
SLA-DQTS: SLA Constrained Adaptive Online Task Scheduling Based on DDQN in Cloud Computing


Abstract
:1. Introduction
- •
- With the widespread application of DRL in task scheduling, we propose an intelligent task scheduling framework using DDQN in cloud computing online task scheduling to optimize the allocation decision of online tasks to virtual machines (VM). In the makespan and cost optimization problems under the constraints of the SLA, the corresponding scheduling strategy is learned according to the load situation.
- •
- Considering the dynamics of the cloud environment, we design a state-action space and reward function. As the environment load changes, the reward function switches the main optimization goal. Using the Gaussian distribution of related features as the state space, the input dimension of the model remains unchanged under different numbers of VMs. The reward function allows the model to adapt to changes in the task load. The fixed-dimensional state space makes it unnecessary to change the model with the number of VMs.
2. Related Work
3. Proposed Online Task Scheduling Model
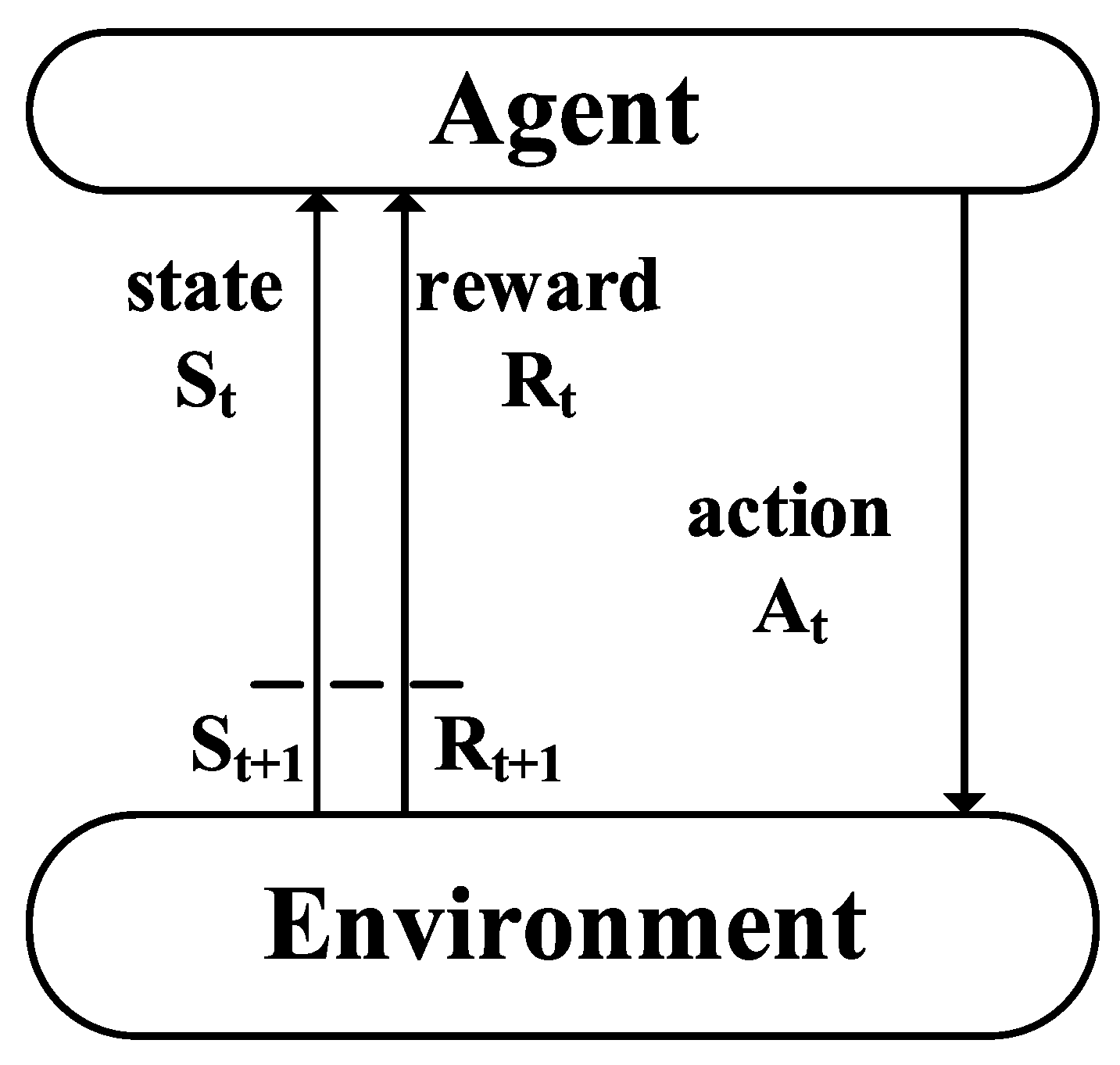
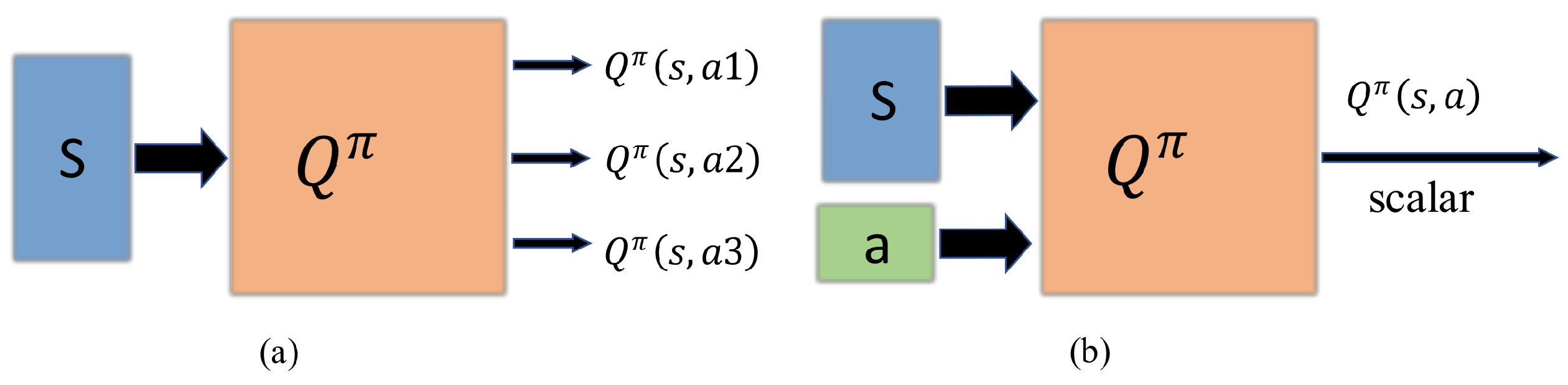
3.1. Deep Learning Technique
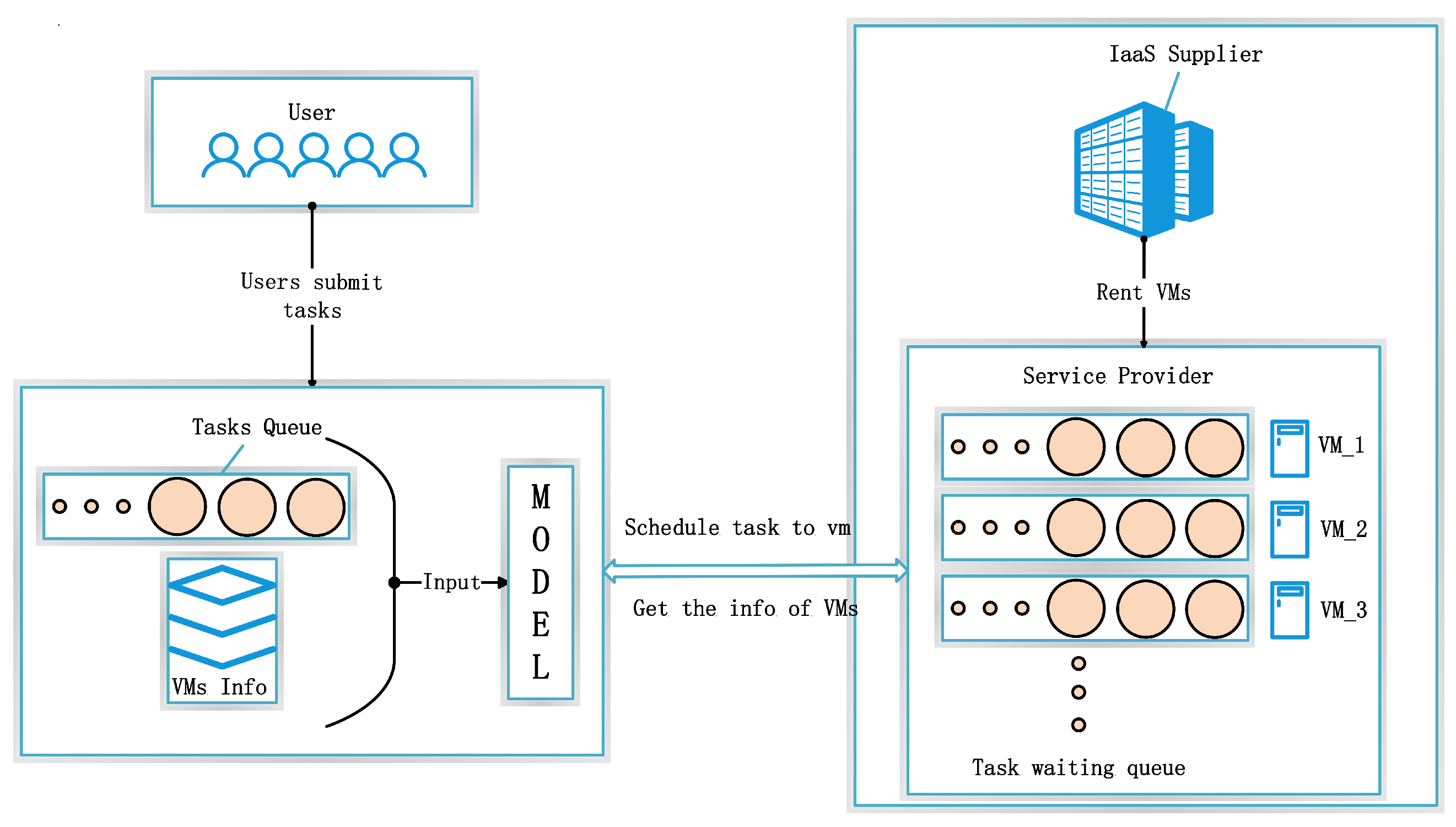
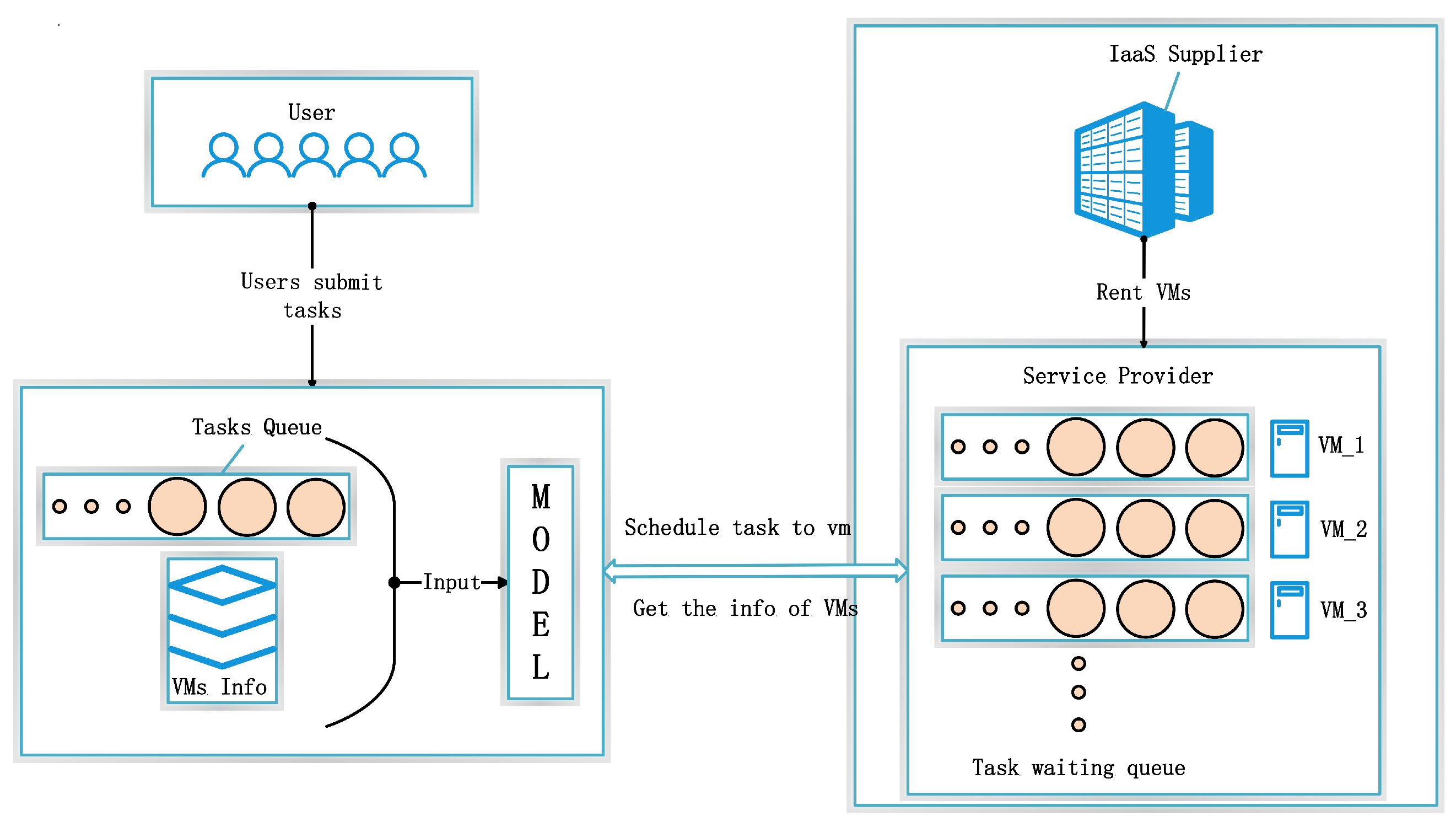
3.2. System Model
3.3. Problem Formulation
4. Algorithm Design
4.1. Input
4.2. Reward
4.3. Model Training
| Algorithm 1 Agent Scheduling Process |
Input:
|
| Algorithm 2 Training Algorithm |
Input:
|
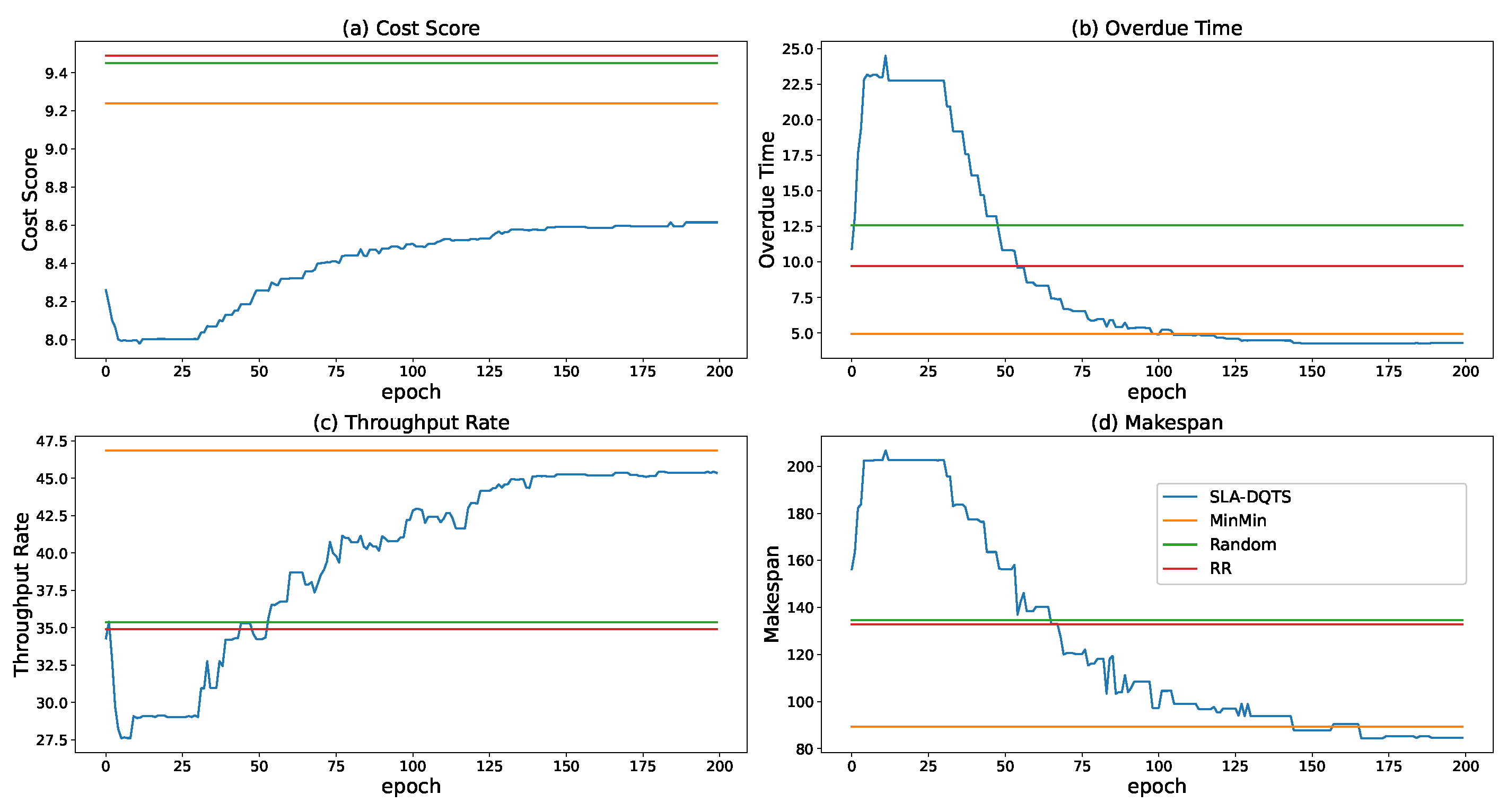
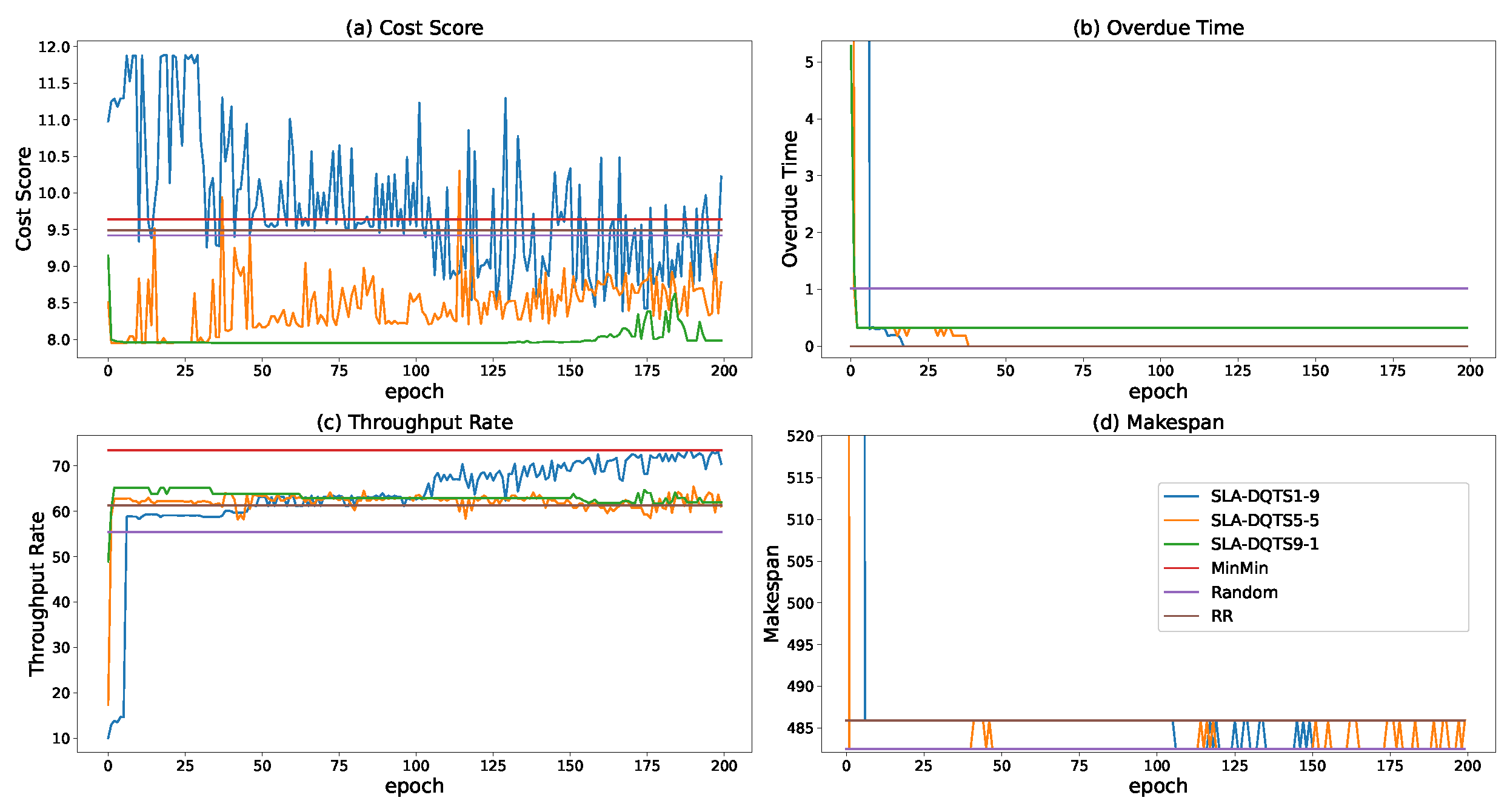
