
Development of Intellectual Web System for Morph Analyzing of Uzbek Words




Abstract
:1. Introduction
Relevance of the Paper
2. Related Works
2.1. UzMor
- Step 1. The word is searched in the dictionary of initial forms. If the word is found in the dictionary, then the program goes to step 4.
- Step 2. The word is read character by character in reverse order (starting from the end of the word) and truncated with the longest matching affixes until it truncates three affixes. Regardless of the number of truncated morphemes, the program will proceed to the next (3rd) step.
- Step 3. The search for the stem of the word is performed, based on the stemming results from the previous step. If the program finds a match for the stem of a word from the stem base, then it goes to step # 4, and if not, it returns to step # 2 *.
- Step 4. A dictionary is returned to the user, consisting of the stem of the word and truncated affixes.
2.2. Uz-Kaz-Nlp-Tools (UKNT)
- Step 1. Wordform is fed to the input.
- Step 2. The program starts stemming the sent word from right to left (from the end). In this case, the endings are truncated as long as the program sees matches of substrings of a word with affixes from the endings base.
- Step 3. The program makes stemmatizations three times, and as a result, there will be three truncated versions of the original word.
- Step 4. UKNT selects the largest dictionary according to quantity of truncated morphemes and returns that as the most correct result.
2.3. Suggested Solution
3. Rules of Word Generation
3.1. Form of Nouns
- Quantity (singular or plural form);
- Affiliation (possessive affixes);
- Declension (case affixes).
3.2. Form of Verbs
- (1)
- Indicative;
- (2)
- Imperative;
- (3)
- Conditional.
- (1)
- Present–future tense (PF tense);
- (2)
- Present continuous (PC tense).
- (1)
- Root verb (RV) + yap + personal affix (PA) = yoz + yap + man = yozyapman (I am writing).
- (2)
- RV + moqda + PA = o‘qi + moqda + san = o‘qimoqdasan (You are reading).
