
Automating Visual Blockage Classification of Culverts with Deep Learning



Abstract
:1. Introduction
- Developed a culvert blockage visual dataset using multiple sources, including real culvert images from WCC records, simulated lab-scale hydrology experiments and computer-generated synthetic images;
- Explored the potential of existing deep learning CNN and conventional machine learning models for classifying blocked culvert images as a potential solution towards automating the manual visual classification process of culverts for making blockage maintenance-related decisions;
- Highlighted the challenges of culvert blockage visual dataset and inferred important insights to help improving the classification performance in future;
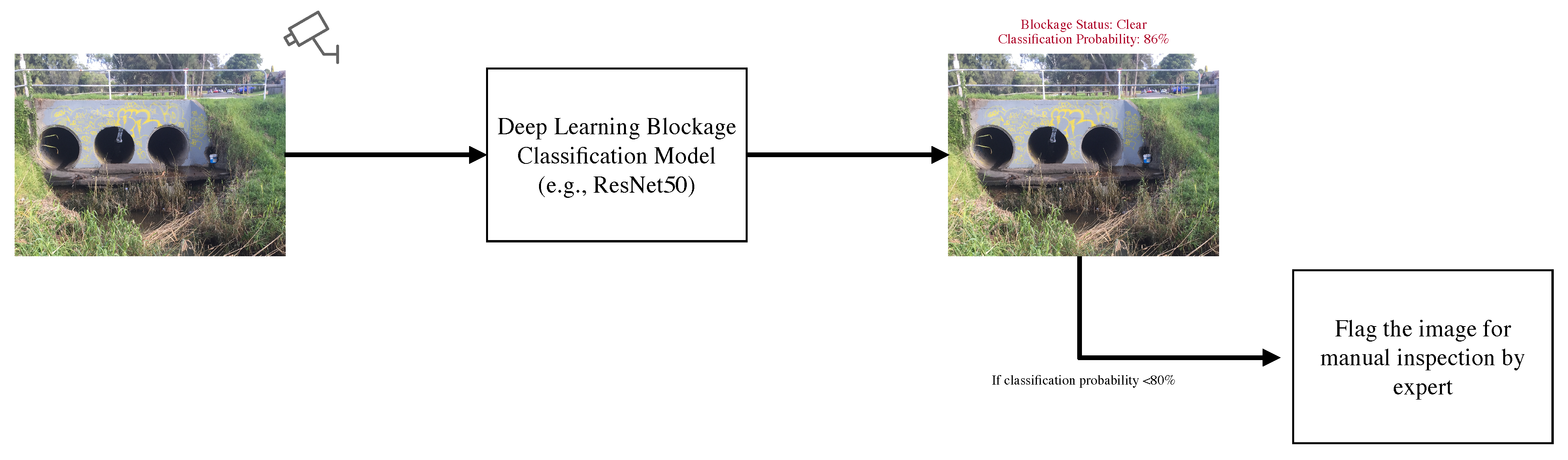
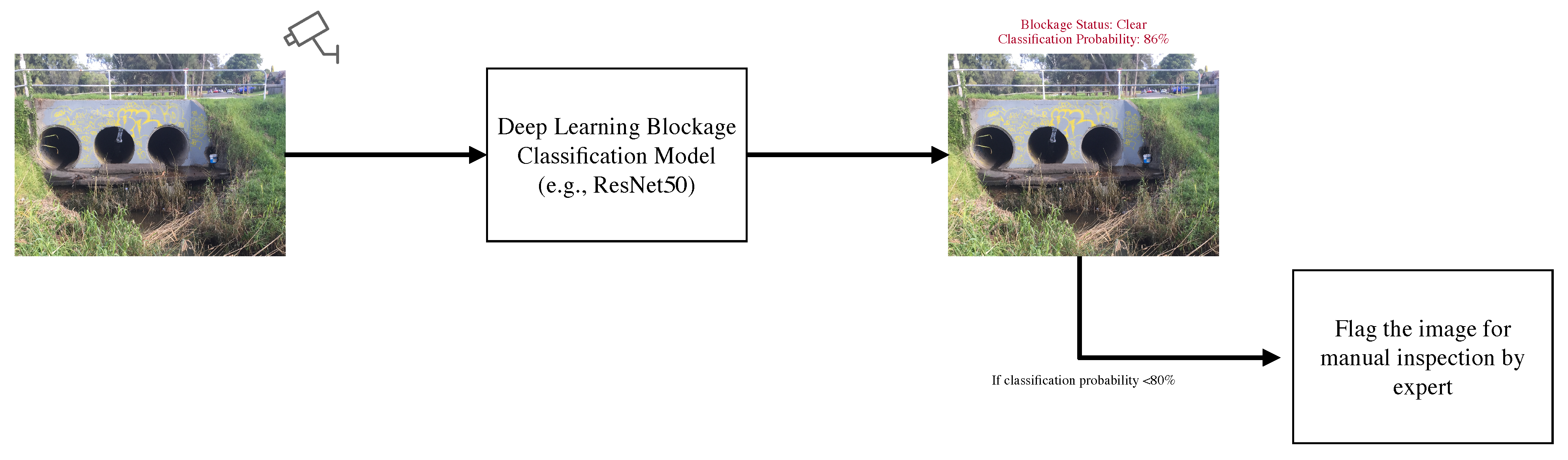
- Proposed a detection-classification pipeline to achieve higher blockage classification accuracy for practical implementation. Furthermore, a partial automation framework based on the class prediction probability is introduced using a single deep learning model to assist the visual inspection process.
