
High Performance DeepFake Video Detection on CNN-Based with Attention Target-Specific Regions and Manual Distillation Extraction


Abstract
:1. Introduction
2. Related Work
2.1. Face Forgery Generation
2.2. Face Forgery Detection
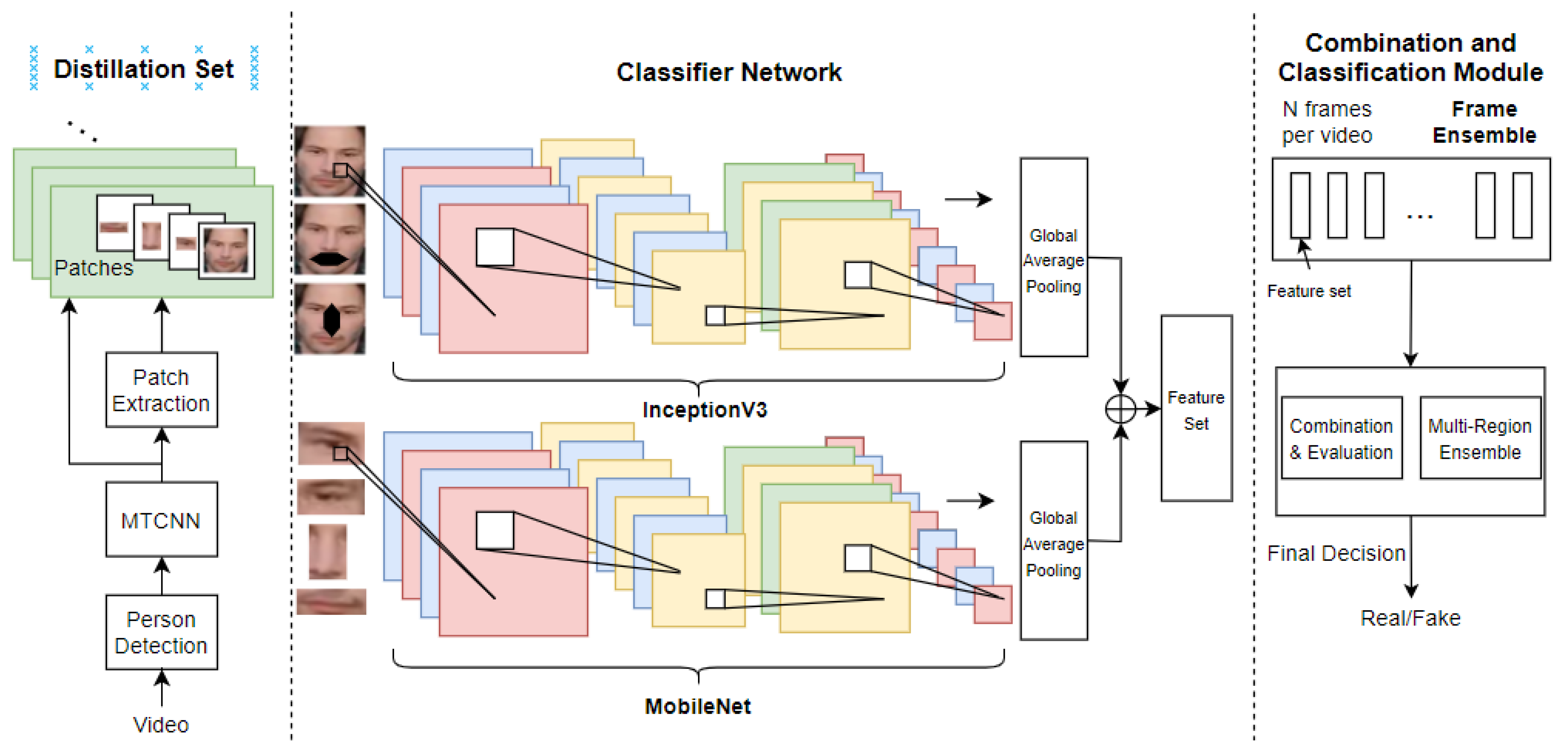
3. Proposed Methodology
3.1. Image Preprocessing
3.1.1. Face Extraction
3.1.2. Face Augmentation
3.1.3. Patch Extraction
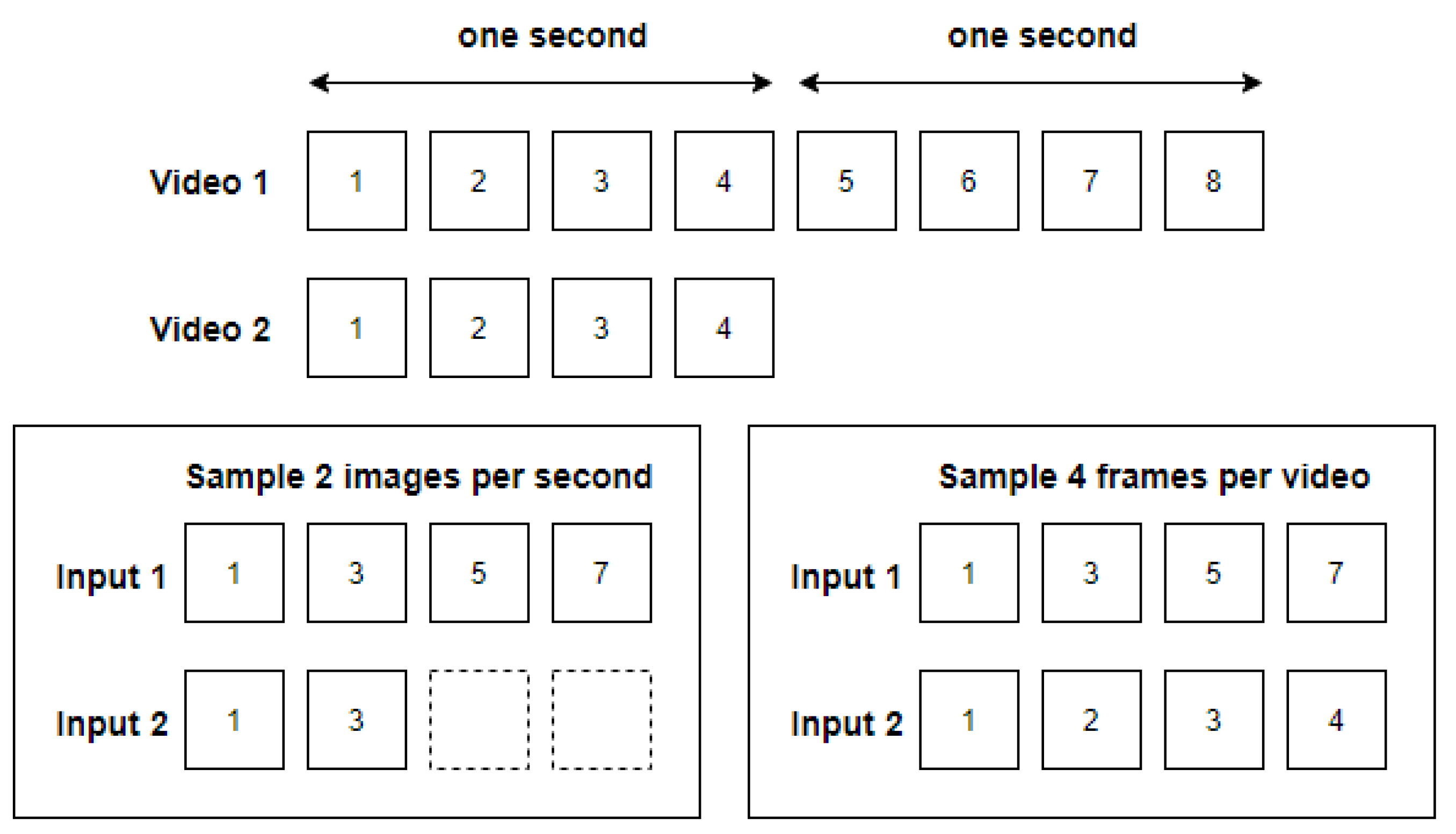
3.1.4. Distillation Set
3.2. Classifier Network Architecture
3.3. Combination and Classification Module
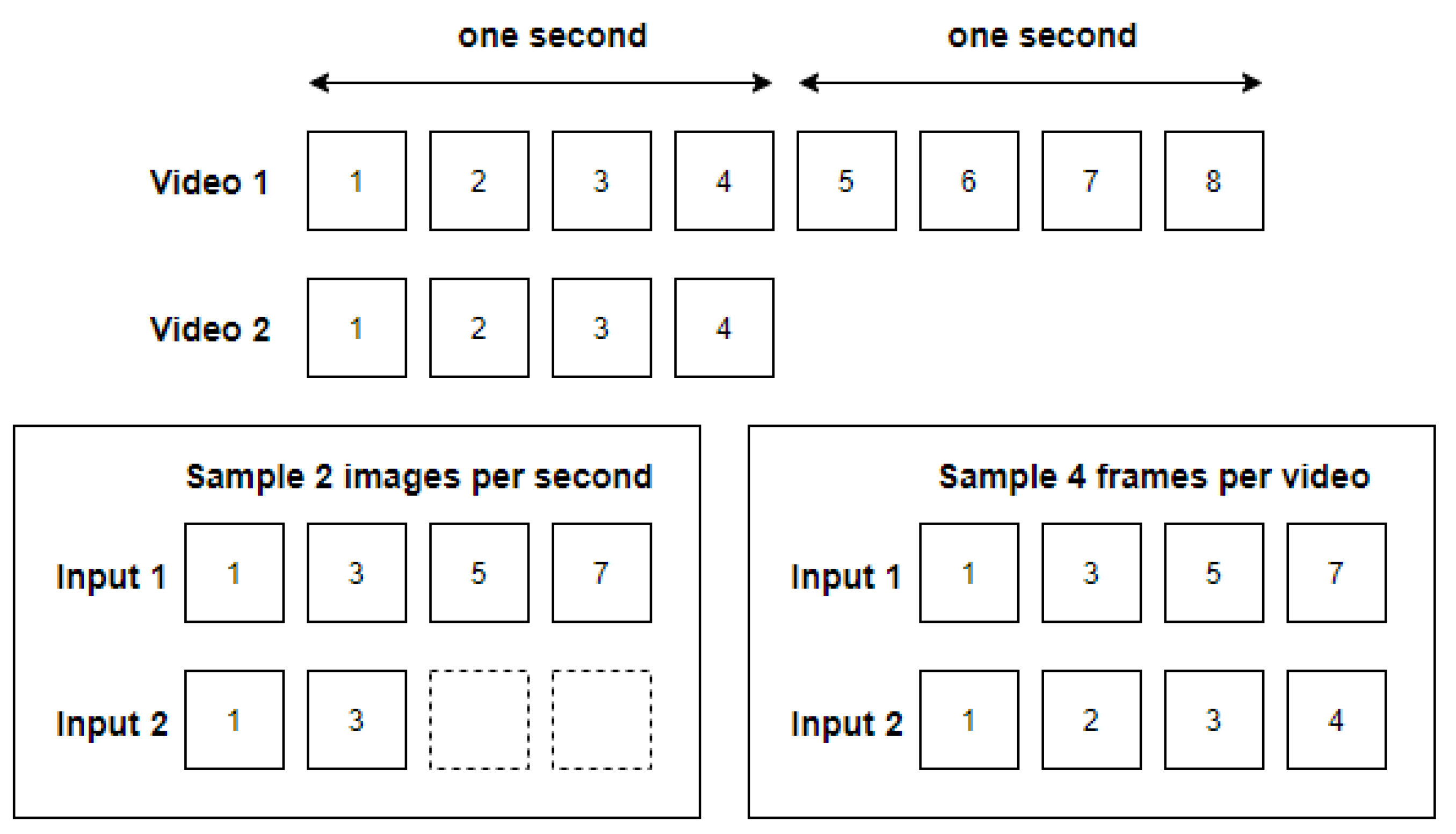
3.3.1. Frame Ensemble
3.3.2. Multi-Region Ensemble
3.3.3. Limitation
4. Experiments
4.1. Dataset
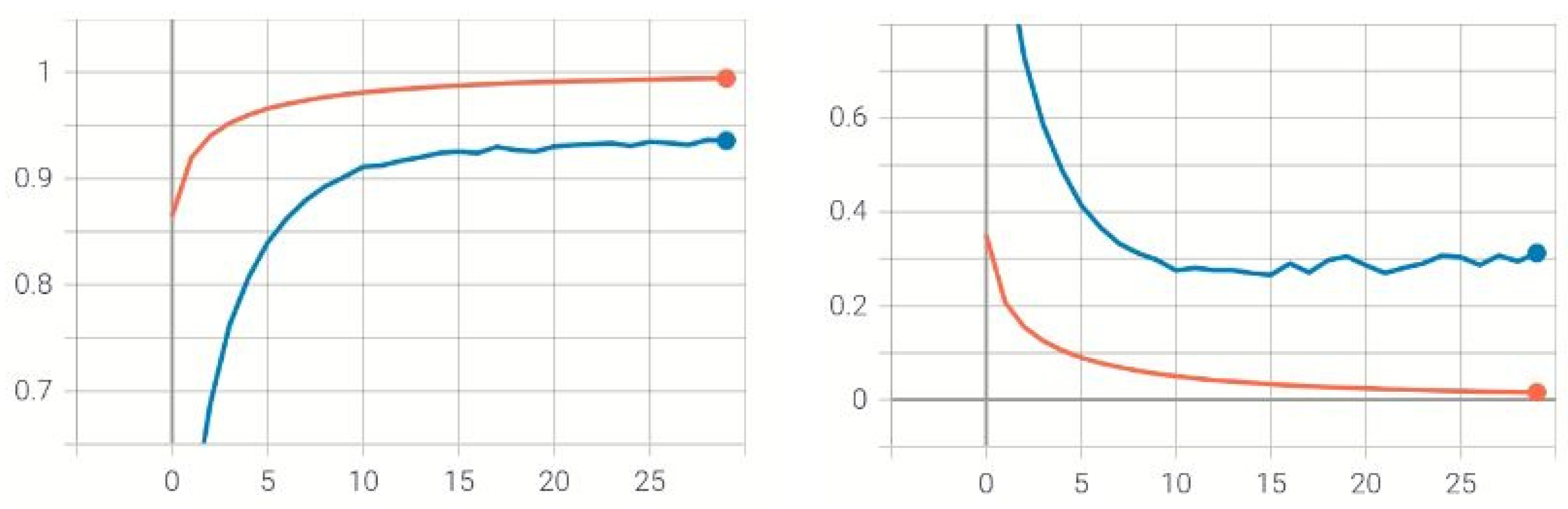
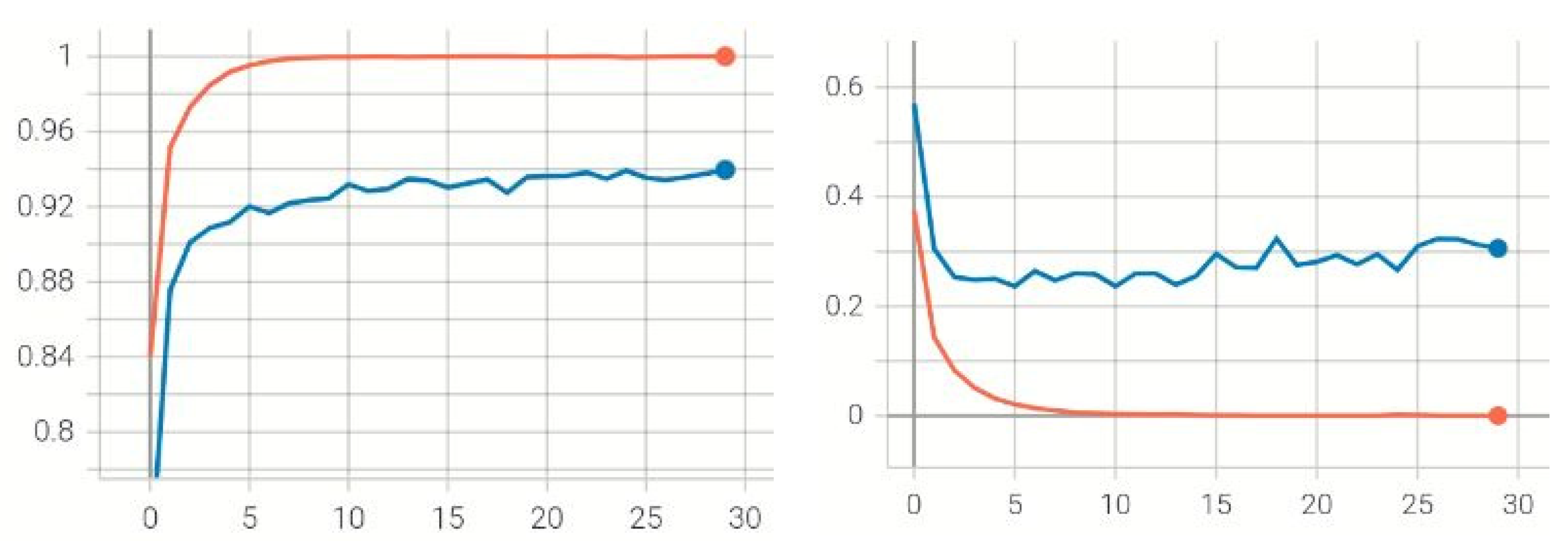
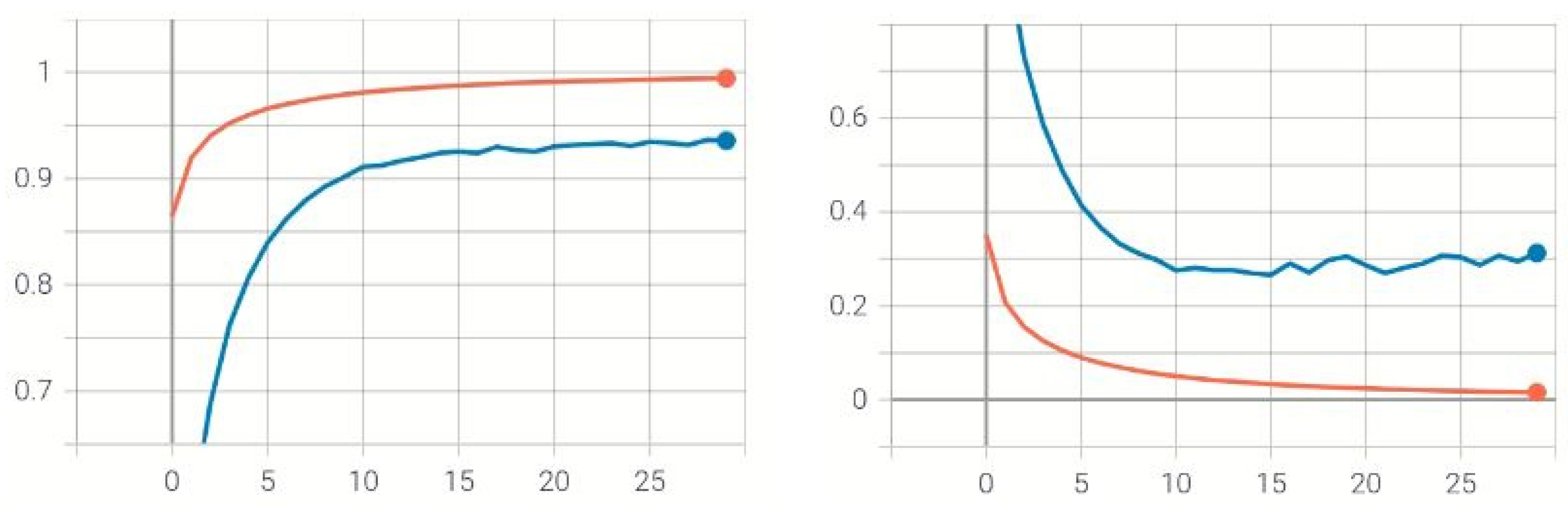
4.2. Training Evaluation
4.2.1. Image Preprocessing
4.2.2. Training Parameters
4.2.3. Evaluation Metrics