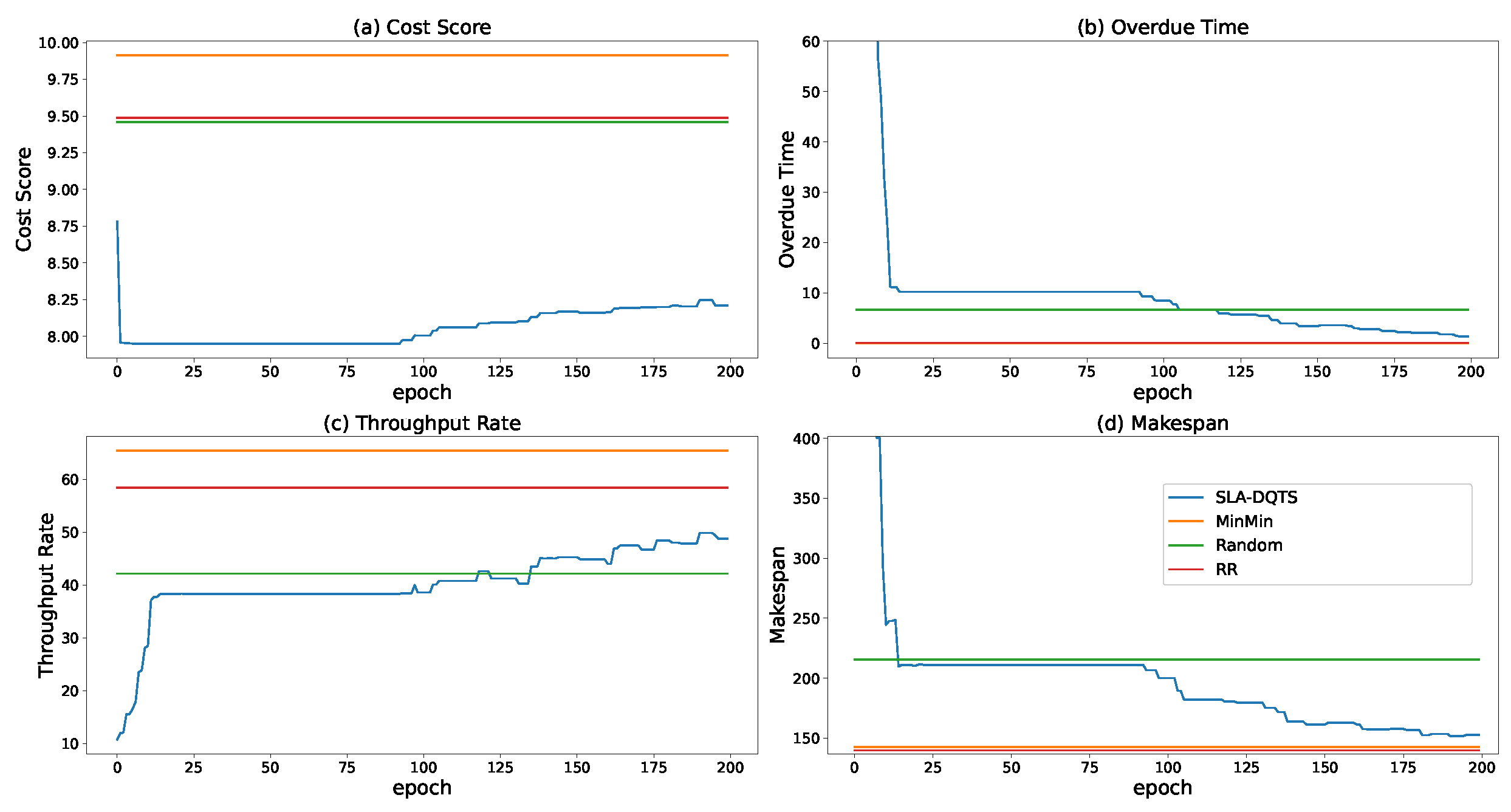
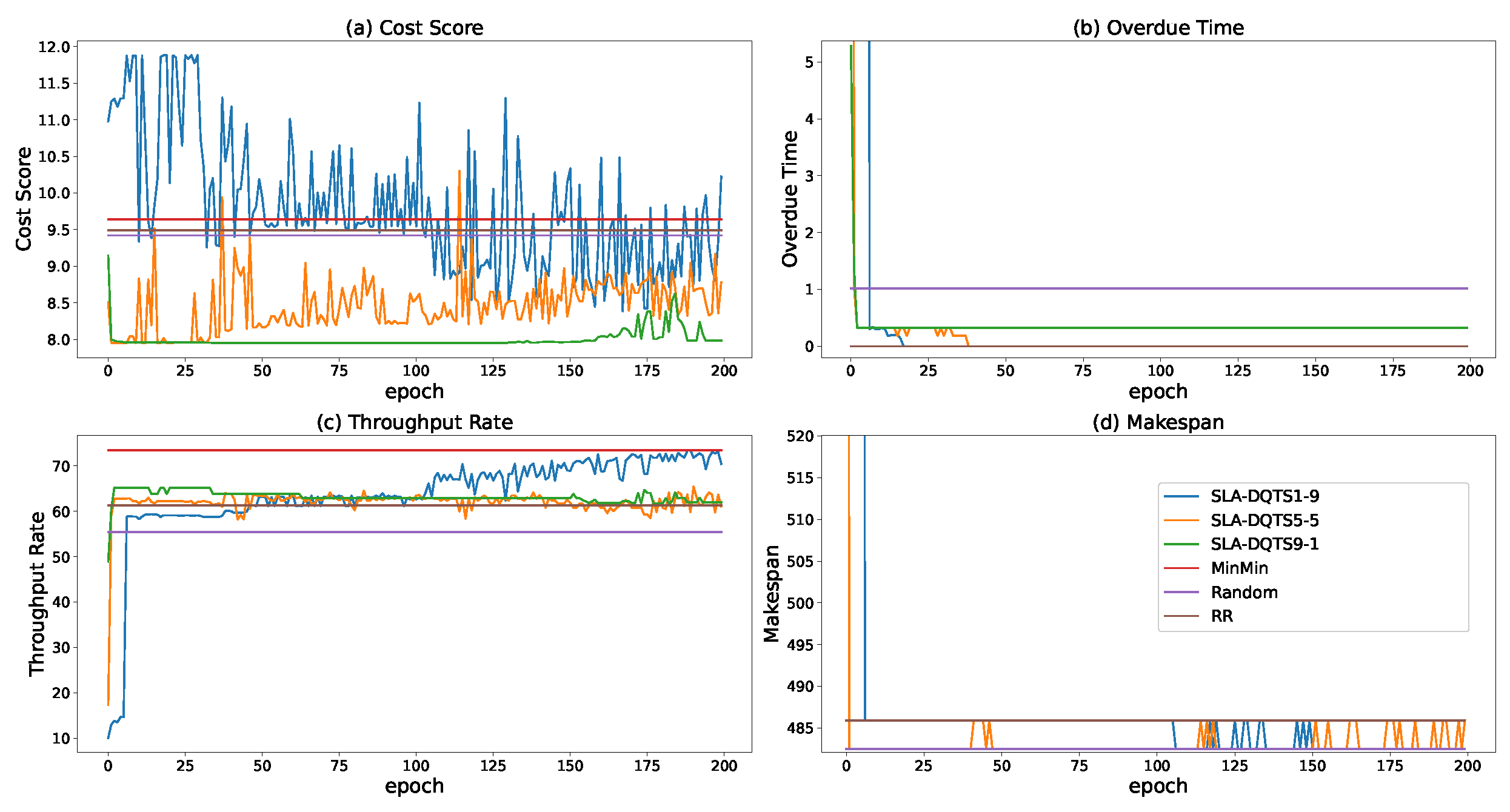
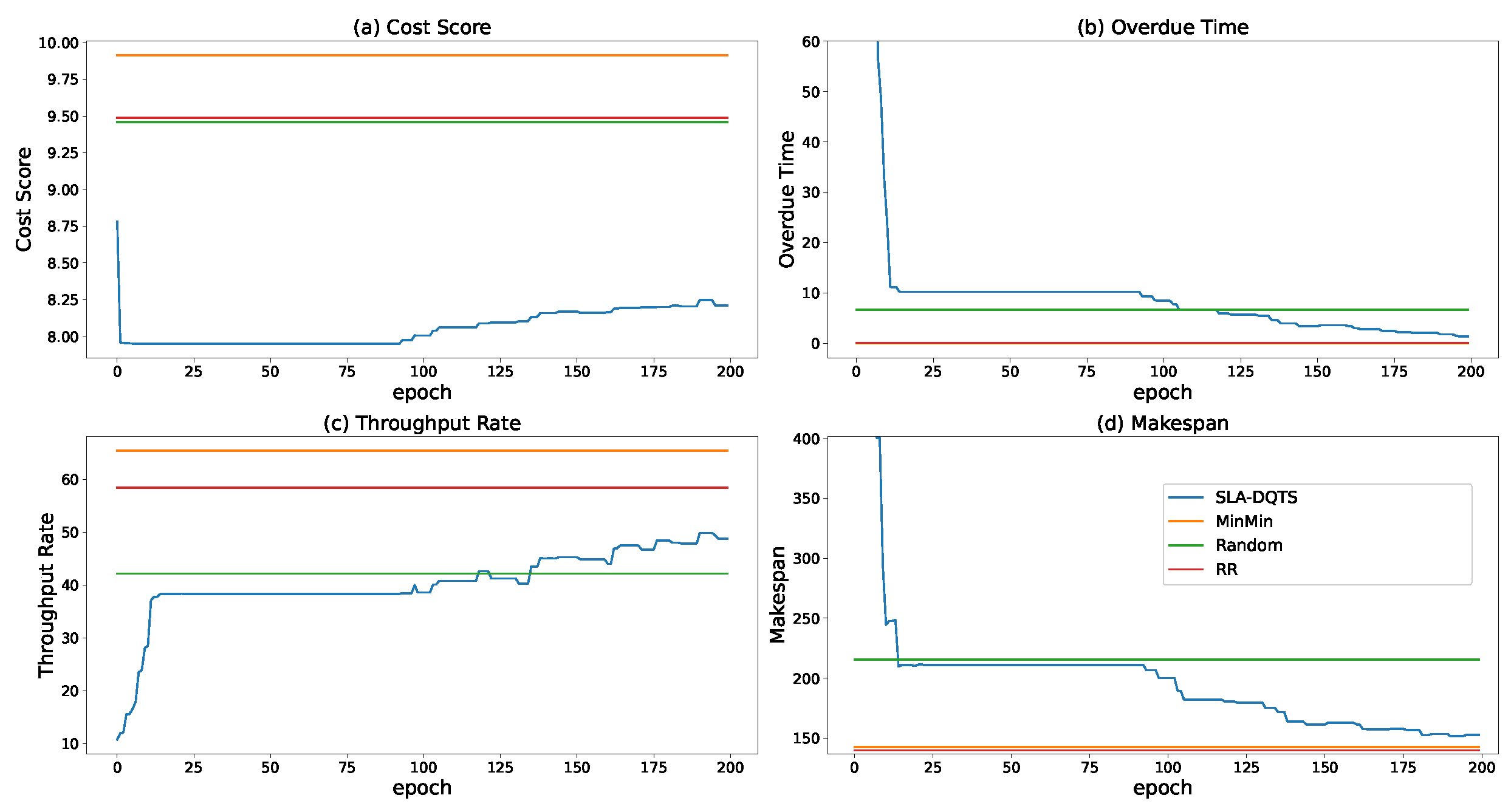
5. Performance Evaluation
5.1. SETUP
- Makespan: completion time of the last task;
- Cost: the product of the execution time of each task and the price of the corresponding VM;
- Throughput: the sum of the task calculation and transmission amounts of each batch of tasks divided by the difference between the start and end times of the batch;
- Overdue time: the difference between the completion and loading times of each task compared with the expected completion time of the task. If it is less than the expected completion time, it is 0, and the difference if it is higher.
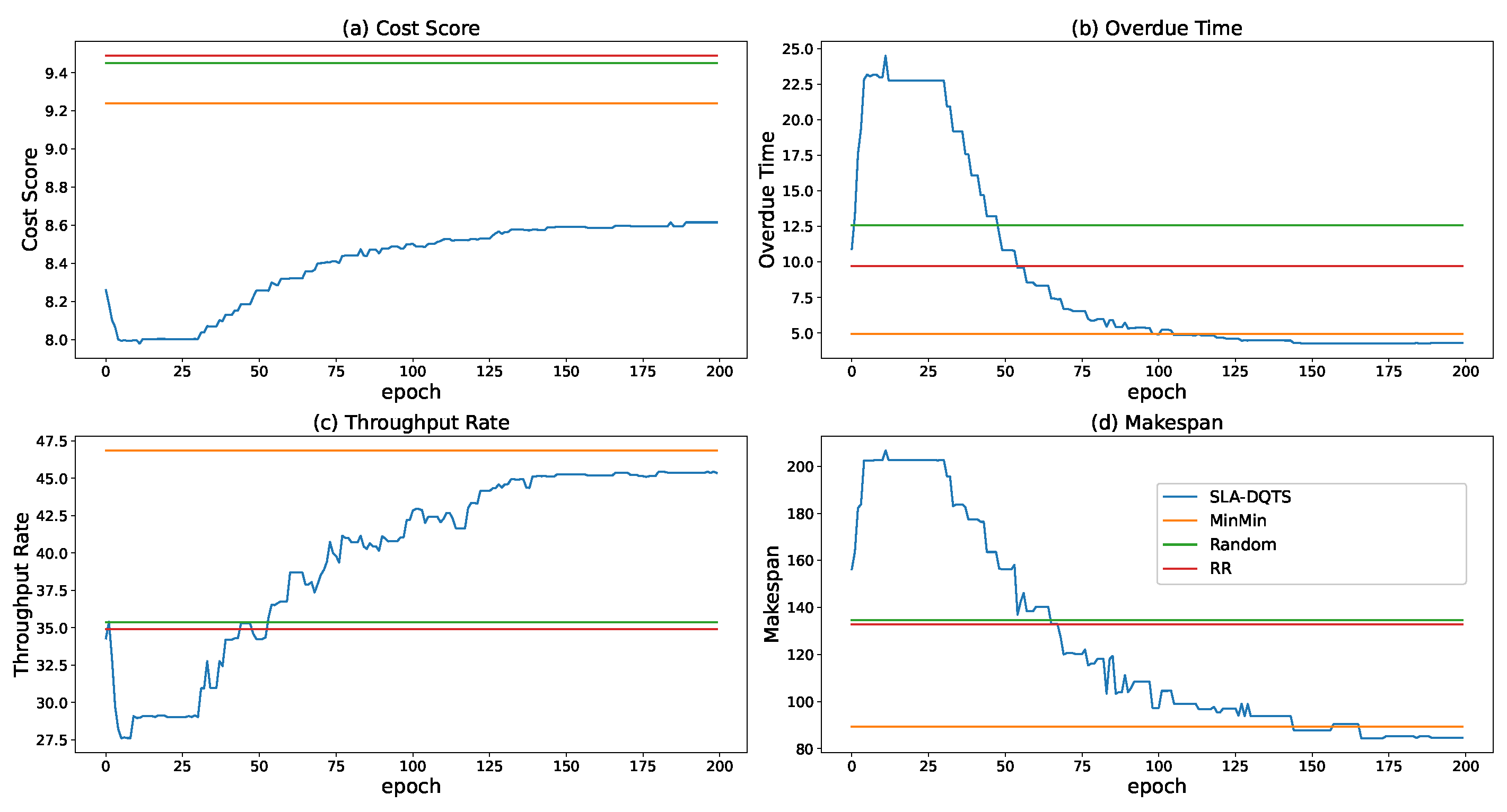
5.2. Experimental Results and Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kumar, K.; Hans, A.; Sharma, A.; Singh, N. Towards the various cloud computing scheduling concerns: A review. In Proceedings of the 2014 Innovative Applications of Computational Intelligence on Power, Energy and Controls with Their Impact on Humanity (CIPECH), Ghaziabad, India, 28–29 November 2014; pp. 482–485. [Google Scholar]
- Ran, L.; Shi, X.; Shang, M. SLAs-aware online task scheduling based on deep reinforcement learning method in cloud environment. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications, IEEE 17th International Conference on Smart City, IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1518–1525. [Google Scholar]
- Keivani, A.; Tapamo, J.R. Task Scheduling in Cloud Computing: A Review. In Proceedings of the 2019 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Winterton, South Africa, 5–6 August 2019; pp. 1–6. [Google Scholar]
