
Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering




Abstract
:1. Introduction
2. Related Work
3. The Proposed Algorithm
- Find users having close/similar tastes with U, by examining the similarity of already submitted ratings in the rDB, to identify U’s near neighbour (NN) users; these users will operate as recommenders to U. Typically, in CF systems, the metrics used to quantify user similarity, is the Pearson correlation coefficient (PCC) and the Cosine Similarity (CS) [55,56], which are expressed as shown in Equations (1) and (2), respectively:
- 2.
- 3.
4. Algorithm Tuning and Experimental Evaluation
- Determine the optimal value of the bsf factor, to tune the proposed algorithm and;
- Evaluate the accuracy of the rating prediction of the proposed algorithm, both when used independently and when combined with a state-of-the-art CF algorithm also aiming at rating prediction accuracy improvement.
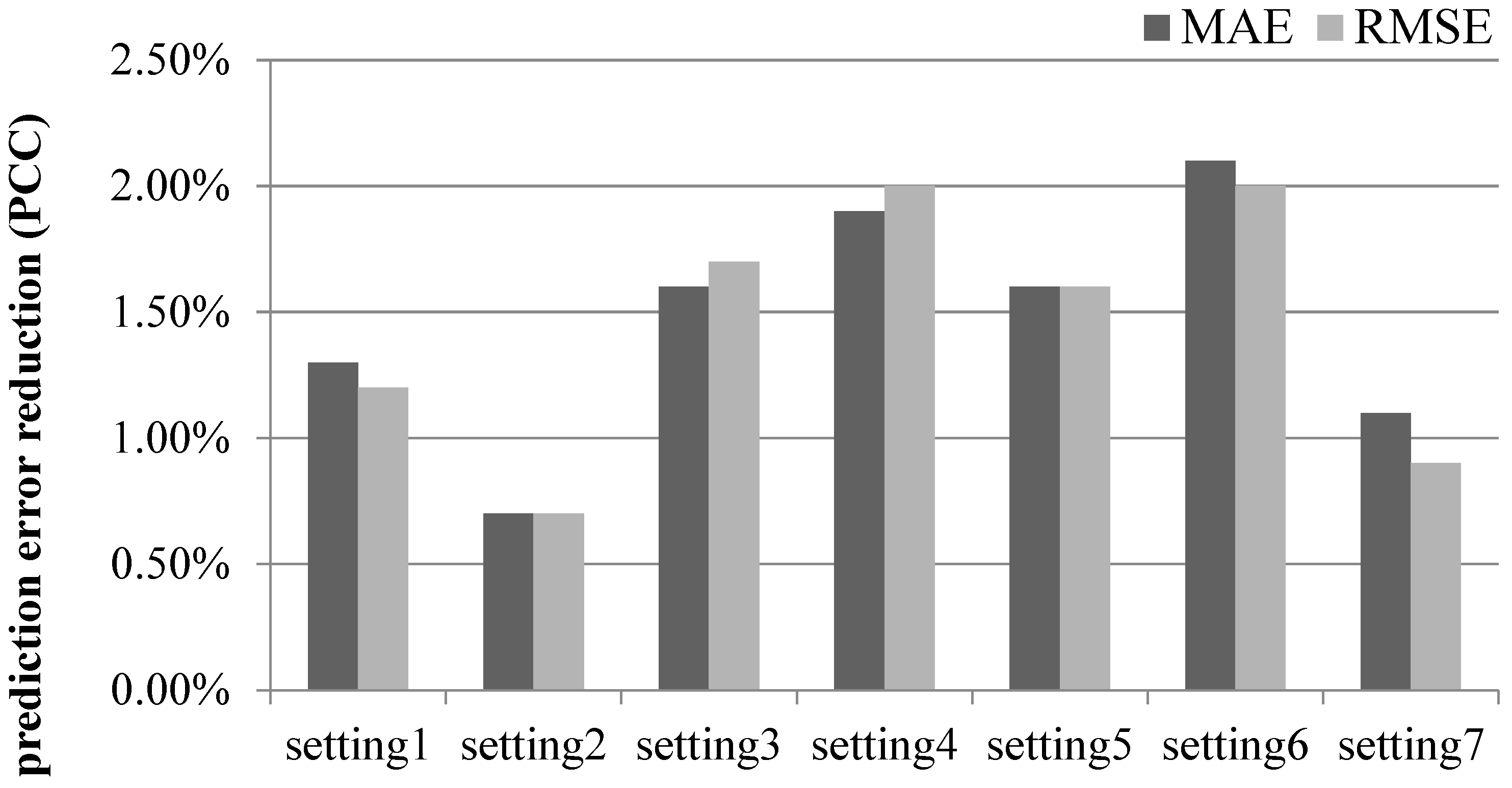
4.1. Determining the Algorithm Parameters
- Setting 1:
- Setting 2:
- Setting 3:
- Setting 4:
- Setting 5:
- Setting 6:
- Setting 7:
- low_thr denotes the value below which a rating is considered to be negative; formally, is_negative(rU,i) ⇔ rU,i ≤ low_thr
- high_thr, correspondingly, represents the value above which a rating is considered to be positive. Formally, is_positive(rU,i)⇔rU,i ≥ high_thr
- blackSheepRatings(U,V) is the number of ratings where users U and V both have a positive (or negative) rating, while the user community has a negative (or positive), respectively, rating on the same item. Formally:
- ⚬
- , where UC is the user community, i.e., the set of users in the dataset
- ⚬
- ⚬
- ⚬
- numCommonlyRated(U,V) is the number of items that have been rated by both U and V; formally,
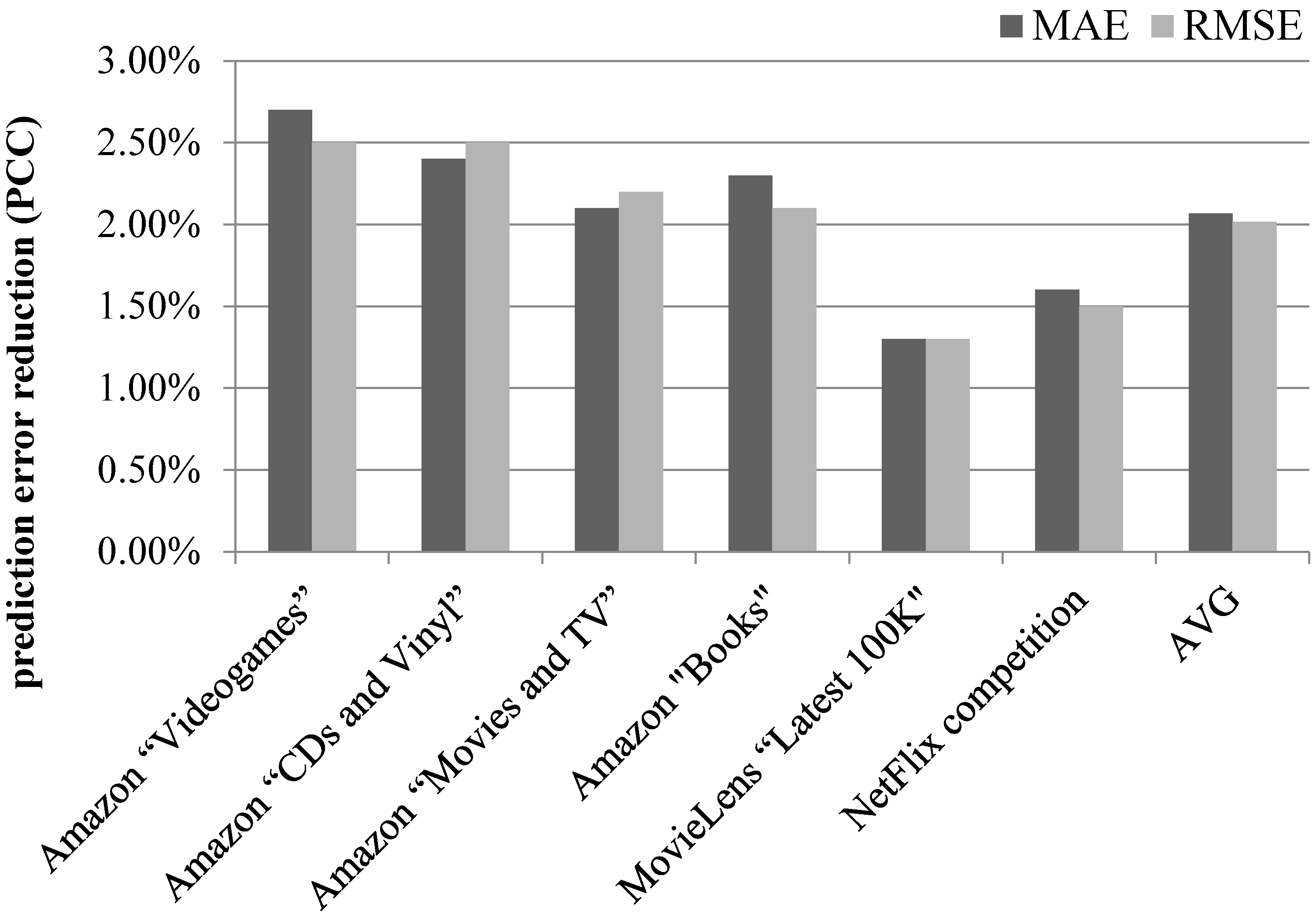
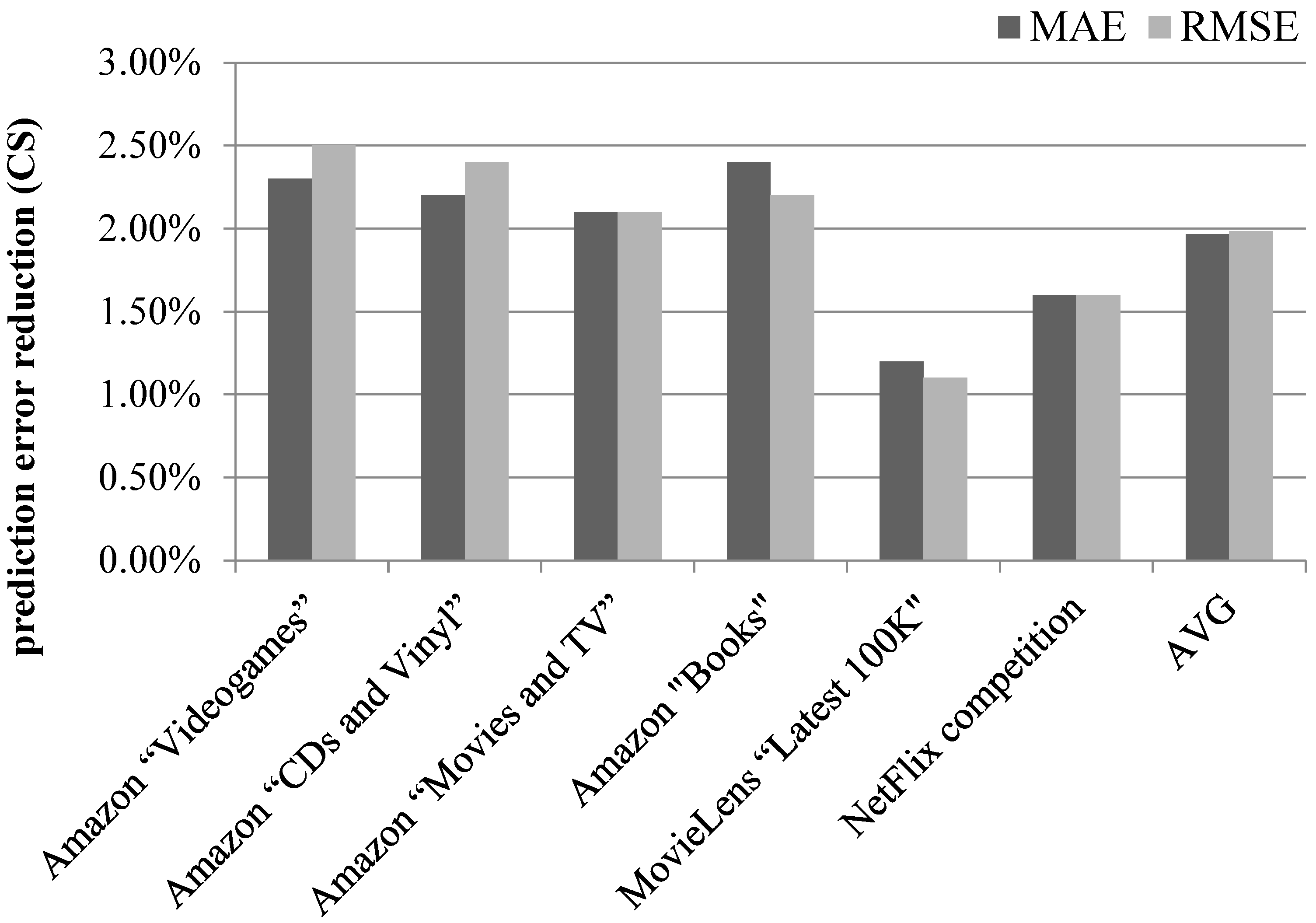
4.2. Rating Prediction Accuracy Improvement Achieved by the Proposed Algorithm
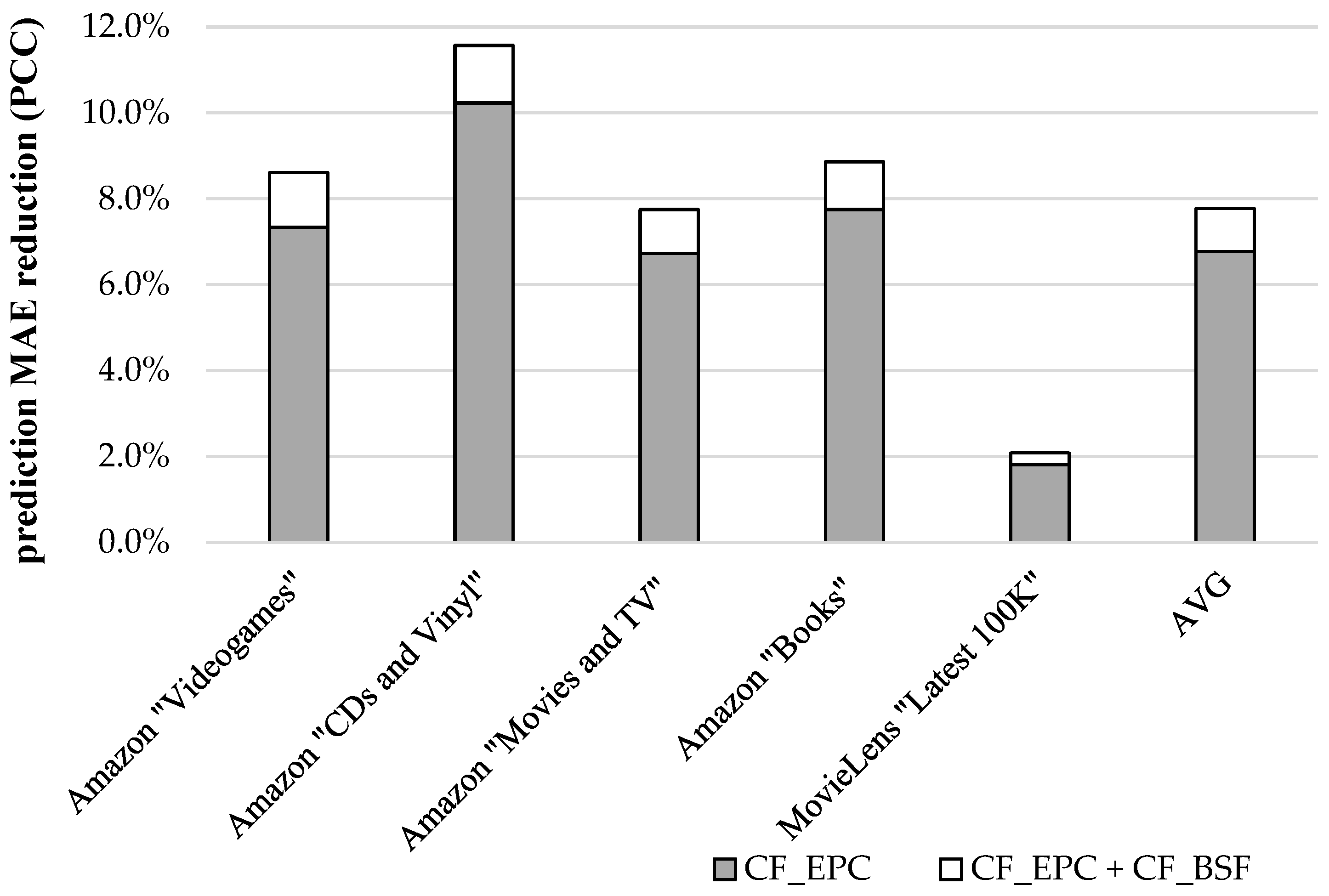
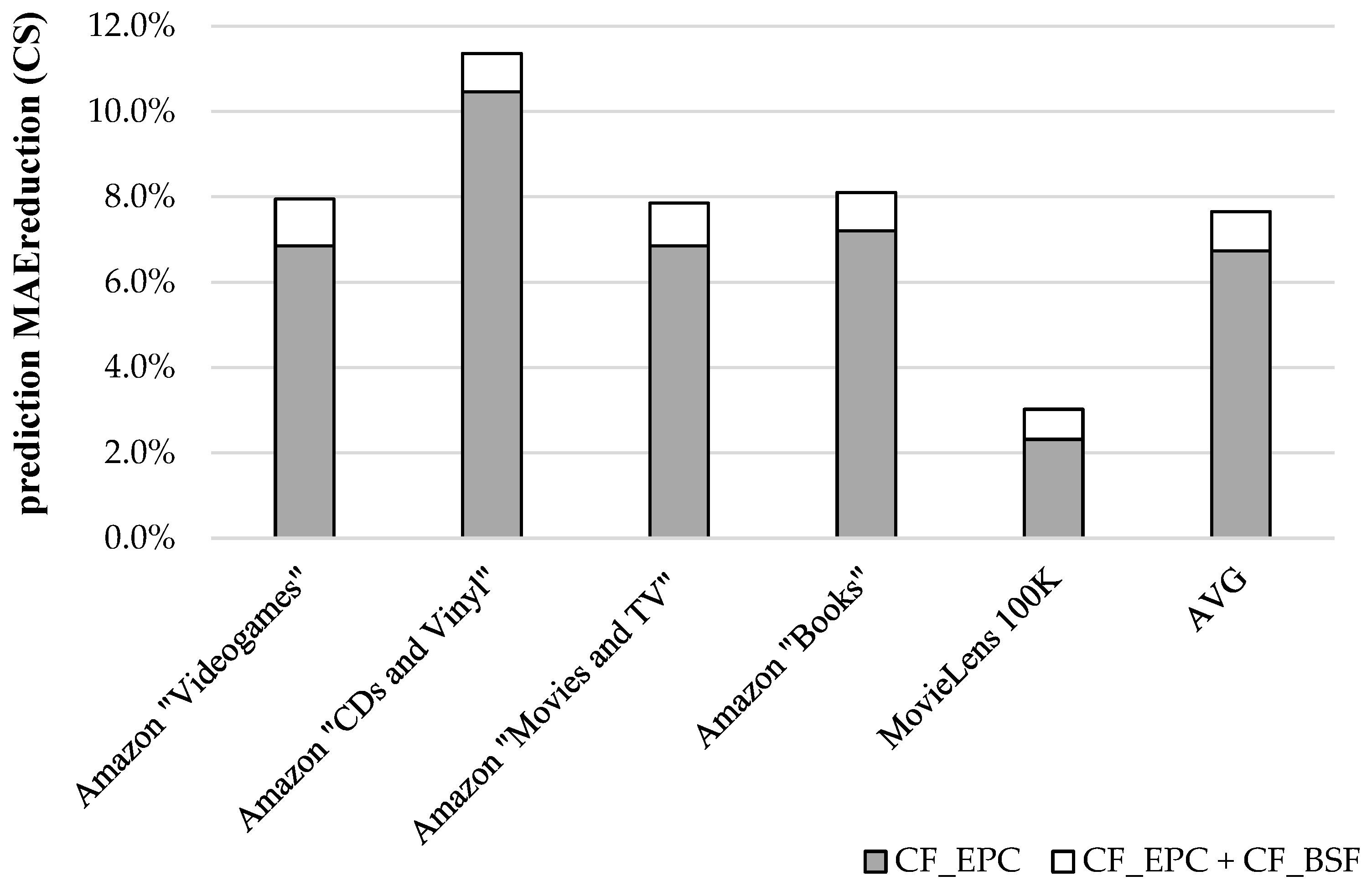
4.3. Combining the Proposed Algorithm with a Second Algorithm Targeting Rating Prediction Accuracy Improvement
4.4. Complexity Analysis of the Proposed Algorithm