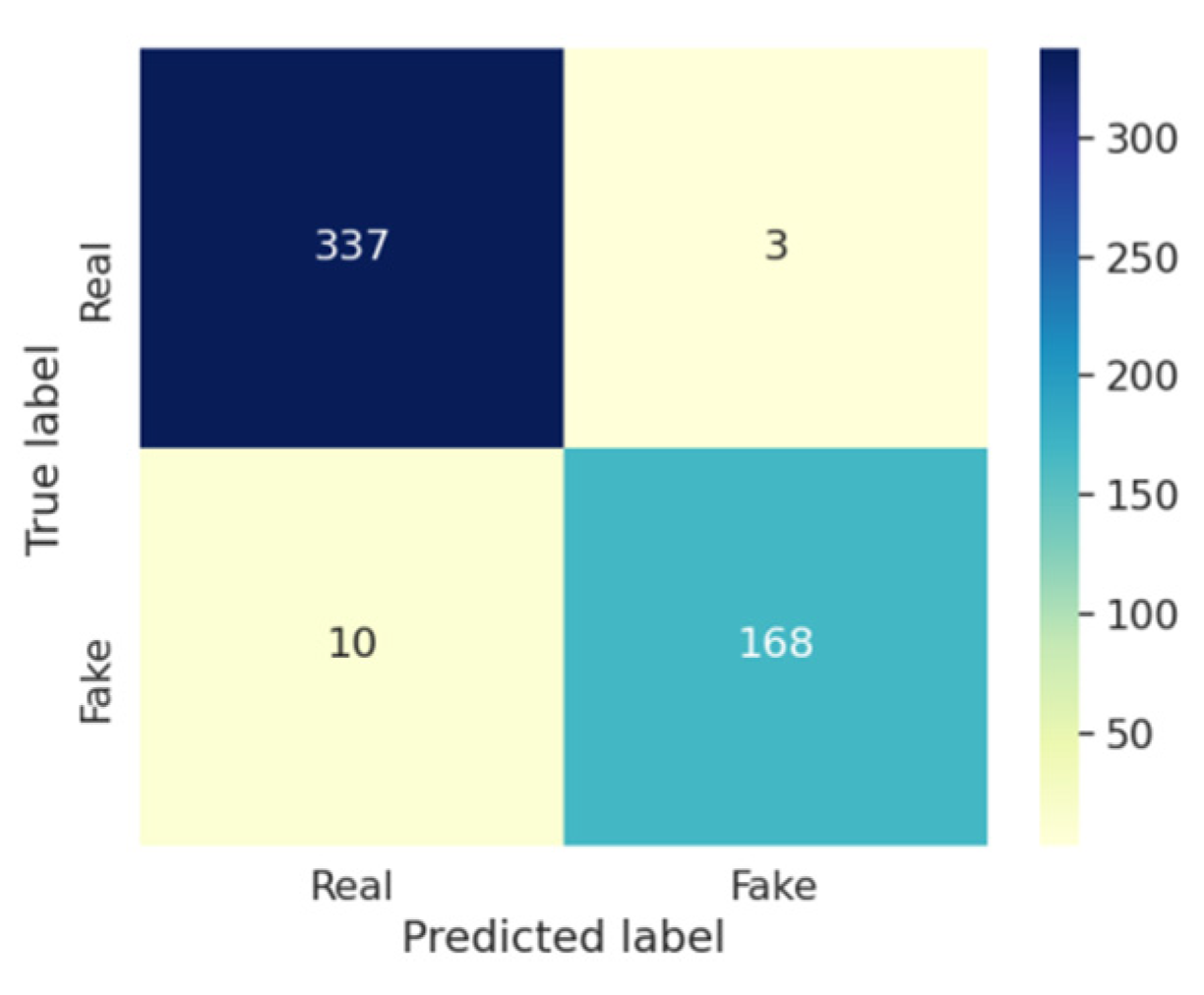
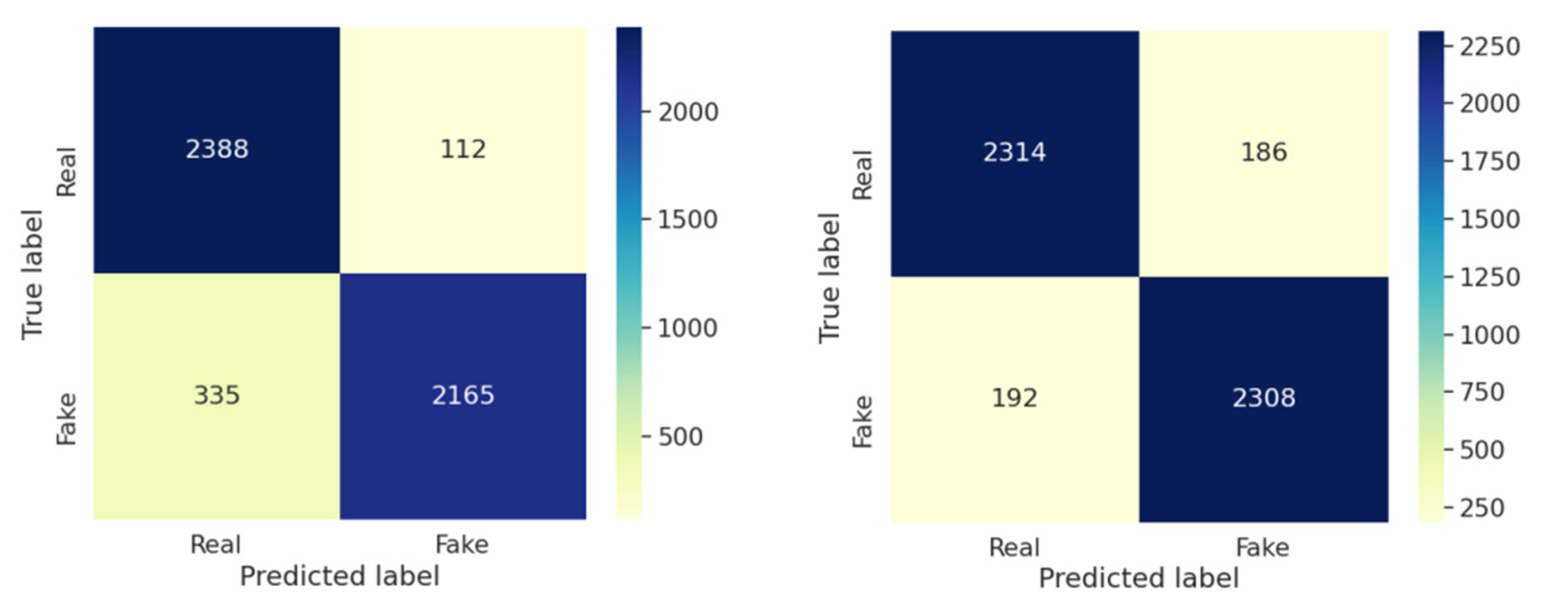
4.3. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ian, G.; Jean, P.A.; Mehdi, M.; Bing, X.; David, W.-F.; Sherjil, O.; Aaron, C.; Yoshua, B. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar]
- Ferreira, S.; Antunes, M.; Correia, M.E. Exposing Manipulated Photos and Videos in Digital Forensics Analysis. J. Imaging 2021, 7, 102. [Google Scholar] [CrossRef]
- Wodajo, D.; Atnafu, S. Deepfake Video Detection Using Convolutional Vision Transformer. arXiv 2021, arXiv:2102.11126. [Google Scholar]
- Heo, Y.J.; Choi, Y.J.; Lee, Y.W.; Kim, B.G. Deepfake Detection Scheme Based on Vision Transformer and Distillation. arXiv 2021, arXiv:2104.01353. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong-Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–23 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Non-Existent