- Almansour, N.; Allah, N.M. A Survey of Scheduling Algorithms in Cloud Computing. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Chengdu, China, 2–3 November 2019; pp. 11–18. [Google Scholar]
- Ma, Y.; Yang, L.; Hu, F. Research on a cloud resource scheduling strategy based on asynchronous reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 920–923. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Shen, W. Distributed manufacturing scheduling using intelligent agents. IEEE Intell. Syst. 2002, 17, 88–94. [Google Scholar] [CrossRef]
- Singh, P.; Dutta, M.; Aggarwal, N. A review of task scheduling based on meta-heuristics approach in cloud computing. Knowl. Inf. Syst. 2017, 52, 1–51. [Google Scholar] [CrossRef]
- Patil, N.; Aeloor, D. A review-different scheduling algorithms in cloud computing environment. In Proceedings of the 2017 11th International Conference on Intelligent Systems and Control (ISCO), Tamilnadu, India, 5–6 January 2017; pp. 182–185. [Google Scholar]
- Pan, Y.; Wang, S.; Wu, L.; Xia, Y.; Zheng, W.; Pang, S.; Zeng, Z.; Chen, P.; Li, Y. A Novel Approach to Scheduling Workflows upon Cloud Resources with Fluctuating Performance. Mobile Netw. Appl. 2020, 25, 690–700. [Google Scholar] [CrossRef]
- Mboula, J.E.N.; Kamla, V.C.; Djamegni, C.T. Cost-time trade-off efficient workflow scheduling in cloud. Simul. Model. Pract. Theory 2020, 103, 102107. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, J. Dynamic Workflow Scheduling based on Autonomic Fault-Tolerant Scheme Selection in Uncertain Cloud Environment. In Proceedings of the 2020 6th International Symposium on System and Software Reliability (ISSSR), Chengdu, China, 24–25 October 2020; pp. 38–45. [Google Scholar]
