
EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning


Abstract
:1. Introduction
- We propose an encoder, utilizing residual learning with improved stem block. This method improves accuracy with a simple operation, can reuse pre-trained weights, and is applicable to other segmentation models;
- We propose a lightweight ASPP utilizing DSConv to minimize the computation costs without degrading accuracy;
- We propose a new efficient decoder combining DSConv and interpolation to achieve a good balance between accuracy and computation costs.
2. Related Work
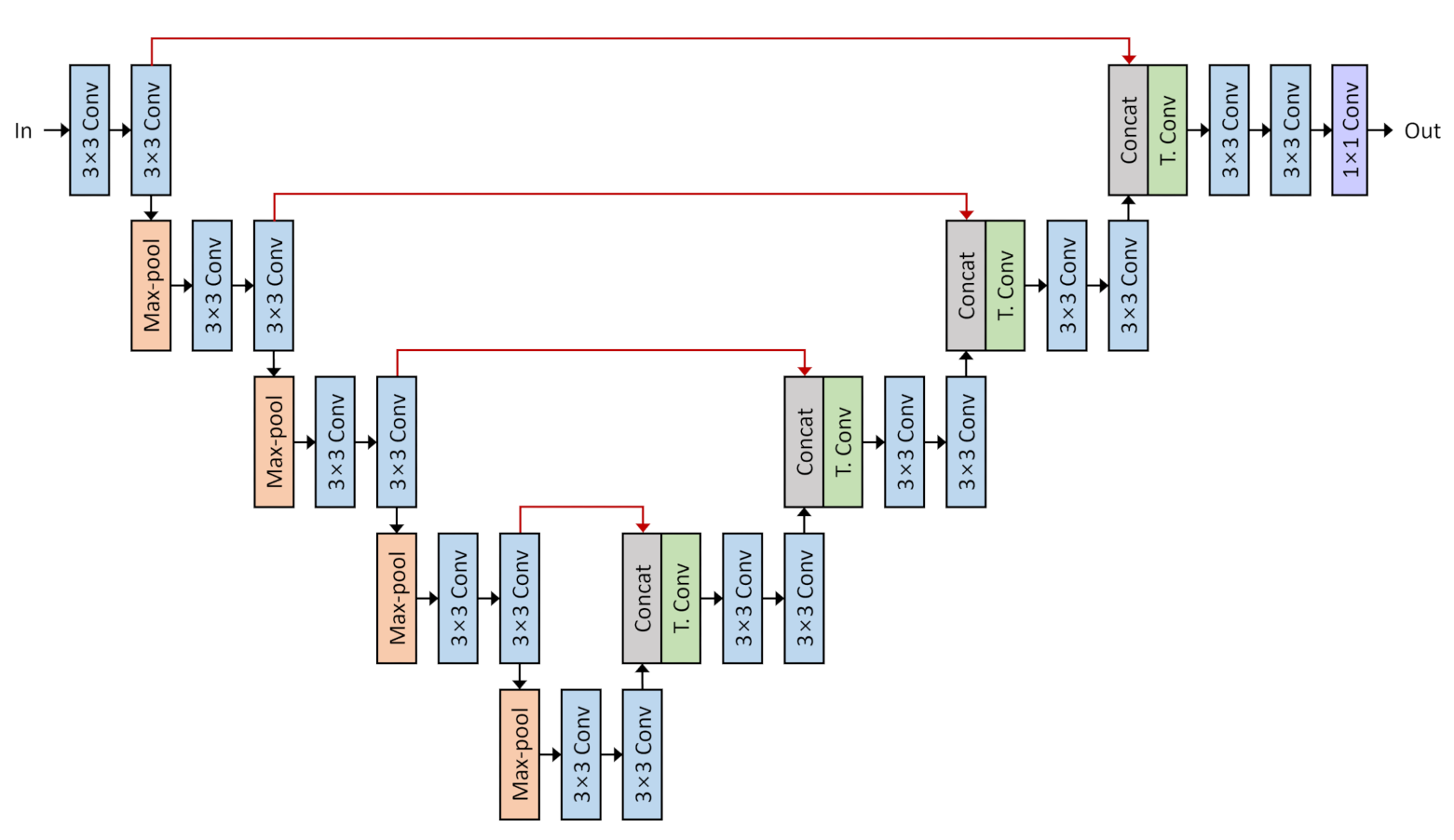
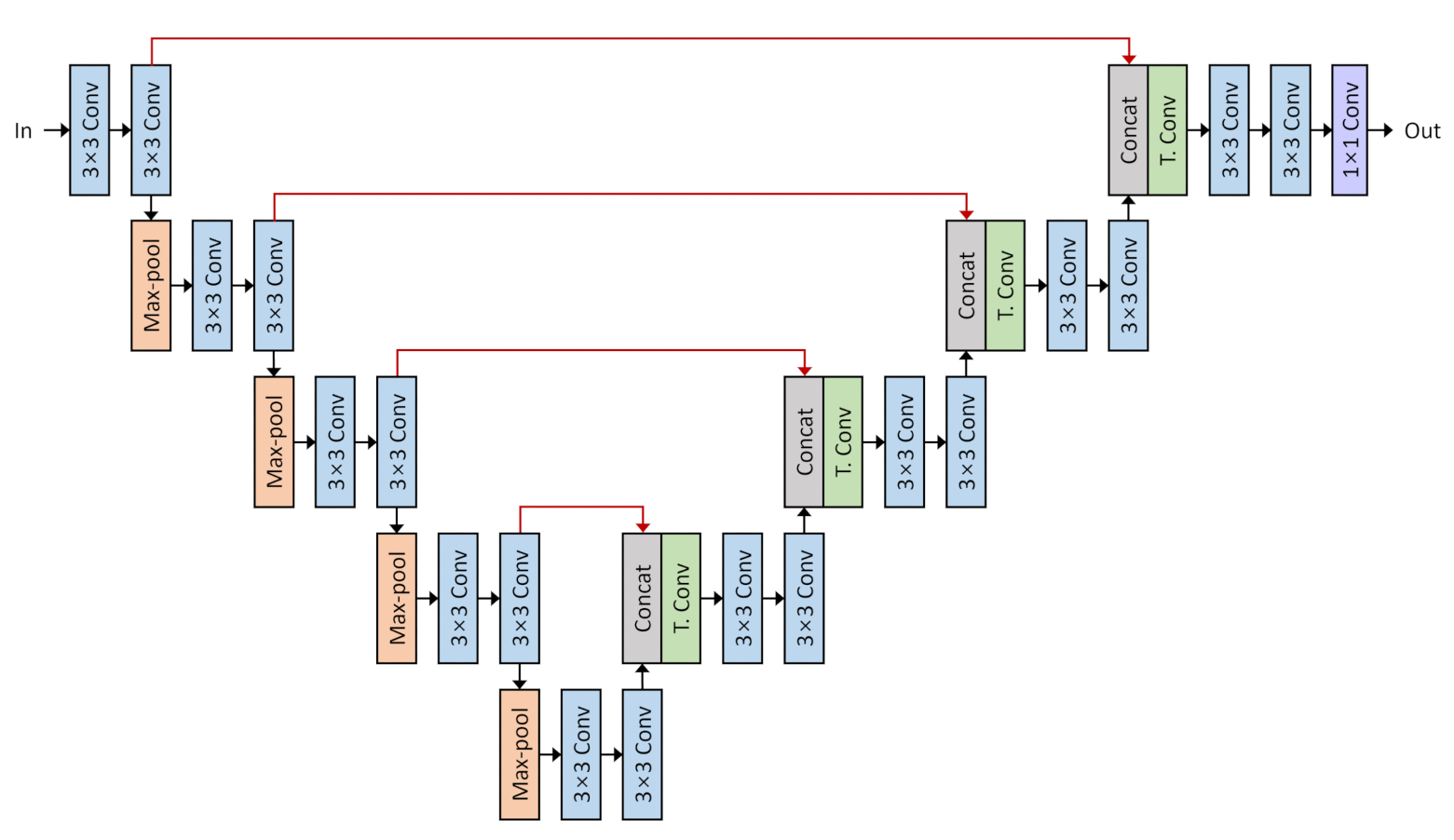
2.1. U-Net
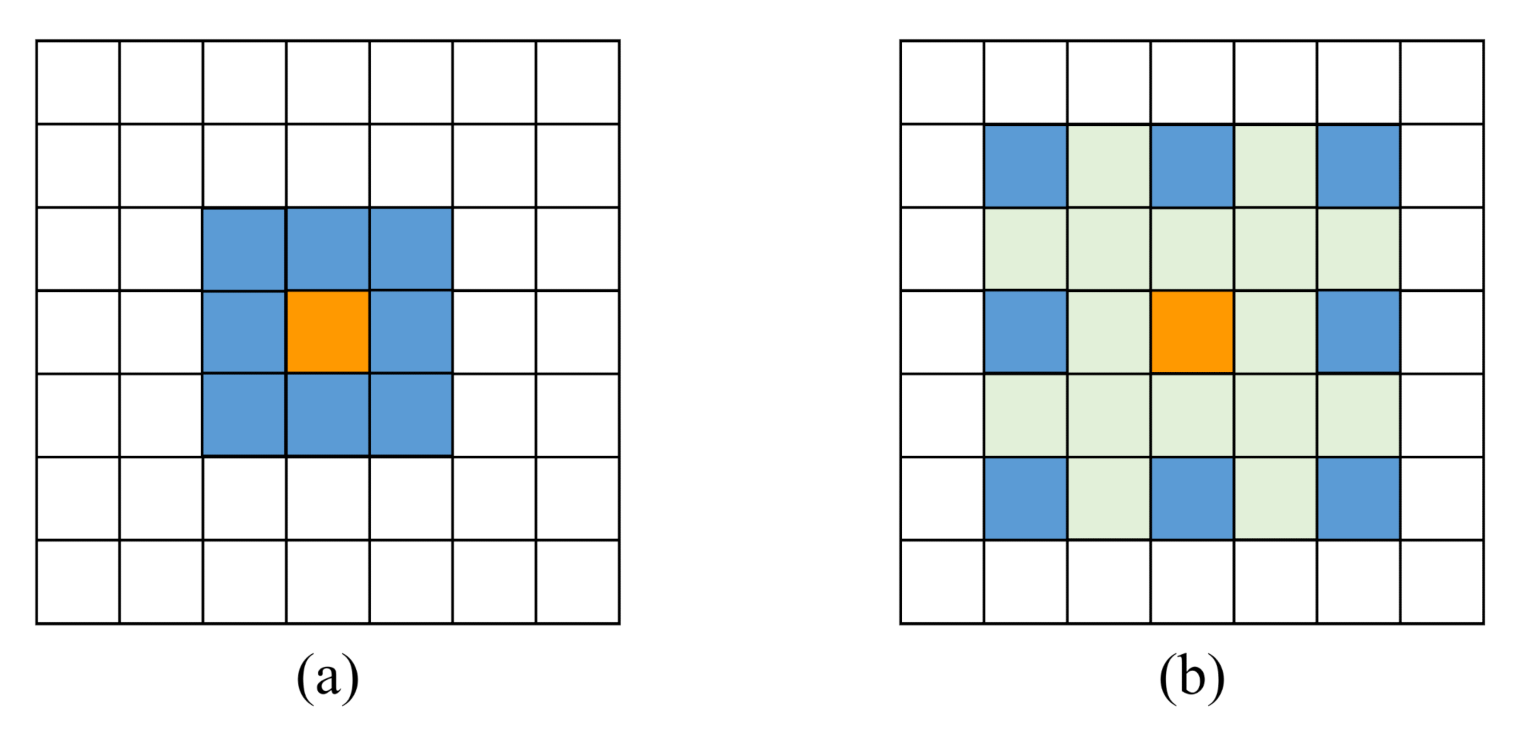
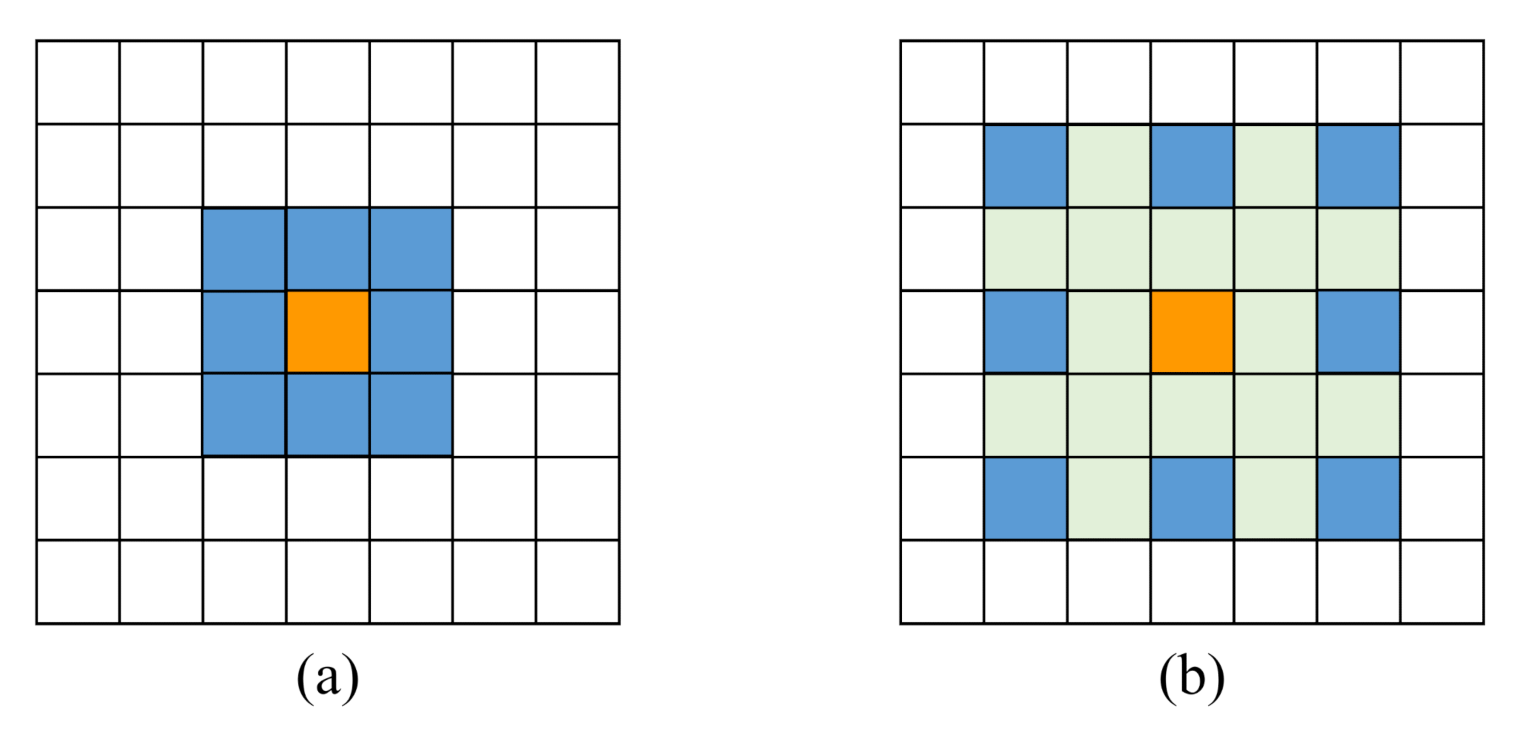
2.2. Atrous Convolution
2.3. Depthwise Separable Convolution
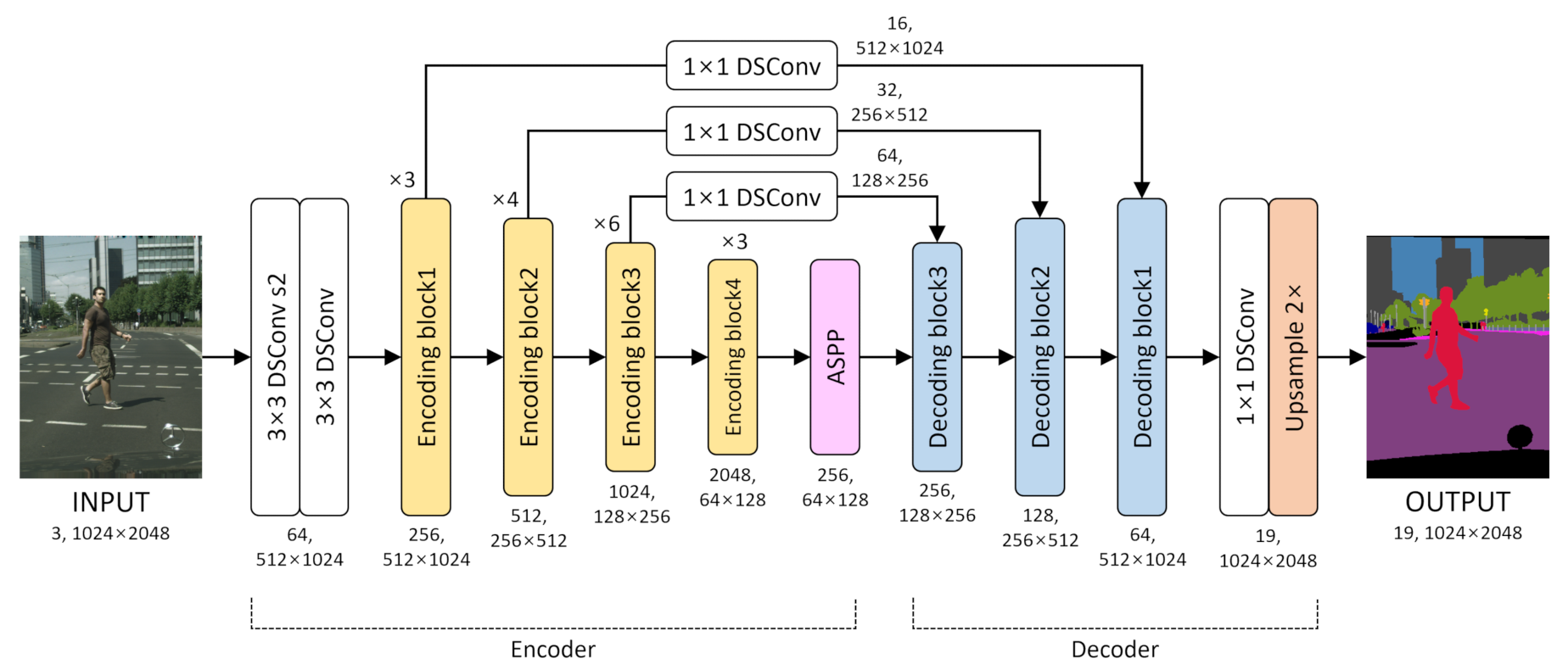
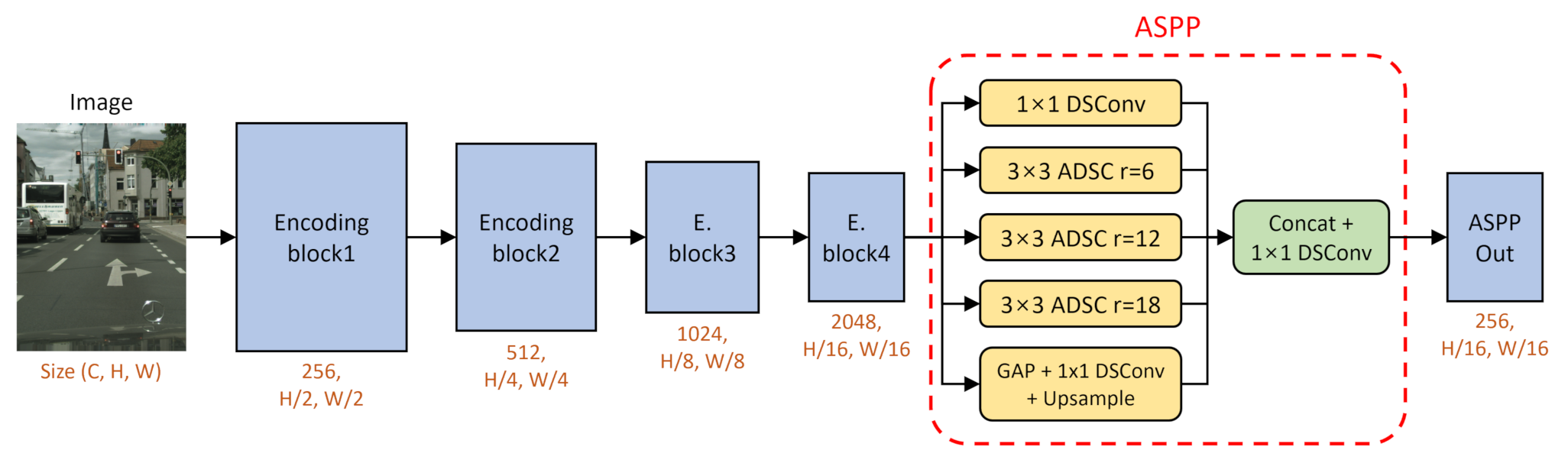
3. Proposed Method
3.1. Encoder for Extracting Features
