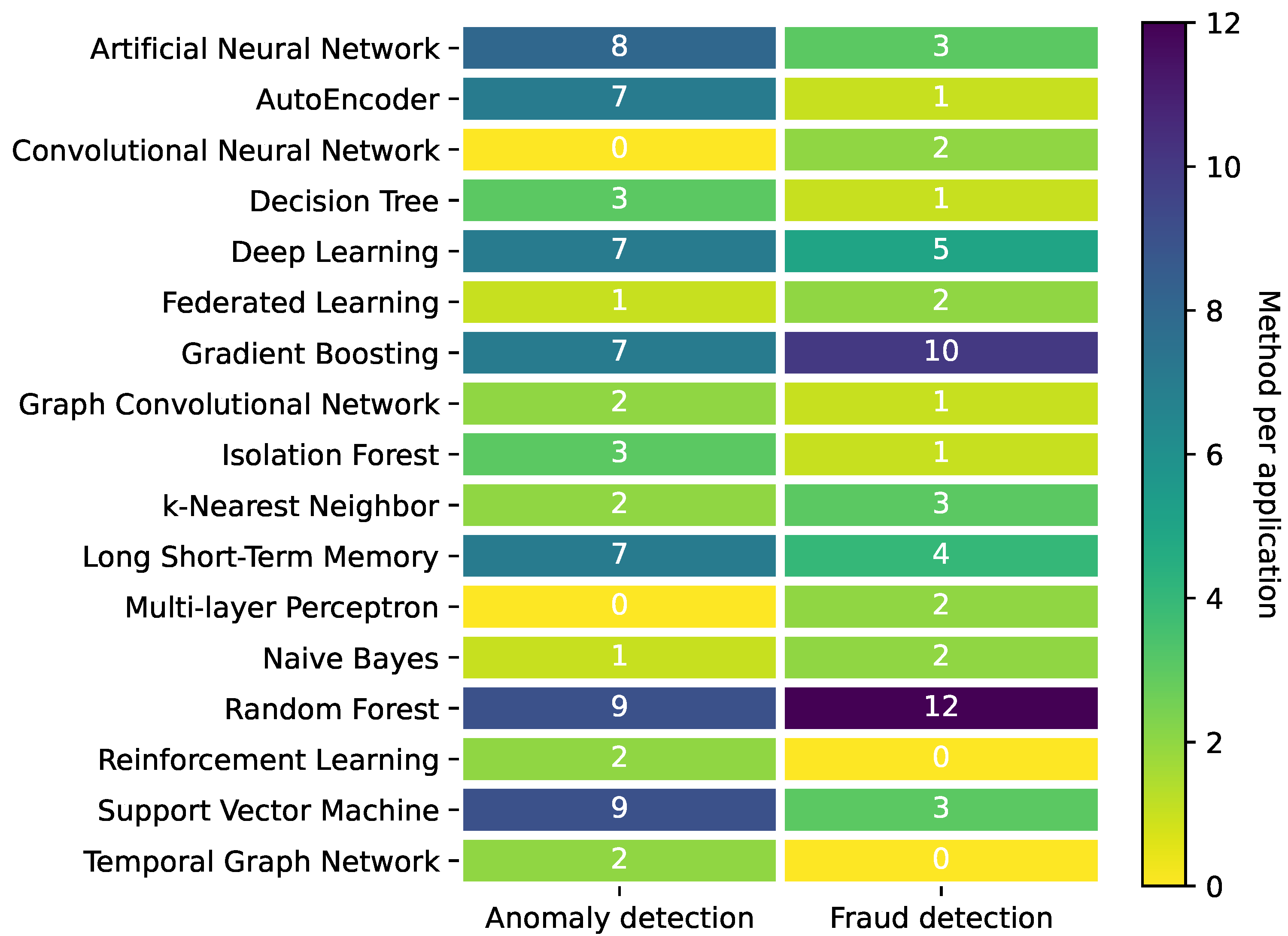
5.2.1. Financial Fraud Detection
KaRuNa is a blockchain-based framework for fraud cryptocurrency schemes created by Sureshbhai et al. [
108]. Their model was based on the LSTM classifier. They used the Elliptic data set to evaluate the performance. This data set was enhanced by adding a classification score for the reduced raw cryptocurrency data obtained from social media, newsapi, and other web sources. The results are visualised with graphs depicting the analysis of tweets and a fraud scheme classification confusion matrix. The precision, recall, and F-score were also provided.
