
A Photo Identification Framework to Prevent Copyright Infringement with Manipulations


Abstract
:1. Introduction
Contributions
- We propose Image RoI Detection, a preprocessing technique that can effectively handle geometric manipulations such as image collage and image cropping, which cannot be solved by existing image search services. To train the image detector used in Image RoI Detection, image collage datasets with 300,000 image collages are introduced.
- We propose Image Hashing that can generate similar binary descriptors from manipulated photos and original photos. This module is designed to handle color manipulations such as color distortion and blur as well as geometric manipulations.
- To accomplish Image Verification, we introduce an geometric alignment method to accurately align an query image with the matched one in the database obtained by Image Hashing method and propose a similarity measurement network to distinguish whether the aligned image infringes copyright robustly to manipulations.
- By applying the aforementioned three steps, we improve the identification accuracy and significantly reduce the false positive rate for manipulated photos. The experimental results demonstrate advantages of each module in the proposed framework and show notable performance improvements of the proposed framework over the state-of-the-art image retrieval method [10].
2. Related Works
2.1. Efficient Object Detection
2.2. Image Hashing
2.3. Image Classification
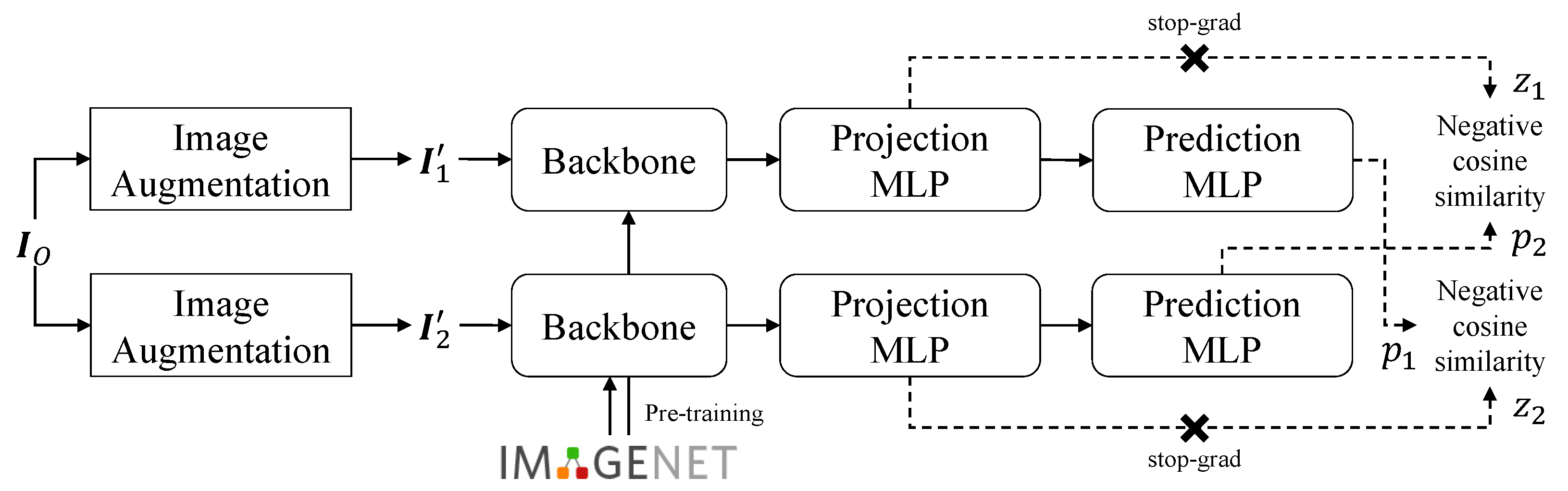
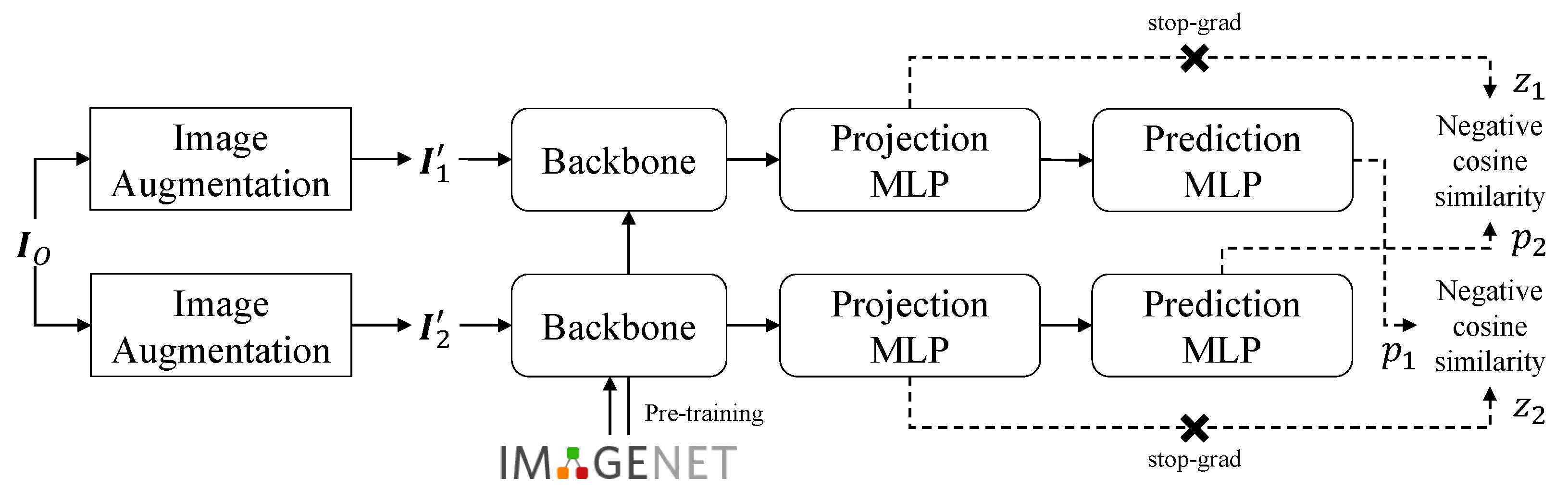
2.4. Self-Supervised Learning
2.5. Siamese Network
2.6. Image Verification Metric
3. Copyright Photo Identification Framework
3.1. Overall Framework
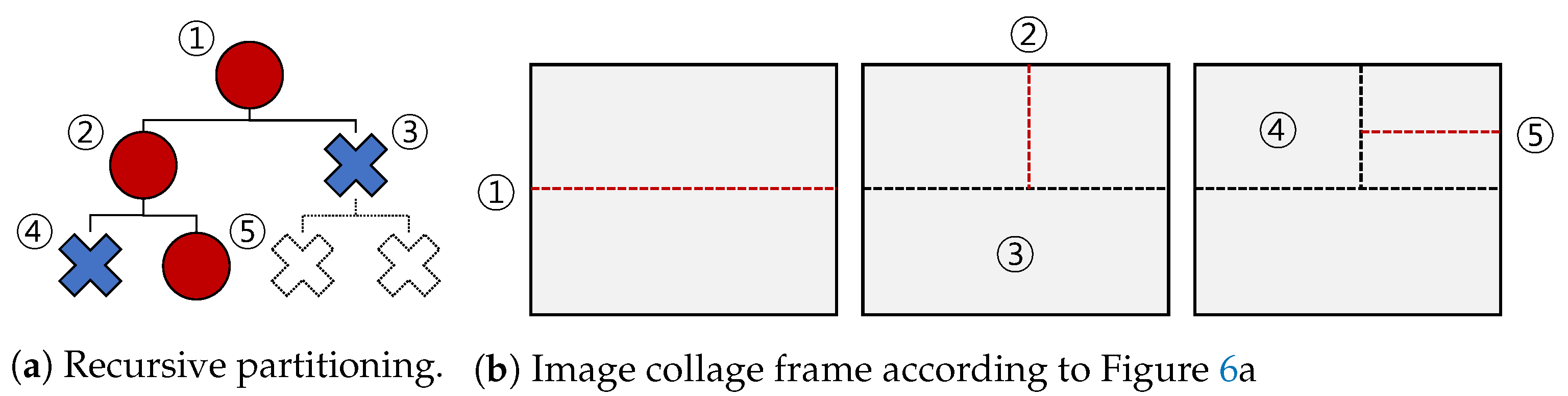
3.2. Image RoI Detection
| Algorithm 1: Generating the template by the partitioning frame. |