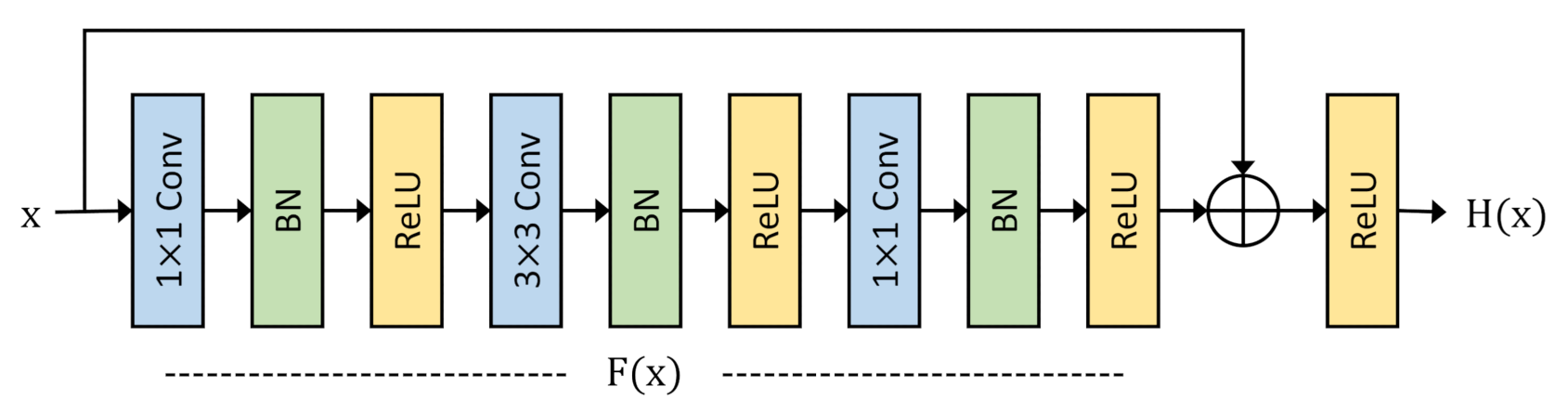
3.1.1. Residual Learning
3.1.2. Atrous Spatial Pyramid Pooling
3.2. Decoder for Precise Segmentation
3.3. Loss Function
4. Results and Discussion
4.1. Implementation Details
4.2. Dataset and Experiment Results
4.3. Ablation Study
4.3.1. ASPP Analysis
4.3.2. DSConv Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EAR-Net | Efficient atrous residual network |
| DSConv | Depthwise separable convolution |
| ASPP | Atrous spatial pyramid pooling |
| CNN | Convolutional neural networks |
| FCN | Fully convolutional networks |
| BN | Batch normalization |
| ReLU | Rectified linear unit |
| ADSC | Atrous depthwise separable convolution |
| GAP | Global average pooling |
References
- Shin, S.; Han, H.; Lee, S.H. Improved YOLOv3 with duplex FPN for object detection based on deep learning. Int. J. Electr. Eng. Educ. 2021. [Google Scholar] [CrossRef]