5. Conclusion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Balabanović, M.; Shoham, Y. Fab: Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Lara-Cabrera, R.; González-Prieto, Á.; Ortega, F. Deep Matrix Factorization Approach for Collaborative Filtering Recommender Systems. Appl. Sci. 2020, 10, 4926. [Google Scholar] [CrossRef]
- Aditya, P.H.; Budi, I.; Munajat, Q. A comparative analysis of memory-based and model-based collaborative filtering on the implementation of recommender system for E-commerce in Indonesia: A case study PT X. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; pp. 303–308. [Google Scholar]
- Cechinel, C.; Sicilia, M.-Á.; Sánchez-Alonso, S.; García-Barriocanal, E. Evaluating collaborative filtering recommendations inside large learning object repositories. Inf. Process. Manag. 2013, 49, 34–50. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Chen, R.; Hua, Q.; Chang, Y.-S.; Wang, B.; Zhang, L.; Kong, X. A Survey of Collaborative Filtering-Based Recommender Systems: From Traditional Methods to Hybrid Methods Based on Social Networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar] [CrossRef]
- Jalili, M.; Ahmadian, S.; Izadi, M.; Moradi, P.; Salehi, M. Evaluating Collaborative Filtering Recommender Algorithms: A Survey. IEEE Access 2018, 6, 74003–74024. [Google Scholar] [CrossRef]
- Gong, S.; Ye, H.; Tan, H. Combining Memory-Based and Model-Based Collaborative Filtering in Recommender System. In Proceedings of the 2009 Pacific-Asia Conference on Circuits, Communications and Systems, Chengdu, China, 16–17 May 2009; pp. 690–693. [Google Scholar]
- Aramanda, A.; Md Abdul, S.; Vedala, R. A Comparison Analysis of Collaborative Filtering Techniques for Recommender Systems. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; Volume 698, pp. 87–95. [Google Scholar]
- Zhang, R.; Liu, Q.; Li, C.G.; Wei, J.-X.; Ma, H. Collaborative Filtering for Recommender Systems. In Proceedings of the 2014 Second International Conference on Advanced Cloud and Big Data, Huangshan, China, 20–22 November 2014; pp. 301–308. [Google Scholar]
- Dong, M.; Yuan, F.; Yao, L.; Wang, X.; Xu, X.; Zhu, L. Trust in recommender systems: A deep learning perspective. arXiv 2020, arXiv:2004.03774. [Google Scholar]
- Toma, C.L. Counting on Friends: Cues to Perceived Trustworthiness in Facebook Profiles. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 495–504. [Google Scholar]
