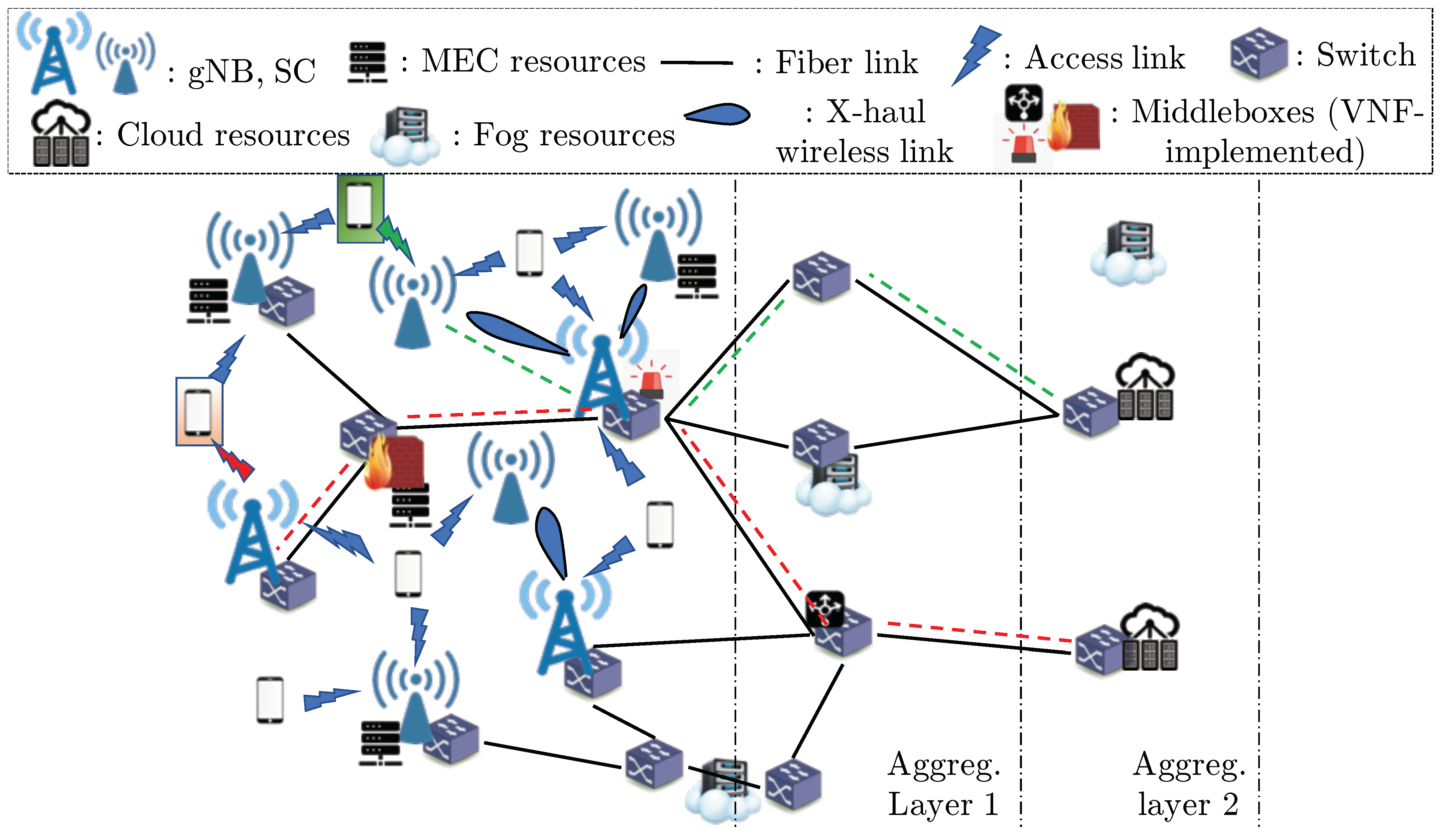
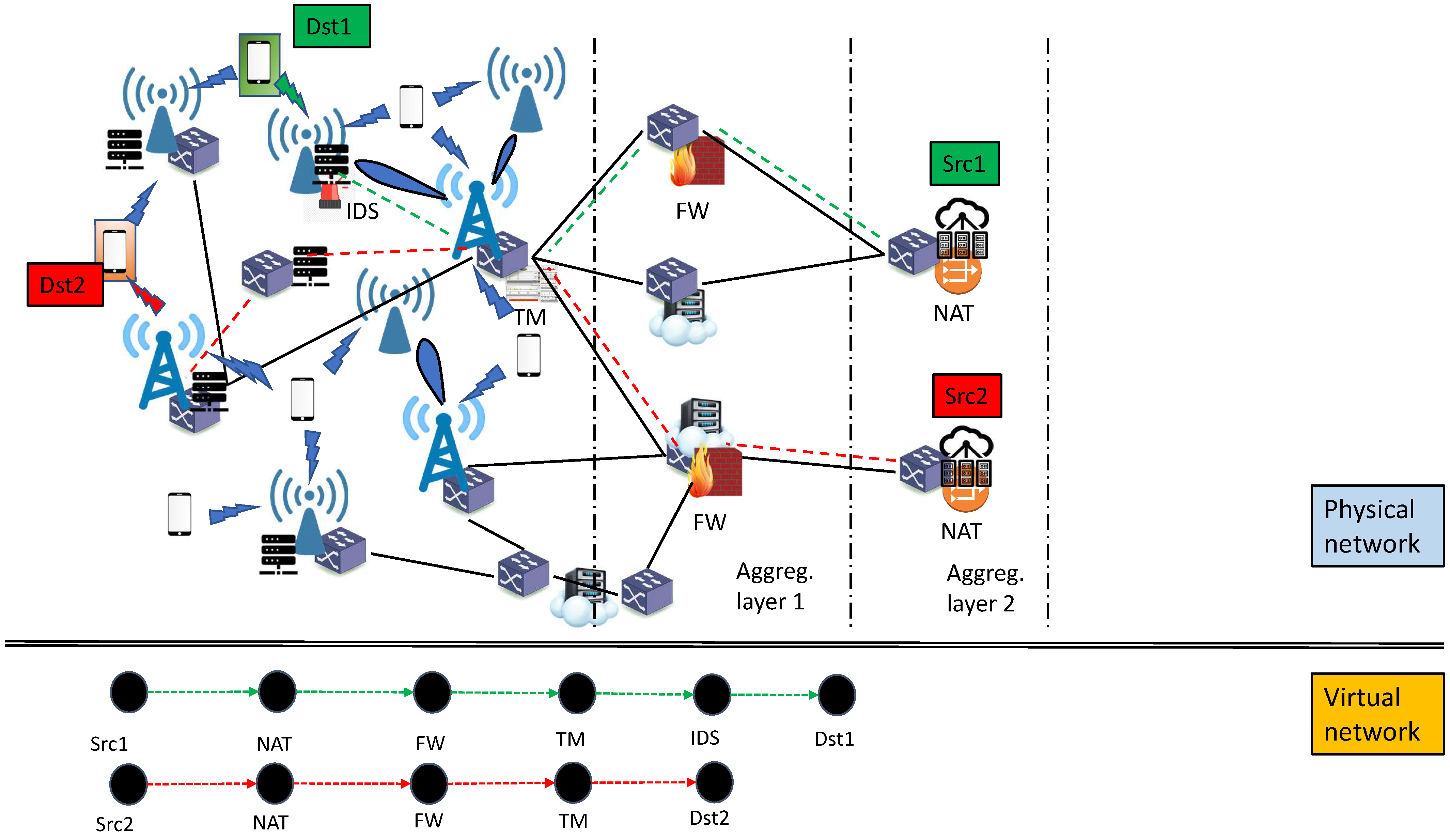
2. System Model and Problem Statement
2.1. Power Consumption Model and Problem Formulation
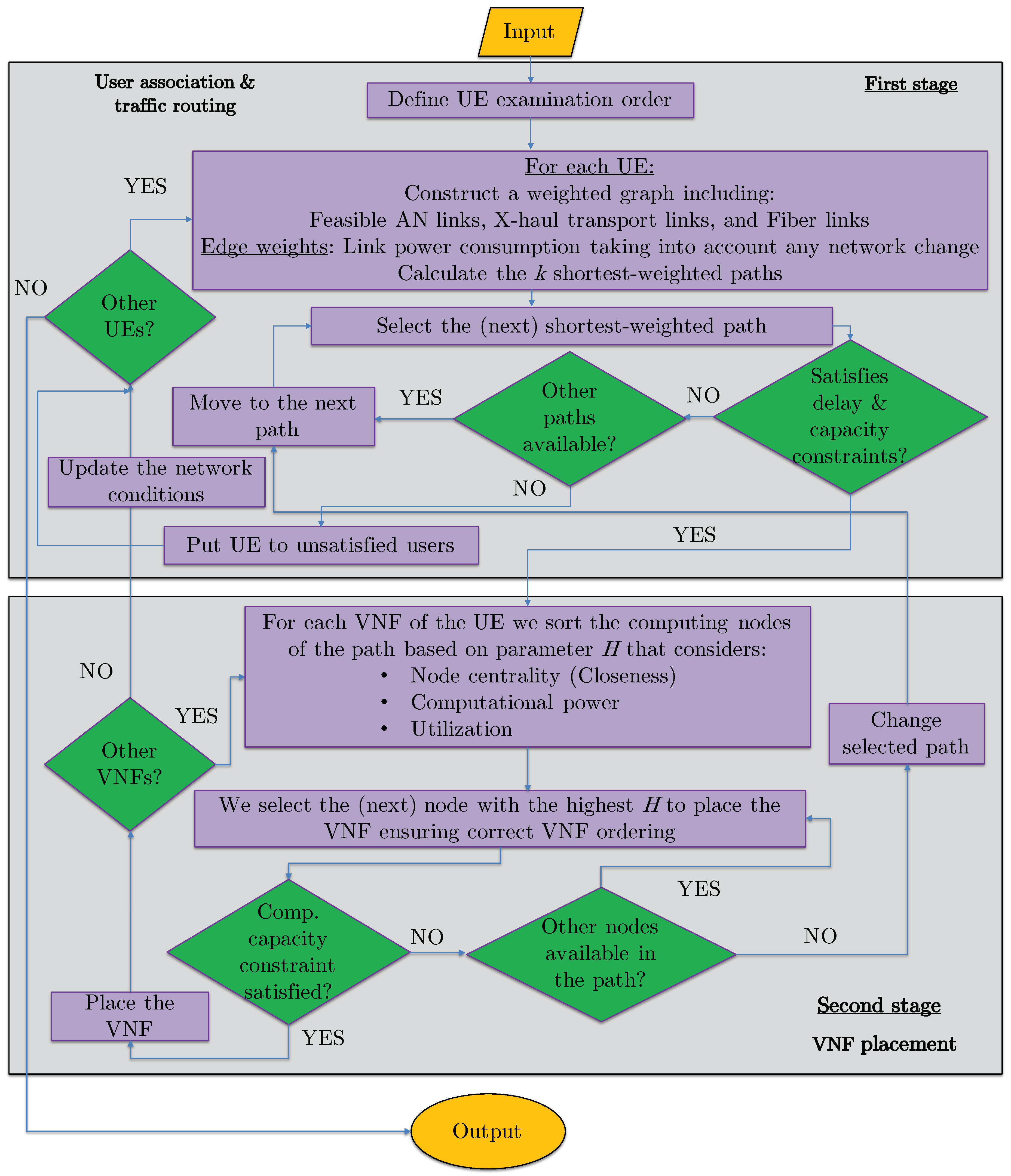
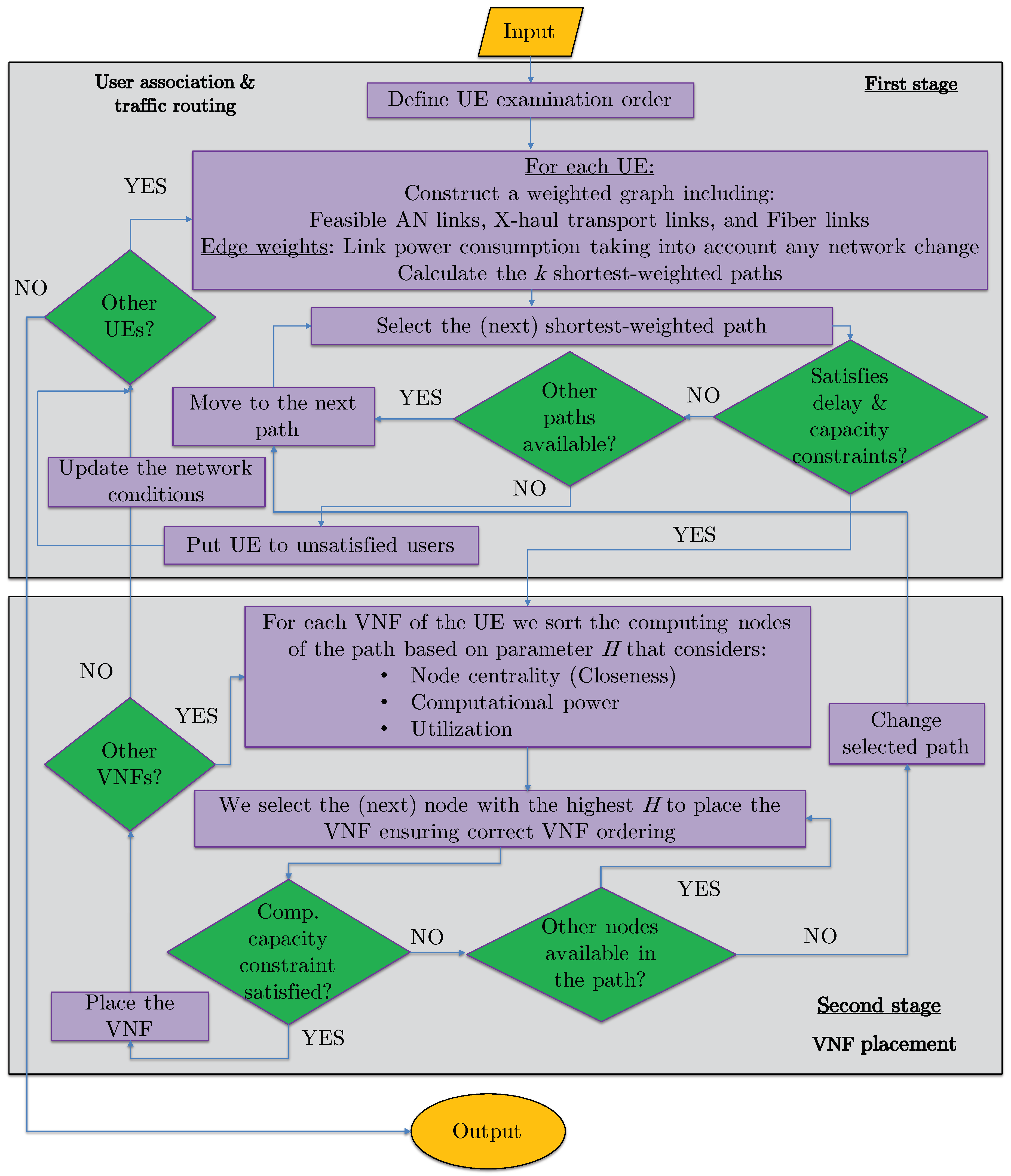
3. Proposed Energy-Efficient Vnf Placement, Traffic Routing, and User Association (Hero)
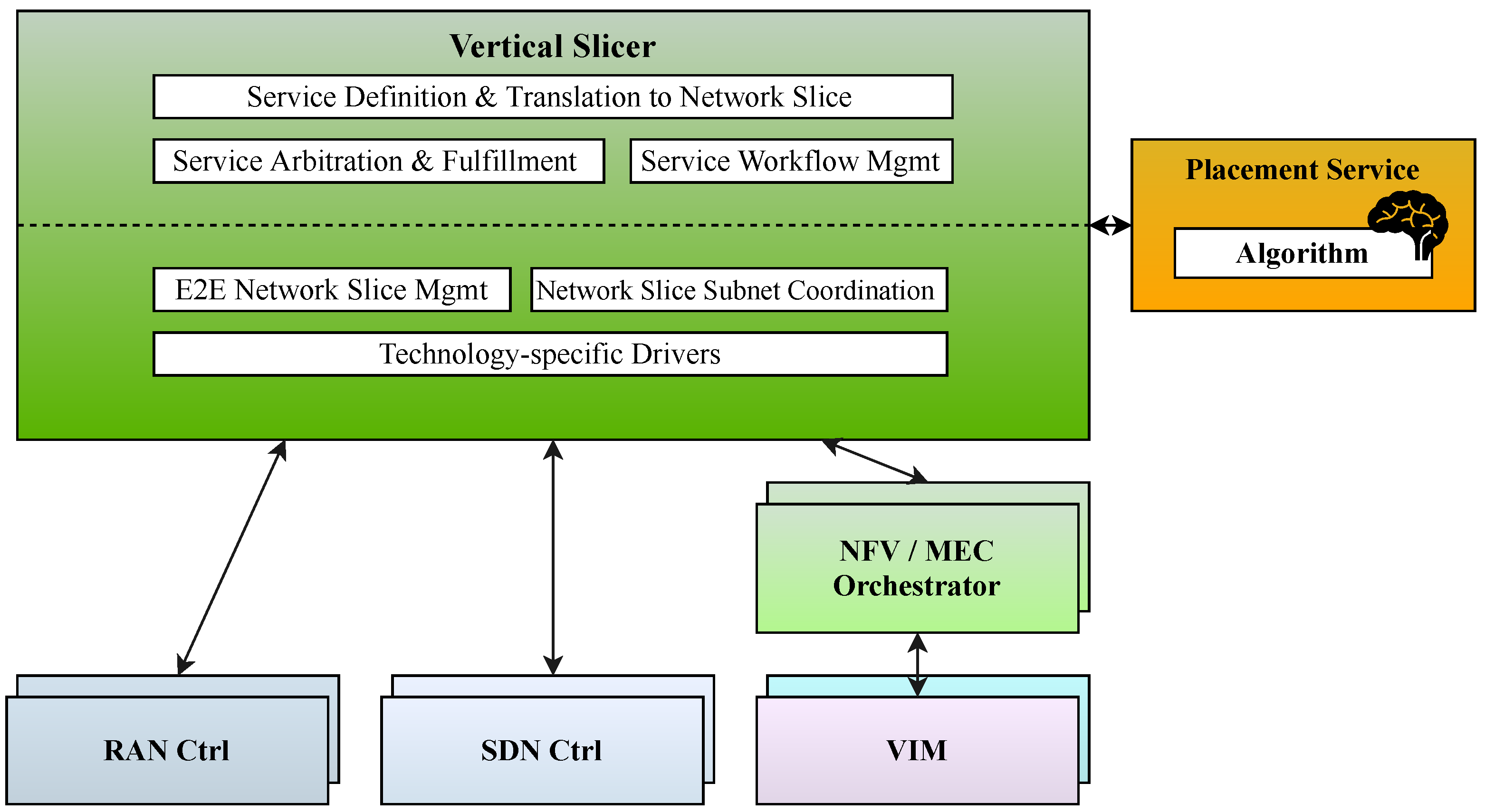
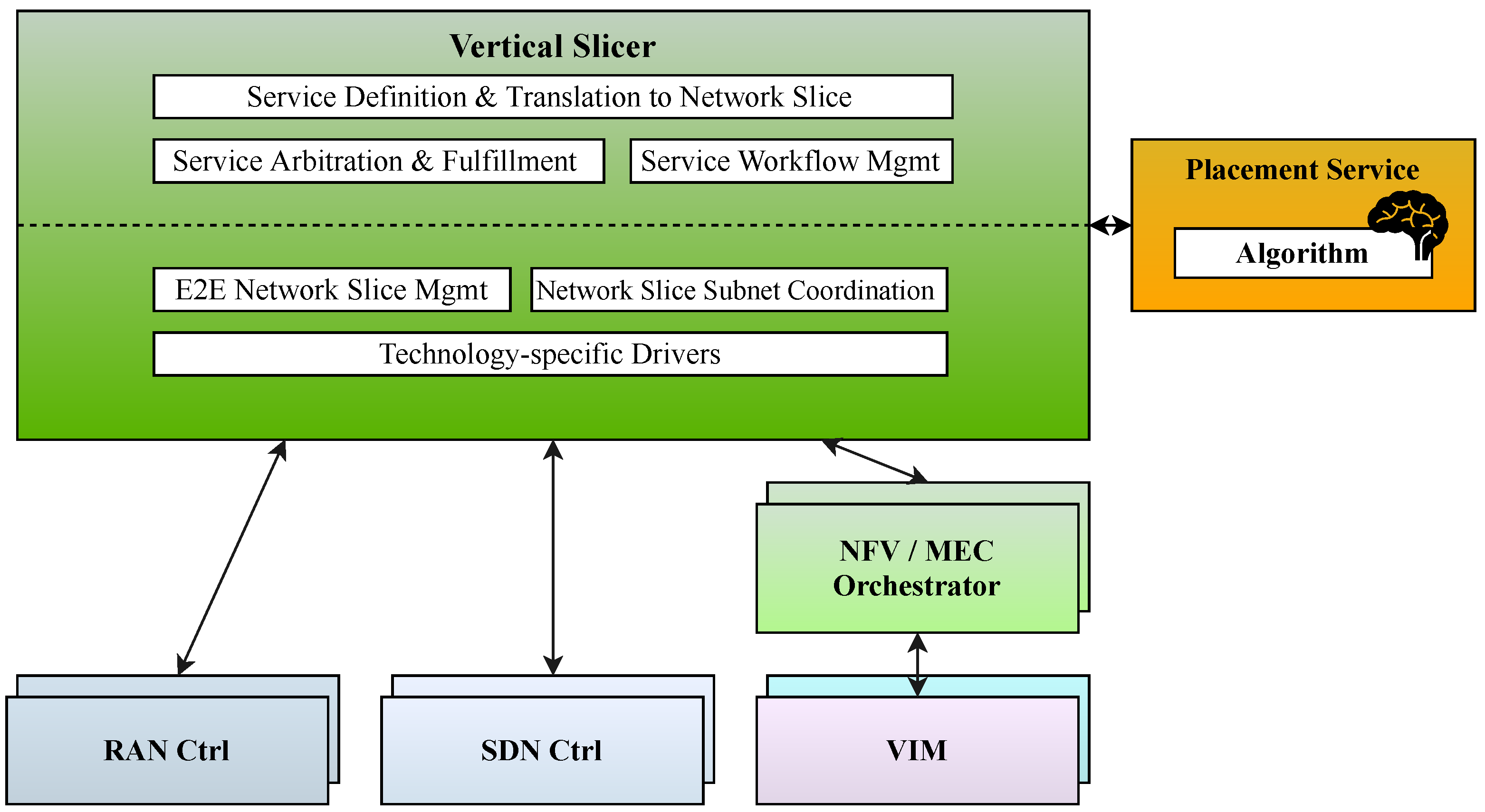
4. Interaction with Orchestration Framework
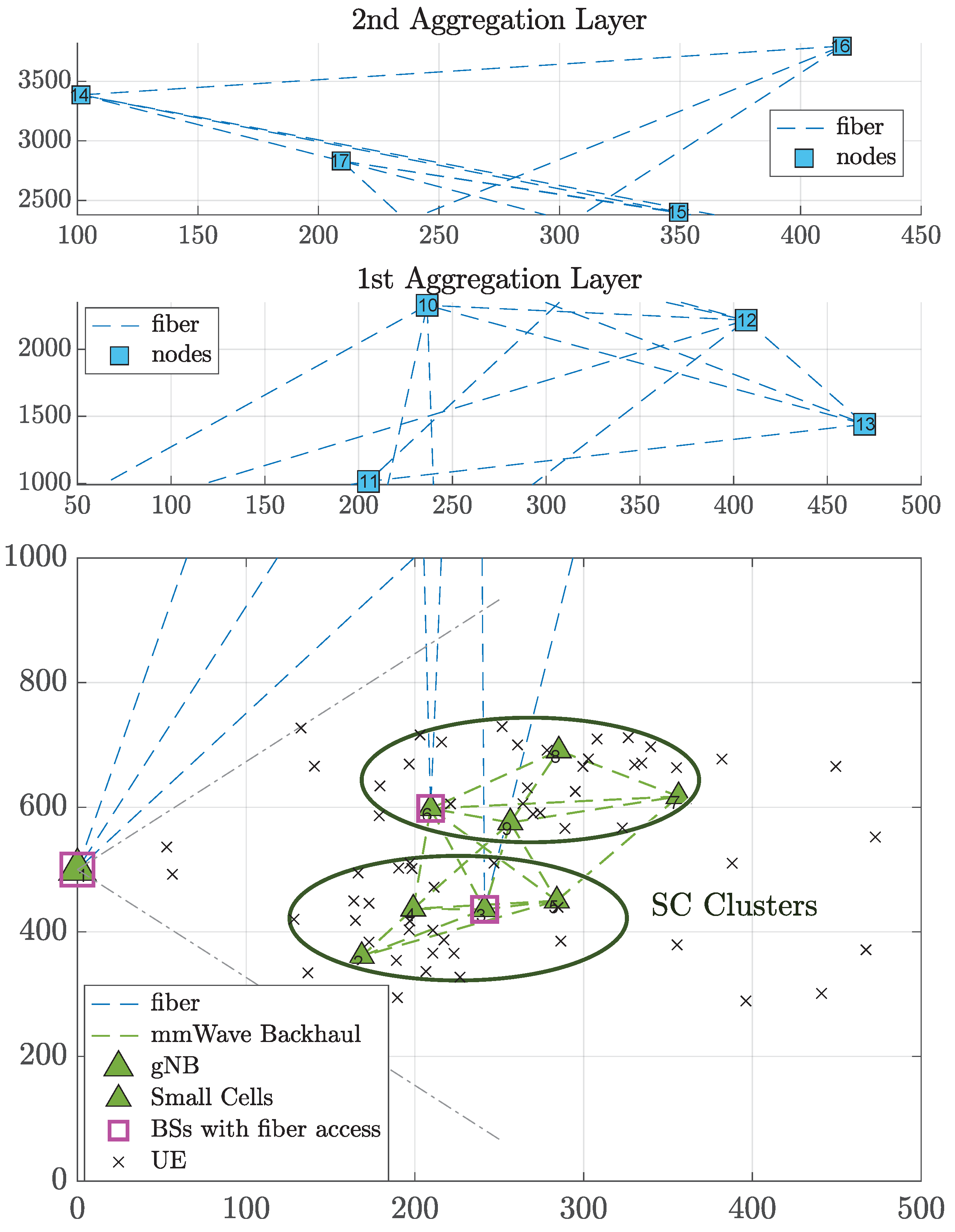
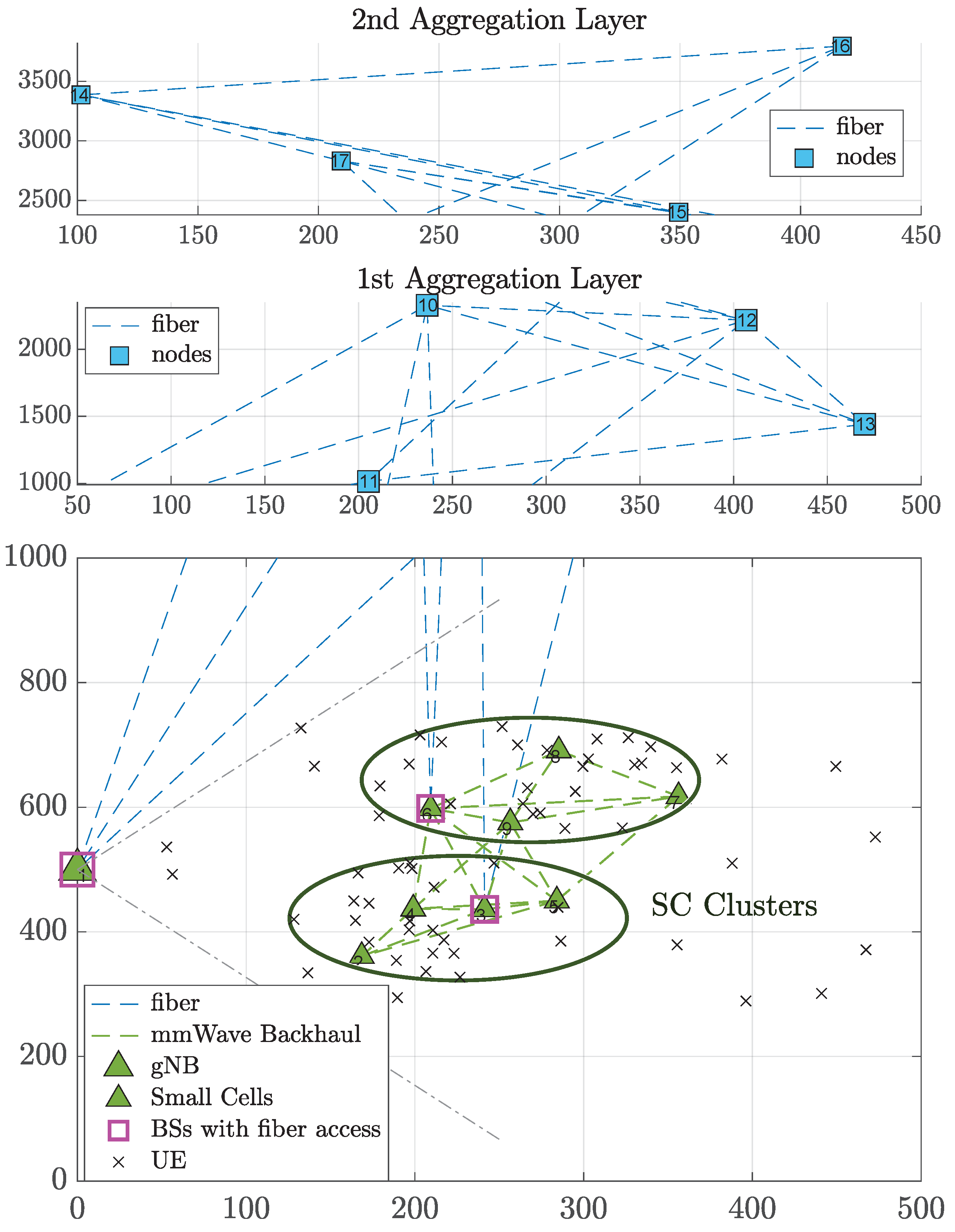
5. Evaluation Methodology and Simulation Scenarios
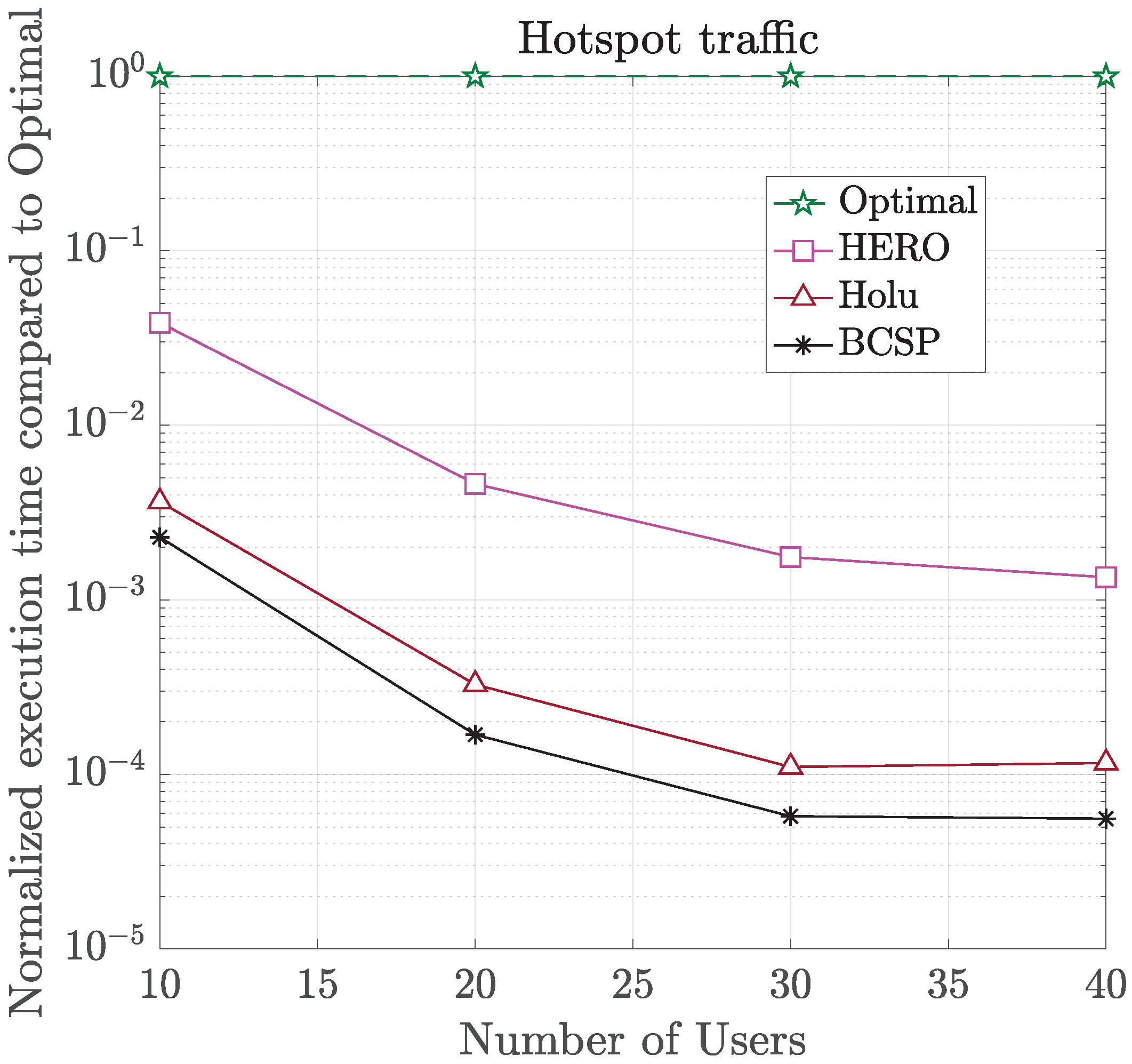
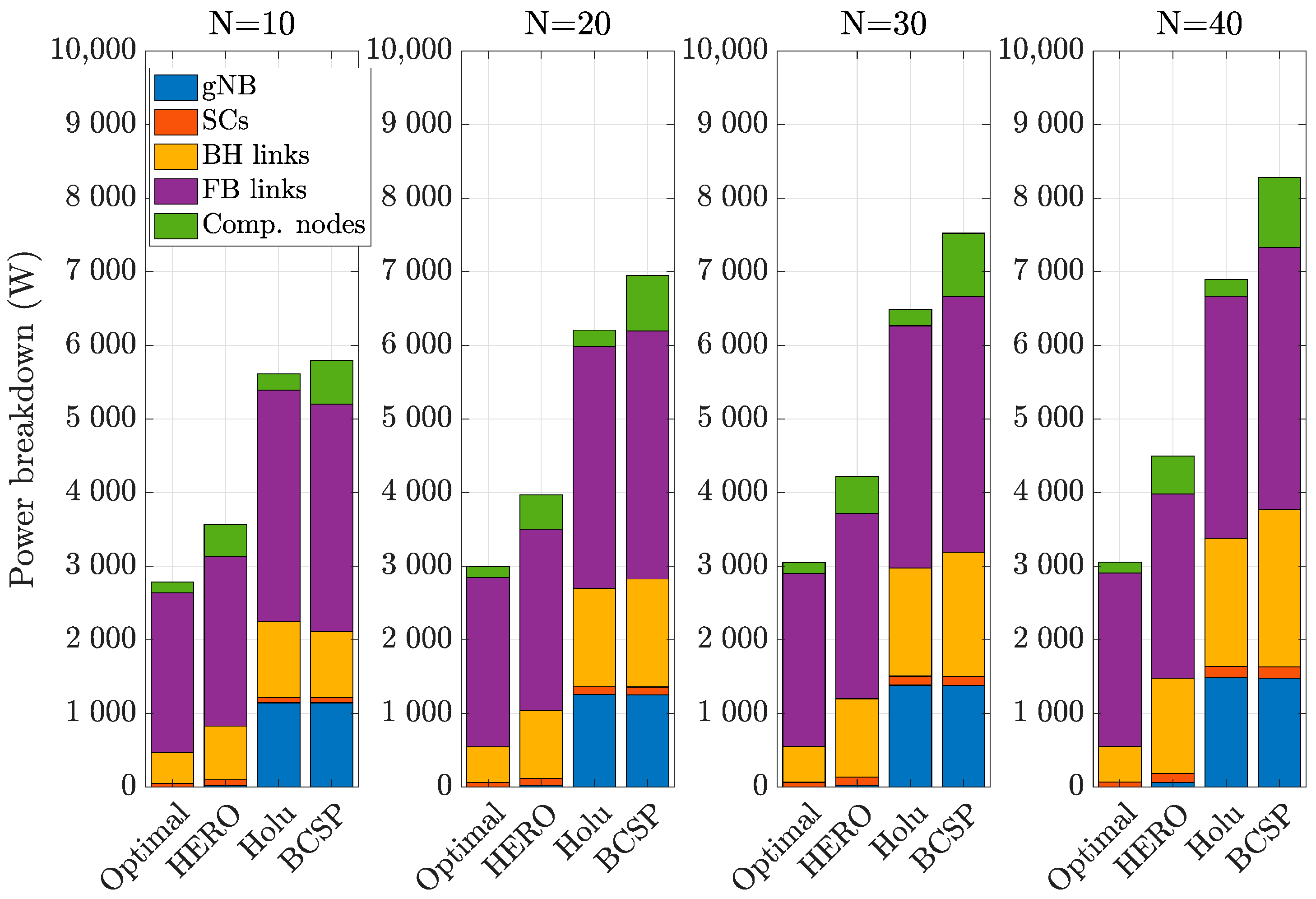
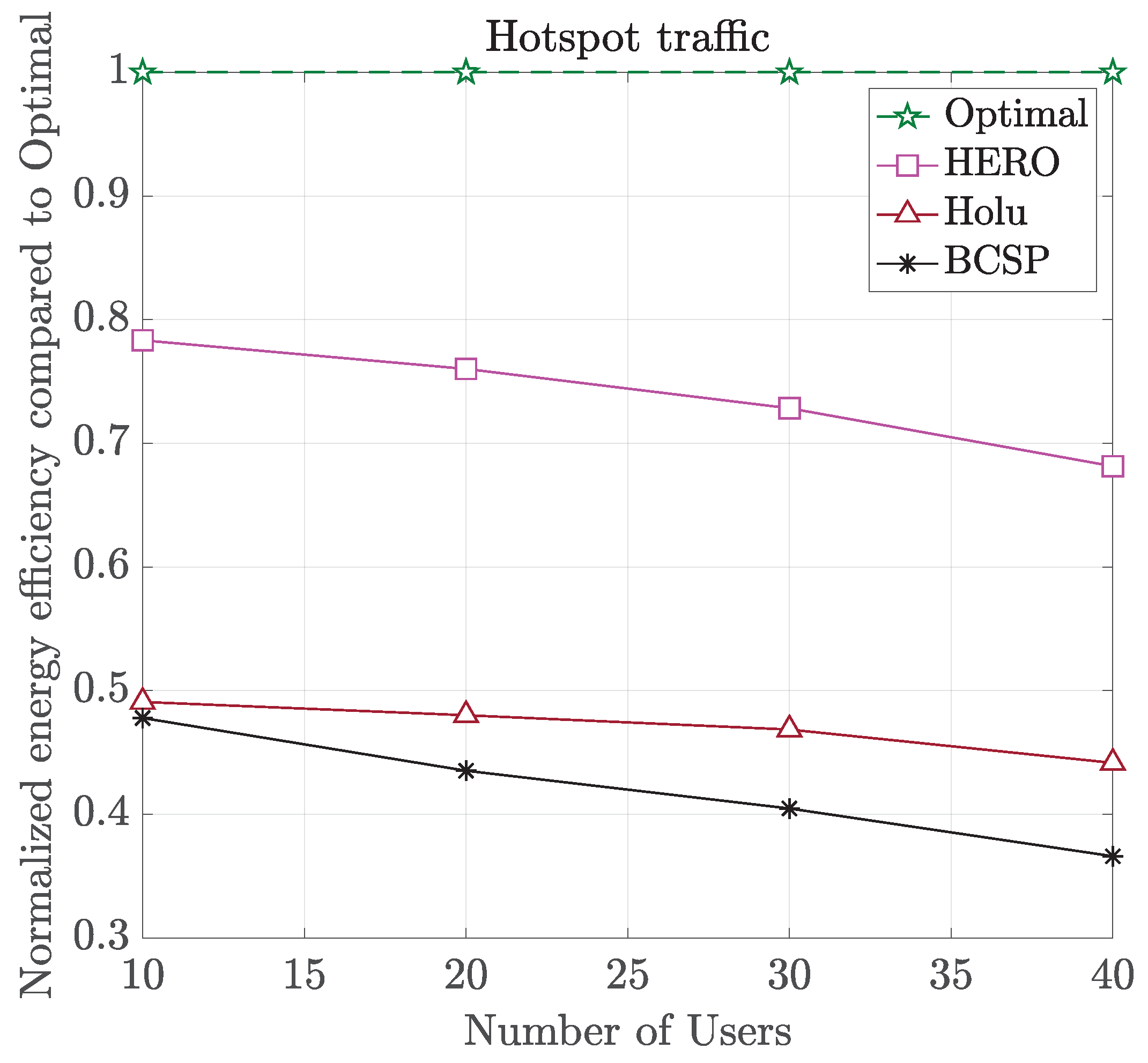
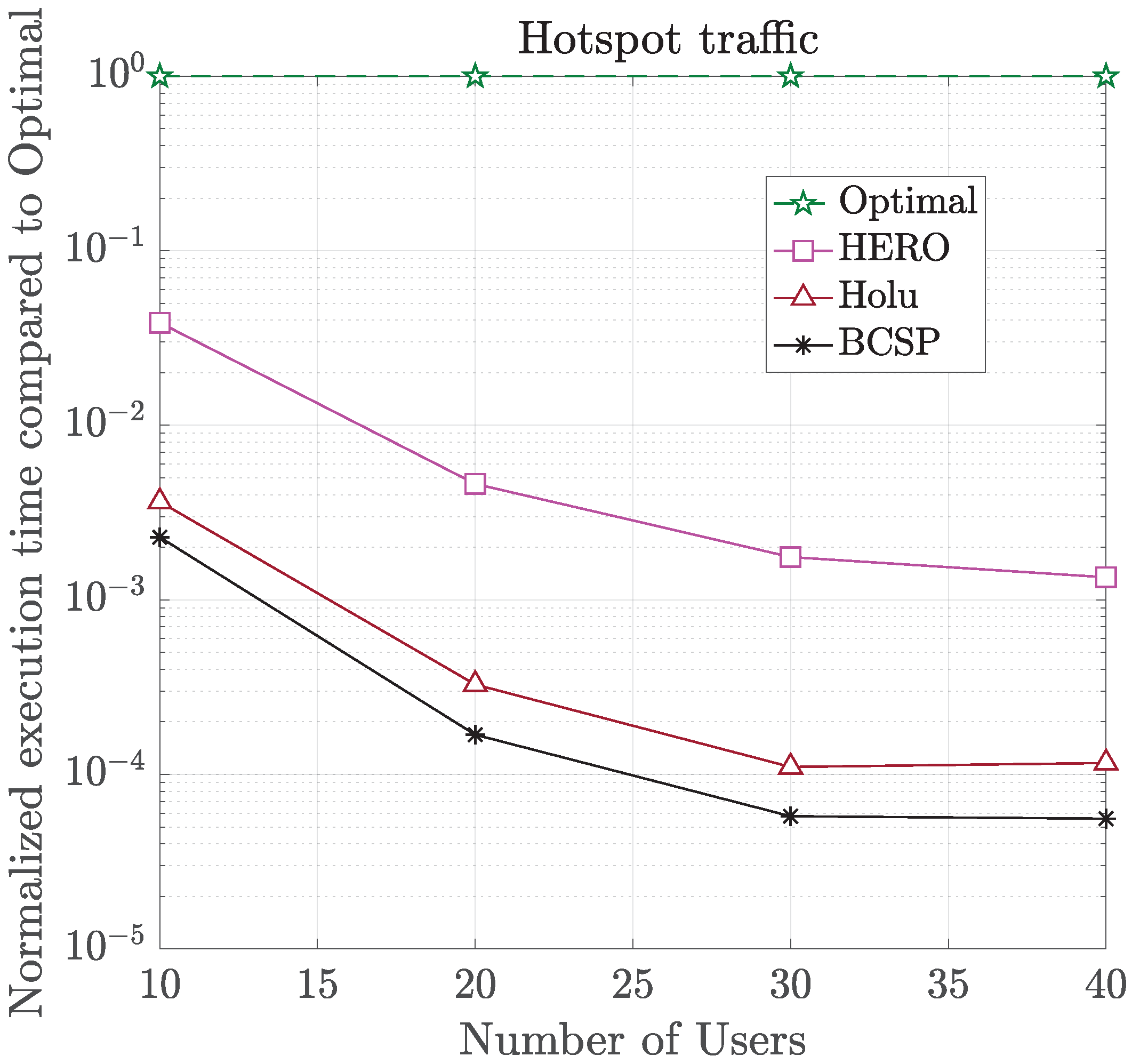
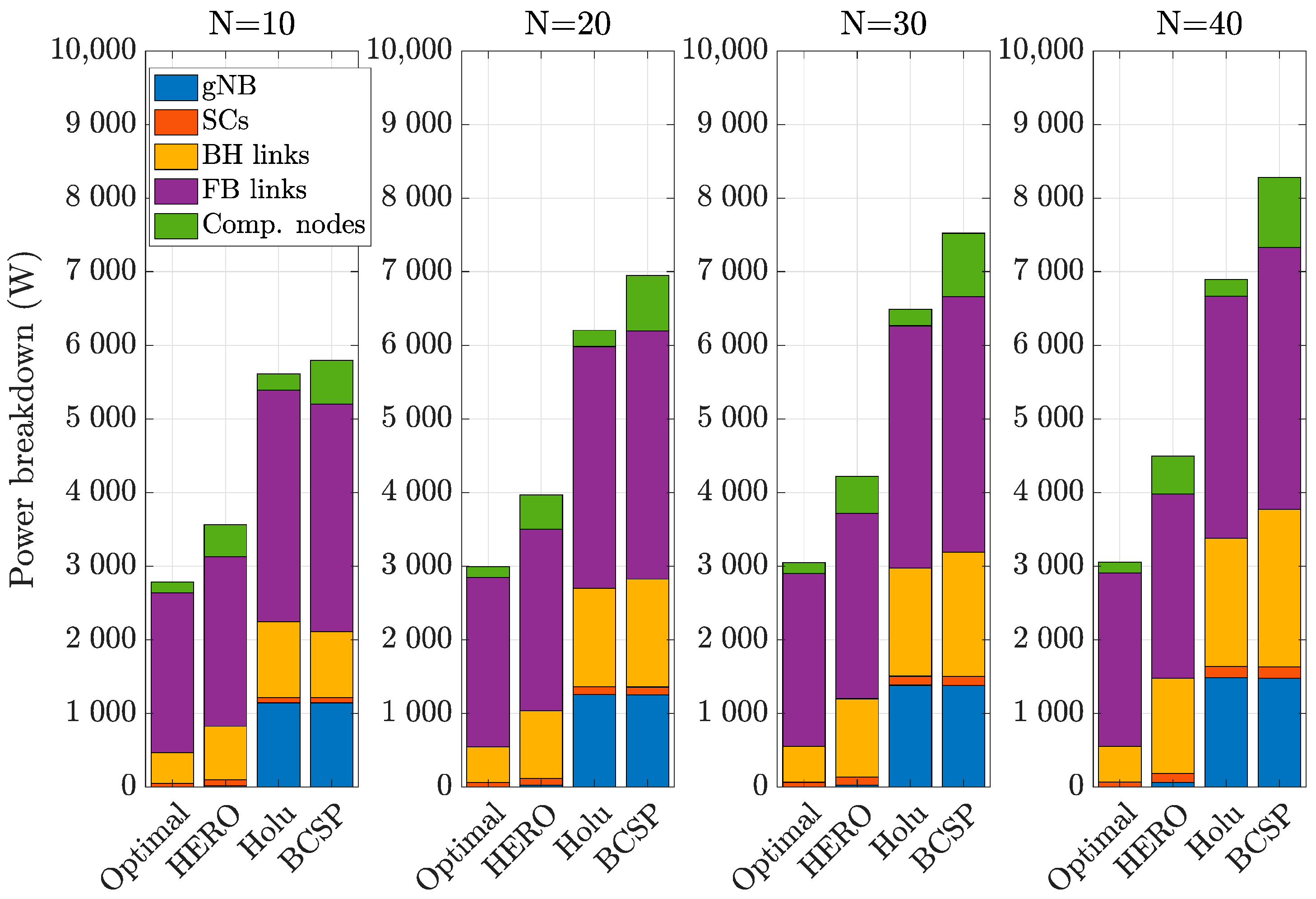
- Holu: This algorithm first performed the VNF placement based on the node centrality (closeness) and the CPU utilization of computing nodes and then decided upon traffic routing targeting the minimization of power consumption, while satisfying the E2E service delay constraint.
