
MSGCN: Multi-Subgraph Based Heterogeneous Graph Convolution Network Embedding


Abstract
:1. Introduction
- A new method is proposed to deal with different types of edges to solve the heterogeneity of edge types. None of the previous approaches attempted to decompose the original graph into multiple subgraphs by type of edges. The subgraphs after decomposition can be viewed as homogeneous graphs, and they can be further processed using the methods previously applied to homogeneous graphs.
- A new model MSGCN is proposed. In MSGCN, the convolution operation is implemented over the subgraphs, which can overcome the heterogeneity of heterogeneous graphs and retain the structure, semantics, and node content information.
- We conducted extensive experiments on some public datasets. The results show that MSGCN outperforms the baselines on multi-class classification tasks and inductive learning tasks.
2. Related Work
2.1. Network Embedding
2.2. Subgraph Embedding
2.3. Dynamic Network Embedding
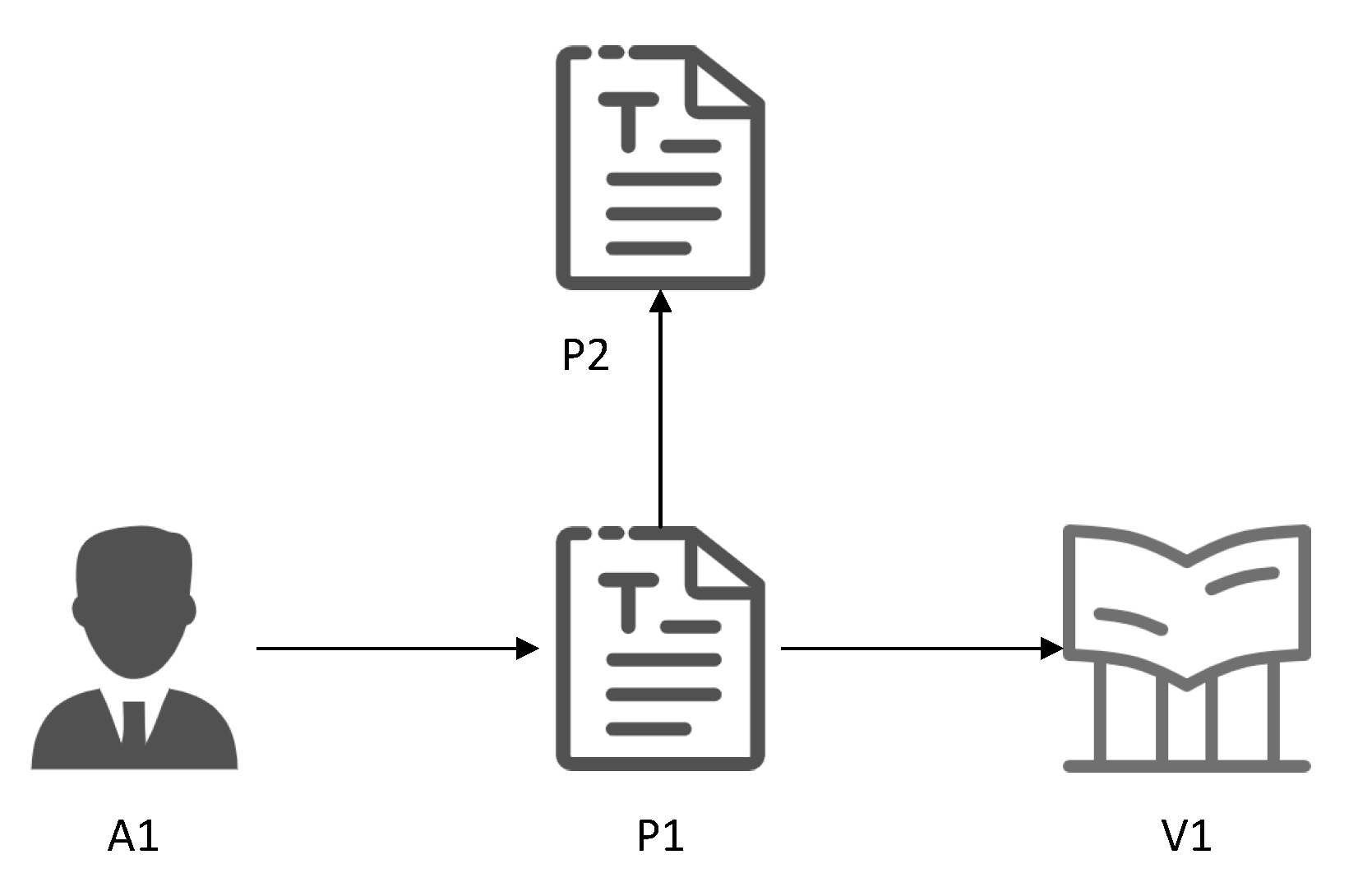
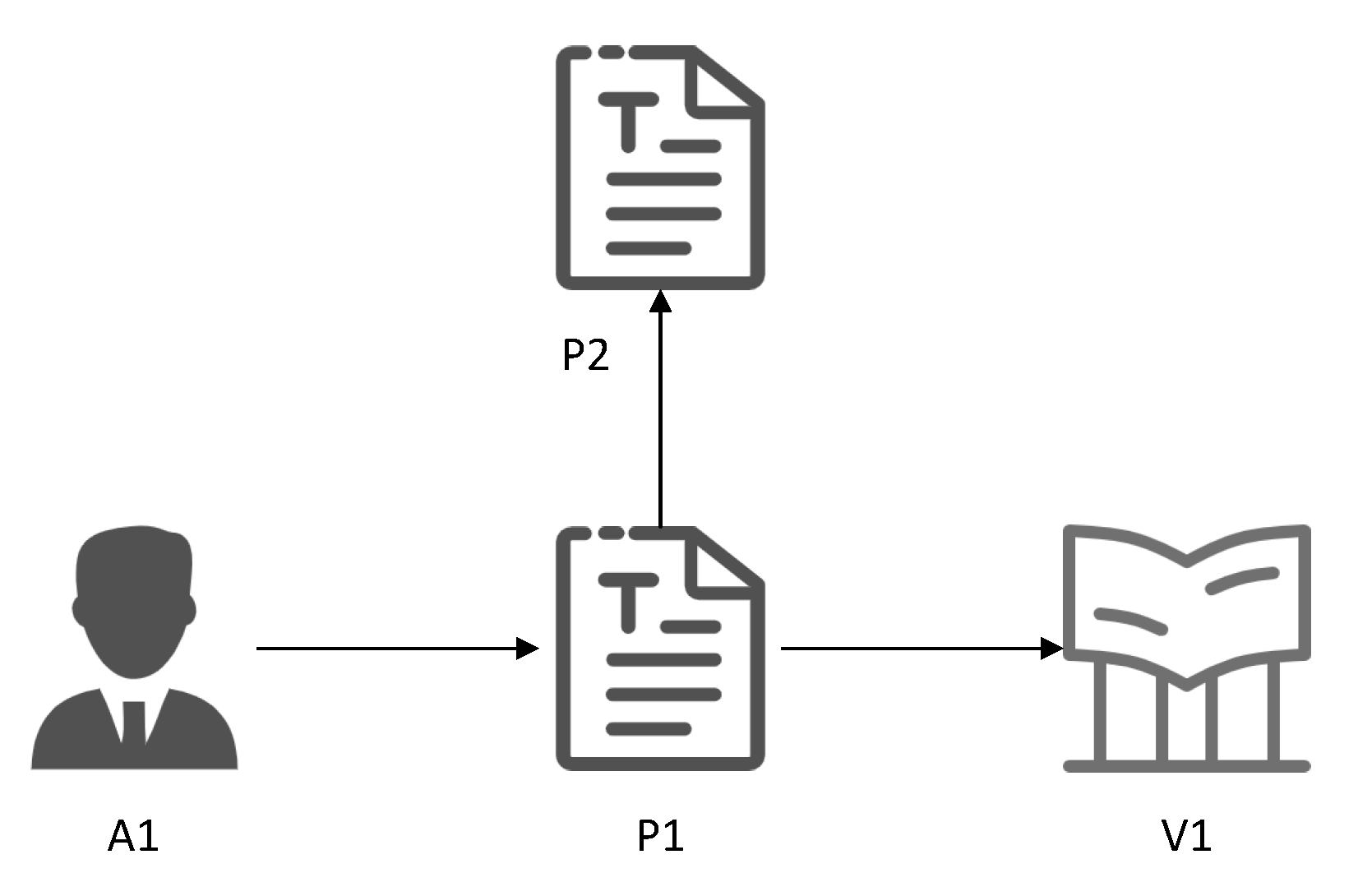
3. Definitions and Symbols
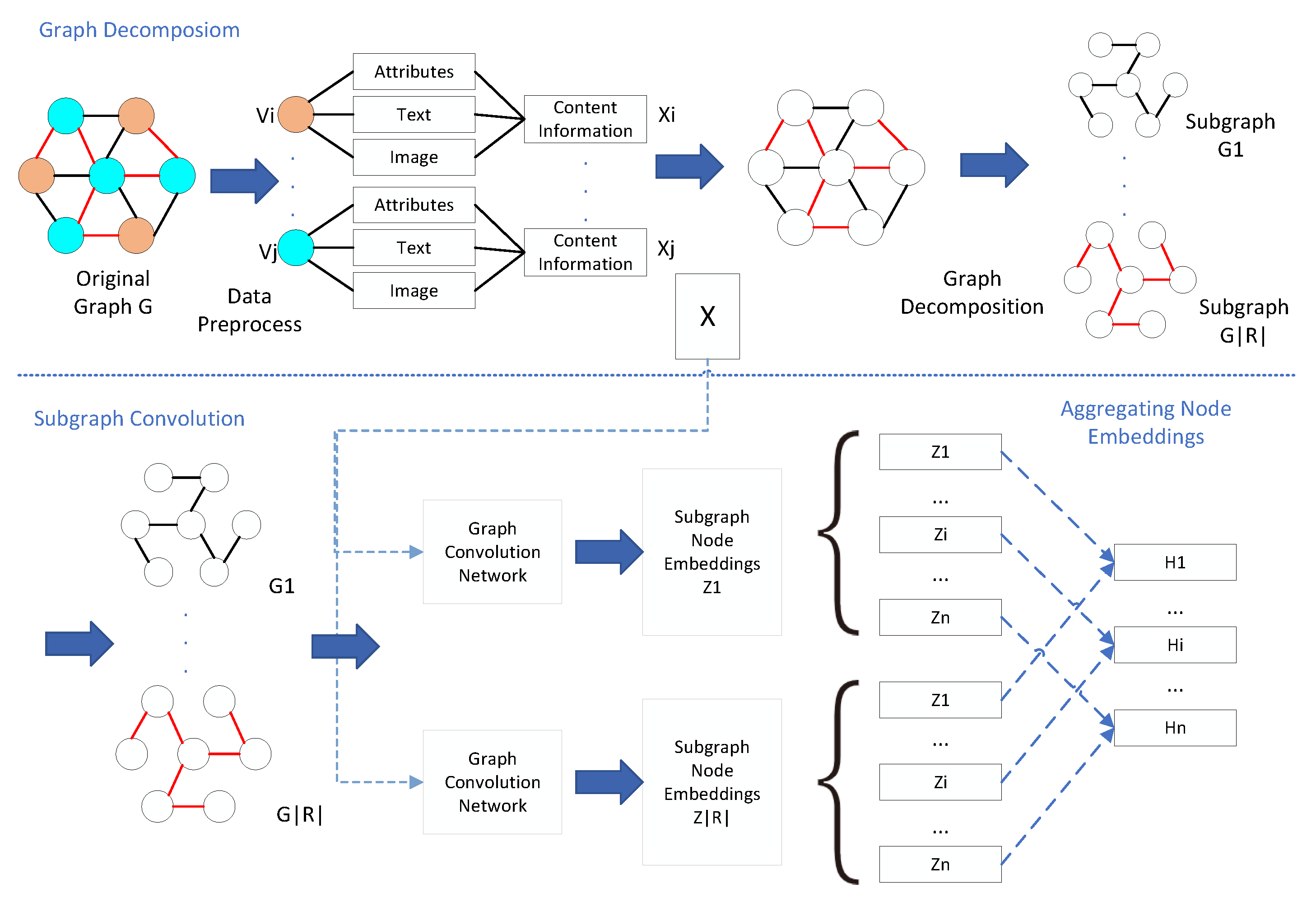
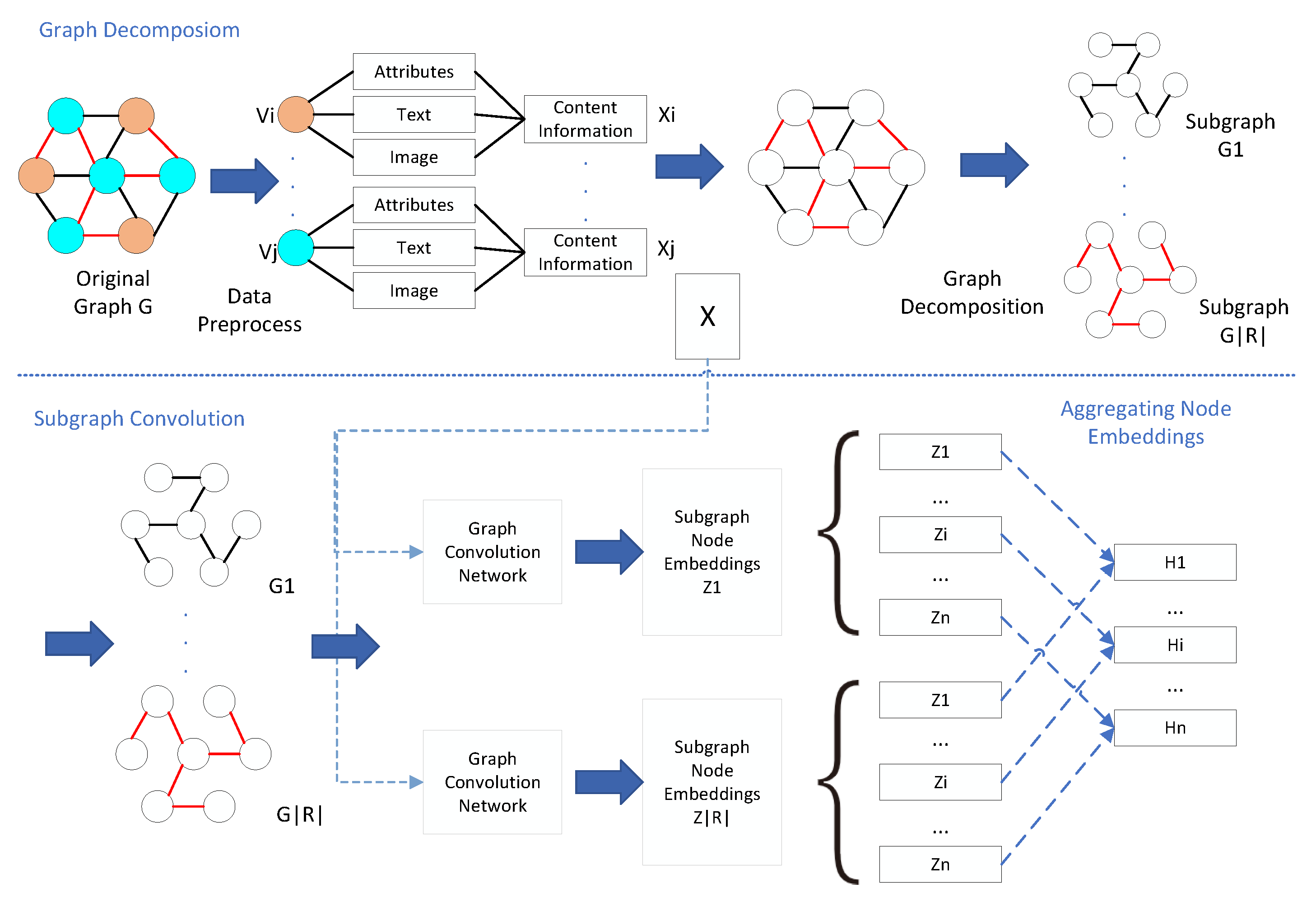
4. MSGCN Framework
4.1. Original Graph Decomposition
4.2. Subgraph Convolution
4.3. Aggregating Node Representations
4.4. Model Optimization
| Algorithm 1: MSGCN Model. |
 |
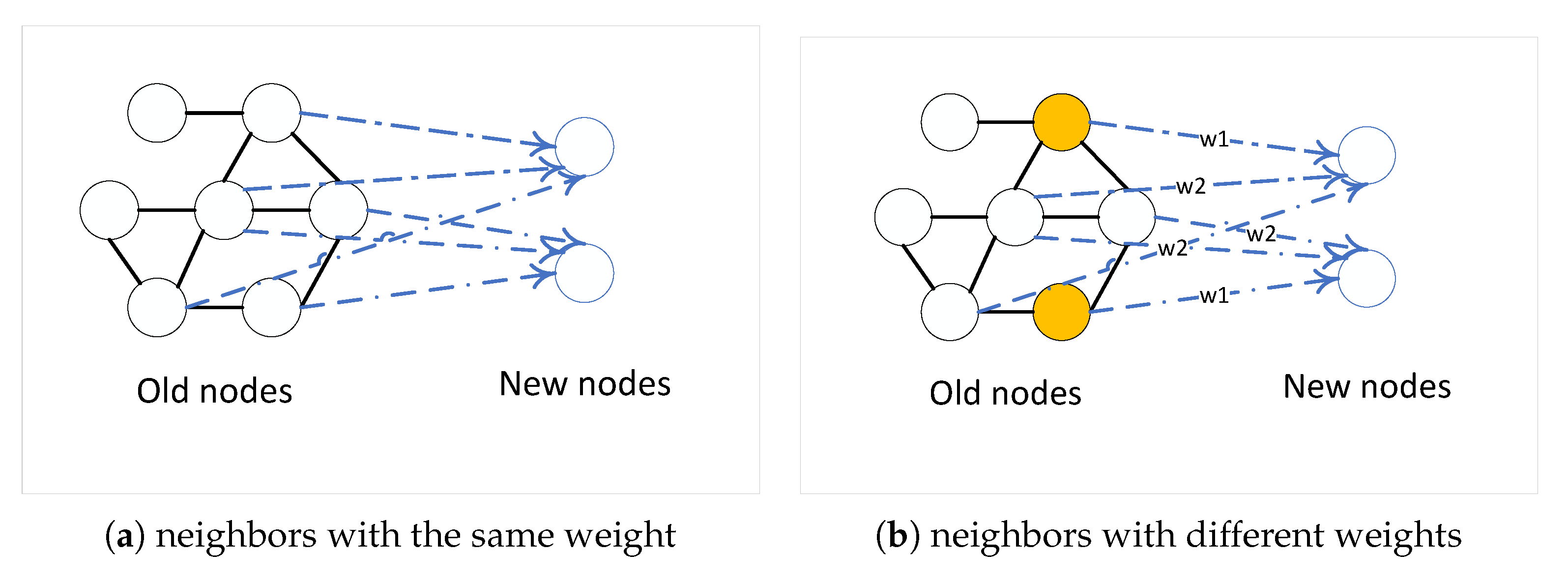
5. Application of the Model
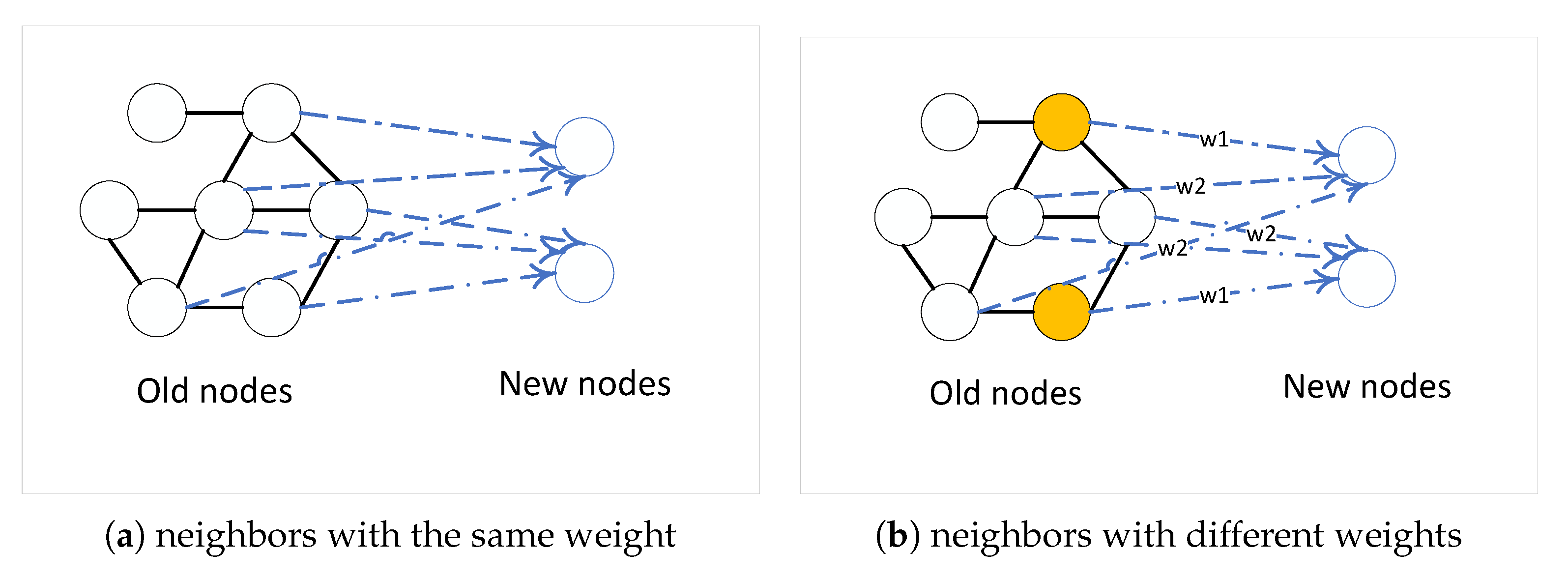
5.1. Transductive Learning Task
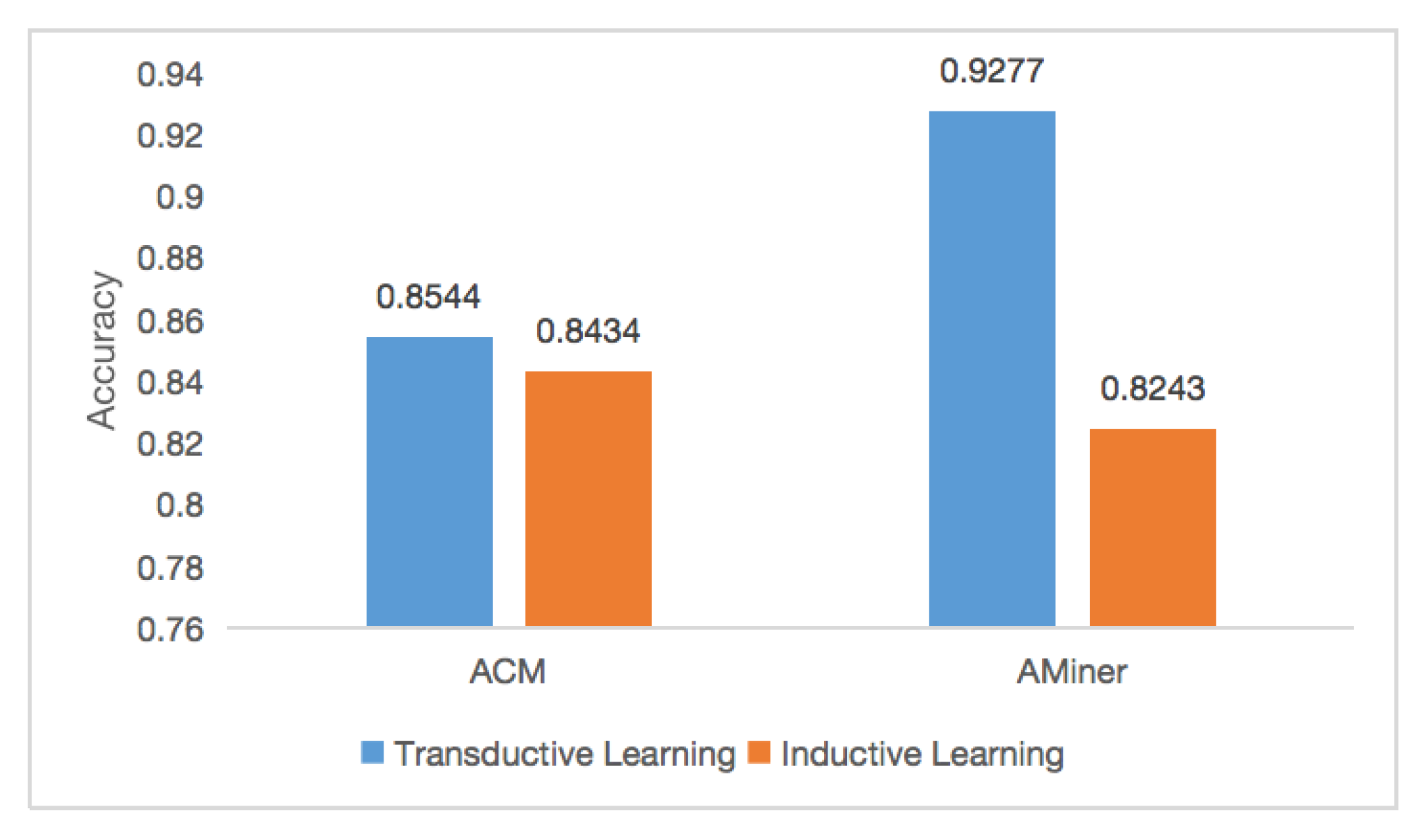
