
Cognitively Driven Arabic Text Readability Assessment Using Eye-Tracking



Abstract
1. Introduction
2. Background
2.1. Overview of Classic Text Readability Assessments
2.1.1. English Classic Readability Measures
2.1.2. Arabic Classic Readability Measures
2.2. Machine-Based Readability Measures
2.3. Eye-Tracking and Reading
- 1.
- Saccades: the participant’s swift eye motions between areas of text. Longer saccades imply text that is straightforward and easily comprehended; short saccades suggest a greater challenge and time required to digest the language [40].
- 2.
- 3.
3. Related Work
3.1. General Text Readability Assessment Studies
3.2. Arabic Text Readability Assessment Studies
3.3. Eye-Tracking in Reading Studies
3.4. Eye-Tracking in Text Readability Assessment
3.5. Discussion
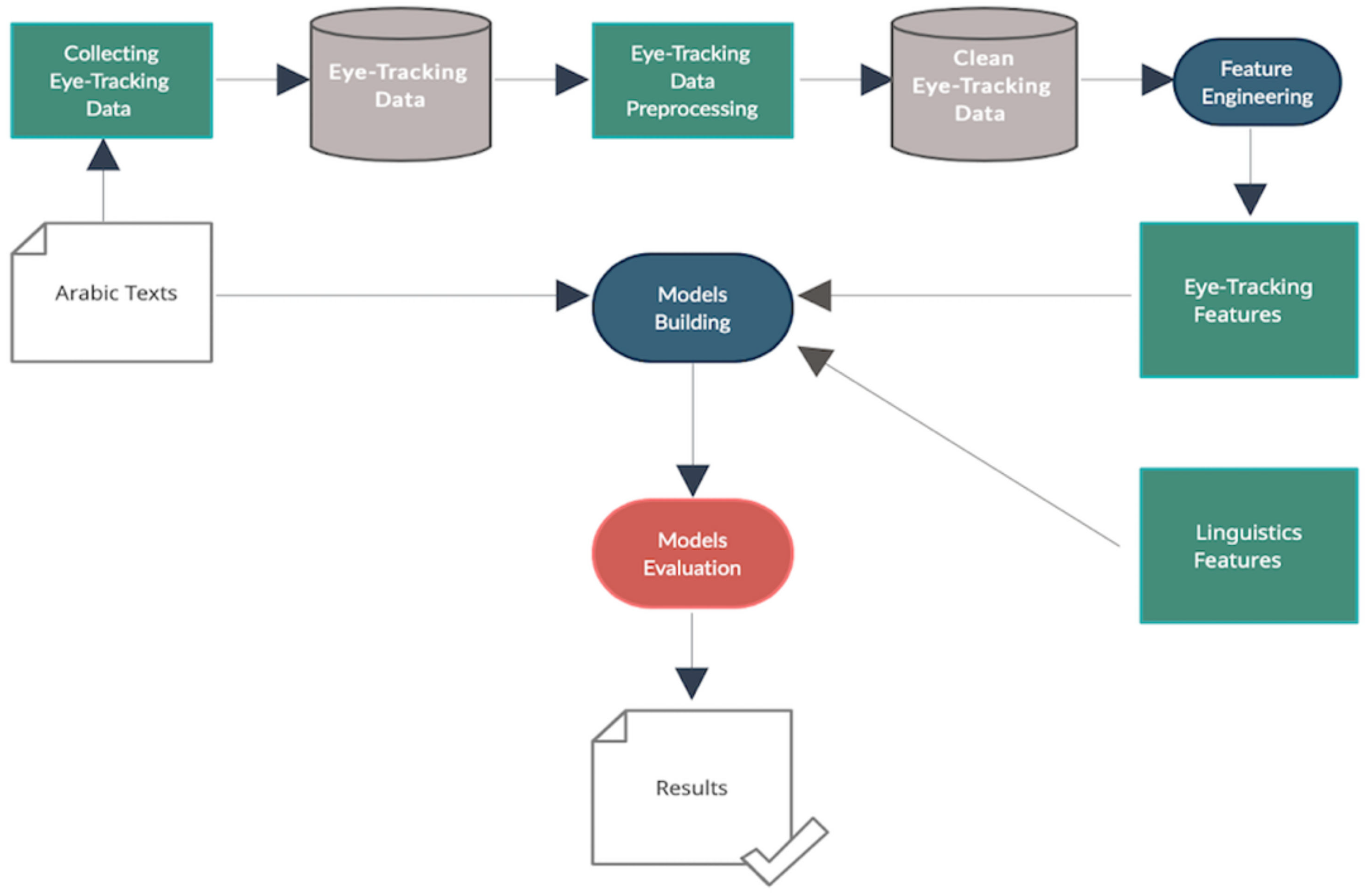
4. Materials and Methods
- 1.