Lifelike Face of Peoples Using StyleGAN2. Available online: https://www.thispersondoesnotexist.com/ (accessed on 11 August 2021).
- StyleGAN2—Official TensorFlow Implementation. Available online: https://github.com/NVlabs/stylegan2 (accessed on 30 June 2021).
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. Rsgan: Face swapping and editing using face and hair representation in latent spaces. arXiv 2018, arXiv:1804.03447. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Natsume, R.; Yatagawa, T.; Morishima, S. Fsnet: An identity-aware generative model for image-based face swapping. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 117–132. [Google Scholar]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Advancing high fidelity identity swapping for forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5074–5083. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8188–8197. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Canton Ferrer, C. The deepfake detection challenge dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Guo, J.; Qian, Z.; Zhou, Z.; Liu, Y. Mulgan: Facial attribute editing by exemplar. arXiv 2019, arXiv:1912.12396. [Google Scholar]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5549–5558. [Google Scholar]
- Usman, B.; Dufour, N.; Saenko, K.; Bregler, C. Cross-Domain Image Manipulation by Demonstration. arXiv 2019, arXiv:1901.10024. [Google Scholar]
- Afifi, M.; Brubaker, M.A.; Brown, M.S. Histogan: Controlling colors of gan-generated and real images via color histograms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 7941–7950. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5781–5790. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 772–781. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 2185–2194. [Google Scholar]
