1. Introduction
The success of modern healthcare services, such as automated diagnosis and personalized medicine, is eminently dependent on the availability of datasets. The dataset size is considered a critical property in determining the performance of a machine learning model. Typically, large datasets lead to better classification performance and small datasets may trigger over-fitting [
1,
2,
3]. In practice, however, collecting medical data faces many challenges due to patients’ privacy, lack of cases due to rare conditions [
4], as well as organizational and legal challenges [
5,
6]. Moreover, in the case of available large datasets, training a model using such data requires further time and computing resources, which may not be available.
Despite the continuous debates and efforts, there is still no agreed definition of what constitutes a small dataset. For instance, Shawe-Taylor et al. [
7] proposed a measurement called Probably Approximately Correct (PAC) for identifying the minimum number of necessary samples to meet the desired accuracy. Some research [
8] has defined small datasets based on algorithmic information theory. The authors in [
9] followed a different approach by examining previous studies that are concerned with dealing with small datasets and their sizes and accordingly defined a range for the size of small datasets.
Establishing a method to find the trend in small datasets is not only of scientific interest but also of practical importance and requires a special care when developing machine learning models. Unfortunately, classification algorithms may perform worse when trained with limited size datasets [
2]. This is because small datasets typically contain less details, hence the classification model cannot generalize patterns in training data. In addition, over-fitting becomes much harder to avoid as it sometimes goes beyond training data to affect the validation set as well [
3].
Classification is a challenging task by itself. It becomes more challenging when dealing with small datasets. The central cause behind this challenge relates to the limited size of training data, which leads to unreliable and biased classification model [
3]. While previous studies are focusing on increasing the accuracy of the classification algorithms on limited size datasets, less effort was made to study the impact of the size property of the dataset on the performance of the classification algorithms, which makes it an open problem in the area that needs more investigation.
Several studies have emerged recently that address the issue of small datasets from different perspectives, including enhancing the performance of classification models on limited datasets [
8,
9,
10,
11] and proposing varying approaches to augment the training set [
12,
13,
14,
15,
16]. For example, in the former category, authors in [
8] proposed two methods for neural network (NN) training on small datasets using Fuzzy ARTMAP neural networks [
10]. In [
11], a novel particle swarm optimization-based virtual sample generation (PSOVSG) approach was proposed to iteratively produce the most suitable virtual samples in the search space. The performance of PSOVSG is tested against other three methods and had superior results.
In the latter category, Li et al. [
12] proposed a non-parametric method for learning trend similarities between attributes and then using them to predict the respective ranges in which attribute values can be situated when other attribute values are provided. Another study [
13] generated data based on the Gaussian distribution by utilizing the smoothness which states that, if two inputs are close to each other, their outputs will be close as well. In [
14], the authors learned the relationship between the dataset features to generate new data attributes using the fuzzy rules. Other studies [
15,
16,
17] have proposed the extending attribute information (EAI) method to investigate the applicability of extracting features from small datasets by applying the similarity-based algorithms using fuzzy membership function on seven different data sets. Authors in [
18] proposed the sample extending attribute (SEA) method to extend a suitable quantity of attributes for improving the learning performance of small datasets and preventing the data from becoming sparse.
Research on the subject has been mostly restricted on increasing the accuracy of the classification algorithms on limited size datasets, little attention has been paid to study the impact of the dataset size on the performance of the classification algorithms. However, the proposed solutions suffer from multiple issues, such as data replicates [
13], unscalability [
8,
10], and noise [
13,
19]. Similar studies to our work exist in the literature, where the main aim is to investigate the extent to which the size of the dataset can impact the classification performance in different domains such as sentiment classification [
2,
20], object detection [
21], plant disease classification [
22], and information retrieval [
23].
Table 1 summarizes the most relevant related works.
