1. Introduction
Speech is the most engaging and acceptable form of communication among one another. Artificial intelligence (AI) systems are currently continuously targeting and working on various challenges of speech-related topics, including speech recognition, speech segmentation, speaker recognition, speech diarization, and so on. Among the different sub-domains of AI, Deep learning (DL) strategies often perform superior to other techniques.
The general implementation of DL was mainly conducted on speech recognition systems. DL methods can be trained on speech recognition without the requirement of speech-to-word alignment [
1]. Often such training strategies are defined as an end-to-end method. End-to-end methods can be easily trained from speech transcripts. Therefore, currently, numerous systems are being developed in the speech recognition domain. Speech recognition systems have exciting usages in voice commands, virtual assistants, search engines, speech-to-text processing, etc. Further, numerous automation systems on speech are currently being developed. A speech denoising mechanism removes environmental sounds from speech audio, helping to provide a clean speech [
2]. Speech synthesis systems artificially enable computers to produce speech sounds [
3], helping computers to communicate with humans. Speech emotion systems further extract human emotions from speech [
4]. Thus, computers can apprehend human feelings. Speech segmentation systems can segment a speech into word/phone levels [
5], helping to identify words and phones from speech. Further, computers can help humans in developing pronunciation [
6]. Among the various speech-based solutions, speaker recognition has fascinating usage of identifying users by hearing speech.
Speaker recognition systems are directly involved with biometric identification systems and are suitable for authenticating users remotely by hearing voices. In perspective to various biometric systems, such as facial recognition, fingerprint matching, and so on, speaker recognition also has vast usability in numerous domains, including telecom, banking, search optimization, and diarization [
7]. Nevertheless, speaker recognition systems suffer difficulties, including speech states, emotional conditions, environmental noise, health conditions, speaking styles, etc. Further, in comparison with supervised speaker recognition approaches, unsupervised and semi-supervised strategies are hardly investigated [
8]. Unsupervised and semi-supervised systems resolve the requirement of labeling a vast quantity of speech data.
DL architectures have been extensively investigated for supervised speaker recognition systems. For speaker and speech recognition models, speech spectrograms and mel-frequency cepstral coefficients (MFCC) [
9] are used as a preprocessing strategy. For such cases, convolutional neural networks (CNN) are generally implemented [
10]. However, current architectures processes raw-audio and extract speaker recognizable features. SincNet [
11] improves the feature extraction process from raw audio waves. The architecture fuses sinc functions with CNN that can extract speaker information from low and high cutoff frequencies. AM-MobileNet1D [
12] further demonstrates that 1D-CNN architectures are sufficient for identifying features from raw audio waveforms. Also, the architecture requires fewer parameters compared to SincNet. Although supervised speaker recognition architectures perform excellently in recognition tasks on a large set of speakers. However, DL strategies require a vast amount of labeled data to operate on speech-related queries.
Generating speech embeddings has been widely observed in the speaker recognition domain [
13,
14,
15]. Embedding refers to generating vectors of continuous values. Often, architectures using speaker embeddings are also termed stage-wise architectures [
7]. Currently, unsupervised speaker recognition systems implement domain adaptation policies, mostly fused with embedding vectors [
7,
16]. Domain adaptation refers to finding appropriate similarities, where a framework is trained on training data, and tested on a similar yet unseen data. Hence, domain adaptation strategies may perform poorly when the variation of training and the unseen dataset is massive. Further, domain adaptation strategies may also produce less accuracy if trained on an inadequate dataset with minimal variation [
15]. Yet, efforts have been made to reduce the interpretation of unseen data over training data, by adding adversarial training [
17], improving training policies [
18], covariance adaptation policies [
19], etc. Although these policies improve the robustness, most strategies are still prone to various speech diversions, such as language, speech pattern, age, emotion, and so on.
Currently, in the aspect of DL, embeddings can be generated using triplet [
20] and pairwise loss [
21] techniques. In triplet loss architecture, three parallel inputs flow through the network: anchor, negative, and positive. The positive input contains a similar class w.r.t. to the anchor, whereas the negative input contains a different class. Comparatively, in pairwise architecture, a pair of information flows either belonging to a single or different class. Triplet architectures have been perceived in speaker feature extraction in supervised practice [
22].
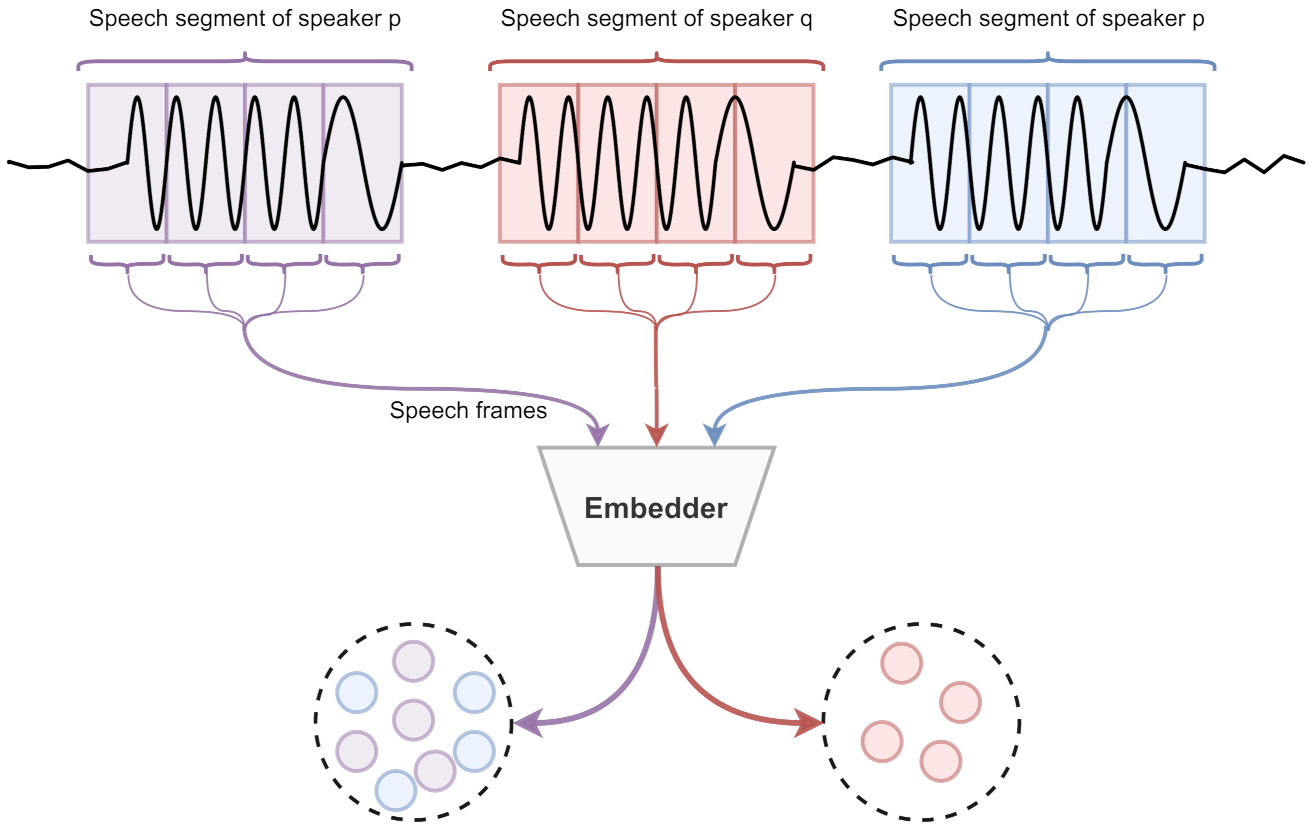
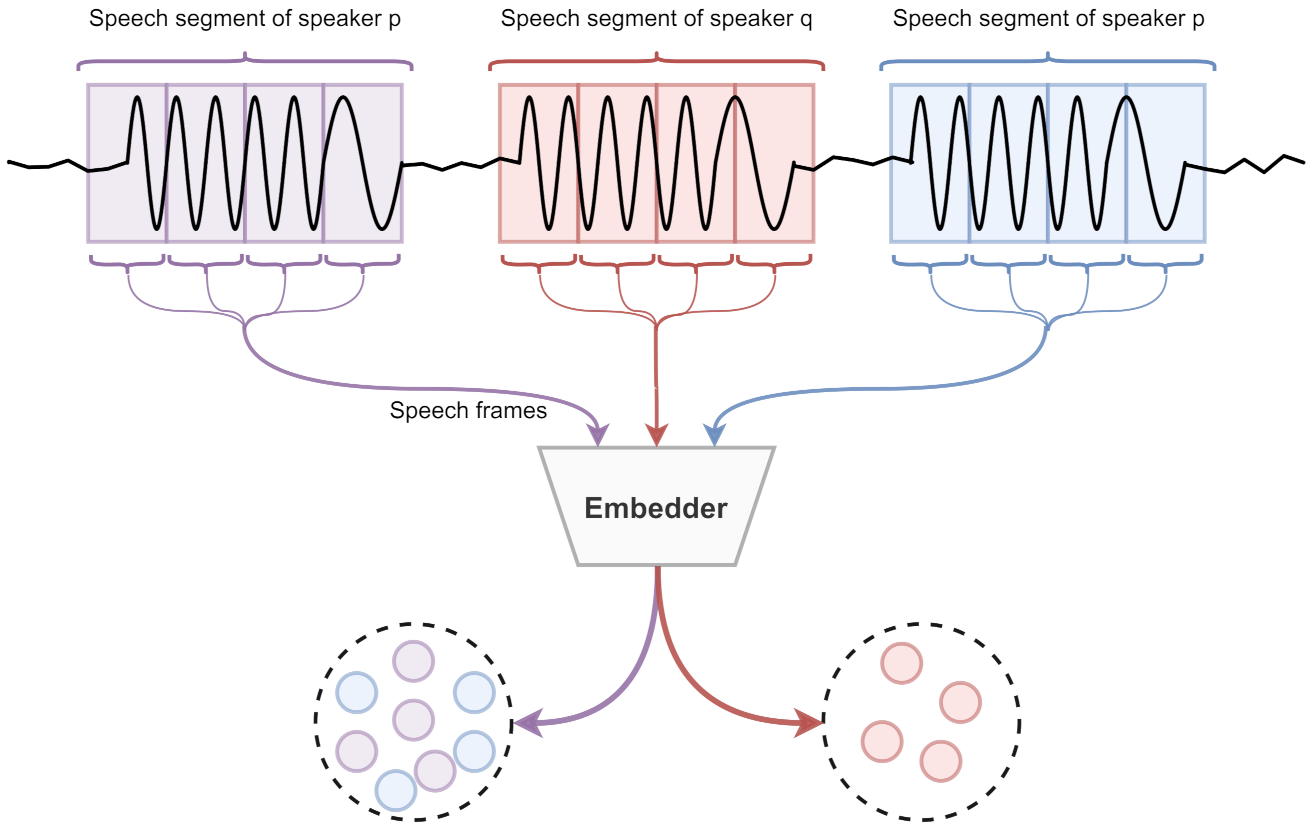