5.2. Inductive Learning Task
6. Experiment
6.1. Dataset
6.2. Baselines
- DeepWalk [3]: A random-walk-based embedding method designed for the same composition, which performs truncated random-walk over the network and is represented by skip-Gram model learning nodes.
- Graph Factorization (GF) [37]: A method of obtaining embedding by decomposing the adjacency matrix of a graph.
- SDNE [23]: Uses an automatic encoder to embed graph nodes and capture highly nonlinear dependencies.
- HOPE [22]: A method that uses generalized singular value decomposition (SVD) to get embeddings efficiently.
- GCN [7]: A classic semi-supervised graph neural network designed for the same composition, aggregating neighborhood information.
- GAT [8]: A neural network approach that applies the mechanism of attention to the same composition.
- TAGCN [45]: TAGCN is one of the variants of GCN. It uses a K graph convolution kernel to extract local features of different sizes.
- HAN [12]: A semi-supervised graph neural network embedding method for heterogeneous graphs that uses node-level attention and semantic attention to aggregate neighborhood information.
- MuSDAC [43]: A method on heterogeneous information networks.
- GraphInception [46]: A deep GCN for collective classification on heterogeneous information networks.
- MSGCN-mean: A variant of MSGCN that simply averages the representation of each node without considering the effect of edges on each node.
6.3. The Experimental Setup
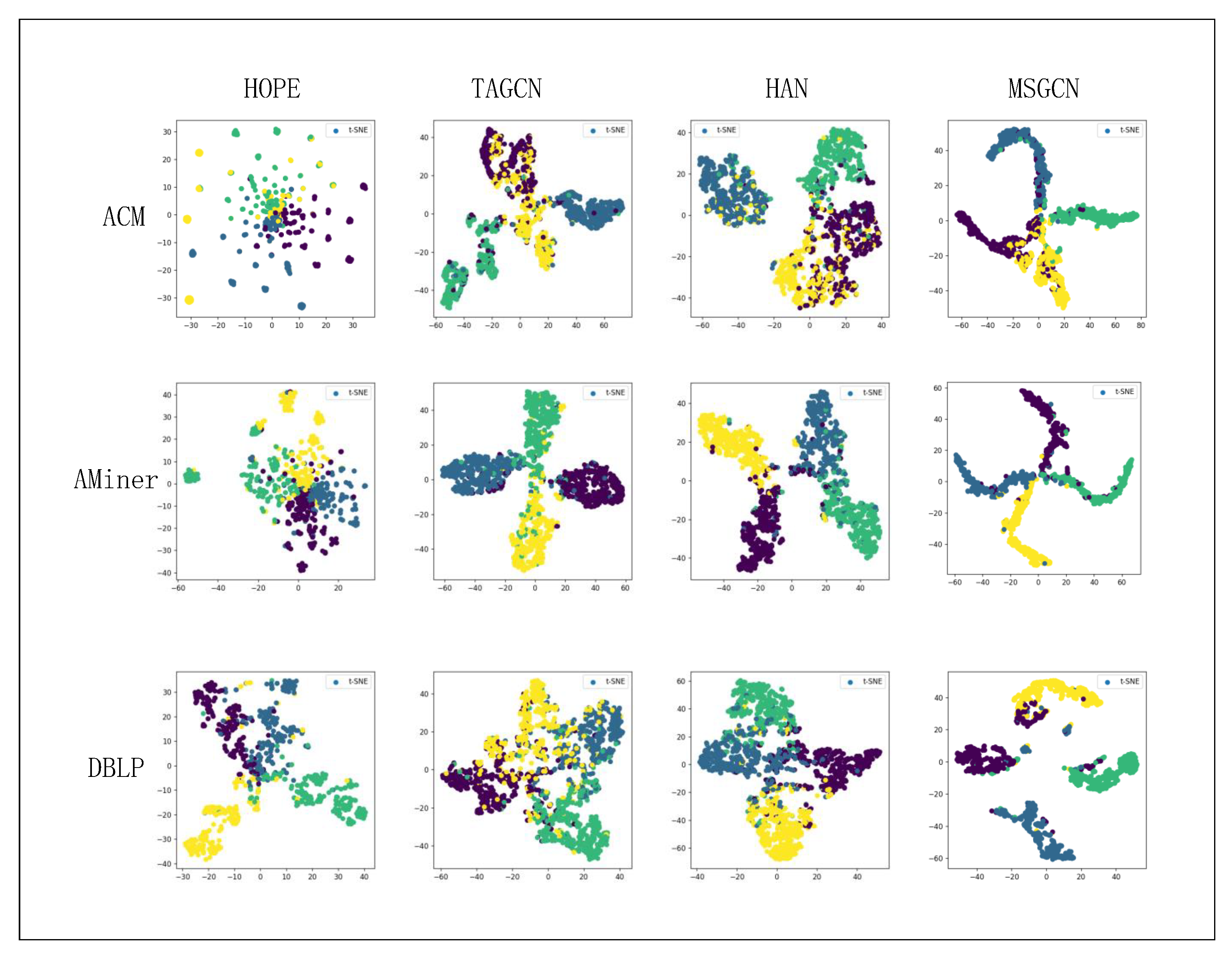