- Bakshy, E.; Eckles, D.; Yan, R.; Rosenn, I. Social influence in social advertising: Evidence from field experiments. In Proceedings of the ACM Conference on Electronic Commerce, Valencia, Spain, 4–8 June 2012; pp. 146–161. [Google Scholar]
- Han, P.; Xie, B.; Yang, F.; Shen, R. A scalable P2P recommender system based on distributed collaborative filtering. Expert Syst. Appl. 2004, 27, 203–210. [Google Scholar] [CrossRef]
- Karabadji, N.E.I.; Beldjoudi, S.; Seridi, H.; Aridhi, S.; Dhifli, W. Improving memory-based user collaborative filtering with evolutionary multi-objective optimization. Expert Syst. Appl. 2018, 98, 153–165. [Google Scholar] [CrossRef]
- Pirasteh, P.; Hwang, D.; Jung, J.E. Weighted Similarity Schemes for High Scalability in User-Based Collaborative Filtering. Mob. Netw. Appl. 2015, 20, 497–507. [Google Scholar] [CrossRef]
- Bell, R.M.; Koren, Y. Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 43–52. [Google Scholar]
- Das, A.S.; Datar, M.; Garg, A.; Rajaram, S. Google news personalization: Scalable online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web—WWW’07, Banff, AB, Canada, 8–12 May 2007; ACM Press: New York, NY, USA, 2007; p. 271. [Google Scholar]
- Margaris, D.; Spiliotopoulos, D.; Karagiorgos, G.; Vassilakis, C. An Algorithm for Density Enrichment of Sparse Collaborative Filtering Datasets Using Robust Predictions as Derived Ratings. Algorithms 2020, 13, 174. [Google Scholar] [CrossRef]
- Margaris, D.; Spiliotopoulos, D.; Karagiorgos, G.; Vassilakis, C.; Vasilopoulos, D. On Addressing the Low Rating Prediction Coverage in Sparse Datasets Using Virtual Ratings. SN Comput. Sci. 2021, 2, 255. [Google Scholar] [CrossRef]
- Chen, L.; Yuan, Y.; Yang, J.; Zahir, A. Improving the Prediction Quality in Memory-Based Collaborative Filtering Using Categorical Features. Electronics 2021, 10, 214. [Google Scholar] [CrossRef]
- Singh, M.; Mehrotra, M. Impact of clustering on quality of recommendation in cluster-based collaborative filtering: An empirical study. Int. J. Bus. Intell. Data Min. 2020, 17, 206. [Google Scholar] [CrossRef]
- Alhijawi, B.; Al-Naymat, G.; Obeid, N.; Awajan, A. Novel predictive model to improve the accuracy of collaborative filtering recommender systems. Inf. Syst. 2021, 96, 101670. [Google Scholar] [CrossRef]
