
Traffic Light and Arrow Signal Recognition Based on a Unified Network


Abstract
:1. Introduction
2. Related Works
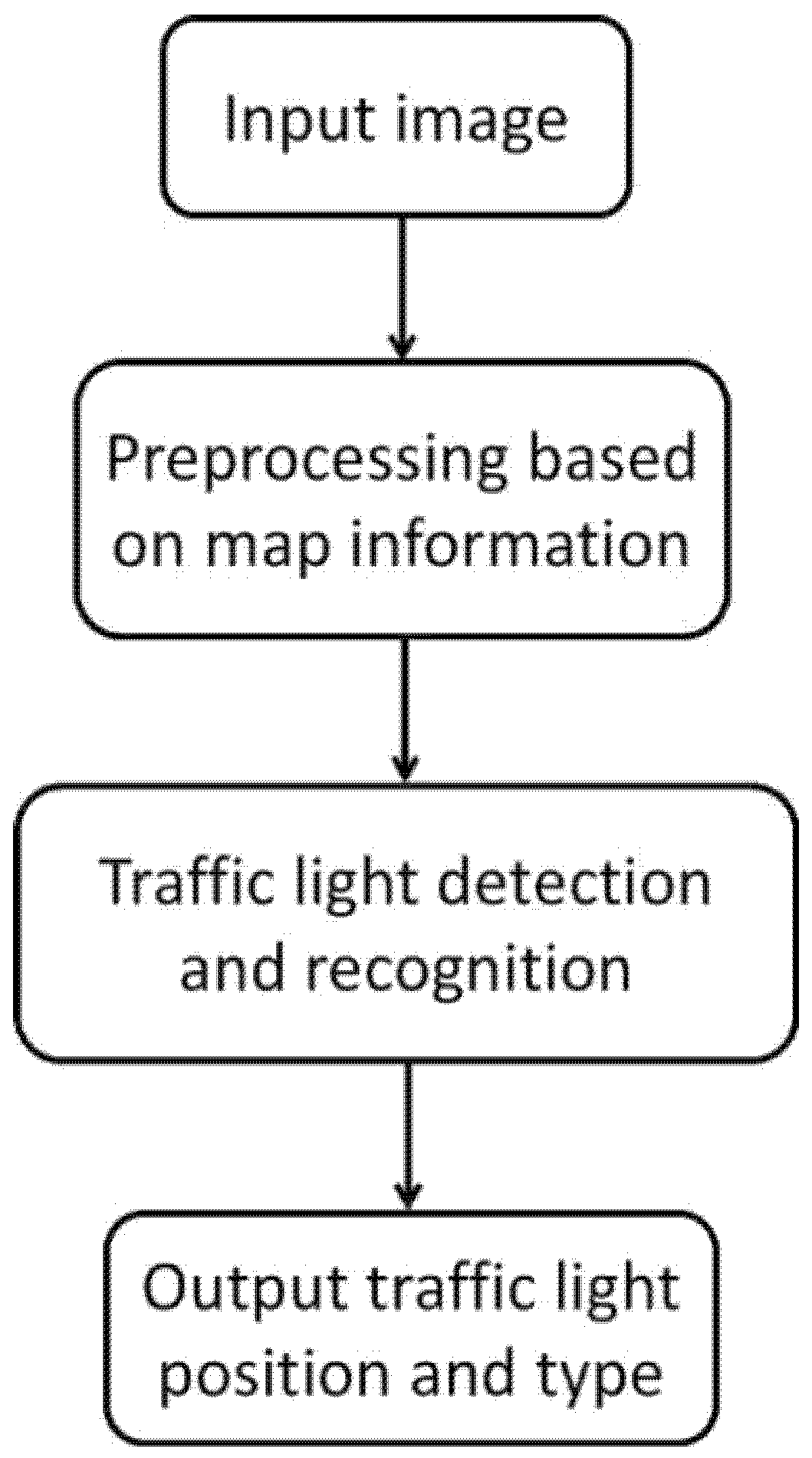
3. Approach
3.1. Preprocessing Based on Map Information
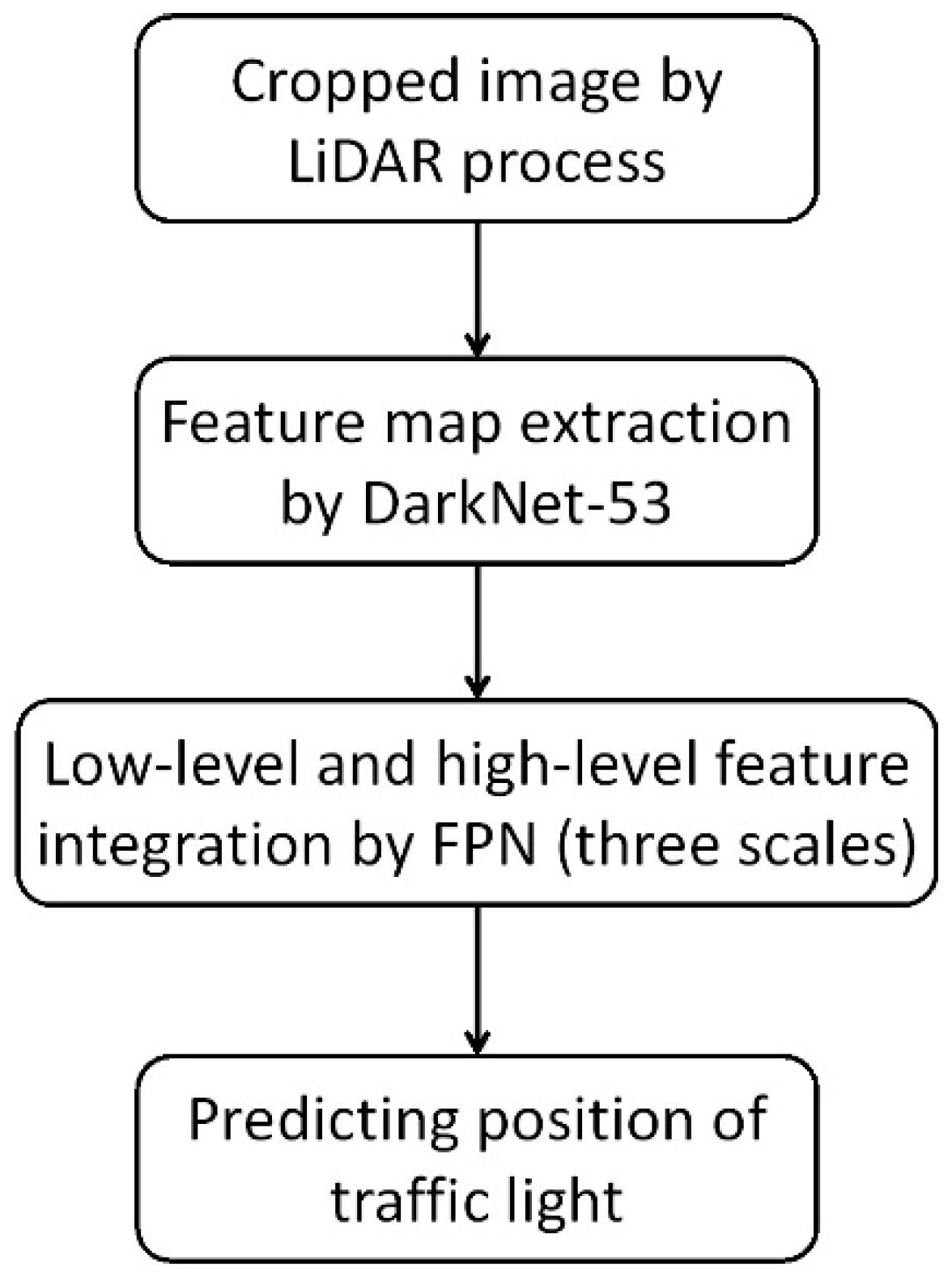
3.2. Traffic Light Detection and Recognition
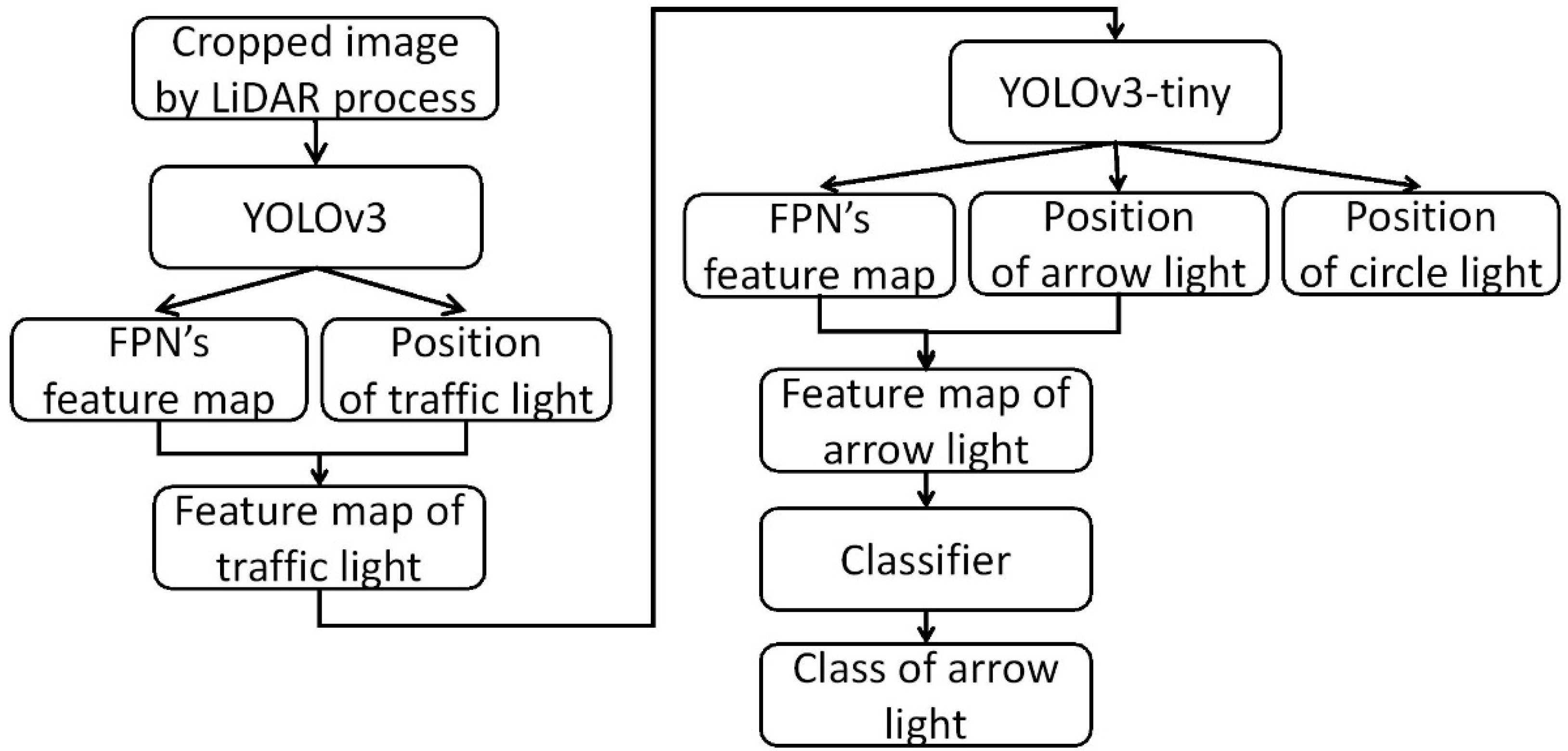
3.3. Unified Network
4. Results
4.1. Dataset
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abboud, K.; Omar, H.A.; Zhuang, W. Interworking of dsrc and cellular network technologies for v2x communications: A survey. IEEE Trans. Veh. Technol. 2016, 65, 9457–9470. [Google Scholar] [CrossRef]
- Jensen, M.B.; Philipsen, M.P.; Møgelmose, A.; Moeslund, T.B.; Trivedi, M.M. Vision for looking at traffic lights: Issues, survey, and perspectives. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1800–1815. [Google Scholar] [CrossRef] [Green Version]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Ramanishka, V.; Chen, Y.T.; Misu, T.; Saenko, K. Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7699–7707. [Google Scholar]
- Waymo. Waymo Open Dataset: An Autonomous Driving Dataset. 2019. Available online: https://waymo.com/open/ (accessed on 7 October 2019).
- Weber, M.; Wolf, P.; Zöllner, J.M. Deeptlr: A single deep convolutional network for detection and classification of traffic lights. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 342–348. [Google Scholar]
- Yeh, T.W.; Lin, H.Y. Detection and recognition of arrow traffic signals using a two-stage neural network structure. In Proceedings of the the 6th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2020), Prague, Czech, 2–4 May 2020; pp. 322–330. [Google Scholar]