This paper introduces an unsupervised strategy of generating speaker embedding directly from the unseen data. Hence, the method does not depend on domain adaptation policies and can adapt diverse features from most speech data. Moreover, we insist on converting DL architecture’s training process to both semi-supervised and unsupervised manners. Yet, to do so, the system requires segmented audio streams (length of 1 s) and needs to guarantee that a segment contains only one person’s speech. The audio segment is further windowed into smaller speech frames (0.2 s) for training the DL architecture. The audio segments are assigned pseudo labels, which are further reconstructed by DL architecture.
Figure 1 illustrates the construction of the training procedure.
The overall contributions of the paper are the following:
We introduce a strategy of generating speaker-dependent embeddings, named u-vector. The training process is domain-independent and directly learns from the unlabeled data.
We use pairwise constraints and non-generative augmentations to train AutoEmbedder architecture.
We explore the possibilities of our strategy in both unsupervised and semi-supervised training criteria.
We evaluate the proposed policy with two inter-cluster based strategies: triplet and pairwise architectures.
We finally conclude that a DL architecture can discriminate speakers from pseudo labels based on feature similarity.
We organize the paper as follows,
Section 2 reviews the related works conducted in speaker recognition domain.
Section 3 clarifies the construction of the training procedure, along with the challenges, and modifications.
Section 4 illustrates the experimental setup, datasets and the analysis of the architecture’s performance. In
Section 5, we sketch the proposed method’s future initiatives along with usabilities. Finally,
Section 6 concludes the paper.
2. Related Work
Speaker recognition has been a topic of interest over the past decades, and various systems have been proposed to solve the challenge. In the domain of speaker recognition, numerous techniques have been observed since late 2000. Among these, embedding architectures have been widely explored to extract the diversity of speech frames. Embedding models are often considered feature extractors, which can generate a speech-print (related to finger-print) of an individual. Hence, every individual’s speech will remain closer in the embedding space, causing to create a cluster of embeddings from speech frames.
Gaussian mixture model (GMM) supervector [
23] (stacking mean vectors from GMM), and Joint factor analysis (JFA) [
24] have been popularly integrated into the speaker recognition task. JFA merges the speaker-dependent and channel-dependent supervector and generates a new supervector based on the dependency. GMM and JFA were significantly accepted as feature extractors and implemented in various speaker recognition strategies. Later on, inspired by JFA, identity vector (i-vector) [
25] was introduced. I-vector contributes to changing the channel-dependent supervectors and integrates speaker information within the supervectors. Hence, i-vector became more sensitive to speech variations and greatly accepted by the researchers. In most cases of JFA and i-vector, MFCC is widely implemented. MFCC is a linear cosine transform of a log power spectrum used to extract a sound’s information. However, a lower MFCC with a lower cepstral coefficient returns only sound information, whereas the higher value of the coefficient represents speaker information as well [
26]. Further, probabilistic linear discriminant analysis (PLDA) [
27] is mostly used for implementing speaker verification and identification systems using i-vectors [
13].
The present improvement of DL architectures has led to revisiting the speech embedding representation neural architecture perspective. Deep vector (d-vector) [
14] is a mutated implementation of the speech frame embeddings using deep neural networks (DNN). The d-vector depends on the automated feature extraction process of DNN. The model’s training process is supervised, and in the basic implementation of the d-vector, it is explored as a text-dependent system. After the training procedure, the softmax layer is left out, and the embeddings are extracted from the last hidden layer. Although the d-vector is based on DNN, further studies have been made using CNN architectures [
28]. In the modified architecture, speech is converted into MEL coefficients, which are normalized and supplied to CNN. Moreover, extensive studies have been made to improve the basic d-vector to a text-independent unsupervised vector generation using domain adaptation [
29]. The mechanism is split into two parts in the upgraded version: a DNN that extracts embeddings and a separately trained classifier that classifies speakers. These studies’ limitation is that most of them require massive labelled data in the training procedure. Also, the embedding performance in the case of unseen speakers dramatically depends on the training data.
As DNN architectures are dependent on the amount of training data, an improved strategy of the d-vector is proposed, named x-vector [
15]. X-vectors are a modified version of d-vector, which depends on basic sound augmentation techniques, noise and reverberation. Further, the implementation highly motivates data augmentation usage and presents a decent accuracy improvement over i-vectors. The default x-vector is implemented based on the improved text-independent version of the d-vector [
29] by properly utilizing data augmentation.
