
MonoMR: Synthesizing Pseudo-2.5D Mixed Reality Content from Monocular Videos


Abstract
:1. Introduction
- We propose MonoMR, a system to synthesize MR content from single or multiple monocular videos.
- We evaluate the quantitative performance of our system.
- We assess the impact of the synthesized content through a user study.
- We develop suitable sample applications using the proposed system.
2. Related Work
2.1. Monocular Video Based Content Synthesis
2.2. Free-Viewpoint Video System
2.3. Human Analysis
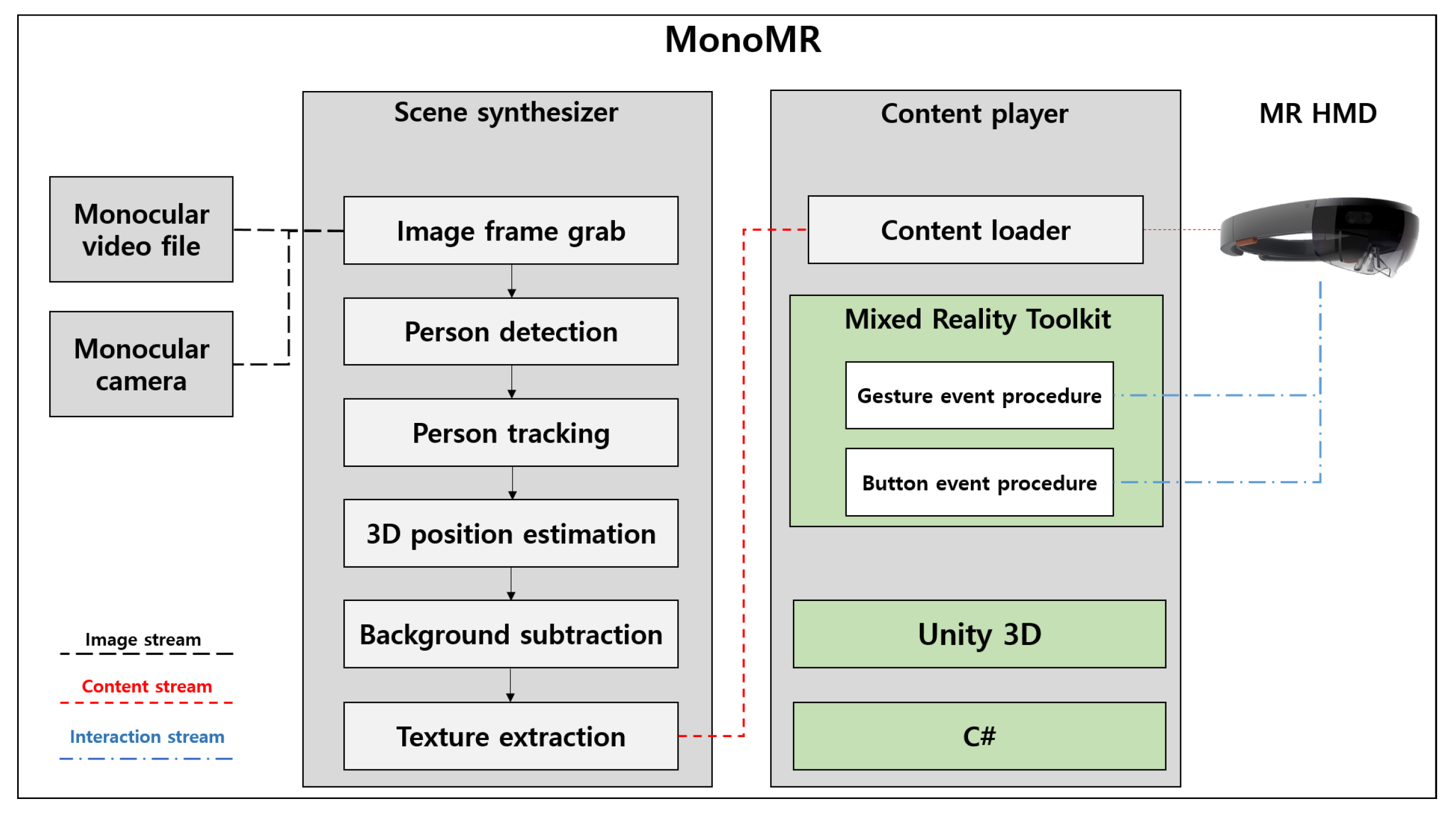
3. MonoMR System
3.1. Person Detection and Tracking
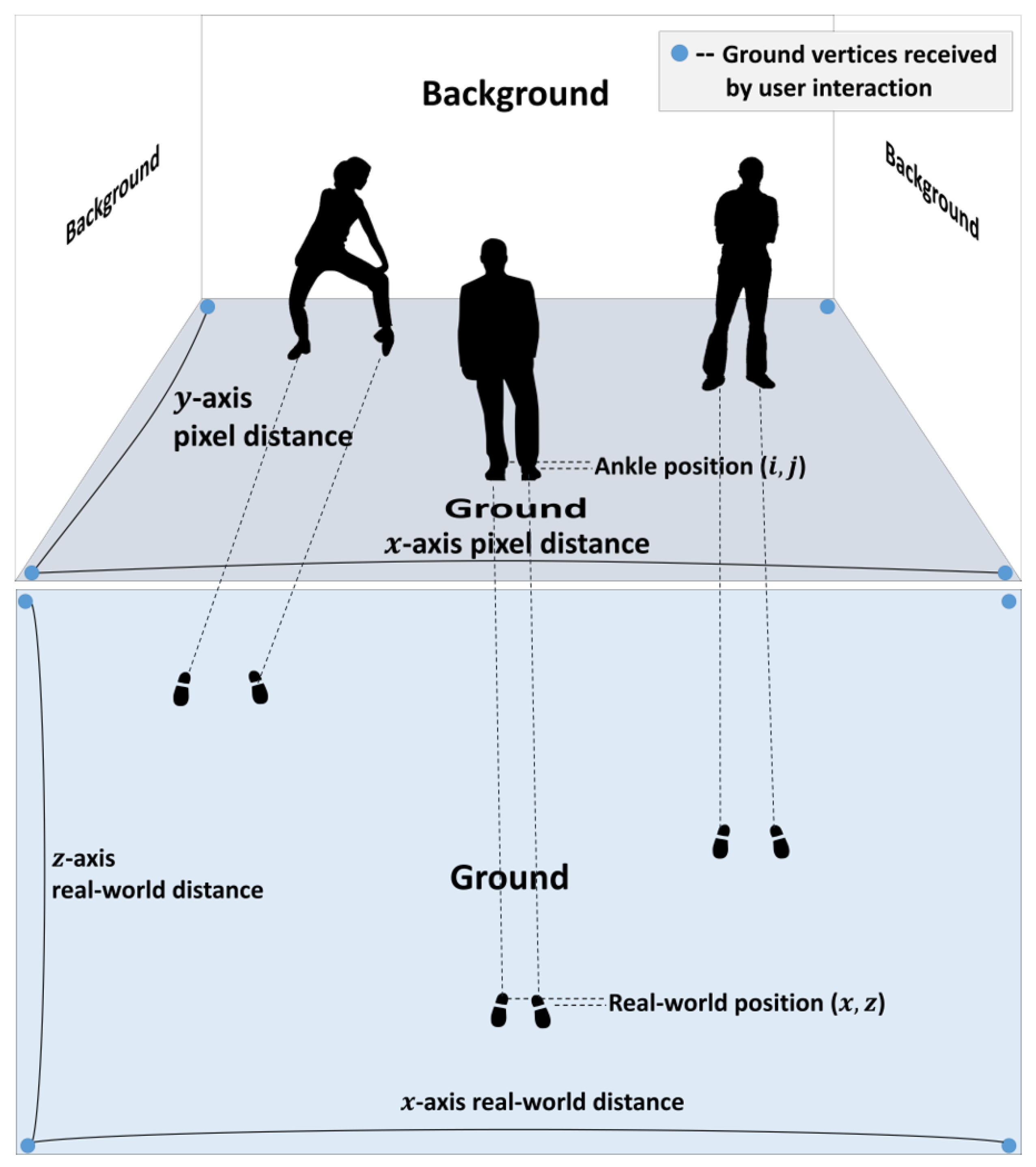