- Shang, G.; Liu, G.; Zhu, P.; Han, J.; Xia, C.; Jiang, K. A Deep Residual U-Type Network for Semantic Segmentation of Orchard Environments. Appl. Sci. 2020, 11, 322. [Google Scholar] [CrossRef]
- Ciprián-Sánchez, J.; Ochoa-Ruiz, G.; Rossi, L.; Morandini, F. Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation. Appl. Sci. 2021, 11, 7046. [Google Scholar] [CrossRef]
- Han, H.-Y.; Chen, Y.-C.; Hsiao, P.-Y.; Fu, L.-C. Using Channel-Wise Attention for Deep CNN Based Real-Time Semantic Segmentation With Class-Aware Edge Information. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1041–1051. [Google Scholar] [CrossRef]
- Sun, Y.; Gao, W.; Pan, S.; Zhao, T.; Peng, Y. An Efficient Module for Instance Segmentation Based on Multi-Level Features and Attention Mechanisms. Appl. Sci. 2021, 11, 968. [Google Scholar] [CrossRef]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lv, Y.; Ma, H.; Li, J.; Liu, S. Attention Guided U-Net With Atrous Convolution for Accurate Retinal Vessels Segmentation. IEEE Access 2020, 8, 32826–32839. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-Net-Based Semantic Segmentation of Small Objects in Urban Remote Sensing Images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Luo, Z.; Zhang, Y.; Zhou, L.; Zhang, B.; Luo, J.; Wu, H. Micro-Vessel Image Segmentation Based on the AD-UNet Model. IEEE Access 2019, 7, 143402–143411. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convo-lutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Intell. Robot. Appl. 2018, 34, 833–851. [Google Scholar]
- Sovetkin, E.; Achterberg, E.J.; Weber, T.; Pieters, B.E. Encoder–Decoder Semantic Segmentation Models for Electroluminescence Images of Thin-Film Photovoltaic Modules. IEEE J. Photovolt. 2021, 11, 444–452. [Google Scholar] [CrossRef]
