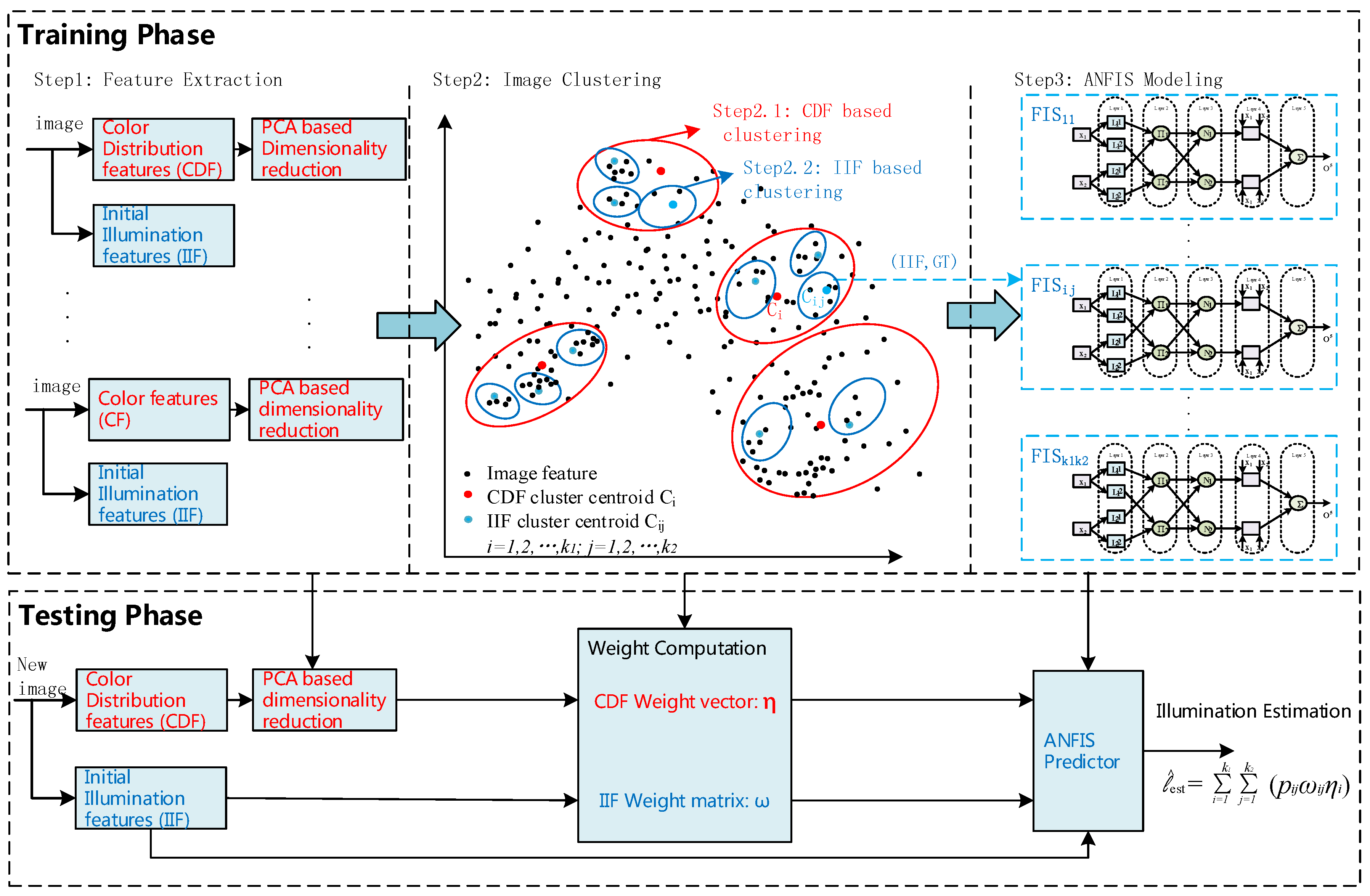
4.1. Experimental Set-Up
Dataset. The proposed method needs a large number of training samples that cover a wide range of color distributions and image illumination features. We use the Gehler-Shi dataset [
38] and the Cube+ dataset [
15,
39], as the two datasets contain modern images indicative of real world images and illumination. The number of all original raw-RGB images is 2275 in total. The training and testing procedure follows the standard 3-fold cross validation commonly in the literature of illuminant estimation. To this end, the whole image dataset is randomly split into three sets, and each time two sets are used for training while the remaining set is used for testing. Parameters used for all experiments are selected based on the first two sets and then are fixed for the third set.
