
The Use of Transfer Learning for Activity Recognition in Instances of Heterogeneous Sensing



Abstract
:1. Introduction
Problem Statement and Contribution
- TL-FmRADLs: a framework that integrates the T/L, AL and data fusion techniques that offers to optimise the performance of learner AR models regardless of the sensing technology source;
- InSync: an open-access dataset that consists of subjects performing activities of daily living while data are collected using three different sensing technologies to facilitate the community future research in transfer learning.
2. Preliminaries
2.1. Teacher/Learner
2.2. Active Learning
2.3. Fusion Techniques
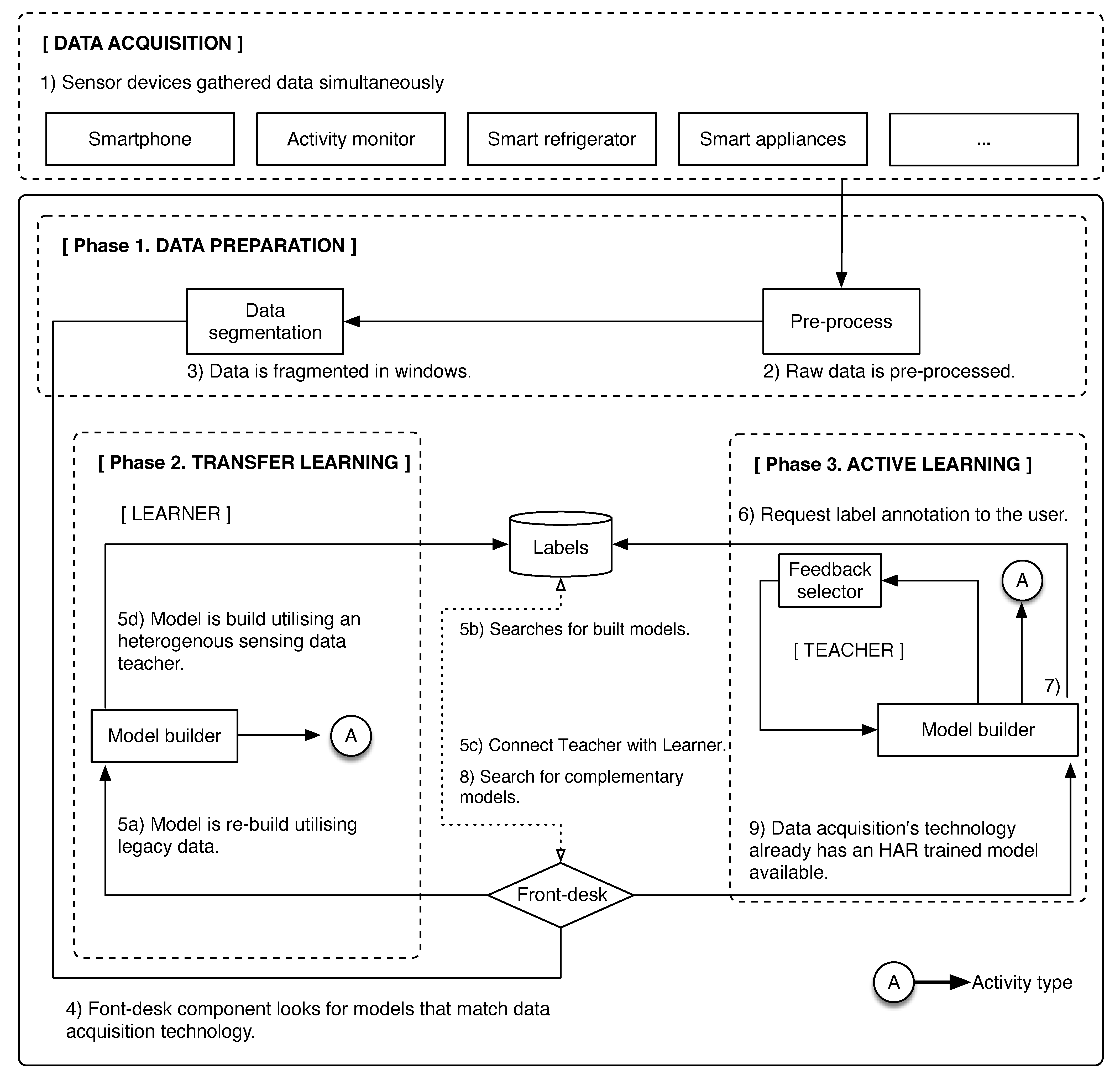
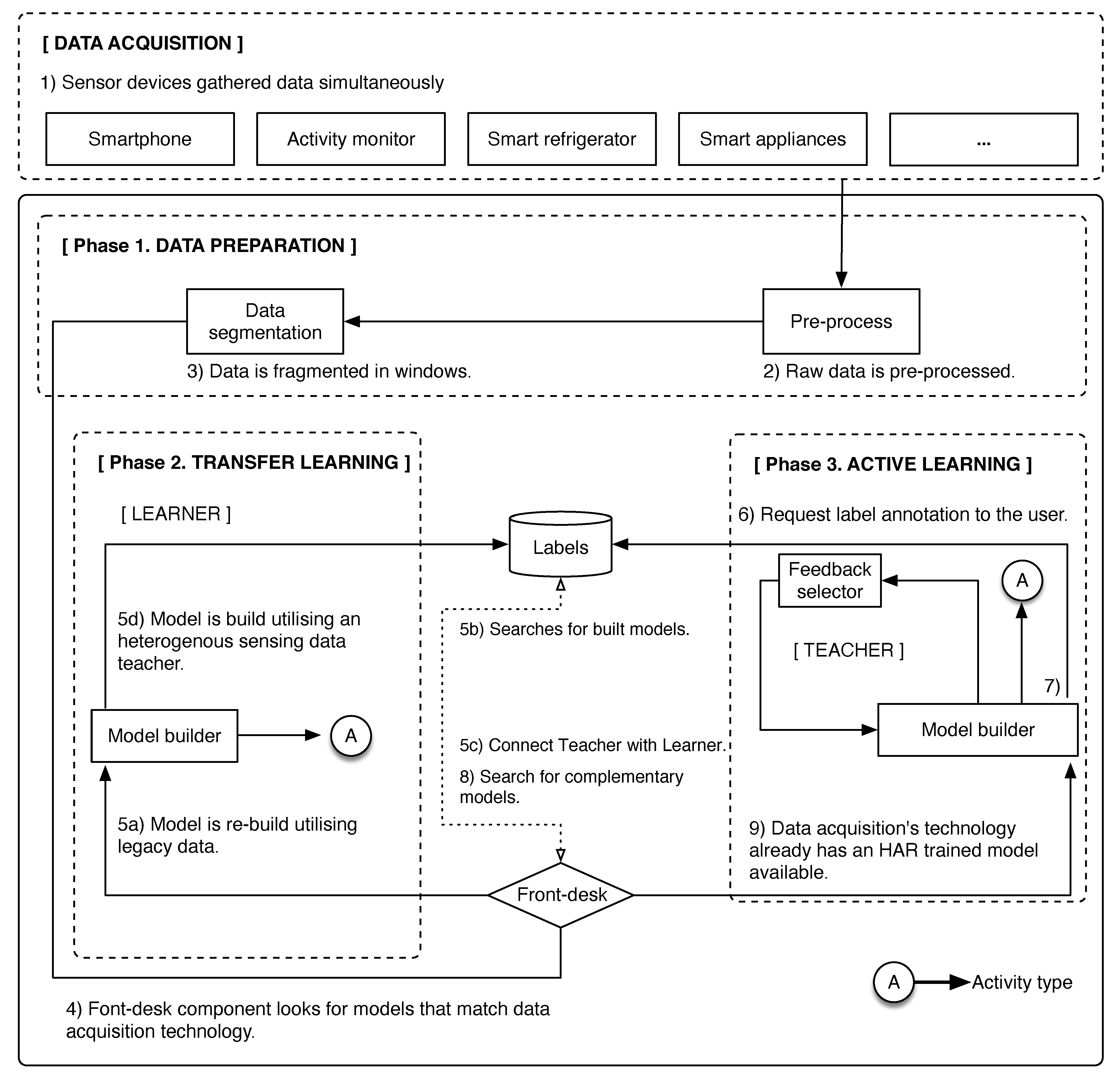
3. Transfer Learning Framework for Recognising Activities of Daily Living across Sensing Technology
3.1. Teacher/Learner Phase
Formalisation and Pseudo-Code
| Algorithm 1 Selection of the teacher models and training of the untrained learner model. Where X: unlabelled dataset, : associated trained model(s), : complementary AR model different than , : n-dimensional tensor consisting of a tandem of features and predicted labels for X, and : most informative learner model. |
| INPUT: X = A pool of unlabelled instances. A pool of AR trained models A complementary AR model different than . k = Index variable. OUTPUT: output = [data, labels]. Most informative AR model (Teacher).
|
| Algorithm 2 Validation of the AR model determined by accuracy reached. |
| INPUT: Error ratio for the AR model in index k given by (). Q = Configurable scalar set a-priori. OUTPUT: Boolean variable to determine whether a condition has been satisfied.
|
| Algorithm 3 Exploration of the classification error lost to determine the training model. |
| INPUT: A pool of unlabelled instances. A specific trained AR model with index k. OUTPUT: = Ratio of misclassified labels.
|
| Algorithm 4 Selection of hyper-parameters from a given AR model. |
| INPUT: A specific trained AR model with index k. OUTPUT: properties = An n-dimensional tensor with design hyper-parameters to build an AR model.