- Mazaheri, G.; Roy-Chowdhury, A.K. Detection and Localization of Facial Expression Manipulations. arXiv 2021, arXiv:2103.08134. [Google Scholar]
- Chen, H.S.; Rouhsedaghat, M.; Ghani, H.; Hu, S.; You, S.; Kuo, C.C.J. DefakeHop: A Light-Weight High-Performance Deepfake Detector. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Das, S.; Datta, A.; Islam, M.; Amin, M. Improving DeepFake Detection Using Dynamic Face Augmentation. arXiv 2021, arXiv:2102.09603. [Google Scholar]
- Kim, D.K.; Kim, D.; Kim, K. Facial Manipulation Detection Based on the Color Distribution Analysis in Edge Region. arXiv 2021, arXiv:2102.01381. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: New York, NY, USA, 2019; pp. 8261–8265. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 June 2019; pp. 83–92. [Google Scholar]
- Kwon, H.; Kwon, O.; Yoon, H.; Park, K.W. Face Friend-Safe Adversarial Example on Face Recognition System. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Split, Croatia, 2–5 July 2019; pp. 547–551. [Google Scholar]
- Kwon, H.; Yoon, H.; Park, K.W. Multi-targeted backdoor: Indentifying backdoor attack for multiple deep neural networks. IEICE Trans. Inf. Syst. 2020, 103, 883–887. [Google Scholar] [CrossRef]
- Wu, J.; Geyer, C.; Rehg, J.M. Real-time human detection using contour cues. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 860–867. [Google Scholar]
- Goyal, K.; Agarwal, K.; Kumar, R. Face detection and tracking: Using OpenCV. In Proceedings of the 2017 International conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; Volume 1, pp. 474–478. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Selim Seferbekov. Available online: https://github.com/selimsef/dfdc_deepfake_challenge (accessed on 8 May 2021).