- Lin, B.; Guo, W.; Lin, X. Online optimization scheduling for scientific workflows with deadline constraint on hybrid clouds. Concurr. Comput. Pract. Exp. 2016, 28, 3079–3095. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. Deadline based resource provisioningand scheduling algorithm for scientific workflows on clouds. IEEE Trans. Cloud Comput. 2014, 2, 222–235. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Guo, W. Real-time task scheduling algorithm for cloud computing based on particle swarm optimization. In Proceedings of the Second International Conference on Cloud Computing and Big Data in Asia, Huangshan, China, 17–19 June 2015; pp. 141–152. [Google Scholar]
- Chen, X.; Long, D. Task scheduling of cloud computing using integrated particle swarm algorithm and ant colony algorithm. Clust. Comput. 2019, 22, 2761–2769. [Google Scholar] [CrossRef]
- Hall, J.; Moessner, K.; Mackenzie, R.; Carrez, F.; Foh, C.H. Dynamic Scheduler Management Using Deep Learning. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 575–585. [Google Scholar] [CrossRef] [Green Version]
- Al-Zoubi, H. Efficient Task Scheduling for Applications on Clouds. In Proceedings of the 2019 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Paris, France, 21–23 June 2019; IEEE: New York, NY, USA, 2019; pp. 10–13. [Google Scholar]