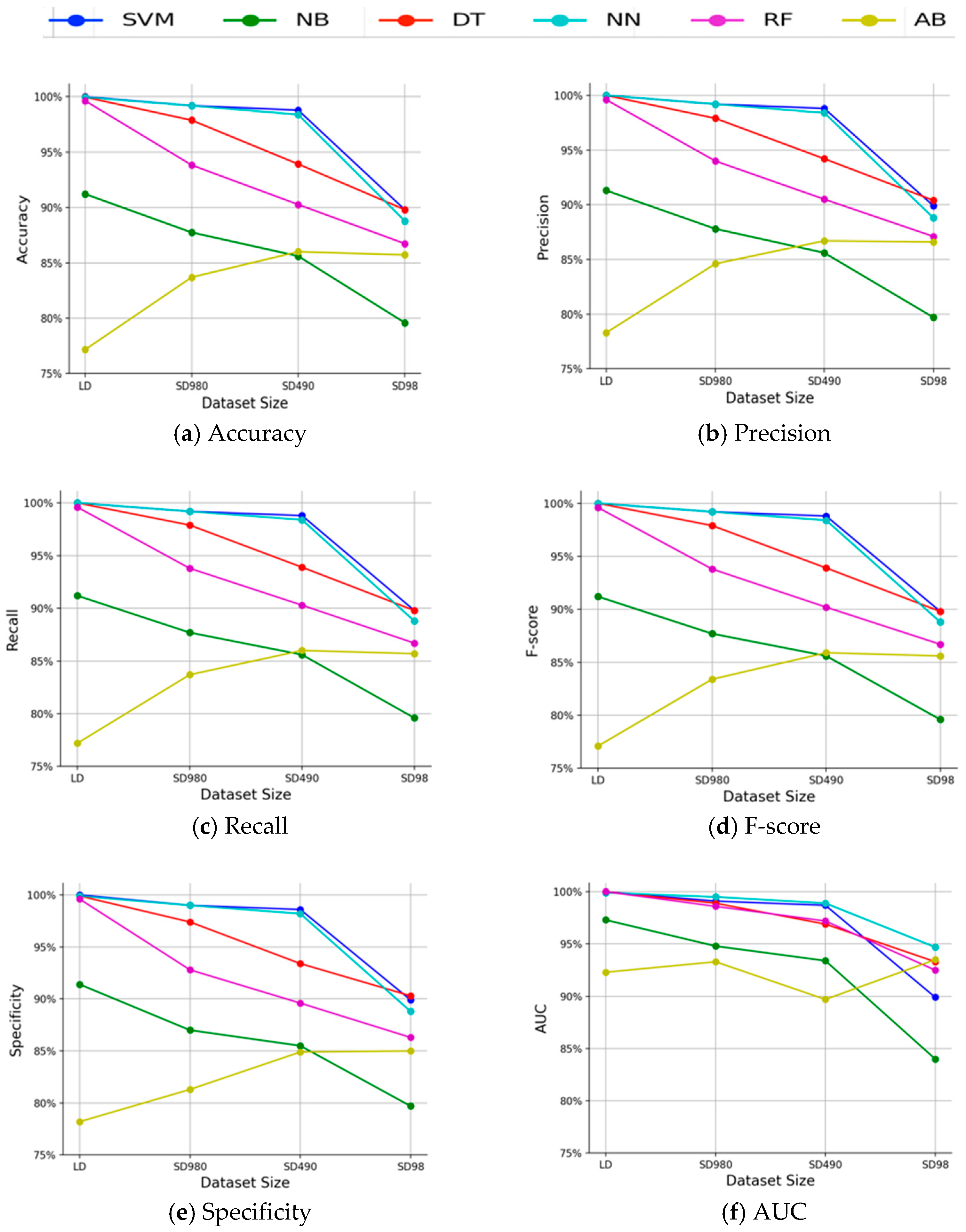
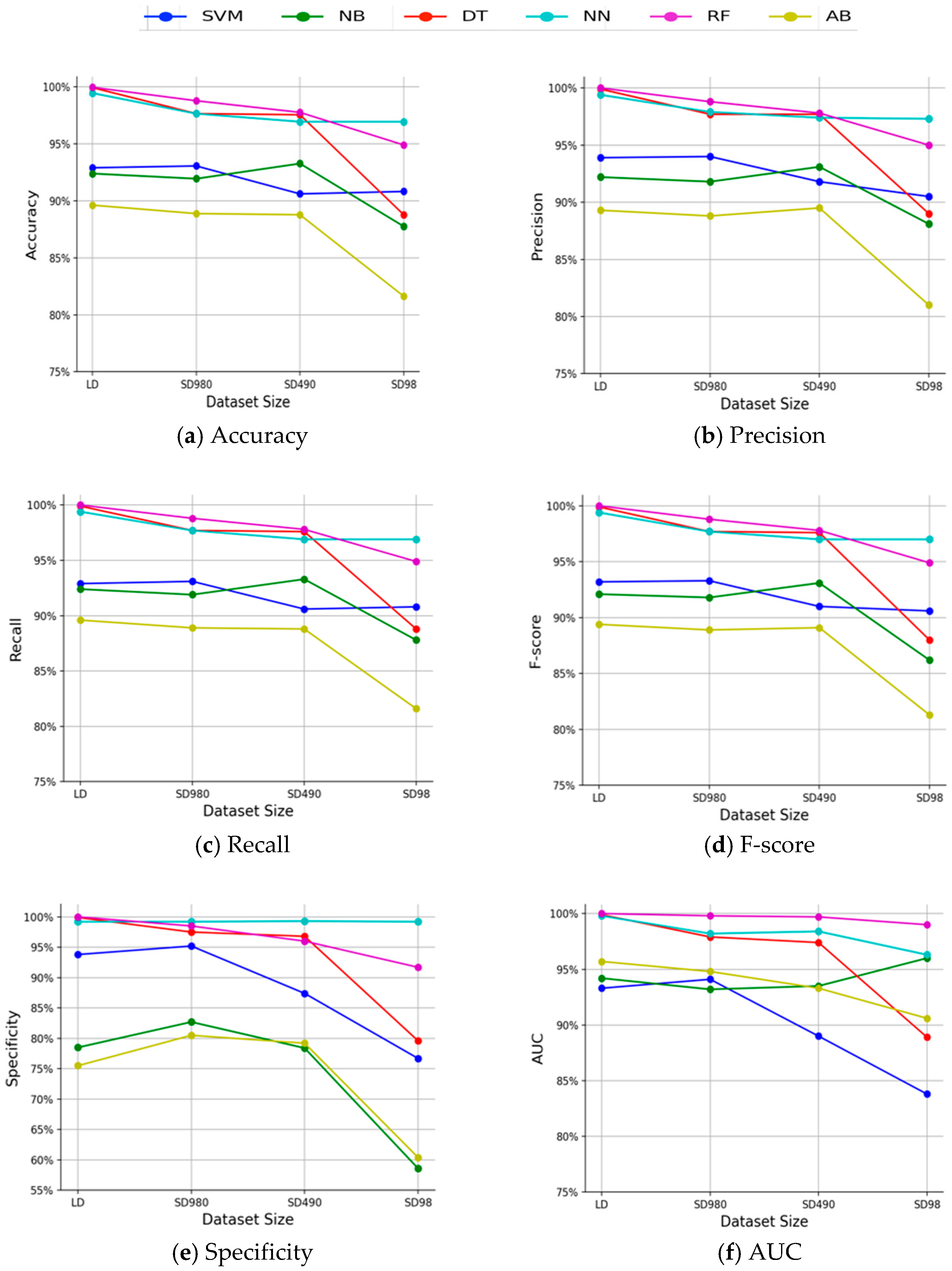
This work aims to investigate the impact of dataset size on the performance of six widely-used supervised machine learning models in the medical domain. For this purpose, we carried out extensive experiments on six classification models including support vector machine (SVM), neural networks (NN), C4.5 decision tree (DT), random forest (RF), adaboost (AB), and naïve Bayes (NB) using twenty medical UCI datasets [
24]. We further implemented three dataset size reduction scenarios on two large datasets, resulting in three small subsets. We then analyzed the change in performance of the models as a response to the reduction of dataset size with respect to accuracy, precision, recall, f-score, specificity, and area under the ROC curve (AUC). Statistical tests are used to assess the statistical significance of the differences in performances in different scenarios.
