1. Introduction
There are many results of using convolutional neural networks (CNNs) in research fields. In various industrial fields, there have been many attempts to apply the research results obtained through CNN models to specific applications. To properly apply the results obtained using a CNN model to specific applications, training data suitable for the application is required.
One of the industries that often use images is augmented reality. Augmented reality provides useful information to users based on recognized real space or objects. For example, trainees learning to assemble a car can learn how to assemble it based on car parts recognized by an augmented reality device such as an HMD or smartphone. As another example, trainees learning machine maintenance can easily recognize the location or condition of a part with an augmented reality device and learn behaviors appropriate to the current machine condition to repair the machine.
To train a CNN model suitable for a specific application in augmented reality, training data suitable for a specific scenario is required. For example, to train a CNN model for recognizing the class of an object, the class labels corresponding to images are required. To train a CNN model for recognizing which part an object is composed of, the mask labels indicating the location and area of each part of the object and the class name of each part are required. It takes a large amount of time and manpower to make the mask labels from the suitable dataset for a specific application. Since each object is usually composed of several parts, making the mask labels of each part takes longer than making the mask labels of each object.
Interactive object segmentation methods enable a user to segment the area pixel level of a target object area through user interaction. Methods using CNNs have emerged that improve the accuracy of object segmentation over classical algorithm methods (e.g., GrabCut [
1]). The interactive object segmentation methods using CNN easily and accurately make the mask labels.
Interactive object segmentation models based on CNN are generally supervised learning through images and ground truth mask labels in the dataset. Due to the limited number of classes of objects in the dataset, the models utilize the backbone of classification models trained with Image Net datasets, which contain the largest number of object classes. However, it is difficult to accurately segment the target part in an object with the models for segmenting the target object. One of the reasons is that the size of the target part is smaller than the size of the target object. Another reason for the lower accuracy of the target part is that the texture in the interaction area during part segmentation is different from the texture during object segmentation. For example, when a user segments the person in the image with the interactive object segmentation model and interaction, it can accurately segment the target object (e.g., person) because it is trained using the clicked areas which contain the different parts of the object. However, when a user segments the target part (e.g., nose) with the same model, it cannot accurately segment the target partly because the model has never been trained with the texture around the nose that the user clicked on.
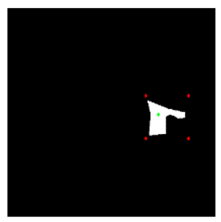
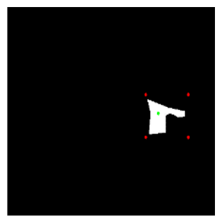
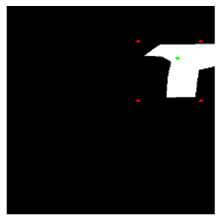
Table 1 below shows the estimated masks when the interactive object segmentation models segment the motorcycle (object) and the motorcycle’s wheel (part). For the two models tested, the accuracy of part segmentation is much lower than the accuracy of object segmentation.
The edge image can be expressed as a binary image if the pixel is greater than the threshold and the pixel is true or false, otherwise, it be expressed as a grayscale image according to the value of the change in the local area. The size of the dataset which consists of edge images is lower than the size of the color image dataset because the edge image consists of a single channel, whereas the color image consists of three or four channels. The edge image, which consists of a single channel, has one disadvantage in that it is difficult to distinguish the class of object in the selected area because there is no texture information, but it can be suitable as training data for the interactive (object) segmentation models. The ability to distinguish between the area of the target object and background is important because it is important for an interactive segmentation model to accurately segment the target area rather than to recognize what it is. Thus, instead of texture information that can recognize the classes of objects, the edge images can be more suitable for an interactive segmentation model than color images. Edge images generated by the classic edge detectors such as Canny Edge [
4] are difficult to use in real applications due to a large amount of noise, but with the advent of edge detectors using CNN models, relatively accurate edge images can be obtained.