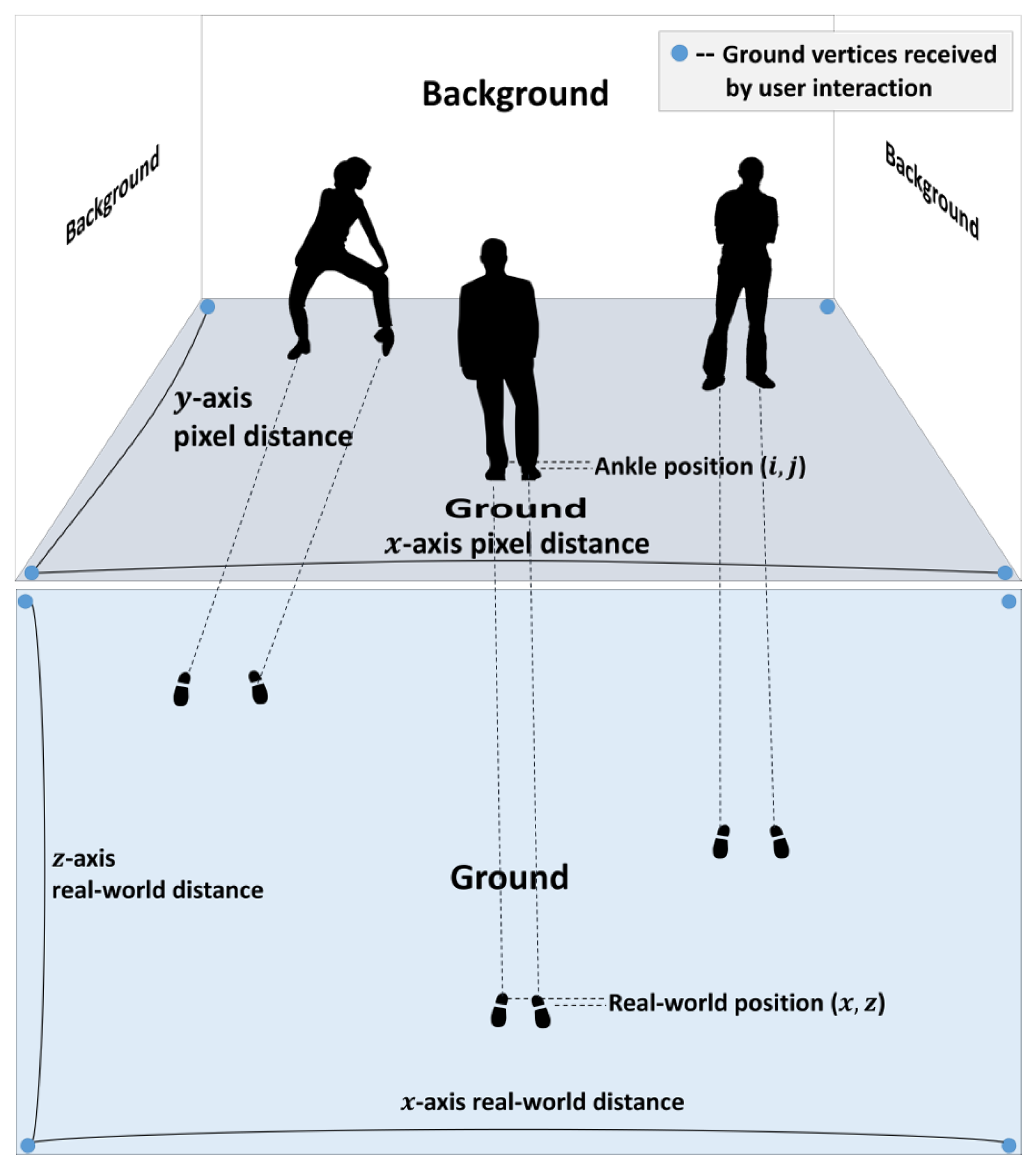
3.2. Pseudo-3D Position Estimation
3.3. Extracting Person Texture Using Background Subtraction
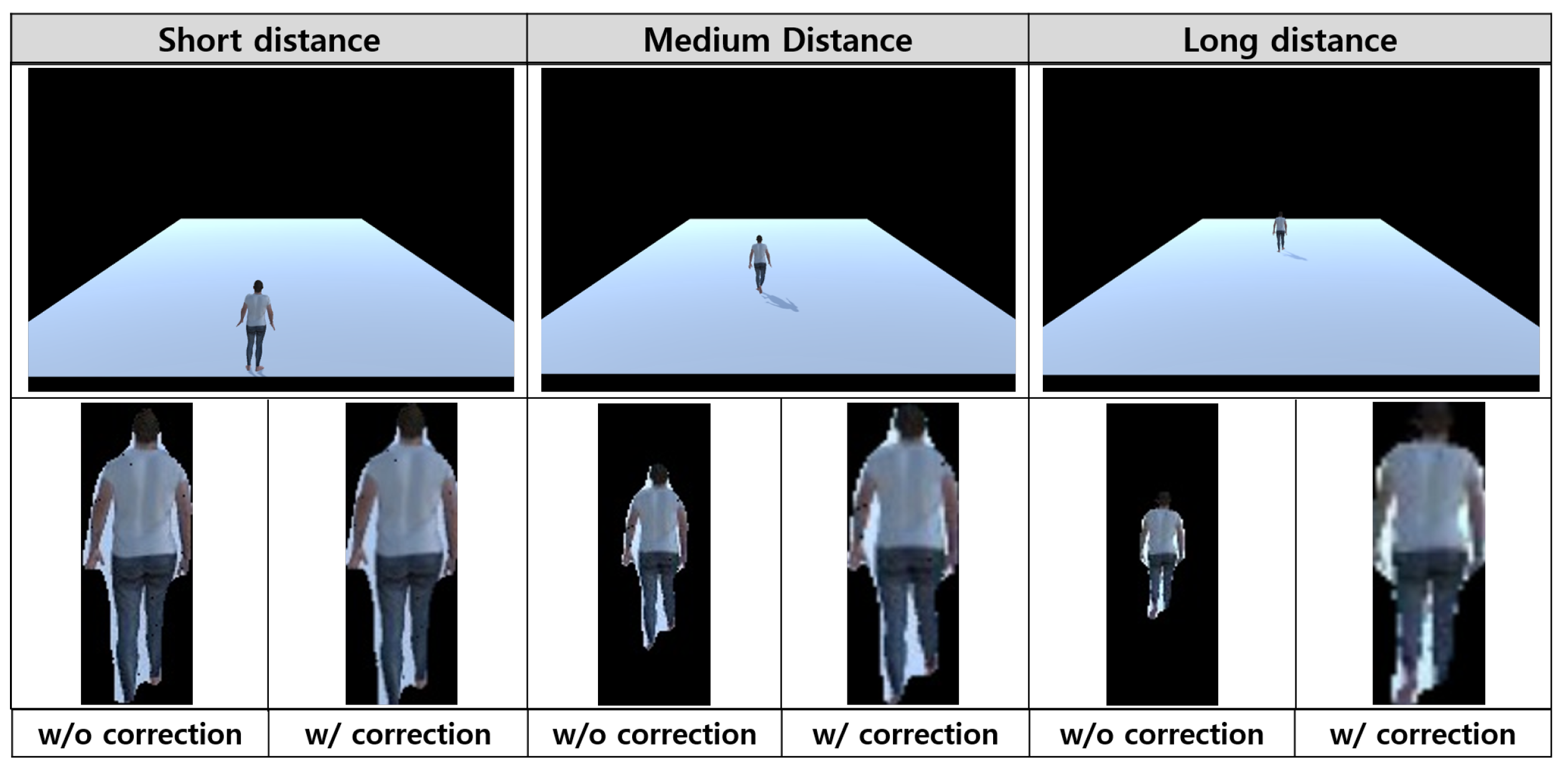
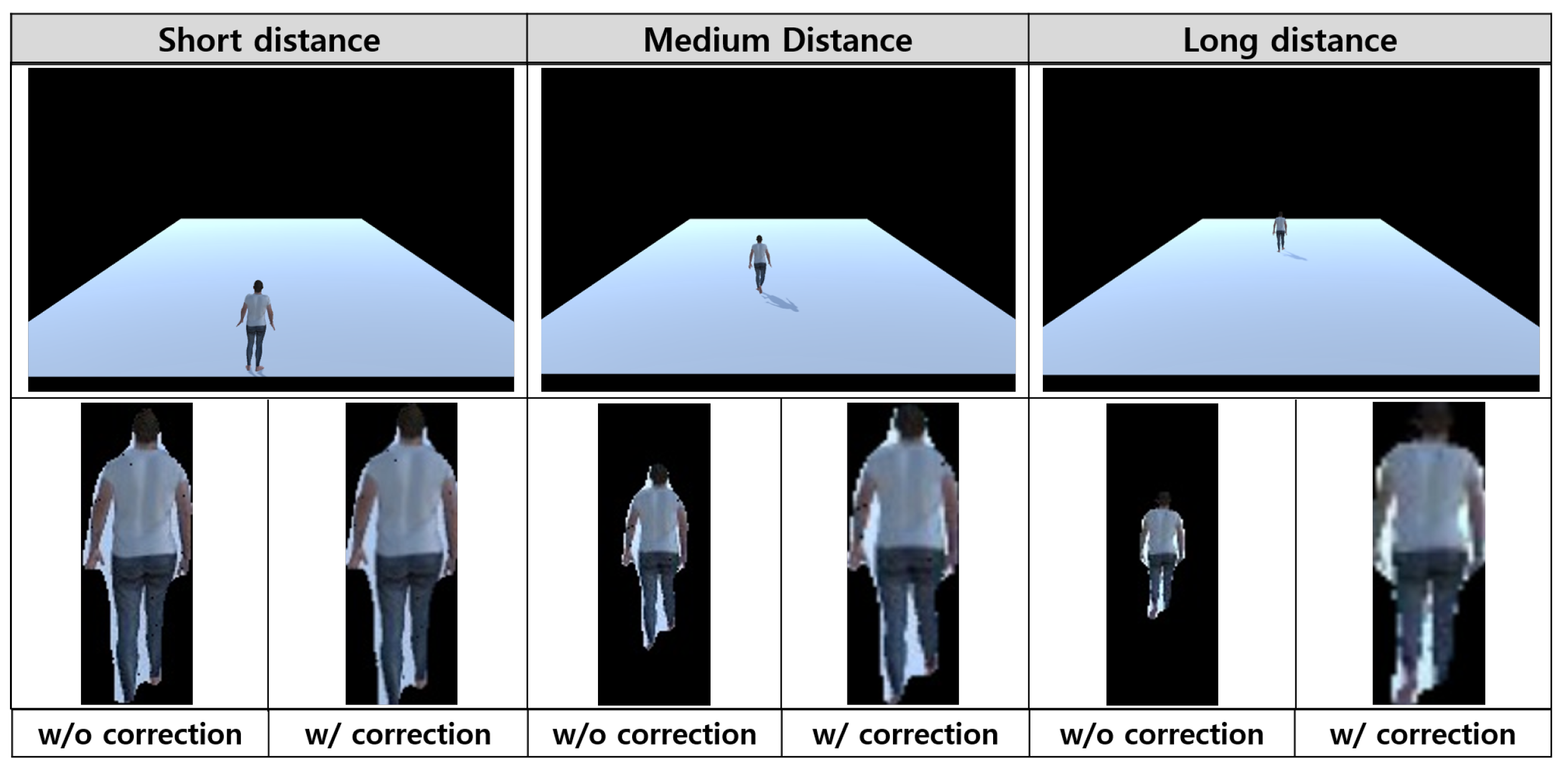
3.4. Texture Size Correction Using Weak-Perspective Projection and Content Synthesis
3.5. Billboard Rendering
