
Development of Knowledge Base Using Human Experience Semantic Network for Instructive Texts




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The development of an adaptive, dynamic and deterministic knowledge structure with qualitative and quantitative attributes, called the human experience semantic network (HESN), is used to capture and structure knowledge from iTexts in the form of nodes and edges;
- The development of a knowledge base, consisting of HESN and domain knowledge, for retaining properties, values, and relationships of different terms or key phrases, found in iTexts. These terms or key phrases could be an entity, action term or verb, attribute, or attribute value. The knowledge is structured for different entities, action terms, attribute, or attribute values based on different operations.
2. Related Work
2.1. Knowledge-Based and Ontology-Based Approaches
2.2. Entity-Relation Extraction
2.3. Limitations in Case of iText
3. Research Methodology
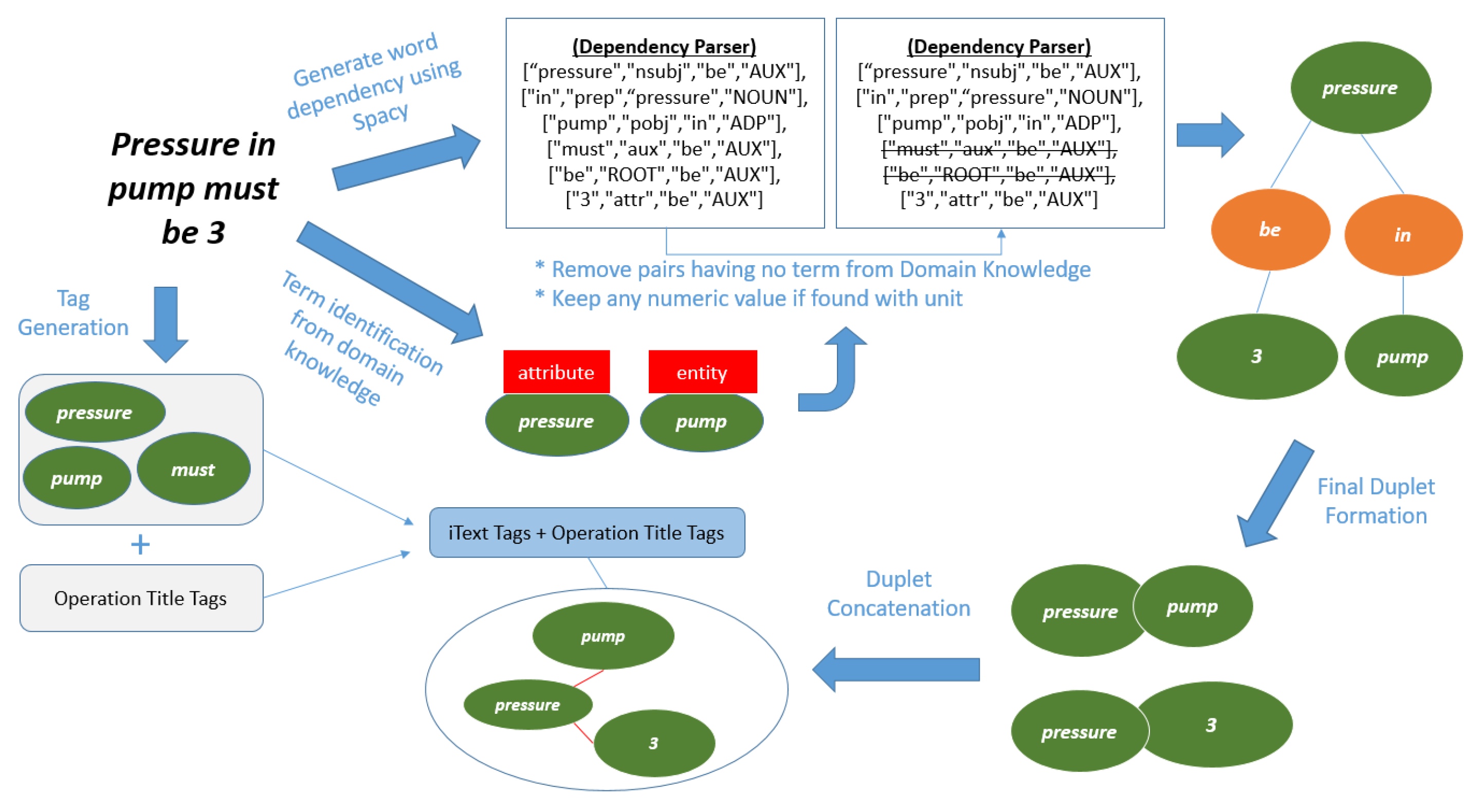
