
ITOC: An Improved Trie-Based Algorithm for Online Packet Classification


Abstract
:1. Introduction
1.1. Motivation and Problem Statement
1.2. Summary and Limitations of Prior Art
1.3. Technical Challenges and Proposed Approach
- Unpredictable new rule arriving time, rule contents, and arrival frequency;
- Lack of available optimization for the new work scene;
- The demand for both low update latency and high lookup speed.
- We put forward an online packet classification algorithm which has a good lookup performance;
- We design an update time prediction using rule wildness and trie status;
- We implement a trie choosing process based on update time predictions to avoid the potential high update latency.
2. Related Work
2.1. Online Packet Classification Algorithm
2.2. Classification Based on Trie
2.3. Optimizations in Trie-Based Algorithm
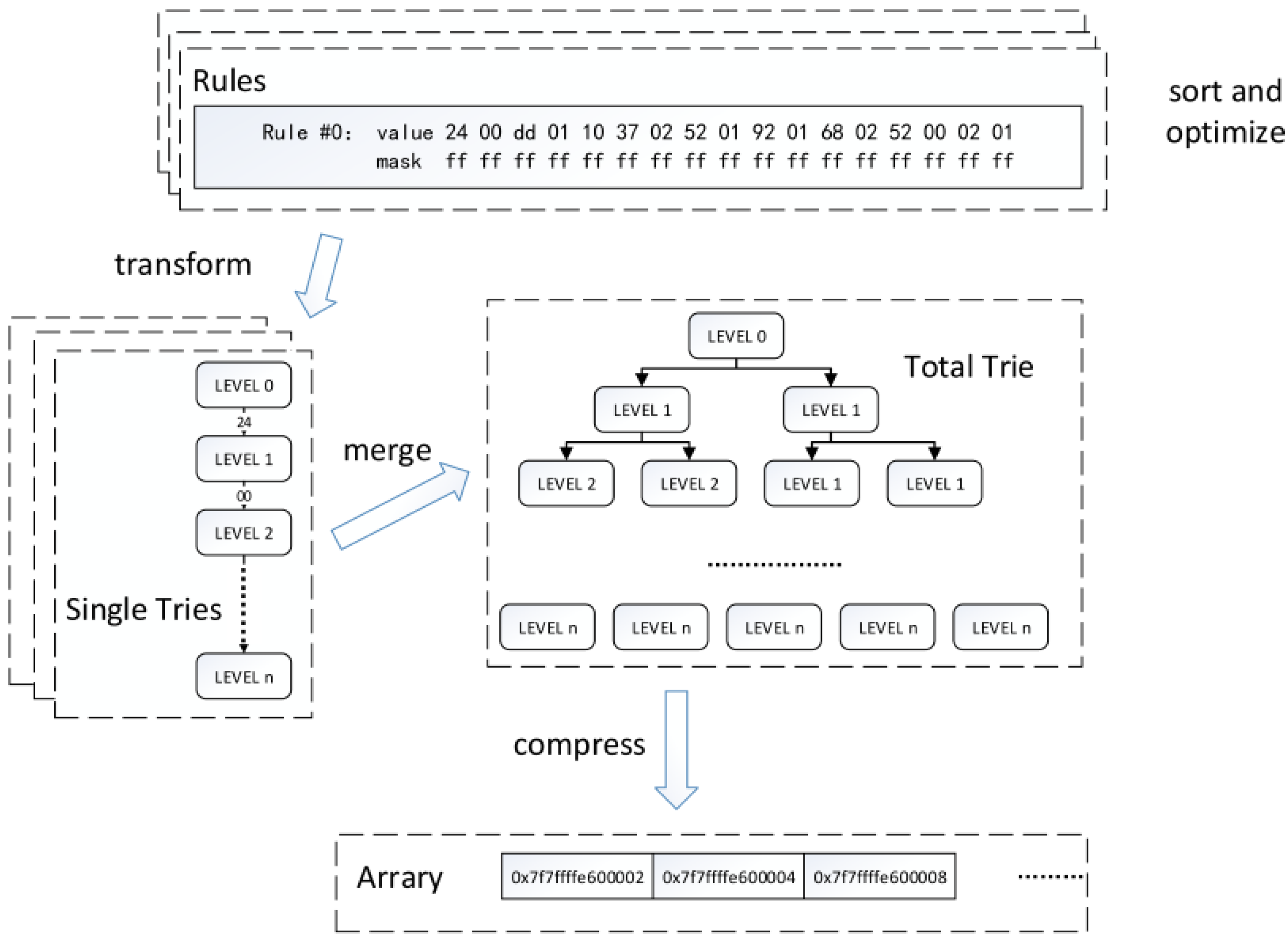
3. The Proposed Algorithm
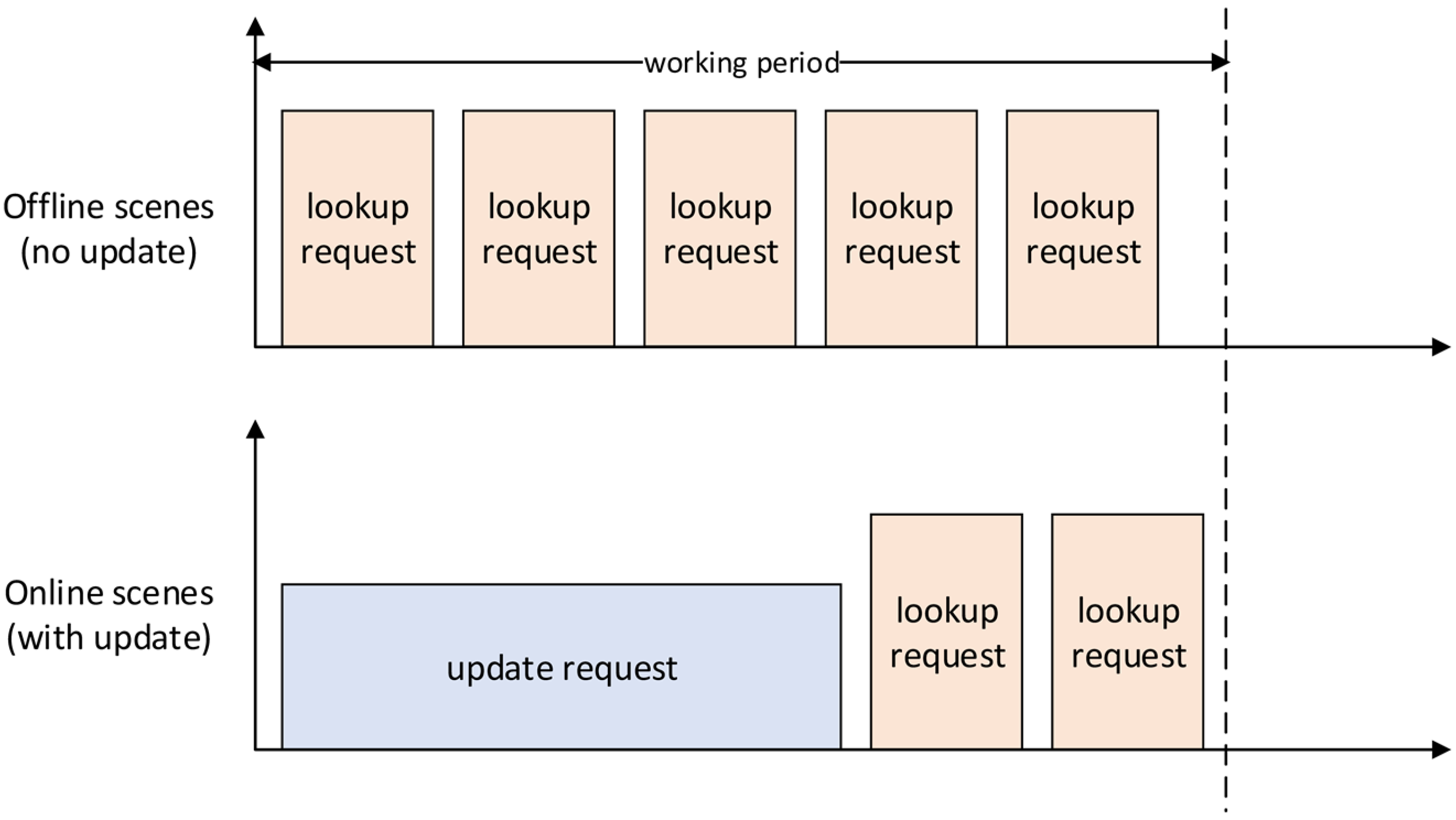
3.1. Problem and Analyzing: How to Optimize the Update Process
3.2. Update Latency Prediction