The present state of the art speech embedding systems tends to be unsupervised. However, the concept of unsupervision still depends on a large set of training data. Both d-vector and x-vectors directly rely on the domain adaptation [
30] policy of neural network architectures. Hence, the performance of these architectures on unseen data massively depends on the volume and diversity of the training dataset. The domain adaptation capability of neural network architectures is further increased by using synthetic datasets [
31]. However, the performance is still dependent on previously learned features, and performance might lack due to data inefficiency and domain variation between training and testing data.
Therefore, we introduce an approach that is independent of domain adaptation of neural network architectures. Instead, the proposed method tends to utilize the automated feature extraction of neural network.
3. Methodology
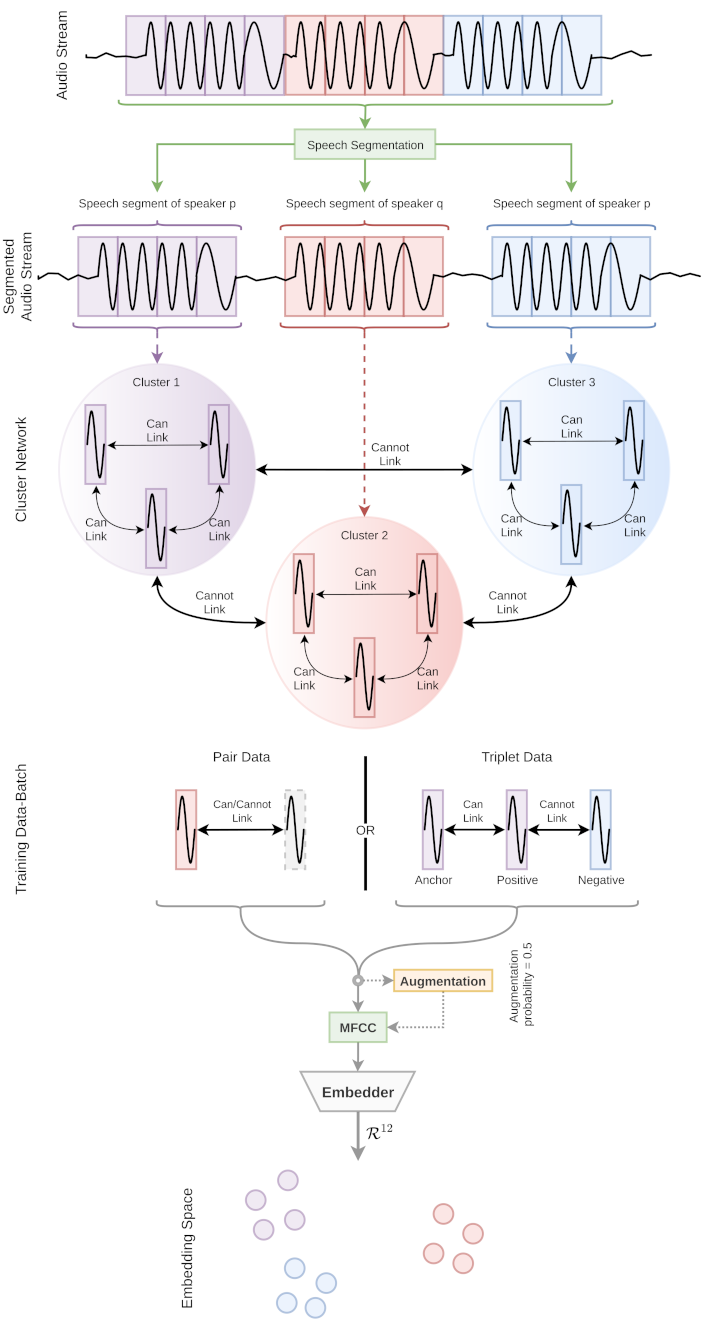
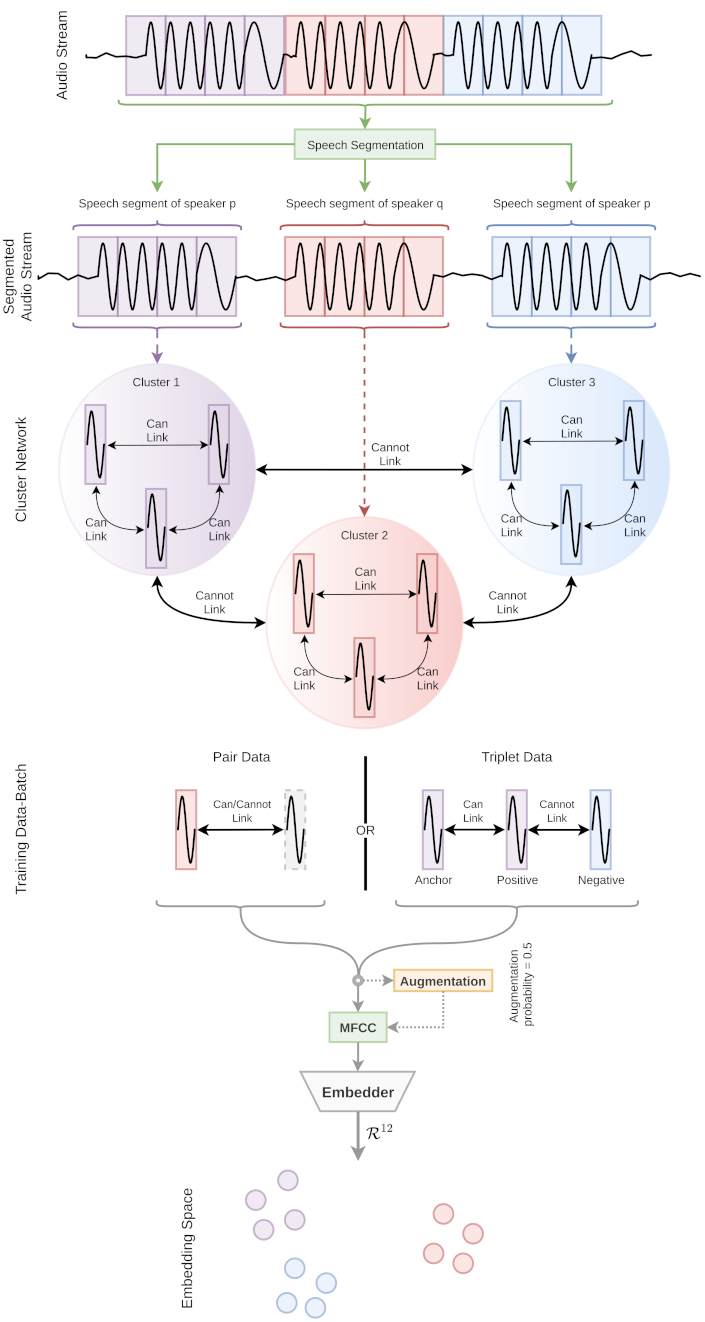
This paper’s clusterable speaker embedding generation is based on a particular assumption: a speaker speaks continuously for a specific time. Hence, if segmentation methods are used or a small speech segment is extracted based on voice segmentation techniques, most speech segments will contain an individual’s speech. However, some segments might be impure, i.e., a single segment may have multiple individuals’ speech. Nevertheless, we argue that the ratio of impurity would be small enough for most general speech conversations. Hence, such a strategy is investigated with the most common neural network pipelines; a siamese network [
32]. AutoEmbedder framework [
21] is used as a DL architecture to extract speaker embeddings.
Figure 2 illustrates the basic workflow of producing u-vectors.
In this section, the methodology of generating u-vector is introduced. The section is segmented as follows: the problem formulation and assumptions are defined in
Section 3.1. The proposed work includes speech segments discussed in
Section 3.2. Further, speech segments are broken into small speech frames for construction pairwise constraint, which is addressed in
Section 3.3. Uncertainties due to the pseudo-labels of pairwise constraints are discussed in
Section 3.4. Challenges of deciding segmentation length are addressed in
Section 3.5. Finally, the DL framework AutoEmbedder [
21], which is used to explore the actual cluster linkage, is theorized in
Section 3.6.