Existing deep-learning models are trained the feature of the color texture of the image in the training dataset. These models show good performance in the evaluation dataset because they are evaluated with color images obtained under similar environment conditions, but when they are applied in the actual industry, the desired performance sometimes is not achieved because the environment is different. On the other hand, an edge image is an image in which the same characteristics are refined even in color images taken under different environments. In this paper, we will examine whether similar performance can be achieved only with edge images instead of color images in interactive object or parts segmentation, which is one of the tasks sensitive to color texture characteristics. One of the contributions of this paper is to find an edge image suitable for an input image of an interactive segmentation model. In this paper, suitable edge images are found through experiments to accurately segment the target object. We conducted the second experiment to compare with the proposed model trained with the edge images which were selected based on the results from the first experiment and the existing interactive object segmentation model. The proposed models were trained with an object segmentation dataset (e.g., PASCAL VOC 2012 [
5] or SBD [
6]), and these were evaluated by a part segmentation dataset. Here we used PASCAL VOC Part [
7] dataset for evaluation. Experimental results showed that the proposed model trained with edge images could segment the target part more accurately compared to the existing segmentation models trained with color images.
2. Related Work
2.1. Semantic Part Segmentation
The problem of segmenting the target part in an image is one of the important issues that has been studied. GMNet [
8], one of the most recently published semantic part segmentation methods, proposed a method of part segmentation by combining CNN and graph methods. The proposed model is trained and evaluated with PASCAL VOC Part [
7] dataset (based on 108 Part) and the average accuracy intersection of union (IOU) is about 50%.
Many studies have been conducted on part segmentation, but there is still a problem that the IOU accuracy is not high enough. One of the reasons the IOU accuracy of part segmentation is not high enough is that segmentation is difficult because the size of part is smaller than the size of objects. Another reason is that the number of part classes is bigger than the number of object classes, so it is difficult to recognize them. In addition, to train a part-segmentation model based on CNN, many mask labels are needed for each part. However, the number of part segmentation datasets is much smaller than the number of object segmentation datasets.
2.2. Interactive Object Segmentation
Unlike semantic segmentation methods, interactive segmentation methodsonly segment the area of the target object or the part with user interaction. In addition, they cannot recognize the classes of the selected object. However, they have the advantage of being able to segment an unlearned object or region through user input.
DeepGrabCut [
9] is one methods of segmentation of the target objects with user interaction. In DeepGrabCut [
9], when the user selects the object around the target object by drawing the bounding box, the object is segmented. In the process of drawing the bounding box, the target object can be segmented easily with one operation, but it is difficult for it to be segmented precisely.
Another interaction method is to use only the click interaction. In this method, segmentation occurs by clicking the target object area and the non-target area. The user can see the object mask predicted by the deep-learning model and finely segment the target object through additional clicks. Forete et al. [
10] proposed a method to solve the problem of IOU accuracy decreasing when the number of clicks increases in the case of the existing models by adding the previously estimated mask as input to the proposed deep-learning model. Maninis et al. [
11] proposed a method of segmentation of the target object by clicking some of the points on the boundary of the target object. Lin et al. [
12] proposed a method for better segmentation of the target object by weighting the area the user first clicked on. Jang et al. [
13] proposed a more accurate object segmentation method (BRS) with refining information converted from user interaction by using the backpropagation method. Sofiiuk et al. [
2] proposed a faster segmentation method (f-BRS) than BRS by performing backpropagation in only part of the model. Zhang et al. [
3] proposed a method (IOG) for segmenting the target objects through interaction that combines the advantages of the bounding box and click methods. In IOG, a user first selects the area around the target object using the bounding box, and then can segment the target object precisely by clicking additionally on the area that is an object or the area that is not an object based on the area of the mask estimated by previous interaction.
The above methods allow a user to accurately segment the target object with less interaction. However, in all of the existing methods, if the part of an object is segmented with these models trained using color images, the IOU accuracy is greatly reduced.
2.3. Color Texture
Geirhos et al. [
14] showed that the CNN models trained to recognize the object classes in the ImageNet dataset focus on the texture feature rather than the shape feature of the object. Since humans focus on the shape features rather than the texture features when recognizing an object, they change the texture of the images to train the proposed model to focus on the shape features of the object when recognizing the target objects.
Because CNN models train based on color texture, they cannot accurately recognize rotated objects. In the results from Wang et al. [
15], instead of changing the texture of the input image, they proposed a method to better recognize the rotated object (Modified National Institute of Standards and Technology (MNIST)) by additionally inputting the grayscale image.