The rest of the paper is organized as follows. In
Section 2, we describe the methodology, including the datasets, the classification models, and performance evaluation. In
Section 3, we present and discuss the results. Finally,
Section 4 concludes our work.
2. Methodology
As mentioned earlier, this study aims to investigate the impact of dataset’s size on the classification performance and recommend the appropriate classifier(s) for limited-size datasets. In order to achieve this goal, we followed an experimental methodology, where we selected datasets of varying sizes and grouped them into two groups: small datasets and large datasets. We extracted three small datasets randomly using sampling without replacement from each large dataset. The partitioning protocol is described in
Section 2.1 below. The goal is to examine the impact of reducing the size of the same dataset on the classification performance. After preprocessing the datasets, a total of six widely-used classification models were trained on all datasets. The performance of the classifiers is evaluated with respect to accuracy, precision, recall, specificity, f-score, and AUC. In the following subsections, we will discuss the dataset selection and partitioning algorithm, the classification models, and the performance evaluation metrics.
2.1. Dataset
We selected twenty data sets from the UCI data repository [
24]. The datasets were selected from medical fields where limited data are common.
Table 2 shows details about the selected datasets, arranged by size, along with their number of attributes and data type. There is no explicit definition for small datasets in the literature. Therefore, in order to determine the size range for selecting small datasets in this work, we reviewed existing works that study small datasets and kept track of the size of their datasets. As shown in
Table 1, the size of small datasets used in the existing works ranges from 18 to 1030 across studies [
8,
11,
12,
13,
14,
15,
17,
18]. Accordingly, the selected twenty datasets were categorized as eighteen small datasets and two large datasets.
The small datasets (DS1-DS18) consist of eighteen medical datasets. The number of instances in these small datasets ranges from 80–1040 instances, and the number of features ranges between 3–49. All small datasets are numerical or numerical with text. In the category of large datasets, there are two datasets; Skin Segmentation dataset (DS19 in
Table 2) and Diabetes 130-US hospitals dataset (DS20 in
Table 2). The former consists of 245,057 instances and four features of numeric datatype, while the latter has 9871 instances and 55 features of mixed numeric and text datatypes.
To study the impact of dataset size on the performance of classifiers, we constructed three small sub-datasets of increasing sizes from each large dataset using sampling without replacement, as shown in
Table 3.
Figure 1 presents the dataset portioning algorithm. As shown in the figure, the algorithm receives two large datasets S
1 and S
2 and returns three small sub-datasets S
1, S
2, and S
3 for each large dataset. It first defines the sizes of the three small sub-datasets (980, 490, and 98). These were selected from the three equal intervals (highest, middle, and lowest) of the size range of small datasets (18–1030), respectively. Next, the algorithm iterates over the large datasets S
1 and S
2. For each dataset, the algorithm creates a copy of the dataset (SL) to void modifying the original dataset. The algorithm then iterates over the array of small sizes in order to create the corresponding small sub-dataset SS
i, where X tuples are extracted randomly without replacement to avoid overlapping between the sub-datasets. This is performed by removing the sub-dataset SS
i from the large dataset SL after extraction. The iterations continue until all three sub-datasets are created for all large datasets. Data preprocessing was carried out for all datasets as necessary to deal with missing values.