- (3)
- RV + a/y + yotir + PA = yoz + a + yotir + man = yozayotirman (I am writing).
3.3. Form of Adjectives
- From nouns (by adding such affixes as: xush-, bad-, ser-, ba-, be-, bar, e.g.);
- From verbs (by adding such affixes as: -choq, -chak, -chiq, -gir, e.g.);
- From merge of two words, which belong to different parts of speech:
- o
- Noun + noun: sher (lion) + yurak (heart) = sheryurak (brave);
- o
- Adjective + noun: qimmat (expensive) + baho (valuable) = qimmatbaho (precious);
- o
- Adverb + verb + {-ar}: tez (fast) + oqar (to flow) = tezoqar (fast-flowing);
- o
- Adverb + noun: yarim (half) + avtomat (automatic) = yarimavtomat (semiautomatic).
3.4. Form of Adverbs
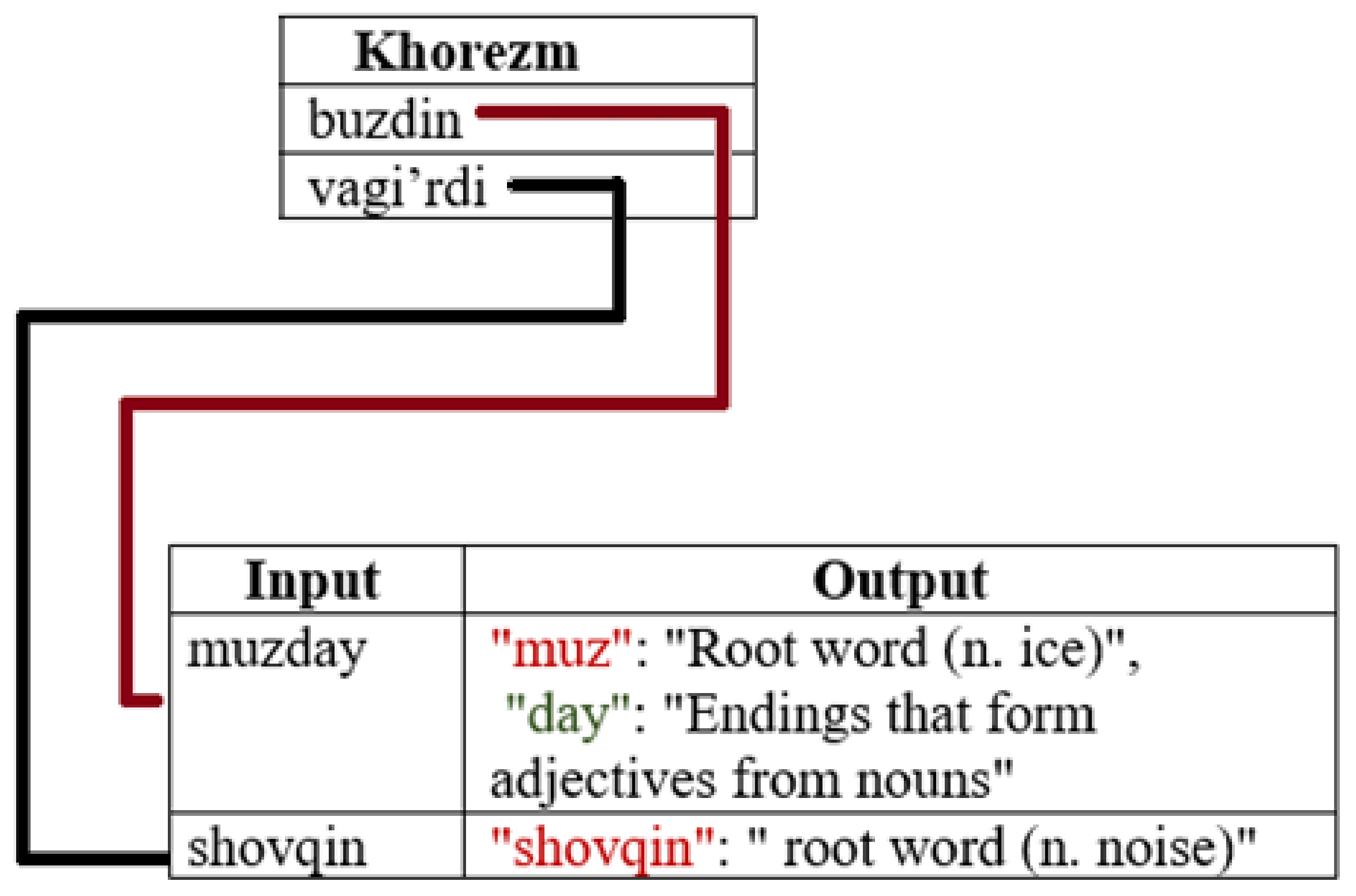
3.5. Exceptions
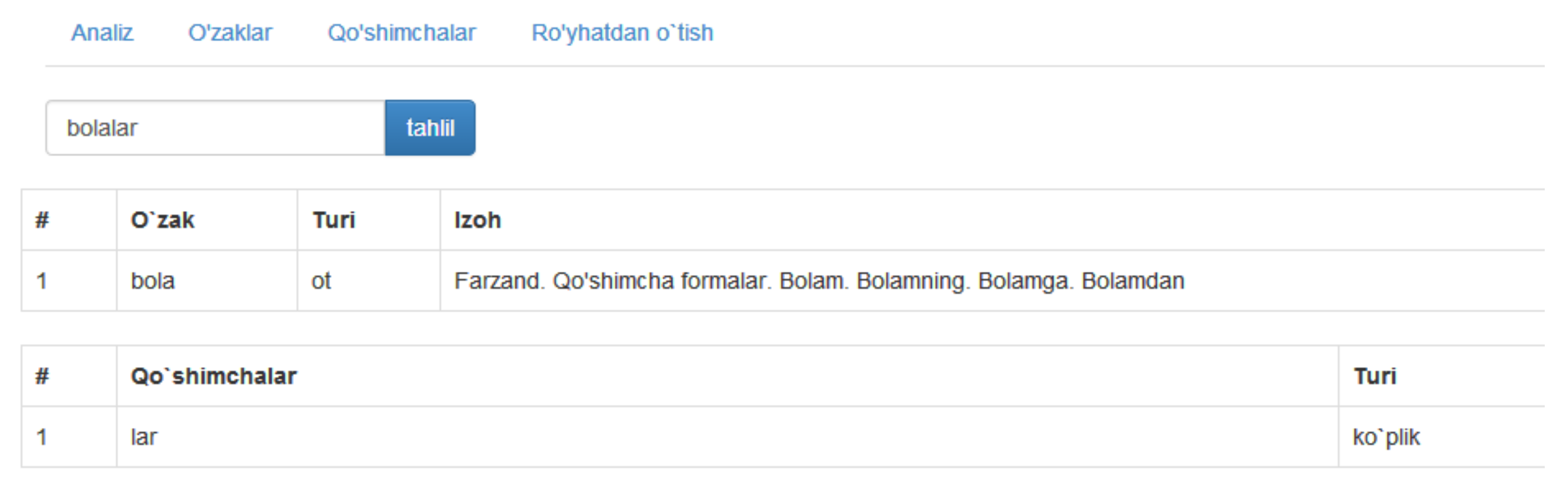
4. Algorithm Implementation and Testing
4.1. System Description
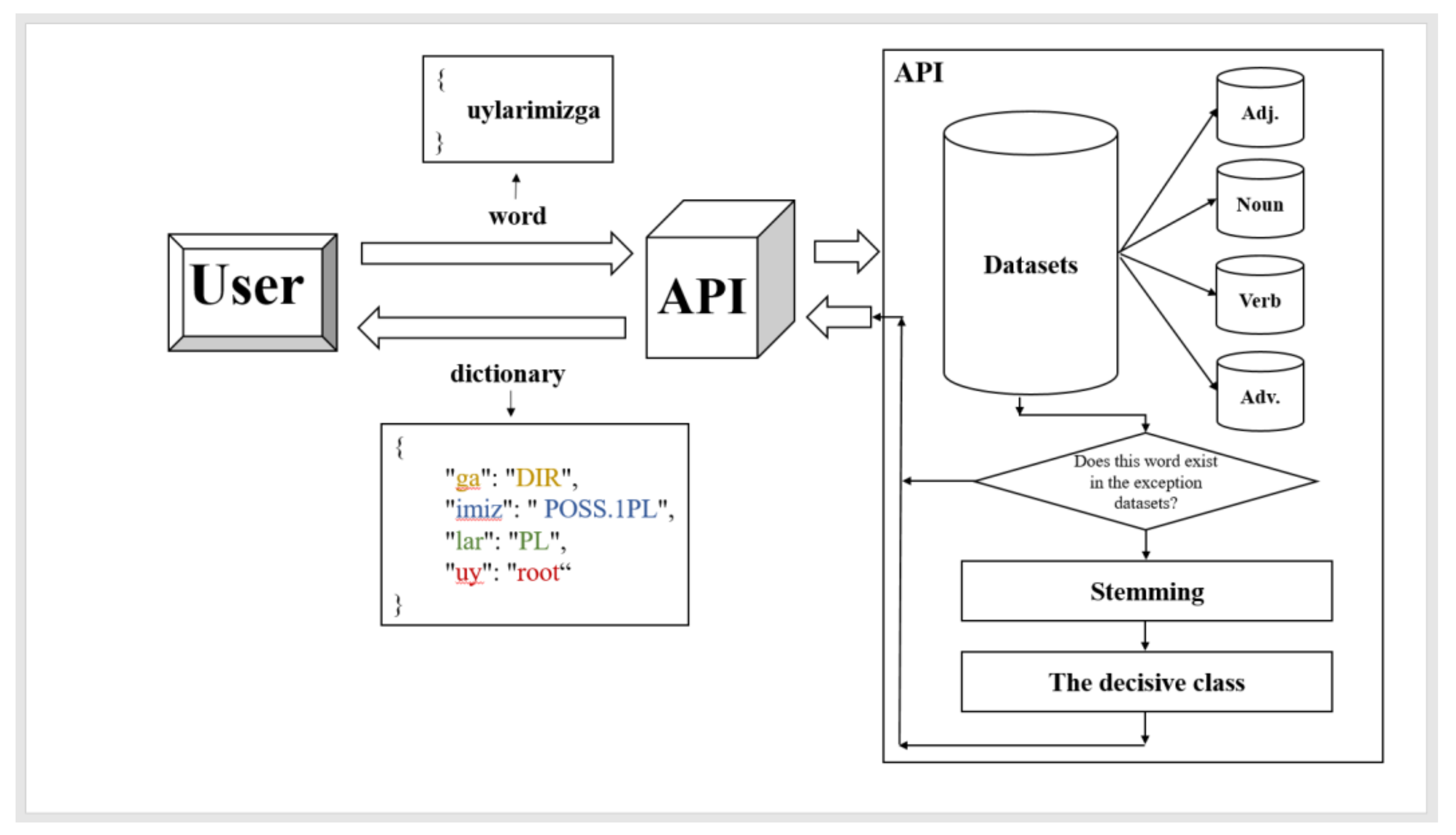
- Step 1. To start the ball rolling, a word is sent to the server.