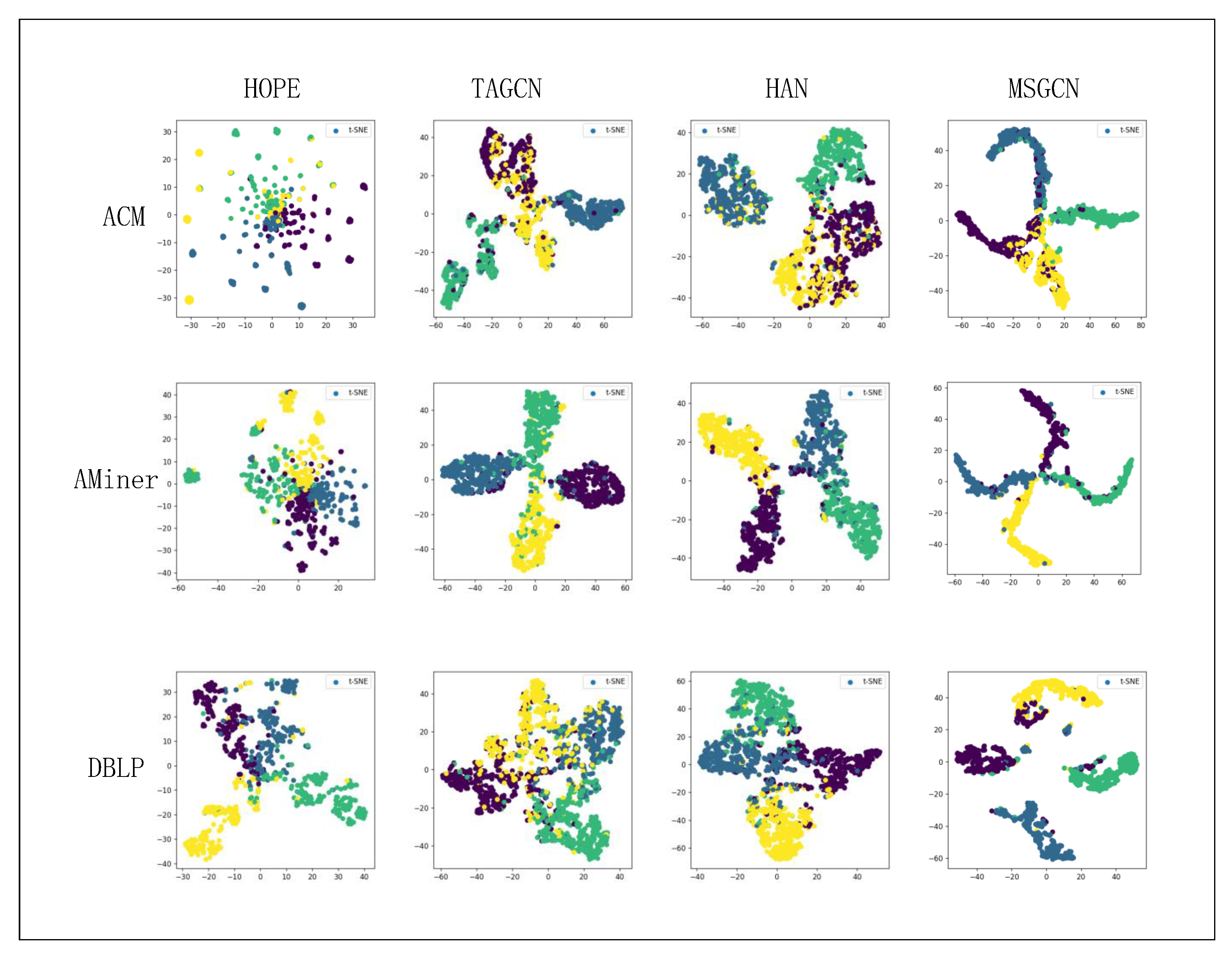
6.4. Multi-Class Node Classification
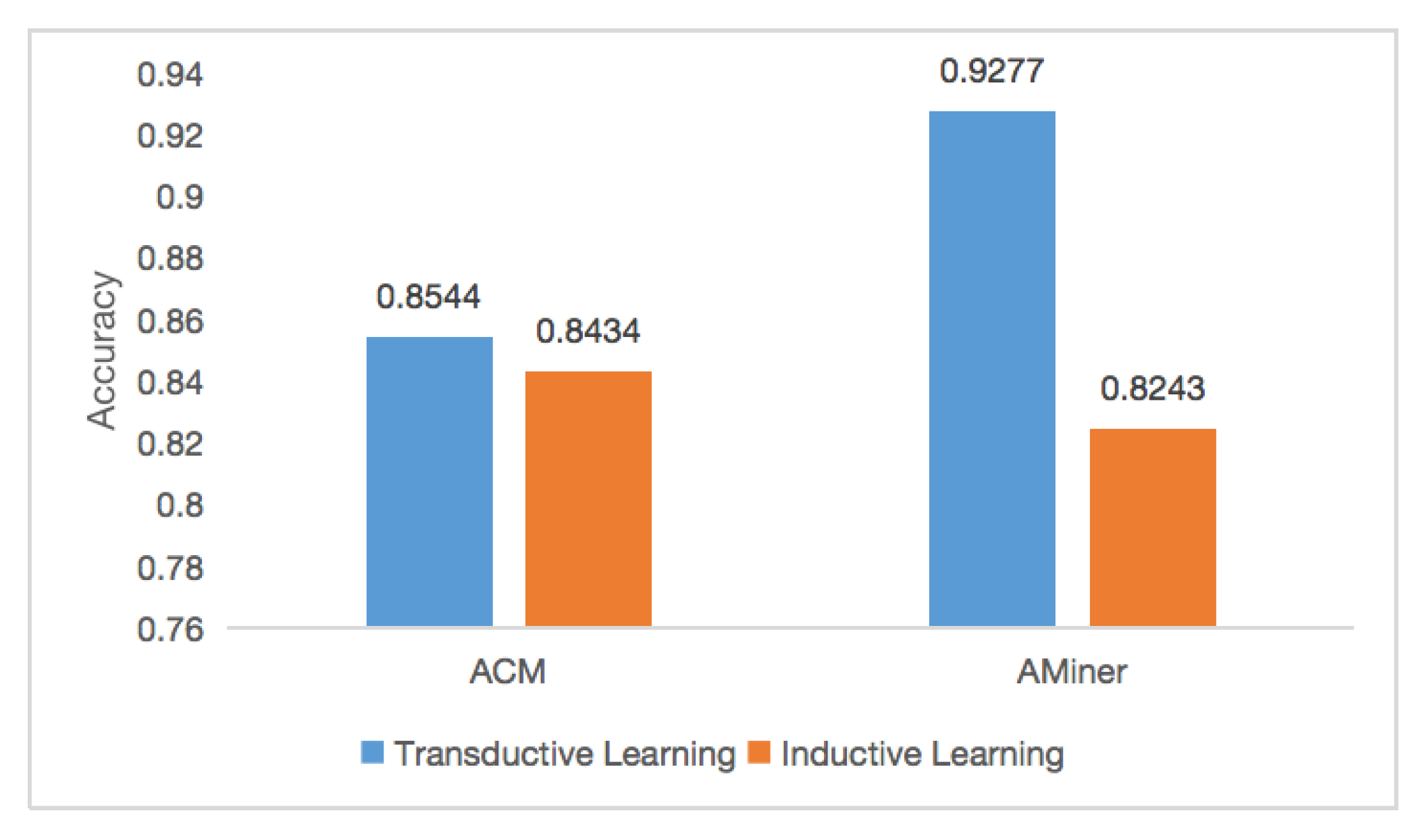
6.5. Inductive Learning Task
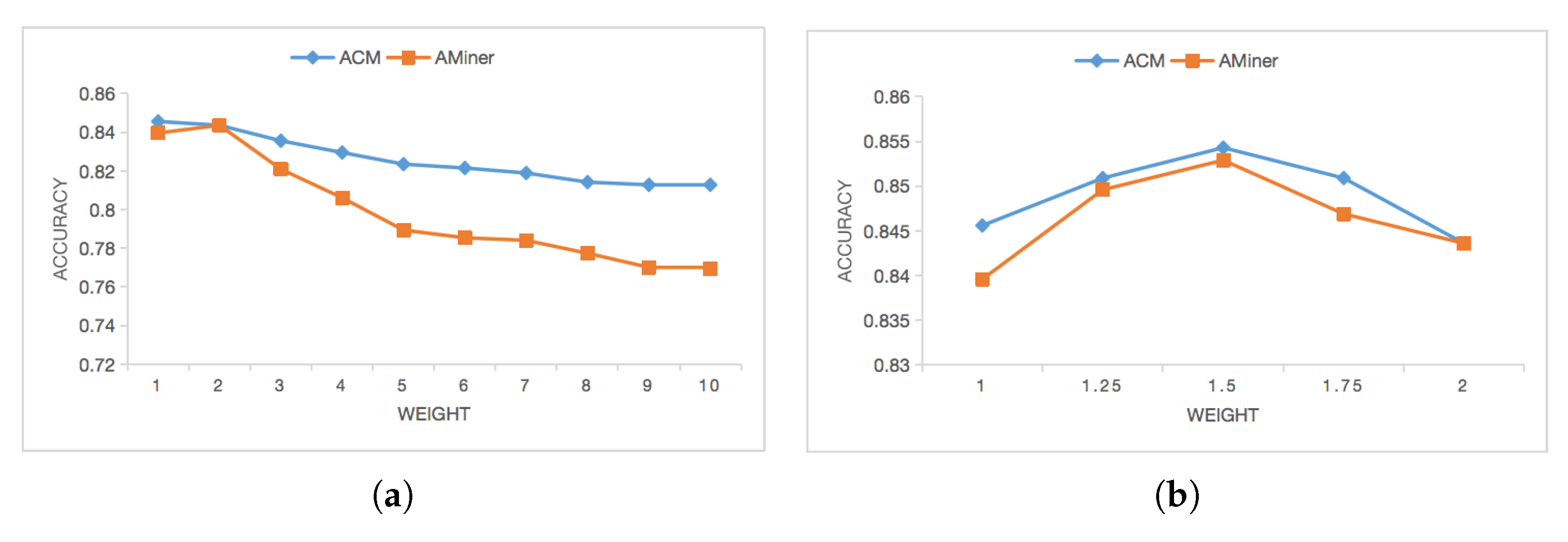
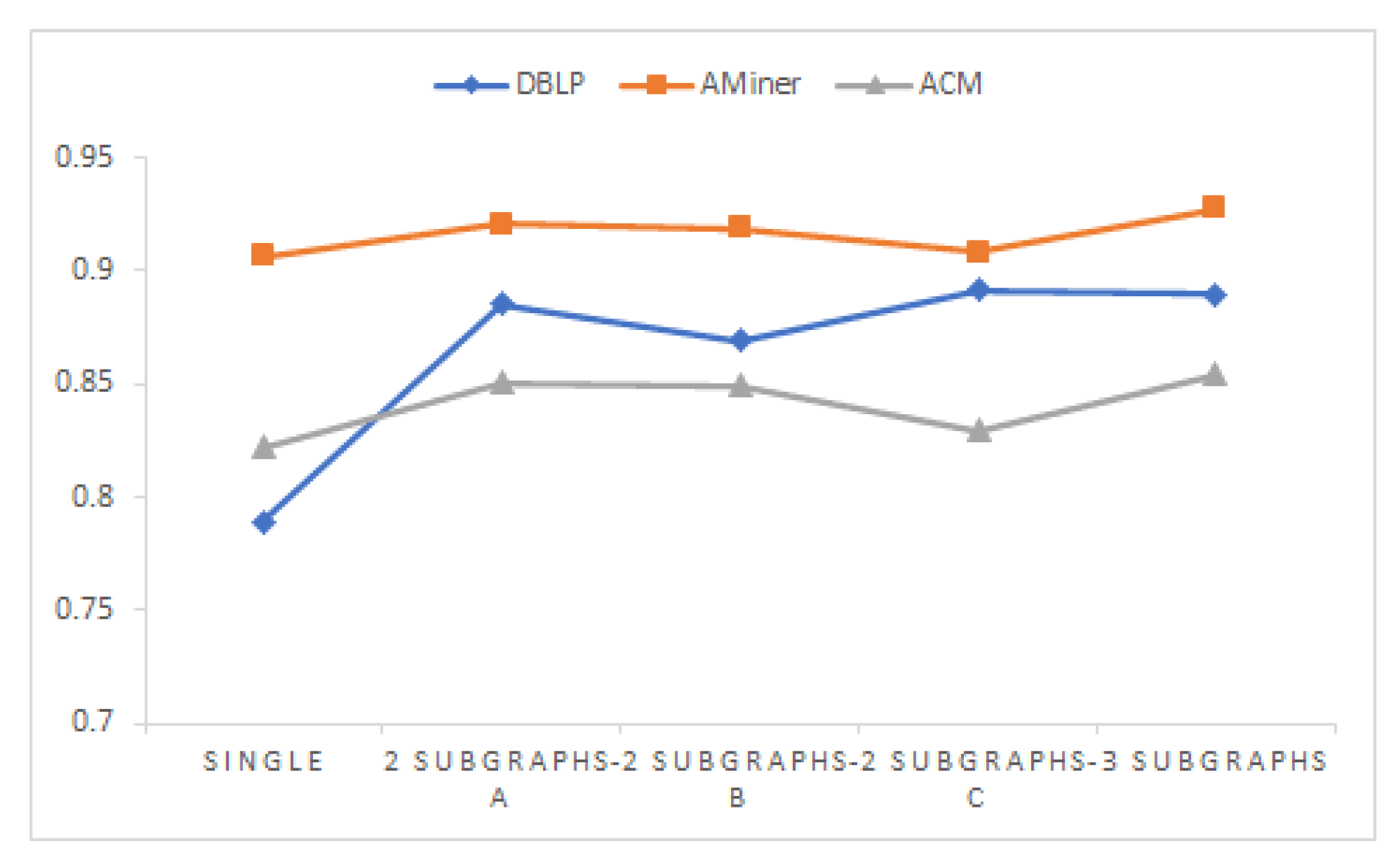
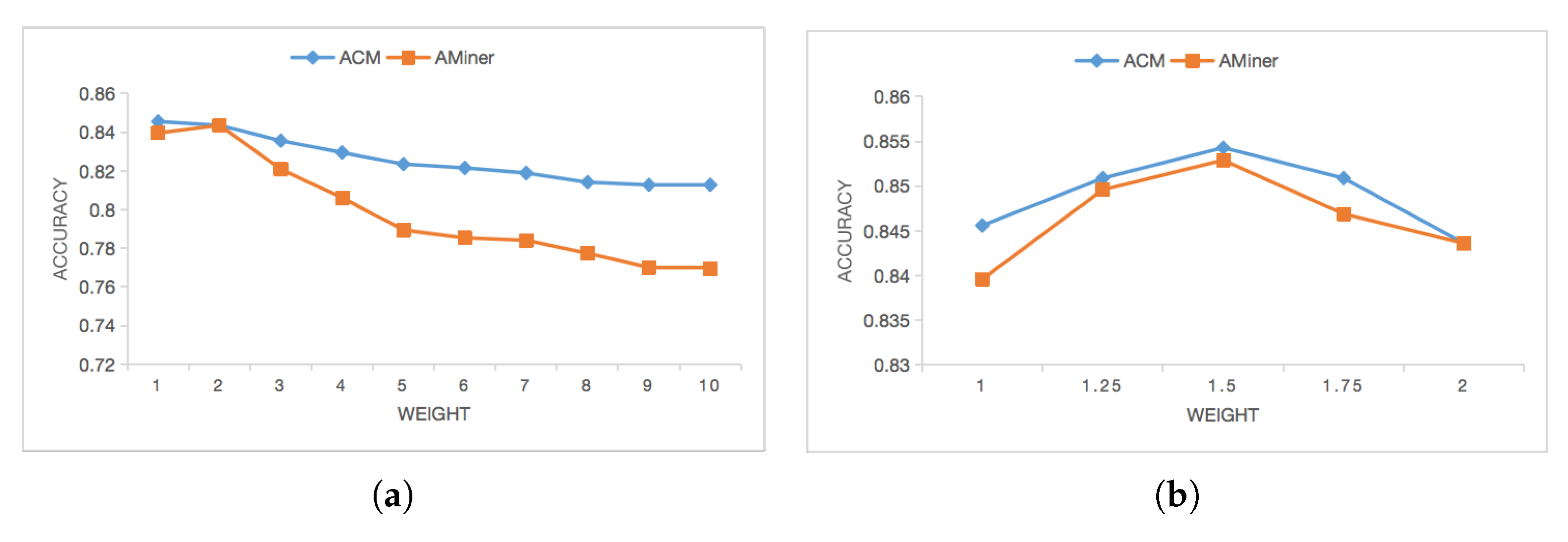
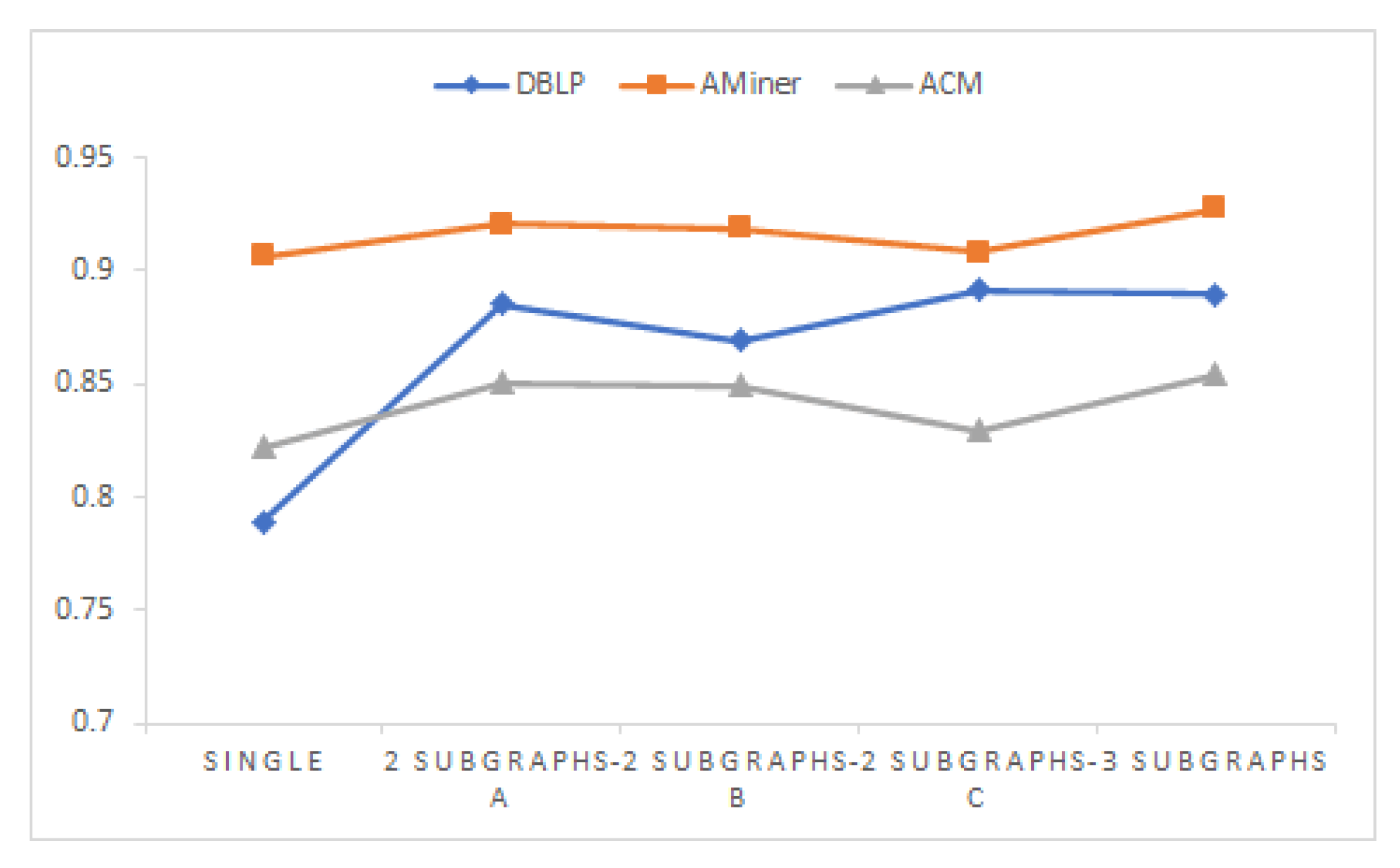
6.6. Extended Experiment
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Yi, P.; Huang, F.; Peng, J. A Fine-grained Graph-based Spatiotemporal Network for Bike Flow Prediction in Bike-sharing Systems. In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), Virtual, 29 April–1 May 2021; pp. 513–521. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. LINE: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, WWW 2015, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dong, Y.; Hu, Z.; Wang, K.; Sun, Y.; Tang, J. Heterogeneous network representation learning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Yokohama, Japan, 11–17 July 2020; pp. 4861–4867. [Google Scholar]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Yu, P.S. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 17–37. [Google Scholar] [CrossRef]
- Cen, Y.; Zou, X.; Zhang, J.; Yang, H.; Zhou, J.; Tang, J. Representation learning for attributed multiplex heterogeneous network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, 4–8 August 2019; pp. 1358–1368. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 357–370. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA,, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous graph transformer. In Proceedings of the WWW ’20: The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2704–2710. [Google Scholar]
