1. Introduction
For several decades, scheduling and job scheduling have received constant attention from both researchers and practitioners from across the world. Such a level of interest is justified by the broad applications of scheduling which go from production planning and manufacturing [
1,
2], construction [
3], cloud computing [
4,
5], transportation [
6], education [
7], healthcare [
8] to CPUs [
9], Internet of Things [
10] and sensor networks [
11]. Moreover, many scheduling problems are NP-hard, increasing the importance of developing faster and more efficient solving methods for scheduling problems with real-life instance sizes.
In the modern day, the approach to scheduling problems has somewhat changed. In order to better model real-life situations, more specific problem variants with additional constraints are considered. Such constraints may include, for example, transport times [
12], setups [
13], limited buffers [
14] or idle times [
15]. As a result, state-of-the-art solving methods often have to employ problem-specific properties to be efficient. Furthermore, due to ever-growing markets and the emergence of Big Data, larger and larger problems are being considered [
16,
17], which is especially true for cloud scheduling [
18,
19].
Finally, in recent years, there has been significant growth in the field of parallel and distributed computing. This is due to technologies such as Nvidia’s compute unified device architecture (CUDA) and message passing interface (MPI) as well as developments in parallel devices such as general-purpose computing on graphics processing units (GPGPU) and manycore processors. As a result, parallel computing has become one of the main ways of increasing the effectiveness and reducing the running time of solving methods for scheduling problems [
20,
21]. This is especially important for reducing the complexity of computing the goal function, which is often the dominant factor in the running time of the solving method [
22].
In this paper, a permutation flow shop scheduling problem with makespan criterion and minimal and maximal machine idle time (FSSP-MMI) is considered. A similar, non-permutation variant was previously considered in [
23]. FSSP-MMI is a variant of the well-known permutation flow shop scheduling problem (FSSP) [
24]. The problem can be used to model some practical processes, e.g., the concreting process (which was described in [
23]). Moreover, this problem is also a generalization of several other variants, including: (a) no-idle; (b) minimal idle time; (c) maximal idle time; and (d) classic FSSP. The aim of the paper was to propose a novel parallel computing technique for the faster computation of the goal function for FSSP-MMI and to develop a solving method that is: (1) capable of solving large-size FSSP-MMI problems in reasonable time; and (2) working fast enough for small- and medium-sized FSSP-MMI problems to be applicable as a local-search subroutine in larger algorithms. A parallel algorithm for FSSP-MMI was previously proposed [
25], but it required massive numbers of processors, even for small problems. We aimed to rectify this drawback. It should also be noted that while it is intended for FSSP-MMI, the parallel technique will also be applicable for the variants (a)–(d) mentioned above, and with some modifications, for some other variants (e.g., setup times).
As such, the main contributions of this paper can be summarized as follows:
A job shift scan operation, based on prefix sums, for correcting overlapping jobs and applicable to a large class of scheduling problems, is proposed and proven;
A work-efficient parallel algorithm for determining the job shift scan in logarithmic time with regard to the number of jobs is proposed;
A parallel method for the quick calculation of the goal function (makespan) for FSSP-MMI in time instead of is proposed;
A simulated annealing metaheuristic solving method, with a parallel makespan calculation for FSSP-MMI, is implemented using the CUDA platform;
Computer experiments indicate that the proposed solving method is able to obtain better makespans in the same time as its sequential counterpart for large problems.
The rest of the paper is structured as follows.
Section 2 contains the literature overview.
Section 3 describes the considered scheduling problem.
Section 4 contains a short explanation of prefix sums and its parallel computation algorithm.
Section 5 describes an extension of the prefix sums for the correction of overlapping jobs and its parallel computation algorithm. In
Section 6, a parallel method for a quick calculation of the makespan for the considered problem is proposed.
Section 7 describes the proposed metaheuristic solving method.
Section 8 contains the computer experiments using the developed solving method. Finally,
Section 9 contains the conclusions and future work. Moreover,
Table 1 contains the overview of the notation used throughout the paper.
3. Problem Formulation
A manufacturing system with n jobs from the set and m machines from the set is considered. Each job i has to be processed on all machines with denoting the processing time of job i on machine a. Moreover, for each machine a, the values and denote the minimal and maximal idle time, respectively. Thus, after completing the processing of one job and before starting the processing of the next one, machine a has to wait for time t, such that and .
Each job has to be processed on machines in the order of increasing machine number: . This order is fixed and represents the technological process. On the other hand, the order of the processing of jobs is the same for each machine and is a decision variable of the problem. This order is described by n-element tuple where the element denotes the job that is processed as i-th. Henceforth, will be called the solution. Furthermore, a few additional constraints exist. Namely, at any given time, a job can be processed by at most one machine. Similarly, at any given time, a machine can process at most one job. Finally, the processing of jobs cannot be interrupted.
From the solution
, one can construct a schedule as the sequence
S:
where
is in turn another sequence describing the starting time of jobs on machine
a:
Thus,
is the starting time of job
on machine
a. Similarly, one can define sequence
C of the job completion times, such that
is the completion time of job
on machine
a. For the simplicity of the notation value,
will be used as shorthand for
. As such, the schedule
S is feasible if and only if all the following constraints are met:
Constraint (3) ensures that the processing of jobs is not interrupted. Due to constraint (4), a job is completed on machine before it starts processing on machine a (enforcing compliance with the technological process). Finally, constraint (5) ensures that jobs on machine a are processed in the order given by solution and that the minimum and maximum idle times and on machine a are respected. It should be noted that due to (3), both S and C can unambiguously describe the schedule.