Implementation details. Our MATLAB implementation, as we show in
https://github.com/yunhuiluo/AnfisIllest (accessed on 22 October 2021), requires approximately 0.34 s computing the CDFs and IIFs for an image with
pixels, 48 bits depth, and PNG format in the training dataset. Once the dimensionality of the CDFs is reduced with PCA, the illuminant estimation process takes an average of 0.65 s; this process includes weight computation, ANFIS prediction, and the final blending output. All the reported runtimes were computed on an Intel Core i5-2450M @ 2.50 GHz computer. Our method requires 5.6 MB to store the PC coefficient matrix, CDF/IIF clustering centroids, ANFIS model parameters, and other necessary settings, using single-precision floating-point representation. For default experiments, unless clearly stated, we choose the cluster numbers of
,
, and use the combination of Gehler-Shi and Cube+ as the training and testing dataset. We set fall-off factors
for weight computation. Due to every time k-means starts to iteration from random initial cluster centroids, the results for every experiment with the same settings might be slightly different.
4.2. Quantitative Results
We followed the evaluation metrics used in most literature to compare each method’s performance. The typical objective measures are based on the angular error (AE) [
9,
18]. AE is the angle in degrees between the illumination’s actual 3D-chromaticity
and its estimation
, which is defined as:
Since the AE is not normally distributed, the median value is used to evaluate the statistical performance along with the trimean value: . The trimean is the weighted average of the first, second, and third quantiles , , and , respectively.
We empirically compare our proposed method against a large number of existing statistics based algorithms on the Gehler-Shi and Cube+ datasets. For each dataset, we give a summary of the performance statistics that are available and always includes the state-of the-art results known to us. For completeness, we also compare our method with the latest learning based methods for illuminant estimation.
Table 2 and
Table 3 show the Mean, Median, Trimean, Best 25%, and Worst 25% of AE values obtained by each method on the Gehler-Shi dataset and the Cube+ dataset, respectively. The results of the proposed method in
Table 2 and
Table 3 are from the two separate experiments, where the Gehler-Shi dataset and the Cube+ dataset were trained and tested separately.
From
Table 2, we can see that on the Gehler-Shi dataset our method outperforms the eight unitary algorithms, with Mean from 3.31 for LSR to 2.96 for ours, and Trimean from 2.87 for LSR to 2.14 for ours. The rate of performance improvement is near 10%. As shown in
Table 2, in all statistics based methods listed, there is only one method, CCATI [
40], that surpasses ours. Also, our method provides better results than using some learning based methods, comparative with ExemplarCC [
41], CNN-based method [
42], and Simple feature regression [
35], except for Worst 25% is slightly big. In addition, it can be seen that both Best 25% and Worst 25% of our method are smaller than those of most statistics based methods listed. This indicates our method remains a better regression accuracy against the diversity of image features. Based on ANFIS, the estimation models and fuzzy weights developed by our method are robust and adaptive for a wide range of image features.
From
Table 3, we also have similar observations for the Cube+ dataset. All five statistics of our method are very near the best values from Color Beaver (Gray world) [
48]. This further validates the effectiveness of our method, as the Cube+ dataset contains 1707 images, bigger than the Gehler-Shi dataset of 568 images. Thus, on the whole our method achieves competitive performances for using Gehler-shi and Cube+ datasets. It should be noticed that our method does not provide the best estimation, but does provide the performance close to the best. Although the proposed method can be further improved and more experiments should be conducted on other benchmark datasets, we can obtain an initial conclusion that some learning-based methods can outperform even the most carefully designed and tested combinations of statistical and fuzzy inference systems. Even so, our method has a significant advantage in the fact that fuzzy models ease of encoding into imaging signal processors.