|
| Algorithm 5 Construction of AR models based on the data and labels given by a teacher. |
| INPUT: X = A pool of unlabelled instances. A transitional AR model to be utilised to train a learner model. OUTPUT: A n-dimensional tensor with a relationship between features and labels.
|
3.2. Active Learning Phase
Formalisation and Pseudo-Code
| Algorithm 6 Request for annotating unlabelled data to the oracle. |
| INPUT: X = A pool of unlabelled instances. OUTPUT: A tuple of unlabelled instance and label give by the oracle.
|
| Algorithm 7 AL phase as depicted along steps 7–9 from the general representation of TL-FmRADLs’ architecture at Figure 1. |
| INPUT: X = A pool of unlabelled instances. A pool of trained AR models where A complementary AR model different than . OUTPUT: [data, labels]. Most informative AR model (Teacher).
|
| Algorithm 8 Selection of complementary AR models in which technological characteristics differ from those of a given model. |
| INPUT: A single AR model. OUTPUT: A pool of AR models aiming to solve the same task as .
|
| Algorithm 9 Selection of a portion of incoming data to serve as a sample of unseen data to test the accuracy of new AR models. |
| INPUT: X = A pool of unlabelled instances. O = Configurable scalar set a-priori. OUTPUT: A sample of unlabelled instances randomly selected.
|
| Algorithm 10 Organised list of the TL-FmRADL’s algorithms in order of execution as introduced in Figure 1. |
| INPUT: Step 1. Sensor devices gather data simultaneously. OUTPUT: Activity type Phase 1. Data preparation Step 2. Raw data are pre-processed. Step 3. Data are fragmented in windows. Phase 2. Transfer Learning Step 4. Front-desk component looks for modules that match data acquisition technology. —Algorithm 1, Algorithm 2, Algorithm 3 Step 5. Model is re-build utilising legacy data. —Algorithm 4, Algorithm 5 Phase 3. Active Learning Step 6. Request label annotation to the user. —Algorithm 6 Step 7. Model is build. —Algorithm 7 Step 8. Search for complementary models. —Algorithm 7, Algorithm 8 Step 9. Data acquisition’s technology already has an HAR trained model available. —Algorithm 7, Algorithm 9 |
