
Framework for the Ensemble of Feature Selection Methods


Abstract
1. Introduction
1.1. Dataset’s Growth
1.2. Context of Ensemble Feature Selection
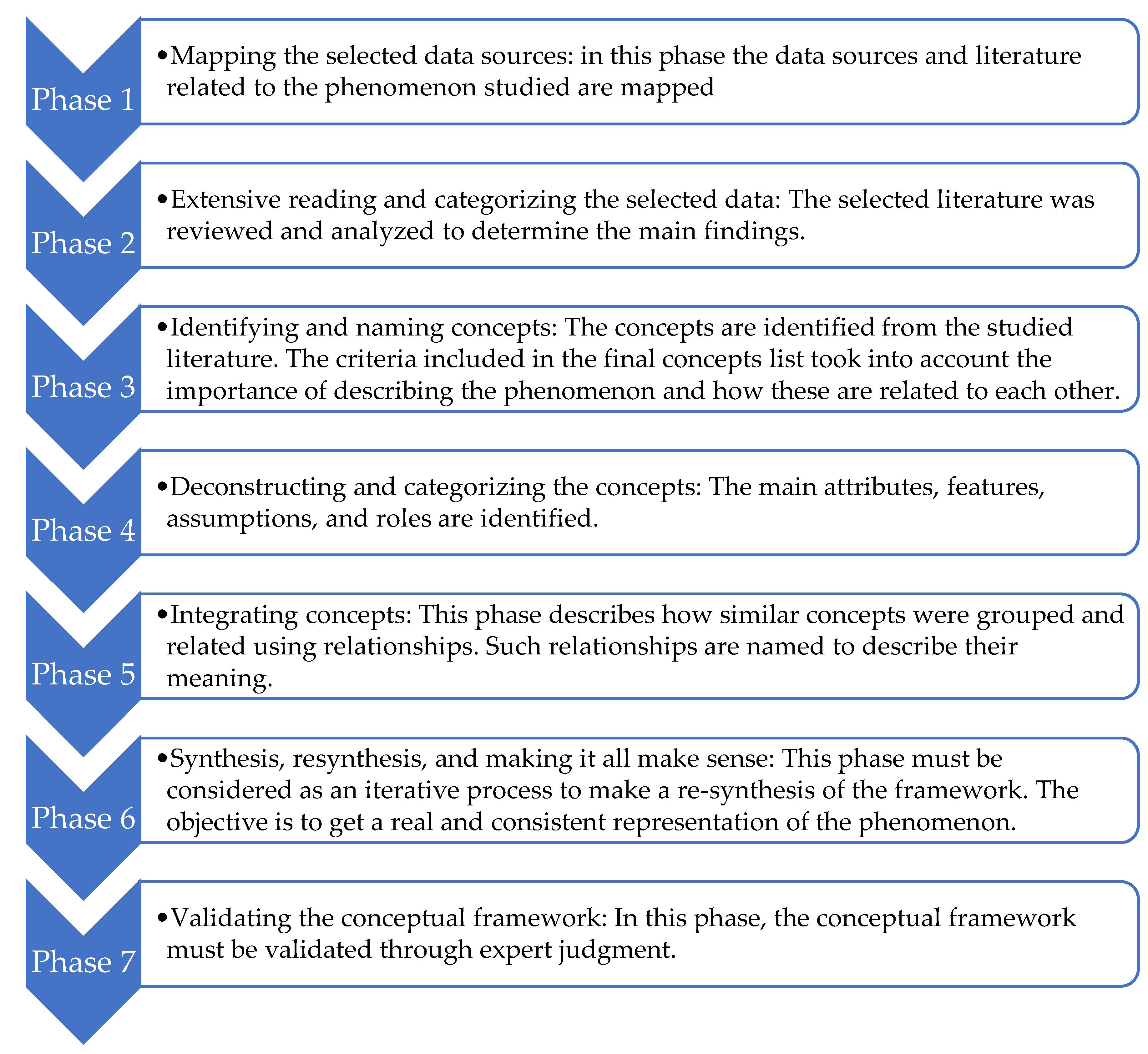
2. Materials and Methods
2.1. Phase 1: Mapping the Selected Data Sources
- Machine Learning
- Relevance Analysis
- Feature Selection
- Dimensionality Reduction
- Ensemble Learning
- Ensemble Feature Selection
- Consensus and aggregation
2.2. Phase 2: Extensive Reading and Categorizing the Selected Data
- Feature Selection
- Performance
- Classification
- Ensemble Learning
- Consensus-Aggregation
2.3. Phase 4: Deconstructing and Categorizing the Concepts
2.4. Phase 6: Synthesis, Re-Synthesis, and Making It All Make Sense
2.5. Phase 7: Validating the Conceptual Framework
3. Results
3.1. Main Concepts
- Filters: techniques that are easy to implement and can be scaled to use datasets with high dimensionality. Nonetheless, this type ignores the interaction with a classifier. For example, an function evaluates the relevance of each feature, and the output of the filter algorithm corresponds to a ranking that orders the features according to [30].