3.1. Problem Formulation and Assumptions
The proposed method tends to solve the speaker recognition system in an unsupervised manner based on some constraints.
Table 1 summarizes the paper’s mathematical notations to facilitate the readers. To comprehend the problem statement, let
be a database of speech segment, where
be a short-length audio segment containing speech of an individual. Also, let
be a smaller window/frame of the audio segment, where
. From a particular speech segment,
,
number of non-overlapping speech frames are generated. As it is stated that a speech segment belongs to a single individual, the smaller speech frames also belong to that individual. From this intuition, we construct pairwise constraints between audio frames. We define two speech frames belong to the same cluster if they belong to the same audio segment. On the contrary, we consider two speech frames that belong to different clusters if they belong to different audio segments. Based on the pairwise relations, a set of cluster
can be generated. Where a single cluster (
) belongs to a specific speech segment. Considering most speech segments will belong to a single speaker, we can assume that most cluster
would contain a single individual’s data. However, as multiple speech segments can belong to a single individual, multiple clusters may contain a single individual’s data. Hence, the challenge is to find such optimal cluster relationships such that no two clusters may contain speech of a single individual. The training strategy has two possibilities, such as:
In the case of an unlabeled dataset, let us consider that each audio file contains a single individual’s speech. For a set of audio files with an unknown number of speakers, our approach is suitable to produce clusterable embeddings based on speakers. This constraint is similar to semi-supervised learning, as some of the pairwise constraints are known [
33].
Let us consider a dataset containing multiple speakers’ conversations, where a single audio stream may include various speakers. In such a case, no pairwise constraints are known, and an unsupervised strategy is required. Hence, we produce hypothetical pairwise constraints based on audio segmentation processes such as VAD, word segmentation [
5], etc., and construct pairwise constraints. However, in such a case, the embedding system’s accuracy depends on the purity of the audio segmentation process.
For both of the problem, DL architecture is used to aggregate multiple clusters such that the resulting cluster contains all of the embeddings of a single individual. We imply that if a DL function can properly extract speech features from audio frames, it can obtain optimal reasoning of speech frames being similar and dissimilar. Further, an optimally trained DL framework can successfully re-cluster the data based on the feature similarity rather than the number of hypothetical clusters. We extend our investigation towards finding such DL training strategy.
Since the approach deals with unsupervisely generating speaker embedding vectors from speech data (without domain adaptation), the output embedding vectors are named as unsupervised vectors (u-vectors). Formally u-vector is defined as follows,
Definition 1. Unsupervised vectors (u-vectors) refer to a set of DNN generated speech embeddings, which are clusterable based on speakers, trained from unlabeled speech segments.
In the formal definition, by DNN, any specific implementation of substantially deep neural networks are indicated, such as convolutional, feedforward, recurrent, etc.
3.2. Speech Segments
To generate the pairwise constraints, it is considered that a speech segment belongs to an individual. Moreover, if it is possible to extract accurate pairwise constraints, a DL framework can be trained using those constraints. To generate such pairwise constraints, speech segmentation procedures are required.
Speech can be easily segmented using various techniques. Methods such as VAD [
34] and word segmentation [
35] can be indeed adopted to define such speech segments, containing the voice of a single individual. It is also feasible to assume that a single individual mostly speaks more than one word in a conversation. Hence, it is also possible to queue multiple speech segments and hypothesize that they come from a single individual. However, increasing the queue or size of a speech segment also increases the probability of impurity of a speech segment (discussed in
Section 3.5). By impurity in a speech segment, it is referred that a speech segment contains more than one speaker. Impure data can often trick the DL frameworks from finding actual relationships among clusters. Hence, to minimize the impurity risk, we study speech segments with a length of one second. After the successful extraction of speech segments, the pairwise constraints are to be constructed. Although the overall framework is dependent on proper speech segmentation techniques, we avoid implementing such segmentation methods. Instead, we provide a detailed evaluation of embedding accuracy based on various levels of cluster impurities.
3.3. Pairwise Constraints
The DL framework is trained based on pairwise constraints. Pairwise constraint contains a pairwise relationship between a pair of inputs. By considering
and
as two random speech frames, two circumstances may occur: (a) speech frames may belong to the same audio segment
or (b) they may belong to different audio segments. In the current state of the problem, as the speech labels’ ground truth is unknown for every speech segment, we consider each segment belonging to different individuals. Hence, the number of unique pseudo labels is equal to
. Mathematically,
being a set of clusters,
being a particular cluster of similar nodes, and
being a specific speech segment,
The DL framework is trained based on the defined cluster constraints. To properly introduce the inter-cluster and intra-cluster relation to a DL framework, we define a gound regression function based on pairwise criteria derived in Equatoin (
1). The function is defined as,
In general, the
outputs the distance constraints that each embedding (generated from speech frames) holds. The function infers that an embedding pair must be at a close distance if they belong to the same cluster or at a distance of
otherwise. However, embedding pairs belonging to different clusters may be at a distance greater than
, which is established in the AutoEmbedder architecture (Equatoin (
4)). We use the pairwise constraints to train a DL architecture. Further, we revisit the data-clusters’ uncertainty and segmenting impurities and explore why a DL framework may be necessary in such a case.
3.4. Uncertainties in Pairwise Constraints
The cluster assignments are mostly uncertain based on two major concerns: (a) the segmented audio may be impure, (b) the ground-truth of cluster assignments are unknown. Therefore, in most cases, the number of ground-label (defined as ) is theoretically not equal to the number of clusters, i.e., and , where . Moreover, due to such impurity and uncertainty of ground-labels, the subsequent flaws in the training dataset (based on pairwise properties) are frequently observed,
Impurity in must-link constraint: The dataset’s core concept is to assume that an audio segment contains only one individual’s speech. Generally, a segmentation system may inaccurately identify speech segments and hold multiple individuals’ speech in a single audio segment. However, if we consider short length audio segments, the probability of speaker fusion rapidly decreases.
Error in cannot-link constraint: Let, and , where . The cluster assignments are considered based on the number of audio segments. Hence, for most datasets, the number of speech segments is greater than the actual number of speakers, . Therefore, considering the ground-truth, the assumption may be wrong, and data pair and may belong to the same cluster considering the ground truth.
If we consider a cluster network with no impurity, then the task of DL is to eliminate the errors in cannot link constraints based on the feature relationship. Hence, if it is possible to prioritize the speech features to a DL framework, it can allegedly aggregate appropriate cluster from erroneous cannot-link clusters. Therefore, training the DL architecture reduces errors in cannot-link constraints. However, reducing the impurity of the input data’s must-link constraints considerably depends on the length of speech segments and segmentation policies.
3.5. Segment Length Analysis
The time-domain length of the speech segments (defined by ) operates a vital role in the overall performance of the training process. Each segment is further windowed into smaller speech frames. Hence, the segment length must be divisible by the length of fixed-size speech frames (defined by ). Various architectures consider overlapped frames while windowing speech signals. However, we avoid such measures, as such overlaps result in mixing similar speech patterns in multiple speech frames.
To illustrate the trade-off of selecting an optimal length of speech segment , let us consider being the mean and the standard deviation (std) of the length of speech segmentations for a given dataset (or a buffer of audio stream). Therefore, statistically, is the optimal minimal length for which we can assume that most segments strictly contains speech of a single individual. However, if the minimum segment length is considered, the number of frames per segment would also reduce.
Reducing the number of frames per segment due to a shorter segment would deliver less inter-cluster relations for each segment. The reduction of inter-cluster association would also cause the DL framework struggle finding feature relation between speech frames. Further, increasing the size of speech segments may also result in impure components, if .