- What is the effect of using eye-tracking features in assessing Arabic text readability?
- 2.
- Which eye movement features contribute the most to Arabic readability prediction?
- 3.
- Which ML model has better performance in modeling human reading difficulties and, thus, better readability prediction using these eye-tracking data?
4.1. Materials
4.2. Participants
4.3. Setup
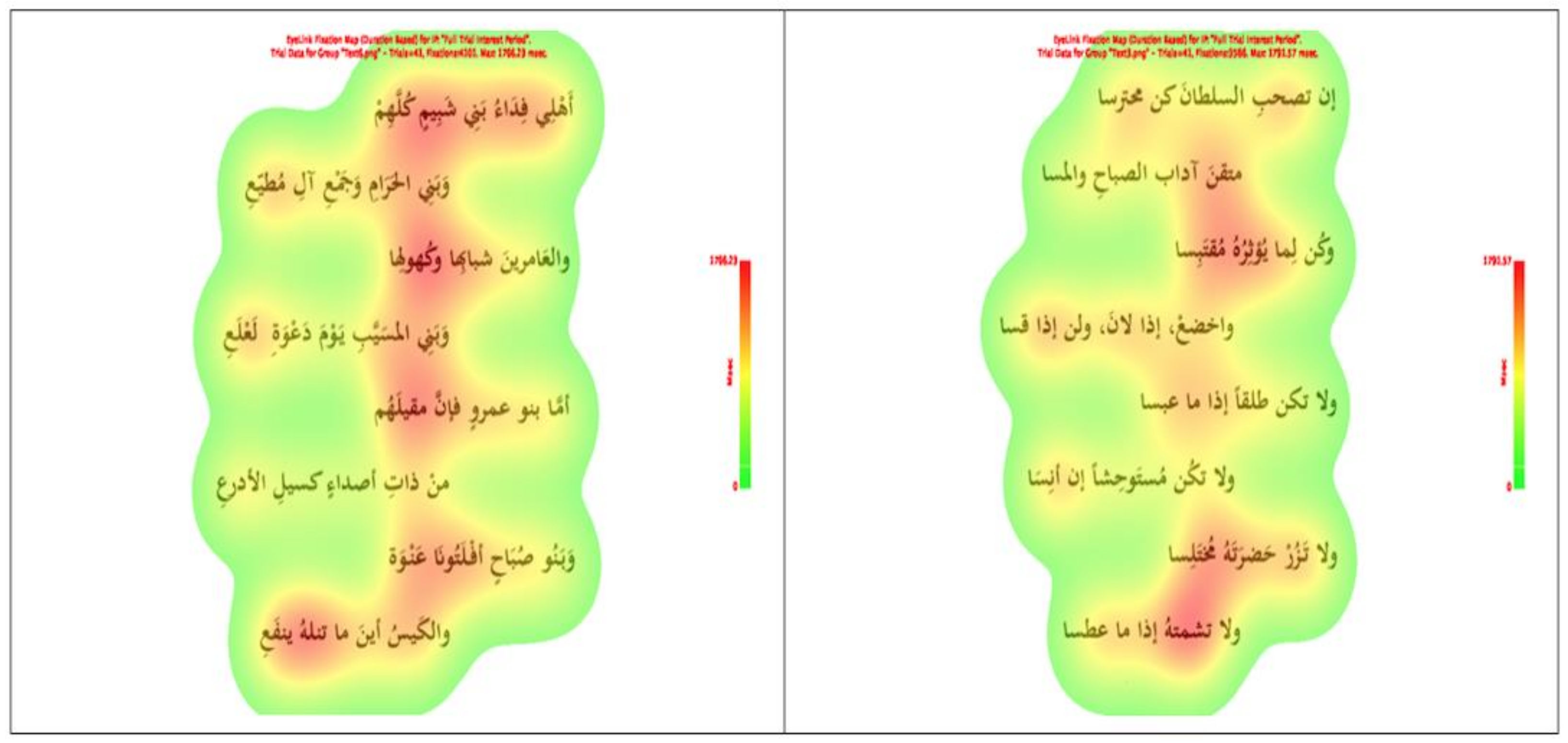
4.4. Experimental Procedure
4.5. Pre-Processing of the Eye-Tracking Data
4.6. Feature Engineering
4.7. Modeling
5. Results and Discussion
5.1. Readability Prediction at the Word Level
5.1.1. Features’ Contribution
5.1.2. Model Comparison
5.2. Readability Prediction at the Text Level
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balyan, R.; McCarthy, K.S.; McNamara, D.S. Comparing Machine Learning Classification Approaches for Predicting Expository Text Difficulty. In Proceedings of the Thirty-First International Flairs Conference, Melbourne, FL, USA, 21–23 May 2018; pp. 421–426. [Google Scholar]
- Collins-Thompson, K. Computational assessment of text readability: A survey of current and future research. ITL-Int. J. Appl. Linguist. 2014, 165, 97–135. [Google Scholar] [CrossRef]
- Dale, E.; Chall, J.S. The Concept of Readability. Elem. Engl. 1949, 26, 19–26. [Google Scholar]
- Alotaibi, S.; Alyahya, M.; Al-Khalifa, H.; Alageel, S.; Abanmy, N. Readability of Arabic Medicine Information Leaflets: A Machine Learning Approach. Procedia Comput. Sci. 2016, 82, 122–126. [Google Scholar] [CrossRef]
- Feng, L.; Elhadad, N.; Huenerfauth, M. Cognitively motivated features for readability assessment. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Athens, Greece, 30 March–3 April 2009; pp. 229–237. [Google Scholar]
- Baazeem, I. Analysing the Effects of Latent Semantic Analysis Parameters on Plain Language Visualisation. Master’s Thesis, Queensland University, Brisbane, QLD, Australia, 2015. [Google Scholar]
- Mesgar, M.; Strube, M. Graph-based coherence modeling for assessing readability. In Proceedings of the Fourth Joint Conference on Lexical and Computational Semantics, Denver, CO, USA, 4–5 June 2015; pp. 309–318. [Google Scholar]
- Vajjala, S.; Meurers, D.; Eitel, A.; Scheiter, K. Towards grounding computational linguistic approaches to readability: Modeling reader-text interaction for easy and difficult texts. In Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity (CL4LC), Osaka, Japan, 11 December 2016; pp. 38–48. [Google Scholar]
- Vajjala, S.; Lucic, I. On understanding the relation between expert annotations of text readability and target reader comprehension. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Association for Computational Linguistics. Florence, Italy, 2 August 2019; pp. 349–359. [Google Scholar]
- Mathias, S.; Kanojia, D.; Mishra, A.; Bhattacharya, P. A Survey on Using Gaze Behaviour for Natural Language Processing. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20) Survey Track, Yokohama, Japan, 11–17 July 2020; pp. 4907–4913. [Google Scholar]
- Singh, A.D.; Mehta, P.; Husain, S.; Rajkumar, R. Quantifying sentence complexity based on eye-tracking measures. In Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity (CL4LC), Osaka, Japan, 11 December 2016; pp. 202–212. [Google Scholar]