- Reddy, G.N.; Kumar, S.P. Regressive Whale Optimization for Workflow Scheduling in Cloud Computing. Int. J. Comput. Intell. Appl. 2019, 18, 1950024. [Google Scholar] [CrossRef]
- Khodar, A.; Chernenkaya, L.V.; Alkhayat, I.; Al-Afare, H.A.F.; Desyatirikova, E.N. Design Model to Improve Task Scheduling in Cloud Computing Based on Particle Swarm Optimization. In Proceedings of the 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg, Russia, 27–30 January 2020; pp. 345–350. [Google Scholar]
- Zhou, Z.; Chang, J.; Hu, Z.; Yu, J.; Li, F. A modified PSO algorithm for task scheduling optimization in cloud computing. Concurr. Comput. Pract. Exp. 2018, 30, e4970. [Google Scholar] [CrossRef]
- Chen, J.; Han, P.; Liu, Y.; Du, X. Scheduling independent tasks in cloud environment based on modified differential evolution. Concurr. Comput. Pract. Exp. 2021. [Google Scholar] [CrossRef]
- Barrett, E.; Howley, E.; Duggan, J. A learning architecture for scheduling workflow applications in the cloud. In Proceedings of the 2011 IEEE Ninth European Conference on Web Services, Lugano, Switzerland, 14–16 September 2011; pp. 83–90. [Google Scholar]
- Peng, Z.; Cui, D.; Zuo, J.; Li, Q.; Xu, B.; Lin, W. Random task scheduling scheme based on reinforcement learning in cloud computing. Clust. Comput. 2015, 18, 1595–1607. [Google Scholar] [CrossRef]
- Xiao, Z.; Liang, P.; Tong, Z.; Li, K.; Khan, S.U.; Li, K. Self-adaptation and mutual adaptation for distributed scheduling in benevolent clouds. Concurr. Comput. Pract. Exp. 2017, 29, e3939. [Google Scholar] [CrossRef]