- BCSP: It considered node centrality (betweeness) for the VNF placement and the shortest-path in terms of delay for routing, while meeting the E2E service delay constraint.
6. Simulation Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3GPP | 3rd Generation Partnership Project |
| 5G | Fifth Generation |
| 5G-NR | 5G-New Radio |
| 5G-PPP | 5G Infrastructure Public Private Partnership |
| 6G | Sixth Generation |
| B5G | Beyond Fifth Generation |
| BS | Base Station |
| AN | Access Network |
| CAPEX | Capital Expenditure |
| CPU | Central Processing Unit |
| C-RAN | Centralized-Radio Access Network |
| DL | Downlink |
| E2E | End-to-end |
| eMBB | Enhanced Mobile Broadband |
| ETSI | European Telecommunications Standards Institute |
| FPGA | Field Programmable Gate Array |
| FW | Firewall |
| gNB | gNodeB |
| GPU | Graphics Processing Unit |
| ICT | Information and Communications Technology |
| IDPS | Intrusion Detection/Prevention System |
| LCM | Lifecycle Management |
| MANO | Management and Orchestration |
| MEC | Multi-Access Edge Computing |
| MILP | Mixed Integer Linear Program |
| mMTC | Massive Machine Type Communication |
| NAT | Network Address Translation |
| NFV | Network Function Virtualization |