- Copeland, L.; Gedeon, T.; Caldwell, S. Effects of text difficulty and readers on predicting reading comprehension from eye movements. In Proceedings of the 2015 6th IEEE International Conference on Cognitive Info communications (Cog. Info. Com.), Gyor, Hungary, 19–21 October 2015; pp. 407–412. [Google Scholar]
- Just, M.A.; Carpenter, P.A. A theory of reading: From eye fixations to comprehension. Psychol. Rev. 1980, 87, 329–354. [Google Scholar] [CrossRef]
- Atvars, A. Eye movement analyses for obtaining Readability Formula for Latvian texts for primary school. Procedia Comput. Sci. 2017, 104, 477–484. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, W.; Song, D.; Zhang, P.; Ren, Q.; Hou, Y. Inferring Document Readability by Integrating Text and Eye Movement Features. In Proceedings of the SIGIR2015 Workshop on Neuro-Physiological Methods in IR Research, Santiago, Chile, 2 December 2015. [Google Scholar]
- Garain, U.; Pandit, O.; Augereau, O.; Okoso, A.; Kise, K. Identification of reader specific difficult words by analyzing eye gaze and document content. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1346–1351. [Google Scholar]
- Mishra, A.; Bhattacharyya, P. Scanpath Complexity: Modeling Reading/Annotation Effort Using Gaze Information. In Cognitively Inspired Natural Language Processing. Cognitive Intelligence and Robotics; Robotics: Singapore, 2018; pp. 77–98. [Google Scholar]
- Al Jarrah, E.Q.A. Using Language Features to Enhance Measuring the Readability of Arabic Text. Master’s Thesis, Yarmouk University, Irbid, Jordan, 2017. [Google Scholar]
- Leal, S.E.; Vieira, J.M.M.; Rodrigues, E.D.S.; Teixeira, E.N.; Aluísio, S. Using Eye-tracking Data to Predict the Readability of Brazilian Portuguese Sentences in Single-task, Multi-task and Sequential Transfer Learning Approaches. In Proceedings of the 28th International Conference on Computational Linguistics, International Committee on Computational Linguistics. Barcelona, Spain, 8–13 December 2020; pp. 5821–5831. [Google Scholar]
- Gonzalez-Garduño, A.V.; Søgaard, A. Learning to predict readability using eye-movement data from natives and learners. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5118–5124. [Google Scholar]
- Litsas, C.; Mastropavlou, M.; Symvonis, A. Text classification for children with dyslexia employing user modelling techniques. In Proceedings of the IISA 2014, The 5th International Conference on Information, Intelligence, Systems and Applications, Chania, Greece, 7–9 July 2014; pp. 1–6. [Google Scholar]
- Fouad, M.M.; Atyah, M.A. MLAR: Machine Learning based System for Measuring the Readability of Online Arabic News. Int. J. Comput. Appl. 2016, 154, 29–33. [Google Scholar] [CrossRef]
- Flesch, R. A new readability yardstick. J. Appl. Psychol. 1948, 32, 221–233. [Google Scholar] [CrossRef]
- Gunning, R. The Technique of Clear Writing; McGraw-Hill Book Company: New York, NY, USA, 1968. [Google Scholar]
- Chall, J.S.; Dale, E. Readability Revisited: The New Dale-Chall Readability Formula; Brookline Books: Cambridge, MA, USA, 1995. [Google Scholar]
- Laughlin, G.H.M. SMOG grading-a new readability formula. J. Read. 1969, 12, 639–646. [Google Scholar]
- Coleman, M.; Liau, T.L. A computer readability formula designed for machine scoring. J. Appl. Psychol. 1975, 60, 283–284. [Google Scholar] [CrossRef]
- Kincaid, J.P.; Fishburne, R.P.; Rogers, R.L.; Chissom, B.S. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel; University of Central Florida: Orlando, FL, USA, 1975. [Google Scholar]