We also implemented some cross dataset experiments to investigate the performances of the proposed method: training with Gehler-Shi and Cube+ datasets combined into one large set, and (1) testing on the Gehler-Shi dataset, or (2) testing on the Cube+ dataset; (3) training on the Gehler-Shi dataset, and testing on the Cube+ dataset; (4) training on the Cube+ dataset, and testing on the Gehler-Shi dataset. For experiment (1), we obtained better results compared with ours in
Table 2; and for experiment (2), similarly better results compared with ours in
Table 3. It is as expected; since the models in both experiments were trained with more data and then can effectively cover a wider range of features. But experiment (3) obtained slightly unsatisfied results; in contrast, experiment (4) just achieved acceptable performances. What makes this significant could be that, compared with the Gehler-Shi dataset, the Cube+ dataset has more diverse image scenes and more extensive distribution of illuminations.
4.3. Qualitative Results
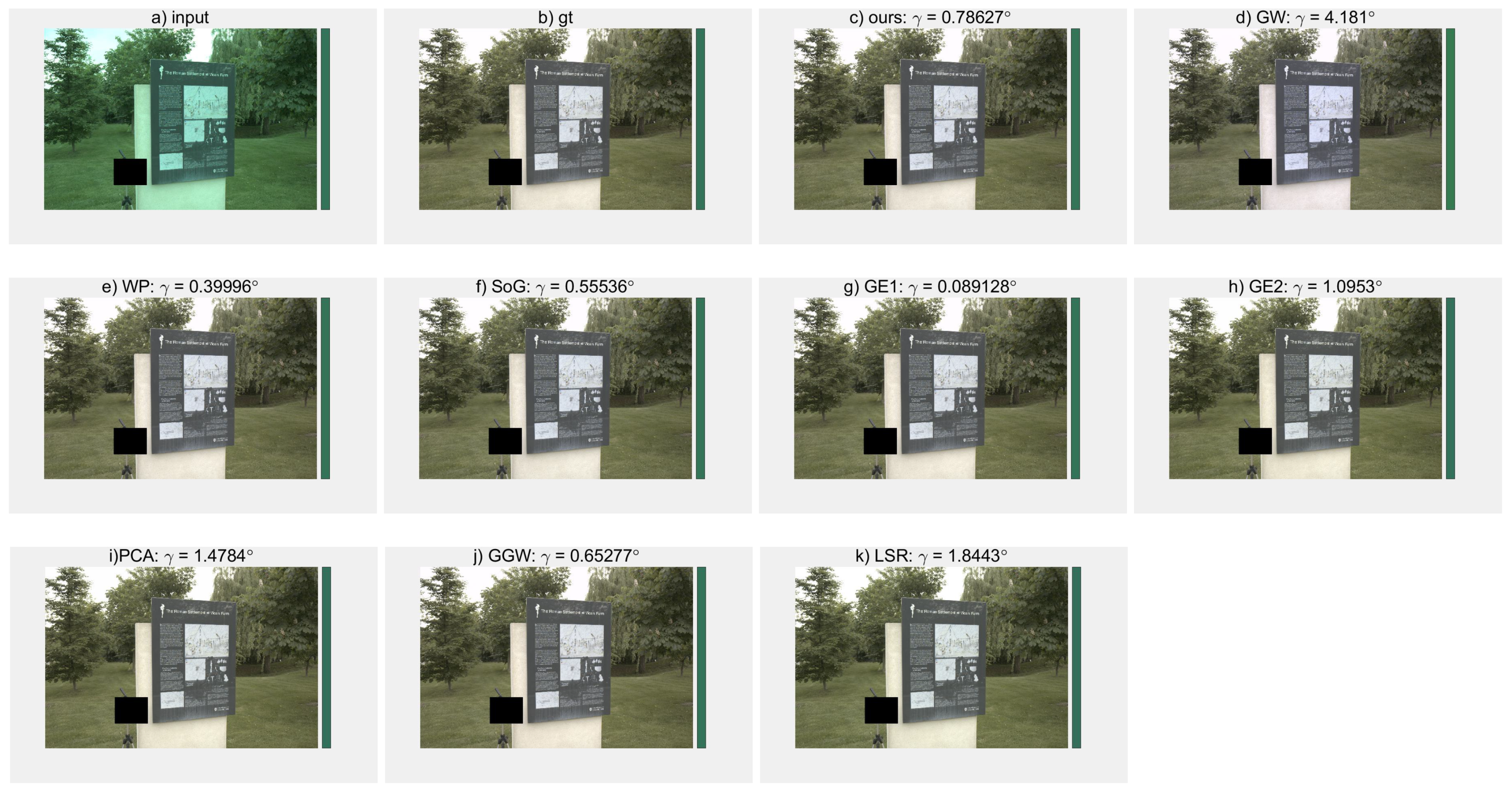
We provide some visual results for Gehler-Shi and Cube+ datasets, as shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7. For each input image, we show the ground truth, our estimated illuminant color and resulting white-balanced image, and other estimated illuminant colors and resulting white-balanced images using the unitary algorithms (GW, GGW, WP, GE1, GE2, SOG, PCA-based, and LSR). In these figures, the color bars on the right side of images (a) and (b) show the ground truth illuminant color. The color bar on the right side of images (c)–(k) shows the illuminant color estimated by the corresponding method, respectively. All images shown are rendered in sRGB color space.