A multilayer perceptron architecture to detect cryptocurrency deception was presented by Dalal and Abulaish [
109]. The data set for their evaluation was collected from the CMC website and labelled either legitimate or deceptive. The evaluation was conducted using Linear Regression, Softmax Regression, SVM, and MLP. The accuracy, precision, TPR, FNR, TNR, and FPR were presented, and it is observed that MLP performed the best.
An improved graph classification algorithm (Graph2Vec) for phishing detection on the Ethereum blockchain was proposed by Yuan et al. [
111]. To create a data set they gathered phishing addresses from etherscan.io and also added the same number of normal addresses. They gathered the transactions for every address, removed the redundant data, and also removed the addresses with less than 10 transactions and more 300 transactions. They presented the evaluation of their algorithm by calculating the precision, recall, and F1-score. They also compared the performance to several other methods, such as node2vec, WL-kernel, and Graph2Vec.
A phishing scam detection system for Ethereum blockchain was presented by Chen et al. [
112]. They used a graph convolutional network and autoencoder to detect phishing accounts. As a data set they used the Ethereum transaction history. They provided a performance comparison of their GCN method, Deep Walk, Node2Vec, and LINE. They showed the results of their AUC, recall, precision, and F1-score.
Zhou et al. [
114] proposed a financial fraud detection method using deep learning (a Convolutional Neural Network). They gathered the data from a large O2O supply chain management platform to create the data set, and calculated the precision, recall, and F1-score of the experimental evaluation. Additionally, they compared their proposition to SVM and a decision tree.
Zhou et al. [
116] proposed a financial fraud detection system by using Node2vec. To evaluate their proposal they used a data set provided from an Internet financial service provider in China. They compared Node2Vec, DeepWalk, and SVM, and presented their results by showing the calculated precision, recall, F1-score and F2-score.
Lou et al. [
115] created an improved Convolutional Neural Network to detect Ponzi contracts. They obtained the data for the data set from etherscan.io. They collected the contracts and converted the hexadecimal bytecodes to the corresponding decimal number. Additionally, they standardised the bycodes. They performed the evaluation on their algorithm and several others (Decision Tree, SVM, XGBoost, OCSVM, Isolation Forest, Random Forest), and presented their corresponding precision, recall, and F-scores.
A Ponzi scheme is not a novel fraud. It is an investment fraud where the scammer pays the old investment clients revenue by using the investments of new clients rather than through legitimate business actions. In a blockchain environment this is done by using smart contracts [
120]. Fan et al. [
117] proposed a Ponzi scheme detection method. To create a data set, they collected Ponzi and non-Ponzi scheme contracts from multiple websites. The contracts were converted from bytecode to opcode using the pyevmasm library and removed the operands. The opcodes were additionally converted to eigenvectors (using Bag Of Words - BOW) to conduct feature extraction utilising n-grams. BOW allows the definition of stop words, so that frequent operators can be removed from the opcode. They compared their method to multiple others by presenting the precision, recall, and F-score.
Machine learning was used by Chen et al. [
120] to detect Ponzi schemes on the Ethereum blockchain. To create a data set, they collected smart contract source code from etherscan.io. and checked whether they were Ponzi scheme contracts manually. The features were then extracted without the course code, all the related transactions were collected and unsuccessful transactions were removed. Next, the contracts were converted from bytecode to opcode, the features were classified, and feature extraction was performed. Multiple algorithms were evaluated and combined, and their performance was presented using precision, recall and F-scores.
Chen et al. [
118] used XGBoost to detect Ponzi schemes on the Ethereum blockchain. To test their system, they collected smart contracts from etherscan.io. The bytecodes were converted to opcodes and their frequency calculated. The contracts were labelled as Ponzi or non-Ponzi. The results were presented by calculating the precision, recall, and F-score.
Machine learning methods were used by Bartoletti et al. [
119] to detect Ponzi schemes on the bitcoin blockchain. To create a data set they collected bitcoin addresses related to Ponzi schemes and their respected transactions. They extracted features that could be useful to detect Ponzi schemes. Additionally, the data set was also filled with a number of addresses not connected to Ponzi schemes. To create an evaluation, they selected several machine learning classifiers: RIPPER, Bayes Network, and Random Forest. They calculated their accuracy, specificity, sensitivity, precision, F-measure, G-mean, and AUC. The results were visualised using confusion matrices.