- El-Haj, M.; Rayson, P. OSMAN―A Novel Arabic Readability Metric. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 8–13 December 2020; pp. 250–255. [Google Scholar]
- Cavalli-Sforza, V.; Saddiki, H.; Nassiri, N. Arabic Readability Research: Current State and Future Directions. Procedia Comput. Sci. 2018, 142, 38–49. [Google Scholar] [CrossRef]
- Dawood, B. The Relationship between Readability and Selected Language Variables. Ph.D. Thesis, Baghdad University, Iraq, Baghdad, 1977. [Google Scholar]
- Al-Heeti, K.N. Judgment analysis technique applied to readability prediction of Arabic reading material. Ph.D. Thesis, University of Northern Colorado, Greeley, CO, USA, 1985. [Google Scholar]
- Daud, N.M.; Hassan, H.; Aziz, N.A. A corpus-based readability formula for estimate of Arabic texts reading difficulty. World Appl. Sci. J. 2013, 21, 168–173. [Google Scholar]
- Al Tamimi, A.K.A.; Jaradat, M.; Al-Jarrah, N.; Ghanem, S. AARI: Automatic Arabic readability index. Int. Arab J. Inf. Technol. 2014, 11, 370–378. [Google Scholar]
- Ghani, K.A.; Noh, A.S.; Yusoff, N.M.R.N.; Hussein, N.H. Developing Readability Computational Formula for Arabic Reading Materials Among Non-native Students in Malaysia. Importance New Technol. 2021, 194, 2041–2057. [Google Scholar] [CrossRef]
- Chen, X.; Meurers, D. Characterizing text difficulty with word frequencies. In Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications, San Diego, CA, USA, 16 June 2016; pp. 84–94. [Google Scholar]
- Mesgar, M.; Strube, M. A neural local coherence model for text quality assessment. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4328–4339. [Google Scholar]
- Al-Edaily, A.; Al-Wabil, A.; Al-Ohali, Y. Interactive Screening for Learning Difficulties: Analyzing Visual Patterns of Reading Arabic Scripts with Eye Tracking. In HCI 2013: HCI International 2013—Posters’ Extended Abstracts; Stephanidis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–7. [Google Scholar]
- Conklin, K.; Pellicer-Sanchez, A. Using eye-tracking in applied linguistics and second language research. Second. Lang. Res. 2016, 32, 453–467. [Google Scholar] [CrossRef]
- Grabar, N.; Farce, E.; Sparrow, L. Study of readability of health documents with eye-tracking approaches. In Proceedings of the 1st Workshop on Automatic Text Adaptation (ATA), Tilburg, The Netherlands, 8 November 2018; pp. 10–20. [Google Scholar]
- Gonzalez-Garduno, A.V.; Søgaard, A. Using gaze to predict text readability. In Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, Copenhagen, Denmark, 8 September 2017; pp. 438–443. [Google Scholar]
- Al-Ajlan, A.A.; Al-Khalifa, H.S.; Al-Salman, A.S. Towards the development of an automatic readability measurements for Arabic language. In Proceedings of the 2008 Third International Conference on Digital Information Management, London, UK, 13–16 November 2008; pp. 506–511. [Google Scholar]
- Forsyth, J.N. Automatic Readability Prediction for Modern Standard Arabic. Ph.D. Thesis, Brigham Young University, Provo, UT, USA, 2014. [Google Scholar]
- Rello, L. DysWebxia: A Text Accessibility Model for People with Dyslexia. Ph.D. Thesis, Pompeu Fabra University, Barcelona, Spain, 2014. [Google Scholar]