In each one of
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7, the AE between the estimated illuminant color and the ground truth is listed on the top of the resulting white-balanced image labelled from (c) to (k). It can be seen that for a given input image, the AE using our method has a value between the maximum and the minimum of all AEs using the unitary algorithms, and generally near the minimum. For example, in
Figure 3, the AE using our method is 0.66, which is below the maxium of 3.46 for GW and near the minimum of 0.16 for GGW. Perhaps not surprisingly, since the proposed method is just based on a combination of unitary algorithms through ANFIS techniques, the result of the proposed method might not always be the best for a specific image. But from the view of entire dataset, the proposed method can obtain superior performances against other unitary algorithms. Results in
Table 2 and
Table 3 have already illustrated this observation.
4.4. Discussion and Further Analysis
We conduct many experiments to exploit the performance potentials of our proposed method. Besides cluster numbers, the factors influencing the performance of our proposal include different combination of unitary algorithms, sparsity of weight matrix obtained, etc.
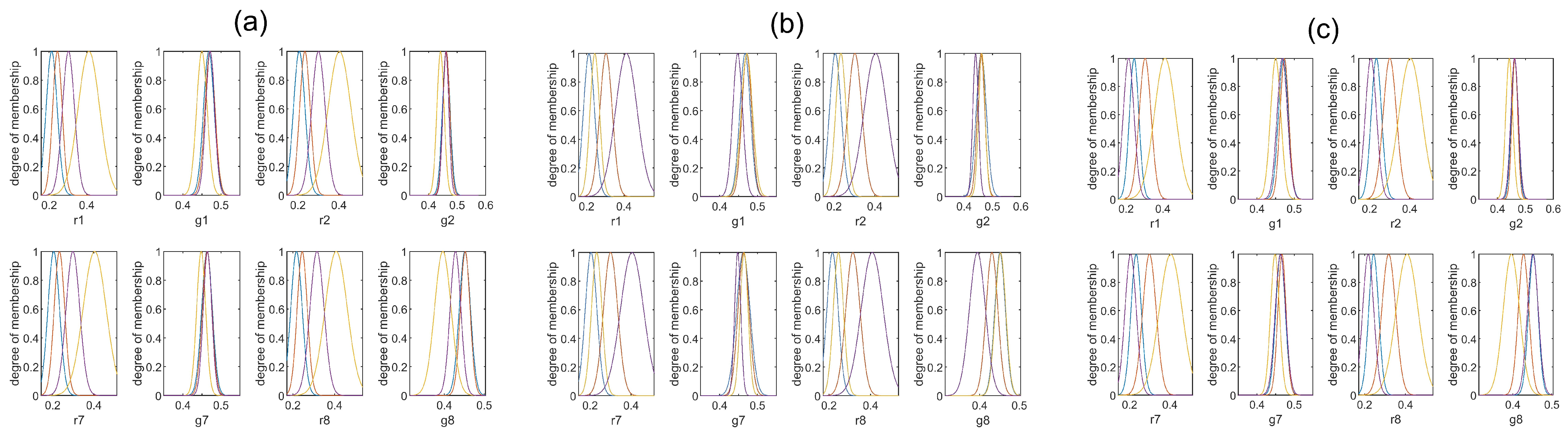
Different cluster numbers. In this study, we performed two steps of image clustering, first CDF based, and then IIF based. Using k-means algorithm, the cluster number can be manually changed in order to obtain better clustering results. The bigger cluster number might make the trained model overfitting, but the smaller cluster number might make the trained model inaccurate due to its limited feature coverage. We used different values of