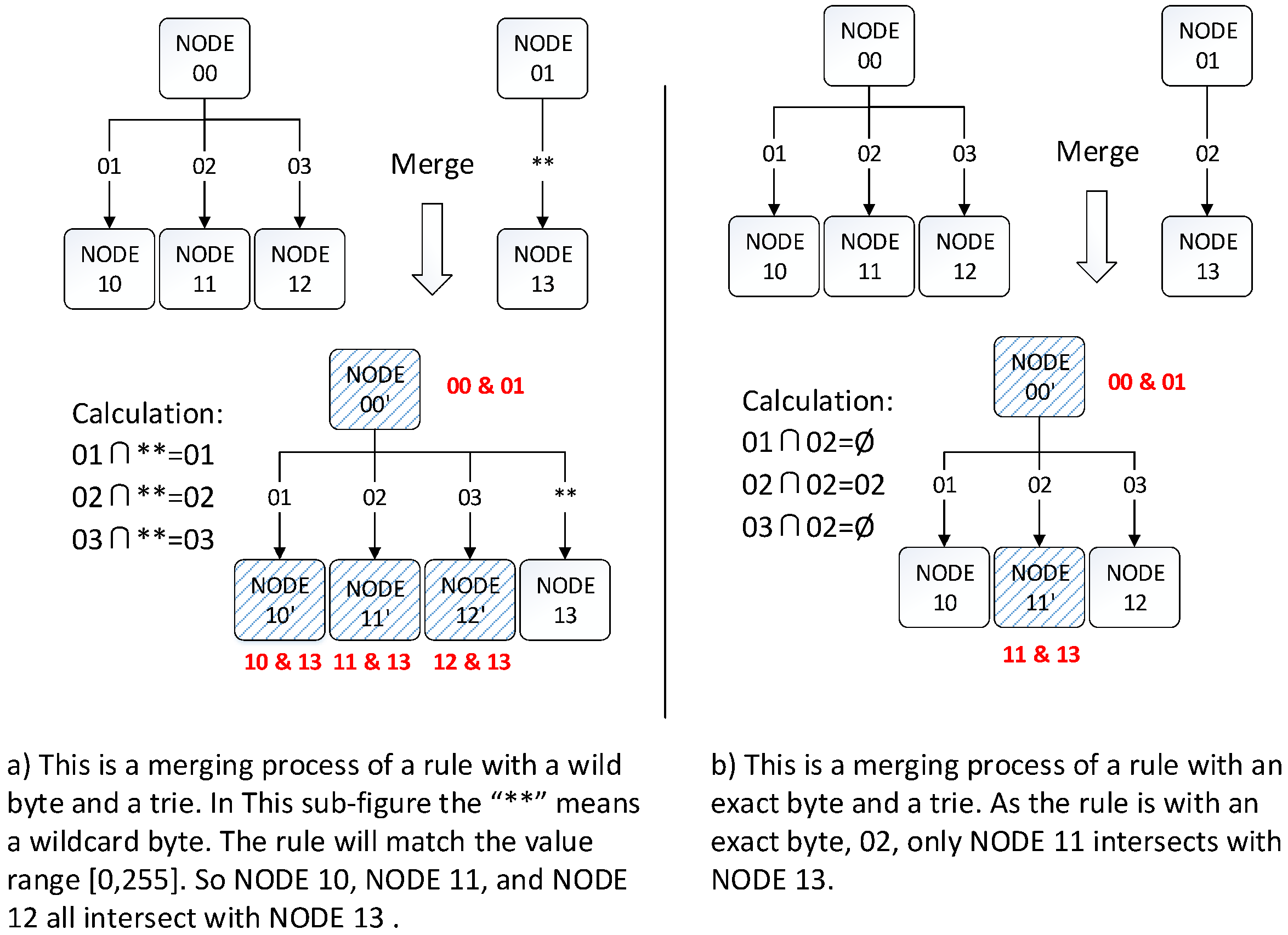
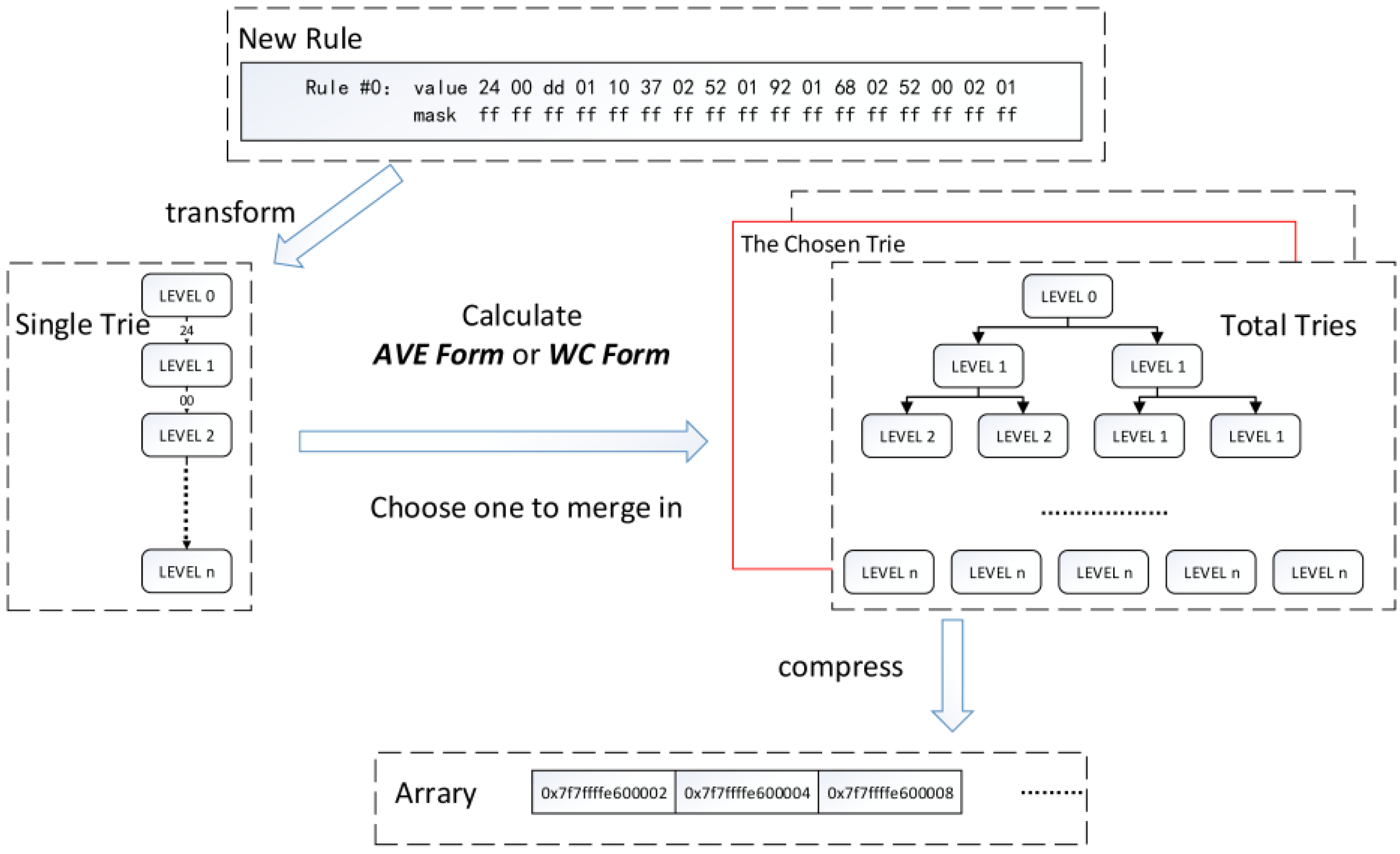
3.3. Optimization: Choose a Trie
| Algorithm 1: Insertion process with trie choosing. |
 |
3.4. Implementation in DPDK
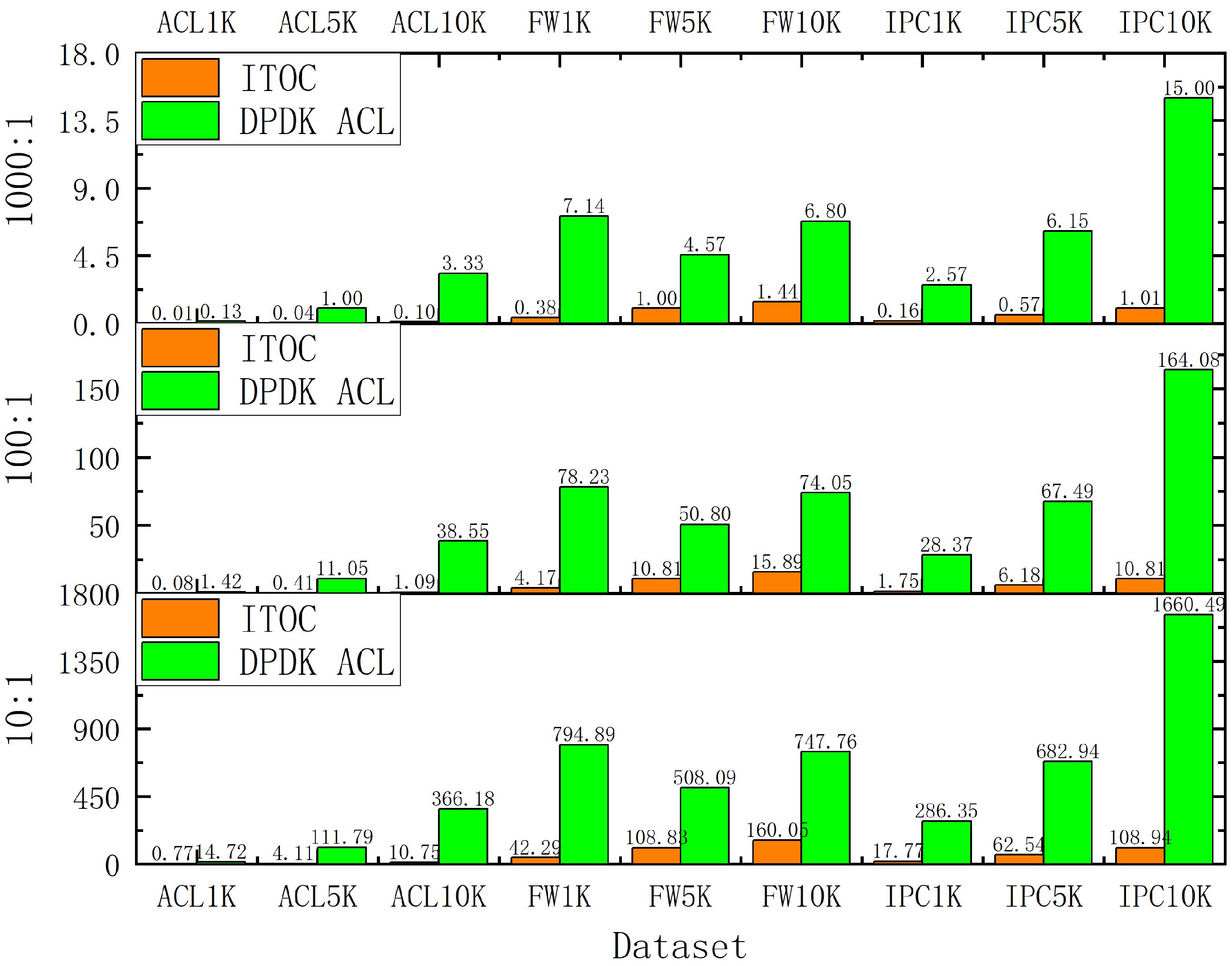
4. Experimental Results