A possible method of constructing schedule
C from solution
is described by Algorithm 1. The method is nearly identical to the one shown for the non-permutation variant of the problem in [
23]. In line 1, the completion time for processing job
on machine 1 is set, since that job has no constraints. In lines 2–3, the completion times for the remaining jobs on machine 1 in order from
to
are set. Since there is no previous machine and
, only the constraint (3) and the left side of constraint (5) have to be met. In lines 4–9, the completion times on the remaining machines are calculated, always finishing the calculations on machine
before moving to machine
a. Lines 5–7 are similar to lines 1–3, except the completion time of the same job from the previous machine (terms
and
) is also taken into account. After this, all constraints on machine
a are met except for the right side of constraint (5). This is corrected by lines 8–9, where the completion time
is increased appropriately if the difference between
and
is more than
. It should be noted that, this time, the jobs are processed from
down to
, so the jobs completing later are corrected first. Due to this, there is a guarantee that each job will have to be shifted at most once. The resulting schedule is always feasible. Moreover, the schedule is always left-shifted as any decrease in any of the completion times would either violate one of the constraints (3)–(5) or would not correspond to the solution
. It should also be noted that Algorithm 1 is also sequential and that its running time is
using a single processor.
| Algorithm 1 Constructing left-shifted schedule C from the solution |
![Applsci 11 08204 i001]() |
Finally, let
be the completion time of the job that completes as last in the schedule described by solution
, meaning that:
The value
is commonly referred to as makespan. The goal of optimization is to find a solution
that minimizes the makespan, meaning that:
where
is the set of all possible solutions. Solution
is called the optimal solution.
To summarize, the mathematical model of the problem can be stated as follows:
where values
S,
C and
are calculated from
, as shown in Algorithm 1.
4. Parallel Prefix Sum
This section briefly describes the concept of a prefix sum and the algorithm for its parallel computation. Prefix sums will be used both directly as part of the final algorithm as well as indirectly as a basis for the construction of a custom scan-like operation. It should be noted that all information in this section is well known in the literature.
Let
be a sequence of
n numbers. Then, the inclusive prefix sum of
x is defined as sequence of
n numbers
such that:
In other words,
holds the sum of all elements of
x up to the
i-th element and including it. Similarly, the exclusive prefix sum is defined as the sequence
such that:
Thus,
holds the sum of all elements up to the
i-th but without including it. It should also be noted that transforming between
y and
is easy as
or alternatively:
The concept of prefix sums has many applications, as pointed out by Blelloch [
57]. Various authors have applied them to robotics [
58], text pattern matching [
59] and
k-means clustering [
60]—among other applications.
Let us discuss the computation complexity of determining prefix sums
y and
for a sequence
x of
n elements. On a single processor, computing either sum requires performing
n additions for a total run time of
using the simple recursive formula:
For parallel algorithms, Hillis and Steele [