4. Experiment Setup
4.1. Teacher/Learner
4.2. Active Learning
5. InSync Dataset
5.1. Activities of Daily Living
- Personal hygiene: comb hair, brush teeth;
- Dressing: put joggers on and off;
- Feeding: drink water from a mug and use a spoon to eat cereal from a bowl;
- Transferring: walk.
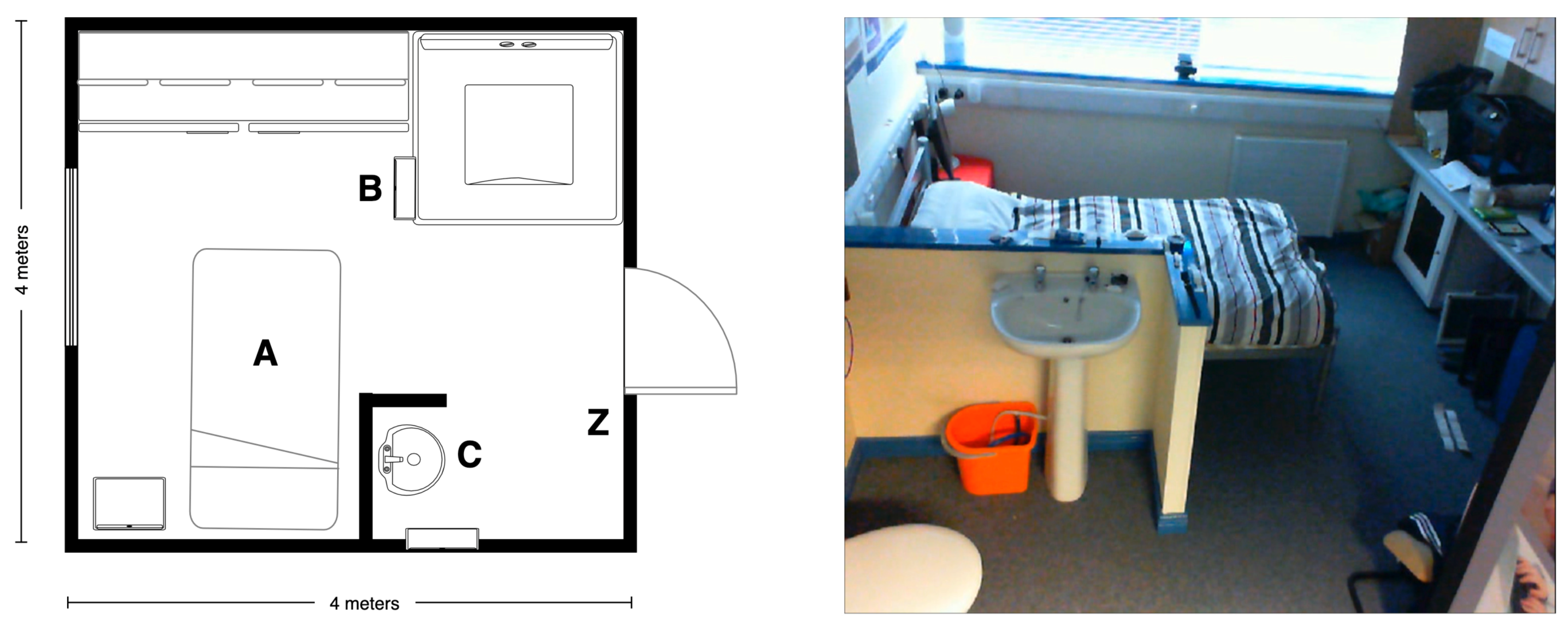
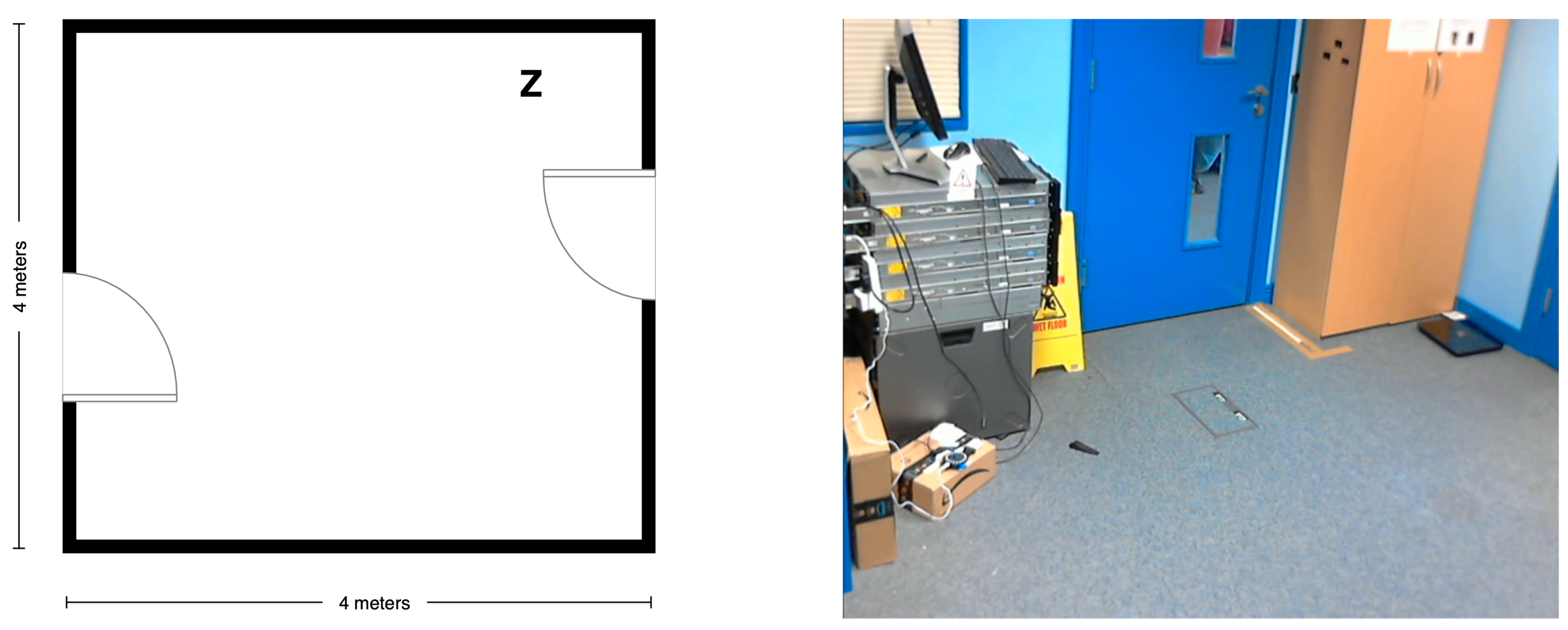
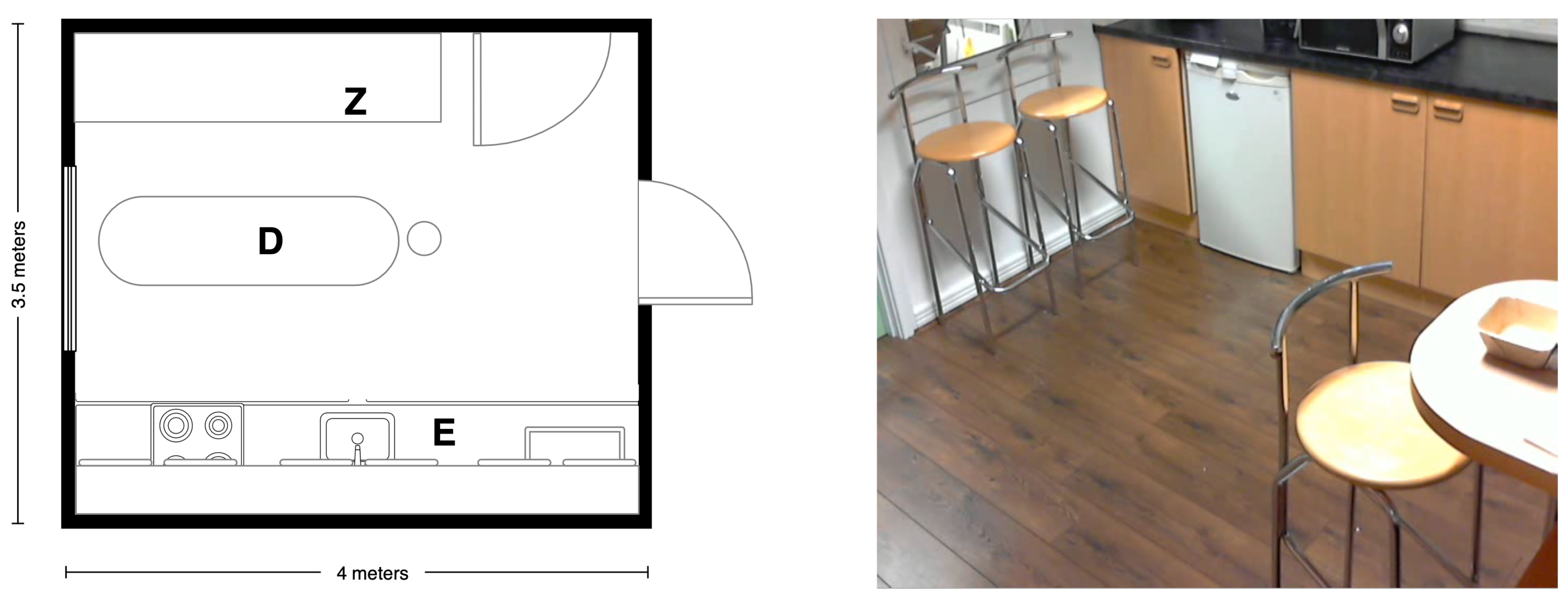
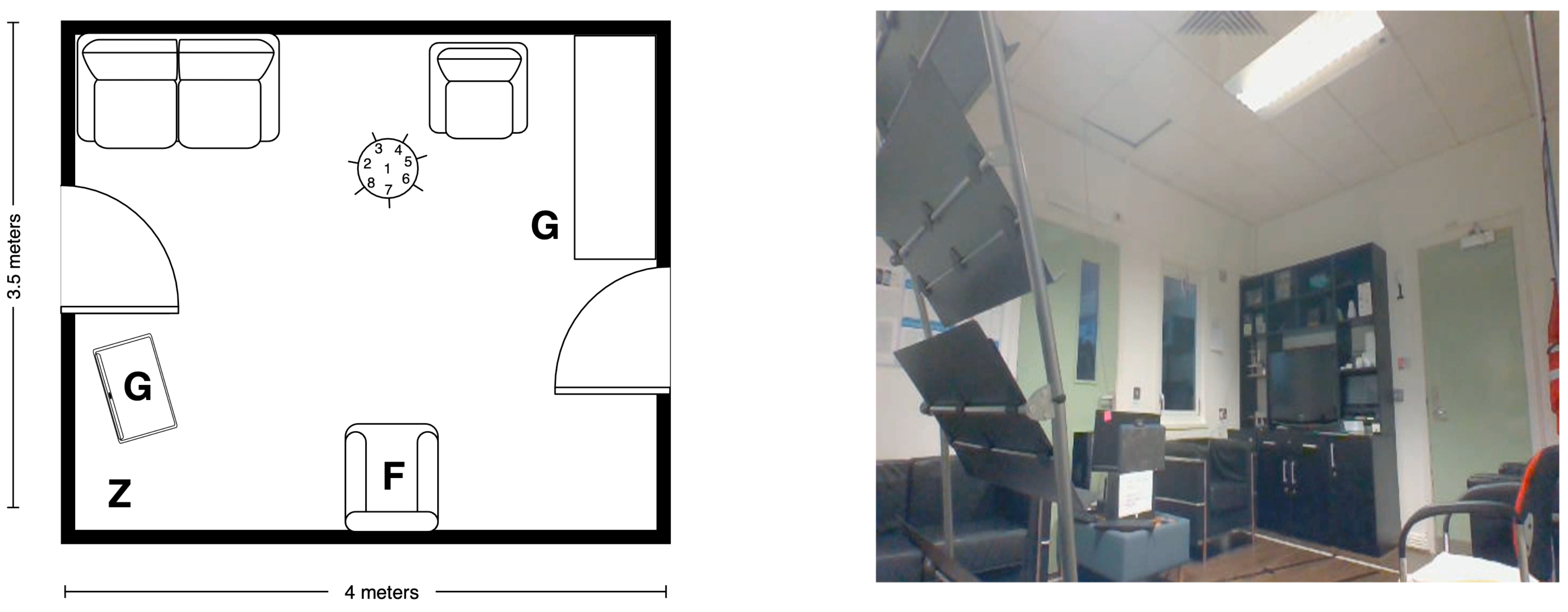
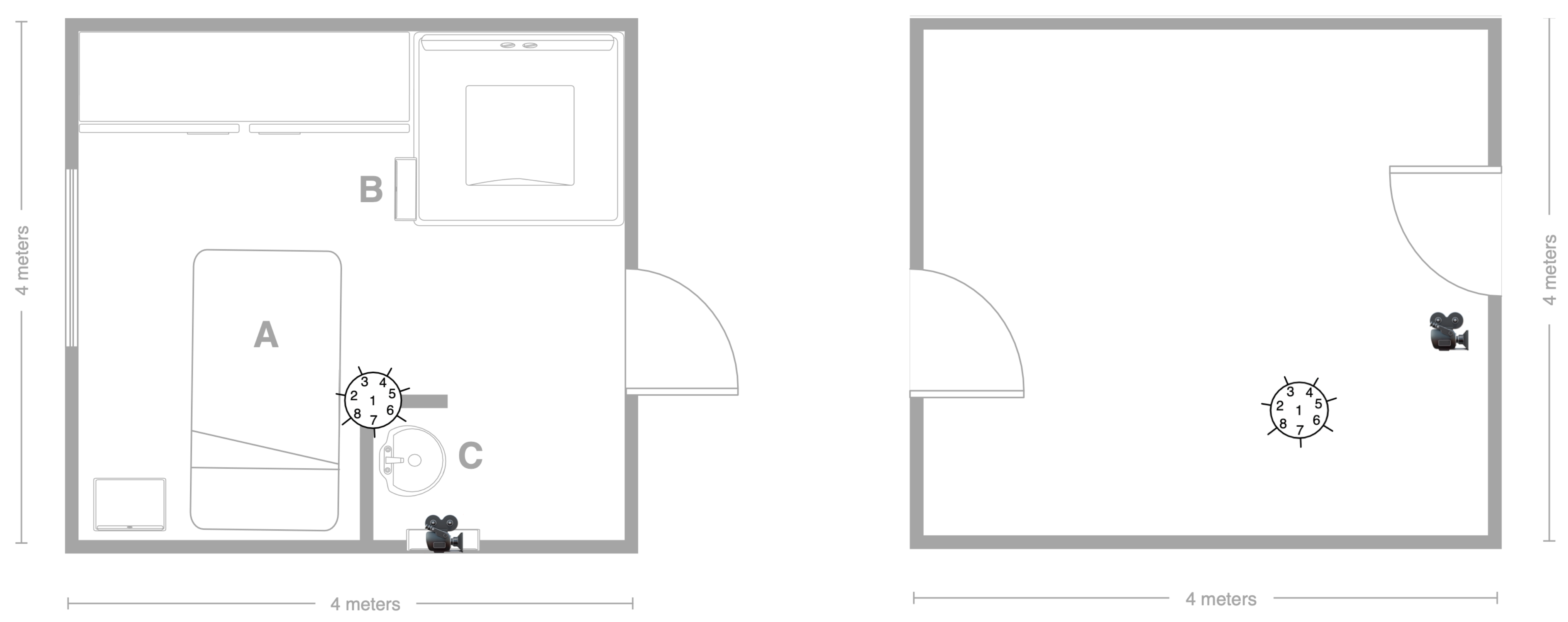
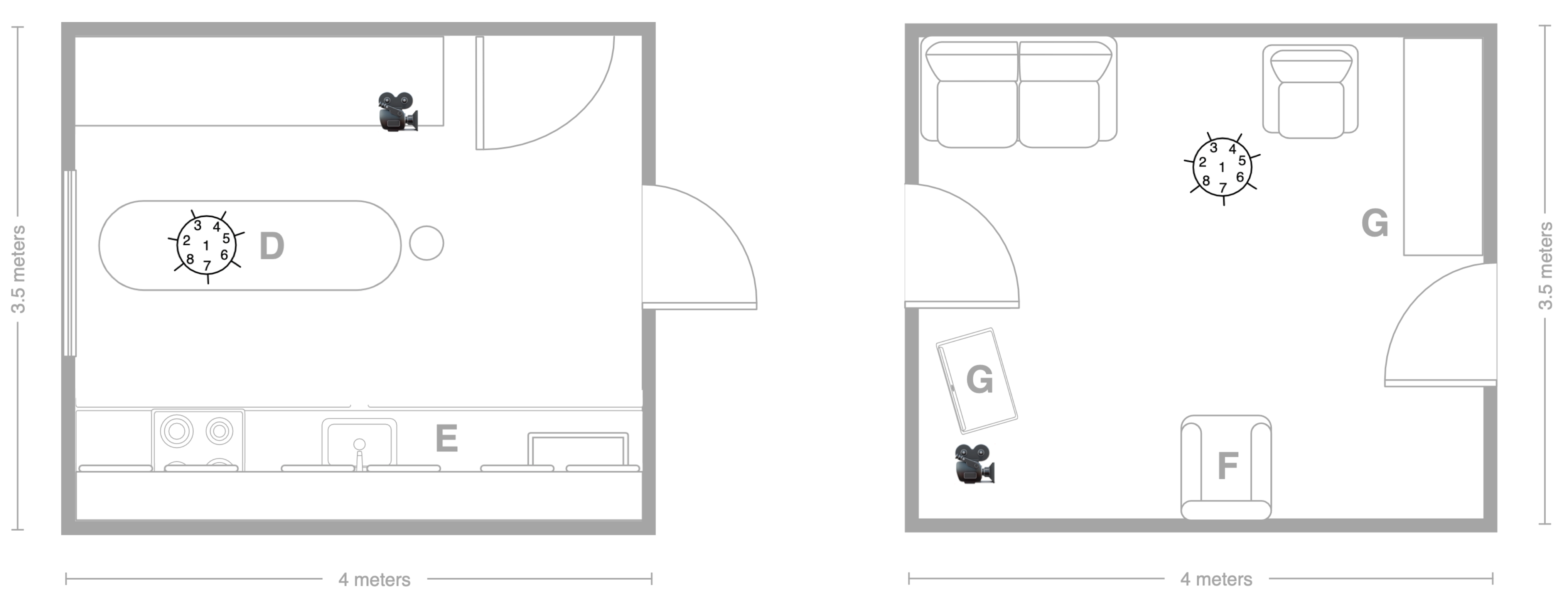
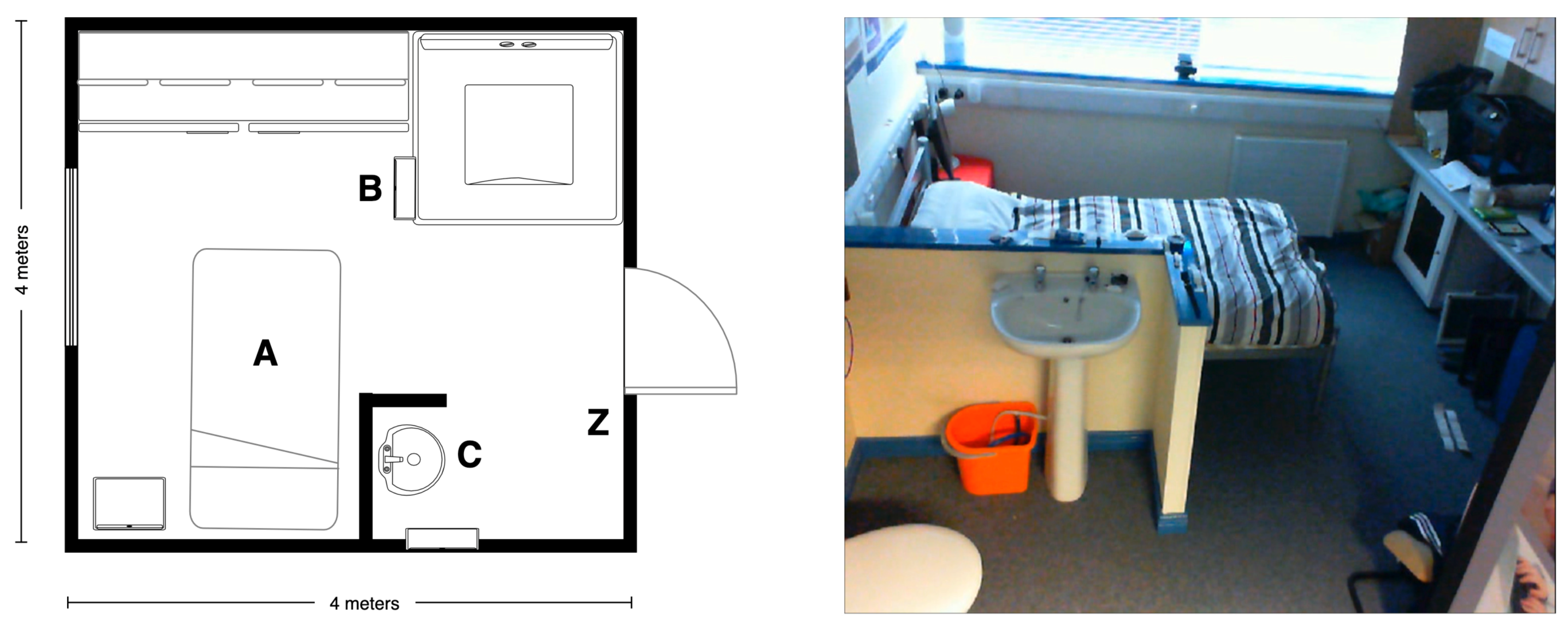
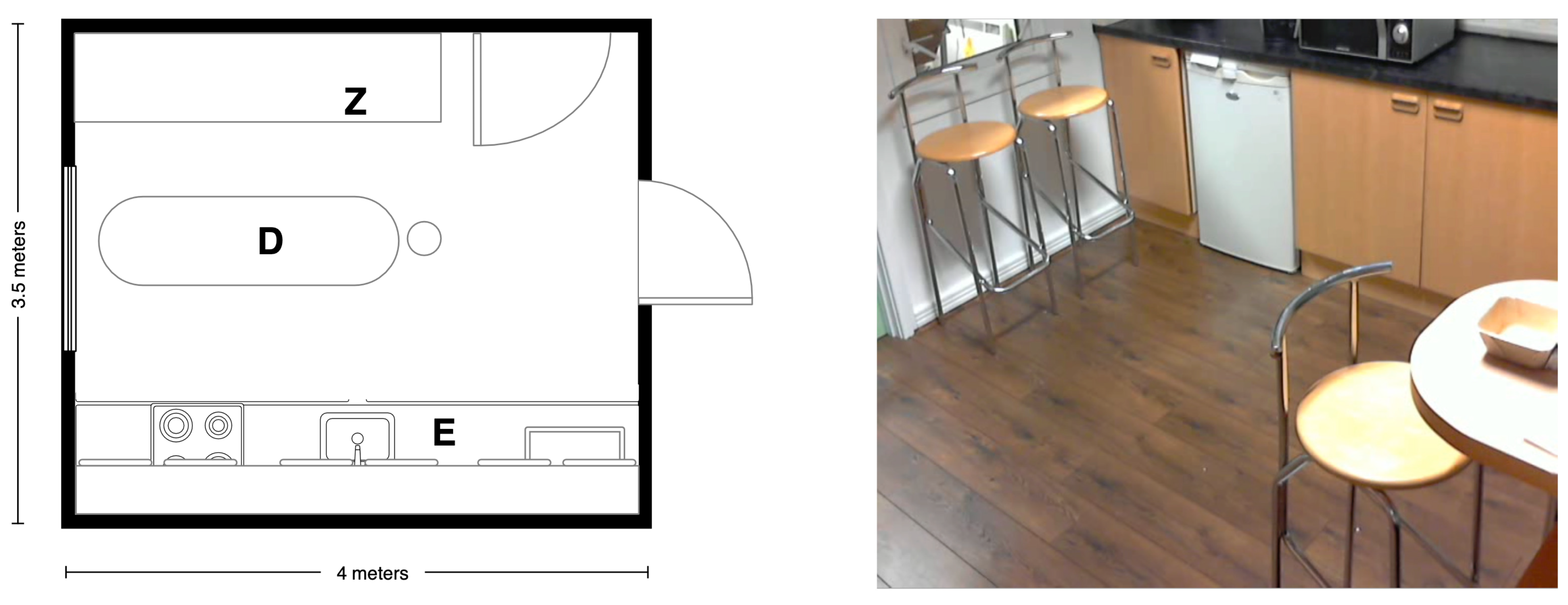
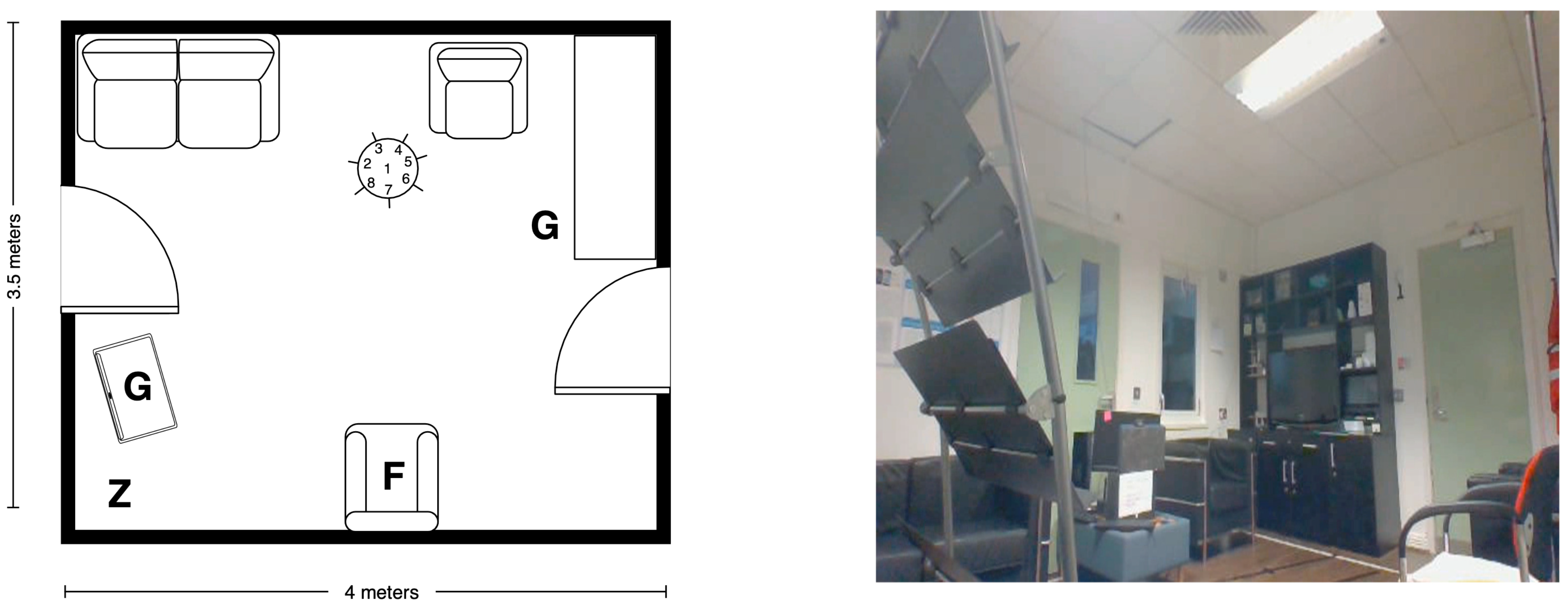
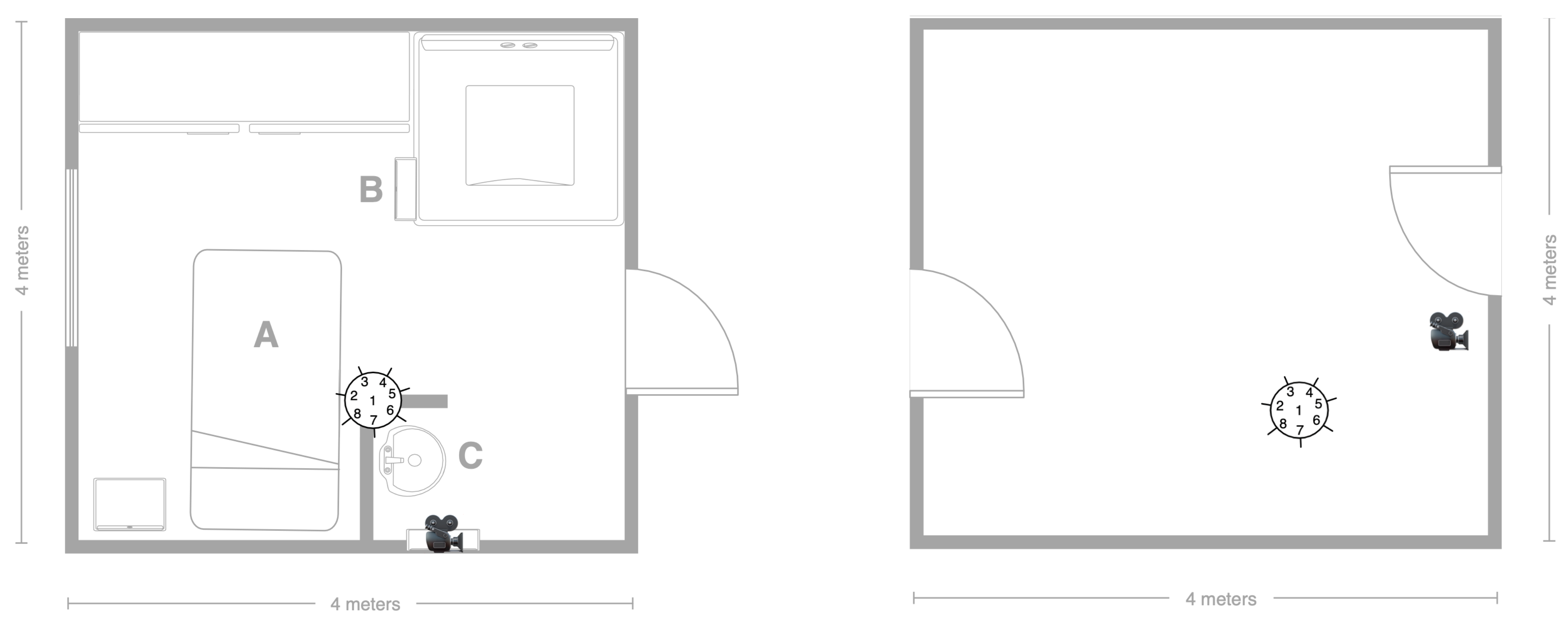
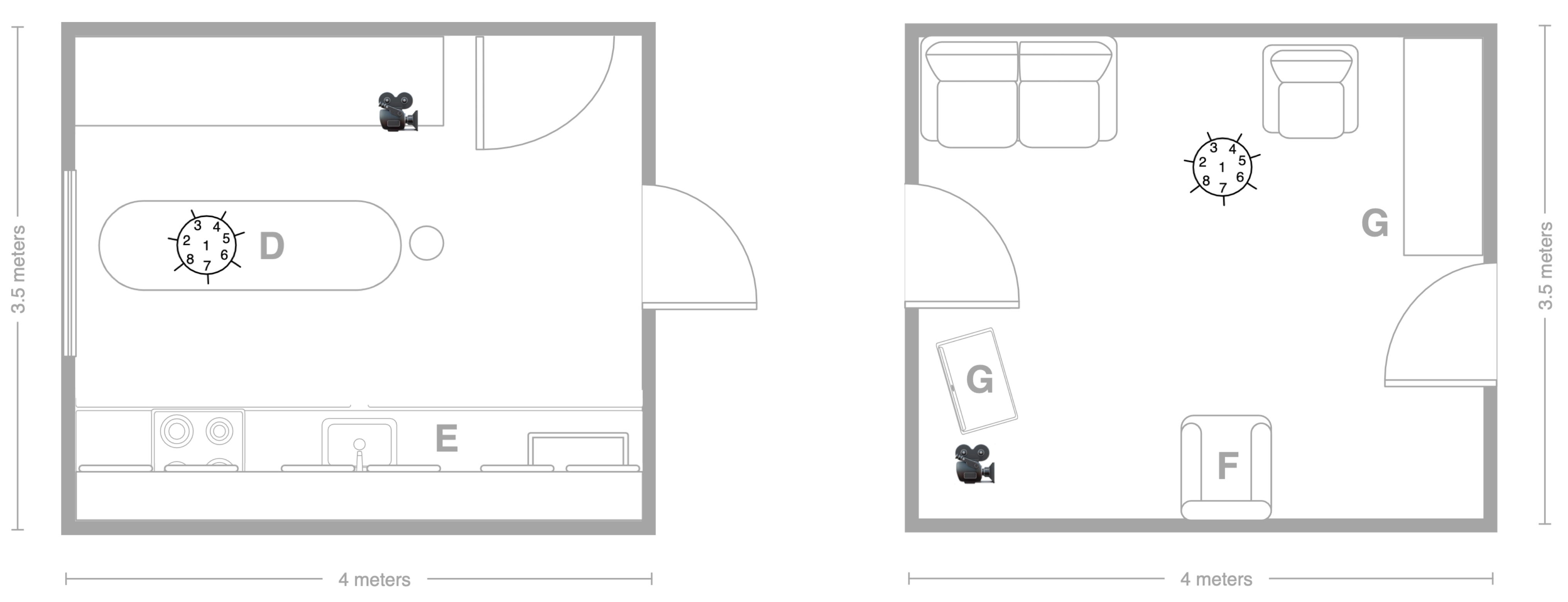
5.2. Recording Scenario
5.3. Scripted Protocol
5.4. Technology
5.4.1. Wearable Domain
5.4.2. Smart-Items Domain