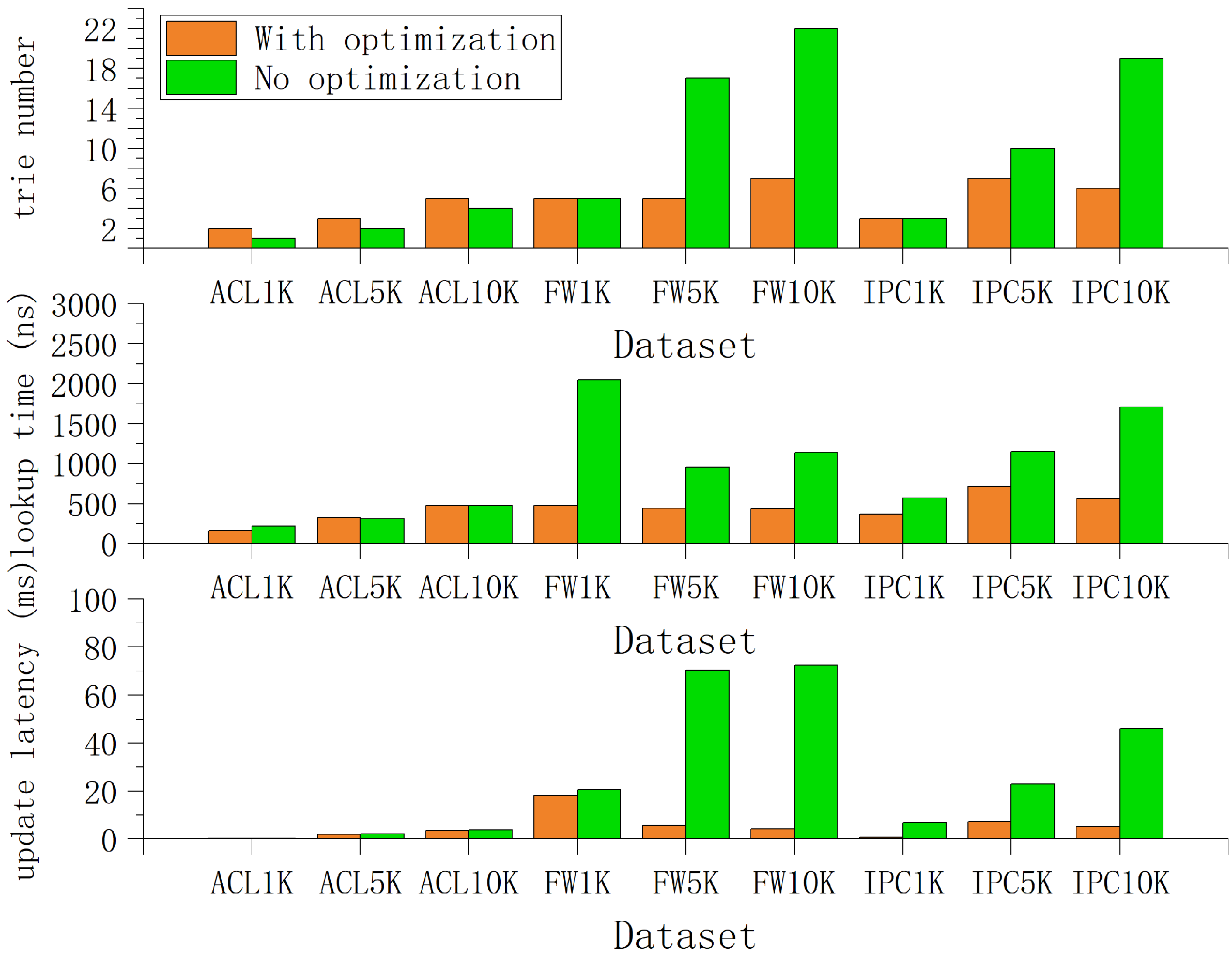
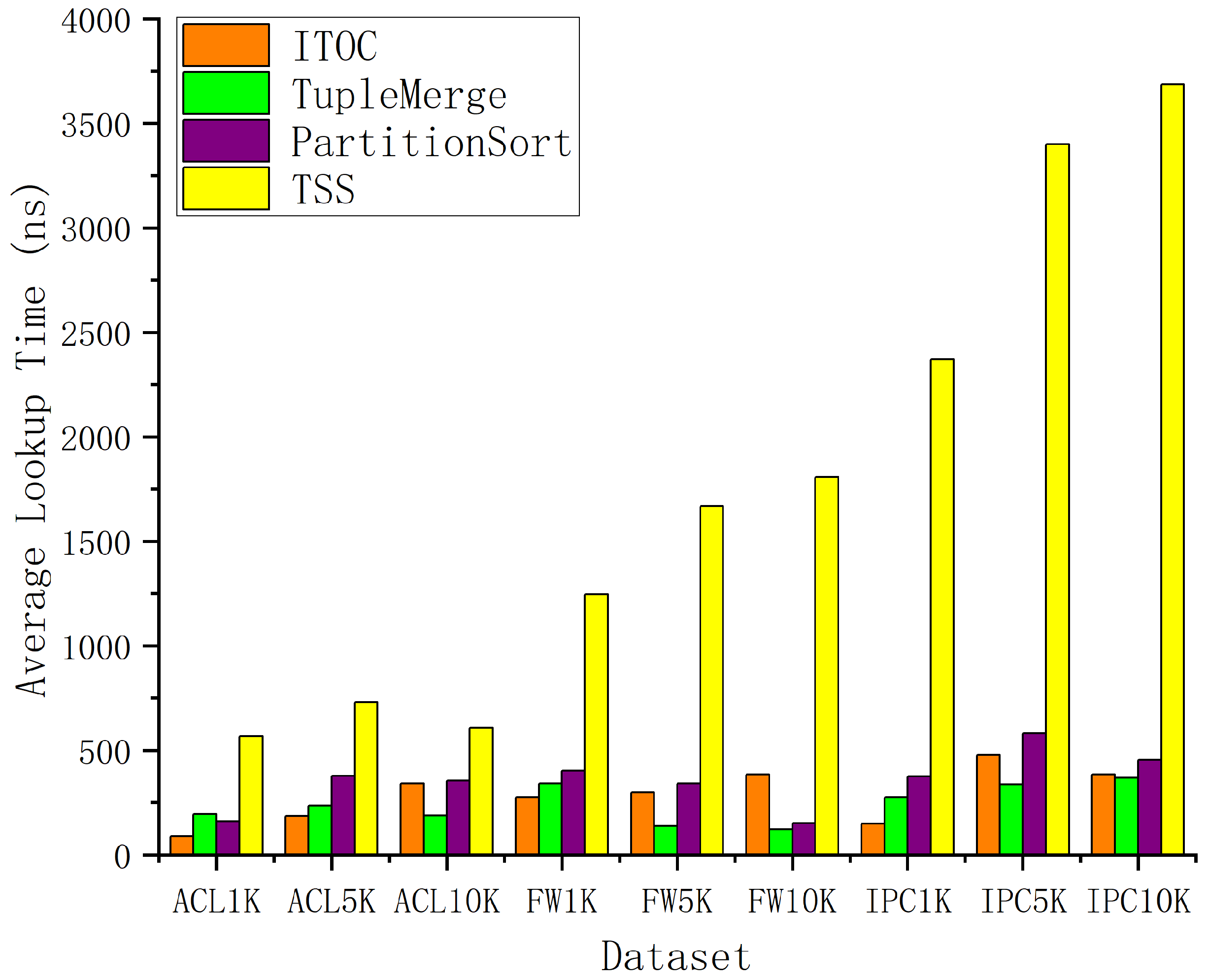
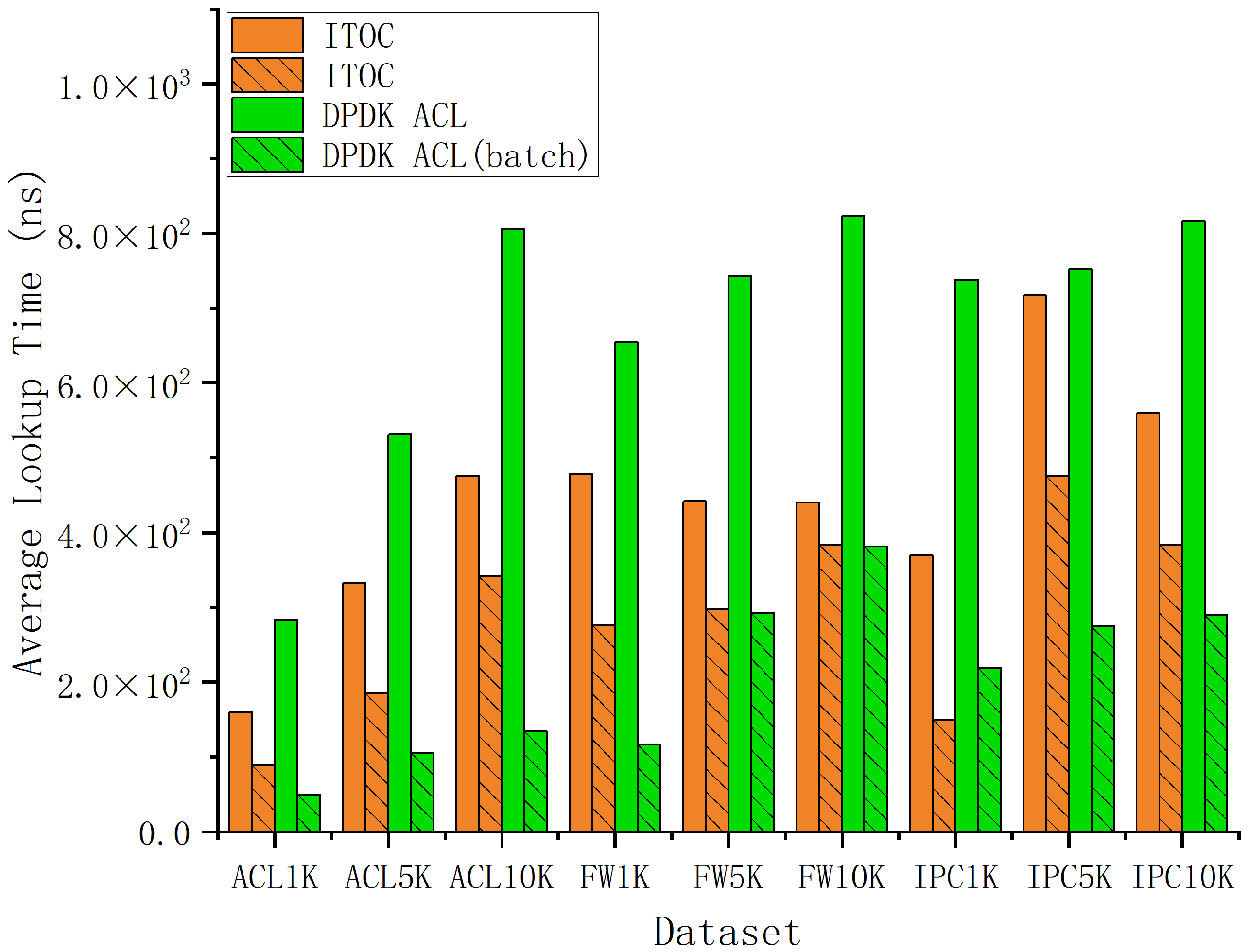
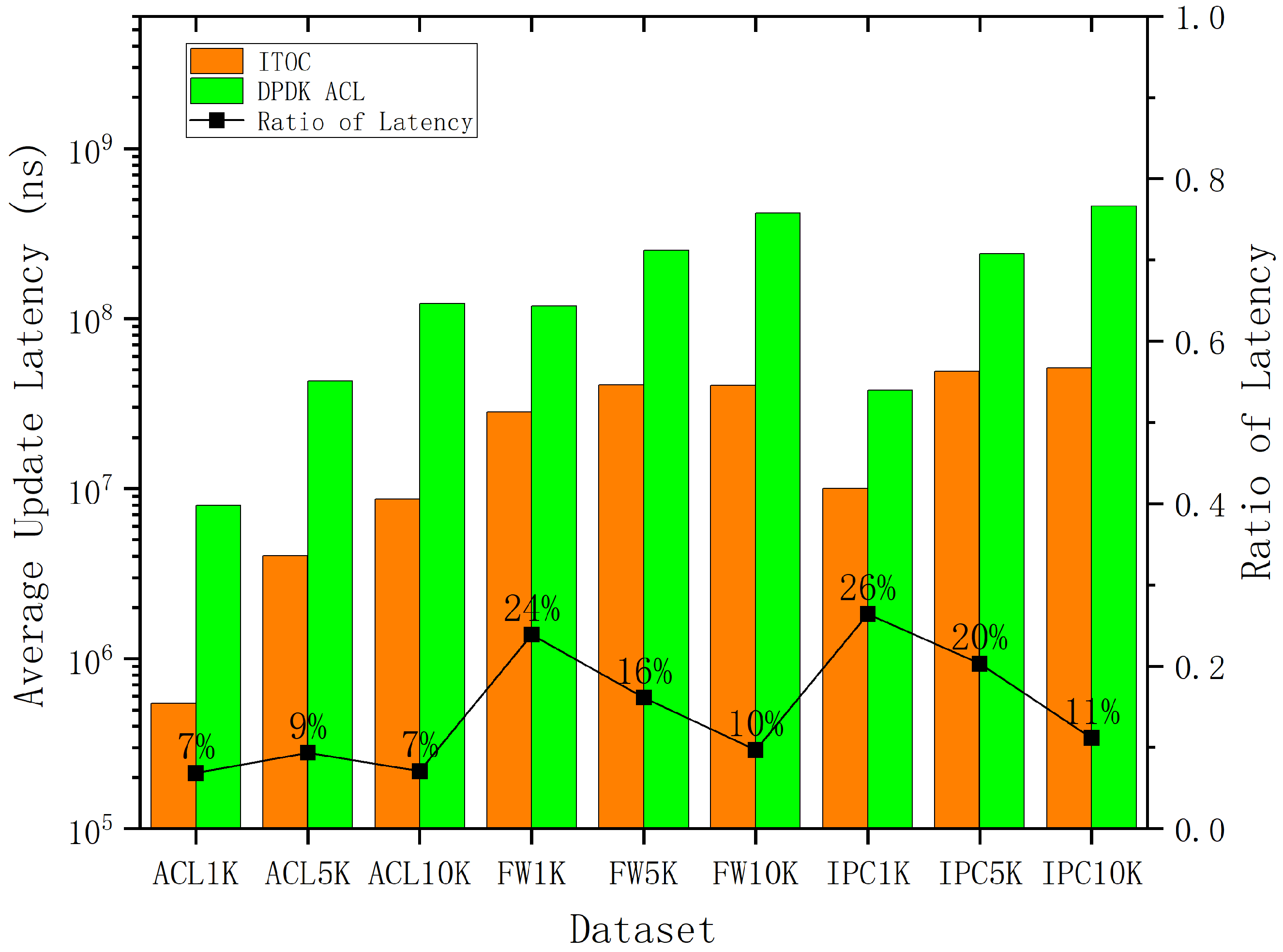
4.1. Simulation Setup
4.2. Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cerović, D.; Del Piccolo, V.; Amamou, A.; Haddadou, K.; Pujolle, G. Fast packet processing: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 3645–3676. [Google Scholar] [CrossRef]
- ONF—Open Network Foundation. Available online: http:/opennetworking.org/ (accessed on 4 June 2021).