- Singh, P.K.; Pramanik, P.K.D.; Choudhury, P. An improved similarity calculation method for collaborative filtering-based recommendation, considering neighbor’s liking and disliking of categorical attributes of items. J. Inf. Optim. Sci. 2019, 40, 397–412. [Google Scholar] [CrossRef]
- Lima, G.R.; Mello, C.E.; Lyra, A.; Zimbrao, G. Applying landmarks to enhance memory-based collaborative filtering. Inf. Sci. 2020, 513, 412–428. [Google Scholar] [CrossRef]
- Ekstrand, M.D. Collaborative Filtering Recommender Systems. Found. Trends Hum. Comput. Interact. 2011, 4, 81–173. [Google Scholar] [CrossRef]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative Filtering Recommender Systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Choi, K.; Suh, Y. A new similarity function for selecting neighbors for each target item in collaborative filtering. Knowl. Based Syst. 2013, 37, 146–153. [Google Scholar] [CrossRef]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A new user similarity model to improve the accuracy of collaborative filtering. Knowl. Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Li, Z.; Sun, X. Iterative rating prediction for neighborhood-based collaborative filtering. Appl. Intell. 2021, 51, 6810–6822. [Google Scholar] [CrossRef]
- Shi, W.; Wang, L.; Qin, J. User Embedding for Rating Prediction in SVD++-Based Collaborative Filtering. Symmetry Basel 2020, 12, 121. [Google Scholar] [CrossRef] [Green Version]
- Ren, L.; Wang, W. An SVM-based collaborative filtering approach for Top-N web services recommendation. Futur. Gener. Comput. Syst. 2018, 78, 531–543. [Google Scholar] [CrossRef]
- Kuang, L.; Yu, L.; Huang, L.; Wang, Y.; Ma, P.; Li, C.; Zhu, Y. A Personalized QoS Prediction Approach for CPS Service Recommendation Based on Reputation and Location-Aware Collaborative Filtering. Sensors 2018, 18, 1556. [Google Scholar] [CrossRef] [Green Version]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef] [Green Version]
- Sánchez-Moreno, D.; López Batista, V.; Vicente, M.D.M.; Sánchez Lázaro, Á.L.; Moreno-García, M.N. Exploiting the User Social Context to Address Neighborhood Bias in Collaborative Filtering Music Recommender Systems. Information 2020, 11, 439. [Google Scholar] [CrossRef]