- Step 2. Firstly, the word is checked in the exception word sets, if the result is positive, the system returns the prepared answer (morphologically analyzed word) to the user. If the search’s result is negative, then the system starts the stemming of the word.
- Step 3. When stemming starts, the algorithm first searches for endings from right to left and, then, at the end, checks the prefixed endings (that is, from left to right).
- Step 4. In this stage, the system forms dictionaries of truncated endings from each part of speech and, then, sends them to the decisive class.
- Step 5. The decisive class compares the composition of the dictionaries of truncated endings. Depending on which dictionary with endings will be larger (quantity of truncated endings), the sent word will belong to that part of speech.
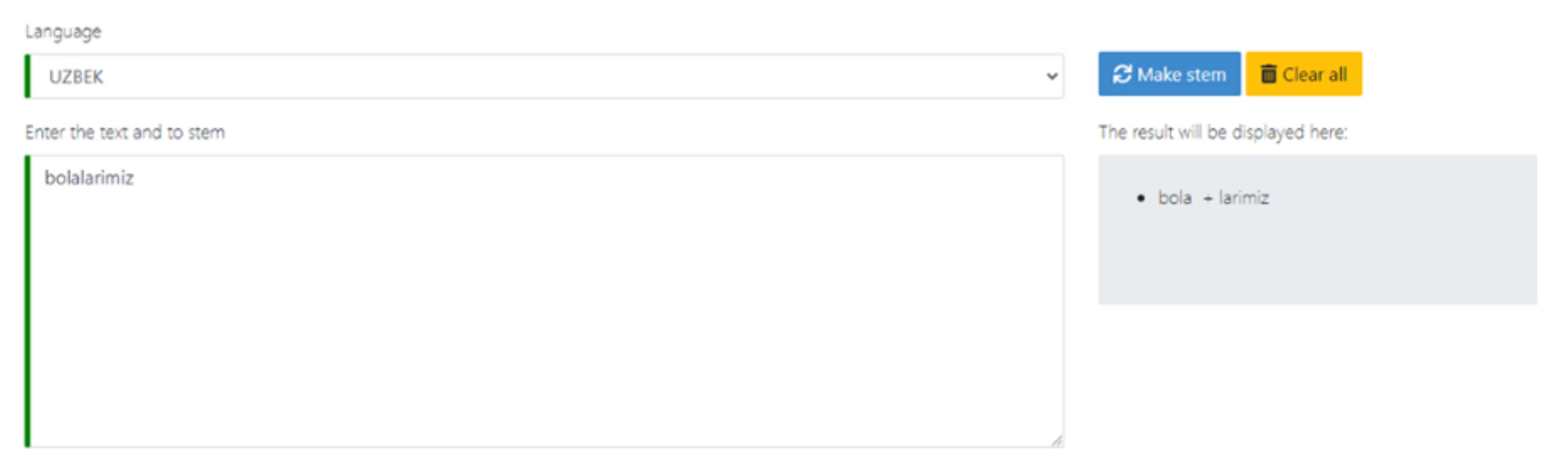
- Step 1. The word uylarimizga is sent to the server.
- Step 2. Since there are no such words in the exception dictionaries, the system will pass it on to the next stage.
- Step 3. Stemming of the word begins; the system uses specific libraries of endings, in order to perform truncation of the word. So, it finds those endings from:
- Noun endings library: uy (N (home)- root) + lar (plural) + imiz (possessive) + ga (Dative-directional case).
- Adjective endings library: nothing will be found.