- Wrappers: methods, which evaluate the relevance of the subsets of features by using a classifier. Thereby, the best subset of features is selected by the learning algorithm. However, the computational cost of these techniques is high because when choosing the best subset, many subsets must be evaluated [5].
- Embedded: type of mechanism, which combines the advantages of the filters and wrappers. The main objective is to get the best performance in the learning process from a learning algorithm using a subset of features [2].
- Consensus: In ensemble learning, it is also called consensus theory of aggregation. Widely used in social sciences and administration, its main objective is to find a way to combine expert opinions through consensus rules [31].
3.2. Conceptual Framework
- Instances must have values in all their columns.
- Instances must not have outliers.
- Values cannot be negative to avoid problems with statistical tests.
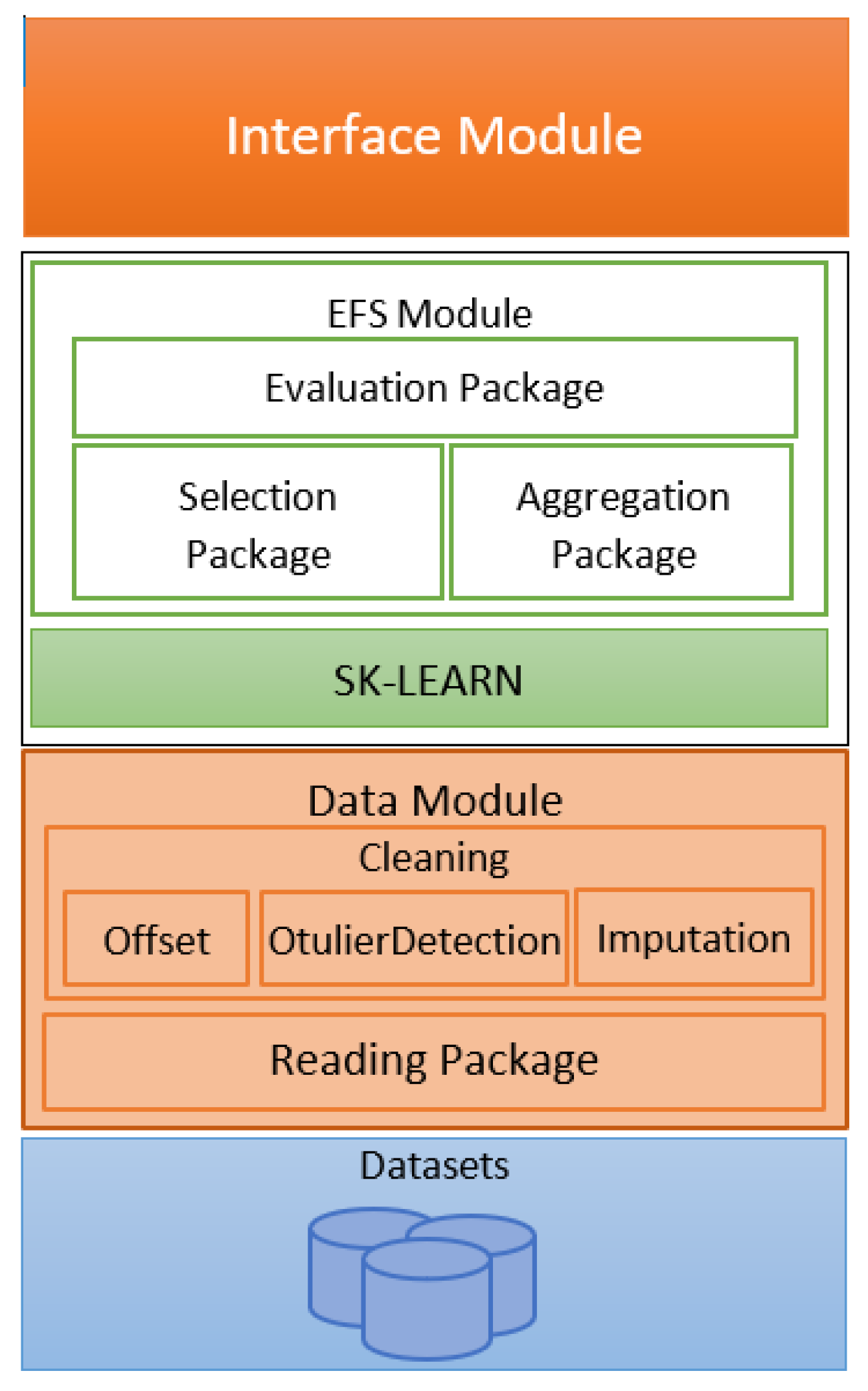
3.3. Implementation of the Conceptual Framework
- Interface Module: It describes a class. The module exposes the functionalities of the framework to new implementations.