Baek et al. [
125] proposed the detection of money laundering with Ethereum cryptocurrency transactions. To create a data set they collected wallets from etherscan.io and extracted the wallets with the largest trading volumes. For the minimisation of data, they chose the expectation maximisation algorithm, and the k-means algorithm for the clustering and weight defining. To present the results they calculated the accuracy, precision, F-measure, and True Negative Rate. A ROC curve and Precision Recall Curves were used for visualisation purposes.
A federated learning framework was used by Liu et al. [
126] to detect poisoning attacks. For the evaluation they used the MNIST and CIFAR-10 data sets. The performance of their model was presented by calculating accuracy for different numbers of participants, and the percentage of modified labels that indicate the strength of the poisoning attack.
Badawi et al. [
110] used machine learning classifiers to detect scams within a bitcoin blockchain. They searched for bitcoin generator scams with multiple search engines: Google, Bitcoin.fr, CuteStat.com, and the Internet Archive. They included multiple classifiers for evaluation purposes. The results were presented by calculating precision, recall, and the F1 score. It shows that SVC and MLP provided the best performance.
Bhowmik et al. [
127] presented a comparative study of machine learning algorithms used for fraud detection in blockchain networks. They used the node2vec algorithm to collect data for the data set. Features were then extracted from the collected data and stored in a CSV file. The CSV was then converted into a dictionary using the node2vec algorithm. A network edge list file was created and the embedding dimensionality reduced. Additionally, the features had to be normalised (the value 1 was assigned to fraudulent transactions, and 0 for the others), the mean and standard deviation were calculated. The results are shown by the achieved accuracy of each algorithm, and it was observed that logistic regression performed the best.
A security enhancement to financial transactions in the bitcoin blockchain was offered by Boughaci and Alkhawaldeh [
121] using machine learning. They used the Elliptic data set and the k-means clustering technique to partition unlabelled data. The measurements were made by using four machine learning algorithms: the Naive Bayes, Bayes Network, AdaBoost, and Random Forest. The precision, recall, TP rate, FP rate, PRC, and area under the ROC curve were calculated. The results showed that Random Forest had the best performance out of the selected algorithms.
Lee et al. [
122] used machine learning to detect illegal transactions on the bitcoin blockchain. They collected hash lists of legal and illegal transactions from multiple websites (such as Silk Road and Blockchain Explorer) to create their data set. The testing was conducted on the artificial neural network and random forest classifier. The F1-scores of these two methods show that random forest was a better fit for this type of detection.
Wen et al. [
113] proposed a framework used for the detection of phishing scams on the Ethereum blockchain. They collected data from Etherscan and added three filer rules to remove accounts with low activity levels, i.e., removing the smart contracts accounts, removing accounts with less than 5 transactions and transfer-in transactions with less than four, and removing accounts whose greatest balance was less than five. The testing was conducted on multiple Machine Learning models including SVM, KNN, and AdaBoost. For each model the precision, recall, F1-score and AUC were presented, and it was concluded that AdaBoost performed best.
A novel methodology for the detection of high yield investment programmes Bitcoin addresses was proposed by Toyoda et al. [
123]. The data were collected by searching for HYIP addresses and collecting their transactions. Feature extraction was then conducted, unneeded parts of the transaction were removed, the BTC was converted to USD, and the transactions were labelled as spent, received, or Coinbase. The evaluation was conducted on multiple algorithms (RF, XGBoost, Neural Network, SVM, k-NN) and the results were shown as TPR and FPR. The best result was provided by Random Forest.
Xu et al. [
124] used the Random Forest classifier to create a detector for eclipse attacks for the Ethereum blockchain. Eclipse attacks are used to isolate a certain user from a network by controlling their outgoing connections. In order to collect data for the data set, they collected the UDP packets from normal and unsolicited nodes. The data were then converted into a readable format using the Ethereum UDP packet dissector and added into the data set. They evaluated their proposition and presented the results for the Random Forest classifier in the form of its precision, recall, F-score, and support.
5.2.2. Cryptojacking, Malware, and Security
Abdulqadder et al. [
128] created an intrusion detection system to mitigate attacks in an SDN/NFV enabled cloud. Their method used a Recurrent Neural Network to detect flow features. They used a network simulator (Ns3) and compared their proposed model to the k-nearest neighbors algorithm by calculating the precision, recall, accuracy, detection rate, and processing time.