| OPEX | Operational Expenditure |
| OSI | Open System Interconnection |
| QoS | Quality of Service |
| RAN | Radio Access Network |
| RB | Resource Block |
| RF | Radio Frequency |
| SINR | Signal to Interference plus Noise Ratio |
| State-of-the-Art | SoA |
| SC | Small Cell |
| SDN | Software Defined Networking |
| SDO | Standards Developing Organization |
| SFC | Service Function Chain |
| TM | Traffic Monitor |
| uRLLC | Ultra Reliable Low Latency Communication |
| UE | User Equipment |
| UHD | Ultra-High Definition |
| VM | Virtual Machine |
| VNF | Virtual Network Function |
| VOC | Video Optimization Controller |
| WOC | WAN Optimization Controller |
References
- Ali, J.; Roh, B.H.; Lee, S. QoS improvement with an optimum controller selection for software-defined networks. PLoS ONE 2019, 14, e0217631. [Google Scholar] [CrossRef] [PubMed]
- Ali, J.; Roh, B.H. Quality of Service improvement with optimal software-defined networking controller and control plane clustering. Comput. Mater. Contin. 2021, 67, 849–875. [Google Scholar] [CrossRef]
- Barakabitze, A.; Ahmad, A.; Mijumbi, R.; Hines, A. 5G network slicing using SDN and NFV: A survey of taxonomy, architectures and future challenges. Comput. Netw. 2020, 167, 106984. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Yang, H.; Ma, R.; Hu, L.; Wang, W.; Chen, Q. Queue-aware dynamic placement of virtual network functions in 5G access network. IEEE Access 2018, 6, 44291–44305. [Google Scholar] [CrossRef]
- Laghrissi, A.; Taleb, T. A survey on the placement of virtual resources and Virtual Network Functions. IEEE Commun. Surv. Tutor. 2019, 1, 1409–1434. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Lu, W.; Zhou, F.; Lu, P.; Zhu, Z. On dynamic Service Function Chain deployment and readjustment. IEEE Trans. Netw. Serv. Manag. 2017, 14, 543–553. [Google Scholar] [CrossRef]
- Dong, L.; da Fonseca, N.; Zhu, Z. Application-Driven provisioning of Service Function Chains over heterogeneous NFV platforms. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3037–3048. [Google Scholar] [CrossRef]
- Cao, H.; Du, J.; Zhao, H.; Luo, D.; Kumar, N.; Yang, L.; Yu, F. Resource-Ability assisted Service Function Chain embedding and scheduling for 6G networks With virtualization. IEEE Trans. Veh. Technol. 2021, 70, 3846–3859. [Google Scholar] [CrossRef]