61] proposed an algorithm that runs on PRAM with
n processors in time
. Unfortunately, this algorithm is not work-efficient as the total number of addition operations performed is
.
A work-efficient algorithm exists, as was shown by Blelloch [
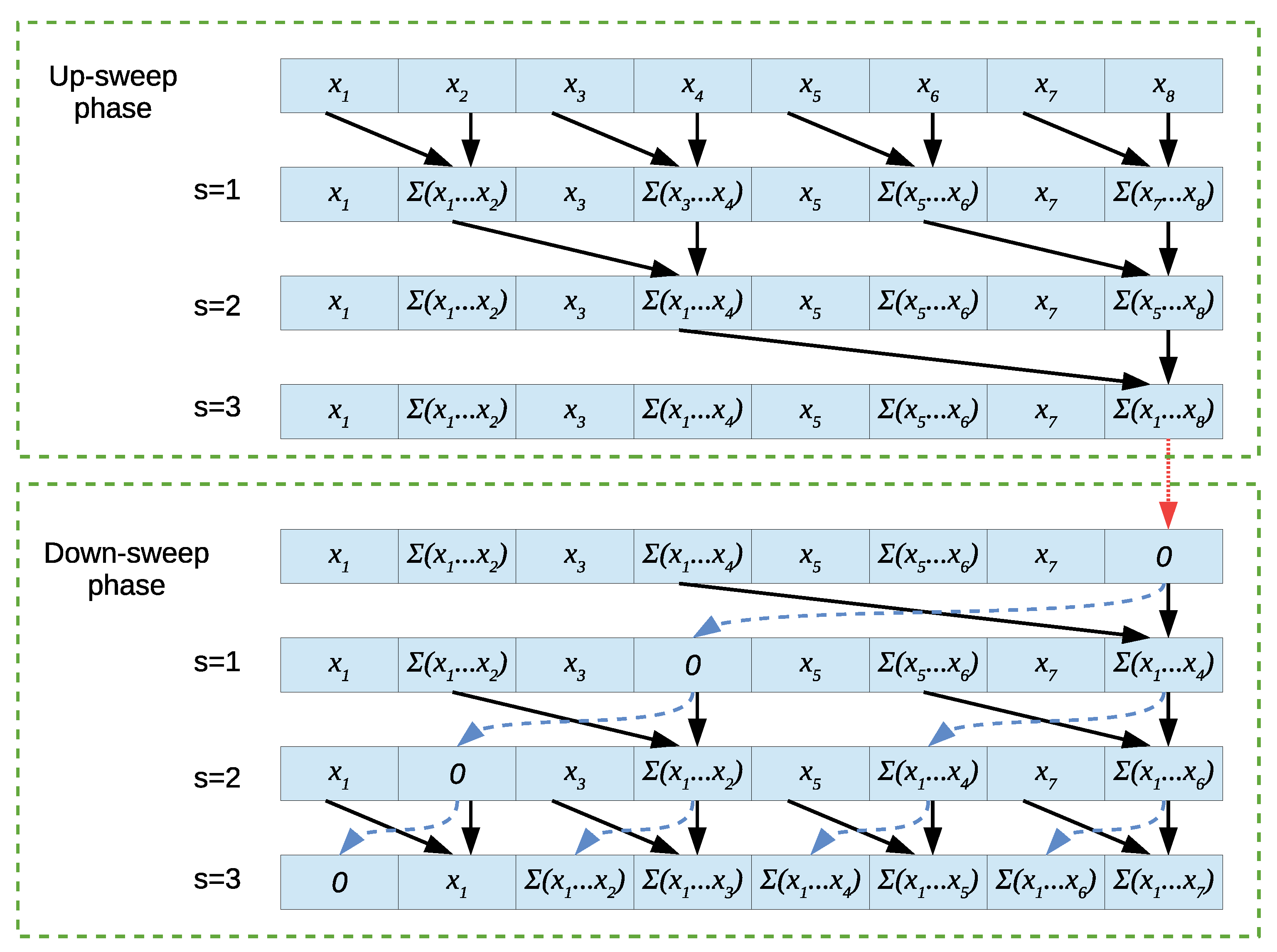
57], and its pseudocode is presented in Algorithm 2. The algorithm works in-place and consists of two major phases: up-sweep and down-sweep. The phases are based on the leaves-to-root and root-to-leaves traversal of binary trees, respectively. The example of how the algorithm works at each step is shown in
Figure 1 for
. Black arrow pairs indicate addition, blue dashed arrows indicate copying and the dotted red arrow indicates the zeroing of the last element.
| Algorithm 2 Work-efficient exclusive parallel prefix sum computation |
![Applsci 11 08204 i002]() |
Lines 1–3 correspond to the up-sweep phase. This phase has steps. In each step, a number of processors compute partial sums. At the end of this phase, the element holds the sum of all elements. Then, in line 4, we zero that element and start the down-sweep phases which happen in lines 5–9. This phase is more complex. At each step, first the value of the “right” element is stored in the temporary variable t (which is a separate private variable for each processor). This corresponds to the start of the blue arrow. Then, a regular addition of the “left” and “right” element is performed and the result is stored in the “right” element. Finally, the blue copying operation is completed by putting the stored value t in the “left” element. The entire algorithm performs additions, copy operations and one zeroing of an element. It thus runs in time on PRAM with n processors and performs additions. One issue is that the base form of the algorithm assumes that n is a power of 2. However, this can be remedied by running the algorithm for size and then either skipping operations that modify elements above element n or discarding the part of the output beyond element n. Let us also note that although Algorithm 2 computes the exclusive prefix sum only, Equations (17)–(19) can be used to quickly transform this result into an inclusive prefix sum.
5. Parallel Job Shift Scan
The concept of prefix sums is based on the addition operator +. However, it was shown before (e.g., by Bleboch [
57]) that the idea can be generalized for a larger class of associative binary operations, for example, the multiplication or maximum. Such a prefix sum generalization is usually called a “scan”. One such scan operation that pertains to scheduling problems will be proposed in this section.
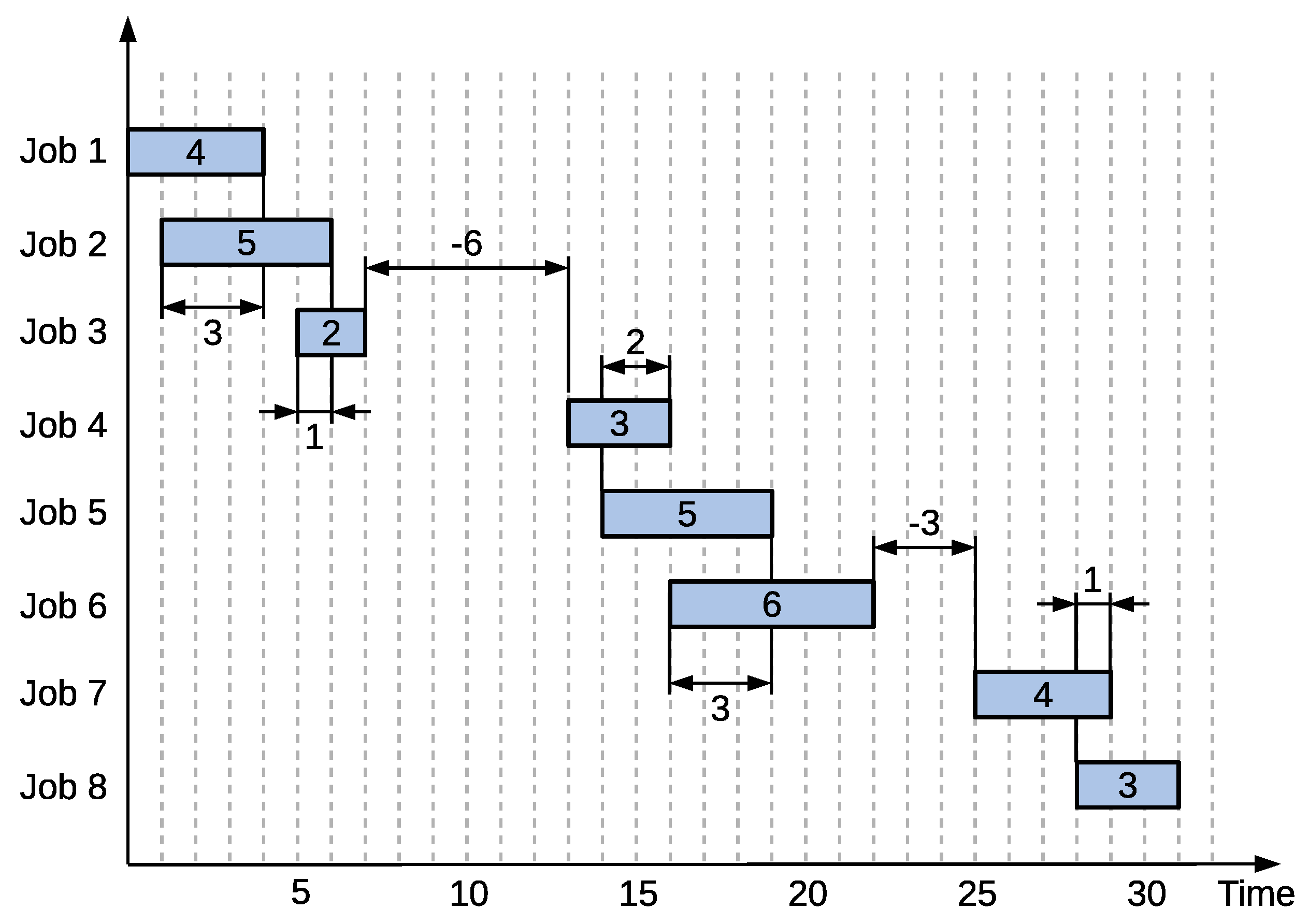
As an example, a schedule for some machine
a in the FSSP with
jobs will be considered. Assume the starting and completion times for jobs on that machine have been set as follows:
Furthermore, assume that the starting times cannot be decreased because they are constrained by completion times on the previous machine, e.g.,
cannot be decreased, because
. Furthermore, assume that the starting and completion times satisfy constraint (3). However, even under those assumptions, the considered schedule is not feasible. This can clearly be seen in
Figure 2. Several jobs are overlapping each other (note that this is still a single machine: vertical differences are for easier visualization only). Indeed, for each pair of adjacent jobs, one can compute
, as indicated in the figure by the dimension lines. If the resulting distance is positive, then the jobs
i and