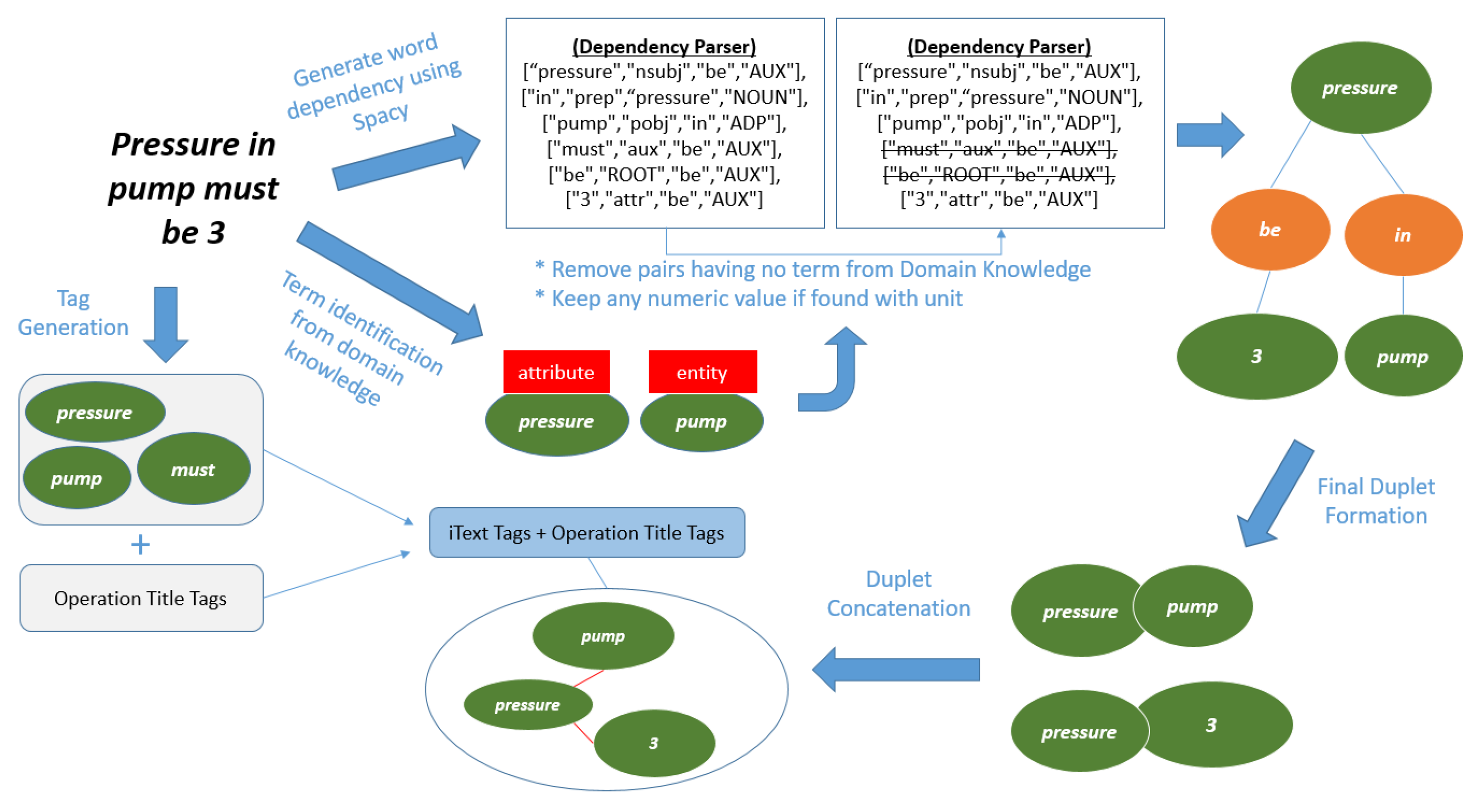
3.1. iTexts Extraction and Preprocessing
3.2. Domain Knowledge Development
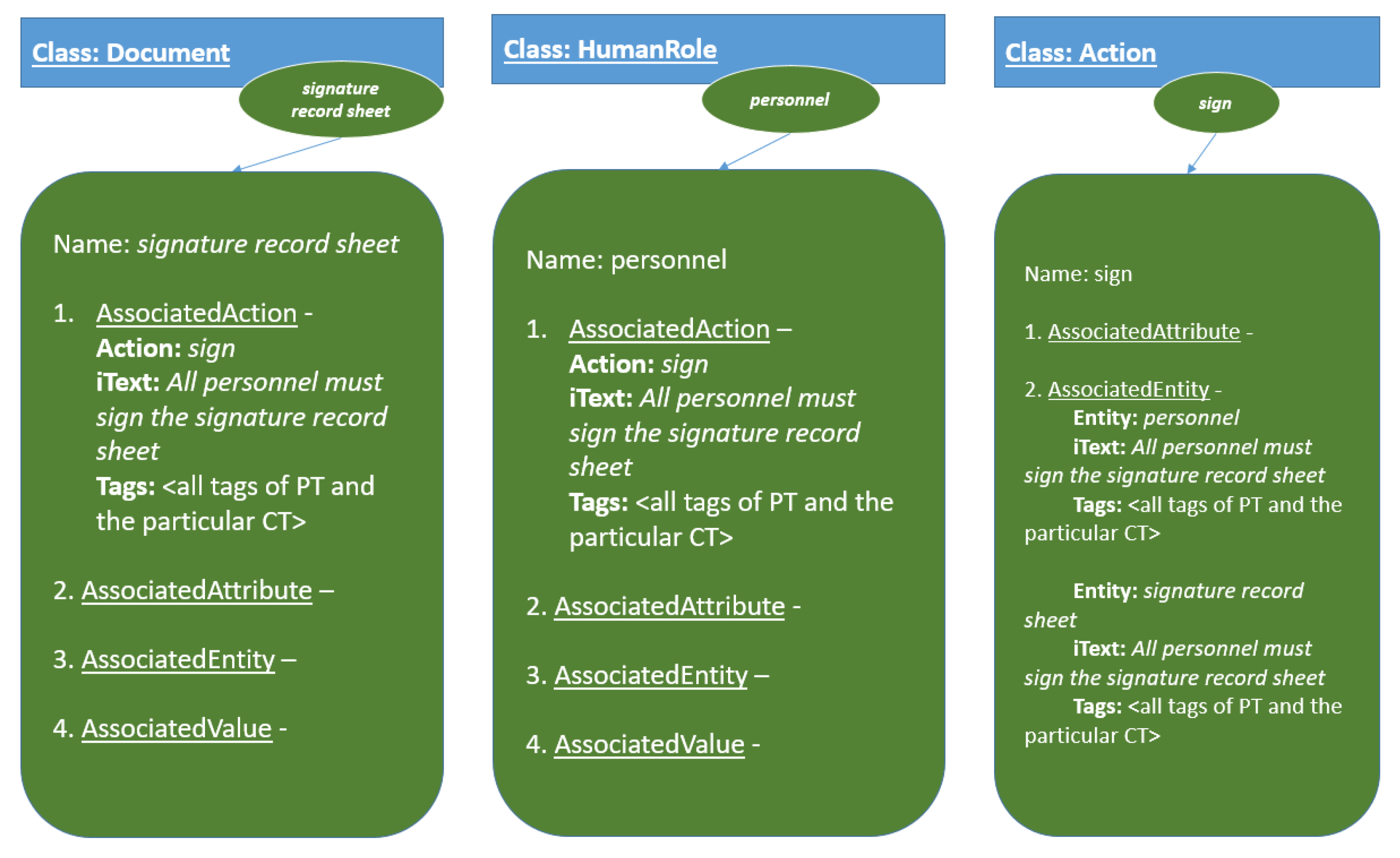
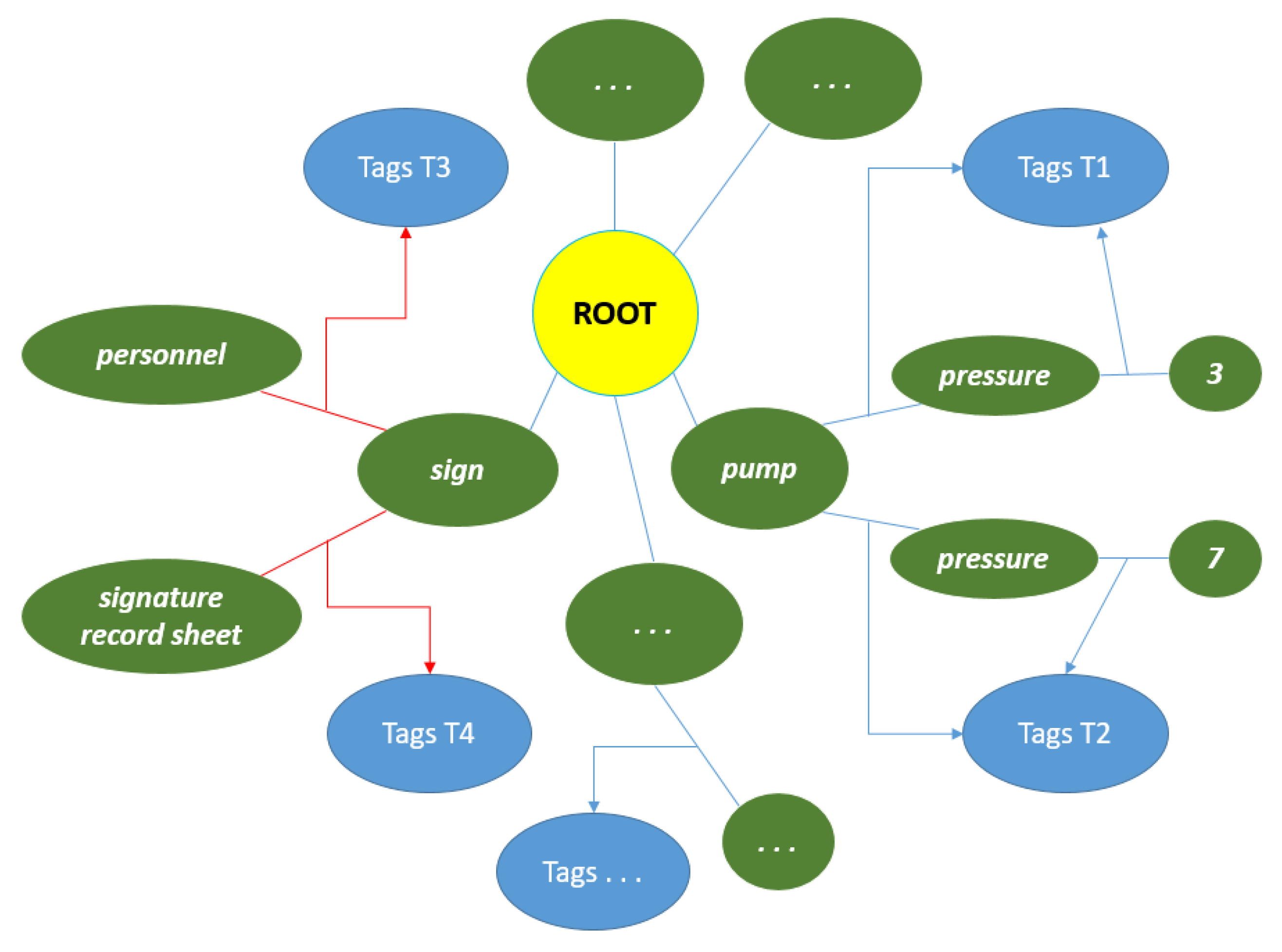
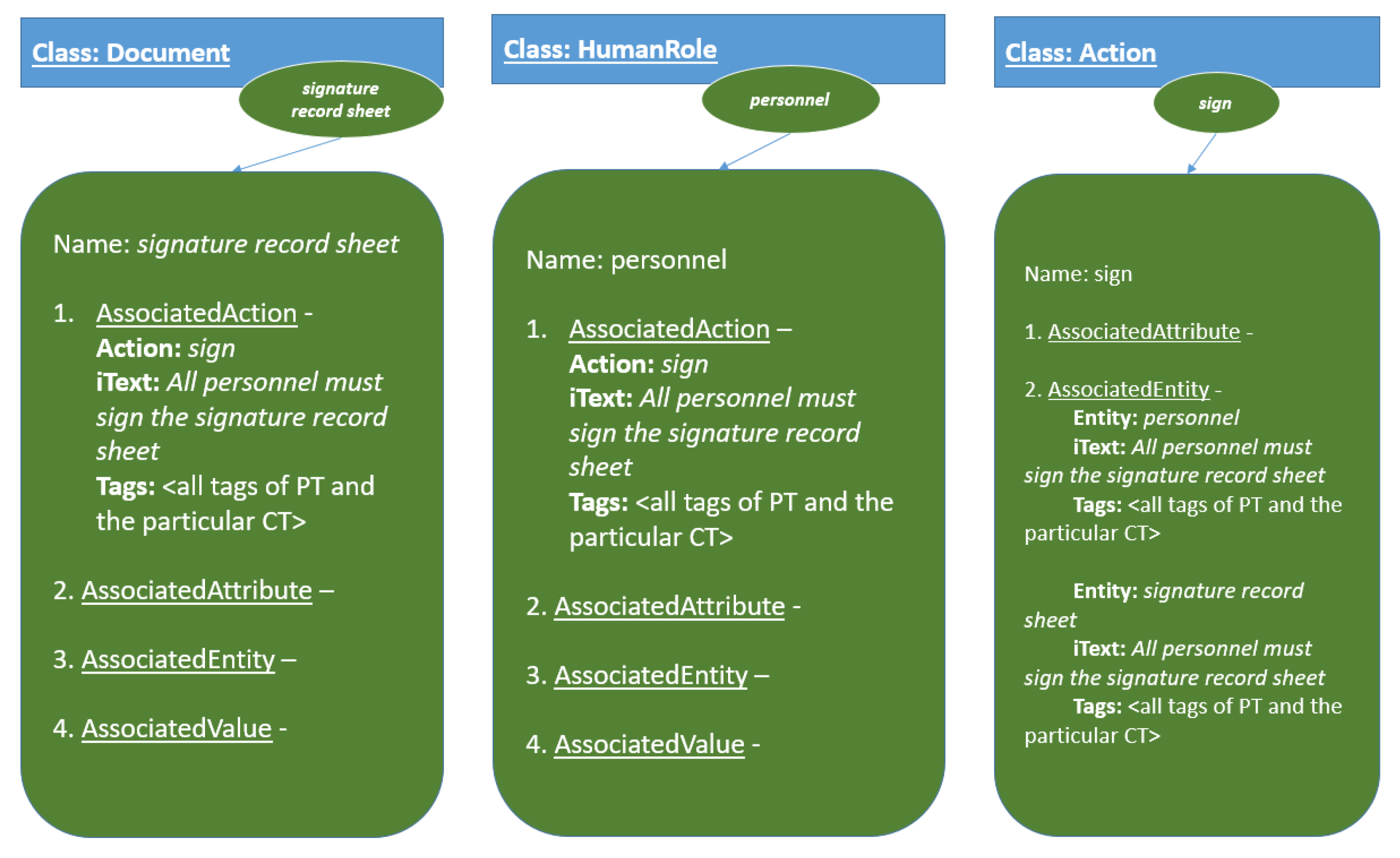