2. Deep Learning Models
2.1. DarkNet53
2.2. ResNet
2.3. MobileNet
2.4. InceptionV3 and InceptionResNet
2.5. VGG16
2.6. DensNet121
2.7. NASNet
2.8. EfficientNet
3. Dataset
3.1. Images of Culvert Openings and Blockage (ICOB)
3.2. Visual Hydrology-Lab Dataset (VHD)
3.3. Synthetic Images of Culverts (SIC)
3.4. Labeling Criteria
- If all of the culvert openings are visible, classify it as “clear”;
- If any of the culvert openings is visually occluded by debris material or foreground object (e.g., debris control structure, vegetation, tree), classify it as “blocked”.
4. Experimental Setup and Evaluation Measures
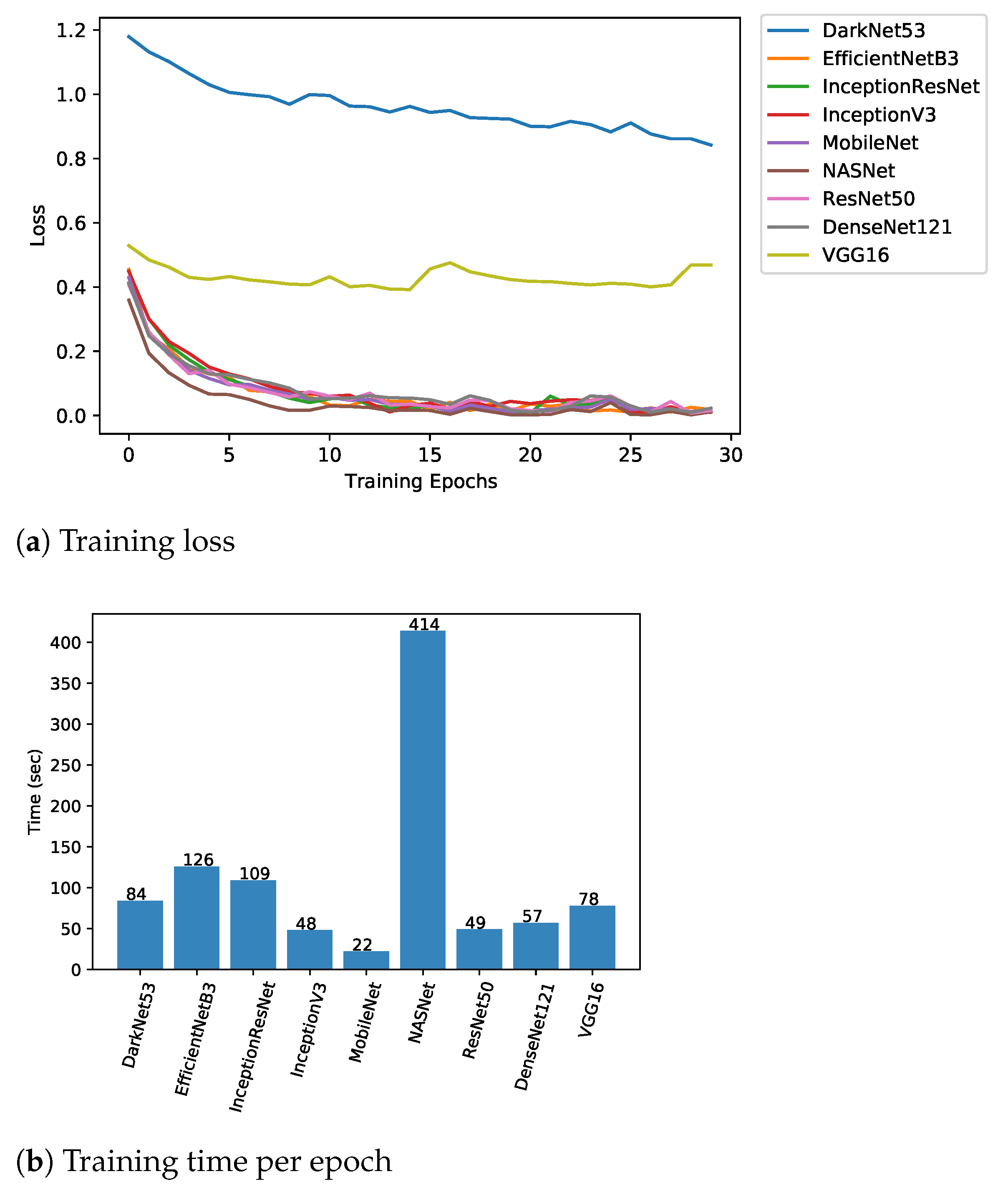
- Loss: Loss is the simplest of the measure to evaluate model training and testing performance. It is the measure of how much instances are classified