There have been many studies to solve the problem of CNN models trained by focusing on the color texture feature, but most of them focus on the classification problem, and relatively few studies deal with the segmentation problem.
2.4. Edge Detector
Edge has been regarded as one of the most basic problems of computer vision because of the aforementioned characteristics. One of the typical classic edge detectors is the canny edge method. Most of the classic edge detectors show some performance, but the accuracy is not high enough for real-world applications.
With the advent of deep learning, especially CNNs, many edge detectors based on CNNs have appeared. Holistically-nested edge detection (HED) [
16] shows higher edge detection accuracy than the classical edge detector based on the VGG [
17] model, which is one of CNN’s models. Many studies for edge detection have been conducted compared to HED. The richer convolutional features for edge detection (RCF) [
18] proposed a method of performing edge detection with high accuracy in real-time based on the VGG model. The dense extreme inception network for edge detection (DexiNed) [
19], one of the most recently proposed edge detectors, accurately detects even small-sized edges with less noise than the results of edge detectors using CNNs.
With the development of deep learning, many edge detectors have been studied, but there are not many applications or studies using edge images estimated from edge detector models.
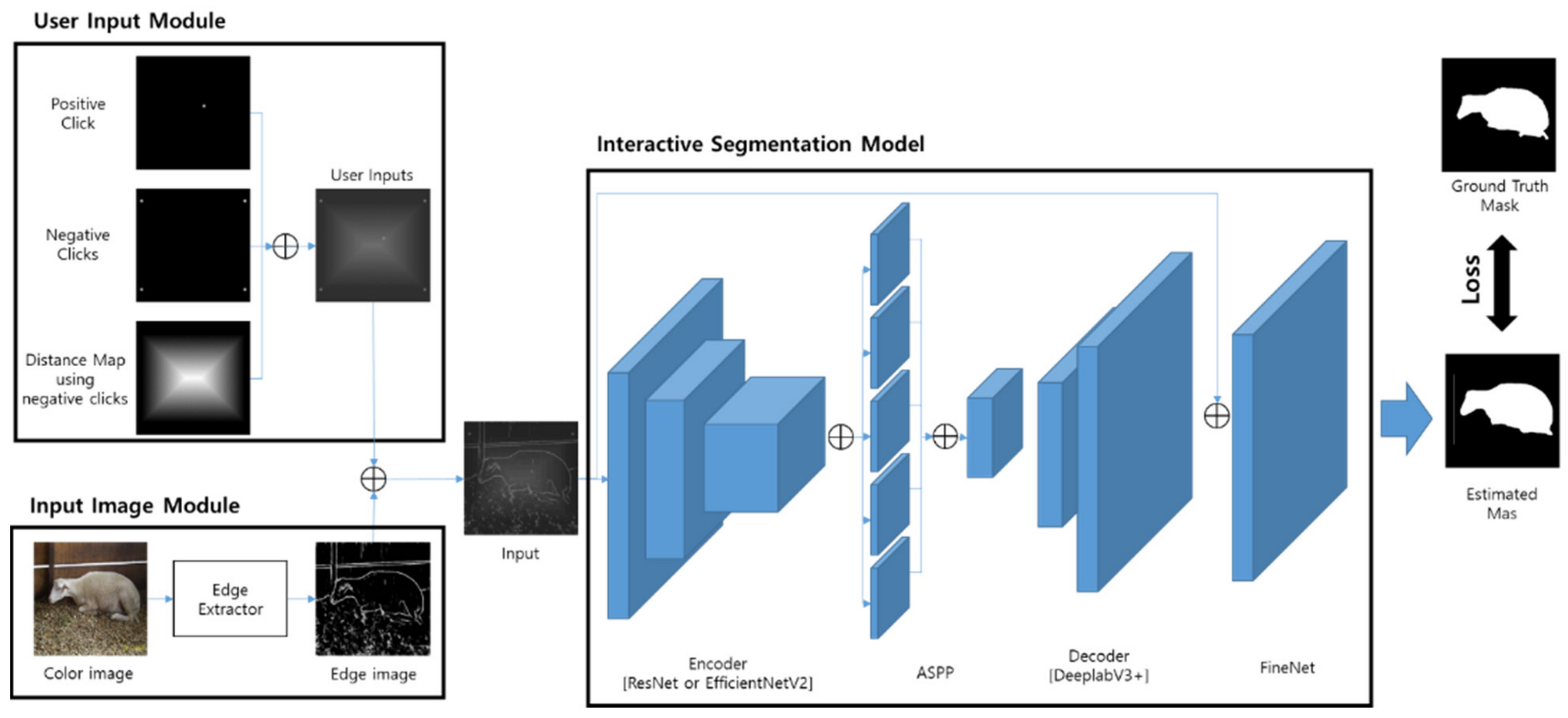
The existing interactive segmentation models are trained on how to interactively segment an object with a color image. Just like the method by adding or changing input images to solve the problem that a CNN is trained by focusing on texture features, an interactive segmentation model can be trained based on shape features instead of texture features when input images are changed. We propose a method to segment the target object or part with the model trained by edge images instead of color images.