To explore the reason of impurity, let us consider an audio stream contains a mean time
with standard deviation of
, after which, the speaker exchanges. In such condition, selecting the length of segment too high may result in being
. However, statistically, in most general conversations, the length of minimal speech segmentation is mostly less than the speaker exchange time,
. Therefore, if we can select such
, for which,
, the rate of impurity would be zero. Hence, selecting
would reduce the rate of impurity. For the experimental datasets, the
is equal to one (illustrated in
Table 2). Hence, we experiment with one-second speech segment. Further, we investigate a pairwise framework in which we try to trick DL architecture into converging towards the ground cluster relationship.
3.6. AutoEmbedder Architecture
As a DL architecture, we use a pairwise constraint-based AutoEmbedder framework to re-cluster speech data. However, we introduce further modifications to the network’s general training process to strengthen the learning progress. In general, the AutoEmbedder architecture is trained based on the pairwise constraints defined by function
. The architecture follows siamese network constraints that can be presented as,
The
function used in Equatoin (
3) is a thresholded ReLU function, such that,
In Equatoin (
3), the
represents a siamese network function, that receives two inputs. The framework contains a single shared DNN network
that map higher dimensional input to a lower dimension clusterable embeddings. The Euclidean distance of the embedding pairs is calculated and passed through the thresholded ReLU activation function derived in Equatoin (
4). The threshold value is a cluster margin of
. Due to the threshold, the siamese architecture always generates outputs in the range
. The L2 loss function is used to train the general AutoEmbedder architecture. The AutoEmbedder architecture is trained using an equal number of must-link and cannot link constraints for each data batch. However, in a triplet architecture, the problem is automatically solved, as each triplet contains a fusion of cannot link (negative) and can-link (positive) data.
3.7. Augmenting Training Data
Both types of cluster relationships (can-link and cannot-link) may contain faulty assumptions and pseudo labels considering the ground truth. Hence, a basic augmentation scheme is used to trick the DL network from overfitting erroneous cluster relationships. Although various augmentation techniques are available, we adhere to mixing noise with speech data for augmentation. For noise augmentation, we implement a basic formula that is,
Here,
is a function that produces augmented speech data, which is inputted as
. The
is a threshold used to define the ratio of mixing
with speech data
. Augmenting noise with speech frames results in less-confusing the AutoEmbedder network in case of erroneous data pairs. Fusing noise may facilitate the architecture by ignoring faulty data pairs due to different noise situations. Moreover, augmenting data also results in data variation, and the network extracts more beneficial features from speech data. Algorithm 1 presents pseudocode of the pairwise training process.
| Algorithm 1 AutoEmbedder training for speaker recognition. |
| Input: Dataset D containing speech frames, DL model with initial weights , |
Distance hyperparameter , Training epochs
|
| Initialize siamese network, |
![Applsci 11 10079 i001]() |
4. Experiments and Evaluations
In this section, the proposed scheme is experimented based on the impurity of speech segmentation. As the architecture’s target is to produce clusterable embedding, we use k-means to measure the purity of the clusters generated by the embedding system. Further, three popular metrics, Accuracy (ACC), normalized mutual information (NMI), and adjusted rand index (ARI), are used to measure clustering effectiveness. The metrics are calculated as demonstrated in [
21], and are widely implemented to refer to the purity of clustering [
33,
39].
4.1. Experimental Setup
The datasets were segmented using a threshold of 16 decibels, implemented as a VAD. The audio streams have been processed with a sample rate of 16,000 Hz. For audio to spectrogram conversion, the parameters are set as described, size of fast-fourier transform: 191, window-size: 128, stride: 34, mel-scales: 100. Speech spectrograms are used as inputs to train the DL architectures.
4.2. Datasets
For experimentation, three speech datasets have been used. TIMIT [
36] and LibriSpeech [
37] are popular speech datasets for English language. Moreover, we use Bengali Automated Speech Recognition Dataset [
38] to show the diversity of our approach for additional languages. Among the three datasets, TIMIT and LirbriSpeech datasets contain studio-grade audio speech. Bengali ASR dataset is crowdsourced hence, contains a diverse sound and noise variation.
Table 2 illustrates some basic statistics of each dataset. Throughout the experiment, we abbreviate LibriSpeech and Bengali ASR dataset as LIBRI and ASR, respectively. As the training procedure augments noise with the speech frames, we use scalable noisy speech dataset [
40]. The dataset contains diverse environmental noises, which helps the architectures to explore and relate speech features.
4.3. Result Analysis
Two methods are implemented, AutoEmbedder (pairwise architecture) and a triplet architecture, to analyze the speech embeddings based on the proposed strategy. However, apart from these two strategies, the currently famous speech vector methods do not hold to the training properties considered in the paper. They mostly follow a supervised learning or domain adaption strategy. Hence, they are disregarded in this experiment.
DenseNet121 [
41], is used as a baseline architecture for both of the DL frameworks. Further, both models are connected with a dense layer consisting of 12 nodes. Therefore, both pairwise and triplet networks produce 12 dimension embedding vectors. L2-normalization is added on the output layer of the triplet network, as it is suggested that it increases the accuracy of the framework [
42]. For AutoEmbedder architecture, the default l2-loss is implemented, whereas the triplet architecture is trained using semi-hard triplet loss. The training pipeline is illustrated in
Figure 3.
The evaluation process guarantees that both architectures are trained using the same dataset/data-subset. As the training process is unsupervised, the architectures receive the same data for the training and testing process. However, for the training process, the labels are unknown and generated based on the paper’s assumptions. We refer to such a dataset as a training dataset. By ground dataset, we refer to the same dataset that further considers the ground truth values. For training both frameworks, we used a batch size of 128. The training is conducted using Adam [
43] optimizer with a learning rate of
. The learning rate and batch size were determined using a grid search. Although batch size 64 and 128 result in better evaluation, batch size 128 was considered due to faster computation.
The training phase’s data processing includes heavy computational complexity, including online noise augmentation and spectrogram conversion. Each dataset is randomly augmented with a threshold range of for the augmentation process. Further, computing ACC, NMI, and ARI metrics require quadratic time complexity. Hence, we limit the number of speakers to 150. Instead of training on the overall dataset, we train on a sub-set of data, where each speaker contains a speech of 10 s. For testing the ground truth data, a random selection of 2-s speech is selected for each speaker. To inquire the architectures properly, we scramble the training dataset’s pseudo labels, that produces a can-link impurity in the dataset labels. Hence, we use the impurity ratio as a training data situation to illustrate the rate of impure cluster assignments on the training data pseudo-labels. The models were kept training until the performance on ground truth labels did not improve within the previous 1500 epochs.