and
so as to find the appropriate choices for the two-step clustering.
Table 4 gives some statistics for the results using different values of
and
. Through these tests, we found this two-step strategy is effective to group the training dataset, such that the images in the same cluster might have similar features that will be conducive to ANFIS modeling.
It should be noted that in
Table 4, we limit
into the range of
, as we find the settings with the total cluster number falling into this range will result in better estimation accuracy. We also can see from
Table 4 that the two-step strategy with the choices of
and
produces the best estimation accuracy. Comparing the results using different
and
, we find
and
are appropriate selections for our method on Gehler-Shi and Cube+ datasets. In our testing, we just have a combined dataset including 2275 images. Without doubt, if we use a larger image dataset, the number of
should increase for better modeling performances. To be a good case in point, k-means algorithm in paper [
51] is used to cluster more than 20,000 images, where the cluster number is optimally set to be about 70.
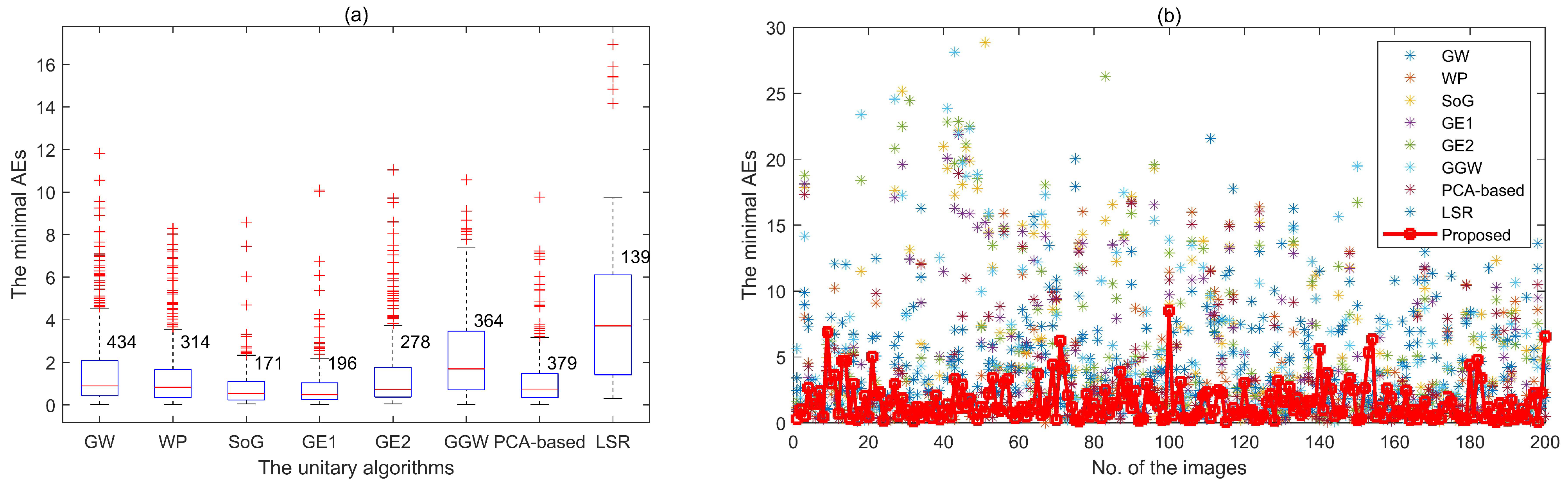
Different combination of unitary algorithms. By default, the proposed method uses the combination of eight unitary algorithms (GW, WP, SoG, GE1, GE2, GGW, PCA-based, and LSR), as we found for any image in our training dataset there are always some of these algorithms providing better illuminant estimation results.