overlap and the job
should be shifted to start later.
However, such a shift is not always enough. Consider the second and third jobs from
Figure 2 with processing times 5 and 2, respectively. Their required shifts are 3 and 1, respectively. Shifting the third job by 1 would be enough if the second job was not shifted as well. As such, the third job needs to be shifted by 4, which is the sum of shifts values 3 and 1. The required “true” shift at job
i is thus related to the sum of shifts up to that job. There is, however, an exception. Consider the fourth job. Its “local” shift is −6, while the sum of previous shifts before it is 4. A regular sum of the two would yield −2 and shift the fourth job earlier. However, the assumption was that jobs cannot decrease their starting times. Thus, the fourth job will not be shifted at all and the sum of −2 is changed to 0 instead. As a result, the sequence
y of the “true” required shifts for all jobs on machine
a is an inclusive scan function given by a recursive formula:
where
is the “local” shift of job
i. It should be noted that value
(and consequently
) is zero when the entire input is considered. This is because the first job processed on the machine has no preceding job and thus will never have to be shifted in this situation. This type of scan function will be called an “inclusive job shift scan”. The exclusive variant can be defined similarly as in the case of a regular prefix sum. For the example schedule from Equations (22) and (23), the resulting “true” job shifts are thus:
After applying these shifts, the corrected feasible schedule on the machine
a is obtained:
In this schedule, no jobs overlap with each other and no job was shifted earlier.
Before moving on to the next section, let us discuss the computational complexity of calculating the job shift scan. For the sequential algorithm, one directly applies Formulas (24) and (25), resulting in a running time of
for
n jobs. As for a parallel algorithm, the first idea was to use Algorithm 2 and adjust it to the job shift scan by replacing the standard summation of
with
as per Formulas (24) and (25). However, such an approach does not work as will be shown with another example. Let us consider the input sequence
. According to the formulas above, the value of the last element of the job shift scan would be:
Now, it is shown that the up-sweep phase of Algorithm 2 ends with the last element of the sequence holding the total sum. For the job shift scan, this element should hold the value 3 computed above. Let us verify this by performing the phase. First, partial sums of elements and as well as and are computed. The results are and . Then, those partial sums are used to compute the final result . However, this does not match the results from (29).
The above shows that applying the base formula directly does not work for the parallel algorithm. The reason for this is that the input has been divided into two subsequences (or blocks): and . The value is placed on the left-most side of the block, informing us how large of a shift the block is able to initially “absorb” before the actual shift takes place. However, when computing the block on its own, the resulting value is 0 and the information of how much of a shift the block can initially absorb is lost. Even if one were to delay applying the maximum, the result of is still , while in reality, the block can “absorb” the shift of 4. Since the sum of the previous block is 2, the resulting total sum remains incorrect.