5.4.3. Environmental Domain
5.5. Annotations
5.6. Subjects
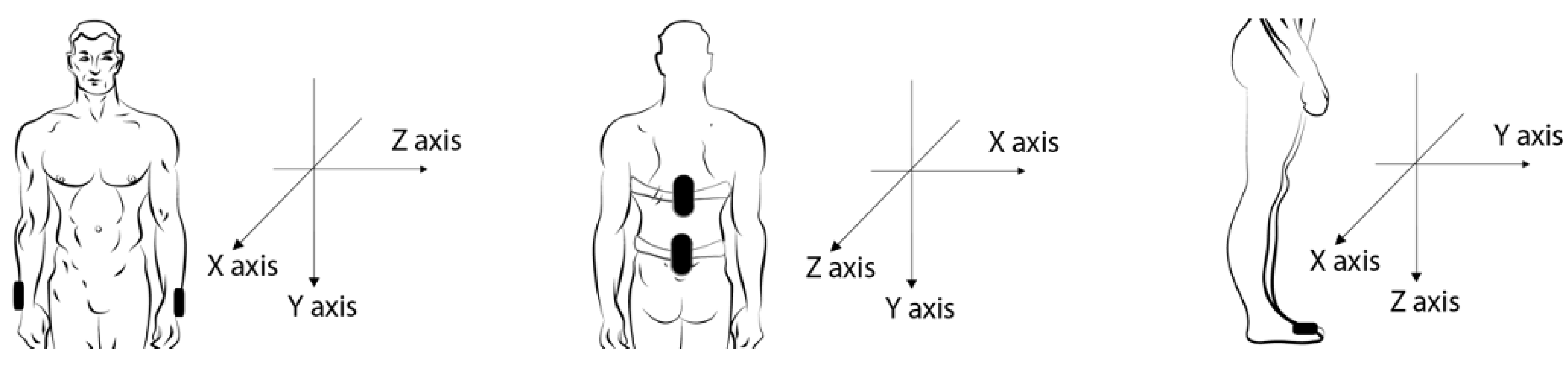
5.7. Data Collection and Preparation
6. Machine-Learning Modelling
7. Results
7.1. Baseline
7.2. Teacher/Learner
7.3. Active Learning
7.4. Comparison
- Radu and Henne [69] presented a method to transfer knowledge where the teacher consisted of mainstream sensing (video) to provide labelled data to the inertial sensors embracing the role as learners;
- Rey et al. [70] proposed a method that works by extracting 2D poses from video frames and then used a regression model to map them to inertial sensors signal;
- Hu and Yang [22] presented a paper in which they used Web knowledge as a bridge to help link the different label spaces between two smart environments. Their method consisted of an unsupervised approach where features were clustered based in their distribution; hence, even though the feature’s space were different, their distribution distance helped to build an association to transfer knowledge.