- Chen, R.; Chang, Y.-S.; Hua, Q.; Gao, Q.; Ji, X.; Wang, B. An enhanced social matrix factorization model for recommendation based on social networks using social interaction factors. Multimed. Tools Appl. 2020, 79, 14147–14177. [Google Scholar] [CrossRef]
- Bok, K.; Ko, G.; Lim, J.; Yoo, J. Personalized content recommendation scheme based on trust in online social networks. Concurr. Comput. Pract. Exp. 2020, 32, e5572. [Google Scholar] [CrossRef]
- Ma, T.; Wang, X.; Zhou, F.; Wang, S. Research on diversity and accuracy of the recommendation system based on multi-objective optimization. Neural Comput. Appl. 2020, 1–9. [Google Scholar] [CrossRef]
- Margaris, D.; Vasilopoulos, D.; Vassilakis, C.; Spiliotopoulos, D. Improving Collaborative Filtering’s Rating Prediction Accuracy by Introducing the Common Item Rating Past Criterion. In Proceedings of the 10th International Conference on Information, Intelligence, Systems and Applications, IISA 2019, Patras, Greece, 15–17 July 2019; pp. 1022–1027. [Google Scholar]
- Thakkar, P.; Varma, K.; Ukani, V.; Mankad, S.; Tanwar, S. Combining User-Based and Item-Based Collaborative Filtering Using Machine Learning. In Information and Communication Technology for Intelligent Systems; Springer: Singapore, 2019; pp. 173–180. [Google Scholar]
- Zarei, M.R.; Moosavi, M.R. A Memory-Based Collaborative Filtering Recommender System Using Social Ties. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; pp. 263–267. [Google Scholar]
- Fan, W.; Ma, Y.; Yin, D.; Wang, J.; Tang, J.; Li, Q. Deep social collaborative filtering. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; ACM: New York, NY, USA, 2019; pp. 305–313. [Google Scholar]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using Linked Open Data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Yang, X.; Liang, C.; Zhao, M.; Wang, H.; Ding, H.; Liu, Y.; Li, Y.; Zhang, J. Collaborative Filtering-Based Recommendation of Online Social Voting. IEEE Trans. Comput. Soc. Syst. 2017, 4, 1–13. [Google Scholar] [CrossRef]
- Zhang, T. Research on collaborative filtering recommendation algorithm based on social network. Int. J. Internet Manuf. Serv. 2019, 6, 343. [Google Scholar] [CrossRef]
- Guo, L.; Liang, J.; Zhu, Y.; Luo, Y.; Sun, L.; Zheng, X. Collaborative filtering recommendation based on trust and emotion. J. Intell. Inf. Syst. 2019, 53, 113–135. [Google Scholar] [CrossRef]