- Fregin, A.; Müller, J.M.; Dietmayer, K.C.J. Feature detectors for traffic light recognition. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 339–346. [Google Scholar]
- Kim, H.K.; Park, J.H.; Jung, H.Y. Effective traffic lights recognition method for real time driving assistance system in the daytime. Int. J. Electr. Comput. Eng. 2011, 5, 1429–1432. [Google Scholar]
- Fregin, A.; Müller, J.M.; Dietmayer, K.C.J. Three ways of using stereo vision for traffic light recognition. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 430–436. [Google Scholar]
- Müller, J.M.; Fregin, A.; Dietmayer, K.C.J. Multi-camera system for traffic light detection: About camera setup and mapping of detections. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 165–172. [Google Scholar]
- Weber, M.; Huber, M.; Zöllner, J.M. Hdtlr: A cnn based hierarchical detector for traffic lights. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 255–260. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Behrendt, K.; Novak, L.; Botros, R. A deep learning approach to traffic lights: Detection, tracking, and classification. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1370–1377. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Müller, J.M.; Dietmayer, K.C.J. Detecting traffic lights by single shot detection. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 266–273. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Bach, M.; Stumper, D.; Dietmayer, K.C.J. Deep convolutional traffic light recognition for automated driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 851–858. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fairfield, N.; Urmson, C. Traffic light mapping and detection. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 5421–5426. [Google Scholar]