- Xing et al. [71] presented two methods (PureTransfer and Transfer+LimitedTrain) for transferring knowledge. For the purposes of this state-of-the-art comparison, only the method reporting highest performance was taken into account (i.e., Transfer+LimitedTrain). Transfer+LimitedTrain method consisted of a DNN which added higher layers to the new targeted model, where only the higher layer is retrained.
8. Discussion
9. Challenges and Research Directions
10. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hernandez, N.; Lundström, J.; Favela, J.; McChesney, I.; Arnrich, B. Literature Review on Transfer Learning for Human Activity Recognition Using Mobile and Wearable Devices with Environmental Technology. SN Comput. Sci. 2020, 1, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Deep, S.; Zheng, X. Leveraging CNN and Transfer Learning for Vision-based Human Activity Recognition. In Proceedings of the 2019 29th International Telecommunication Networks and Applications Conference (ITNAC), Auckland, New Zealand, 27–29 November 2019; pp. 1–4. [Google Scholar]
- Casserfelt, K.; Mihailescu, R. An investigation of transfer learning for deep architectures in group activity recognition. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kyoto, Japan, 11–15 March 2019; pp. 58–64. [Google Scholar]
- Alshalali, T.; Josyula, D. Fine-Tuning of Pre-Trained Deep Learning Models with Extreme Learning Machine. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 469–473. [Google Scholar]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [Green Version]
- Hachiya, H.; Sugiyama, M.; Ueda, N. Importance-weighted least-squares probabilistic classifier for covariate shift adaptation with application to human activity recognition. Neurocomputing 2012, 80, 93–101. [Google Scholar] [CrossRef]
- van Kasteren, T.; Englebienne, G.; Kröse, B. Recognizing Activities in Multiple Contexts using Transfer Learning. In Proceedings of the AAAI AI in Eldercare Symposium, Arlington, VA, USA, 7–9 November 2008. [Google Scholar]
- Cao, L.; Liu, Z.; Huang, T.S. Cross-dataset action detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Yang, Q.; Pan, S.J. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar]
- Hossain, H.M.S.; Khan, M.A.A.H.; Roy, N. DeActive: Scaling Activity Recognition with Active Deep Learning. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.A.U.; Roy, N. Unseen Activity Recognitions: A Hierarchical Active Transfer Learning Approach. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 436–446. [Google Scholar]
- Civitarese, G.; Bettini, C.; Sztyler, T.; Riboni, D.; Stuckenschmidt, H. NECTAR: Knowledge-based Collaborative Active Learning for Activity Recognition. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications, Athens, Greece, 19–23 March 2018. [Google Scholar]
- Civitarese, G.; Bettini, C. newNECTAR: Collaborative active learning for knowledge-based probabilistic activity recognition. Pervasive Mob. Comput. 2019, 56, 88–105. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chang, X.; Li, X.; Sheng, Q.Z.; Chen, W. Multi-Task Support Vector Machines for Feature Selection with Shared Knowledge Discovery. Signal Process. 2016, 120, 746–753. [Google Scholar] [CrossRef]
- Feuz, K.D.; Cook, D.J. Collegial activity learning between heterogeneous sensors. Knowl. Inf. Syst. 2017, 53, 337–364. [Google Scholar] [CrossRef] [PubMed]
- Rokni, S.A.; Ghasemzadeh, H. Autonomous Training of Activity Recognition Algorithms in Mobile Sensors: A Transfer Learning Approach in Context-Invariant Views. IEEE Trans. Mob. Comput. 2018, 17, 1764–1777. [Google Scholar] [CrossRef]
- Kurz, M.; Hölzl, G.; Ferscha, A.; Calatroni, A.; Roggen, D.; Tröster, G. Real-Time Transfer and Evaluation of Activity Recognition Capabilities in an Opportunistic System. In Proceedings of the Third International Conference on Adaptive and Self-Adaptive Systems and Applications, Rome, Italy, 25–30 September 2011. [Google Scholar]
- Roggen, D.; Förster, K.; Calatroni, A.; Tröster, G. The adARC pattern analysis architecture for adaptive human activity recognition systems. J. Ambient. Intell. Humaniz. Comput. 2013, 4, 169–186. [Google Scholar] [CrossRef] [Green Version]
- Calatroni, A.; Roggen, D.; Tröster, G. Automatic transfer of activity recognition capabilities between body-worn motion sensors: Training newcomers to recognize locomotion. In Proceedings of the Eighth International Conference on Networked Sensing Systems (INSS’11), Penghu, Taiwan, 12–15 June 2011. [Google Scholar]
- Hernandez, N.; Razzaq, M.A.; Nugent, C.; McChesney, I.; Zhang, S. Transfer Learning and Data Fusion Approach to Recognize Activities of Daily Life. In Proceedings of the 12th EAI International Conference on Pervasive Computing Technologies for Healthcare, New York, NY, USA, 21–24 May 2018. [Google Scholar]
- Hu, D.H.; Yang, Q. Transfer learning for activity recognition via sensor mapping. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Zheng, V.W.; Hu, D.H.; Yang, Q. Cross-domain activity recognition. In Proceedings of the 11th International Conference on Ubiquitous Computing, Orlando, FL, USA, 30 September–3 October 2009; pp. 61–70. [Google Scholar]
- Fallahzadeh, R.; Ghasemzadeh, H. Personalization without User Interruption: Boosting Activity Recognition in New Subjects Using Unlabeled Data. In Proceedings of the 2017 ACM/IEEE 8th International Conference on Cyber-Physical Systems (ICCPS), Hong Kong, China, 17–19 May 2017. [Google Scholar]
- Settles, B. Active Learning Literature Survey; University of Wisconsin: Madison, WI, USA, 2010. [Google Scholar]
- Wen, J.; Zhong, M.; Indulska, J. Creating general model for activity recognition with minimum labelled data. In Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 9–11 September 2015. [Google Scholar]
- Zhou, B.; Cheng, J.; Sundholm, M.; Reiss, A.; Huang, W.; Amft, O.; Lukowicz, P. Smart table surface: A novel approach to pervasive dining monitoring. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communications, St. Louis, MO, USA, 23–27 March 2015. [Google Scholar]
- Hu, L.; Chen, Y.; Wang, S.; Wang, J.; Shen, J.; Jiang, X.; Shen, Z. Less Annotation on Personalized Activity Recognition Using Context Data. In Proceedings of the 13th IEEE International Conference on Ubiquitous Intelligence and Computing, Toulouse, France, 18–21 July 2017. [Google Scholar]
- Saeedi, R.; Sasani, K.; Gebremedhin, A.H. Co-MEAL: Cost-Optimal Multi-Expert Active Learning Architecture for Mobile Health Monitoring. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Boston, MA, USA, 20–23 August 2017; ACM: New York, NY, USA, 2017; pp. 432–441. [Google Scholar]
- Dao, M.S.; Nguyen-Gia, T.A.; Mai, V.C. Daily Human Activities Recognition Using Heterogeneous Sensors from Smartphones. Procedia Comput. Sci. 2017, 111, 323–328. [Google Scholar] [CrossRef]
- Liu, J.; Li, T.; Xie, P.; Du, S.; Teng, F.; Yang, X. Urban big data fusion based on deep learning: An overview. Inf. Fusion 2020, 53, 123–133. [Google Scholar] [CrossRef]
- Meng, T.; Jing, X.; Yan, Z.; Pedrycz, W. A survey on machine learning for data fusion. Inf. Fusion 2020, 57, 115–129. [Google Scholar] [CrossRef]
- Song, H.; Thiagarajan, J.J.; Sattigeri, P.; Ramamurthy, K.N.; Spanias, A. A deep learning approach to multiple kernel fusion. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Junior, O.L.; Delgado, D.; Gonçalves, V.; Nunes, U. Trainable classifier-fusion schemes: An application to pedestrian detection. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009. [Google Scholar]
- Nweke, H.F.; Teh, Y.W.; Alo, U.R.; Mujtaba, G. Analysis of Multi-Sensor Fusion for Mobile and Wearable Sensor Based Human Activity Recognition. In Proceedings of the International Conference on Data Processing and Applications, Guangzhou, China, 12–14 May 2018; ACM: New York, NY, USA, 2018; pp. 22–26. [Google Scholar]
- Ramkumar, A.S.; Poorna, B. Ontology Based Semantic Search: An Introduction and a Survey of Current Approaches. In Proceedings of the 2014 International Conference on Intelligent Computing Applications, Coimbatore, India, 6–7 March 2014; pp. 372–376. [Google Scholar]
- Gudur, G.K.; Sundaramoorthy, P.; Umaashankar, V. ActiveHARNet: Towards on-device deep Bayesian active learning for human activity recognition. In Proceedings of the 3rd International Workshop on Deep Learning for Mobile Systems and Applications, Co-Located with MobiSys 2019, Seoul, Korea, 21 June 2019. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 3 January 2021).