- Zhang, Z.-P.; Kudo, Y.; Murai, T.; Ren, Y.-G. Enhancing Recommendation Accuracy of Item-Based Collaborative Filtering via Item-Variance Weighting. Appl. Sci. 2019, 9, 1928. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wei, Q.; Zhang, L.; Wang, B.; Ho, W.-H. Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems. Appl. Sci. 2020, 10, 1257. [Google Scholar] [CrossRef] [Green Version]
- Yan, H.; Tang, Y. Collaborative Filtering Based on Gaussian Mixture Model and Improved Jaccard Similarity. IEEE Access 2019, 7, 118690–118701. [Google Scholar] [CrossRef]
- Jiang, L.; Cheng, Y.; Yang, L.; Li, J.; Yan, H.; Wang, X. A trust-based collaborative filtering algorithm for E-commerce recommendation system. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3023–3034. [Google Scholar] [CrossRef] [Green Version]
- Veras De Sena Rosa, R.E.; Guimaraes, F.A.S.; da Silva Mendonça, R.; de Lucena, V.F. Improving Prediction Accuracy in Neighborhood-Based Collaborative Filtering by Using Local Similarity. IEEE Access 2020, 8, 142795–142809. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Hazra, D.; Park, S.; Byun, Y.C. Toward Improving the Prediction Accuracy of Product Recommendation System Using Extreme Gradient Boosting and Encoding Approaches. Symmetry Basel 2020, 12, 1566. [Google Scholar] [CrossRef]
- Iftikhar, A.; Ghazanfar, M.A.; Ayub, M.; Mehmood, Z.; Maqsood, M. An Improved Product Recommendation Method for Collaborative Filtering. IEEE Access 2020, 8, 123841–123857. [Google Scholar] [CrossRef]
- Margaris, D.; Spiliotopoulos, D.; Vassilakis, C.; Vasilopoulos, D. Improving collaborative filtering’s rating prediction accuracy by introducing the experiencing period criterion. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Chen, V.X.; Tang, T.Y. Incorporating Singular Value Decomposition in User-based Collaborative Filtering Technique for a Movie Recommendation System. In Proceedings of the 2019 International Conference on Pattern Recognition and Artificial Intelligence—PRAI ’19, Wenzhou, China, 26–28 August 2019; ACM Press: New York, NY, USA, 2019; pp. 12–15. [Google Scholar]
- Liu, X. Improved Collaborative Filtering Algorithm Based on Multi-dimensional Fusion Similarity. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 440–443. [Google Scholar]