- Cudak, M.; Ghosh, A.; Ghosh, A.; Andrews, J. Integrated access and backhaul: A key enabler for 5G millimeter-wave deployments. IEEE Commun. Mag. 2021, 59, 88–94. [Google Scholar] [CrossRef]
- Ghribi, C.; Mechtri, M.; Zeghlache, D. A dynamic programming algorithm for joint VNF placement and chaining. In Proceedings of the 2016 ACM Workshop on Cloud-Assisted Networking, Irvine, CA, USA, 12 December 2016. [Google Scholar]
- Ma, Y.; Liang, W.; Huang, M.; Xu, W.; Guo, S. Virtual Network Function service provisioning in MEC via trading off the usages between computing and communication resources. (early access). IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Soualah, O.; Mechtri, M.; Ghribi, C.; Zeghlache, D. Energy efficient algorithm for VNF placement and chaining. In Proceedings of the 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017. [Google Scholar]
- Ayoubi, S.; Sebbah, S.; Assi, C. A logic-based Benders decomposition approach for the VNF assignment problem. IEEE Trans. Cloud Comput. 2019, 7, 894–906. [Google Scholar] [CrossRef]
- Varasteh, A.; Madiwalar, B.; van Bemten, A.; Kellerer, W.; Mas–Machuca, C. Holu: Power-aware and delay-constrained VNF placement and chaining. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1524–1539. [Google Scholar] [CrossRef]
- Tajiki, M.; Salsano, S.; Chiaraviglio, L.; Shojafar, M.; Akbari, B. Joint energy efficient and QoS-aware path allocation and VNF placement for Service Function Chaining. IEEE Trans. Netw. Serv. Manag. 2019, 16, 374–388. [Google Scholar] [CrossRef] [Green Version]
- Dietrich, D.; Papagianni, C.; Papadimitriou, P.; Baras, J. Network function placement on virtualized cellular cores. In Proceedings of the 2017 9th International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 4–8 January 2017. [Google Scholar]
- Yang, S.; Li, F.; Trajanovski, S.; Chen, X.; Wang, Y.; Fu, X. Delay-aware Virtual Network Function placement and routing in edge clouds. IEEE Trans. Mobile Comput. 2021, 20, 445–459. [Google Scholar] [CrossRef] [Green Version]
- Spinelli, F.; Mancuso, V. Toward enabled industrial verticals in 5G: A survey on MEC-based approaches to provisioning and flexibility. IEEE Commun. Surv. Tutor. 2021, 23, 596–630. [Google Scholar] [CrossRef]
- Open Source MANO. 2021. Available online: https://osm.etsi.org/ (accessed on 7 October 2021).