- Yasutomi, S.; Arakaki, T.; Matsuoka, R.; Sakai, A.; Komatsu, R.; Shozu, K.; Dozen, A.; Machino, H.; Asada, K.; Kaneko, S.; et al. Shadow Estimation for Ultrasound Images Using Auto-Encoding Structures and Synthetic Shadows. Appl. Sci. 2021, 11, 1127. [Google Scholar] [CrossRef]
- Estrada, S.; Conjeti, S.; Ahmad, M.; Navab, N.; Reuter, M. Competition vs. Concatenation in Skip Connections of Fully Convolutional Networks. In Machine Learning in Medical Imaging, Proceedings of the International Workshop on Machine Learning in Medical Imaging, Granada, Spain, 16 September 2018; Springer: Cham, Switzerland, 2018; pp. 214–222. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Se-mantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, Y.; Li, Y.; Wang, L.; Rosing, T. Depthwise Convolution Is All You Need for Learning Multiple Visual Domains. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8368–8375. [Google Scholar] [CrossRef]
- Doi, K.; Iwasaki, A. The Effect of Focal Loss in Semantic Segmentation of High Resolution Aerial Image. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2018), Valencia, Spain, 22–27 July 2018; pp. 6919–6922. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhou, Q.; Xiong, J.; Wu, X.; Jin, X. ESNet: An Efficient Symmetric Network for Real-Time Semantic Segmentation. In Pattern Recognition and Computer Vision, Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xi’an, China, 8–11 November 2019; Springer International Publishing: Cham, Switzerland, 2019; Volume 11858, pp. 41–52. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. Lednet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Gong, X.; Liu, X.; Zhang, Q.; Li, Y.; Wang, Z. FasterSeg: Searching for Faster Real-time Semantic Segmentation. arXiv 2019, arXiv:1912.10917. [Google Scholar]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3309–3318. [Google Scholar] [CrossRef] [Green Version]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet for Real-time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 21–24 June 2021; pp. 9716–9725. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Descriptions |
|---|---|
| CPU | AMD Ryzen 3700x |
| GPU | NVIDIA RTX 3090 2× |
| RAM | 64 GB |
| OS | Ubuntu 21.04 |
| Framework | PyTorch 1.9 |
| Method | Params (M) | MIoU (%) |
|---|---|---|
| FCN [8] | 35.3 | 65.3 |
| U-Net [9] | 31.0 | 55.8 |
| SegNet [32] | 29.5 | 57.0 |
| ENet [21] | 0.4 | 57.0 |
| ESNet [33] | 1.7 | 69.1 |
| LEDNet [34] | 0.9 | 69.2 |
| DeepLabv2 [14] | 262.1 | 70.4 |
| ICNet [22] | 26.5 | 70.6 |
| FasterSeg [35] | 4.4 | 71.5 |
| FRRN [36] | - | 71.8 |
| DeepLabv3 [15] | 58.0 | 72.0 |
| STDC1 [37] | 8.4 | 72.2 |
| DeepLabv3+ [16] | 54.7 | 72.3 |
| EAR-Net | 26.8 | 72.3 |
| Method | Params (M) | MIoU (%) |
|---|---|---|
| BS | 24.3 | 67.0 |
| BS + ASPP (rate = 4, 8, 12) | 26.8 | 71.0 |
| BS + ASPP (rate = 6, 12, 18) | 26.8 | 72.3 |
| BS + ASPP (rate = 8, 16, 24) | 26.8 | 71.0 |
| Method | Params (M) | MIoU (%) |
|---|---|---|
| EAR-Net w/ traditional conv | 41.0 | 70.6 |
| EAR-Net | 26.8 | 72.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, S.; Lee, S.; Han, H. EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning. Appl. Sci. 2021, 11, 9119. https://doi.org/10.3390/app11199119
Shin S, Lee S, Han H. EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning. Applied Sciences. 2021; 11(19):9119. https://doi.org/10.3390/app11199119
Chicago/Turabian StyleShin, Seokyong, Sanghun Lee, and Hyunho Han. 2021. "EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning" Applied Sciences 11, no. 19: 9119. https://doi.org/10.3390/app11199119
APA StyleShin, S., Lee, S., & Han, H. (2021). EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning. Applied Sciences, 11(19), 9119. https://doi.org/10.3390/app11199119