- Singh, P.K.; Sinha, M.; Das, S.; Choudhury, P. Enhancing recommendation accuracy of item-based collaborative filtering using Bhattacharyya coefficient and most similar item. Appl. Intell. 2020, 50, 4708–4731. [Google Scholar] [CrossRef]
- Cao, H.; Chen, Z.; Cheng, M.; Zhao, S.; Wang, T.; Li, Y. You Recommend, I Buy. Proc. ACM Hum. Comput. Interact. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Chen, M.; Beutel, A.; Covington, P.; Jain, S.; Belletti, F.; Chi, E.H. Top-K Off-Policy Correction for a REINFORCE Recommender System. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; ACM: New York, NY, USA, 2019; pp. 456–464. [Google Scholar]
- Jia, H.; Saule, E. An Analysis of Citation Recommender Systems. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, Sydney, Australia, 31 July–3 August 2017; ACM: New York, NY, USA, 2017; pp. 216–223. [Google Scholar]
- Doan, T.-N.; Lim, E.-P. Modeling Check-In Behavior with Geographical Neighborhood Influence of Venues. In Advanced Data Mining and Applications; ADMA 2017 Lecture Notes in Computer Science; Cong, G., Peng, W.C., Zhang, W., Li, C., Sun, A., Eds.; Springer: Cham, Switzerland, 2017; Volume 10604, pp. 429–444. [Google Scholar]
- Margaris, D.; Kobusinska, A.; Spiliotopoulos, D.; Vassilakis, C. An Adaptive Social Network-Aware Collaborative Filtering Algorithm for Improved Rating Prediction Accuracy. IEEE Access 2020, 8, 68301–68310. [Google Scholar] [CrossRef]
- Hassanieh, L.A.; Jaoudeh, C.A.; Abdo, J.B.; Demerjian, J. Similarity measures for collaborative filtering recommender systems. In Proceedings of the 2018 IEEE Middle East and North Africa Communications Conference (MENACOMM), Jounieh, Lebanon, 18–20 April 2018; pp. 1–5. [Google Scholar]
- Kumar, P.; Kumar, V.; Thakur, R.S. A new approach for rating prediction system using collaborative filtering. Iran J. Comput. Sci. 2019, 2, 81–87. [Google Scholar] [CrossRef]
- McAuley, J.; Pandey, R.; Leskovec, J. Inferring Networks of Substitutable and Complementary Products. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’15, Sydney, Australia, 10–13 August 2015; pp. 785–794. [Google Scholar]
- Amazon Product Data. Available online: http://jmcauley.ucsd.edu/data/amazon/links.html (accessed on 11 June 2021).
- Movie Lens Datasets. Available online: http://grouplens.org/datasets/movielens/ (accessed on 11 June 2021).