 |
3.3. Image Hashing
3.4. Image Verification
3.4.1. Image Alignment
| Algorithm 2: Pseudo-code for calculating the optimal transform matrix by RANSAC. |
 |
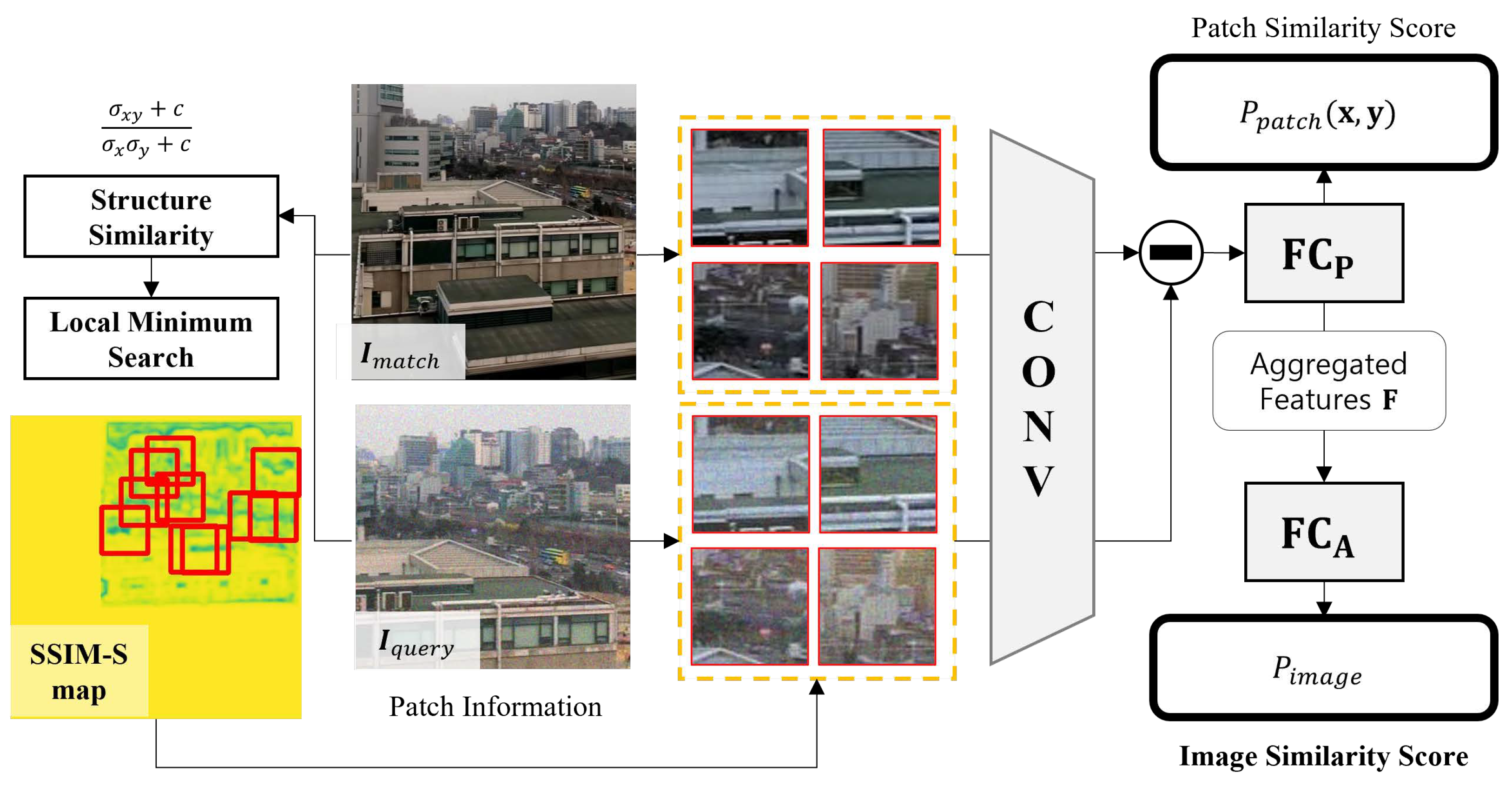
3.4.2. Image Similarity Siamese Network
4. Implementation Details
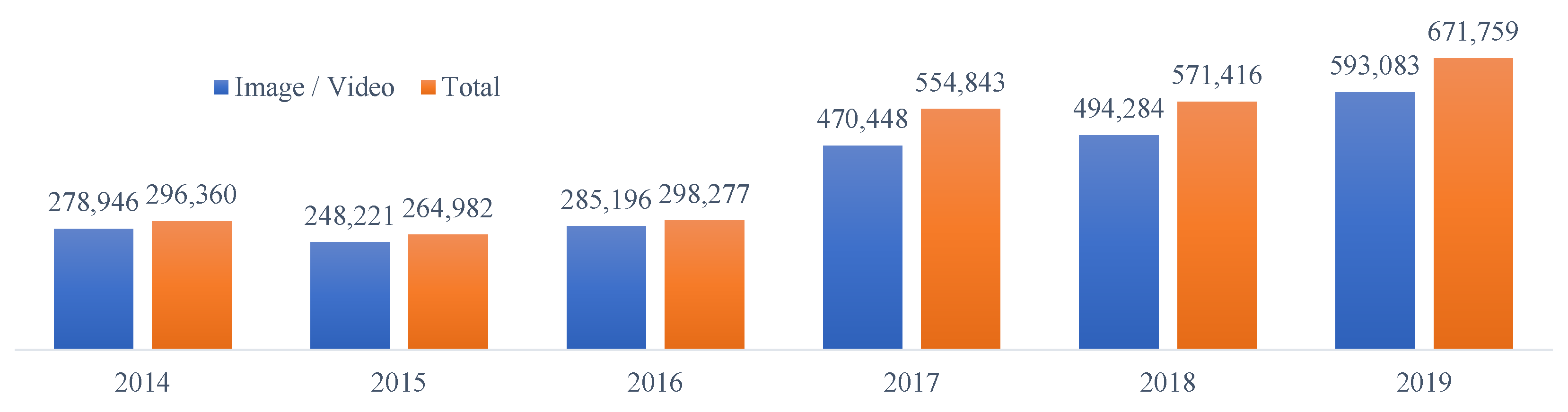
4.1. Photo Copyright Dataset
4.2. Image RoI Detection
4.3. Image Hashing
4.4. Image Verification
5. Experimental Results
5.1. Image Detector with Image Collage Dataset
5.2. Image Hashing
5.2.1. Geometric Manipulation
5.2.2. Color Manipulation
5.3. Image Verification
5.3.1. Image Alignment
5.3.2. Image Similarity Siamese Network
5.4. Overall Framework Test for Photo Copyright Identification
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Copytrack. Available online: https://www.copytrack.com/ (accessed on 27 September 2021).
- Korea Copyright Commission. Available online: https://www.copyright.or.kr/eng/main.do (accessed on 27 September 2021).
- Oh, T.; Choi, N.; Kim, D.; Lee, S. Low-complexity and robust comic fingerprint method for comic identification. Signal Process. Image Commun. 2015, 39, 1–16. [Google Scholar] [CrossRef]
- Lee, S.-H.; Kim, D.; Jadhav, S.; Lee, S. A restoration method for distorted comics to improve comic contents identification. Int. J. Doc. Anal. Recognit. 2017, 20, 223–240. [Google Scholar] [CrossRef]
- Lee, S.-H.; Kim, J.; Lee, S. An identification framework for print-scan books in a large database. Inf. Sci. 2017, 396, 33–54. [Google Scholar] [CrossRef]
- Kim, D.; Lee, S.-H.; Jadhav, S.; Kwon, H.; Lee, S. Robust fingerprinting method for webtoon identification in large-scale databases. IEEE Access 2018, 6, 37932–37946. [Google Scholar] [CrossRef]
- Google Image Search. Available online: https://www.google.co.kr/imghp (accessed on 27 September 2021).