2.2. Classification Models
We used six different widely-used classifiers, which include probabilistic classification using naïve Bayes (NB), decision function classification using support vector machine (SVM), neural network (NN), decision tree induction C4.5 (DT), tree ensemble random forest (RF), and ensemble adaptive boosting (AB). Below, we shed light on these classification models:
SVM: The objective of the SVM algorithm is to find the hyperplane in the data that gives the largest separation margin between data instances and classifies them into two classes. It can be explained based on four basic concepts, the separating hyperplane, the maximum margin hyperplane, the soft margin, and finally the kernel function [
25,
26].
NB: It is a supervised learning method based on the Bayesian theorem. Therefore, it is considered as a statistical method for classification. It works by calculating explicit probabilities for hypotheses. NB models use the method of maximum likelihood for parameter estimation. Literature showed that it often performs better in many complex real world applications. One of the features of this method is that it is robust to noise in data, and it can estimate the parameters using a small training set [
25,
26,
27].
DT: A Decision Tree is constructed as a binary classification tree, based on the training data. In the tree structure, class labels are represented by leaf nodes, while the internal nodes represent the conjunction of features that assess class. There are several DT algorithms, Notable decision tree algorithms include: ID3 (Iterative Dichotomiser 3), C4.5 (successor of ID3), and CART (Classification And Regression Tree) [
25,
26]. In this study, the C4.5 algorithm for DT is selected for deploying the DT classification.
NN: It is one of the most widely-used classification models, as it is a good alternative to several traditional classification methods. One of the main advantages of NN is that it is a data-driven self-adaptive method, in that it is adjustable to the data without the need for explicit specification of the underlying model. Another feature of NN is that it represents a nonlinear model-free method [
25,
26,
27].
RF: As the name implies, the RF classifier consists of a number of individual decision trees. Each of the individual decision trees in the forest is used for a majority voting of the output class, the class that has the majority of votes becomes the model’s predicted class [
25].
AB: One of the most important “families” of ensemble methods is Boosting, and within the boosting algorithms, the adaptive boosting (AB) algorithm is one of the most important. The adaptiveness of AD comes in the form of successive weak learners and fine-tuning them in favor of those instances misclassified by previous classifiers. Some of the properties of AD is that it is sensitive to noisy data and outliers, but, in some cases, it can be less susceptible to the overfitting than other learning algorithms [
28].
2.3. Performance Evaluation
In contrast to most existing efforts in literature, which used accuracy as the performance measure, we evaluate the performance of the classification models with respect to six important metrics in the medical domain, namely, accuracy, precision, recall, F-score, specificity, and AUC. Furthermore, the Mann–Whitney U test is applied to assess the statistical significance between the performance of the models in different scenarios.
5. Conclusions
Recent years have witnessed an increased interest in modern healthcare services, such as automated diagnosis and personalized medicine. However, the success of such services is eminently dependent on the availability of datasets. Collecting medical data may face many challenges such as patients’ privacy and lack of data for rare conditions. This work aims to investigate the impact of dataset size on the performance of six widely-used supervised machine learning models in the medical domain. For this purpose, we carried out extensive experiments on six classification models including SVM, NN, DT, RF, AB, and NB using twenty medical UCI datasets [
24]. We further implemented three dataset size reduction scenarios on two large datasets, resulting in three small subsets. We then analyzed the change in performance of the models as a response to the reduction of dataset size with respect to accuracy, precision, recall, f-score, specificity, and AUC. Statistical tests are used to assess the statistical significance of the differences in performances in different scenarios.
Several interesting conclusions can be made. First, the overall performance of classifiers depends on the extent to which a dataset represents the original distribution rather than its size. Second, the most robust model for limited medical data is AB and NB, followed by SVM, and then RF and NN, while the least robust model is DT. Third, a robust machine learning model to limited dataset does not necessarily imply that it provides the best performance compared to other models. Our results are in agreement with previous studies [
2]. A natural progression of this research would be to investigate the minimum dataset size that each classifier needs in order to maximize its performance.

 ,
, 

{kind=link}
{kind=link}
{kind=link}