- Fu, T.-Y.; Lee, W.-C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM 2017, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Zhao, J.; Wang, X.; Shi, C.; Hu, B.; Song, G.; Ye, Y. Heterogeneous graph structure learning for graph neural networks. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; pp. 4697–4705. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Adhikari, B.; Zhang, Y.; Ramakrishnan, N.; Prakash, B.A. Distributed representations of subgraphs. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 111–117. [Google Scholar]
- Yuan, C.; Li, J.; Zhou, W.; Lu, Y.; Zhang, X.; Hu, S. Dyhgcn: A dynamic heterogeneous graph convolutional network to learn users’ dynamic preferences for information diffusion prediction. In Proceedings of the Machine Learning and Knowledge Discovery in Databases - European Conference, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020; pp. 347–363. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, VIC, Australia, 19–23 October 2015; pp. 891–900. [Google Scholar]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1105–1114. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Adhikari, B.; Zhang, Y.; Ramakrishnan, N.; Prakash, B.A. Sub2vec: Feature learning for subgraphs. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Narayanan, A.; Chandramohan, M.; Chen, L.; Liu, Y.; Saminathan, S. subgraph2vec: Learning distributed representations of rooted sub-graphs from large graphs. arXiv 2016, arXiv:1606.08928. [Google Scholar]