- Wang, J.; Cheng, G.; You, J.; Sun, P. SEANet:Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Che, H.; Wang, Z.; Zheng, K.; Liu, B. DRES: Dynamic range encoding scheme for TCAM coprocessors. IEEE Trans. Comput. 2008, 57, 902–915. [Google Scholar] [CrossRef]
- Liu, A.X.; Meiners, C.R.; Torng, E. TCAM Razor: A systematic approach towards minimizing packet classifiers in TCAMs. IEEE/ACM Trans. Netw. 2009, 18, 490–500. [Google Scholar] [CrossRef] [Green Version]
- Meiners, C.R.; Liu, A.X.; Torng, E.; Patel, J. Split: Optimizing space, power, and throughput for TCAM-based classification. In Proceedings of the 2011 ACM/IEEE Seventh Symposium on Architectures for Networking and Communications Systems, Brooklyn, NY, USA, 3–4 October 2011; pp. 200–210. [Google Scholar]
- Kogan, K.; Nikolenko, S.I.; Rottenstreich, O.; Culhane, W.; Eugster, P. Exploiting order independence for scalable and expressive packet classification. IEEE/ACM Trans. Netw. 2015, 24, 1251–1264. [Google Scholar] [CrossRef]
- Ahmed, O.; Areibi, S.; Fayek, D. PCIU: An efficient packet classification algorithm with an incremental update capability. In Proceedings of the 2010 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS’10), Ottawa, ON, Canada, 11–14 July 2010; pp. 81–88. [Google Scholar]
- Ganegedara, T.; Jiang, W.; Prasanna, V.K. A scalable and modular architecture for high-performance packet classification. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 1135–1144. [Google Scholar] [CrossRef]
- Qu, Y.R.; Prasanna, V.K. High-performance and dynamically updatable packet classification engine on FPGA. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 197–209. [Google Scholar] [CrossRef]
- Gupta, P.; McKeown, N. Classifying packets with hierarchical intelligent cuttings. IEEE Micro 2000, 20, 34–41. [Google Scholar] [CrossRef]
- Singh, S.; Baboescu, F.; Varghese, G.; Wang, J. Packet classification using multidimensional cutting. In Proceedings of the 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Karlsruhe, Germany, 25–29 August 2003; pp. 213–224. [Google Scholar]
- Vamanan, B.; Voskuilen, G.; Vijaykumar, T. EffiCuts: Optimizing packet classification for memory and throughput. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 207–218. [Google Scholar] [CrossRef]
- Li, W.; Li, X.; Li, H.; Xie, G. Cutsplit: A decision-tree combining cutting and splitting for scalable packet classification. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 2645–2653. [Google Scholar]
- Srinivasan, V.; Suri, S.; Varghese, G. Packet classification using tuple space search. In Proceedings of the Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Cambridge, MA, USA, 30 August–3 September 1999; pp. 135–146. [Google Scholar]
- Fredkin, E. Trie memory. Commun. ACM 1960, 3, 490–499. [Google Scholar] [CrossRef]
- Heinz, S.; Zobel, J.; Williams, H.E. Burst tries: A fast, efficient data structure for string keys. ACM Trans. Inf. Syst. (TOIS) 2002, 20, 192–223. [Google Scholar] [CrossRef]
- Yingchareonthawornchai, S.; Daly, J.; Liu, A.X.; Torng, E. A sorted partitioning approach to high-speed and fast-update OpenFlow classification. In Proceedings of the 2016 IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–10. [Google Scholar]
- Daly, J.; Bruschi, V.; Linguaglossa, L.; Pontarelli, S.; Rossi, D.; Tollet, J.; Torng, E.; Yourtchenko, A. Tuplemerge: Fast software packet processing for online packet classification. IEEE/ACM Trans. Netw. 2019, 27, 1417–1431. [Google Scholar] [CrossRef]
- Song, H. Protocol-oblivious forwarding: Unleash the power of SDN through a future-proof forwarding plane. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013; pp. 127–132. [Google Scholar]
- DPDK. Available online: http://www.dpdk.org/ (accessed on 4 June 2021).
- Taylor, D.E.; Turner, J.S. Classbench: A packet classification benchmark. IEEE/ACM Trans. Netw. 2007, 15, 499–511. [Google Scholar] [CrossRef] [Green Version]
- Matoušek, J.; Antichi, G.; Lučanskỳ, A.; Moore, A.W.; Kořenek, J. Classbench-ng: Recasting classbench after a decade of network evolution. In Proceedings of the 2017 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Beijing, China, 18–19 May 2017; pp. 204–216. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | 100 | 200 | 500 | 800 | 1000 | 2000 | 3000 | 4000 | 5000 |
|---|---|---|---|---|---|---|---|---|---|
| ACL | 10 | 7 | 6 | 5 | 5 | 5 | 5 | 4 | 4 |
| FW | 16 | 11 | 9 | 8 | 8 | 7 | 7 | 9 | 10 |
| IPC | 11 | 7 | 7 | 7 | 7 | 6 | 9 | 10 | 11 |
| Dataset | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | 8000 | 9000 | 10,000 |
|---|---|---|---|---|---|---|---|---|---|
| ACL | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| FW | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| IPC | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| Dataset | 1000 | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | 8000 |
|---|---|---|---|---|---|---|---|---|
| ACL | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| FW | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| IPC | 6 | 6 | 8 | 8 | 8 | 8 | 8 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, J.; Chen, X.; Wu, J. ITOC: An Improved Trie-Based Algorithm for Online Packet Classification. Appl. Sci. 2021, 11, 8693. https://doi.org/10.3390/app11188693
Li Y, Wang J, Chen X, Wu J. ITOC: An Improved Trie-Based Algorithm for Online Packet Classification. Applied Sciences. 2021; 11(18):8693. https://doi.org/10.3390/app11188693
Chicago/Turabian StyleLi, Yifei, Jinlin Wang, Xiao Chen, and Jinghong Wu. 2021. "ITOC: An Improved Trie-Based Algorithm for Online Packet Classification" Applied Sciences 11, no. 18: 8693. https://doi.org/10.3390/app11188693
APA StyleLi, Y., Wang, J., Chen, X., & Wu, J. (2021). ITOC: An Improved Trie-Based Algorithm for Online Packet Classification. Applied Sciences, 11(18), 8693. https://doi.org/10.3390/app11188693