Liu et al. [
129] provided a classification and sharing method of malware that uses threat intelligence. Their method is based on the Broad Learning network. The Kaggle’s malware classification data set was used for evaluation. Data were preprocessed in order to convert the malware data from binary to hexadecimal, and then convert the hexadecimal values into a matrix to create a grey scale image. They compared the proposed algorithm to several other algorithms (k-nearest neighbor, Random Forest, and a Convolutional Neural Network) using accuracy and duration dependent on the image size.
A decentralized firewall that uses Deep Belief Neural Networks to detect malware was proposed by Raje et al. [
130]. The data set used for evaluation was a combination of the MALIMG data set (for malicious data) and vanilla windows installations (for the benign data). They presented the results by showing the accuracy and TPR.
Deep Recurrent Neural Networks (LSTM) were used by Yazdinejad et al. [
131] to detect cryptocurrency malware. Their data set is comprised of real-world cryptocurrency malware samples and benign samples. They extracted the scripts of each file and created samples of the original code. The operators, operands, and memory addresses were removed from the data set. They conducted the evaluation of different LSTM configurations and provided their accuracy, and comparison to other ML classifiers (SVM, Naive Bayes, Decision Tree, KNN, MLP, AdaBoost, Random Forest).
A deep learning model for the detection of malware on the Quorum chain was presented by Gao et al. [
133]. They compared their new model to other algorithms, such as Decision Tree, k-NN, Logistic Regression and SVM. The results were presented using their precision, recall, F1-score, and z-values.
Kumar et al. [
135] proposed a system for malware detection on Android IoT devices. They used a data set composed of both benign and malware applications. The data were collected from the Google Play Store and Chinese App store. They conducted the evaluation on several machine learning algorithms, i.e., Improved Naive Bayer, SVM, KNN, Naive Bayes, and DBN. The results were presented using TPR, FPR, and accuracy. The best results were given by the Improved Naive Bayes algorithm.
Vesely and Žadnik [
150] focused their work on the detection of cryptocurrency miners. They used a data set that was collected in the Czech National Research and Educational Network, and subnets of three major institutions. The data set contained mining and non-mining clients, and was annotated accordingly. The results were presented using cumulative normalised distribution functions and confusion matrices.
A deep learning approach for detecting cryptomining malware was presented by Databian et al. [
137]. They evaluated LSTM, attention-based LSTM and Convolutional Neural Networks. In order to create their data set they collected the cryptominer samples from virustotal.com and removed all the inactive samples. The evaluation of the aforementioned methods is shown by presenting their accuracy, precision, recall, F-measure, MCC, and FPR. The best results were given by ATT-LSTM.
Machine learning was used by Caprolu et al. [
138] to detect cryptojacking. The Random Forest algorithm was selected as the most appropriate for this task. They tested the proposed method on multiple scenarios: a baseline example that simply monitors the traffic on the client, the detection of full nodes, detection of miners, and sponge-attack detection. All results were presented by calculating the F1-score and using AUC curves.
Gangwal et al. [
139] proposed a machine learning based system for the detection of covert cryptomining. They collected events and information about the performance of computers (processor events, hardware events, software events, and hardware cache events). In the case of missing values, they were replaced with the mean of the associated event. They trained and evaluated two machine learning methods, i.e., Random Forest and SVM. The testing was conducted on multiple scenarios, and the results were presented using accuracy, precision, recall, F1, and confusion matrices.
A solution to detect cryptojacking using magnetic side-channels and machine learning was presented by Gangwal and Conti [
146]. They used two different laptops to collect the data for the data set. They used laptops to conduct cryptominning and profiled the events. In addition to the hardware and software measurements, they also measured the generated magnetic fields. Before the data could be used for training and testing, a scaling function had to be used to normalise the input data. They tested the KNN classifier, and presented their results using confusion matrices, full-stack classifications, accuracy, precision, recall, and F1-score.
Mansor et al. [
147] compared the use of machine learning algorithms to detect cryptojacking. They tested the performance of Random Forest and Gradient Boost on a data set with both malicious and benign applications. Their results showed the confusion matrices and TP/FP rates for both algorithms.
A system that detects cryptomining malware using machine learning and deep learning was proposed by Pastor et al. [
140]. They used Mouseworld to generate the needed data. Additionally, they used the DS1 data set. Multiple machine learning models were evaluated (FCNN, Random Forest, Logistic Regression, CART, and C4.5). After presenting their F1, precision, recall, accuracy, AUC ROC, AUC P-R and confusion matrices, it was observed that RF, C4.5, and FCNN performed well.