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–23 June 2019; pp. 5187–5196. [Google Scholar]
- Wei, H.; Laszewski, M.; Kehtarnavaz, N. Deep learning-based person detection and classification for far field video surveillance. In Proceedings of the 2018 IEEE 13th Dallas Circuits and Systems Conference (DCAS), Dallas, TX, USA, 12 November 2018; pp. 1–4. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. Gridmask data augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Singh, K.K.; Yu, H.; Sarmasi, A.; Pradeep, G.; Lee, Y.J. Hide-and-seek: A data augmentation technique for weakly-supervised localization and beyond. arXiv 2018, arXiv:1811.02545. [Google Scholar]
- Miao, C.; Chu, Q.; Li, W.; Gong, T.; Zhuang, W.; Yu, N. Towards Generalizable and Robust Face Manipulation Detection via Bag-of-local-feature. arXiv 2021, arXiv:2103.07915. [Google Scholar]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. Int. Conf. Mach. Learn. 2021, 139, 10347–10357. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–2 July 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S.C.D. A large-scale challenging dataset for DeepFake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14–19. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a capsule network to detect fake images and videos. arXiv 2019, arXiv:1910.12467. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | |||
|---|---|---|---|
| Negative | Positive | ||
| Actual | Negative | True Negative (TN) | False Positive (FP) |
| Positive | False Negative (FN) | True Positive (TP) | |
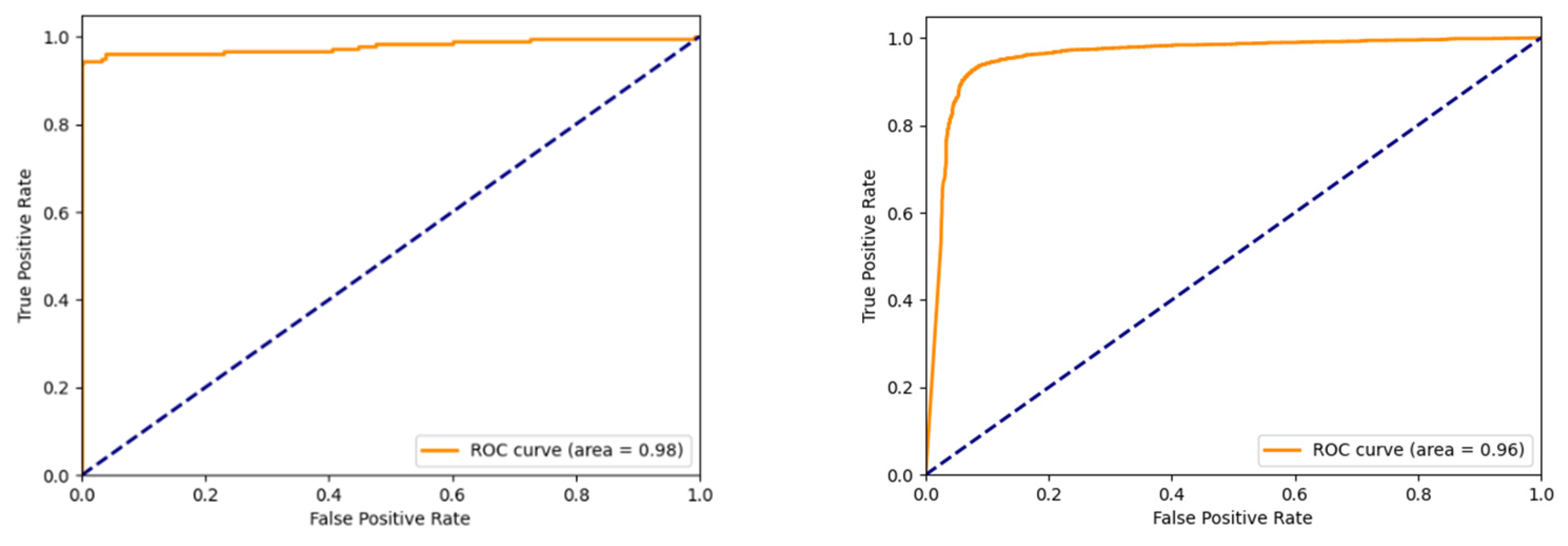
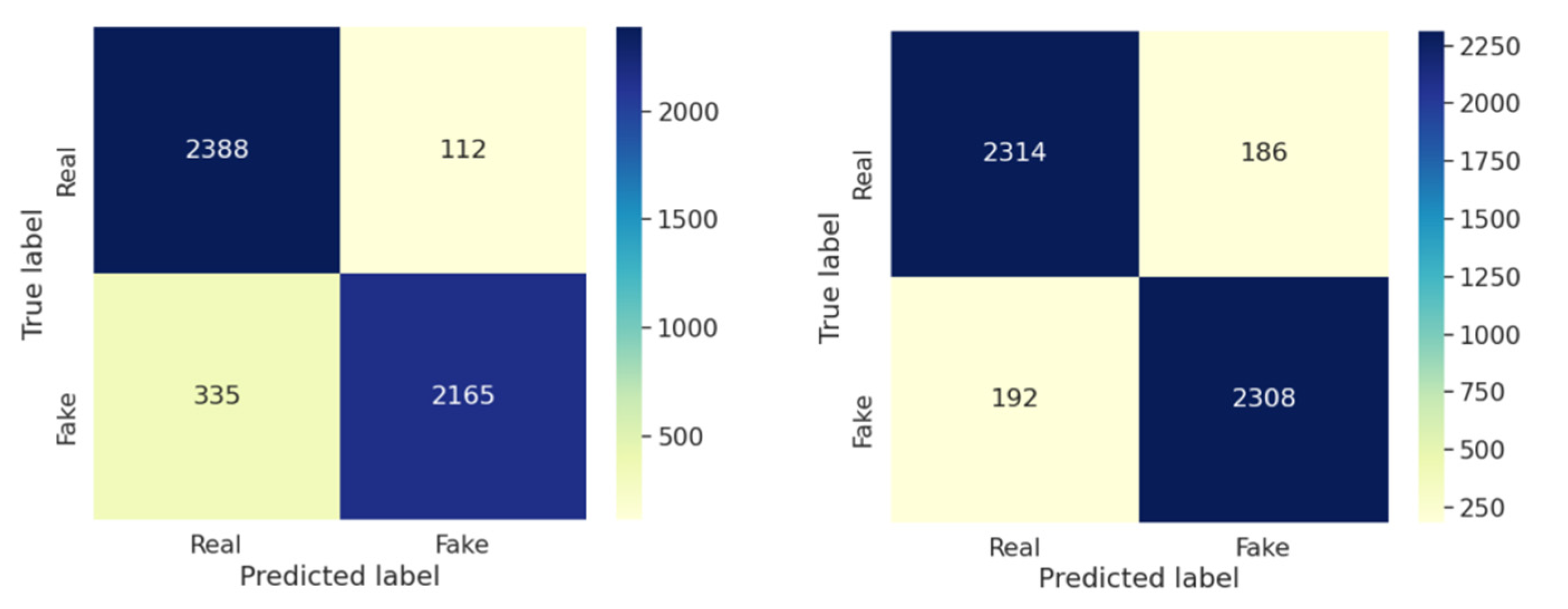
| Accuracy of Validation Set | Loss of Validation Set | |
|---|---|---|
| Celeb-DF v2 | 94.2% | 0.3 |