- EFS Module: It is the core of the framework. This component includes all the functionalities associated with the FS based on our ensemble method.
- Evaluation Package: This groups a set of functions to evaluate the accuracy and stability of an EFS output.
- Selection Package: It contains a set of methods to select subsets of relevant features.
- Aggregation Package: It integrates the outputs of n methods of FS using a criterion to aggregate the outputs.
- SCIKIT-LEARN: It is a Machine Learning library that supports the implementation of our EFS package.
- Data Module: It includes the functions to read and preprocess the datasets. The module allows the reading of data from CVS files to adjust them according to assumptions and constraints considered in the conceptual framework design.
- Offset Package: It describes functionalities to calculate an offset dataset to avoid negative values.
- Imputation Package: It implements the Multivariate Imputation to handle datasets with missing values. The authors presented the implementation and evaluation of this component in a previous study [36].
- Outliers Detection Package: This package considers a software component to implement methods of detection of outliers. These methods include, for instance, basic methods as the Standard Deviation or advanced methods as Novelty and Outlier Detection from scikit-learn [37].
3.3.1. Evaluation of the Framework
3.3.2. Performance
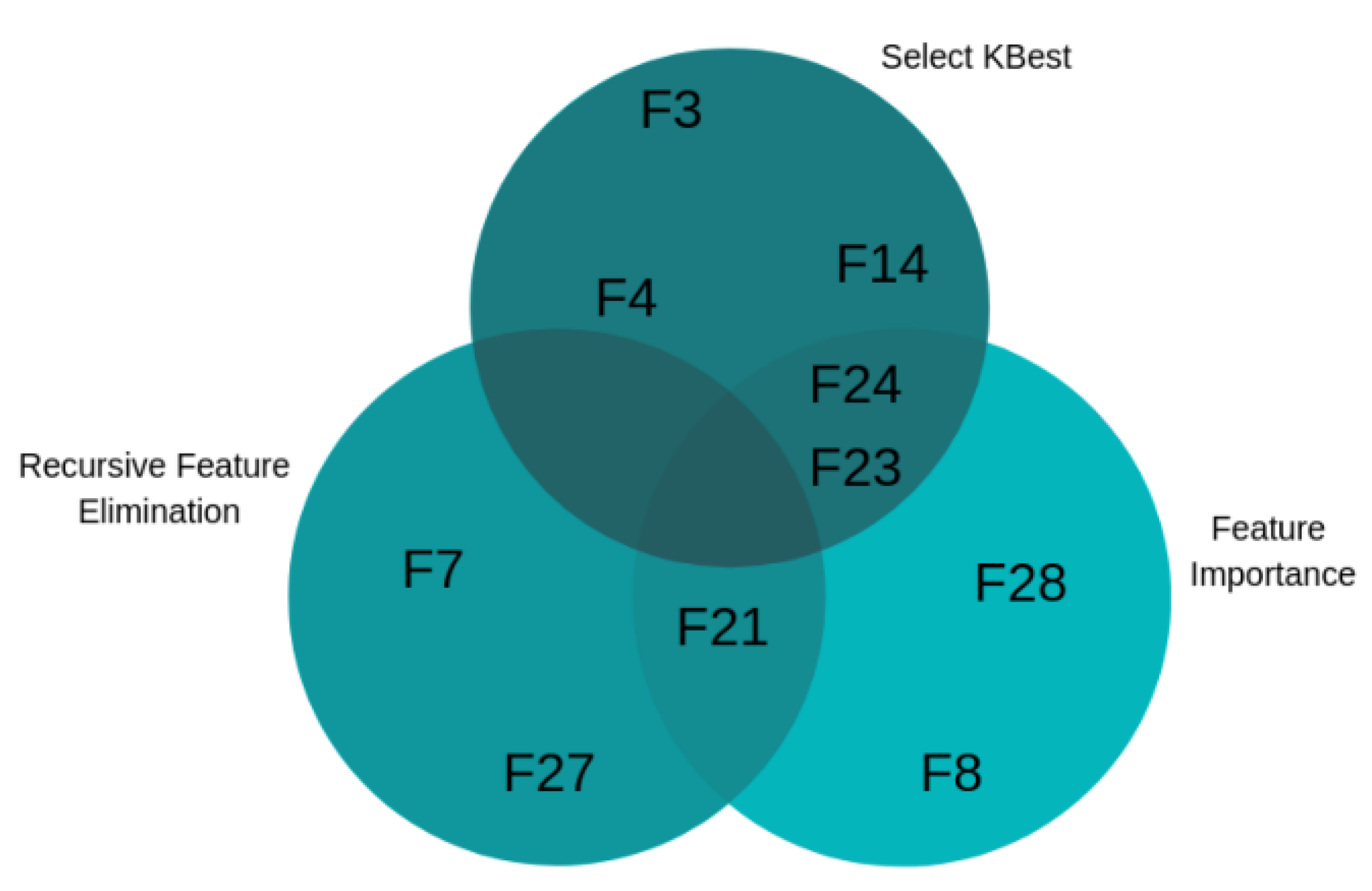
3.3.3. Subsets of Relevant Features
3.3.4. Stability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pereira, A.G. Selección de Características Para el Reconocimiento de Patrones con Datos de Alta Dimensionalidad en Fusión Nuclear. Ph.D. Thesis, Universidad Nacional de Educacion a Distancia, Bogotá, Colombia, 2015. [Google Scholar]
- Guyon, I. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition, 2nd ed.; Academic Press: San Diego, CA, USA, 2003. [Google Scholar]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef]
- Kohavi, R.; John, H. Artificial Intelligence Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Sa, N.; Bolo, V. An ensemble of filters and classifiers for microarray data classification. Pattern Recognit. J. 2012, 45, 531–539. [Google Scholar]
- Bolon-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A.; Benitez, J.M.; Herrera, F. A review of microarray datasets and applied feature selection methods. Inf. Sci. 2014, 282, 111–135. [Google Scholar] [CrossRef]