4. Experiments
In order to train the proposed models, we trained them with only the training image set excluding the evaluation image set of the PASCAL VOC 2012 [
5] dataset and the SBD [
6] dataset. The proposed models have only been trained to segment the target object with user interaction, not to segment the target part. The PASCAL VOC Part [
7] dataset was used only when evaluating the proposed models.
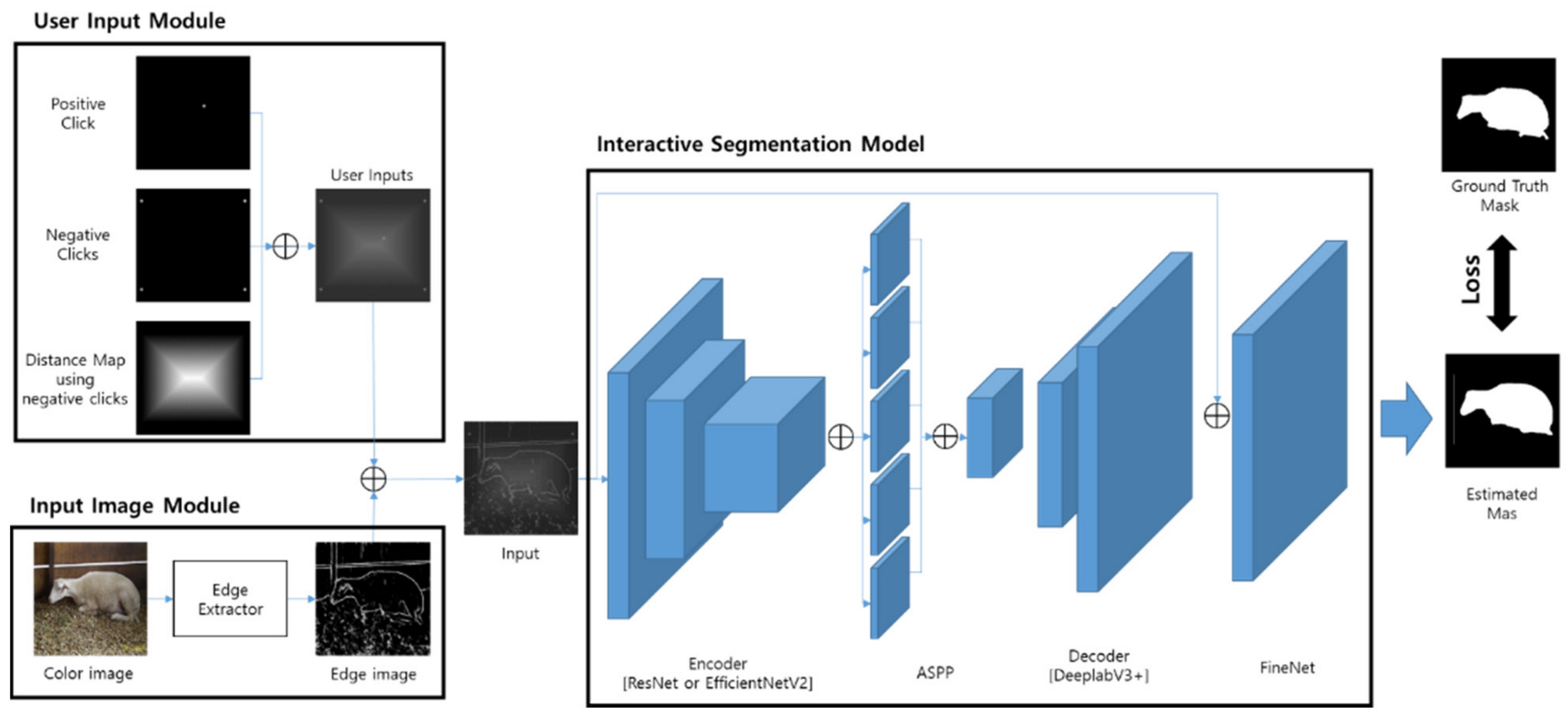
Unlike color images, edge images do not have texture information, so it is necessary to set a segmentation area for users to interact with. The interaction method of IOG is that a user sets the segmentable area by drawing a bounding box and distinguishing the object area and the non-object area by clicking. Many existing interactive segmentation models take color images as input, but because their interaction methods are different, they are excluded from the comparative evaluation, and only the IOG model was comparatively evaluated. There is no study on interactive part segmentation, and in the case of part segmentation, parts of general objects were compared with the latest model among models that can be segmented.
4.1. Implementation Detail
4.1.1. User Interaction
We generated user input based on the ground truth mask of each object in the training dataset. As for the method of generating the click position in the IOG [
3] paper, the positive points are randomly selected from the area larger than 0.8 from the normalized image after distance-transforming the ground truth mask. The feature of the distance map is generated from 4 points of the bounding box.
4.1.2. Edge Images
The edge image is generated from the edge detection model based on CNN. After the outputs of each layer are applied to 1 × 1 convolution, the normalized edge images are generated by applying the up-sampling function and the sigmoid function. The edge detection models used are RCF [
18] and DexiNed [
19]. For each edge detection model, the edge image of the first layer, the edge image of the second layer, the edge image of the third layer, and the final edge image are compared. The reason we did not experiment with the edge image above the fourth layer is there is little information about the texture inside the selected area when segmenting part. When training the proposed model, the edge image is used as the color image in advance. To use the trained proposed model, it is necessary to convert the color image to an edge image. In our PC environment, the average computation time for RCF is about 520 ms, and the average computation time for DexiNed is about 430 ms.