MineCap: An incremental learning method for cryptojacking detection was presented by Neto et al. [
141]. They used mining pools running on specific TCP ports to collect the data needed for the data set. After the data were collected, unnecessary information was removed (source IP, destination IP, source port, destination port, transport protocol). They evaluated multiple classification algorithms, i.e., Random Forest, Logistic Regression, Gradient Boosted Tree, Naive Bayes. The results were presented using a graph with the ROC curve, and a graph containing the precision, sensibility, and specificity. Additionally, more graphs were presented that showed the accuracy of the ML algorithms.
Kharraz et al. [
144] created OUTGUARD—a system that detects in-browser covert cryptomining. To construct their data set they collected the blacklist pattern information from CoinBlockerList, NoCoin, and minerBlock. They then gathered websites that contained JavaScript libraries matching the blacklist patterns. They used Wappalyzer to label the cryptojacking libraries and also added non-cyprojacking websites to the data set. Lastly a set of features was extracted including: JavaScript execution time, JavaScript compilation time, garbage collection, Iframe resource loads, CPU usage, etc. To evaluate the proposed system, they presented the score ratio based on the feature, and TPR and FPR ratio graph.
Yang et al. [
132] proposed a spam transaction attack detection model that is based on Deep Learning and LSTM (GRU and WGAN-div). The data set was created by using the bitcoin sound code and simulating the needed environment. The results were presented with an accuracy and false alarm rate, and compared to ADvISE, SVDD, and OC-SVM.
Deebak and Al-Turjman [
151] used machine learning to measure privacy protection and cyber risks. Multiple machine learning algorithms, i.e., XGBoost, Nearest Neighbor, SVM, and Decision-Tree were used to detect fraudulent behaviour. The data set used for testing purposes was collected from an insurance company. The detection was focused on whether the claims were fraudulent or not. The performance was measured using accuracy, precision, recall, F1-score and training time.
A supervised learning model that can be used to identify illegal activities in the bitcoin blockchain was created by Nerurkar [
153] et al. The data set was collected from the VJTI Blockchain lab, and the raw data were converted to CSV files. The necessary features were extracted and multiple hash addresses (from a single entity) were grouped by using multi-input heuristic clustering. The experimental study of their approach was conducted comparing the performance of SVM, LogReg, XGBoost, Random Forest and their custom proposed model. The results were presented by calculating the precision, recall, and F-score, and by multiple graphs showing the scalability, learning curves, and performance of each method.
A method for the detection of intrusion and DoS attacks on E-voting systems was presented by Cheema et al. [
145]. They used the UNSW-NB15 data set to train and test two SVM classifier models (Gaussian and Linear). The evaluation was made using accuracy, area under the curve, and prediction speed.
A cryptojacking detection method using machine learning was presented by Nukala [
143]. He tested KNN, Random Forest, Decision Trees, SVM, and Naive Bayes. The data set consisted of cache hits and misses, and the performance was presented using the models accuracy, precision, recall, and F1-score. The best F1 score was given by SVM.
The T-distributed stochastic neighbour embedding was used by Sun et al. [
154] to detect malicious user activity on Ethereum. They used an existing data set, and extracted the ones that could be associated with malicious behaviour. Node clustering was employed to detect such behaviour. The performed work was presented using Eigenvector visualisation.
Supervised machine learning was used by Ostapowicz and Zbikowski [
142] to detect fraudulent accounts on the Ethereum blockchain. Data were obtained from Etherscan.io, and the empty wallets were removed (the ones with no transactions). The evaluation included three machine learning classifiers (Random Forest, SVM, and XGBoost). The probability specificity, recall, precision, FPR, F1, and confusion matrices were presented for each of the evaluated methods. Random Forest obtained the best results.
Farrugia et al. [
152] presented the detection of illicit accounts on the Ethereum blockchain by using XGBoost. They created the data set by collecting the data from the Etherscamdb and a local Geth client. They collected both normal accounts and those labelled as illicit. The data were filtered by removing the duplicate accounts, their transactions were gathered using Etherscan API, and removing unsuccessful transactions. The data were visualised utilising a 2D and 3D t-SNE scatter plot. To evaluate their proposal, they calculated the accuracy, sensitivity, specificity, F1-score, and AUC for multiple scenarios. They also provide a graph with the average logarithmic loss, classification error, and a confusion matrix.