- Hirabayashi, M.; Sujiwo, A.; Monrroy, A.; Kato, S.; Edahiro, M. Traffic light recognition using high-definition map features. Robot. Auton. Syst. 2019, 111, 62–72. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Ma, H.; Wang, X.; Zhang, X. Traffic light recognition for complex scene with fusion detections. IEEE Trans. Intell. Transp. Syst. 2018, 19, 199–208. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Stop | StopLeft | Go | GoLeft | Warning | WarningLeft | All |
|---|---|---|---|---|---|---|---|
| Color detector | - | - | - | - | - | - | 0.04 |
| Spot detector | - | - | - | - | - | - | 0.0004 |
| ACF detector | - | - | - | - | - | - | 0.36 |
| Faster R-CNN | 0.14 | 0.01 | 0.19 | 0.001 | - | - | 0.09 |
| SLD | 0.08 | - | 0.10 | - | - | - | 0.09 |
| Modified ACF detector | 0.63 | 0.13 | 0.40 | 0.37 | - | - | 0.38 |
| Multi-detector | 0.72 | 0.28 | 0.52 | 0.40 | - | - | 0.48 |
| Our approach | 0.70 | 0.40 | 0.88 | 0.71 | 0.52 | 0.24 | 0.66 |
| Method | YOLOv3 + AlexNet | YOLOv3 + YOLOv3-tiny + LeNet | Unified Network | Unified Network |
|---|---|---|---|---|
| Data augmentation | - | - | - | ✓ |
| mAP | 0.36 | 0.55 | 0.57 | 0.67 |
| Speed (ms) | 31 | 52 | 40 | 40 |
| Traffic Light Size | 0–5 | 5–10 | 10–15 | 15–20 | 20–25 | 25–30 | 30–35 | 35–40 | 40–45 | 45–50 | 50–55 | 55–60 | 60–65 | 65–70 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mAP | 0.33 | 0.48 | 0.82 | 0.80 | 0.76 | 0.75 | 0.69 | 0.74 | 0.77 | 0.63 | 0.69 | 0.69 | 0.55 | 0.62 |
| Distance | 0–15 | 15–30 | 30–45 | 45–60 | 60–75 | 75–90 | 90–100 | |||||||
| Traffic light size (3.5 mm) | 62 | 20 | 15 | 9 | 7 | 6 | 5 | |||||||