- Soualhia, M.; Khomh, F.; Tahar, S. A dynamic and failure-aware task scheduling framework for hadoop. IEEE Trans. Cloud Comput. 2018, 8, 553–569. [Google Scholar] [CrossRef]
- Riera, J.F.; Batallé, J.; Bonnet, J.; Días, M.; McGrath, M.; Petralia, G.; Liberati, F.; Giuseppi, A.; Pietrabissa, A.; Ceselli, A.; et al. TeNOR: Steps towards an orchestration platform for multi-PoP NFV deployment. In Proceedings of the 2016 IEEE NetSoft Conference and Workshops (NetSoft), Seoul, Korea, 6–10 June 2016; pp. 243–250. [Google Scholar]
- Jayswal, A.K. Hybrid Load-Balanced Scheduling in Scalable Cloud Environment. Int. J. Inf. Syst. Model. Des. (IJISMD) 2020, 11, 62–78. [Google Scholar] [CrossRef]
- Kaur, A.; Singh, P.; Singh Batth, R.; Peng Lim, C. Deep-Q learning-based heterogeneous earliest finish time scheduling algorithm for scientific workflows in cloud. Software Pract. Exp. 2020. [Google Scholar] [CrossRef]
- Cui, D.; Peng, Z.; Xiong, J.; Xu, B.; Lin, W. A reinforcement learning-based mixed job scheduler scheme for grid or iaas cloud. IEEE Trans. Cloud Comput. 2017, 8, 1030–1039. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, H.; Deng, X.; Li, K.; Li, K. A scheduling scheme in the cloud computing environment using deep Q-learning. Inf. Sci. 2020, 512, 1170–1191. [Google Scholar] [CrossRef]
- Li, F.; Hu, B. Deepjs: Job scheduling based on deep reinforcement learning in cloud data center. In Proceedings of the 2019 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019; pp. 48–53. [Google Scholar]
- Dong, T.; Xue, F.; Xiao, C.; Li, J. Task scheduling based on deep reinforcement learning in a cloud manufacturing environment. Concurr. Comput. Pract. Exp. 2020, 32, e5654. [Google Scholar] [CrossRef]