- Yandex Images. Available online: https://yandex.com/images/ (accessed on 27 September 2021).
- TinEye Reverse Image Search. Available online: https://tineye.com/ (accessed on 27 September 2021).
- Song, J.; He, T.; Gao, L.; Xu, X.; Hanjalic, A.; Shen, H.T. Binary generative adversarial networks for image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32.1. [Google Scholar]
- Mcconnell, R.K. Method of and Apparatus for Pattern Recognition. U.S. Patent 4,567,610, 28 January 1986. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14–19 June 2020; pp. 10781–10790. Available online: https://openaccess.thecvf.com/content_CVPR_2020/html/Tan_EfficientDet_Scalable_and_Efficient_Object_Detection_CVPR_2020_paper.html (accessed on 20 August 2021).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.-Y.; Shlens, J.; Le, Q.V. Learning data augmentation strategies for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 566–583. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cao, Y.; Long, M.; Liu, B.; Wang, J. Deep cauchy hashing for hamming space retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1229–1237. [Google Scholar]
- Cakir, F.; He, K.; Bargal, S.A.; Sclaroff, S. Hashing with mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2424–2437. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zieba, M.; Semberecki, P.; El-Gaaly, T.; Trzcinski, T. BinGAN: Learning compact binary descriptors with a regularized GAN. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 3612–3622. [Google Scholar]
- Deng, C.; Yang, E.; Liu, T.; Li, J.; Liu, W.; Tao, D. Unsupervised semantic-preserving adversarial hashing for image search. IEEE Trans. Image Process. 2019, 28, 4032–4044. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Krizehevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://citeseerx.ist.psu.edu/ (accessed on 27 September 2021).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 10–13 December 2011. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (PMLR), Montréal, QC, Canada, 6–8 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Richemond, P.H.; Gril, J.-B.; Altche, F.; Tallec, C.; Strub, F.; Brock, A.; Smith, S.; De, S.; Pascanu, R. BYOL works even without batch statistics. arXiv 2020, arXiv:2010.10241. [Google Scholar]