The above issue can be solved as follows. We start by adding a second temporary sequence
z with the same number of elements as
x and
y. Thus, each block of elements (jobs)
i will be described by a pair of values
and
. Value
indicates the job shift at the end of block
i (at its right-most job). This value will either be positive (shift of size
required) or zero (no shift). On the other hand,
will indicate the maximal shift from a preceding (“left”) block that block
i is able to absorb without forcing an additional shift on the following (“right”) blocks. As such, the
value will either be positive (absorption of a shift up to
is possible) or zero (no absorption possible). Values
and
are computed simultaneously. After both sequences were determined, sequence
z is discarded (it is only required through the calculation to keep track of the current absorption), while sequence
y holds the required job shift scan. Thus, the previous operation in the form of:
is replaced with a new operation:
The remaining questions are: (1) how to define the binary operator ⊕; and (2) how to define the initial values of sequences y and z based on x. Question (2) is answered by the following Lemma.
Lemma 1. Let be an element of input sequence x, i.e., is a block of jobs of size 1. Then, the values and describing that block are given by Proof. Three cases must be considered: when is positive; equal to zero; and negative. When , then the job overlaps with the previous one and the length of the overlapped part is . In this case, is the required “local” shift, so . Since the job itself will be shifted to the right, then no additional shift from earlier elements can be absorbed and thus the left-most absorption . These results match the assumed Equations (32) and (33). When , then the starting time of the job is exactly the same as the completion time of the previous job. In such a case, no shift is necessary, but any shift from the left will propagate, leaving no possibility of absorption. Thus, , matching the expected values from (32) and (33). Finally, when , then there is a gap from the previous job of length . As a result, the job is not shifted, so . Furthermore, due to the gap, we can absorb the shift from the left up to the size of the gap, so . Once again, this matches the expected Equations (32) and (33). □
The above Lemma described how to initialize sequences y and z. Now, the other question is that of how to combine two adjacent blocks, i.e., how to define the operation ⊕ from (31). This was performed by the following Lemma.
Lemma 2. Let and where and be two blocks of jobs. Let these blocks be described by pairs and , respectively. Then, block is described by pair which is given by Proof. Let us first notice that blocks a and b are continuous, i.e., block a contains all jobs from the one being processed on the considered machine as i-th to the one being processed as j-th and block b contains all jobs from the -th to k-th. Secondly, the blocks are adjacent with block a appearing earlier, i.e., the next job being processed on the machine after processing all jobs of block a is the first job of block b.
First consider the value . This value should be the largest shift coming from the left that the combined block c can absorb. It is known that the left-most side of c is also the left-most side of a, so c will be able to absorb at least as big of a shift as a would, hence . If the shift exceeds , then a will absorb the of it and the rest will propagate into block b. Block b would normally be able to absorb the shift of , but one also needs to take into account the shift of block a that will be propagated into b. Three cases are possible. If , then b can absorb and the total possible absorption of c is simply . If but , then b will absorb from a and will still be able to absorb up to , which was not absorbed from . The total possible absorption will then be . Finally, if , then b will use all of to absorb the shift from a, meaning that it will not be able to absorb any additional shift from the block preceding a, so the total absorption of c will just be . All three cases match the expected result (35).
Now, consider the value in a similar manner. This value should be the total shift that will be propagated into the next block to the “right” of c. The right-most part of c is b so this shift will be at least as big as . Now, one also needs to add the possible shift from block a. Normally, this would be , but block b can itself absorb up to . Once again, three subcases are possible. If , then b cannot absorb anything and the entire shift propagates to the end of b. As a result, . If but , then b will absorb the shift of and the remainder of will be propagated and thus . Finally, if , then b will absorb all of and nothing will propagate into b, leaving . All of these cases match the expected result (34). □
With Lemma 2, the binary relation:
was defined through:
Before proceeding, two more properties of the binary operation ⊕, which will be required for the next step, will be proven as short corollaries below.
Corollary 1. The binary operation is not commutative.
Proof. To prove this property, it is sufficient to show a single example for which:
After applying the formulas from Lemma 2 one obtains
. Now, if the operands are swapped then the result is:
□
Corollary 2. The neutral element of the binary relation is .
Proof. This is trivially proven by assuming and in formulas from Lemma 2 and showing that, as a result, and . Since ⊕ is not commutative, it is also done in reverse by assuming and and showing that and . In both cases, the results match the expectation. □
With Lemmas 1 and 2 as well as Corollaries 1 and 2, it is now possible to propose the parallel algorithm for the job shift scan.
Theorem 1. The job shift scan given by the recursive Formulas (24) and (25) for the input sequence of n elements can be determined in time on a PRAM machine with n processors.
Proof. The algorithm is based on Algorithm 2, but with several changes applied. Before the start of the up-sweep phase, an additional array z with n elements is created. Since the algorithm works in-place, the array x will serve as array y. Arrays x and z are initialized as per Equations (32) and (33) from Lemma 1. It should be noted that (33) is performed first, as (32) overwrites . Since each pair can be computed separately, this x and z initialization phase can be done in time using n processors.
Then, the up-sweep phase of Algorithm 2 is conducted, which is performed the same way as for a regular prefix sum, with one exception: the + operator in line 3 is replaced with the ⊕ operator from Lemma 2. Because of this, line 3 will turn into two separate assignments. Furthermore, the value is updated first and then . This is because the new value of requires the old value of . This way, one avoids using temporary variables. While calculating (37) and (38) takes more time than a simple addition and assignment, it can still be achieved in time . Thus, the up-sweep phase can be performed in time using n processors, just as in the case of the regular prefix sum.