Figure 8a gives the distribution of the minimum AEs under these unitary algorithms for each image in Gehler-Shi and Cube+ datasets. It can be seen that for most images, there is a unitary algorithm to estimate illuminant color with AE being less than 3. This figure shows that if we use an appropriate, linear or nonlinear, combination of these unitary algorithms, it is possible to achieve better accuracy of illumnation estimation.
To further exploit better combination relationships, we design several combinations of these unitary algorithms to implement the proposed method. Some of them contain less than eight unitary algorithms. The experimental results are shown in
Table 5. The results indicate that the configuration with the combination of GW, WP, PCA-based, and LSR results in the best illuminant estimation accuracy.
Figure 8b shows the minimum AE distribution for each method versus minimum AE obtainable with this chosen combination. It clearly shows the proposed method outperforms most of the eight unitary algorithms. It should be noted that this optimal combination might be just applicable for our experiments based on Gehler-Shi and Cube+ datasets. This experiment also indicates that seeking optimal combination is necessary to improve performances for illuminant estimation.
Using sparse weight matrix. In the proposed method, we use CDF weight vector
and IIF weight matrix
to measure what degree an image belongs to each cluster. We can define an integrated weight matrix
, where
is the final weight for the
ij-th ANFIS predictor. Since commonly there are many elements in
and
much less than 1 and very near to zero, i.e., the weights or possibilities for an image belonging to some clusters are very low, we can set all these elements’ values to zero and then recalculate the values of other elements. For simplicity, we set a threshold
for
. If
, set
.
W will become a sparse matrix
. To assure the element summary of each row of
to be 1, recalculate
,
,
, as below:
where
represents the summary of all elements greater than
in the
i-th row of
W.
We performed some experiments using the sparse weight matrix by setting
between
. We find the results change towards slightly improvement along with the increasing value of
, and the best performance corresponds to
, as
Table 6 shows. By using the sparse weight matrix, we just need to weight a small number of outputs from ANFIS models, and the computation effort will reduce much more.
Comparison with one-step clustering. We also conduct experiments to validate the effectiveness of our proposed two-step clustering strategy against the one-step clustering method. In so-called one-step clustering, we keep
or
to be 1, and just change the value of the other one.
Table 7 lists some statistical metrics for the results under different
and
values. In this table, Median and Trimean for
and
, Best 25% for
and
, and Worst 25% for
and
are all lower than the counterparts for
and
. But the case with
and
has the lowest Mean and almost the best in the rest metrics. Moreover, we find that the values of Worst 25% will fluctuate with as much as 1.11 degrees for
. This implies that the illuminant estimation is not robust in this case. Therefore, we can say the proposed method using the two-step clustering with
and
is better than using the one-step strategy. We suppose that since CDFs and IIFs can be regarded as the representatives of different image characteristics, separately applying CDF and IIF to cluster the images, i.e., using two steps, may result in good performances.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}