- Liu, N.; Li, Z.; Xu, J.; Xu, Z.; Lin, S.; Qiu, Q.; Tang, J.; Wang, Y. A hierarchical framework of cloud resource allocation and power management using deep reinforcement learning. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 372–382. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.H.; Konwinski, A.; Lee, G.; Patterson, D.A.; Rabkin, A.; Stoica, I.; et al. Above the Clouds: A Berkeley View of Cloud Computing; Technical Report UCB/EECS-2009-28; EECS Department, University of California: Berkeley, CA, USA, 2009; Volume 28. [Google Scholar]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Task instance i | |
| Computing resource requirements for task i | |
| Bandwidth resource requirements for task i | |
| Number of tasks corresponding to computing resources for task i | |
| Number of tasks corresponding to bandwidth resources for task i | |
| Task processing time expected by user for task i | |
| Time when task i is submitted to task center | |
| Time when task i is executed by node | |
| Time when task i is completed | |
| Execution cost for task i | |
| VM instance j | |
| Number of instructions executed per second by VM | |
| Bandwidth of VM | |
| Price per second of VM | |
| Time to execute by | |
| Time from completion of all tasks assigned to calculated by clock at current moment until VM is idle | |
| Machine set of executable requirements | |
| VM set in cluster | |
| Overdue time calculation equation for task allocated to at current clock | |
| r | Reward function |