Before proceeding to the down-sweep phase, the last element has to be zeroed (red arrow in
Figure 1. This is done by writing 0 to both
and
(as per Corollary 2). Then, the down-sweep phase starts. The copying of elements (blue arrows) is simply performed by doing both
and
for appropriate
i and
j values. Finally, the + operations (black arrows) once again need to be replaced with the new ⊕ operations. However, there is one difference compared with the up-sweep phase. Let us go back to
Figure 1 and see how
is computed during the down-sweep phase (
). This is done by summing
with
. However,
, which represents earlier jobs, is on the right, while
, representing later jobs, is on the left. This property is true for the entirety of the down-sweep phase. For the regular prefix sum, it had no consequence as the + operator is commutative. However, as per Corollary 1, the ⊕ operator is not commutative. In order to fix this, one needs to swap the order of operands in line 8 of the Algorithm 2. With the presented changes, the down-sweep phase of the algorithm can be completed in time
using
n processors.
After the down-sweep phase is finished, array x contains the required job shift scan, while array z can be discarded. The running time of the algorithm on PRAM with n processors is . □
It is also easy to see that the above parallel job shift scan algorithm is work-efficient as it performs the
addition and maximum operations, just as the sequential version that is directly derived from Equations (
24) and (25).
6. Parallel Makespan Calculation
In this section, the results of Theorem 1 as well as the parallel prefix sums will be applied to reduce the time required to compute the makespan for the FSSP-MMI problem, as shown by the following Theorem.
Theorem 2. Let π be a solution for the permutation flow shop problem with minimal and maximal idle time. Then, the makespan for π can be determined in time on PRAM with n processors.
Proof. In order to stay consistent with the nomenclature of the paper, will be used for indexing, instead of . The actual implementation can use either. It is also assumed that and are matrices such that row a contains processing (or completion) times for machine a. As a reminder, takes into account the processing order , while does not. Thus, one must remember to access instead of .
The algorithm is split into m phases, with phase a determining all values on machine a before moving onto machine .
Phase 1 is started by performing an exclusive prefix sum of sequence
and using sequence
as output. This can be done in time
with Algorithm 2. After this,
contains the sum of the processing times of all jobs processed on
a before job
i. Then, each value
is modified as follows:
The above can be calculated for each
i independently, so it can be done in time
with
n processors. The reason it is done this way is that, on the first machine, one does not have to worry about the previous machine or maximal idle time
. The jobs are “glued” together: the first job starts at time 0 and the next job starts exactly
after the previous job is completed. The starting time of a job is thus the sum of the processing times of all jobs before it (performed by the prefix sum) plus the minimal idle time
occurring exactly
times (performed by (
42)). However, since a completion time is needed, and not a starting time,
is added as well. After this,
holds correct completion times for machine 1, which was done in time
using
n processors.
Let us move onto phases 2 through
m. They are more complex compared to phase 1, however, they are identical to each other, so only one of them will be described. Assume it is phase
a. The phase is started as essentially identical to phase 1: the exclusive prefix sum of
is computed, using
as output and corrected with:
Essentially being the same as phase 1, the part of phase a up to this point can be performed in time using n processors.
The computed values
hold completion times; however, they satisfy only the left side of constraint (5). Those starting times need to be corrected to satisfy the constraint (4). The corrections are started by performing:
This correction is similar to the original line 7 of Algorithm 1. Furthermore, since each value can be corrected independently, this correction can be performed in time .
However, there is one issue with the correction (
44): it is only local. If
is increased by 5, while
is not increased at all and the gap between the completion time of
i and starting time of
was less than 5, then the jobs will overlap. However, this is exactly the same issue which was discussed in
Section 5 and
Figure 2 that led to the definition of the job shift scan. Thus, this scan can be used to compute the “true” required shift and finish the correction as shown below.
First, the needed “local” jobs shifts are computed in array
x of
n elements as follows:
The first job on the machine has no preceding jobs, hence . For subsequent jobs, one computes the difference between the completion time of job (value ) and the starting time of job i (value ). If there is no need for a job shift, then the difference should be equal to the minimal idle time, hence the last term . Since each element is computed independently, the entire array can be calculated in time on n processors.
Then, the job shift scan is calculated in parallel in time
with input in array
as shown by Theorem 1. The additional arrays
y and
z of
n elements are used, as required by this algorithm. As a result, array
y now holds the “true” shifts required for each job. The only problem is that the algorithm yields the exclusive job shift scan, while an inclusive one is required. Thus, the result of the job shift scan is applied to correct the completion times
, while also applying Formulas (
18) and (19) to obtain the inclusive scan:
Terms
and
change the exclusive job shift scan into an inclusive one, where
is obtained through:
The corrections (
47)–(
49) can also be done in time
.
The phase
a up to this point can be performed in time
. The resulting completion times
satisfy all of the constraints (
3)–(5) with one exception: the right side of the constraint (5), which pertains to the maximal idle time
. In other words, the phases so far give the same result as lines 1–7 from the sequential Algorithm 1. In other words, a parallel equivalent of the remaining lines 8–9 of that algorithm needs to be performed as well.
Fortunately, this last issue can be corrected in similar fashion; however, instead of preventing jobs overlapping, excessively large gaps between jobs are prevented. Specifically, one can compute the difference between the starting time of job
and the completion time of job
i. If the difference is more than
, then there is a “local” required shift for job
i. Otherwise, there is no shift required, but there might be a possibility of absorption. The difference is that, previously, one block was pushed, which could result in the block to its right being pushed as well. This time, a block is being “pulled” to the next block (because there was more of a gap between them than is allowed), which might in turn force the block to its left to be “pulled” as well. Despite this “practical” difference, it is mathematically the same process. Thus, the array
is once again prepared in time
as follows:
As one can see, this time the array is prepared a little differently. This is because previously the first job always had a 0 shift and then shifts propagated from left to right. This time, the last job
n has no required shift and “pulls” propagate from right to left. Thus, the direction has to be changed. The simplest way to do this is to prepare the input
x from the other end, which allows using the same parallel job shift scan as previously, which will be completed in time
. After obtaining the job shift scan (using arrays
y and
z), the correction is applied, remembering to reverse the direction back and change the scan from exclusive to inclusive:
where
is obtained as before. This correction is done in time
. After this, all completion times in sequence
are correct and phase
a ends. All operations in phase
a had a running time of either
or
thus the entire phase can be completed in time
using
n processors.