- Verb endings library: uy (verb (to gather) − root) + lar (plural) + i (unknown) + miz (personal affix of plural form) + ga (unknown).
- Adverb endings library: nothing will be found.
- Step 4. At this stage, the system forms a large dictionary, which contains other smaller dictionaries obtained from the previous stage (noun, adjective, verb, and adverb).
- Step 5. The system starts iterating over the large dictionary obtained from stage 4. Four dictionaries with truncated endings and a word root in each one is searched. According to the calculation, the verbs’ dictionary has more key-value pairs of endings, but the program only counts known endings. So, the system will choose the dictionary, which contains the biggest number of known morphemes. As a result, the number of truncated endings in the noun dictionary significantly exceeds the number of other dictionaries’ endings. Thus, the dictionary of nouns is taken as the most appropriate, and the system accepts the original word uylarimizga as a noun with its endings.
4.2. Algorithm Implementation and Testing
5. Problems and Solution
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jurayeva, N.; Sultanov, R.; Abdullayeva, S.; Rakhimjonova, V. Systematization of word combinations in the uzbek language. Sci. World 2020, 6, 65–68. [Google Scholar]
- Durdona, E. Official style of uzbek language. Int. J. Word Art 2019, 1, 3–11. [Google Scholar]
- Population, Total—Uzbekistan, Azerbaijan, Turkey, Turkmenistan, Kazakhstan, Tajikistan, Kyrgyz Republic. Available online: https://data.worldbank.org/indicator/SP.POP.TOTL?locations=UZ-AZ-TR-TM-KZ-TJ-KG&view=map (accessed on 20 September 2021).
- Barakhnin, V.B.; Fedotov, A.M.; Bakiyeva, A.M.; Bakiyev, M.N.; Tazhibayeva, S.Z.; Batura, T.V.; Lukpanova, L.K. The software system for the study the morphology of the Kazakh language. In Proceedings of the ICPE 2017 International Conference on Psychology and Education, Moscow, Russia, 8–9 June 2017; pp. 18–27. [Google Scholar]
- Ismatullayev, X. Samouchitel Uzbekskogo Yazyika. Tashkent: Tashkent, Uzbekistan, 1991; pp. 129–131. [Google Scholar]
- Abdurakhmonova, N. Modeling analitic forms of verb in Uzbek as stage of morphological analysis in machine translation. Iran. J. Soc. Sci. Humanit. Res. 2017, 5, 3–5. [Google Scholar]
- Abdurakhmonova, N. Ontological model of uzbek language (as example morphology). In Proceedings of the XV International Conference on Computational and Cognitive Linguistics TEL-2018, Kazan, Russia, 31 October–3 November 2020; pp. 5–11. [Google Scholar]
- Barakhnin, V.B.; Fedotov, A.M.; Bakieva, A.M.; Bakiev, M.N.; Tazhibaeva, S.Z.; Batura, T.V.; Kozhemyakina, O.Y.; Tusupov, D.A.; Sambetbaeva, M.A.; Lukpanova, L.K. Algoritmi generatsii i stemmatizatsii slovoform Kazakhskogo yazyka. Cloud Sci. 2017, 4, 434–449. [Google Scholar]
- Kozhemyakina, O.Y.; Tagirova, E.P. The translation algorithm from pre-reform spelling into modern spelling, taking into account the morphology of words. J. Phys. Conf. Ser. 2019, 1405, 1–8. [Google Scholar] [CrossRef]
- Dusmukhamedov, U.S. Razrabotka Slovarya Fonemi i Morfem Uzbekskogo Yazyka na Osnove Informasii v Uznet (Dlya Dalneyshego Vnedrenya v Google Translate). Master’s Thesis, Tashkent University of Information Technologies, Tashkent, Uzbekistan, 2018. [Google Scholar]
- Matlatipov, S.; Tukeyev, U.; Aripov, M. Towards the Uzbek Language Endings as a Language Resource. In Advances in Computational Collective Intelligence; Hernes, M., Wojtkiewicz, K., Szczerbicki, E., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Abdurakhmonova, N.; Urdishev, K. Corpus Based Teaching Uzbek as A Foreign Language. J. Foreign Lang. Teach. Appl. Linguist. 2019, 6, 131–136. [Google Scholar]
- Hushmurodova, S.H. Structural discordances of english and uzbek set expressions. J. Crit. Rev. 2020, 7, 383–385. [Google Scholar]
- Turaeva, R. Linguistic Ambiguities of Uzbek and Classification of Uzbek Dialects. Anthr. Int. Rev. Anthropol. Linguist. 2015, 110, 463–475. [Google Scholar] [CrossRef]
- Anarbaev, O. Some Aspects of Periodization of Word Formation in the Uzbek Language. Available online: http://www.rusnauka.com/pdf/280795.docx (accessed on 22 September 2021).