| DFDC | 93.75% | 0.295 |
| Celeb-DF v2 | DFDC | Number of Parameters | |
|---|---|---|---|
| Zhou et al. (2017) [5] | 53.8% | 61.4% | 24 M |
| Afchar et al. (2018) [6] | 54.8% | 75.3% | 27.9 K |
| Rossler et al. (2019) [47] | 48.2% | 49.9% | 22.8 M |
| Nguyen et al. (2019) [53] | 57.5% | 53.3% | 3.9 M |
| Li et al. (2020) [54] | 64.6% | 75.5% | - |
| Chen et al. (2021) [28] | 90.56% | - | 42.8 K |
| Heo et-al. (2021) [4] | - | 97.8% | - |
| Ours | 97.8% | 95.8% | 26 M |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Ours–Celeb-DF v2 | 0.9825 | 0.9438 | 0.9628 | 0.9749 |
| Ours–DFDC | 0.9254 | 0.9232 | 0.9243 | 0.9244 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, V.-N.; Lee, S.-H.; Le, H.-S.; Kwon, K.-R. High Performance DeepFake Video Detection on CNN-Based with Attention Target-Specific Regions and Manual Distillation Extraction. Appl. Sci. 2021, 11, 7678. https://doi.org/10.3390/app11167678
Tran V-N, Lee S-H, Le H-S, Kwon K-R. High Performance DeepFake Video Detection on CNN-Based with Attention Target-Specific Regions and Manual Distillation Extraction. Applied Sciences. 2021; 11(16):7678. https://doi.org/10.3390/app11167678
Chicago/Turabian StyleTran, Van-Nhan, Suk-Hwan Lee, Hoanh-Su Le, and Ki-Ryong Kwon. 2021. "High Performance DeepFake Video Detection on CNN-Based with Attention Target-Specific Regions and Manual Distillation Extraction" Applied Sciences 11, no. 16: 7678. https://doi.org/10.3390/app11167678
APA StyleTran, V.-N., Lee, S.-H., Le, H.-S., & Kwon, K.-R. (2021). High Performance DeepFake Video Detection on CNN-Based with Attention Target-Specific Regions and Manual Distillation Extraction. Applied Sciences, 11(16), 7678. https://doi.org/10.3390/app11167678