After phase m was completed, the value of the makespan is equal to . Since any phase (including phase 1) can be done in time and there are m phases, in conclusion, the algorithm runs in time on PRAM with n processors. □
It should be noted that, while the results of Theorem 1 were employed to calculate the goal function for FSSP-MMI, the job shift scan has wider applications. It could be used for a multitude of scheduling problems with precedence constraints (need for pushing or pulling jobs according to some rules with propagation in place). Similar results could be obtained for scheduling problems with limited wait constraints or setup times, for example. In particular, this result can be employed for classic and widely-used FSSPs with any method that requires recalculating the makespan from scratch. Such a situation arises, for example, with genetic operators in many Genetic Algorithm-based approaches to scheduling.
8. Computer Experiment
In this section, the results of computer experiments to measure the parallel speedup of the proposed solving methods as well as some of its subroutines are described. The problem instances generation, the experiment setting and the measure of quality for comparing different variants of the SA metaheuristic will also be described.
Considering the testing environment and software used, all programs were written in C/C++ in Visual Studio 2019 version 16.10.2 and compiled using the Release configuration. All programs were run on a server with the AMD Ryzen Threadripper 3990X CPU (2.9 MHz, 64-cores), 64 GB of RAM and an RTX 2080 Ti GPU (1.35 GHz, 11 GB memory, 4352 CUDA cores) in the Microsoft Windows 10 Pro operating system.
In the first experiment, the speedups obtained for several subroutines are shown. At first, for comparison, the results of the implementation of the parallel prefix sum calculation are presented. For each input length
n, an array of
n integers of random values were created. The prefix sum calculation was then executed on CPU, the GPU with the single thread and GPU with
n threads, obtaining the running times
,
and
, respectively. Since the running times were small, the computation was repeated a number of times depending on
n (e.g., 400,000 times for
and 25 times for
n = 262,144) and the total running time was measured. After this, the obtained total was divided by the number of repetitions. The measured running times (in milliseconds) and speedups of the parallel version against both sequential versions are shown in
Table 2.
It can be observed that the speedup compared to the sequential GPU was already visible at
elements with the maximal speedup of over 350 at
n = 262,144. Compared to the CPU, the speedups are much lower both due to the lower GPU core speeds as well as the overhead of the executing CUDA kernels. Nonetheless, speedups against CPU are observed for
32,768 with a maximal speedup of 4.55. This is similar to the speedup reported by Harris et al. for the same
n [
67].
The next experiment concerns the running times and speedups of the job shift scan from Theorem 1 and the goal function calculation from Theorem 2. Similar experiments as with the prefix sums were performed but with a different number of repetitions. For the makespan calculation
was assumed. Such a number of machines allowed to lessen the effect of the constant overhead, while also keeping the computation time reasonable. Reporting the running times of the sequential GPU and CPU versions was omitted, as they can be derived from the speedup. The results are shown in
Table 3.
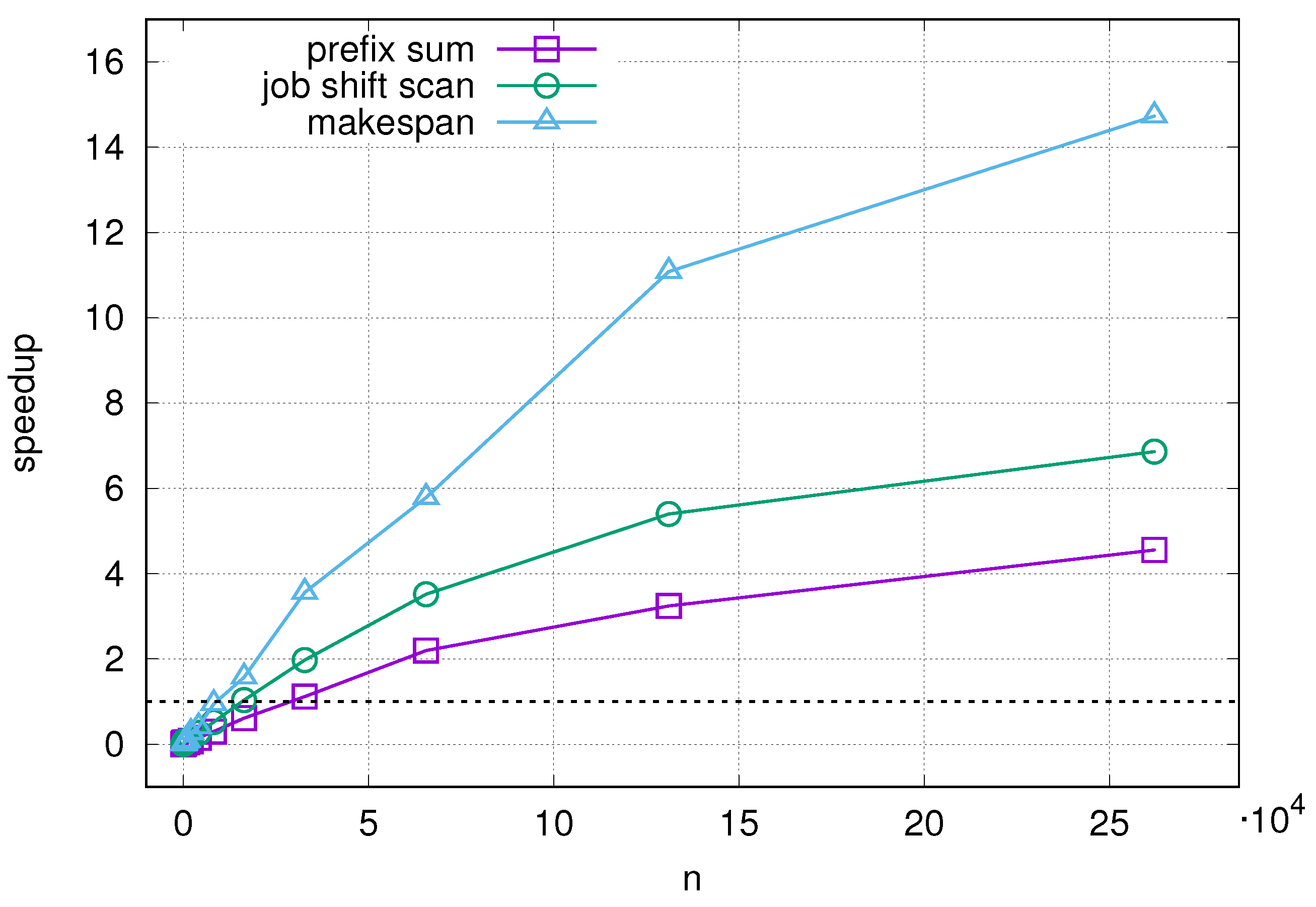
The computation times and speedups against the sequential GPU for the job shift scan are comparable to those for the prefix sum from