4.1.3. Training and Evaluation
The proposed models are first trained for 1000 epochs and further trained for up to 1000 epochs by further reducing the learning rate. The image size of the training dataset is fixed to 512 × 512 and the batch size is set to five to train the proposed models. SGD is used as the optimizer. When first training the proposed models, the learning rate is 10
−7, and in additional training, the learning rate is changed to 10
−9. When conducting the additional training, cosine annealing is applied to reduce the learning rate at every epoch. The momentum value is set to 0.9 and the weight decay is set to 10
−3. After training, the proposed models are evaluated by the accuracy of segmenting part with the PASCAL VOC Part [
7] dataset.
4.2. Comparison to the State-of-the Art Models
We evaluated the proposed models in two ways to compare them with the existing state-of-the-art models. The first experiment compared the IOU accuracy of object and part segmentation between the proposed models and the existing interactive object segmentation model with the PASCAL VOC [
7] dataset. We used the IOG [
3] model as the interactive object segmentation model for comparison. During the experiment, the proposed models and the IOG model were evaluated using the same interaction information (two clicks for the bounding box and one click for the object). The code and parameters of IOG were from
https://github.com/shiyinzhang/Inside-Outside-Guidance (accessed on 21 August 2021). The second experiment was to compare the IOU accuracy of part segmentation with the model for semantic part segmentation trained with the PASCAL VOC Part [
7] dataset and the proposed models. The interactive segmentation models use the input image and interaction information for each part or object, but the semantic part-segmentation model uses only the image as input without additional interaction information. Although the input information of the two types of models is different, a semantic part-segmentation model was added as one of the comparison models to compare the accuracy of part segmentation since, to date, there has been no study evaluating the accuracy of part segmentation with the interactive object segmentation model.





{kind=link}
{kind=link}