- Yu, H.; Yang, X.; Zheng, S.; Sun, C. Active Learning From Imbalanced Data: A Solution of Online Weighted Extreme Learning Machine. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1088–1103. [Google Scholar] [CrossRef]
- Graf, C. The lawton instrumental activities of daily living scale. Am. J. Nurs. 2008, 108, 52–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pires, I.M.; Marques, G.; Garcia, N.M.; Pombo, N.; Flórez-Revuelta, F.; Zdravevski, E.; Spinsante, S. A Review on the Artificial Intelligence Algorithms for the Recognition of Activities of Daily Living Using Sensors in Mobile Devices. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Karvonen, N.; Kleyko, D. A Domain Knowledge-Based Solution for Human Activity Recognition: The UJA Dataset Analysis. Proceedings 2018, 2, 1261. [Google Scholar] [CrossRef] [Green Version]
- Ramasamy Ramamurthy, S.; Roy, N. Recent trends in machine learning for human activity recognition: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1254. [Google Scholar] [CrossRef]
- Sebestyen, G.; Stoica, I.; Hangan, A. Human activity recognition and monitoring for elderly people. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2016; pp. 341–347. [Google Scholar]
- Cerón, J.D.; López, D.M.; Eskofier, B.M. Human Activity Recognition Using Binary Sensors, BLE Beacons, an Intelligent Floor and Acceleration Data: A Machine Learning Approach. Proceedings 2018, 2, 1265. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–16. [Google Scholar] [CrossRef]
- Wearable Sensor Technology|Wireless IMU|ECG|EMG|GSR. Available online: http://www.shimmersensing.com/ (accessed on 3 January 2021).
- MATRIX Voice. Available online: https://matrix.one/ (accessed on 3 January 2021).
- Heimann Sensor—Leading in Thermopile Infrared Arrays. Available online: https://www.heimannsensor.com/ (accessed on 3 January 2021).
- Shahmohammadi, F.; Hosseini, A.; King, C.E.; Sarrafzadeh, M. Smartwatch Based Activity Recognition Using Active Learning. In Proceedings of the 2017 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Philadelphia, PA, USA, 17–19 July 2017; pp. 321–329. [Google Scholar]
- Alt Murphy, M.; Bergquist, F.; Hagström, B.; Hernández, N.; Johansson, D.; Ohlsson, F.; Sandsjö, L.; Wipenmyr, J.; Malmgren, K. An upper body garment with integrated sensors for people with neurological disorders: Early development and evaluation. BMC Biomed. Eng. 2019, 1, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bamberg, S.J.M.; Benbasat, A.Y.; Scarborough, D.M.; Krebs, D.E.; Paradiso, J.A. Gait Analysis Using a Shoe-Integrated Wireless Sensor System. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 413–423. [Google Scholar] [CrossRef] [Green Version]
- Lee, P.H. Data imputation for accelerometer-measured physical activity: The combined approach. Am. J. Clin. Nutr. 2013, 97, 965–971. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hegde, N.; Bries, M.; Sazonov, E. A comparative review of footwear-based wearable systems. Electronics 2016, 5, 48. [Google Scholar] [CrossRef]
- Avvenuti, M.; Carbonaro, N.; Cimino, M.G.; Cola, G.; Tognetti, A.; Vaglini, G. Smart shoe-assisted evaluation of using a single trunk/pocket-worn accelerometer to detect gait phases. Sensors 2018, 18, 3811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Kim, J. Energy-Efficient Real-Time Human Activity Recognition on Smart Mobile Devices. Mob. Inf. Syst. 2016, 2016, 2316757. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Lu, X.; Wahlstrom, J.; Markham, A.; Trigoni, N. Deep Neural Network Based Inertial Odometry Using Low-cost Inertial Measurement Units. IEEE Trans. Mob. Comput. 2019, 20, 1351–1364. [Google Scholar] [CrossRef]
- Dehghani, A.; Sarbishei, O.; Glatard, T.; Shihab, E. A quantitative comparison of overlapping and non-overlapping sliding windows for human activity recognition using inertial sensors. Sensors 2019, 19, 5026. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Xu, W.; Pang, Y.; Yang, Y.; Liu, Y. Human Activity Recognition Based On Convolutional Neural Network. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–21 August 2018; pp. 165–170. [Google Scholar]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Alemayoh, T.T.; Hoon Lee, J.; Okamoto, S. Deep Learning Based Real-time Daily Human Activity Recognition and Its Implementation in a Smartphone. In Proceedings of the 2019 16th International Conference on Ubiquitous Robots (UR), Jeju, Korea, 24–27 June 2019; pp. 179–182. [Google Scholar]
- Zou, D.; Cao, Y.; Zhou, D.; Gu, Q. Gradient descent optimizes over-parameterized deep ReLU networks. Mach. Learn. 2020, 109, 467–492. [Google Scholar] [CrossRef]
- Schmidt-Hieber, J. Nonparametric regression using deep neural networks with relu activation function. Ann. Stat. 2020, 48, 1875–1897. [Google Scholar] [CrossRef]
- Bui, H.M.; Lech, M.; Cheng, E.; Neville, K.; Burnett, I.S. Using grayscale images for object recognition with convolutional-recursive neural network. In Proceedings of the 2016 IEEE Sixth International Conference on Communications and Electronics (ICCE), Ha Long, Vietnam, 27–29 July 2016; pp. 321–325. [Google Scholar]
- Scheurer, S.; Tedesco, S.; O’Flynn, B.; Brown, K.N. Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance. Sensors 2020, 20, 3647. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P. Deep Neural Network Ensembles for Time Series Classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Radu, V.; Henne, M. Vision2Sensor: Knowledge Transfer Across Sensing Modalities for Human Activity Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Rey, V.F.; Hevesi, P.; Kovalenko, O.; Lukowicz, P. Let there be IMU data: Generating training data for wearable, motion sensor based activity recognition from monocular RGB videos. In Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 699–708. [Google Scholar]
- Xing, T.; Sandha, S.S.; Balaji, B.; Chakraborty, S.; Srivastava, M. Enabling edge devices that learn from each other: Cross modal training for activity recognition. In Proceedings of the 1st International Workshop on Edge Systems, Analytics and Networking, Munich, Germany, 10–15 June 2018; pp. 37–42. [Google Scholar]
- Nugent, C.; Cleland, I.; Santanna, A.; Espinilla, M.; Synnott, J.; Banos, O.; Lundström, J.; Hallberg, J.; Calzada, A. An Initiative for the Creation of Open Datasets Within Pervasive Healthcare. In Proceedings of the 10th EAI International Conference on Pervasive Computing Technologies for Healthcare, Cancun, Mexico, 16–19 May 2016; ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering): Brussels, Belgium, 2016; pp. 318–321. [Google Scholar]