3.6. Playing Synthesized Content on MR HMDs
4. Performance Evaluation
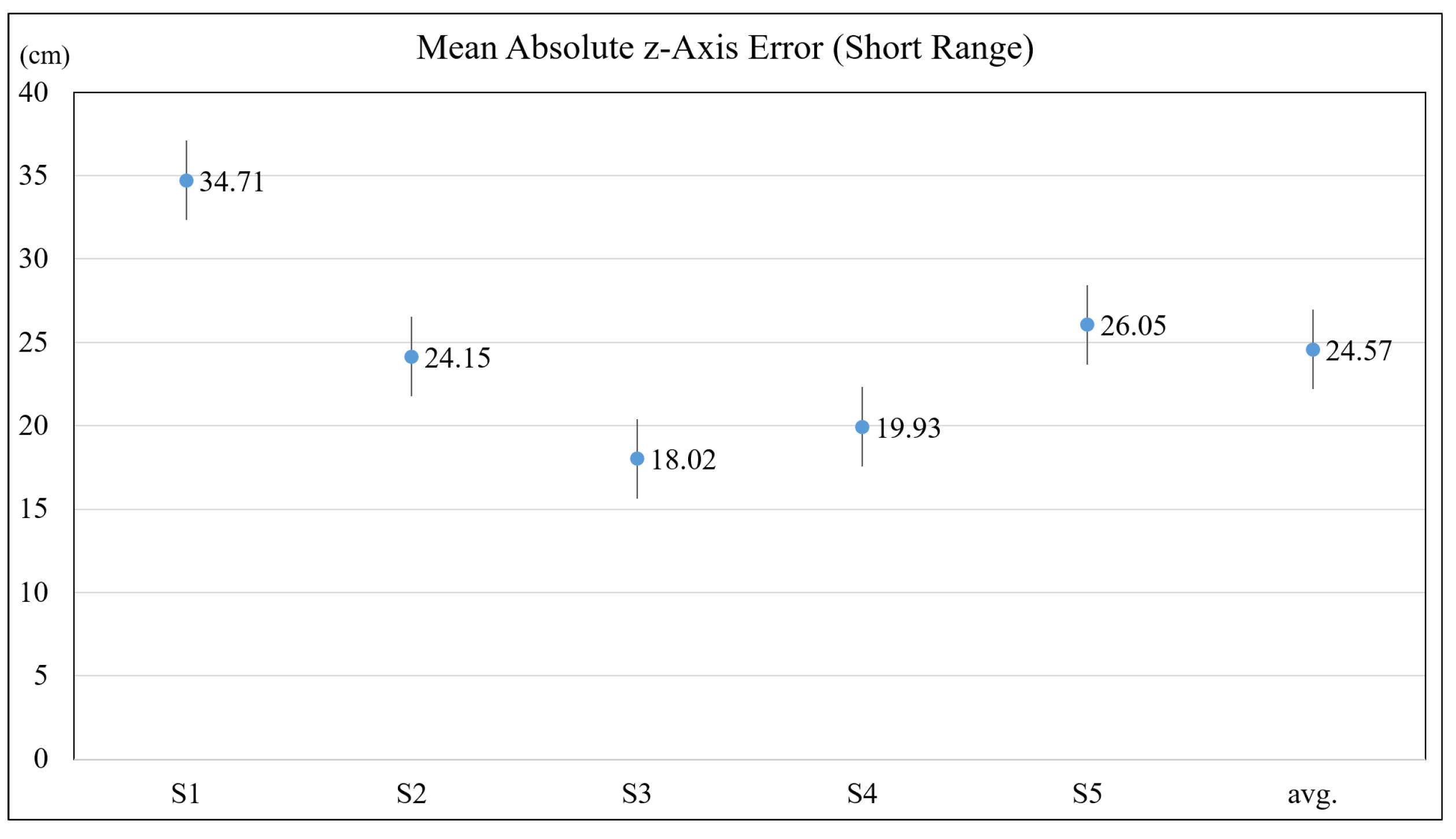
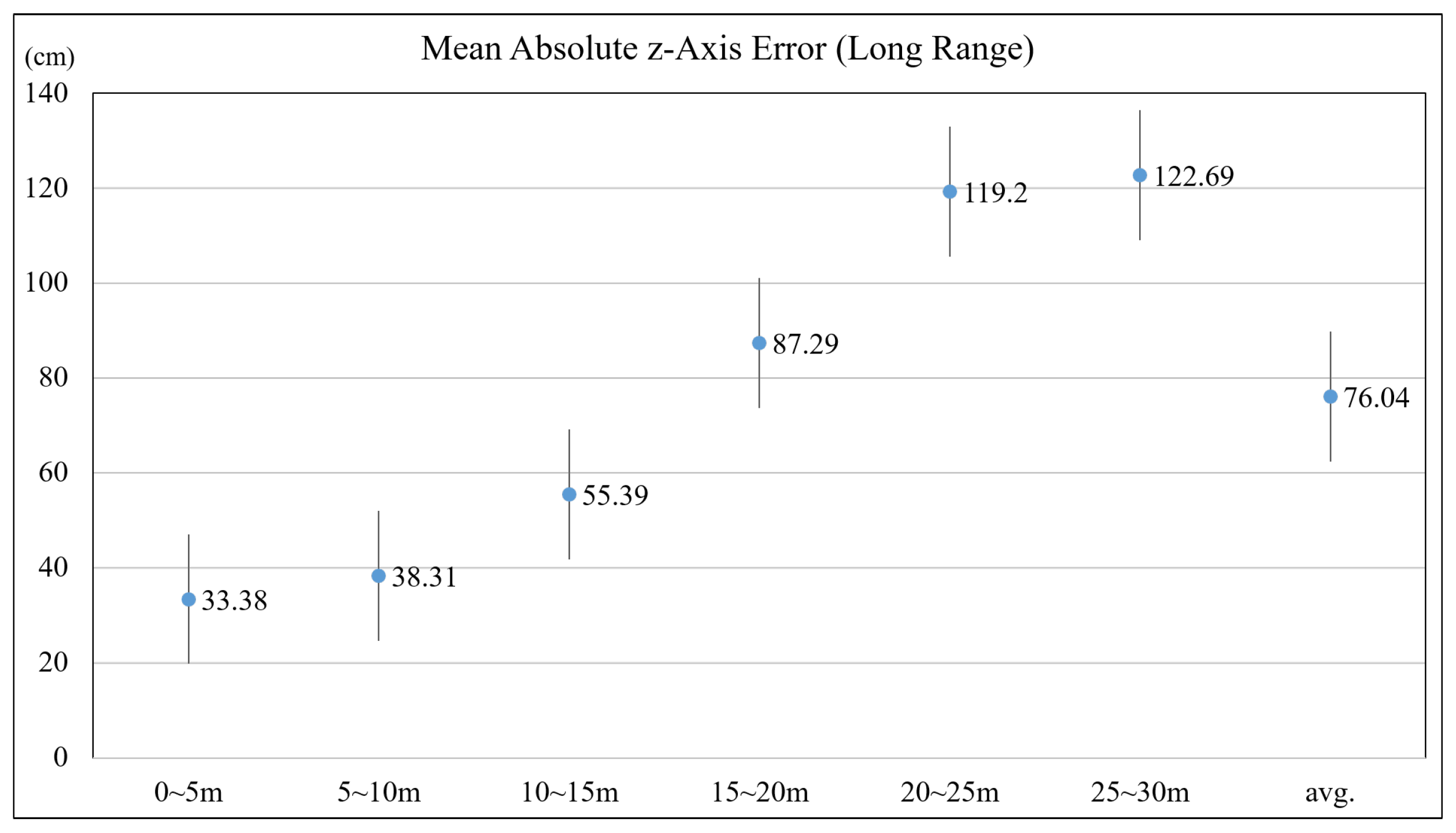
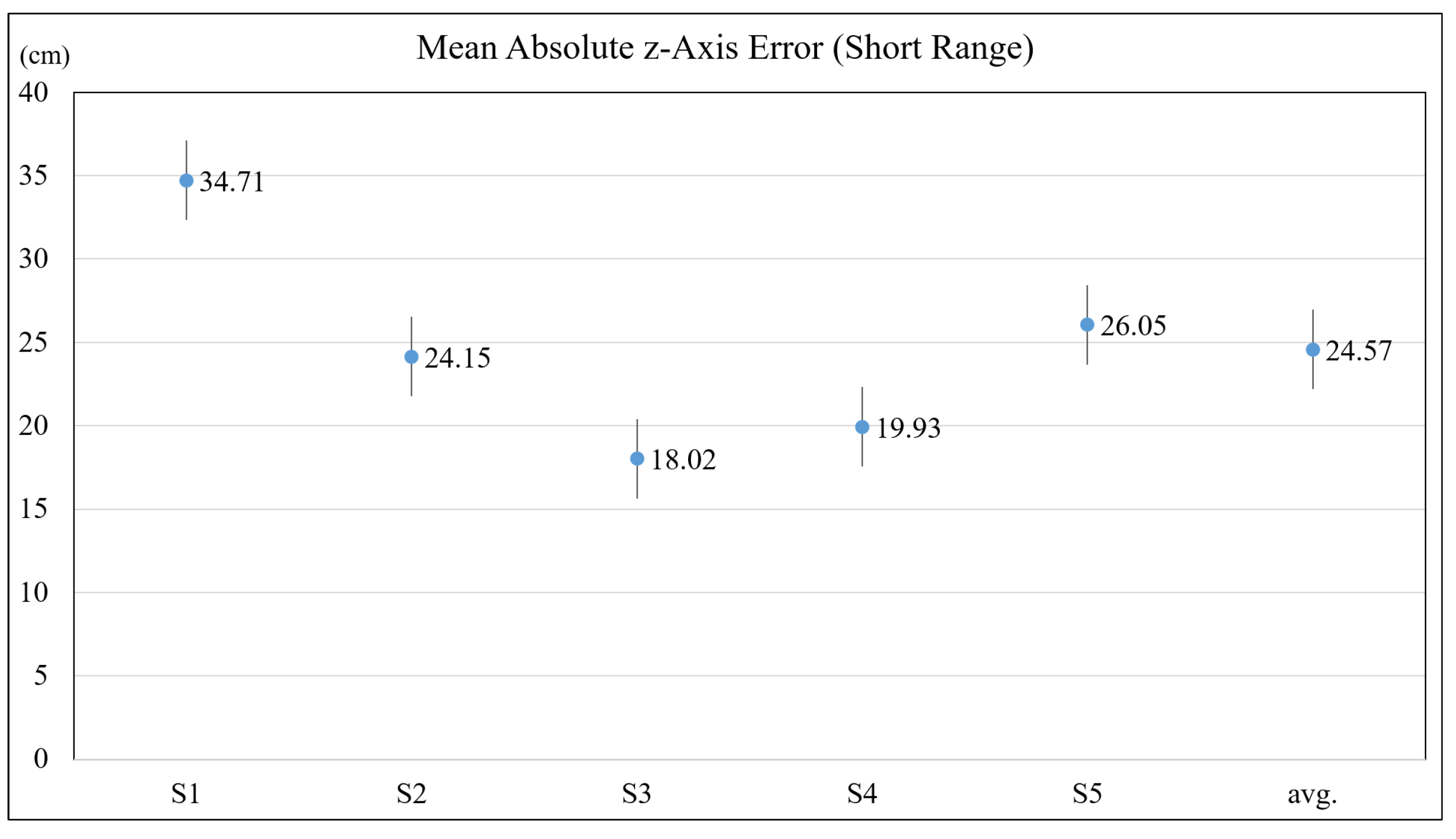
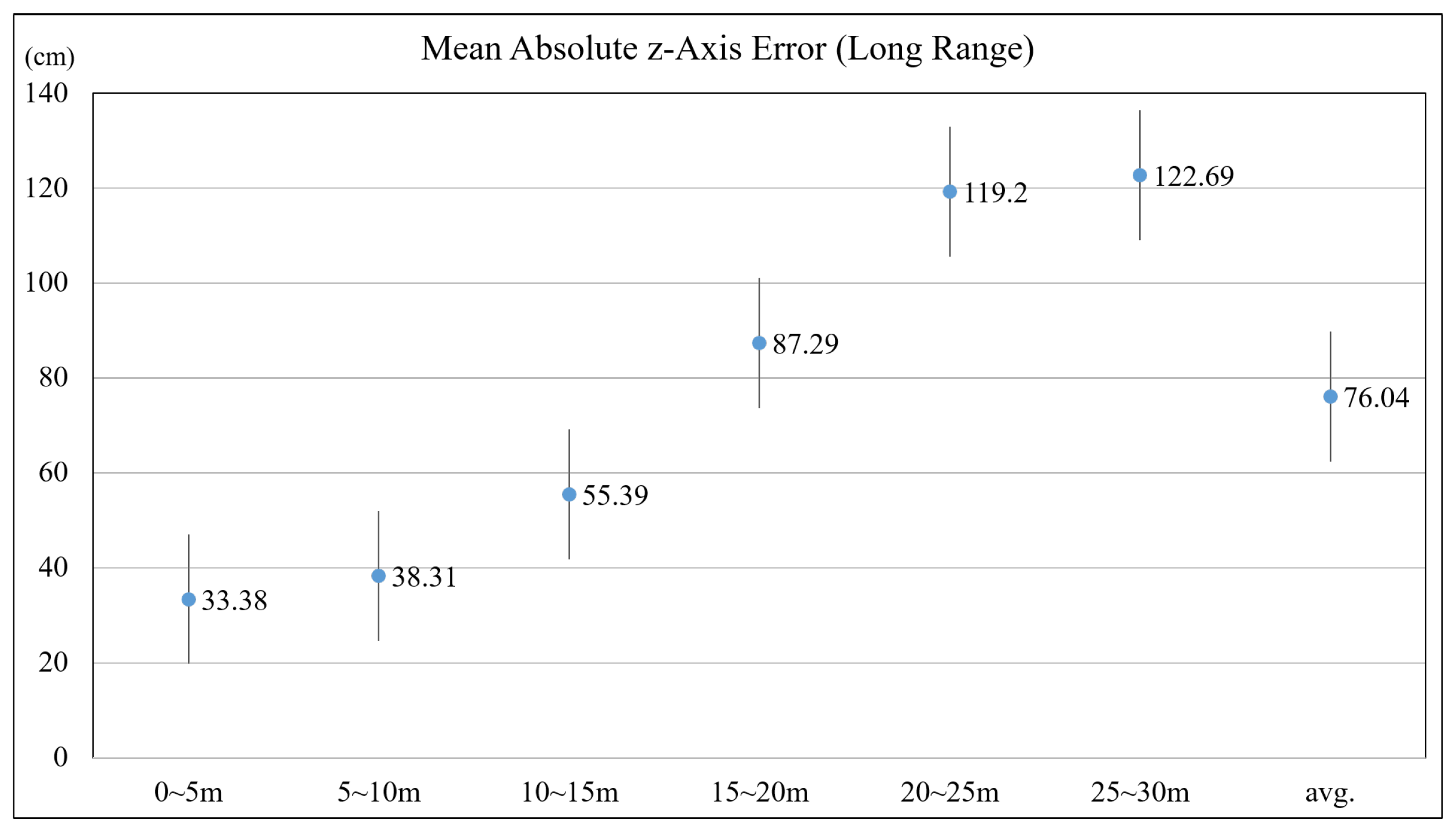
4.1. Accuracy of Depth Estimation
4.2. Accuracy of Texture Extraction
4.3. Processing Speed