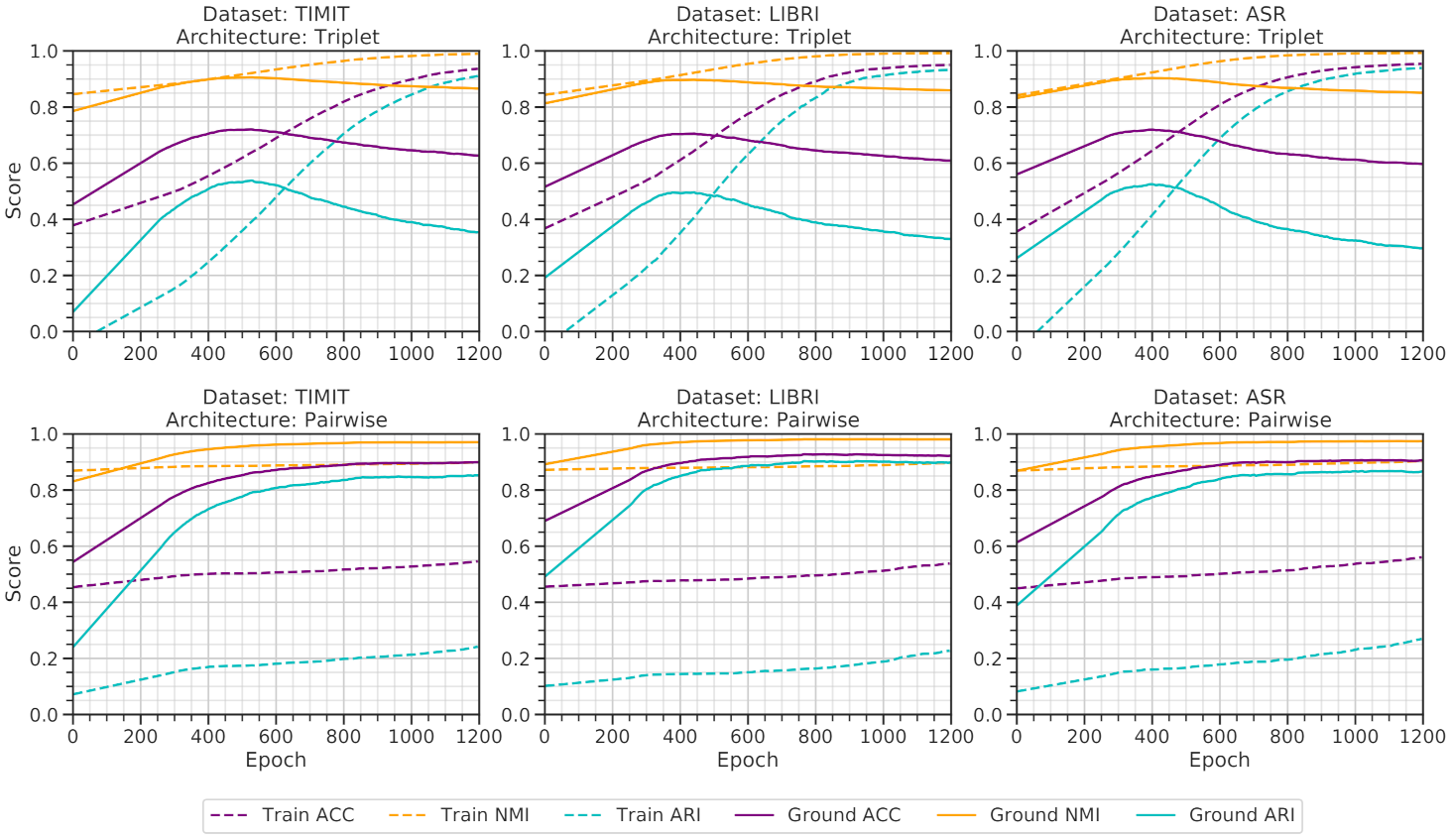
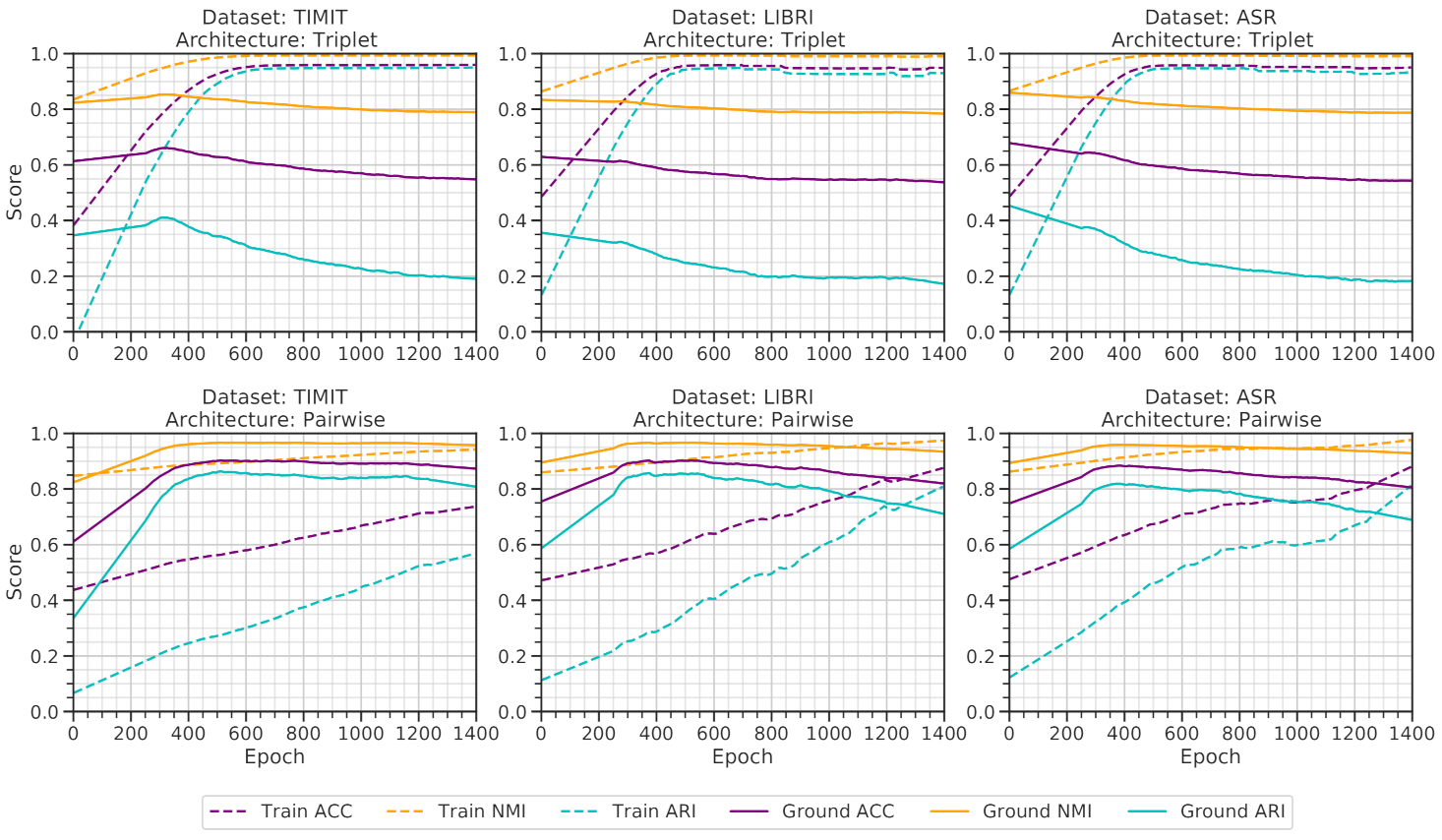
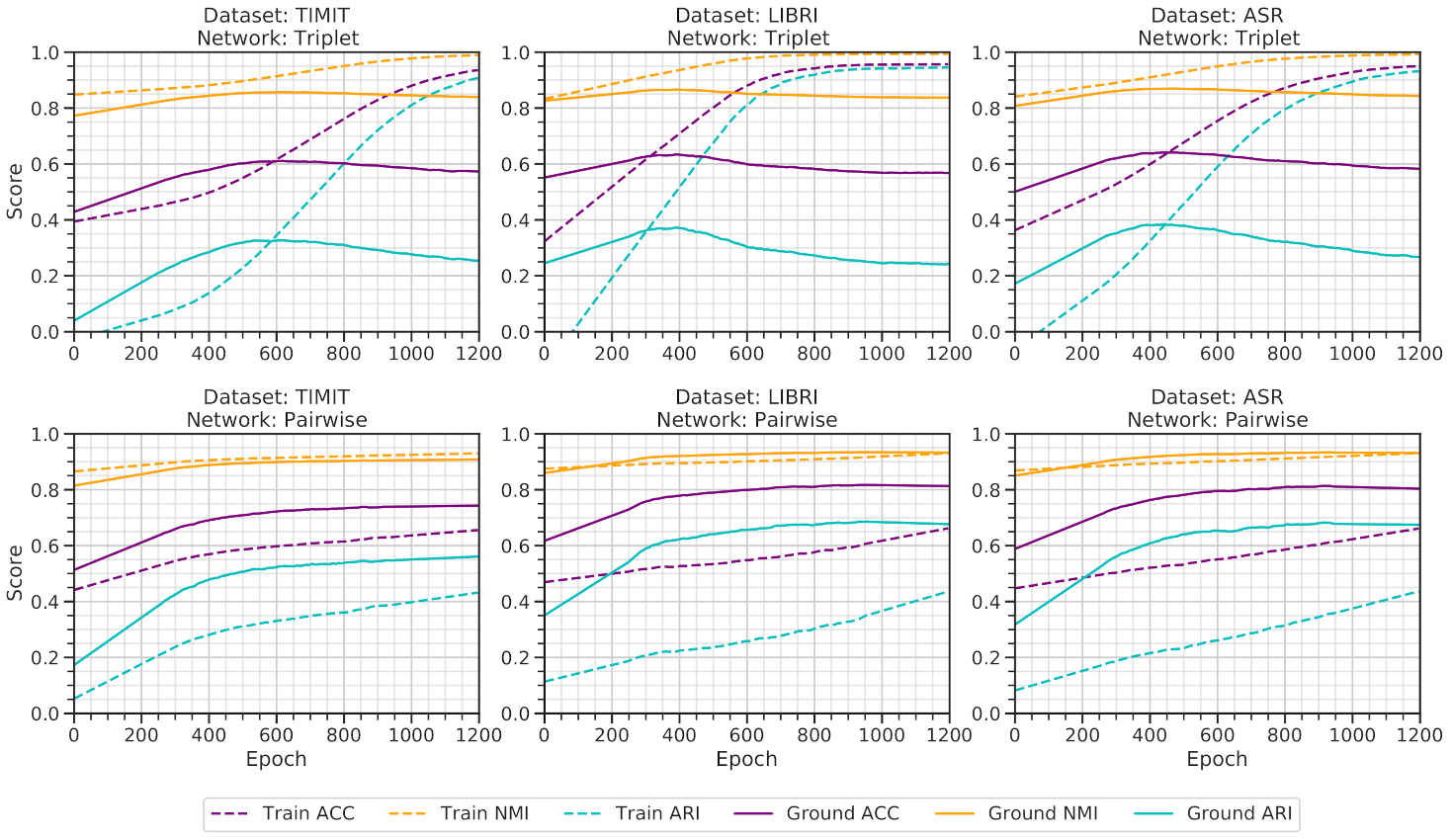
Figure 4 illustrates a benchmark of the triplet and pairwise architectures while training on three different datasets, with speakers = 25 and impurity = 0. The triplet architectures smoothly learn from the training data and greatly overfits on the augmented training data. The ground dataset benchmark is also as expected since the triplet architectures’ correctness first increases and gradually decreases due to overfitting. Hence, from the visualization, it can be acknowledged that the triplet network only memorizes the speech features concerning the pseudo labels assigned to them.
On the contrary, the pairwise architecture generates a satisfactory performance, with some irregularities. In general, deep learning architectures produce higher accuracy on the training dataset than validation dataset. However, in such a case, the ground dataset’s performance is mostly more elevated than the training dataset. Yet, the performance on the ground datasets generally decreases after 400 epochs. As the number of speakers is small, the architecture easily gets overfitted on the training dataset. Further increasing the number of speakers to 50 reduces the overfitting on training data, as illustrated in
Figure 5. The triplet architecture still overfits on the training data’s pseudo label, whereas, the pairwise architecture gives a balanced performance on the ground dataset.
Increasing the impurity of the inter-connection of the training data reduces the performance of the architectures.
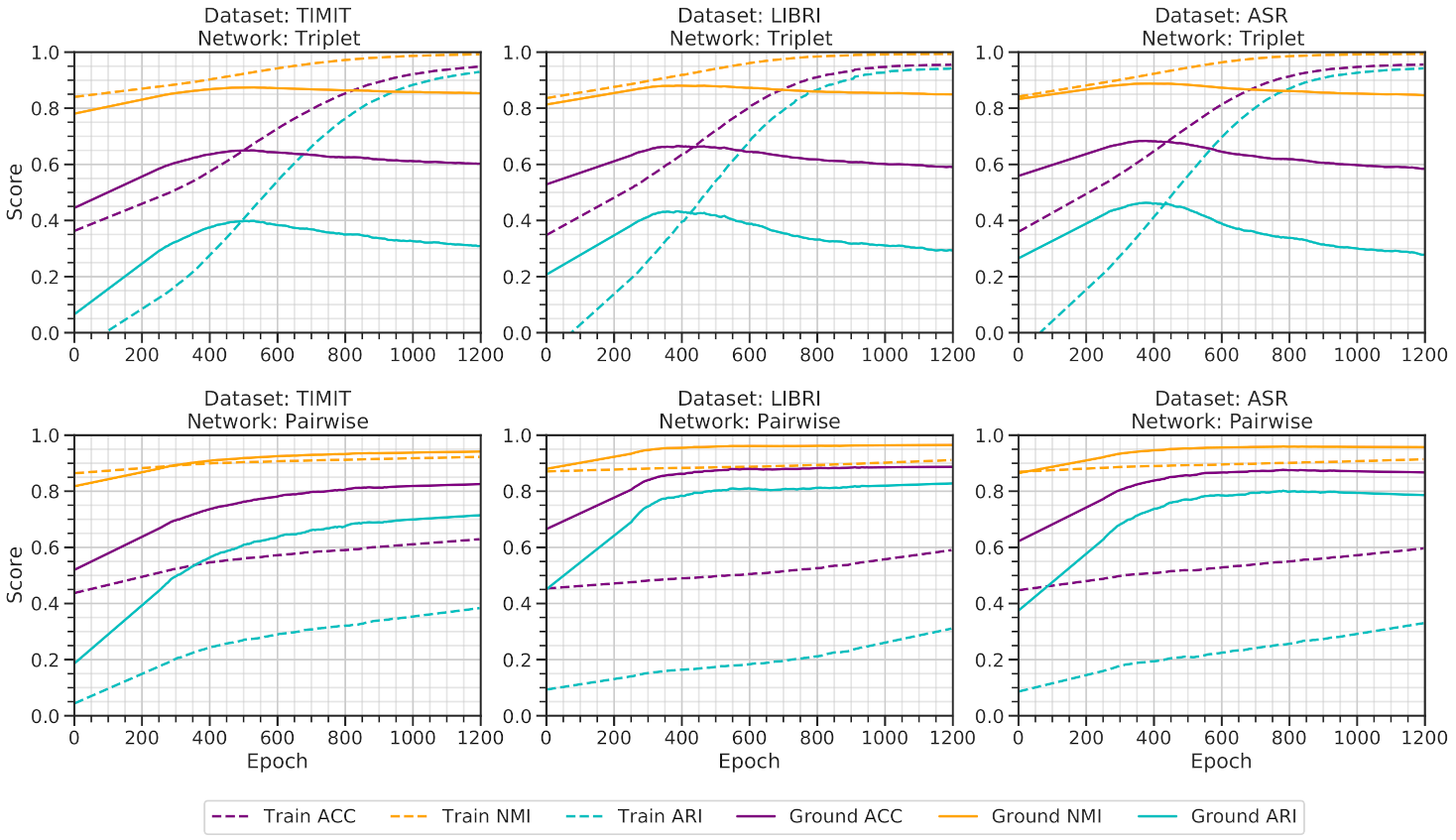
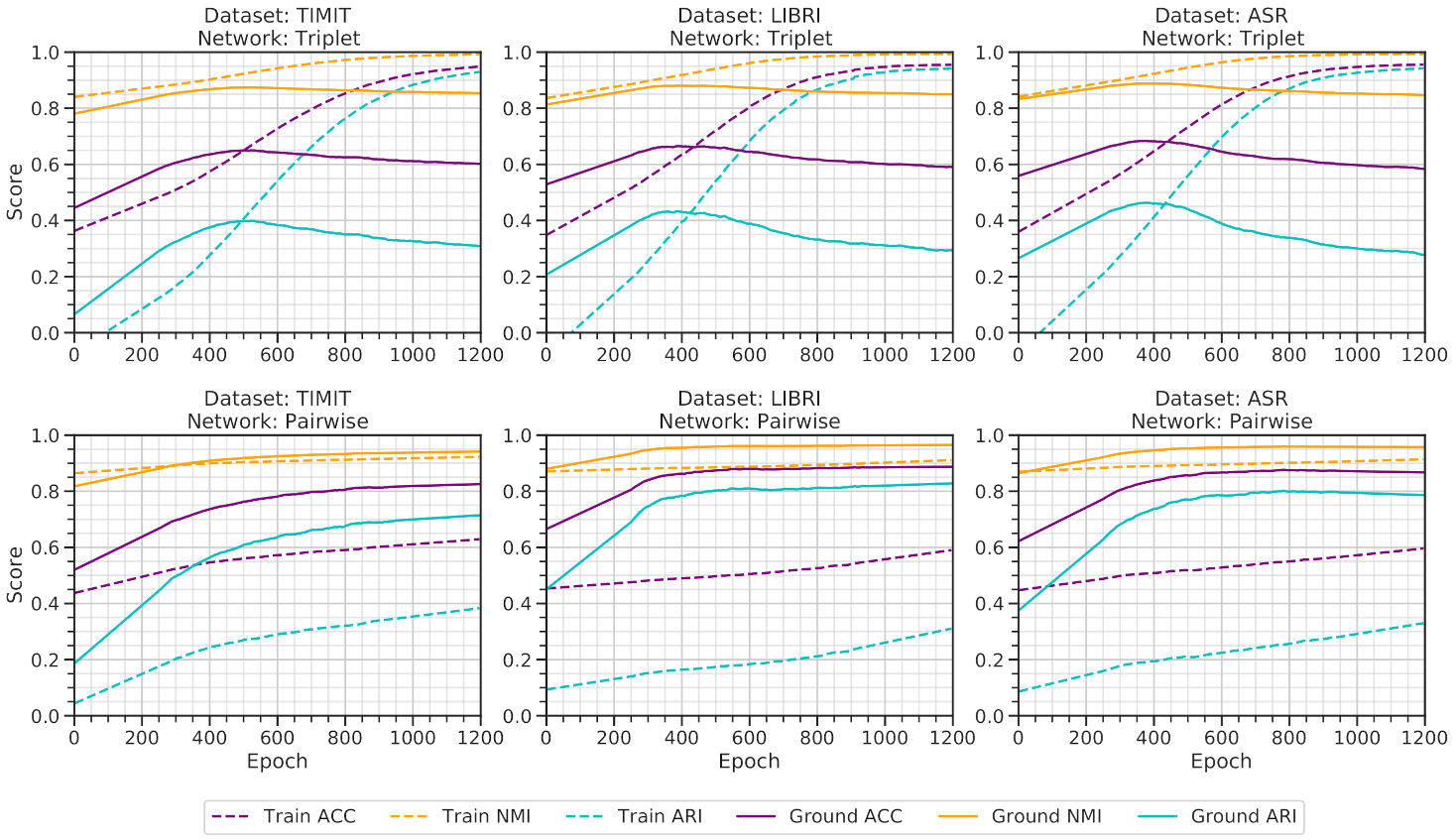
Figure 6 and
Figure 7 illustrates benchmarks conducted with impurity = 0.05 and impurity = 0.1 while considering speakers = 50. The triplet architecture still overfits on the training architecture. In contrast, pairwise architecture slowly memorizes the training dataset. Yet, it holds a marginal exactness on the ground data before overfitting on the training data.
Triplet architecture, trained over semi-hard triplet loss strictly targets the positive points (based on the anchor) and minimizes the distance between the anchor and positive data. For negative points, the loss function also strictly distance the embeddings. As the loss function heavily maintains the criteria mentioned above, the architecture gets overfitted on the hypothetical constrains disregarding the actual feature-dependent relations.