- Florian, S.; Dmitry, K.; James, P. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, S. Deep learning of human visual sensitivity in image quality assessment framework. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1676–1684. [Google Scholar]
- Kim, W.; Kim, J.; Ahn, S.; Kim, J.; Lee, S. Deep video quality assessor: From spatio-temporal visual sensitivity to a convolutional neural aggregation network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 219–234. [Google Scholar]
- Kim, W.; Nguyen, A.-D.; Lee, S.; Bovik, A.C. Dynamic receptive field generation for full-reference image quality assessment. IEEE Trans. Image Process. 2020, 29, 4219–4231. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerlnad, 2014; pp. 740–755. [Google Scholar]
- Alcantarilla, P.F. Solutions, T. Fast explicit diffusion for accelerated features in nonlinear scale spaces. IEEE Trans. Patten Anal. Mach. Intell. 2011, 34, 1281–1298. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van, G.L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Huber, P.J. Robust Statistics; Wiley: Hoboken, NJ, USA, 1981; p. 1. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector | Average IoU | Avg. Time (s) | |
|---|---|---|---|
| Yolo v3 [17] | 0.75 | 0.02 | |
| Faster R-CNN [14] | ResNet50 | 0.76 | 0.3 |
| without FPN [19] | ResNet101 | 0.86 | 0.3 |
| Faster R-CNN [14] | ResNet50 | 0.82 | 0.17 |
| with FPN [19] | ResNet101 | 0.83 | 0.17 |
| EfficientDet [12] | D0 | 0.92 | 0.06 |
| D1 | 0.98 | 0.08 | |
| D2 | 0.98 | 0.11 | |
| D3 | 0.99 | 0.15 | |
| Method | Binary Descriptor Size | IoU | |||
|---|---|---|---|---|---|
| ∼0.7 | ∼0.8 | ∼0.9 | ∼1.0 | ||
| HoG [11] | 128 | 4.5% | 36.8% | 72.4% | 88.5% |
| 256 | 5.4% | 40.5% | 78.0% | 92.5% | |
| 512 | 7.8% | 45.6% | 83.5% | 94.1% | |
| BinaryGAN [10] | 128 | 15.5% | 47.6% | 78.5% | 90.6% |
| 256 | 22.6% | 55.1% | 82.9% | 95.2% | |
| 512 | 25.7% | 56.3% | 85.7% | 95.9% | |
| Proposed image hashing | 128 | 18.7% | 50.6% | 80.0% | 91.0% |
| 256 | 26.8% | 59.2% | 83.7% | 95.5% | |
| 512 | 30.1% | 62.4% | 86.8% | 96.1% | |
| Method | Binary Descriptor Size | Color Distortion | Brightness Change | Gaussian Blur |
|---|---|---|---|---|
| HoG [11] | 128 | 77.6% | 93.2% | 89.2% |
| 256 | 80.9% | 94.4% | 90.9% | |
| 512 | 82.1% | 95.6% | 92.6% | |
| BinaryGAN [10] | 128 | 76.8% | 92.9% | 89.0% |