- Azpiazu, I.M.; Pera, M.S. Multiattentive Recurrent Neural Network Architecture for Multilingual Readability Assessment. Trans. Assoc. Comput. Linguist. 2019, 7, 421–436. [Google Scholar] [CrossRef]
- Martinc, M.; Pollak, S.; Robnik-Šikonja, M. Supervised and unsupervised neural approaches to text readability. Comput. Linguist. 2021, 47, 141–179. [Google Scholar] [CrossRef]
- De Oliveira, A.M.; Germano, G.; Capellini, S.A. Comparison of Reading Performance in Students with Developmental Dyslexia by Sex. Paidéia 2017, 27, 306–313. [Google Scholar] [CrossRef]
- Crossley, S.A.; Allen, L.K.; Snow, E.L.; McNamara, D.S. Incorporating learning characteristics into automatic essay scoring models: What individual differences and linguistic features tell us about writing quality. J. Educ. Data Min. 2016, 8, 1–19. [Google Scholar]
- Mesgar, M.; Strube, M. Lexical coherence graph modeling using word embeddings. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1414–1423. [Google Scholar]
- Xu, P.; Saghir, H.; Kang, J.S.; Long, T.; Bose, A.J.; Cao, Y.; Cheung, J.C.K. A cross-domain transferable neural coherence model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 678–687. [Google Scholar]
- Logeswaran, L.; Lee, H.; Radev, D. Sentence Ordering and Coherence Modeling using Recurrent Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5285–5292. [Google Scholar]
- Zhang, M.; Feng, V.W.; Qin, B.; Hirst, G.; Liu, T.; Huang, J. Encoding world knowledge in the evaluation of local coherence. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 1087–1096. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Li, J.; Hovy, E. A model of coherence based on distributed sentence representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 2039–2048. [Google Scholar]
- Marie-Sainte, S.L.; Alalyani, N.; Alotaibi, S.; Ghouzali, S.; Abunadi, I. Arabic Natural Language Processing and Machine Learning-Based Systems. IEEE Access 2018, 7, 7011–7020. [Google Scholar] [CrossRef]
- Shen, W.; Williams, J.; Marius, T.; Salesky, E. A language-independent approach to automatic text difficulty assessment for second-language learners. In Proceedings of the 2nd Workshop on Predicting and Improving Text Readability for Target Reader Populations, Sofia, Bulgaria, 8 August 2013; pp. 30–38. [Google Scholar]
- Nassiri, N.; Lakhouaja, A.; Cavalli-Sforza, V. Arabic L2 readability assessment: Dimensionality reduction study. J. King Saud. Univ. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Saddiki, H.; Cavalli-Sforza, V.; Bouzoubaa, K. Enhancing Visualization in Readability Reports for Arabic Texts. Procedia Comput. Sci. 2017, 117, 241–247. [Google Scholar] [CrossRef]
- Khallaf, N.; Sharoff, S. Automatic difficulty classification of Arabic sentences. In Proceedings of the Sixth Arabic Natural Language Processing Workshop (WANLP), Virtual. Kyiv, Ukraine, 19 April 2021; pp. 105–114. [Google Scholar]
- Sood, E.; Tannert, S.; Frassinelli, D.; Bulling, A.; Vu, N.T. Interpreting Attention Models with Human Visual Attention in Machine Reading Comprehension. In Proceedings of the 24th Conference on Computational Natural Language Learning, Virtual. 19–20 November 2020; pp. 12–25. [Google Scholar]
- Frazier, L.; Rayner, K. Making and correcting errors during sentence comprehension: Eye movements in the analysis of structurally ambiguous sentences. Cogn. Psychol. 1982, 14, 178–210. [Google Scholar] [CrossRef]