- Tang, J.; Qu, M.; Mei, Q. PTE: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 1th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar]
- Wang, M.; Lin, Y.; Lin, G.; Yang, K.; Wu, X. M2GRL: A multi-task multi-view graph representation learning framework for web-scale recommender systems. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 23–27 August 2020; pp. 2349–2358. [Google Scholar]
- Mahdavi, S.; Khoshraftar, S.; An, A. dynnode2vec: Scalable dynamic network embedding. In Proceedings of the International Conference on Big Data, Big Data 2018, Seattle, WA, USA, 10–13 December 2018; pp. 3762–3765. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.B.; Leiserson, C.E. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 5363–5370. [Google Scholar]
- Nguyen, G.H.; Lee, J.B.; Rossi, R.A.; Ahmed, N.K.; Koh, E.; Kim, S. Continuous-time dynamic network embeddings. In Proceedings of the Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon, France, 23–27 April 2018; pp. 969–976. [Google Scholar]
- Ye, Y.; Hou, S.; Chen, L.; Lei, J.; Wan, W.; Wang, J.; Xiong, Q.; Shao, F. Out-of-sample node representation learning for heterogeneous graph in real-time android malware detection. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; pp. 4150–4156. [Google Scholar]
- Sankar, A.; Wu, Y.; Gou, L.; Zhang, W.; Yang, H. Dysat: Deep neural representation learning on dynamic graphs via self-attention networks. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 519–527. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Gallagher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93–106. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; Yang, S. Community preserving network embedding. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, 4–9 February 2017; pp. 203–209. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl.-Based Syst. 2018, 151, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Shervashidze, N.; Narayanamurthy, S.M.; Josifovski, V.; Smola, A.J. Distributed large-scale natural graph factorization. In Proceedings of the 22nd International World Wide Web Conference, WWW ’13, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 37–48. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, 2–4 May 2013. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. MAGNN: Metapath aggregated graph neural network for heterogeneous graph embedding. In Proceedings of the WWW ’20: The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Xie, Y.; Li, C.; Yu, B.; Zhang, C.; Tang, Z. A survey on dynamic network embedding. arXiv 2020, arXiv:2006.08093. [Google Scholar]
- Rong, X. word2vec parameter learning explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Yang, S.; Song, G.; Jin, Y.; Du, L. Domain adaptive classification on heterogeneous information networks. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Yokohama, Japan, 11–17 July 2020; pp. 1410–1416. [Google Scholar]