- Lee, C.-P.; Leu, Y. A novel hybrid feature selection method for microarray data analysis. Appl. Soft Comput. 2011, 11, 208–213. [Google Scholar] [CrossRef]
- Li, Y.; Wang, G.; Chen, H.; Shi, L.; Qin, L. An Ant Colony Optimization Based Dimension Reduction Method for High-Dimensional Datasets. J. Bionic Eng. 2013, 10, 231–241. [Google Scholar] [CrossRef]
- Cai, R.; Hao, Z.; Yang, X.; Wen, W. An efficient gene selection algorithm based on mutual information. Neurocomputing 2009, 72, 991–999. [Google Scholar] [CrossRef]
- Basto, V.; Yevseyeva, I.; Méndez, J.R.; Zhao, J. A spam filtering multi-objective optimization study covering parsimony maximization and three-way classification. Appl. Soft Comput. J. 2017, 48, 111–123. [Google Scholar] [CrossRef][Green Version]
- Choi, D.; Ko, B.; Kim, H.; Kim, P. Journal of Network and Computer Applications Text analysis for detecting terrorism-related articles on the web. J. Netw. Comput. Appl. 2014, 38, 16–21. [Google Scholar] [CrossRef]
- den Hartog, D.N.; Kobayashi, V.; Bekers, H.; Kismihók, G. Text Classification for Organizational Researchers: A Tutorial. Organ. Res. Methods 2017, 21, 1–34. [Google Scholar]
- Xia, R.; Xu, F.; Yu, J.; Qi, Y.; Cambria, E. Polarity shift detection, elimination and ensemble: A three-stage model for document-level sentiment analysis. Inf. Process. Manag. 2016, 52, 36–45. [Google Scholar] [CrossRef]
- García-Pablos, A.; Cuadros, M.; Rigau, G. W2VLDA: Almost unsupervised system for Aspect Based Sentiment Analysis. Expert Syst. Appl. 2018, 91, 127–137. [Google Scholar] [CrossRef]
- Bandhakavi, A.; Wiratunga, N.; Padmanabhan, D.; Massie, S. Lexicon based feature extraction for emotion text classification. Pattern Recognit. Lett. 2017, 93, 133–142. [Google Scholar] [CrossRef]
- Mera-Gaona, M.; Vargas-Cañas, R.; Lopez, D.M. Towards a Selection Mechanism of Relevant Features for Automatic Epileptic Seizures Detection. Stud. Health Technol. Inform. 2016, 228, 722–726. [Google Scholar]
- Bolón-canedo, V.; Alonso-betanzos, N.S.A. Feature selection for high-dimensional data. Prog. Artif. Intell. 2016, 5, 65–75. [Google Scholar] [CrossRef]
- Dheeru, D.; Taniskidou, E.K. UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2017. [Google Scholar]
- Chang, C.; Lin, C. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–39. [Google Scholar] [CrossRef]
- Bay, S.D. Combining Nearest Neighbor Classifiers Through Multiple Feature Subsets. In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; pp. 37–45. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.114.4233&rep=rep1&type=pdf (accessed on 17 August 2021).