In contrast, AutoEmbedder architecture learns to extract features rather than being overfitted in the training data. The reasoning lies in the training strategy of the network. The l2-loss does not strictly consider learning the hypothetical constraints and learns for each batch of data aggregately. As the architecture is not strictly supervised using the loss function, it obtains the feature similarity of audio data. Therefore the architecture re-clusters the data on hyperspace based on feature similarity.
We further investigate with AutoEmbedder based pairwise architecture with various speaker and impurity condition.
Table 3,
Table 4 and
Table 5 illustrates the metrics on training and ground dataset for TIMIT, LIBRI and, ASR datasets, respectively. The table illustrates a detailed overview of the performance variation based on the number of speakers and impurity in the training dataset. The pairwise architecture maintains a marginal performance with impurity = 0 on every dataset. However, increasing the number of speakers results in reducing the performance of the architecture. On the contrary, increasing the impurity of the speech segment further reduces the performance of the architecture. A small fluctuation is observed for LIBRI and ASR dataset while the number of speakers is kept on 25 and 50. Increasing the number of speakers from 25 to 50 causes an increase in accuracy, which is inconsistent.
The architecture requires a sufficient number of speech variations from users to explore the proper feature relationship between speech frames. Limiting the number of speakers to 25 caused the interpretation of speech to be reduced. Hence, the architecture struggles to find better speech relations, and lessened performance is observed. Increasing the number of speakers to 50 balances the speech variations in the training data and causes an increase in accuracy.
5. Discussion
The pairwise architecture with training strategy results in a good performance in the speaker recognition process. However, throughout the investigation, the architecture tends to have some issues that have to be considered. Firstly, training the architecture with lesser speech variation causes overfitting, observed while keeping