| Traffic light size (12 mm) | - | 43 | 39 | 29 | 21 | 15 | 15 | |||||||
| Distance | 0–15 | 15–30 | 30–45 | 45–60 | 60–75 | 75–90 | 90–100 | |||||||
| mAP (3.5 mm) | 0.38 | 0.62 | 0.57 | 0.47 | 0.46 | 0.37 | 0.32 | |||||||
| mAP (12 mm) | - | 0.79 | 0.68 | 0.69 | 0.70 | 0.63 | 0.51 | |||||||
| Detection | State | Type | ||||||
|---|---|---|---|---|---|---|---|---|
| Class | Traffic Light | Red | Yellow | Green | Arrow | Left | Straight | Right |
| mAP | 0.97 | 0.93 | 0.90 | 0.64 | 0.91 | 0.87 | 0.98 | 0.97 |
| Class | Close | Red | Yellow | Green | Left | Straight | Right |
|---|---|---|---|---|---|---|---|
| mAP | 0.43 | 0.78 | 0.79 | 0.76 | No data | 0.55 | No data |
| Class | Red Left | Red Right | Straight Left | Straight Right | Left Right | Red Left Right | Straight Left Right |
| mAP | 0.55 | 0.45 | 0.64 | 0.87 | 0.84 | No data | 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, T.-W.; Lin, H.-Y.; Chang, C.-C. Traffic Light and Arrow Signal Recognition Based on a Unified Network. Appl. Sci. 2021, 11, 8066. https://doi.org/10.3390/app11178066
Yeh T-W, Lin H-Y, Chang C-C. Traffic Light and Arrow Signal Recognition Based on a Unified Network. Applied Sciences. 2021; 11(17):8066. https://doi.org/10.3390/app11178066
Chicago/Turabian StyleYeh, Tien-Wen, Huei-Yung Lin, and Chin-Chen Chang. 2021. "Traffic Light and Arrow Signal Recognition Based on a Unified Network" Applied Sciences 11, no. 17: 8066. https://doi.org/10.3390/app11178066
APA StyleYeh, T.-W., Lin, H.-Y., & Chang, C.-C. (2021). Traffic Light and Arrow Signal Recognition Based on a Unified Network. Applied Sciences, 11(17), 8066. https://doi.org/10.3390/app11178066