| Average task processing speed of this batch | |
| Task cost performance of this batch | |
| Average task overdue time of batch | |
| Weight value of in reward | |
| Weight value of in reward | |
| Time from submission until all batch tasks completed | |
| Value by which task exceeds expected value; if not exceeded, it is zero, so it is always greater than or equal to 0 |
| Parameter | Range |
|---|---|
| number | [2, 5) |
| mips | [100, 5100) |
| bw | [40, 290) |
| duration | [5, 35) |
| Algorithm | Flops | Memory | Complexity | Execution Time |
|---|---|---|---|---|
| SLA_DQTS | N*247 k | 124 k | 247 k | 0.01362 |
| Min-Min | - | 1 | N*M | 0.00477 |
| Random | - | 1 | 1 | 0.00296 |
| RR | - | 1 | 1 | 0.00165 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Peng, Z.; Cui, D.; Li, Q. SLA-DQTS: SLA Constrained Adaptive Online Task Scheduling Based on DDQN in Cloud Computing. Appl. Sci. 2021, 11, 9360. https://doi.org/10.3390/app11209360
Li K, Peng Z, Cui D, Li Q. SLA-DQTS: SLA Constrained Adaptive Online Task Scheduling Based on DDQN in Cloud Computing. Applied Sciences. 2021; 11(20):9360. https://doi.org/10.3390/app11209360
Chicago/Turabian StyleLi, Kaibin, Zhiping Peng, Delong Cui, and Qirui Li. 2021. "SLA-DQTS: SLA Constrained Adaptive Online Task Scheduling Based on DDQN in Cloud Computing" Applied Sciences 11, no. 20: 9360. https://doi.org/10.3390/app11209360
APA StyleLi, K., Peng, Z., Cui, D., & Li, Q. (2021). SLA-DQTS: SLA Constrained Adaptive Online Task Scheduling Based on DDQN in Cloud Computing. Applied Sciences, 11(20), 9360. https://doi.org/10.3390/app11209360