- Seidl, T.; Enderle, J. Binary Search. In Algorithms Unplugged; Vöcking, B., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 5–11. [Google Scholar]
- Porter, M. The Porter Stemming Algorithm. 1980. Available online: http://tartarus.org/martin/PorterStemmer/ (accessed on 22 September 2021).
- Madrahimov, O. Ozbek Tili Oğuz Lakhjasining Khiva Shevasi (Khiva Sub-dialect of Oguz Dialect of the Uzbek Language); Obdolov Regional Press: Urgench, Uzbekistan, 1999; Available online: http://www.rusnauka.com/pdf/275155.pdf (accessed on 22 September 2021).
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet Physics Doklady; Russian Academy of Sciences: Moscow, Russia, 1966; Volume 10, pp. 707–710. [Google Scholar]
- Mengliev, D.; Barakhnin, V.; Abdurakhmonova, N. Morphoanalyzer. Available online: https://github.com/shogunuz/Morphoanalyzer (accessed on 12 August 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positives | Negatives |
|---|---|
| 1. The presence of a large base of bases (20,000) | 1. Can only recognize and analyze nouns |
| 2. The presence of a base of endings, which allows you to generate ~120 combinations of word forms | 2. Limited set of affixes |
| 3. Having loops to choose the best combination of affixes | 3. Absence of a base of word forms—exceptions |
| Positives | Negatives |
|---|---|
| 1. The presence of a base of endings, which allows you to generate ~665 combinations of word forms | 1. Only works for nouns and verbs |
| 2. The presence of 3 cycles to choose the best combination of affixes | 2. Lack of a base of basics |
| 3. Having loops to choose the best combination of affixes | 3. Absence of a base of word forms—exceptions |
| Positives | Negatives |
|---|---|
| 1. The presence of a base of word stems | 1. Poorly copes with informal word forms |
| 2. The presence of a base of endings, which allows you to generate more than 400 combinations of word forms | |
| 3. Works for all major parts of speech | |
| 4. The presence of a base of words—exceptions | |
| 5. Availability of a database of words of Oghuz Uzbek |
| Singular | Plural |
|---|---|
| bola (a boy) | bolalar (boys) |
| qiz (a girl) | qizlar (girls) |
| odam (a human) | odamlar (humans) |
| The Last Letter of Noun Is Vowel | The Last Letter of Noun Is Consonant | ||
|---|---|---|---|
| Singular Affixes | Plural Affixes | Singular Affixes | Plural Affixes |
| -m, -ng, -si | -miz, -ngiz, -(lar)i | -im, -ing, -i | -imiz, -ingiz, -(lar)i |
| # | Grammar Cases | Affixes |
|---|---|---|
| 1. | Nominative | - |
| 2. | Genitive | -ning |
| 3. | Accusative | -ni |
| 4. | Dative | -ga, -ka, -qa |
| 5. | Locative | -da |
| 6. | Ablative | -dan |
| # | Grammar Cases | Affixes | ||||
|---|---|---|---|---|---|---|
| Singular Form | ||||||
| Root Word + y | Personal Affix | Result | Root Word + a | Personal Affix | Result | |
| 1. | yasha + y | man | yashayman (I live\I will live) | o‘rgan + a | man | o‘rganaman (I study\I will study) |
| 2. | yasha + y | san | yashaysan (You live\you will live) | o‘rgan + a | san | o‘rganasan (You study\You will study) |
| 3. | yasha + y | di | yashaydi (he lives\she will live) | o‘rgan + a | di | o‘rganadi (He studies\She will study) |
| Plural Form | ||||||
| Root Word + y | Personal Affix | Result | Root Word + a | Personal Affix | Result | |