3.3. Human Experience Semantic Network (HESN)
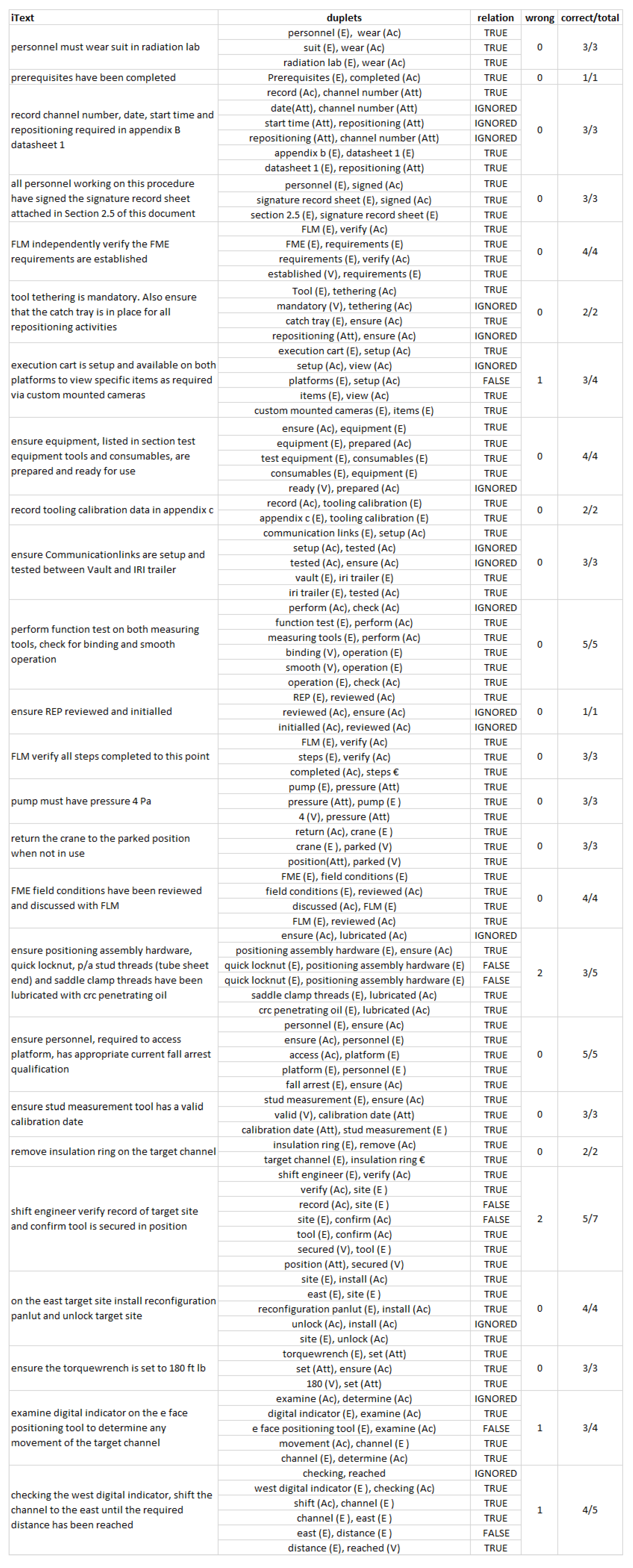
3.4. Entity, Action, Attribute and Value Recognition and Linking
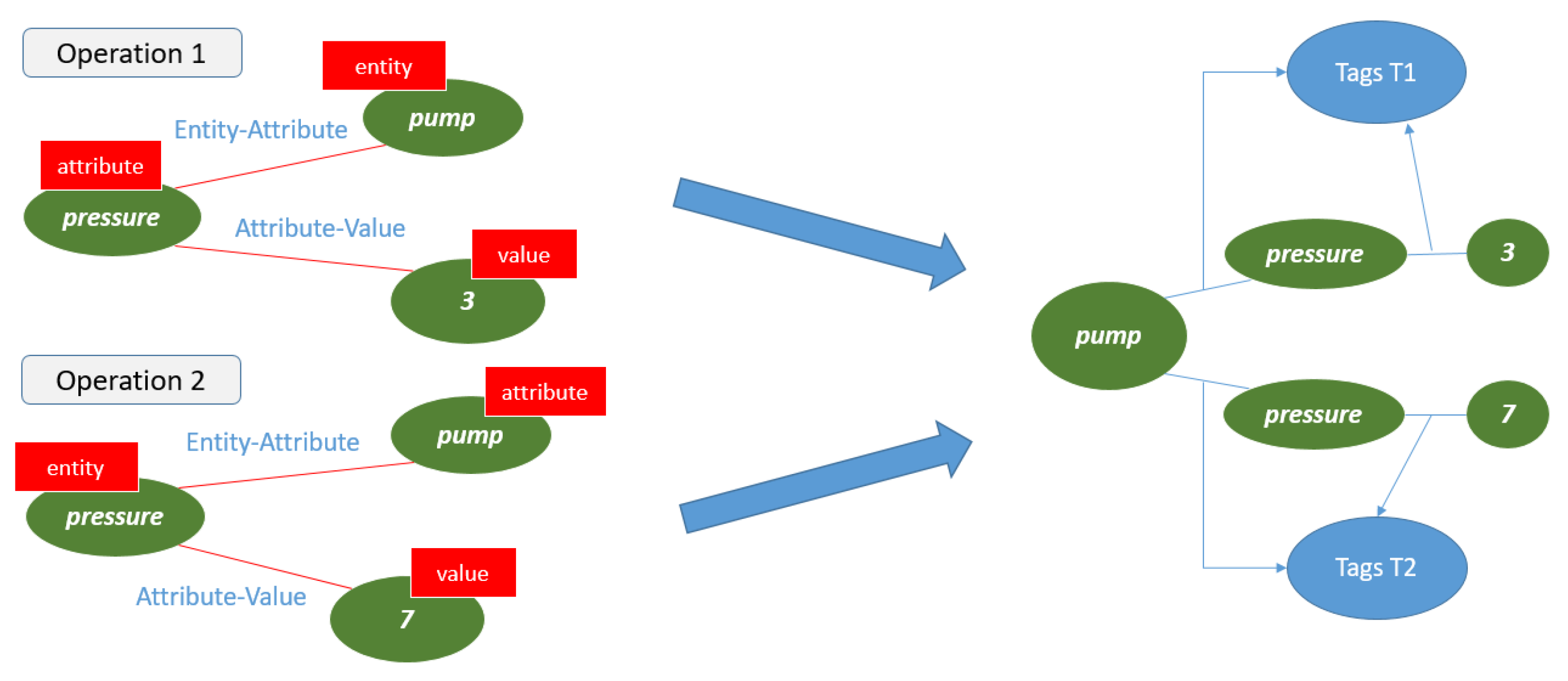
3.5. Tag Generation and Relation Tracking
3.6. Update HESN