- Clifton, C.; Staub, A.; Rayner, K. Eye movements in reading words and sentences. In Eye Movements; Gompel, R.P.G.V., Fischer, M.H., Murray, W.S., Hill, R.L., Eds.; Elsevier: Oxford, UK, 2007; pp. 341–371. [Google Scholar]
- Rayner, K.; Chace, K.H.; Slattery, T.; Ashby, J. Eye Movements as Reflections of Comprehension Processes in Reading. Sci. Stud. Read. 2006, 10, 241–255. [Google Scholar] [CrossRef]
- Liversedge, S.P.; Paterson, K.B.; Pickering, M.J. Eye movements and measures of reading time. In Eye Guidance in Reading and Scene Perception; Underwood, G., Ed.; Elsevier: Amsterdam, The Netherlands, 1998; pp. 55–75. [Google Scholar]
- Schroeder, S.; Hyönä, J.; Liversedge, S.P. Developmental eye-tracking research in reading: Introduction to the special issue. J. Cogn. Psychol. 2015, 27, 500–510. [Google Scholar] [CrossRef]
- Raney, G.E.; Campbell, S.J.; Bovee, J.C. Using Eye Movements to Evaluate the Cognitive Processes Involved in Text Comprehension. J. Vis. Exp. 2014, 83, e50780. [Google Scholar] [CrossRef] [PubMed]
- Sinha, A.; Roy, D.; Chaki, R.; De, B.K.; Saha, S.K. Readability Analysis Based on Cognitive Assessment Using Physiological Sensing. IEEE Sens. J. 2019, 19, 8127–8135. [Google Scholar] [CrossRef]
- Zubov, V.I.; Petrova, T.E. Lexically or grammatically adapted texts: What is easier to process for secondary school children? Procedia Comput. Sci. 2020, 176, 2117–2124. [Google Scholar] [CrossRef]
- Merkx, D.; Frank, S.L. Comparing Transformers and RNNs on predicting human sentence processing data. arXiv 2020, arXiv:2005.09471. [Google Scholar]
- Wilcox, E.; Gauthier, J.; Hu, J.; Qian, P.; Levy, R. On the predictive power of neural language models for human real-time comprehension behavior. In Proceedings of the 42nd Annual Meeting of the Cognitive Science Society, Virtual. 29 July–1 August 2020; pp. 1707–1713. [Google Scholar]
- Goodkind, A.; Bicknell, K. Predictive power of word surprisal for reading times is a linear function of language model quality. In Proceedings of the 8th Workshop on Cognitive Modeling and Computational Linguistics (CMCL 2018), Salt Lake City, UT, USA, 7 January 2018; pp. 10–18. [Google Scholar]
- Aurnhammer, C.; Frank, S.L. Comparing gated and simple recurrent neural network architectures as models of human sentence processing. In Proceedings of the 41st Annual Conference of the Cognitive Science Society (CogSci 2019), Montreal, QC, Canada, 24–27 July 2019; pp. 112–118. [Google Scholar]
- Clifton, C.; Staub, A. Syntactic influences on eye movements during reading. Oxf. Handb. Online 2011, 3, 895–910. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef] [PubMed]
- Adab: The World Encyclopedia of Arabic Literature. Available online: https://www.adab.com (accessed on 1 February 2021).
- Bensoltana, D.; Asselah, B. Exploration of Arabic reading, in terms of the vocalization of the text form by registering the eyes movements of pupils. World J. Neurosci. 2013, 3, 263–268. [Google Scholar] [CrossRef][Green Version]
- S. R. Ltd. SR Research EyeLink. Available online: https://www.sr-research.com (accessed on 20 March 2021).
- S. R. Ltd. EyeLink Data Viewer User’s Manual. Available online: http://sr-research.jp/support/files/dvmanual.pdf (accessed on 20 April 2021).
- WEKA. The Workbench for Machine Learning. Available online: https://www.cs.waikato.ac.nz/mL/weka/ (accessed on 10 May 2021).