| 1. | yasha + y | miz | yashaymiz (We live\We will live) | o‘rgan + a | miz | o‘rganamiz (We study\We will study) |
| 2. | yasha + y | siz | yashaysiz (You live\You will live) | o‘rgan + a | siz | o‘rganasiz (You study\You will study) |
| 3. | yasha + y | dilar | yashaydilar (They live\They will live) | o‘rgan + a | dilar | o‘rganadilar (They study\They will study) |
| Root Verb | -di Affix | Personal Affix | Result | Translation | |
|---|---|---|---|---|---|
| Singular form | |||||
| 1. | ishla | -di | -m | Ishladim | I worked |
| 2. | -ng | Ishlading | You worked | ||
| 3. | - | Ishladi | She\He worked | ||
| plural form | |||||
| 1. | ishla | -di | -k | Ishladik | We worked |
| 2. | -ngiz | Ishladingiz | You worked | ||
| 3. | -lar | Ishladilar | They worked | ||
| # | Grammar Cases | Affixes |
|---|---|---|
| 1. | Nominative | - |
| 2. | Genitive | -ning |
| Root | Affix | Result | Translation | |
|---|---|---|---|---|
| 1. | do‘stlar (friends) | -cha | do‘stlarcha | friendly |
| 2. | qahramon (hero) | -chasiga | qahramonchasiga | heroically |
| 3. | kecha (yesterday) sen (you) | -dek -day | kechadek senday | as yesterday as you |
| 4. | tonna (ton) | -lab | tonnalab | in tons |
| Input | Output | ||
|---|---|---|---|
| Dadamlar | Dada | M | lar |
| Word | root—noun | possessive affix | affix of plural form |
| Input | Output | |||
|---|---|---|---|---|
| Muzlatgich | muz- | -la | -t | -gich |
| Word | root—noun | root—verb | voice | ending, which forms noun from verb |
| id | Input | Output |
|---|---|---|
| 1. | uylarimizga | “ga”: “DIR”, “imiz”: “ POSS.1PL”, “lar”: “PL”, “uy”: “root” |
| 2. | telefoningizga | “ga”: “Dative-directional case (To whom? What? Why? Where?): bolaga, kitobga”, “ingiz”: “2nd person, consonant endings, plural: uy-ingiz, kitob-ingiz” ,“telefon”: “Root word (noun)” |
| 3. | xushhavo | “xush”: “Endings that form adjectives from nouns: xushfe’l, xushhavo”, “havo”: “Root word (noun)” |
| id | Input | Output |
|---|---|---|
| 1. | bahorgi | “bahor”: “Root word (n. spring)”, “gi”: “Endings that form adjectives from nouns: bahorgi (adj. spring)” |
| 2. | kelinchak | “kelin”: “ root word (bride)”, “chak”: “ this ending is used as an affectionate” |
| 3. | dadamlar | “dada”: “root word (father)”, “m”: “ auxiliary particle”, “lar”: “ this ending is used as an affectionate, not as an plural ending” |
| id | Input | Output |
|---|---|---|
| 1 | asal | “asal”: “Root word”“ |
| 2 | David | “david”: “Root word” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mengliev, D.; Barakhnin, V.; Abdurakhmonova, N. Development of Intellectual Web System for Morph Analyzing of Uzbek Words. Appl. Sci. 2021, 11, 9117. https://doi.org/10.3390/app11199117
Mengliev D, Barakhnin V, Abdurakhmonova N. Development of Intellectual Web System for Morph Analyzing of Uzbek Words. Applied Sciences. 2021; 11(19):9117. https://doi.org/10.3390/app11199117
Chicago/Turabian StyleMengliev, Davlatyor, Vladimir Barakhnin, and Nilufar Abdurakhmonova. 2021. "Development of Intellectual Web System for Morph Analyzing of Uzbek Words" Applied Sciences 11, no. 19: 9117. https://doi.org/10.3390/app11199117
APA StyleMengliev, D., Barakhnin, V., & Abdurakhmonova, N. (2021). Development of Intellectual Web System for Morph Analyzing of Uzbek Words. Applied Sciences, 11(19), 9117. https://doi.org/10.3390/app11199117