- Zheng, Z.; Webb, G.I.; Ting, K.M. Integrating boosting and stochastic attribute selection committees for further improving the performance of decision tree learning. In Proceedings of the Tenth IEEE International Conference on Tools with Artificial Intelligence (Cat. No.98CH36294), Taipei, Taiwan, 10–12 November 1998; pp. 321–332. Available online: https://ieeexplore.ieee.org/document/744846 (accessed on 17 August 2021). [CrossRef]
- Opitz, D.W. Feature Selection for Ensembles. In National Conference on Artifi.cial Intelligence; Springer: Berlin/Heidelberg, Germany, 1999; pp. 379–384. Available online: https://www.aaai.org/Papers/AAAI/1999/AAAI99-055.pdf (accessed on 17 August 2021).
- Piao, Y.; Piao, M.; Park, K.; Ryu, K.H. An ensemble correlation-based gene selection algorithm for cancer classification with gene expression data. Bioinformatics 2012, 28, 3306–3315. [Google Scholar] [CrossRef]
- Mohammad, L.; Tajudin, A.; Al-betar, M.A.; Ahmad, O. Text feature selection with a robust weight scheme and dynamic dimension reduction to text document clustering. Expert Syst. Appl. 2017, 84, 24–36. Available online: https://ur.booksc.eu/book/67787096/455350 (accessed on 17 August 2021).
- Neuman, U.; Genze, N.; Heider, D. EFS: An ensemble feature selection tool implemented as R-package and web-application. BioData Min. 2017, 1–9. Available online: https://biodatamining.biomedcentral.com/articles/10.1186/s13040-017-0142-8 (accessed on 17 August 2021).
- Koehrsen, W. A Feature Selection Tool for Machine Learning in Python, Towards Data Science. 2018. Available online: https://towardsdatascience.com/a-feature-selection-tool-for-machine-learning-in-python-b64dd23710f0 (accessed on 7 November 2018).
- Jabareen, Y. Building a Conceptual Framework: Philosophy, Definitions, and Procedure. Int. J. Qual. Methods 2009, 8, 49–62. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; Wiley-Interscience: Hoboken, NJ, USA, 2004; Available online: https://www.springer.com/gp/book/9780792381983 (accessed on 17 August 2021).
- Yu, L.; Liu, H. Efficient Feature Selection via Analysis of Relevance and Redundancy. J. Mach. Learn. Res. 2004, 5, 1205–1224. [Google Scholar]
- Seijo-Pardo, B.; Porto-Díaz, I.; Bolón-Canedo, V.; Alonso-Betanzos, A. Ensemble feature selection: Homogeneous and heterogeneous approaches. Knowl.-Based Syst. 2017, 118, 124–139. [Google Scholar] [CrossRef]
- IBM. Manual CRISP-DM de IBM SPSS Modeler; IBM Corp.: Armonk, NY, USA, 2012; p. 56. Available online: https://www.ibm.com/docs/es/spss-modeler/SaaS?topic=guide-introduction-crisp-dm (accessed on 17 August 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mera-Gaona, M.; Neumann, U.; Vargas-Canas, R.; López, D.M. Evaluating the impact of multivariate imputation by MICE in feature selection. PLoS ONE 2021, 16, e0254720. [Google Scholar] [CrossRef] [PubMed]
- Scikit-Learn. Documentation—Scikit-Learn. 2021. Available online: https://scikit-learn.org/stable/modules/outlier_detection.html (accessed on 16 August 2021).