- Harper, F.M.; Konstan, J.A. The Movie Lens Datasets. ACM Trans. Interact. Intell. Syst. 2016, 5, 1–19. [Google Scholar] [CrossRef]
- Bennett, J.; Elkan, C.; Liu, B.; Smyth, P.; Tikk, D. KDD Cup and workshop 2007. ACM SIGKDD Explor. Newsl. 2007, 9, 51–52. [Google Scholar] [CrossRef]
- Mei, D.; Huang, N.; Li, X. Light Graph Convolutional Collaborative Filtering with Multi-Aspect Information. IEEE Access 2021, 9, 34433–34441. [Google Scholar] [CrossRef]
- Barkan, O.; Fuchs, Y.; Caciularu, A.; Koenigstein, N. Explainable Recommendations via Attentive Multi-Persona Collaborative Filtering. In Proceedings of the Fourteenth ACM Conference on Recommender Systems, Brasilia, Brazil, 22–26 September 2020; ACM: New York, NY, USA, 2020; pp. 468–473. [Google Scholar]
- Zhang, Y.; Lou, J.; Chen, L.; Yuan, X.; Li, J.; Johnsten, T.; Tzeng, N.-F. Towards Poisoning the Neural Collaborative Filtering-Based Recommender Systems. In Computer Security—ESORICS 2020, Proceedings of the 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, 14–18 September 2020; Springer: Cham, Switzerland, 2020; pp. 461–479. [Google Scholar]
- Fang, J.; Li, B.; Gao, M. Collaborative filtering recommendation algorithm based on deep neural network fusion. Int. J. Sens. Netw. 2020, 34, 71. [Google Scholar] [CrossRef]
- Zhang, Z.; Kudo, Y.; Murai, T. Neighbor selection for user-based collaborative filtering using covering-based rough sets. Ann. Oper. Res. 2017, 256, 359–374. [Google Scholar] [CrossRef] [Green Version]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’99, Berkeley, CA, USA, 15–19 August 1999; ACM Press: New York, NY, USA, 1999; pp. 230–237. [Google Scholar]
- Saric, A.; Hadzikadic, M.; Wilson, D. Alternative Formulas for Rating Prediction Using Collaborative Filtering. In International Symposium on Methodologies for Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 301–310. [Google Scholar]
- Jain, G.; Mahara, T.; Tripathi, K.N. A Survey of Similarity Measures for Collaborative Filtering-Based Recommender System. In Soft Computing: Theories and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 343–352. [Google Scholar]
- Bellogín, A.; Sánchez, P. Collaborative filtering based on subsequence matching: A new approach. Inf. Sci. 2017, 418, 432–446. [Google Scholar] [CrossRef]
- Margaris, D.; Spiliotopoulos, D.; Vassilakis, C. Social Relations versus Near Neighbours: Reliable Recommenders in Limited Information Social Network Collaborative Filtering for Online Advertising. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2019), Vancouver, BC, Canada, 27–30 August 2019; ACM: Vancouver, BC, Canada, 2019; pp. 1160–1167. [Google Scholar]
- Ortega, F.; González-Prieto, Á.; Bobadilla, J.; Gutiérrez, A. Collaborative Filtering to Predict Sensor Array Values in Large IoT Networks. Sensors 2020, 20, 4628. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Xu, X.; Xue, F.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized Recommendation System Based on Collaborative Filtering for IoT Scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Gao, H.; Xu, Y.; Yin, Y.; Zhang, W.; Li, R.; Wang, X. Context-Aware QoS Prediction with Neural Collaborative Filtering for Internet-of-Things Services. IEEE Internet Things J. 2020, 7, 4532–4542. [Google Scholar] [CrossRef]
- Li, X.; Cheng, X.; Su, S.; Li, S.; Yang, J. A hybrid collaborative filtering model for social influence prediction in event-based social networks. Neurocomputing 2017, 230, 197–209. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, L.; Lee, K.; Palanisamy, B.; Zhang, Q. Improving Collaborative Filtering with Social Influence over Heterogeneous Information Networks. ACM Trans. Internet Technol. 2020, 20, 1–29. [Google Scholar] [CrossRef]
- Bobadilla, J.; González-Prieto, Á.; Ortega, F.; Lara-Cabrera, R. Deep learning feature selection to unhide demographic recommender systems factors. Neural Comput. Appl. 2021, 33, 7291–7308. [Google Scholar] [CrossRef]
- Yassine, A.; Mohamed, L.; Al Achhab, M. Intelligent recommender system based on unsupervised machine learning and demographic attributes. Simul. Model. Pract. Theory 2021, 107, 102198. [Google Scholar] [CrossRef]
- Keerthika, K.; Saravanan, T. Enhanced Product Recommendations based on Seasonality and Demography in Ecommerce. In Proceedings of the 2020 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 18–19 December 2020; pp. 721–723. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | #Users | #Items | #Ratings | Density |
|---|---|---|---|---|
| Amazon “Videogames” | 24 K | 11 K | 232 K | 0.09% |
| Amazon “CDs and Vinyl” | 75 K | 64 K | 1.1 M | 0.02% |
| Amazon “Movies and TV” | 124 K | 50 K | 1.7 M | 0.03% |
| Amazon “Books” | 604 K | 368 K | 8.9 M | 0.004% |
| MovieLens “Latest 100K—Recommended for education and development” | 670 | 9 K | 100 K | 1.7% |
| NetFlix competition | 480 K | 18 K | 96 M | 1.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Margaris, D.; Spiliotopoulos, D.; Vassilakis, C. Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering. Appl. Sci. 2021, 11, 8369. https://doi.org/10.3390/app11188369
Margaris D, Spiliotopoulos D, Vassilakis C. Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering. Applied Sciences. 2021; 11(18):8369. https://doi.org/10.3390/app11188369
Chicago/Turabian StyleMargaris, Dionisis, Dimitris Spiliotopoulos, and Costas Vassilakis. 2021. "Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering" Applied Sciences 11, no. 18: 8369. https://doi.org/10.3390/app11188369
APA StyleMargaris, D., Spiliotopoulos, D., & Vassilakis, C. (2021). Augmenting Black Sheep Neighbour Importance for Enhancing Rating Prediction Accuracy in Collaborative Filtering. Applied Sciences, 11(18), 8369. https://doi.org/10.3390/app11188369