5. Small-Scale User Study
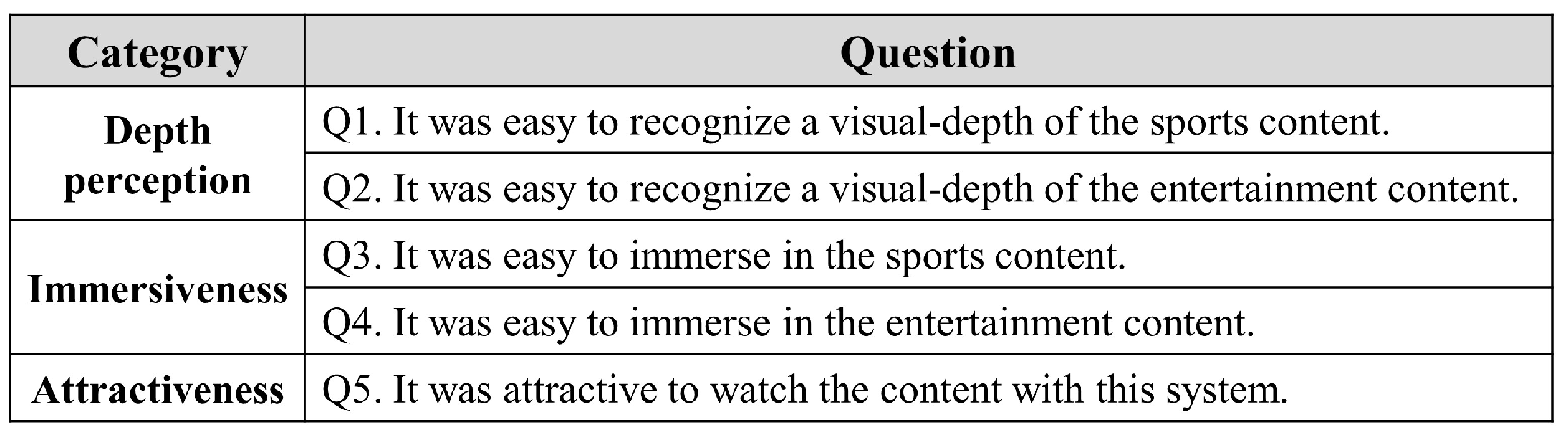
5.1. Experiment Design
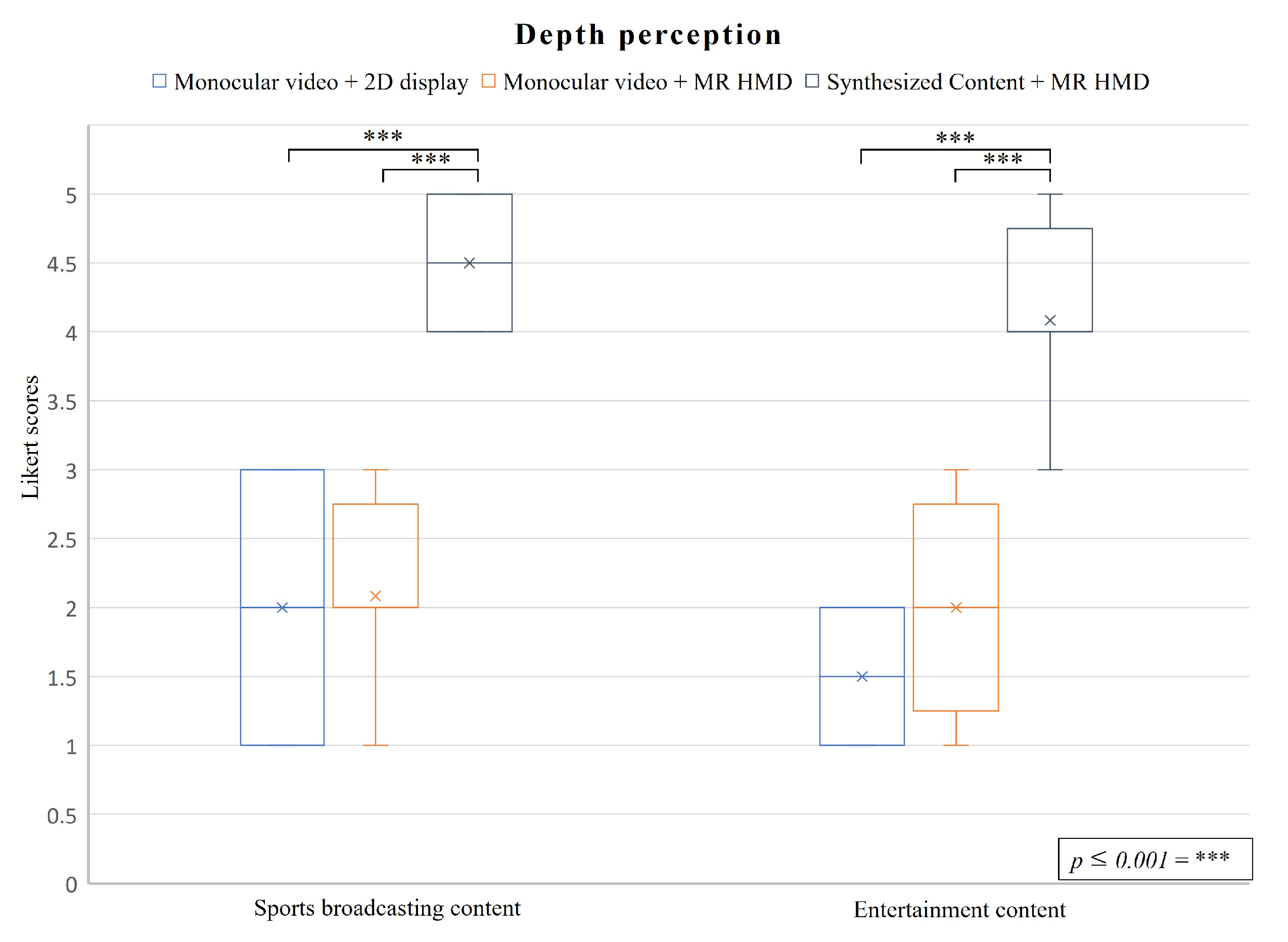
- Depth perception: How much of a stereoscopic degree the user feels in the content.
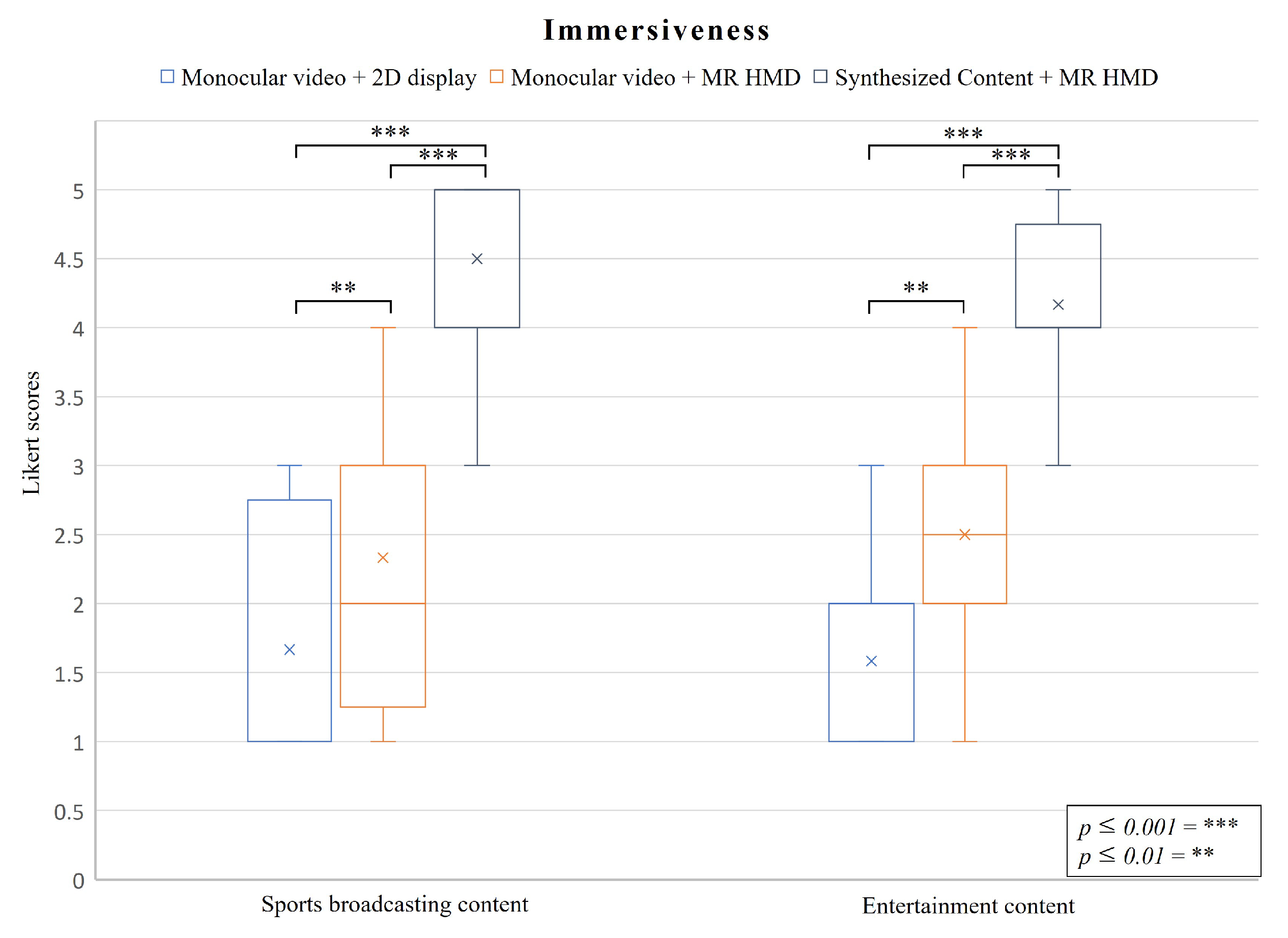
- Immersiveness: How immersed is the user in the content.