- O-RAN Alliance. 2021. Available online: https://www.o-ran.org/ (accessed on 7 October 2021).
- Casetti, C.; Chiasserini, C.; Martín-Pérez, J.; Molner, N.; Deiss, T. The Vertical Slicer: Verticals’ Entry Point to 5G Networks. In Proceedings of the 27th European Conference on Networks and Communications (EuCNC 2018), Ljubljana, Slovenia, 18–21 June 2018. [Google Scholar]
- Perez, M.G.; Perez, G.M.; Giardina, P.; Bernini, G.; Neves, P.; Alcaraz-Calero, J.; Wang, Q.; Koutsopoulos, K. Self-Organizing Capabilities in 5G Networks: NFV & SDN Coordination in a Complex Use Case. In Proceedings of the 27th European Conference on Networks and Communications (EuCNC 2018), Ljubljana, Slovenia, 18–21 June 2018. [Google Scholar]
- Khalili, H.; Papageorgiou, A.; Siddiqui, M.; Meixner, C.C.; Carrozzo, G.; Nejabati, R.; Simeonidou, D. Network Slicing-aware NFV Orchestration for 5G Service Platforms. In Proceedings of the 28th European Conference on Networks and Communications (EuCNC 2019), Valencia, Spain, 18–21 June 2019. [Google Scholar]
- Mesodiakaki, A.; Zola, E.; Santos, R.; Kassler, A. Optimal user association, backhaul routing and switching off in 5G heterogeneous networks with mesh millimeter wave backhaul links. Ad Hoc Netw. 2018, 78, 99–114. [Google Scholar] [CrossRef]
- ETSI ES 203 228: Environmental Engineering (EE): Assessment of Mobile Network Energy Efficiency, November 2020. v.1.3.1. Available online: https://www.etsi.org/deliver/etsi_es/203200_203299/203228/01.03.01_60/es_203228v010301p.pdf (accessed on 7 October 2021).
- ETSI EN 303 471: Energy Efficiency Measurement Methodology and Metrics for Network Function Virtualisation (NFV), January 2019. v.1.1.1. Available online: https://www.etsi.org/deliver/etsi_en/303400_303499/303471/01.01.01_60/en_303471v010101p.pdf (accessed on 7 October 2021).
- Li, X.; Garcia-Saavedra, A.; Costa-Perez, X.; Bernardos, C.; Guimaraes, C.; Antevski, K.; Mangues-Bafalluy, J.; Baranda, J.; Zeydan, E.; Corujo, D.; et al. 5Growth: An End-to-End Service Platform for Automated Deployment and Management of Vertical Services over 5G Networks. IEEE Commun. Mag. 2012, 59, 84–89. [Google Scholar] [CrossRef]
- Gatzianas, M.; Mesodiakaki, A.; Kalfas, G.; Pleros, N. Energy-efficient joint computational and network resource planning in Beyond 5G networks. Proc. IEEE Globecom. 2021. to appear. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Vertical Slicer. Available online: https://github.com/nextworks-it/slicer (accessed on 7 October 2021).
- TR 28.541: Management and Orchestration; 5G Network Resource Model (NRM); Stage 2 and Stage 3 (Rel. 17), 2020. v. 17.0.0. Available online: https://www.3gpp.org/ftp//Specs/archive/28_series/28.541/28541-h01.zip (accessed on 7 October 2021).
- ILOG CPLEX Optimization Studio. 2020. Available online: https://www.ibm.com/products/ilog-cplex-optimization-studio (accessed on 7 October 2021).
- Heddeghem, W.V.; Idzikowski, F.; Vereecken, W.; Colle, D.; Pickavet, M.; Demeester, P. Power consumption modeling in optical multilayer networks. Photon. Netw. Commun. 2012, 24, 86–102. [Google Scholar] [CrossRef] [Green Version]


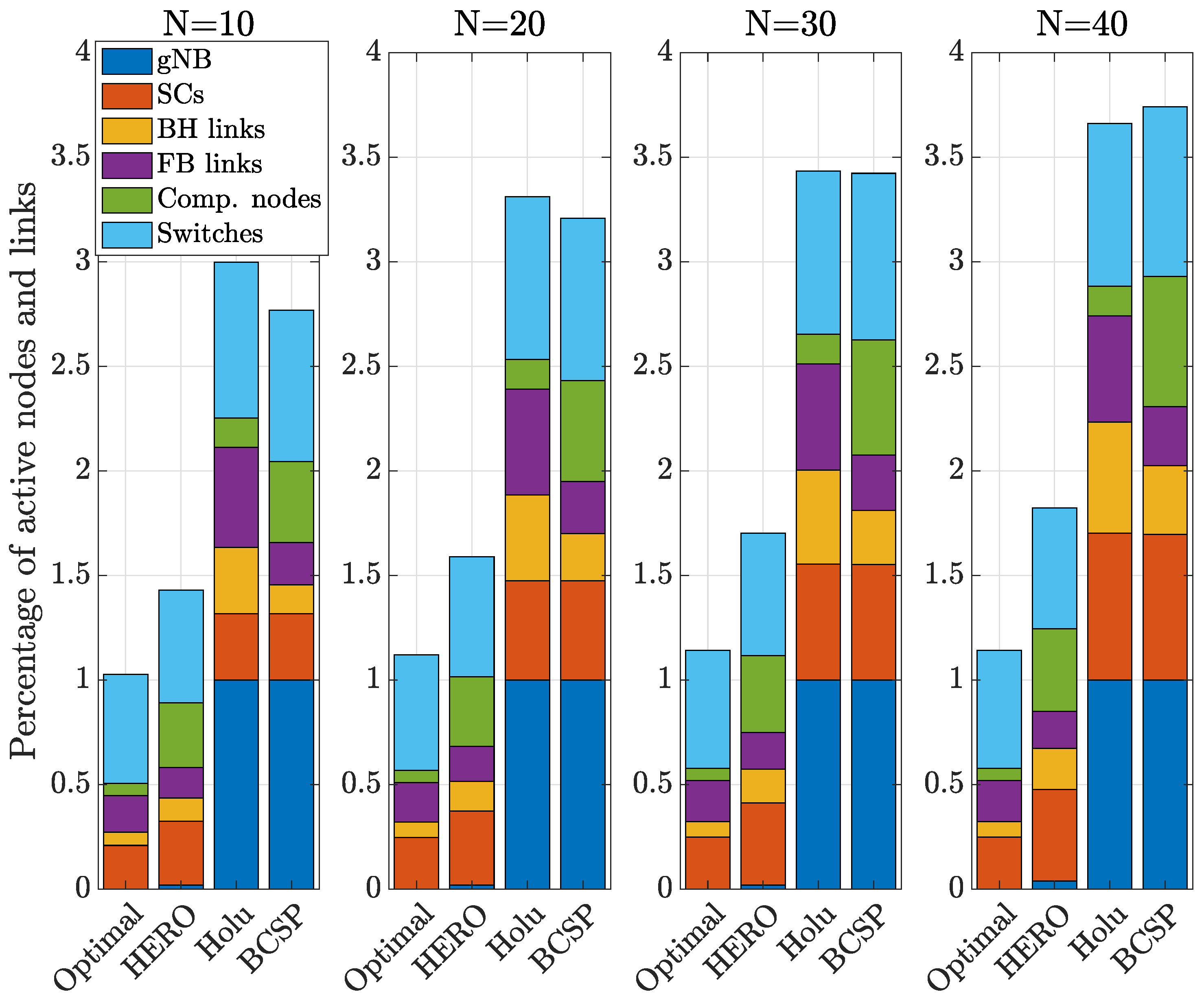

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
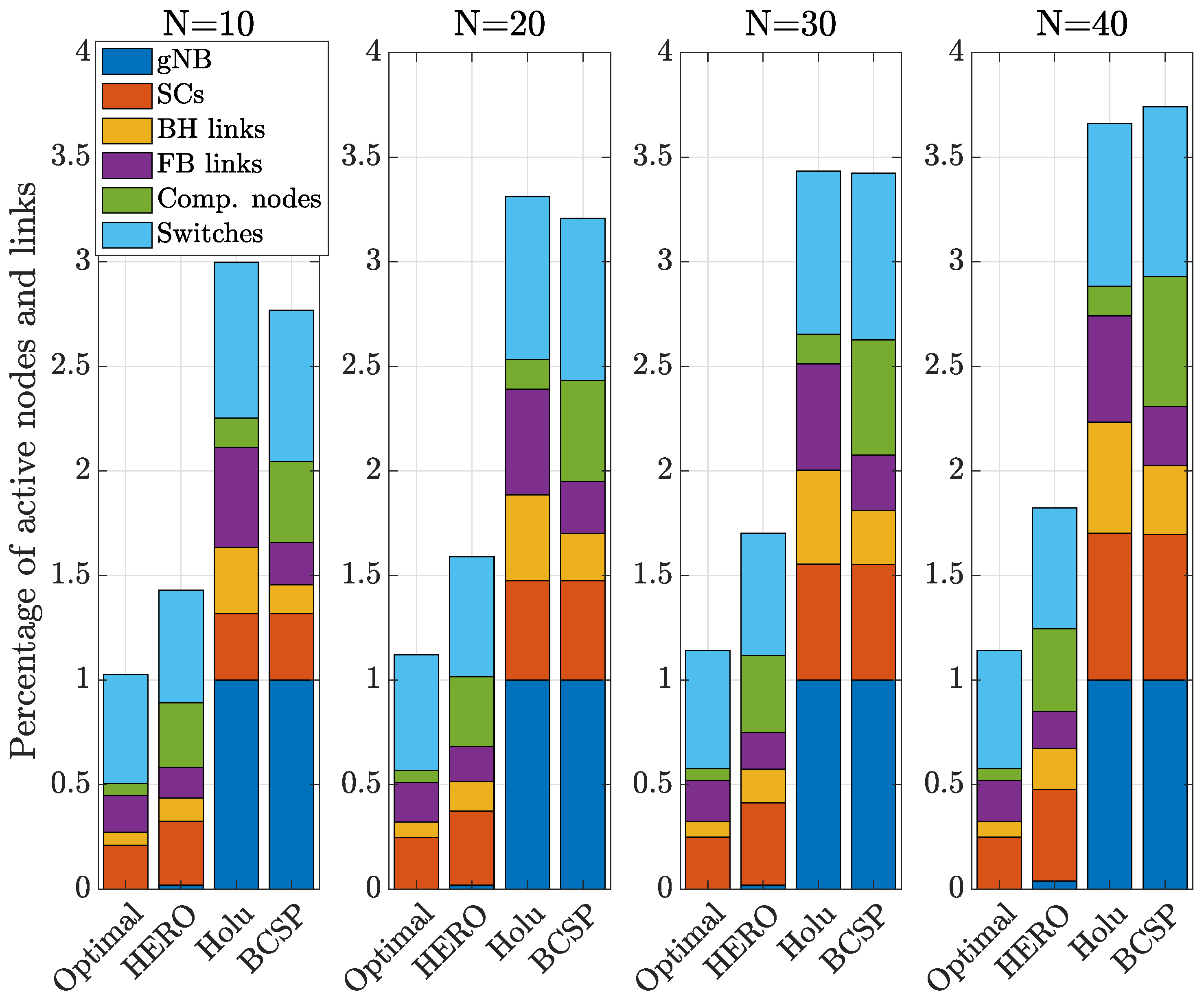{kind=link}
| Symbol | Interpretation | Notation for Element (In Case of Sets) | Symbol | Interpretation | Notation for Element (In Case of Sets) |
|---|---|---|---|---|---|
| Input parameters | |||||
| Set of network nodes (excluding mobile users) | Set of nodes equipped with switch | ||||
| Set of network links (excluding access links) | Set of UEs | j | |||
| , | Set of fiber (resp. wireless) non-access links | Set of access links | |||
| Communication capacity of link e | NA | Delay (i.e., transmission + propagation) induced by link e | NA | ||