4. Advantage of the Proposed Knowledge Base
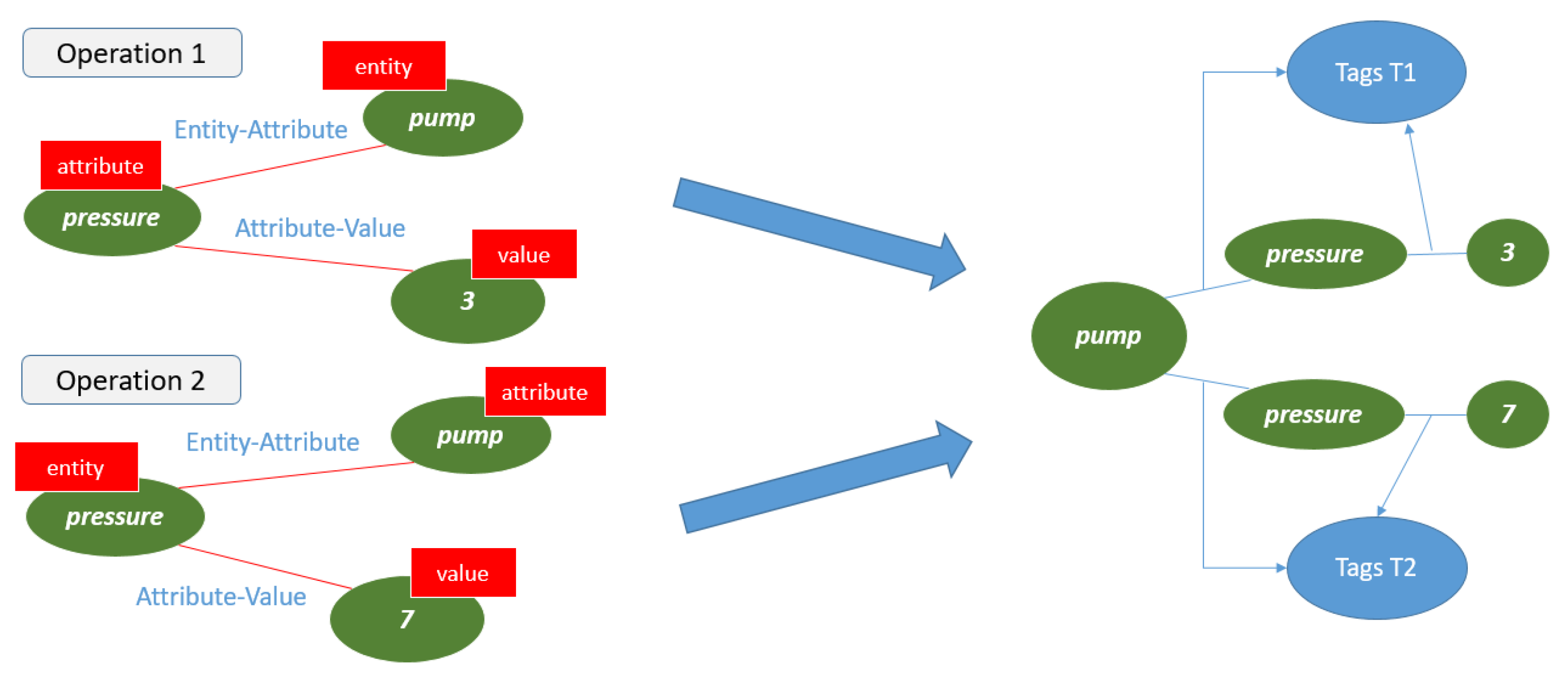
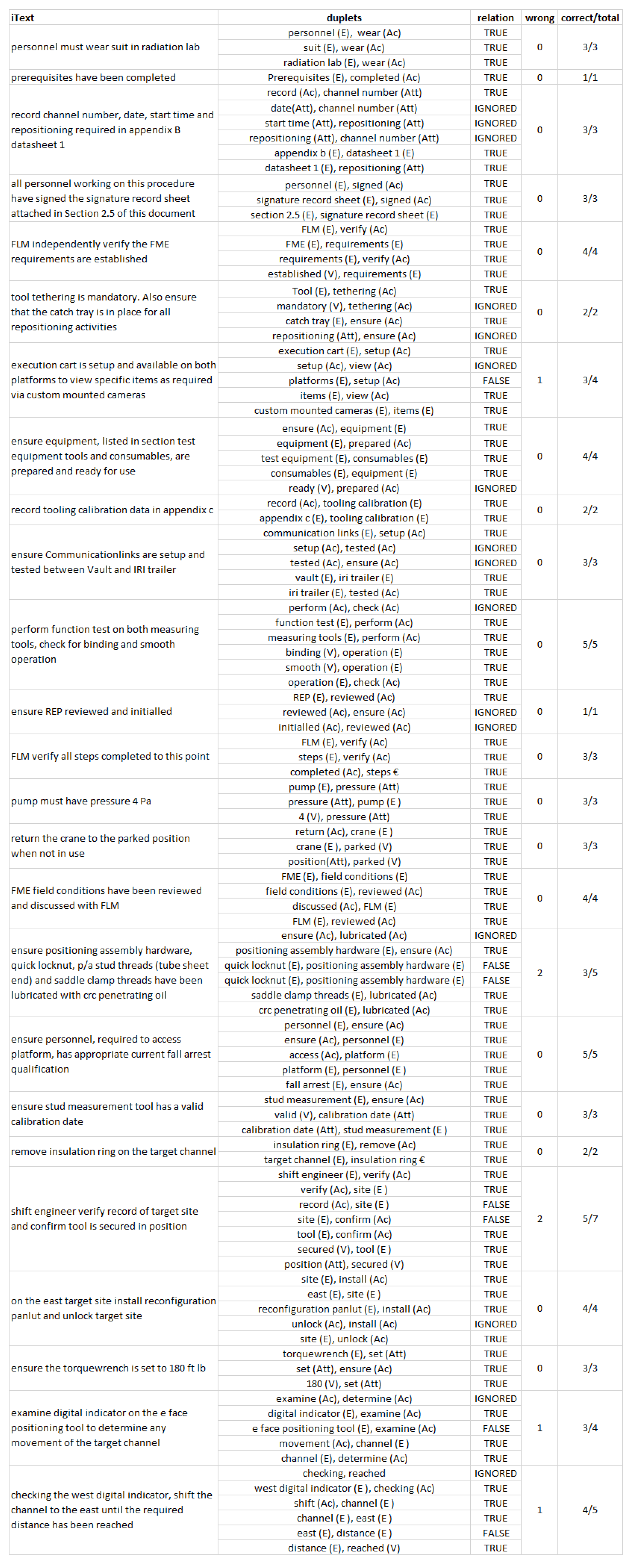
4.1. Query Evaluation
- What should be the pressure of pump for Operation 1?
- What should be the pressure of pump for Operation 2?