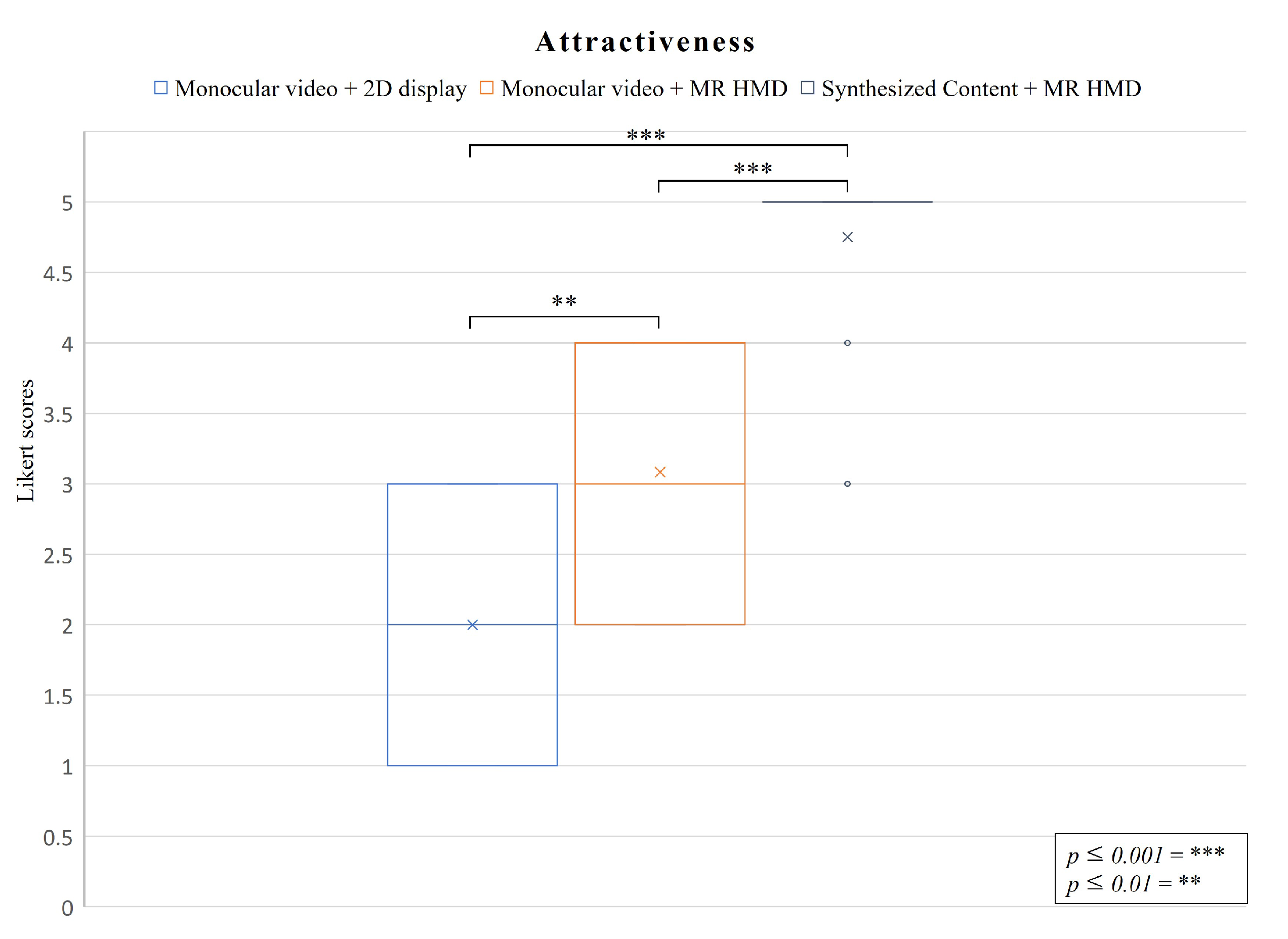
- Attractiveness: How interested is the user in the content.
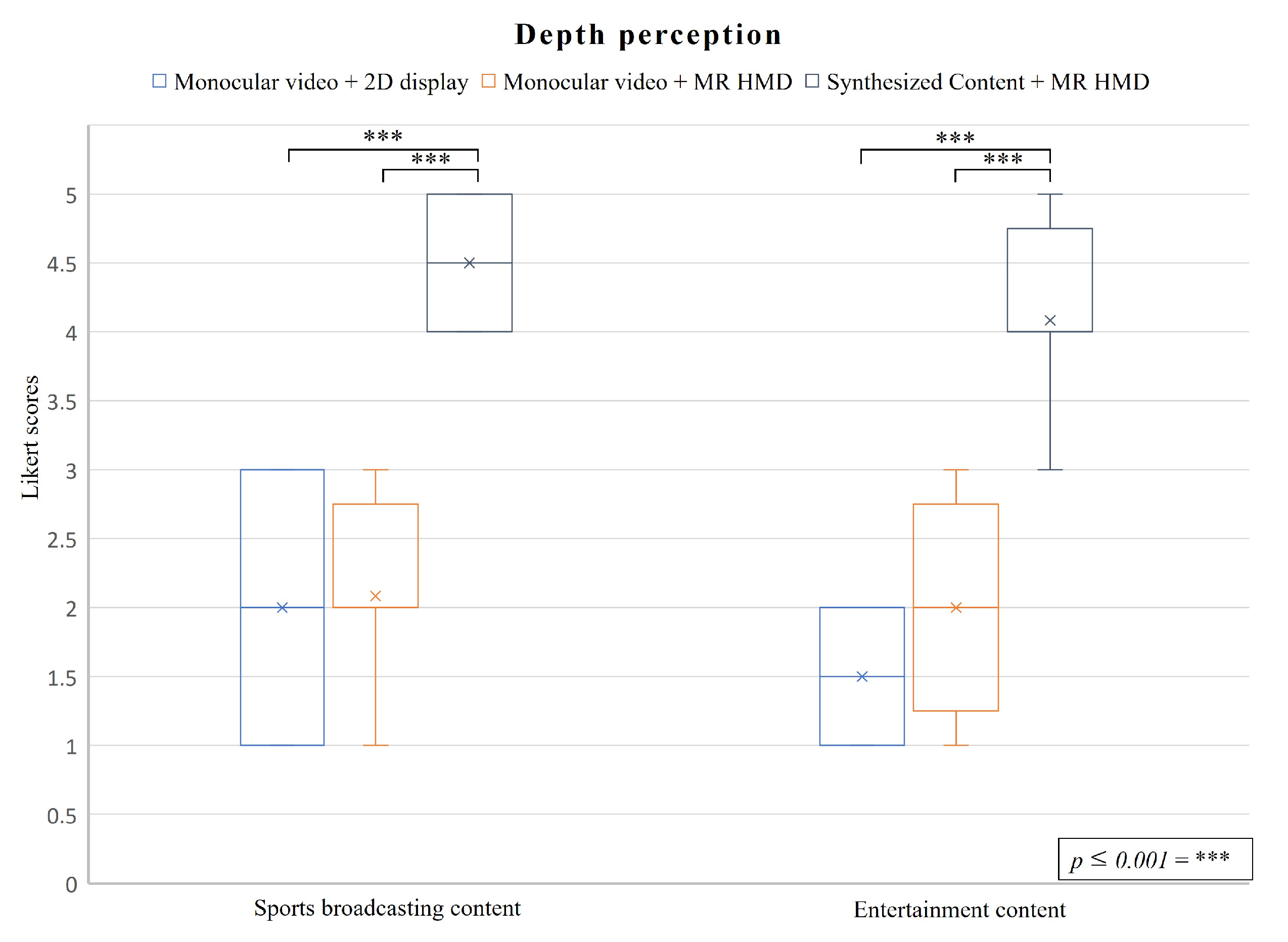
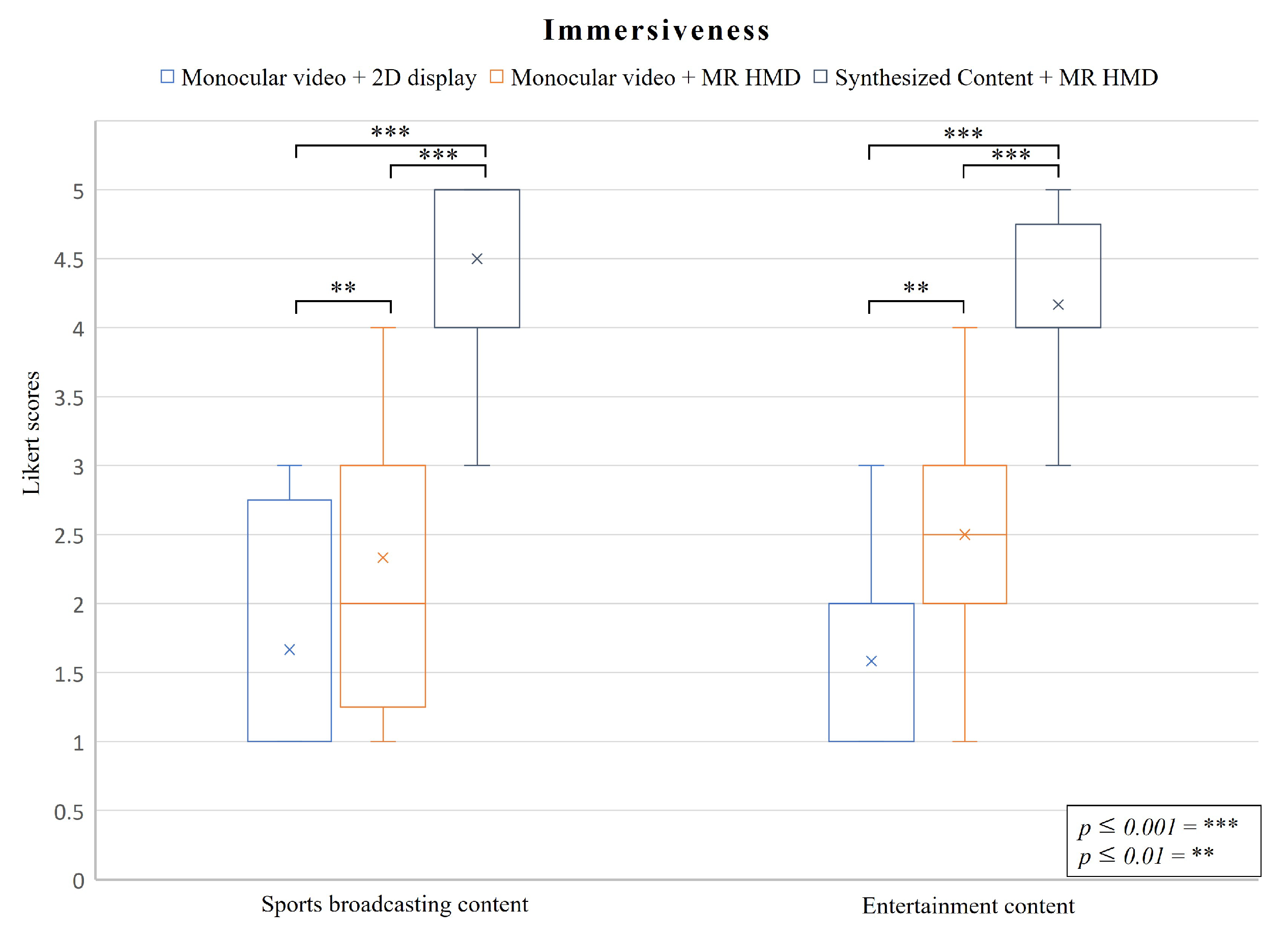
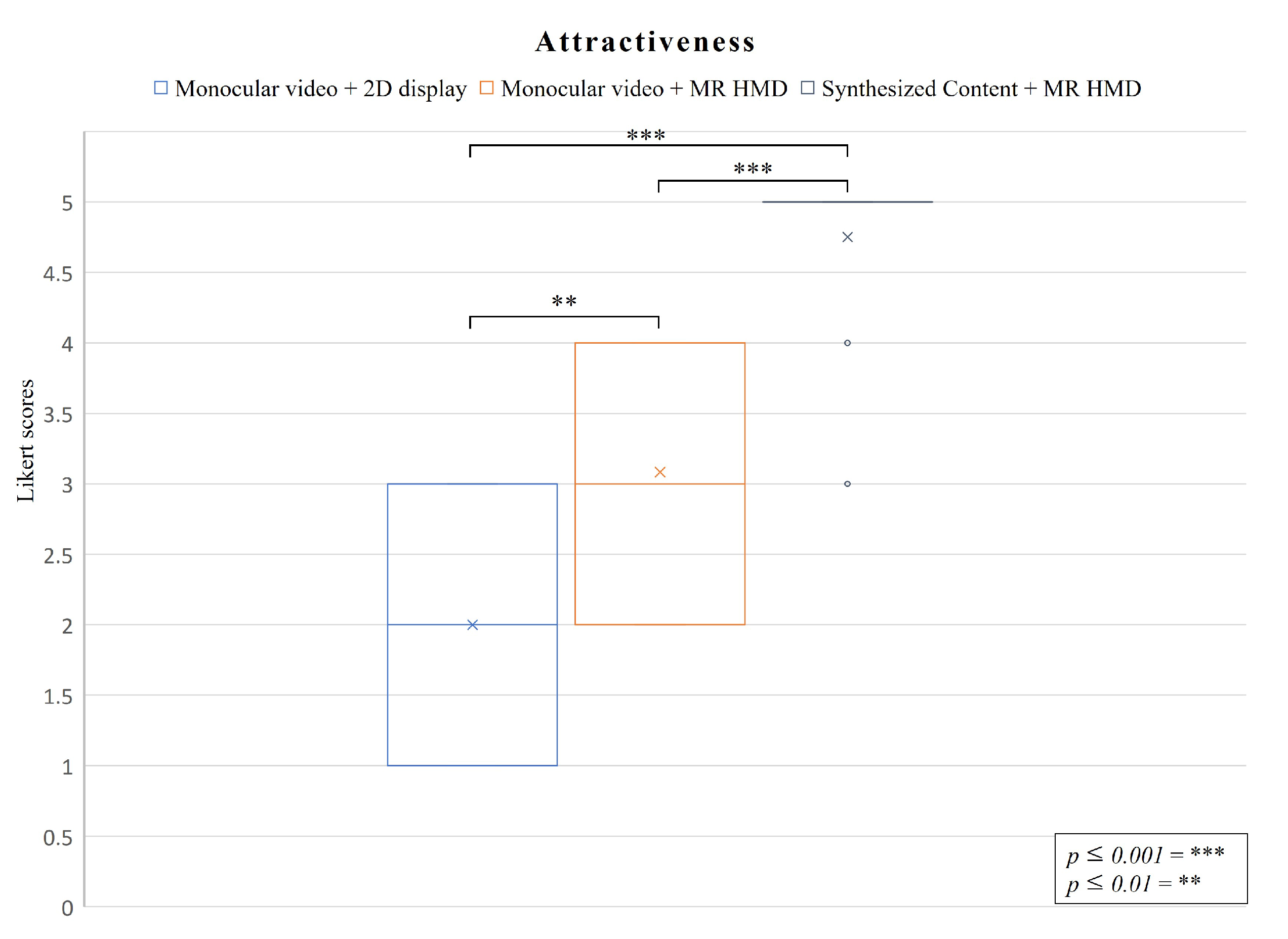
- C1: Monocular videos displayed on a flat-panel display.
- C2: Monocular videos displayed on a MR HMD.
- C3: Synthesized content displayed on a MR HMD.
5.2. Results
5.2.1. Depth Perception
5.2.2. Immersiveness
5.2.3. Attractiveness
6. Applications
6.1. Immersive Sports Broadcasting
6.2. Dynamic Entertainment Content
6.3. Effective Surveillance System
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Collet, A.; Chuang, M.; Sweeney, P.; Gillett, D.; Evseev, D.; Calabrese, D.; Hoppe, H.; Kirk, A.; Sullivan, S. High-quality Streamable Free-viewpoint Video. ACM Trans. Graph. 2015, 34, 69:1–69:13. [Google Scholar] [CrossRef]
- Orts-Escolano, S.; Rhemann, C.; Fanello, S.; Chang, W.; Kowdle, A.; Degtyarev, Y.; Kim, D.; Davidson, P.L.; Khamis, S.; Dou, M.; et al. Holoportation: Virtual 3D Teleportation in Real-time. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology (UIST ’16), Tokyo, Japan, 16–19 October 2016; ACM: New York, NY, USA, 2016; pp. 741–754. [Google Scholar] [CrossRef]
- Canon Announces Development of the Free Viewpoint Video System Virtual Camera System That Creates an Immersive Viewing Experience. Available online: https://global.canon/en/news/2017/20170921.html (accessed on 16 August 2021).
- Intel® True View—See More Game Than Ever. Available online: https://www.intel.com/content/www/us/en/sports/technology/true-view.html (accessed on 24 July 2021).