- Kong, X.; Yu, P.S.; Ding, Y.; Wild, D.J. Meta path-based collective classification in heterogeneous information networks. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, CIKM’12, Maui, HI, USA, 29 October–2 November 2012; pp. 1567–1571. [Google Scholar]
- Du, J.; Zhang, S.; Wu, G.; Moura, J.M.F.; Kar, S. Topology adaptive graph convolutional networks. arXiv 2017, arXiv:1710.10370. [Google Scholar]
- Xiong, Y.; Zhang, Y.; Kong, X.; Chen, H.; Zhu, Y. Graphinception: Convolutional neural networks for collective classification in heterogeneous information networks. IEEE Trans. Knowl. Data Eng. 2021, 33, 1960–1972. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Areas | Methods |
|---|---|
| Network Embedding | GraRep [21], HOPE [22], DeepWalk [3], Node2vec [4], SDNE [23], GCN [7], GAT [8], Metapath2vec [24], HIN2Vec [16], HAN [12], HetGNN [14] |
| Subgraph Embedding | Sub2vec [25], Subgraph2vec [26], PTE [27], M2GRL [28] |
| Dynamic Network Embedding | dynnode2vec [29], EvolveGCN [30], CTDNE [31], HG2Img [32], DySAT [33] |
| Symbols | Descriptions |
|---|---|
| Original homogeneous graph and the i-th subgraph | |
| V | Node set |
| E | Edge set |
| The edge set of the i-th subgraph | |
| X | Node content information matrix |
| The adjacency matrix of the i-th subgraph | |
| W | Weight matrix |
| The vector representation of the i-th subgraph | |
| The degree matrix of the i-th subgraph | |
| H | The final output embeddings |
| The new node set | |
| Sampled adjacency matrix | |
| Vector representation of the new nodes |
| Dataset | Nodes | Node Types | Edge Type A | Type B | Type C | Labels |