- Cavalli-Sforza, V.; Mezouar, M.E.; Saddiki, H. Matching an Arabic text to a learners’ curriculum. In Proceedings of the 2014 Fifth International Conference on Arabic Language Processing (CITALA 2014), Oujda, Morocco, 26–27 November 2014; pp. 79–88. [Google Scholar]
- Al-Khalifa, H.S.; Al-Ajlan, A.A. Automatic readability measurements of the Arabic text: An exploratory study. Arab. J. Sci. Eng. 2010, 35, 103–124. [Google Scholar]
- Barrett, M.; Agic, Ž.; Søgaard, A. The dundee treebank. In Proceedings of the 14th International Workshop on Treebanks and Linguistic Theories (TLT14), Warsaw, Poland, 11–12 December 2015; pp. 242–248. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Formula Name | Year | Formula Mathematical Calculation |
|---|---|---|
| Dawood Readability Score [31] | 1977 | Dawood Readability Score = −0.0533 × W − 0.2066 × S + 5.5543 × p − 1.0801 where “W” is the average number of characters per word, “S” is the average number of words per sentence, and “p” is the average frequency. |
| Al-Heeti [32] Grade Level | 1984 | Al-Heeti Grade Level = (AWL × 4.414) − 13.468 where “AWL” is the average number of characters per word. |
| A Corpus-Based Readability Formula [33] | 2013 | Readability score of a sentence = Total reversed ranking of each word in a sentence/No. of words per sentence. |
| Automatic Arabic Readability Index (AARI) [34] | 2014 | AARIBase = (3.28 × NOC) + (1.43 × ACW) + (1.24 × AWS) where “NOC” is the character count, “ACW” is the average number of characters per word, and “AWS” is the average number of words per sentence. Afterwards, the AARI base formula was mapped to grade levels as follows: Grade Level = (AARI + 472.42)/1046.3 |
| Open Source Metric for Measuring Arabic Narratives (OSMAN) [29] | 2016 | OSMAN Score = 200.791 − 1.015 × (A/B) − 24.181 × (C/A + D/A + G/A + H/A) “where ‘A’ is the total number of words counted using [the] Stanford Arabic word tokenizer, ‘B’ is the total number of sentences counted automatically using common delimiters to split text into sentences, ‘C’ is the number of hard words (words with more than 5 letters—Long words); the word length was counted with the absence of diacritics in order to avoid counting the diacritics as letters, ‘D’ is the number of syllables in a word, ‘E’ is the total number of characters ignoring digits, ‘G’ is the number of complex words in Arabic (words with more than four syllables), ‘H’ is the number of ‘Faseeh’ words (complex word with any of the following Arabic letters (‘ء’, ‘ئ’,‘وء’, ‘ذ’, ‘ ظ’) or ending with (‘وا’, ‘ون’)” [29]. |
| Computational Formula for Arabic Reading Materials Among Non-Native Students [35] | 2021 | Y= 31.830 − 0.298 X1 − 0.178 X2 + 0.043 X3 + 2.444 where Y = readability level, X1 = common and frequent words, X2 = conjunction and punctuation, X3 = average number of words per sentence; Constant = 31.830 and Error = 2.444 |
| File Name | OSMAN Readability Score | Sentences Count | Words Count | Syllables Count | Faseeh Words Count |
|---|---|---|---|---|---|
| Andalusian Era Poems | |||||
| Text 1 | 157.15 | 8 | 38 | 48 | 0 |
| Text 2 | 144.58 | 8 | 33 | 54 | 0 |
| Text 3 | 163.60 | 8 | 39 | 36 | 1 |
| Pre-Islamic Era Poems | |||||
| Text 4 | 101.99 | 8 | 37 | 120 | 1 |
| Text 5 | 123.92 | 8 | 39 | 102 | 2 |
| Text 6 | 114.10 | 8 | 40 | 113 | 1 |
| Eye-Tracking Feature | Description |
|---|---|
| IA_DWELL_TIME | The summation of all fixations’ durations that occurred on a specific IA in a trial |
| IA_DWELL_TIME_% | The percentage of the total trial time that a participant devoted to fixating on a specific IA |
| IA_FIRST_FIXATION_DURATION | The duration of a participant’s fixation on a specific interest area for the first time in a trial |
| IA_FIXATION_COUNT | The total number of fixations for a participant on a specific IA in a trial |