- IEEE Computational Intelligence Society. Standard for eXtensible Event Stream (XES) for Achieving Interoperability in Event Logs and Event Streams; IEEE Computational Intelligence Society: Washington, DC, USA, 2016. [Google Scholar]
- Hernandez-Cruz, N.; McChesney, I.; Rafferty, J.; Nugent, C.; Synnott, J.; Zhang, S. Portal Design for the Open Data Initiative: A Preliminary Study. Proceedings 2018, 2, 1244. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alternative | Ratio of Labelled Data Shared by the Teacher Model: Unshared Data |
|---|---|
| T/L100 | 100:0 |
| T/L075 | 75:25 |
| T/L050 | 50:50 |
| T/L025 | 25:75 |
| Alternative | Ratio of Data to Concatenated: Data Missing Concatenation |
|---|---|
| AL100 | 100:0 |
| AL075 | 75:25 |
| AL050 | 50:50 |
| AL025 | 25:75 |
| Subject | Performed Runs | Excluded Runs | Total |
|---|---|---|---|
| S01 | 8 | 2 | 6 |
| S02 | 8 | 0 | 8 |
| S03 | 4 | 0 | 4 |
| S04 | 7 | 0 | 7 |
| S05 | 6 | 1 | 5 |
| S06 | 5 | 0 | 5 |
| S07 | 6 | 0 | 6 |
| S08 | 6 | 1 | 5 |
| S09 | 6 | 0 | 6 |
| S10 | 6 | 1 | 5 |
| Total | 62 | 5 | 57 |
| Subject | Average | Standard Deviation |
|---|---|---|
| S01 | 95.2 | 0.8 |
| S02 | 96.2 | 2.0 |
| S03 | 91.7 | 3.4 |
| S04 | 90.2 | 2.2 |
| S05 | 88.8 | 2.9 |
| S06 | 92.9 | 1.5 |
| S07 | 89.9 | 1.9 |
| S08 | 90.6 | 1.2 |
| S09 | 86.8 | 2.0 |
| S10 | 87.5 | 2.1 |
| Subject | Average | Standard Deviation |
|---|---|---|
| S01 | 78.9 | 0.6 |
| S02 | 76.7 | 2.5 |
| S03 | 62.7 | 0.7 |
| S04 | 57.0 | 7.4 |
| S05 | 71.3 | 0.4 |
| S06 | 70.1 | 0.6 |
| S07 | 62.8 | 5.6 |
| S08 | 67.2 | 0.4 |
| S09 | 69.0 | 4.0 |
| S10 | 69.0 | 0.5 |
| Subject | Average | Standard Deviation |
|---|---|---|
| S01 | 99.0 | 0.9 |
| S02 | 98.9 | 0.4 |
| S03 | 99.0 | 0.6 |
| S04 | 95.4 | 0.7 |
| S05 | 92.5 | 0.6 |
| S06 | 97.9 | 0.5 |
| S07 | 94.4 | 1.0 |
| S08 | 93.5 | 0.8 |
| S09 | 91.4 | 0.5 |
| S10 | 90.9 | 1.1 |
| Subjects | Inertial-Learner Baseline | T/L100 | T/L075 | T/L050 | T/L025 |
|---|---|---|---|---|---|
| S01 | 95.2 | 95.9 | 95.9 | 95.4 | 95.5 |
| S02 | 96.2 | 99.1 | 99.0 | 99.0 | 99.0 |
| S03 | 91.7 | 93.2 | 93.2 | 93.1 | 92.9 |
| S04 | 90.2 | 91.4 | 92.2 | 92.2 | 92.3 |
| S05 | 88.8 | 84.6 | 91.6 | 89.4 | 86.1 |
| S06 | 92.9 | 93.5 | 94.7 | 94.6 | 95.0 |
| S07 | 89.9 | 88.7 | 92.8 | 92.8 | 92.3 |
| S08 | 90.6 | 92.8 | 92.1 | 92.5 | 92.8 |
| S09 | 86.8 | 89.0 | 91.7 | 91.8 | 91.5 |
| S10 | 87.5 | 83.8 | 90.2 | 89.5 | 86.2 |
| Average | 91.0 | 91.2 | 93.4 | 93.0 | 92.3 |
| Subjects | Audio-Learner Baseline | T/L100 | T/L075 | T/L050 | T/L025 |
|---|---|---|---|---|---|
| S01 | 78.9 | 78.9 | 79.0 | 78.6 | 79.3 |
| S02 | 76.7 | 77.0 | 77.8 | 77.6 | 77.7 |
| S03 | 62.7 | 65.2 | 65.7 | 65.6 | 65.8 |
| S04 | 57.0 | 68.5 | 68.9 | 68.7 | 68.6 |
| S05 | 71.3 | 67.7 | 73.0 | 70.1 | 68.3 |
| S06 | 70.1 | 70.8 | 71.8 | 70.7 | 70.7 |
| S07 | 62.8 | 71.3 | 73.3 | 72.8 | 72.0 |
| S08 | 67.2 | 68.0 | 68.9 | 67.8 | 68.0 |
| S09 | 69.0 | 71.0 | 72.9 | 73.0 | 72.3 |
| S10 | 69.0 | 65.3 | 70.9 | 70.1 | 68.3 |
| Average | 68.5 | 70.4 | 72.2 | 71.5 | 71.1 |
| Subjects | Inertial-Learner Baseline | AL100 | AL075 | AL050 | AL025 |
|---|---|---|---|---|---|
| S01 | 95.2 | 97.2 | 97.0 | 93.1 | 91.0 |
| S02 | 96.2 | 97.0 | 98.6 | 98.5 | 96.3 |
| S03 | 91.7 | 97.2 | 93.4 | 92.8 | 91.6 |
| S04 | 90.2 | 98.6 | 96.7 | 94.3 | 91.1 |
| S05 | 88.8 | 96.6 | 92.6 | 89.3 | 88.6 |
| S06 | 92.9 | 98.4 | 97.0 | 95.0 | 93.7 |
| S07 | 89.9 | 93.2 | 92.6 | 91.7 | 90.8 |
| S08 | 90.6 | 92.0 | 91.5 | 90.1 | 88.8 |
| S09 | 86.8 | 96.1 | 95.6 | 89.3 | 86.7 |
| S10 | 87.5 | 94.4 | 94.8 | 90.8 | 88.9 |
| Average | 91.0 | 96.1 | 95.0 | 92.5 | 90.8 |
| Subjects | Audio-Learner Baseline | AL100 | AL075 | AL050 | AL025 |
|---|---|---|---|---|---|
| S01 | 78.9 | 95.2 | 87.6 | 80.7 | 74.3 |
| S02 | 76.7 | 93.5 | 88.1 | 79.2 | 75.5 |
| S03 | 62.7 | 94.6 | 86.1 | 77.7 | 72.0 |
| S04 | 57.0 | 96.5 | 86.8 | 79.5 | 73.7 |
| S05 | 71.3 | 95.5 | 87.1 | 80.5 | 73.8 |
| S06 | 70.1 | 96.4 | 89.2 | 81.2 | 73.5 |
| S07 | 62.8 | 93.4 | 86.1 | 78.8 | 75.5 |
| S08 | 67.2 | 89.2 | 84.2 | 77.8 | 70.7 |
| S09 | 69.0 | 93.0 | 87.4 | 79.8 | 73.2 |
| S10 | 69.0 | 93.1 | 87.9 | 79.9 | 71.5 |
| Average | 68.5 | 94.0 | 87.0 | 79.5 | 73.4 |
| Subjects | Inertial-Learner | Image-Teacher | Inertial-Learner (Fusion Stage) |
|---|---|---|---|
| S01 | 95.2 | 99.0 | 97.2 |
| S02 | 96.2 | 98.9 | 97.0 |
| S03 | 91.7 | 99.0 | 97.2 |
| S04 | 90.2 | 95.4 | 98.6 |
| S05 | 88.8 | 92.5 | 96.6 |
| S06 | 92.9 | 97.9 | 98.4 |
| S07 | 89.9 | 94.4 | 93.2 |
| S08 | 90.6 | 93.5 | 92.0 |
| S09 | 86.8 | 91.4 | 96.1 |
| S10 | 87.5 | 90.9 | 94.4 |
| Average | 91.0 | 95.3 | 96.1 |
| Subjects | Audio-Learner | Image-Teacher | Audio-Learner (Fusion Stage) |
|---|---|---|---|
| S01 | 78.9 | 99.0 | 95.2 |
| S02 | 76.7 | 98.9 | 93.5 |
| S03 | 62.7 | 99.0 | 94.6 |
| S04 | 57.0 | 95.4 | 96.5 |
| S05 | 71.3 | 92.5 | 95.5 |
| S06 | 70.1 | 97.9 | 96.4 |
| S07 | 62.8 | 94.4 | 93.4 |
| S08 | 67.2 | 93.5 | 89.2 |
| S09 | 69.0 | 91.4 | 93.0 |
| S10 | 69.0 | 90.9 | 93.1 |
| Average | 68.5 | 95.3 | 94.0 |
| Research Method | Teacher | Learner | Baseline | Achieved | Improvement |
|---|---|---|---|---|---|
| Radu and Henne [69] | Image | Inertial | 95.4 | 97.1 | 1.7 |
| Rey et al. [70] | Image | Inertial | 85.0 | 90.0 | 5.0 |
| Hu and Yang [22] | CPP | CIA | 47.3 | 59.8 | 12.5 |
| Hu and Yang [22] | CIA | CPP | 42.8 | 61.2 | 18.4 |
| Xing et al. [71] | Inertial | Image | 72.3 | 75.1 | 2.9 |
| Xing et al. [71] | Inertial | Audio | 84.3 | 87.8 | 3.5 |
| Xing et al. [71] | Image | Audio | 84.1 | 90.4 | 6.2 |
| Xing et al. [71] | Image | Inertial | 70.7 | 94.4 | 23.6 |
| TL-FmRADLs | Image | Inertial | 91.0 | 96.1 | 5.1 |
| TL-FmRADLs | Image | Audio | 68.5 | 94.0 | 25.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Cruz, N.; Nugent, C.; Zhang, S.; McChesney, I. The Use of Transfer Learning for Activity Recognition in Instances of Heterogeneous Sensing. Appl. Sci. 2021, 11, 7660. https://doi.org/10.3390/app11167660
Hernandez-Cruz N, Nugent C, Zhang S, McChesney I. The Use of Transfer Learning for Activity Recognition in Instances of Heterogeneous Sensing. Applied Sciences. 2021; 11(16):7660. https://doi.org/10.3390/app11167660
Chicago/Turabian StyleHernandez-Cruz, Netzahualcoyotl, Chris Nugent, Shuai Zhang, and Ian McChesney. 2021. "The Use of Transfer Learning for Activity Recognition in Instances of Heterogeneous Sensing" Applied Sciences 11, no. 16: 7660. https://doi.org/10.3390/app11167660
APA StyleHernandez-Cruz, N., Nugent, C., Zhang, S., & McChesney, I. (2021). The Use of Transfer Learning for Activity Recognition in Instances of Heterogeneous Sensing. Applied Sciences, 11(16), 7660. https://doi.org/10.3390/app11167660