|---|---|---|---|---|---|---|
| DBLP | 1496 | 3 | 2602 | 673,730 | 977,348 | 4 |
| AMiner | 1500 | 3 | 4360 | 554 | 89,274 | 4 |
| ACM | 1500 | 3 | 4960 | 6691 | 26,748 | 4 |
| Dataset | DBLP | AMiner | ACM | |
|---|---|---|---|---|
| Method | ||||
| DeepWalk | 0.8736 | 0.904 | 0.8386 | |
| GF | 0.8061 | 0.7867 | 0.724 | |
| HOPE | 0.9064 | 0.86 | 0.8213 | |
| SDNE | 0.8983 | 0.804 | 0.8227 | |
| GAT | 0.5683 | 0.9066 | 0.6777 | |
| GCN | 0.6566 | 0.9036 | 0.6767 | |
| TAGCN | 0.7851 | 0.9147 | 0.8353 | |
| HAN | 0.8484 | 0.9006 | 0.8444 | |
| MuSDAC | 0.8170 | 0.7990 | 0.7900 | |
| GraphInception | 0.7090 | 0.6030 | 0.5930 | |
| MSGCN | 0.9096 | 0.9277 | 0.8594 | |
| MSGCN-mean | 0.8203 | 0.9327 | 0.8695 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Huang, F.; Peng, J. MSGCN: Multi-Subgraph Based Heterogeneous Graph Convolution Network Embedding. Appl. Sci. 2021, 11, 9832. https://doi.org/10.3390/app11219832
Chen J, Huang F, Peng J. MSGCN: Multi-Subgraph Based Heterogeneous Graph Convolution Network Embedding. Applied Sciences. 2021; 11(21):9832. https://doi.org/10.3390/app11219832
Chicago/Turabian StyleChen, Junhui, Feihu Huang, and Jian Peng. 2021. "MSGCN: Multi-Subgraph Based Heterogeneous Graph Convolution Network Embedding" Applied Sciences 11, no. 21: 9832. https://doi.org/10.3390/app11219832
APA StyleChen, J., Huang, F., & Peng, J. (2021). MSGCN: Multi-Subgraph Based Heterogeneous Graph Convolution Network Embedding. Applied Sciences, 11(21), 9832. https://doi.org/10.3390/app11219832