| IA_FIX_COUNT_% | The percentage of the total number of fixations in a trial that a participant devoted to a specific IA |
| IA_RUN_COUNT | The count of how many times a participant entered a specific interest area left (runs) in a trial |
| IA_VISITED_TRIAL_% | The percentage of trials that have at least one fixation on a specific IA |
| IA_REVISIT_TRIAL_% | The percentage of trials that have one or more run of fixations on a specific IA |
| Reg. Model | Using Gaze Data | CC | MAE | RMSE | RAE (%) | RRSE (%) |
|---|---|---|---|---|---|---|
| LR | x | 0.96 | 11.98 | 13.83 | 28.86 | 26.56 |
 | 0.98 | 9.14 | 11.50 | 21.99 | 22.05 | |
| SMO-reg | x | 0.96 | 11.47 | 14.50 | 27.62 | 27.86 |
| 0.98 | 8.88 | 11.67 | 21.36 | 22.38 | |
| MLP | x | 0.93 | 15.09 | 19.48 | 36.33 | 37.43 |
| 0.95 | 12.43 | 15.87 | 29.90 | 30.42 | |
| M5P Tree | x | 0.96 | 12.44 | 14.70 | 29.97 | 28.23 |
| 0.97 | 9.78 | 12.73 | 23.54 | 24.40 | |
| REP Tree | x | 0.95 | 12.19 | 16.76 | 29.31 | 32.13 |
| 0.91 | 16.51 | 21.69 | 39.83 | 41.68 |
| Performance Measure | LR | MLP | SMOreg | M5P | REPTree |
|---|---|---|---|---|---|
| CC | 0.20 | 0.94 v | 0.96 v | 0.85 v | 0.00 * |
| MAE | 40.69 | 17.69 * | 14.29 * | 38.45 * | 41.55 |
| RMSE | 50.15 | 21.87 * | 15.75 * | 50.39 | 51.37 |
| RAE | 97.94 | 43.37 * | 34.97 * | 92.20 * | 100.00 |
| RRSE | 97.62 | 43.18 * | 30.96 * | 97.82 | 100.00 |
| Performance Measure | LR | MLP | SMOreg | M5P | REPTree |
|---|---|---|---|---|---|
| CC | 0.14 | 0.76 v | 0.93 v | −0.02 | 0.00 |
| MAE | 12.43 | 8.00 * | 4.90 * | 12.68 v | 12.58 |
| RMSE | 15.43 | 9.94 * | 6.25 * | 15.60 | 15.63 |
| RAE | 98.76 | 64.20 * | 39.28 * | 100.92 v | 100.00 |
| RRSE | 98.76 | 63.86 * | 40.51 * | 100.05 | 100.00 |
| Eye-Tracking Feature | Description |
|---|---|
| FIXATION_COUNT (FC) | The average number of fixations in a text. |
| FIXATION_DURATION_MEAN (FDM) | The average duration of fixations (in milliseconds) a participant makes in a text. |
| SACCADE_AMPLITUDE_MEAN (SAM) | Average size (in degrees of visual angle) of all saccades in the trial group. “This is calculated by summing up the amplitude of all saccades in the trial group divided by the total number of saccades in the group” [78]. |
| SACCADE_COUNT (SC) | The average number of saccades in a text. |
| RUN_COUNT (RC) | The average count of how many times a participant makes runs of fixations in a text. |
| Texts | FC | FDM | SAM | SC | RC | Participants’ Common Subjective Readability |
|---|---|---|---|---|---|---|
| Text 1 | 80.9 | 276.01 | 1.79 | 81.15 | 41.88 | E |
| Text 2 | 89.39 | 293.92 | 1.65 | 89.54 | 49.59 | M/E |
| Text 3 | 86.98 | 280.19 | 1.75 | 87.22 | 49.68 | E |
| Text 4 | 102.63 | 290.63 | 1.53 | 102.88 | 53.56 | M/D |
| Text 5 | 108.15 | 282.38 | 1.74 | 108.37 | 54.1 | M/D |
| Text 6 | 100.02 | 287.06 | 1.66 | 100.24 | 53.12 | M/D |
| Texts | FC | FDM | SAM | SC | RC | Participants’ Common Subjective Readability |
|---|---|---|---|---|---|---|
| Texts 1–3 | 85.76 | 283.37 | 1.73 | 85.97 | 47.05 | E |
| Texts 4–6 | 103.6 | 286.69 | 1.64 | 103.83 | 53.59 | M/D |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baazeem, I.; Al-Khalifa, H.; Al-Salman, A. Cognitively Driven Arabic Text Readability Assessment Using Eye-Tracking. Appl. Sci. 2021, 11, 8607. https://doi.org/10.3390/app11188607
Baazeem I, Al-Khalifa H, Al-Salman A. Cognitively Driven Arabic Text Readability Assessment Using Eye-Tracking. Applied Sciences. 2021; 11(18):8607. https://doi.org/10.3390/app11188607
Chicago/Turabian StyleBaazeem, Ibtehal, Hend Al-Khalifa, and Abdulmalik Al-Salman. 2021. "Cognitively Driven Arabic Text Readability Assessment Using Eye-Tracking" Applied Sciences 11, no. 18: 8607. https://doi.org/10.3390/app11188607
APA StyleBaazeem, I., Al-Khalifa, H., & Al-Salman, A. (2021). Cognitively Driven Arabic Text Readability Assessment Using Eye-Tracking. Applied Sciences, 11(18), 8607. https://doi.org/10.3390/app11188607