- Mera-Gaona, M.; López, D.M.; Vargas-Canas, R. An Ensemble Feature Selection Approach to Identify Relevant Features from EEG Signals. Appl. Sci. 2021, 11, 6983. [Google Scholar] [CrossRef]
- Neumann, U.; Riemenschneider, M.; Sowa, J.-P.; Baars, T.; Kälsch, J.; Canbay, A.; Heider, D. Compensation of feature selection biases accompanied with improved predictive performance for binary classification by using a novel ensemble feature selection approach. BioData Min. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Kalousis, A.; Prados, J.; Hilario, M. Stability of feature selection algorithms: A study on high-dimensional spaces. Knowl. Inf. Syst. 2007, 12, 95–116. [Google Scholar] [CrossRef]
- Lachner-Piza, D.; Epitashvili, N.; Schulze-Bonhage, A.; Stieglitz, T.; Jacobs, J.; Dümpelmann, M. A single channel sleep-spindle detector based on multivariate classification of EEG epochs: MUSSDET. J. Neurosci. Methods 2018, 297, 31–43. [Google Scholar] [CrossRef]
- Su, J.; Yi, D.; Liu, C.; Guo, L.; Chen, W.-H. Dimension Reduction Aided Hyperspectral Image Classification with a Small-sized Training Dataset: Experimental Comparisons. Sensors 2017, 17, 2726. [Google Scholar] [CrossRef] [PubMed]
- Khair, N.M.; Hariharan, M.; Yaacob, S.; Basah, S.N. Locality sensitivity discriminant analysis-based feature ranking of human emotion actions recognition. J. Phys. Ther. Sci. 2015, 27, 2649–2653. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Garbarine, E.; DePasquale, J.; Gadia, V.; Polikar, R.; Rosen, G. Information-theoretic approaches to SVM feature selection for metagenome read classification. Comput. Biol. Chem. 2011, 35, 199–209. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sonar | SPECTF | WDBC | |
|---|---|---|---|
| SelectKBest | 5 | 5 | 4 |
| RFE | 3 | 3 | 3 |
| Feature Importance | 5 | 5 | 4 |
| EFS | 10 | 10 | 10 |
| Features | Features Selected by F-EFS | Features Selected in [39] | % of Elimination of Features by F-EFS | % of Elimination of Features by [39] | |
|---|---|---|---|---|---|
| Sonar | 60 | 10 | 24 | 83.30% | 40% |
| SPECTF | 44 | 10 | 19 | 56.70% | 43.20% |
| WDBC | 30 | 10 | 10 | 66.70% | 66.70% |
| Sonar | SPECTF | WDBC | |
|---|---|---|---|
| SelectKBest | 84.05% | 53.22% | 90.35% |
| RFE | 85.50% | 53.22% | 93.65% |
| Feature Importance | 84.05% | 59.67% | 92.10% |
| F-EFS | 86.95% | 60.75% | 93.85% |
| Sonar | SPECTF | WDBC | |
|---|---|---|---|
| SelectKBest | 73.91% | 63.44% | 89.47% |
| RFE | 65.21% | 68.81% | 87.71% |
| Feature Importance | 78.26% | 72.58% | 89.47% |
| F-EFS | 73.91% | 74.73% | 92.10% |
| Features | Stability | |
|---|---|---|
| Sonar | F9, F10, F11, F12, F21, F35, F36, F45, F46, F49 | 1 |
| SPECTF | F4, F25, F26, F28, F30, F36, F40, F42, F43, F44 | 1 |
| WDBC | F3, F4, F7, F8, F14, F21, F23, F24, F27, F28 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mera-Gaona, M.; López, D.M.; Vargas-Canas, R.; Neumann, U. Framework for the Ensemble of Feature Selection Methods. Appl. Sci. 2021, 11, 8122. https://doi.org/10.3390/app11178122
Mera-Gaona M, López DM, Vargas-Canas R, Neumann U. Framework for the Ensemble of Feature Selection Methods. Applied Sciences. 2021; 11(17):8122. https://doi.org/10.3390/app11178122
Chicago/Turabian StyleMera-Gaona, Maritza, Diego M. López, Rubiel Vargas-Canas, and Ursula Neumann. 2021. "Framework for the Ensemble of Feature Selection Methods" Applied Sciences 11, no. 17: 8122. https://doi.org/10.3390/app11178122
APA StyleMera-Gaona, M., López, D. M., Vargas-Canas, R., & Neumann, U. (2021). Framework for the Ensemble of Feature Selection Methods. Applied Sciences, 11(17), 8122. https://doi.org/10.3390/app11178122