- Goorts, P.; Maesen, S.; Dumont, M.; Rogmans, S.; Bekaert, P. Free viewpoint video for soccer using histogram-based validity maps in plane sweeping. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 3, pp. 378–386. [Google Scholar]
- Ye, G.; Liu, Y.; Deng, Y.; Hasler, N.; Ji, X.; Dai, Q.; Theobalt, C. Free-Viewpoint Video of Human Actors Using Multiple Handheld Kinects. IEEE Trans. Cybern. 2013, 43, 1370–1382. [Google Scholar] [CrossRef] [PubMed]
- Pavlakos, G.; Zhu, L.; Zhou, X.; Daniilidis, K. Learning to Estimate 3D Human Pose and Shape From a Single Color Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ballan, L.; Brostow, G.J.; Puwein, J.; Pollefeys, M. Unstructured Video-based Rendering: Interactive Exploration of Casually Captured Videos. ACM Trans. Graph. 2010, 29, 87:1–87:11. [Google Scholar] [CrossRef]
- Chen, J.; Paris, S.; Wang, J.; Matusik, W.; Cohen, M.; Durand, F. The video mesh: A data structure for image-based three-dimensional video editing. In Proceedings of the 2011 IEEE International Conference on Computational Photography (ICCP), Pittsburgh, PA, USA, 8–10 April 2011; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Russell, C.; Yu, R.; Agapito, L. Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 583–598. [Google Scholar]
- Langlotz, T.; Zingerle, M.; Grasset, R.; Kaufmann, H.; Reitmayr, G. AR Record & Replay: Situated Compositing of Video Content in Mobile Augmented Reality. In Proceedings of the 24th Australian Computer-Human Interaction Conference (OzCHI ’12), Melbourne, Australia, 26–30 November 2012; ACM: New York, NY, USA, 2012; pp. 318–326. [Google Scholar] [CrossRef]
- Mohr, P.; Mandl, D.; Tatzgern, M.; Veas, E.; Schmalstieg, D.; Kalkofen, D. Retargeting Video Tutorials Showing Tools With Surface Contact to Augmented Reality. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (CHI ’17), Denver, CO, USA, 6–11 May 2017; ACM: New York, NY, USA, 2017; pp. 6547–6558. [Google Scholar] [CrossRef]
- Kanade, T.; Rander, P.; Narayanan, P.J. Virtualized reality: Constructing virtual worlds from real scenes. IEEE MultiMed. 1997, 4, 34–47. [Google Scholar] [CrossRef] [Green Version]
- Kitahara, I.; Ohta, Y.; Saito, H.; Akimichi, S.; Ono, T.; Kanade, T. Recording of multiple videos in a large-scale space for large-scale virtualized reality. Kyokai Joho Imeji Zasshi J. Inst. Image Inf. Telev. Eng. 2002, 56, 1328–1333. [Google Scholar]
- Koyama, T.; Kitahara, I.; Ohta, Y. Live mixed-reality 3D video in soccer stadium. In Proceedings of the Second IEEE and ACM International Symposium on Mixed and Augmented Reality, Tokyo, Japan, 10 October 2003; pp. 178–186. [Google Scholar] [CrossRef]
- Kameda, Y.; Koyama, T.; Mukaigawa, Y.; Yoshikawa, F.; Ohta, Y. Free viewpoint browsing of live soccer games. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME) (IEEE Cat. No.04TH8763), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 747–750. [Google Scholar] [CrossRef]
- Grau, O.; Hilton, A.; Kilner, J.; Miller, G.; Sargeant, T.; Starck, J. A Free-Viewpoint Video System for Visualization of Sport Scenes. SMPTE Motion Imaging J. 2007, 116, 213–219. [Google Scholar] [CrossRef]
- Grau, O.; Thomas, G.A.; Hilton, A.; Kilner, J.; Starck, J. A Robust Free-Viewpoint Video System for Sport Scenes. In Proceedings of the 2007 3DTV Conference, Kos, Greece, 7–9 May 2007; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Bogomjakov, A.; Gotsman, C.; Magnor, M. Free-viewpoint video from depth cameras. In Proceedings of the International Workshop on Vision, Modeling and Visualization (VMV), Aachen, Germany, 22–24 November 2006; pp. 89–96. [Google Scholar]
- Kuster, C.; Popa, T.; Zach, C.; Gotsman, C.; Gross, M.H. FreeCam: A Hybrid Camera System for Interactive Free-Viewpoint Video. In Proceedings of the International Workshop on Vision, Modeling and Visualization (VMV), Berlin, Germany, 4–6 October 2011; pp. 89–96. [Google Scholar]
- Matsumoto, K.; Song, C.; de Sorbier, F.; Saito, H. Free viewpoint video synthesis using multi-view depth and color cameras. In Proceedings of the IVMSP 2013, Seoul, Korea, 10–12 June 2013; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Horry, Y.; Anjyo, K.I.; Arai, K. Tour into the Picture: Using a Spidery Mesh Interface to Make Animation from a Single Image. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques ( SIGGRAPH ’97), Los Angeles, CA, USA, 3–8 August 1997; ACM Press/Addison-Wesley Publishing Co.: New York, NY, USA, 1997; pp. 225–232. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar] [CrossRef] [Green Version]
- Rematas, K.; Kemelmacher-Shlizerman, I.; Curless, B.; Seitz, S. Soccer on Your Tabletop. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Watanabe, T.; Kitahara, I.; Kameda, Y.; Ohta, Y. 3D Free-viewpoint video capturing interface by using bimanual operation. In Proceedings of the 2010 3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video, Tampere, Finland, 7–9 June 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Kashiwakuma, J.; Kitahara, I.; Kameda, Y.; Ohta, Y. A Virtual Camera Controlling Method Using Multi-touch Gestures for Capturing Free-viewpoint Video. In Proceedings of the 11th European Conference on Interactive TV and Video (EuroITV ’13), Como, Italy, 24–26 June 2013; ACM: New York, NY, USA, 2013; pp. 67–74. [Google Scholar] [CrossRef]
- Inamoto, N.; Saito, H. Free Viewpoint Video Synthesis and Presentation of Sporting Events for Mixed Reality Entertainment. In Proceedings of the 2004 ACM SIGCHI International Conference on Advances in Computer Entertainment Technology (ACE ’04), Singapore, 3–5 June 2004; ACM: New York, NY, USA, 2004; pp. 42–50. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.; Schiele, B. DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A Skinned Multi-Person Linear Model. ACM Trans. Graph. Proc. SIGGRAPH Asia 2015, 34, 248:1–248:16. [Google Scholar] [CrossRef]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. In Computer Vision–ECCV 2016; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 561–578. [Google Scholar]
- Kuhn, H.W. The Hungarian Method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Boykov, Y.; Funka-Lea, G. Graph Cuts and Efficient N-D Image Segmentation. Int. J. Comput. Vis. 2006, 70, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Zivkovic, Z.; van der Heijden, F. Efficient Adaptive Density Estimation Per Image Pixel for the Task of Background Subtraction. Pattern Recogn. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Akenine-Moller, T.; Haines, E.; Hoffman, N. Real-Time Rendering, 3rd ed.; A. K. Peters, Ltd.: Natick, MA, USA, 2008. [Google Scholar]
- D’Orazio, T.; Leo, M.; Mosca, N.; Spagnolo, P.; Mazzeo, P.L. A Semi-automatic System for Ground Truth Generation of Soccer Video Sequences. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS ’09), Genova, Italy, 2–4 September 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 559–564. [Google Scholar] [CrossRef]
- Daniel, W. Applied Nonparametric Statistics; Duxbury Advanced Series in Statistics and Decision Sciences; PWS-KENT: Boston, MA, USA, 1990. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical Methods for Research Workers. In Breakthroughs in Statistics: Methodology and Distribution; Kotz, S., Johnson, N.L., Eds.; Springer: New York, NY, USA, 1992; pp. 66–70. [Google Scholar] [CrossRef]
- Du, R.; Bista, S.; Varshney, A. Video Fields: Fusing Multiple Surveillance Videos into a Dynamic Virtual Environment. In Proceedings of the 21st International Conference on Web3D Technology (Web3D ’16), Anaheim, CA, USA, 22–24 July 2016; ACM: New York, NY, USA, 2016; pp. 165–172. [Google Scholar] [CrossRef] [Green Version]
- Hattori, K.; Hattori, H.; Ono, Y.; Nishino, K.; Itoh, M.; Boddeti, V.; Kanade, T. Image Dataset for Researches about Surveillance Camera-CMUSRD (Surveillance Research Dataset); Technical Report; Carnegie Mellon University: Pittsburgh, PA, USA, 2014. [Google Scholar]
- Yao, Q.; Sankoh, H.; Nonaka, K.; Naito, S. Automatic camera self-calibration for immersive navigation of free viewpoint sports video. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), Montreal, QC, Canada, 21–23 September 2016; pp. 1–6. [Google Scholar]
- Shade, J.; Gortler, S.; He, L.W.; Szeliski, R. Layered Depth Images. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’98), Orlando, FL, USA, 19–24 July 1998; ACM: New York, NY, USA, 1998; pp. 231–242. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Choi, H.; Moon, G.; Lee, K.M. Pose2Mesh: Graph Convolutional Network for 3D Human Pose and Mesh Recovery from a 2D Human Pose. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1988. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Procedure | Time (ms) |
|---|---|
| Person detection with normal/precision modes | 137.83/406.94 |
| Person tracking | 0.07 |
| Pseudo-3D position estimation | 0.03 |
| Texture extraction with background subtraction | 41.43 |
| Total processing time with normal / precision modes | 179.36/448.47 |
| Procedure | Time (ms) |
|---|---|
| Texture extraction with background subtraction (Ours) | 41.43 |
| Texture extraction with mask R-CNN | 2545 |
| Source | Sum Sq. | d.f. | Mean Sq. | Chi Sq. |
|---|---|---|---|---|
| Method (*) | 315.65 | 2 | 157.82 | 46.87 |
| Content | 3.56 | 1 | 3.56 | 2.95 |
| Source | Sum Sq. | d.f. | Mean Sq. | Chi Sq. |
|---|---|---|---|---|
| Method (*) | 166.54 | 2 | 83.27 | 24.17 |
| Content | 0.13 | 1 | 0.13 | 0.1 |
| Source | Sum Sq. | d.f. | Mean Sq. | Chi Sq. |
|---|---|---|---|---|
| Method (*) | 166.54 | 2 | 83.27 | 24.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, D.-H.; Koike, H. MonoMR: Synthesizing Pseudo-2.5D Mixed Reality Content from Monocular Videos. Appl. Sci. 2021, 11, 7946. https://doi.org/10.3390/app11177946
Hwang D-H, Koike H. MonoMR: Synthesizing Pseudo-2.5D Mixed Reality Content from Monocular Videos. Applied Sciences. 2021; 11(17):7946. https://doi.org/10.3390/app11177946
Chicago/Turabian StyleHwang, Dong-Hyun, and Hideki Koike. 2021. "MonoMR: Synthesizing Pseudo-2.5D Mixed Reality Content from Monocular Videos" Applied Sciences 11, no. 17: 7946. https://doi.org/10.3390/app11177946
APA StyleHwang, D.-H., & Koike, H. (2021). MonoMR: Synthesizing Pseudo-2.5D Mixed Reality Content from Monocular Videos. Applied Sciences, 11(17), 7946. https://doi.org/10.3390/app11177946