4.2. Relation Extraction
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Smidts, C. A method for systematically developing the knowledge base of reactor operators in nuclear power plants to support cognitive modeling of operator performance. Reliab. Eng. Syst. Saf. 2019, 186, 64–77. [Google Scholar] [CrossRef]
- Rodríguez-García, M.Á.; García-Sánchez, F.; Valencia-García, R. Knowledge-Based System for Crop Pests and Diseases Recognition. Electronics 2021, 10, 905. [Google Scholar] [CrossRef]
- Skobelev, P.; Simonova, E.; Smirnov, S.; Budaev, D.; Voshchuk, G.; Morokov, A. Development of a Knowledge Base in the “Smart Farming” System for Agricultural Enterprise Management. Procedia Comput. Sci. 2019, 150, 154–161. [Google Scholar] [CrossRef]
- Ritou, M.; Belkadi, F.; Yahouni, Z.; Cunha, C.D.; Laroche, F.; Furet, B. Knowledge-based multi-level aggregation for decision aid in the machining industry. CIRP Ann. 2019, 68, 475–478. [Google Scholar] [CrossRef]
- Zhong, W.; Li, C.; Peng, X.; Wan, F.; An, X.; Tian, Z. A Knowledge Base System for Operation Optimization: Design and Implementation Practice for the Polyethylene Process. Engineering 2019, 5, 1041–1048. [Google Scholar] [CrossRef]
- Li, T.; Chen, Z. An ontology-based learning approach for automatically classifying security requirements. J. Syst. Softw. 2020, 165, 110566. [Google Scholar] [CrossRef]
- Wu, C.; Wu, P.; Wang, J.; Jiang, R.; Chen, M.; Wang, X. Ontological knowledge base for concrete bridge rehabilitation project management. Autom. Constr. 2021, 121, 103428. [Google Scholar] [CrossRef]
- Sanfilippo, E.M.; Belkadi, F.; Bernard, A. Ontology-based knowledge representation for additive manufacturing. Comput. Ind. 2019, 109, 182–194. [Google Scholar] [CrossRef]
- Wątróbski, J. Ontology learning methods from text—An extensive knowledge-based approach. Procedia Comput. Sci. 2020, 176, 3356–3368. [Google Scholar] [CrossRef]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. Int. J. Linguist. Lang. Resour. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Bach, N.; Badaskar, S. A Review of Relation Extraction. Lit. Rev. Lang. Stat. II 2007, 2, 1–15. [Google Scholar]
- Martinez-Rodriguez, J.L.; Lopez-Arevalo, I.; Rios-Alvarado, A.B. OpenIE-based approach for Knowledge Graph construction from text. Expert Syst. Appl. 2018, 113, 339–355. [Google Scholar] [CrossRef]
- Kim, T.; Yun, Y.; Kim, N. Deep Learning-Based Knowledge Graph Generation for COVID-19. Sustainability 2021, 13, 2276. [Google Scholar] [CrossRef]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Xu, S.; Zhu, L. Semantic relation extraction aware of N-gram features from unstructured biomedical text. J. Biomed. Inform. 2018, 86, 59–70. [Google Scholar] [CrossRef] [PubMed]
- Nie, B.; Sun, S. Knowledge graph embedding via reasoning over entities, relations, and text. Future Gener. Comput. Syst. 2019, 91, 426–433. [Google Scholar] [CrossRef]
- Xu, B.; Zhuge, H. The influence of semantic link network on the ability of question-answering system. Future Gener. Comput. Syst. 2020, 108, 1–14. [Google Scholar] [CrossRef]
- Guo, A.; Tan, Z.; Zhao, X. Measuring Triplet Trustworthiness in Knowledge Graphs via Expanded Relation Detection. In Knowledge Science, Engineering and Management; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 65–76. [Google Scholar] [CrossRef]
- Xiao, S.; Song, M. A Text-Generated Method to Joint Extraction of Entities and Relations. Appl. Sci. 2019, 9, 3795. [Google Scholar] [CrossRef] [Green Version]
- Spacy.io. Industrial-Strength Natural Language Processing in Python. Available online: https://spacy.io/ (accessed on 18 April 2021).



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabbar, H.A.; Jabar, S.S.A.; Hassan, H.A.; Ren, J. Development of Knowledge Base Using Human Experience Semantic Network for Instructive Texts. Appl. Sci. 2021, 11, 8072. https://doi.org/10.3390/app11178072
Gabbar HA, Jabar SSA, Hassan HA, Ren J. Development of Knowledge Base Using Human Experience Semantic Network for Instructive Texts. Applied Sciences. 2021; 11(17):8072. https://doi.org/10.3390/app11178072
Chicago/Turabian StyleGabbar, Hossam A., Sk Sami Al Jabar, Hassan A. Hassan, and Jing Ren. 2021. "Development of Knowledge Base Using Human Experience Semantic Network for Instructive Texts" Applied Sciences 11, no. 17: 8072. https://doi.org/10.3390/app11178072
APA StyleGabbar, H. A., Jabar, S. S. A., Hassan, H. A., & Ren, J. (2021). Development of Knowledge Base Using Human Experience Semantic Network for Instructive Texts. Applied Sciences, 11(17), 8072. https://doi.org/10.3390/app11178072