A method for the detection of suspicious users was proposed by Mittal and Bhatia [
136]. They used two data sets to evaluate their system: Bitcoin-OTC and Bitcoin-Alpha. Multiple machine learning techniques were evaluated, such as SVM, Naive Bayes, Decision Tree, and Neural Networks. They presented the results of the evaluation providing the precision, recall, F1-score, support, and accuracy from each machine learning algorithm, and for each data set.
A supervised learning model to identify illegal activities within the bitcoin blockchain was presented by Nerurkar et al. [
149]. The data set was taken from the VJTI Blockchain lab and converted to CSV files. They evaluated the proposed model on multiple classifiers (SVM, Logistic Regression, XGBoost, and Random Forest). The results of the valuation were presented with a several performance variables (like AUc, accuracy, sensitivity, detection rate, kappa, P-value, etc.), confusion matrices, CPU and RAM utilisation, learning curves, scalability graphs of the models, and performance graphs of the models.
An estimate of the proportion of malicious entities in the bitcoin system was proposed by Sun Yin and Vatrapu [
148]. They used supervised machine learning. The data set consisted of categorised and uncategorised data for every cluster in the blockchain environment. Data were cleaned from all of the empty cells (values depending on the cell type were inserted in the empty cells—0 for integers, 0.0 for float, and the string values depended on the column). Manual feature extraction and feature engineering was conducted after the data set was cleared of missing values. Multiple classifiers were tested and presented using mean CV-Accuracy and SD. Gradient boosting and bagging proved to have the best performance, so they were chosen for further research.
Chen et al. [
134] created a decentralised autonomous video copyright protection system based on blockchain. They evaluated their system using the VCDB data set, and presented the dimension, recall, and query speed.
5.2.4. IoT and Sensors
Ding et al. [
160] proposed a multiple object tracking system using HashNet from deep hash extraction. They used the MOT15 data set for the evaluation and acquired multiple results (mostly tracked agents, mostly lost agents, False Positives, False Negatives, identity switches, multi-object tracking accuracy and multi-object tracking precision).
AIT is an deep learning based trust management system for vehicular networks proposed by Zhang et al. [
161]. To create a data set, they used SUMO (Simulator of Urban MObility) to generate maps and vehicular network simulations. Their model is based on the Feedforward Neural Network, and for the evaluation (precision, recall, percentage of malicious nodes, and accuracy) it was compared to the Recurrent Neural Network and Convolutional Neural Network.
Liu et al. [
163] used blockhain and Federated Learning for intrusion detection in vehicular edge computing. They used the KDD Cup99 data sets of edge vehicles to test the proposed system and represent the precision rate, recall rate, and accuracy rate changes with respect to data size.
Zhang et al. [
162] proposed a target detection and automatic monitor scheme based on blockchain and deep learning models. They used the CIFER-10 and Mnist data set to conduct the performance evaluation of the proposed model. The results showed the training accuracy and loss.
Hao et al. [
164] used Generative Adversarial Neural Networks to detect fraudulent behaviour in the IoT. They prepared two sets of data: one set for the digital signature frauds (containing messages, private keys, and public keys), and another data set for asymmetric encryption frauds (plaintext, private keys, and public keys).
Supervised machine learning for outlier detection was used by Salimitari et al. [
165]. They created a simulation of an IoT network with 100 sensors and collected their data. The performance was presented using fault tolerance and accuracy.
BITS: A blockchain based intelligent transportation system was proposed by Maskey et al. [
166]. They used machine learning to detect outliers within the system. Simulated data were used from multiple data and randomly injected 10% outlier values. They presented the outcome of the Isolation Forest model using a graph that included the accuracy and false positive rate.
A multi-level trust mechanism against Sybil attacks in vehicular networks was presented by Haddaji et al. [
167]. They tested the system with three different machine learning algorithms: SVM, KNN, and Random Forest. The algorithms were tested using the VeReMi data set that contains multiple types of attacks: Constant attack, Constant offset attack, Random attack, Random offset attack, and Eventual stop attack. They presented the accuracy and time consumed per test for each of the selected algorithms, and showed that KNN gave the best ratio of accuracy and consumed time.
Dhieb et al. [
168] presented a system for fraud detection and risk measurement in the Insurance sector. For their experiment they used four machine learning classifiers (Decision Tree, SVM, Nearest Neighbor, and XGBoost) on a data set obtained from an insurance company. They calculated the accuracy, recall, precision, and F1-score, and showed that XGBoost performed the best. Additionally, they provided the normalised confusion matrix for XGBoost.






{kind=link}
{kind=link}
{kind=link}
{kind=link}