| 256 | 78.0% | 94.0% | 90.6% | |
| 512 | 80.9% | 95.4% | 92.1% | |
| Proposed image hashing | 128 | 77.4% | 93.4% | 90.2% |
| 256 | 78.9% | 94.7% | 91.7% | |
| 512 | 81.2% | 95.8% | 93.0% |
| Clipping Proportion | ∼10% | ∼15% | ∼20% | ∼25% | ∼30% |
|---|---|---|---|---|---|
| Avg. IoU | 0.998 | 0.998 | 0.998 | 0.998 | 0.997 |
| Min. IoU | 0.991 | 0.989 | 0.992 | 0.986 | 0.990 |
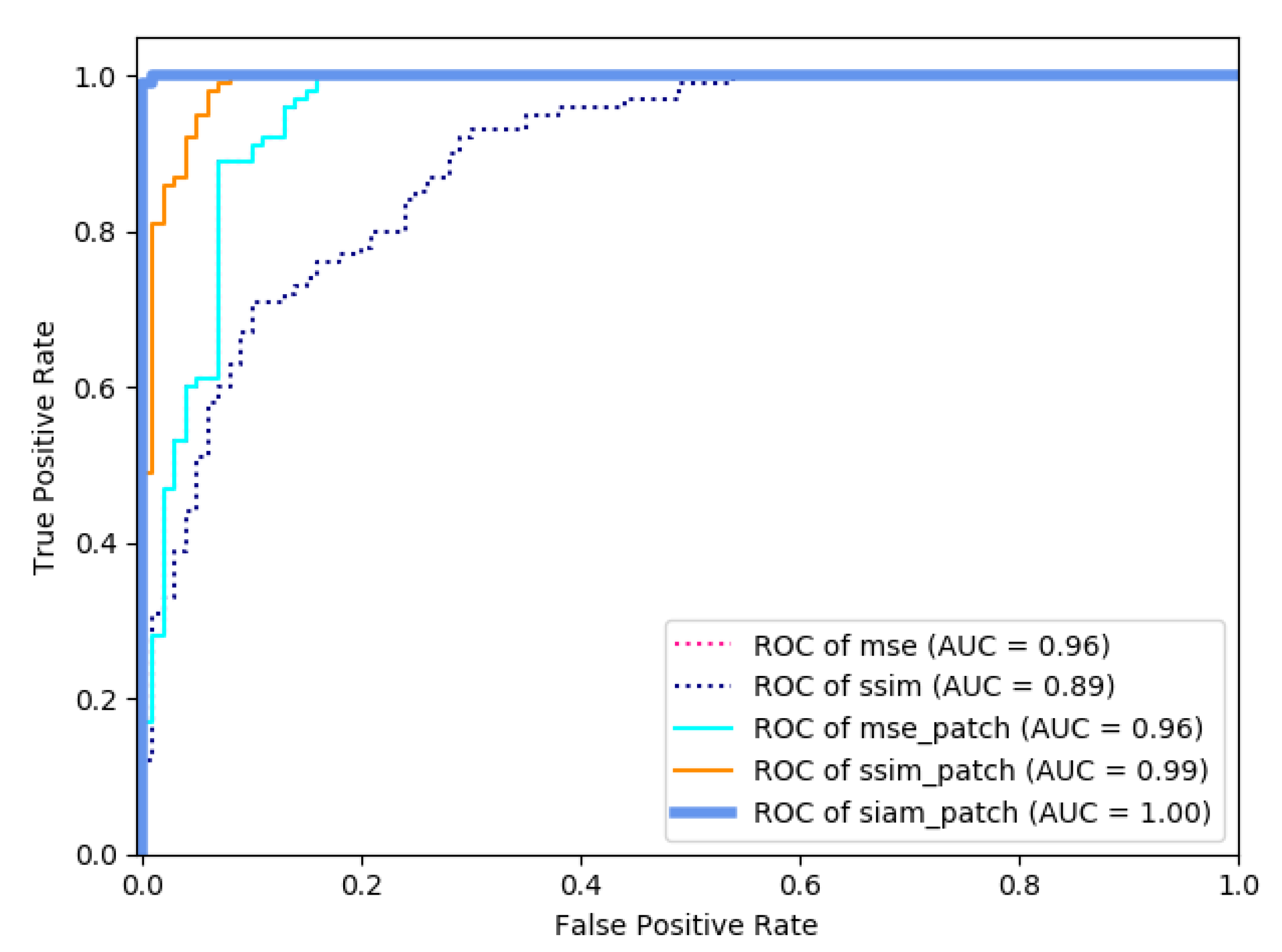
| Similarity Metric | F1-Score | AUC | FN (FP = 0.01) | FN (FP = 0.05) | FN (FP = 0.1) |
|---|---|---|---|---|---|
| MSE | 0.669 | 0.96 | 0.82 | 0.48 | 0.4 |
| SSIM [40] | 0.855 | 0.89 | 0.85 | 0.48 | 0.4 |
| MSE Patch | 0.669 | 0.96 | 0.82 | 0.72 | 0.10 |
| SSIM [40] Patch | 0.855 | 0.99 | 0.50 | 0.19 | 0.02 |
| Siam Patch | 0.995 | 1.00 | 0.02 | 0.01 | 0.00 |
| Method | (1) Image hashing only | ||
| Result | Identified | Unidentified | Misidentified |
| HoG | 3.4% | - | 96.6% |
| BinaryGAN | 7.4% | - | 92.6% |
| Proposed | 8.2% | - | 91.8% |
| Method | (2) Image RoI detection + Image hashing | ||
| Result | Identified | Unidentified | Misidentified |
| HoG | 79.4% | - | 20.6% |
| BinaryGAN | 83.1% | - | 16.9% |
| Proposed | 88.7% | - | 11.3% |
| Method | (3) Image RoI detection + Image hashing + Image verification | ||
| Result | Identified | Unidentified | Misidentified |
| HoG | 79.4% | 16.4% | 4.2% |
| BinaryGAN | 83.1% | 13.6% | 3.3% |
| Proposed | 88.7% | 8.5% | 2.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Heo, S.; Kang, J.; Kang, H.; Lee, S. A Photo Identification Framework to Prevent Copyright Infringement with Manipulations. Appl. Sci. 2021, 11, 9194. https://doi.org/10.3390/app11199194
Kim D, Heo S, Kang J, Kang H, Lee S. A Photo Identification Framework to Prevent Copyright Infringement with Manipulations. Applied Sciences. 2021; 11(19):9194. https://doi.org/10.3390/app11199194
Chicago/Turabian StyleKim, Doyoung, Suwoong Heo, Jiwoo Kang, Hogab Kang, and Sanghoon Lee. 2021. "A Photo Identification Framework to Prevent Copyright Infringement with Manipulations" Applied Sciences 11, no. 19: 9194. https://doi.org/10.3390/app11199194
APA StyleKim, D., Heo, S., Kang, J., Kang, H., & Lee, S. (2021). A Photo Identification Framework to Prevent Copyright Infringement with Manipulations. Applied Sciences, 11(19), 9194. https://doi.org/10.3390/app11199194