. Secondly, as the augmentation procedure fuses noises, speech data with excessive noises may not generate a good result. The degradation of performance due to excessive noise is a common concern, and by using a denoising mechanism, the situation can be handled [
2]. Further, as the system is fully segmentation dependent, the target lies in developing an optimal audio segmentation procedure. Resolving these challenges would benefit the architecture for a wide range of speaker recognition and evaluation usage.
Apart from the limitations, the u-vector strategy requires no pre-training on large speaker datasets, which is often observed in i-vector, d-vector, and x-vector [
7]. Further, the u-vector strategy requires comparatively less per-speaker data than the other embedding strategies mentioned above. In the case of augmentations, u-vector architecture does not require any labeled data, which is primarily observed in generative speaker recognition architectures [
44]. In an overall perspective, the u-vector mitigates the requirement of labeled data to a minimum.
Aside from implementing u-vectors in an unsupervised and semi-supervised manner, the strategy can be implemented in self-supervised learning. Although self-supervised learning has its various forms based on the domain, u-vector aligns with contrastive self-supervised learning strategies [
45]. In general, self-supervised learning learns better model representation (weights of a model) from unlabeled data. Further, the trained model is used to train on a small quantity of labeled data. U-vectors can be used to initialize model representations in the first stage of self-supervised learning. Further, a classification method/layer can be equipped with the model for training the model on labeled data.
Finally, industrial systems often can not label every data. However, if a large labeled dataset is required, then building a model can become costly. Therefore, unsupervised, semi/self-supervised learning in speaker recognition systems is expected to produce low-cost and attainable systems.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}