| Set of BSs that UE j can connect to | a | Set of UEs that can be served by BS a | j | ||
| Set of network nodes equipped with computational resources | y | Amount of computational resources available at node y | NA | ||
| Set of available VNFs | where : VNF id, : VNF data processing capacity, : amount of CPU resources required by VNF, : delay induced by VNF processing | ||||
| Set of available SFCs | |||||
| Set of VNFs comprising SFC | f | Virtual directed graph describing SFC via virtual node set and virtual edge set | NA | ||
| Set of requests by UEs | where s: source node of service request, : E2E requested rate, : E2E requested latency, : requested SFC | ||||
| Number of RBs needed to be assigned by BS a to UE j to meet its requested rate | |||||
| Switch idle power | NA | Idle power of transmitter in mmWave link e | NA | ||
| Idle power of gNB a | NA | idle power of SC a | NA | ||
| Number of RF chains used in transmitter of mmWave link | NA | , | Number of RF chains used by gNB, SC | NA | |
| Slope parameter of transmitter in mmWave link e | NA | , | Slope parameter of transmitter in gNB, SC a | NA | |
| Decision variables | |||||
| Boolean indicator of whether UE j actually connects to BS a | Boolean indicator of whether VNF f requested by service q is deployed on node | ||||
| , | Boolean indicator of whether physical link belongs to the physical path onto which the virtual link is mapped for SFC | Number of instances of VNF f deployed on node | |||
| Boolean indicator of whether fiber link actually carries traffic in either of its directions | , | Boolean indicator of whether fiber link actually carries traffic from n to m | |||
| Boolean indicator of whether the computational resources of node y are used | Boolean indicator of whether the switch at node n is actually used to forward traffic | ||||
| Boolean indicator for whether BS a serves any UEs | Boolean indicator of whether wireless link e is actually used to serve any traffic | ||||
| Auxiliary variable for [25] | Auxiliary variable for [25] | ||||
| Type | VNF Ordering | Throughput (Mbps) | Delay (ms) | Share (%) |
|---|---|---|---|---|
| Web | NAT→FW→TM→WOC→IDPS | [0.6–1] | 500 | 20 |
| VoIP | NAT→FW→TM→FW→NAT | [0.404–0.64] | 100 | 20 |
| Streaming | NAT→FW→TM→VOC→IDPS | [5–24] | 100 | 39 |
| Gaming | NAT→FW→VOC→WOC→IDPS | [0.24–0.5] | 60 | 6 |
| Ultra RT AI/ML | NAT→NAT | [15–25] | 1 | 15 |
| Type | NAT | FW | TM | VOC | WOC | IDPS |
|---|---|---|---|---|---|---|
| Process Capacity (Mbps) | 500 | 400 | 200 | 578 | 300 | 600 |
| GFLOPS Requirement | 110 | 440 | 55 | 110 | 110 | 440 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gatzianas, M.; Mesodiakaki, A.; Kalfas, G.; Pleros, N.; Moscatelli, F.; Landi, G.; Ciulli, N.; Lossi, L. Offline Joint Network and Computational Resource Allocation for Energy-Efficient 5G and beyond Networks. Appl. Sci. 2021, 11, 10547. https://doi.org/10.3390/app112210547
Gatzianas M, Mesodiakaki A, Kalfas G, Pleros N, Moscatelli F, Landi G, Ciulli N, Lossi L. Offline Joint Network and Computational Resource Allocation for Energy-Efficient 5G and beyond Networks. Applied Sciences. 2021; 11(22):10547. https://doi.org/10.3390/app112210547
Chicago/Turabian StyleGatzianas, Marios, Agapi Mesodiakaki, George Kalfas, Nikos Pleros, Francesca Moscatelli, Giada Landi, Nicola Ciulli, and Leonardo Lossi. 2021. "Offline Joint Network and Computational Resource Allocation for Energy-Efficient 5G and beyond Networks" Applied Sciences 11, no. 22: 10547. https://doi.org/10.3390/app112210547
APA StyleGatzianas, M., Mesodiakaki, A., Kalfas, G., Pleros, N., Moscatelli, F., Landi, G., Ciulli, N., & Lossi, L. (2021). Offline Joint Network and Computational Resource Allocation for Energy-Efficient 5G and beyond Networks. Applied Sciences, 11(22), 10547. https://doi.org/10.3390/app112210547