Table 2. Speedups against the CPU are observed for
16,384 with the top speedup of over 6.8. The results for the makespan calculation, however, are more surprising. Even though this procedure relies on the prefix sum and jobs shift scan, the observed speedups are vastly different. The speedup against GPU is lower at first (observable from approximately
), but becomes much higher, with over 1000 for
n = 262,144. Similarly, against CPU, the speedup is obtained from approximately
and the highest speedup observed is over 14.7. However, one possible explanation for this result is that most of the CUDA kernels launched during the makespan computation work in time
instead of
—further increasing the perceived speedup. The speedups obtained for the prefix sum, job shift scan and makespan calculations against the GPU and CPU are shown in
Figure 3 and
Figure 4.
Then, research was conducted to compare the SAC, SAG and SAP variants of the SA metaheuristic. As for problem instances, 12 instances groups were prepared with
sizes from
to 65,536 × 300. The reason for choosing such an instance size was both to consider large-scale problems (for cloud scheduling and Big Data applications), as well as to research the limitations of the speedup achievable with this method. For each instance group, 10 instances were prepared (as in the original Taillard scheme), yielding 120 instances in total. Each instance was generated using the pseudo-random number generator used by Taillard [
68], which is often used, with slight modification, by researchers, in order to stay consistent with Taillard’s original instances. The generation procedure is shown in Algorithm 4. The same 120 seed values as in Taillard’s were used.
| Algorithm 4 Instance generation procedure |
![Applsci 11 08204 i004]() |
All three SA variants have a time limit as their stopping conditions, thus, the comparison will be based on the quality of solutions (makespan values) the variants are able to provide in that time limit. In order to compare instances of vastly different sizes, the percentage relative deviation (PRD) was chosen as the quality measure. Assuming that
is a solution provided by the given algorithm for the given instance, then PRD is defined as
where
is a reference solution. Ideally, this would be the optimal solution, but it can be also a best-known or arbitrary solution. In this research, the parallel variant (SAP) will be compared with the sequential variants (SAG and SAC), therefore:
where
,
,
are the solutions found by the SAP, SAG and SAC variants, respectively. Furthermore,
,
and
denote the number of iterations performed by the SAP, SAG and SAC variants, respectively.
Since SA is a probabilistic method, every instance was executed 10 times and the results are shown in
Table 4. Each value is an average out of 100 runs (10 instances, 10 repeats for instance). As expected, the SAP variant is able to perform more iterations in the given time limit starting at approximately
. At
65,536, the SAP is able to complete 665 times more iterations than SAG. Similarly, from approximately
11,000, the SAP variant performs more iterations than SAC, with almost as many as six times more at
65,536. By executing more iterations, the SAP variant provided makespans shorter by up to 5% on average compared to the SAG variant, with the highest average improvement (4.8%) observed for
. The improvement when compared with the SAC variant is much smaller (under 0.5%), but still noticeable.



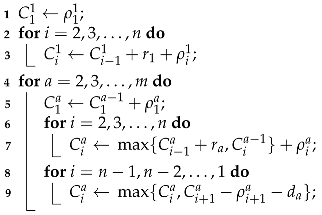
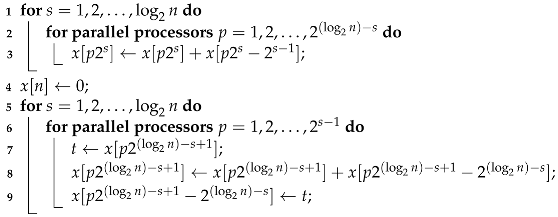




{kind=link}
{kind=link}
{kind=link}
{kind=link}