incorrectly and is the ratio of number of incorrect predictions over total predictions. Minimum value of loss indicated better performance;
- Accuracy: In contrast to loss, accuracy is the measure that how much percentage of data instances are classified correctly. It is the ratio of number of correct predictions over total predictions. High value of accuracy represents better performance;
- Precision Score: Precision measures the ability of a model to not to classify a negative instance as positive. It answers the question that from all the positive predicted instances by model, how many were actually positive. The equation below presents the expression for the precision score:
- Recall Score: Recall answers the question that from all the positive instances, how many were correctly classified by the model. Expression for recall score is given as follows:
- F1 Score: F1 score is the single measure which combines both precision and recall by harmonic mean and range between 0 and 1. Higher F1 score indicates the better performance of model. Expression for F1 score is given as follows:
- Jaccard Index: In context of classification, Jaccard similarity index score measures the similarity between predicted labels and actual labels. Mathematically, let denotes the predicted label and y denotes the actual label, then J index can be expressed as follows. Higher J index indicates better performance of model.
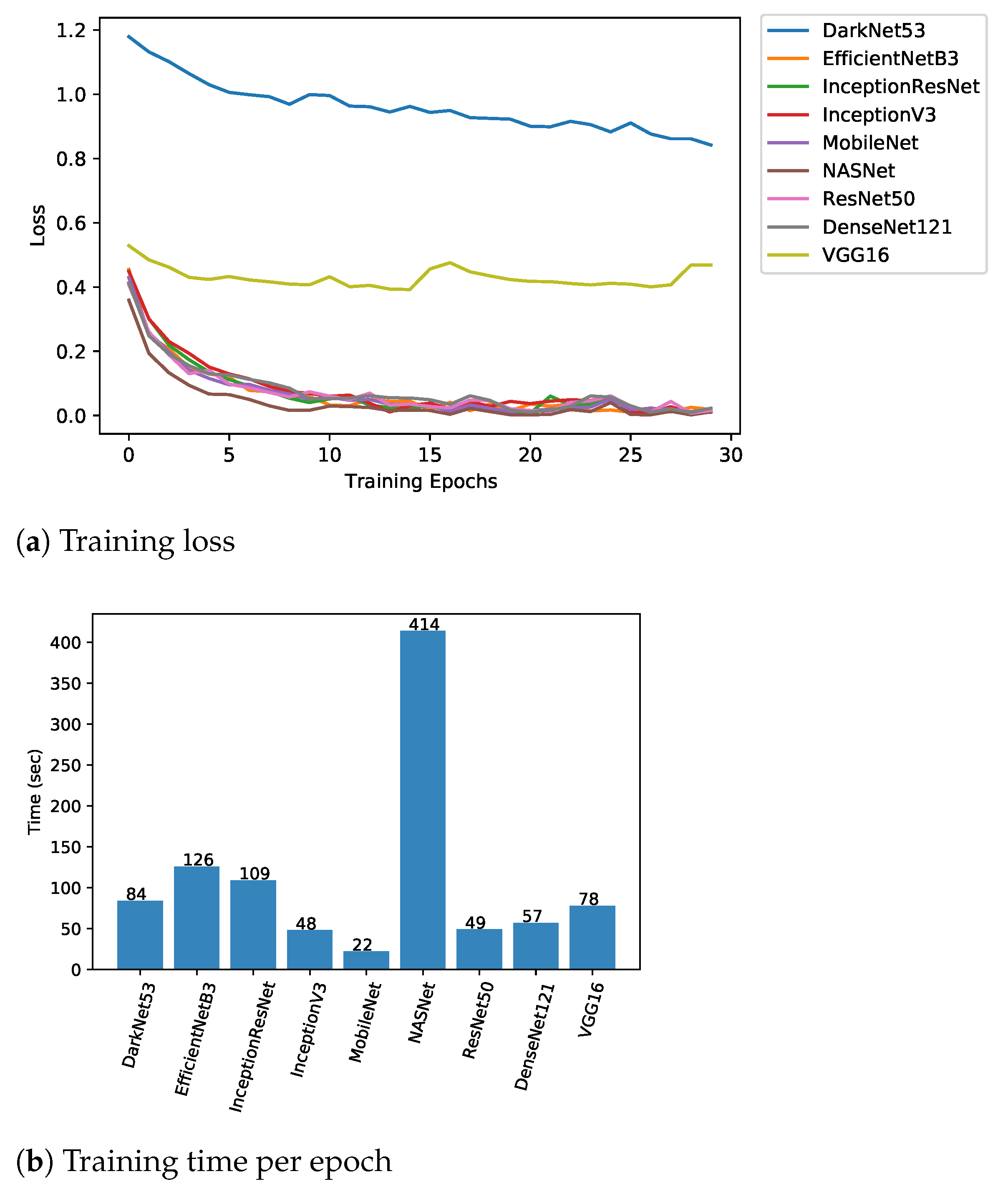
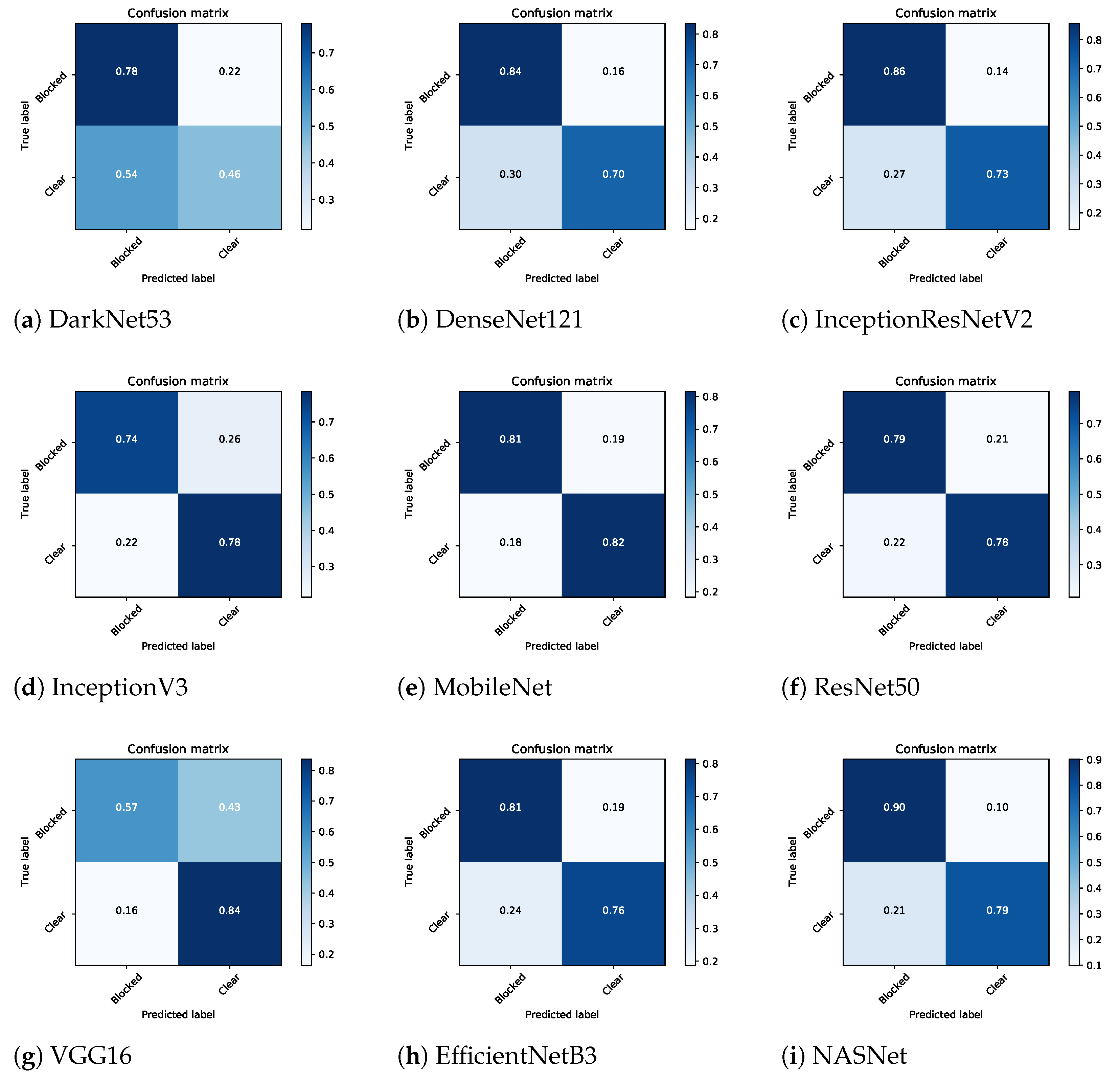
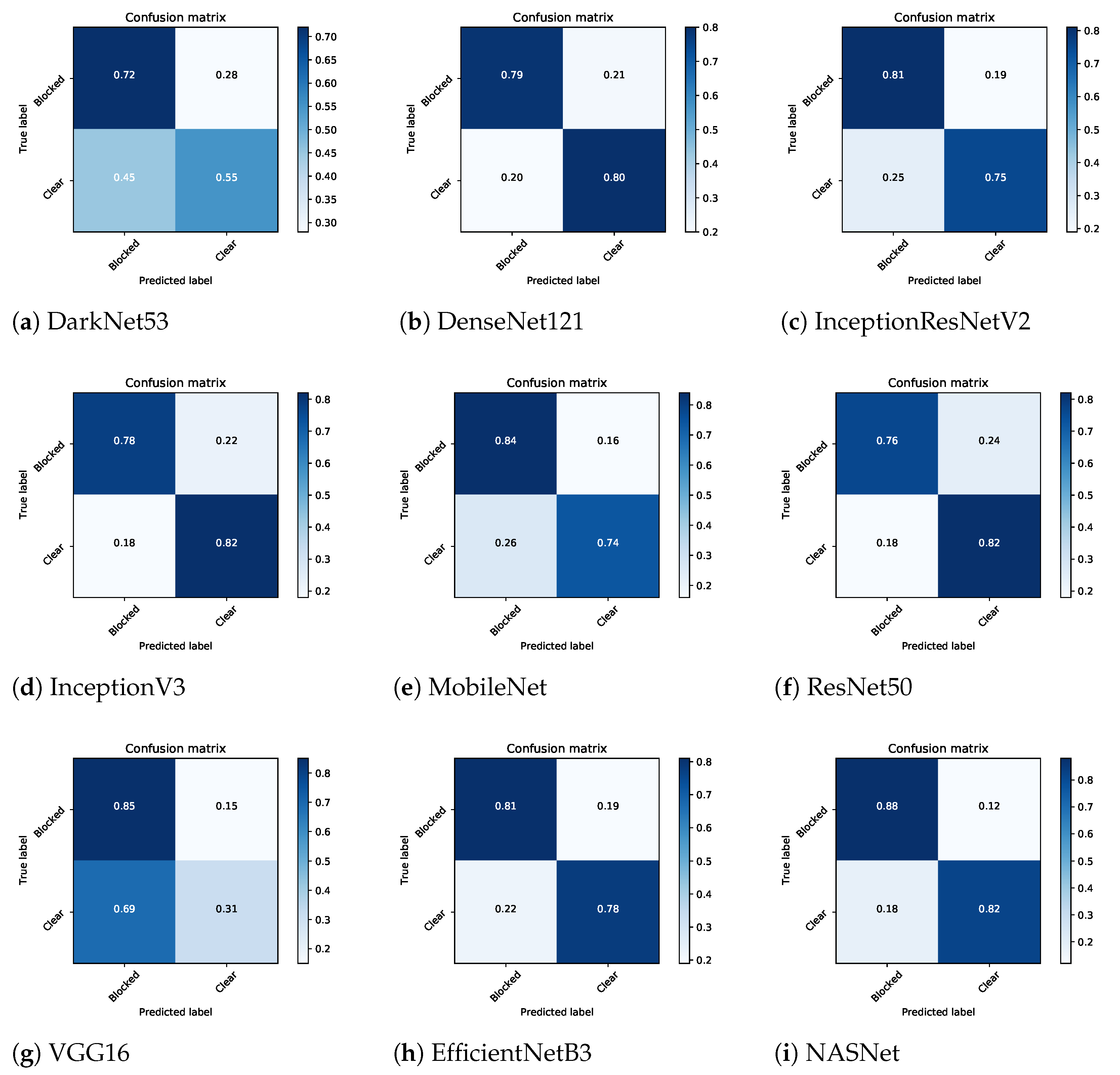
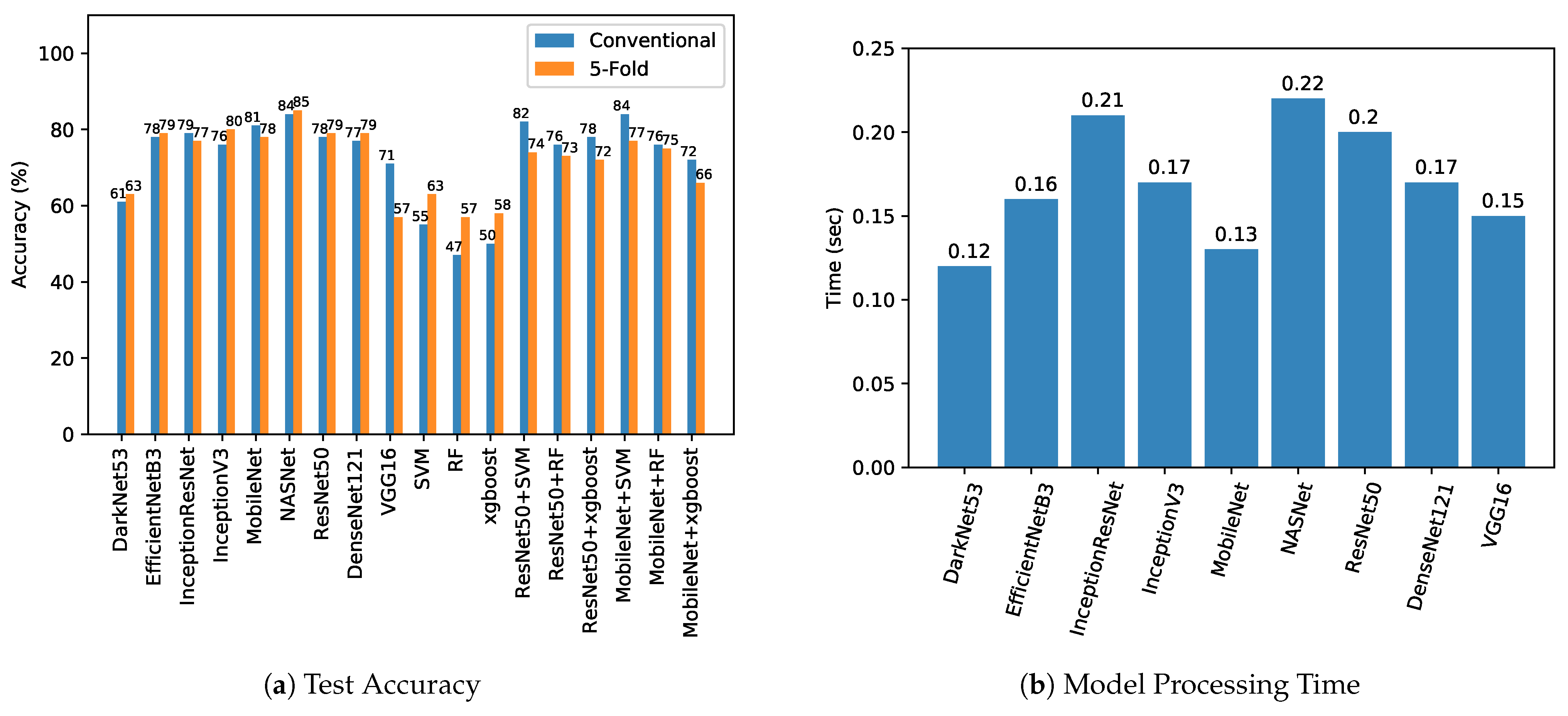
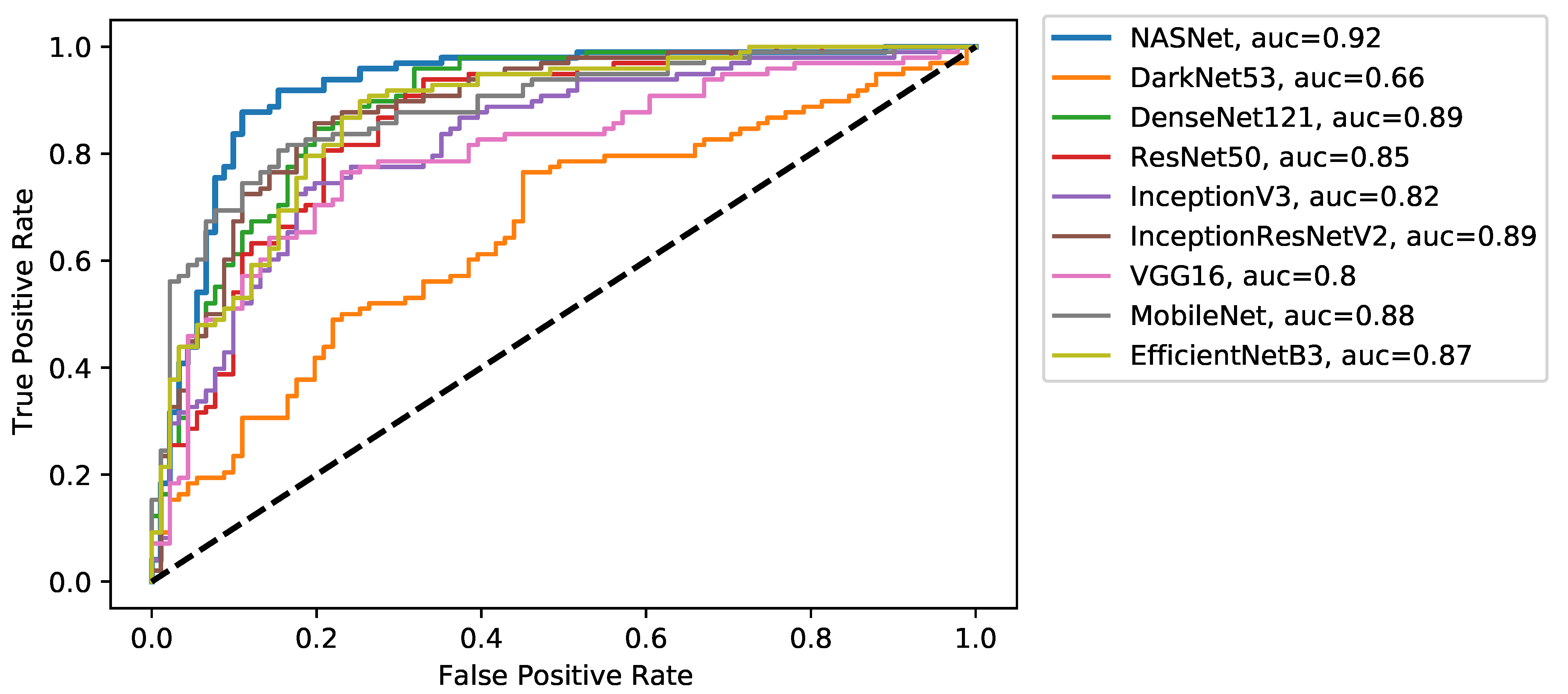
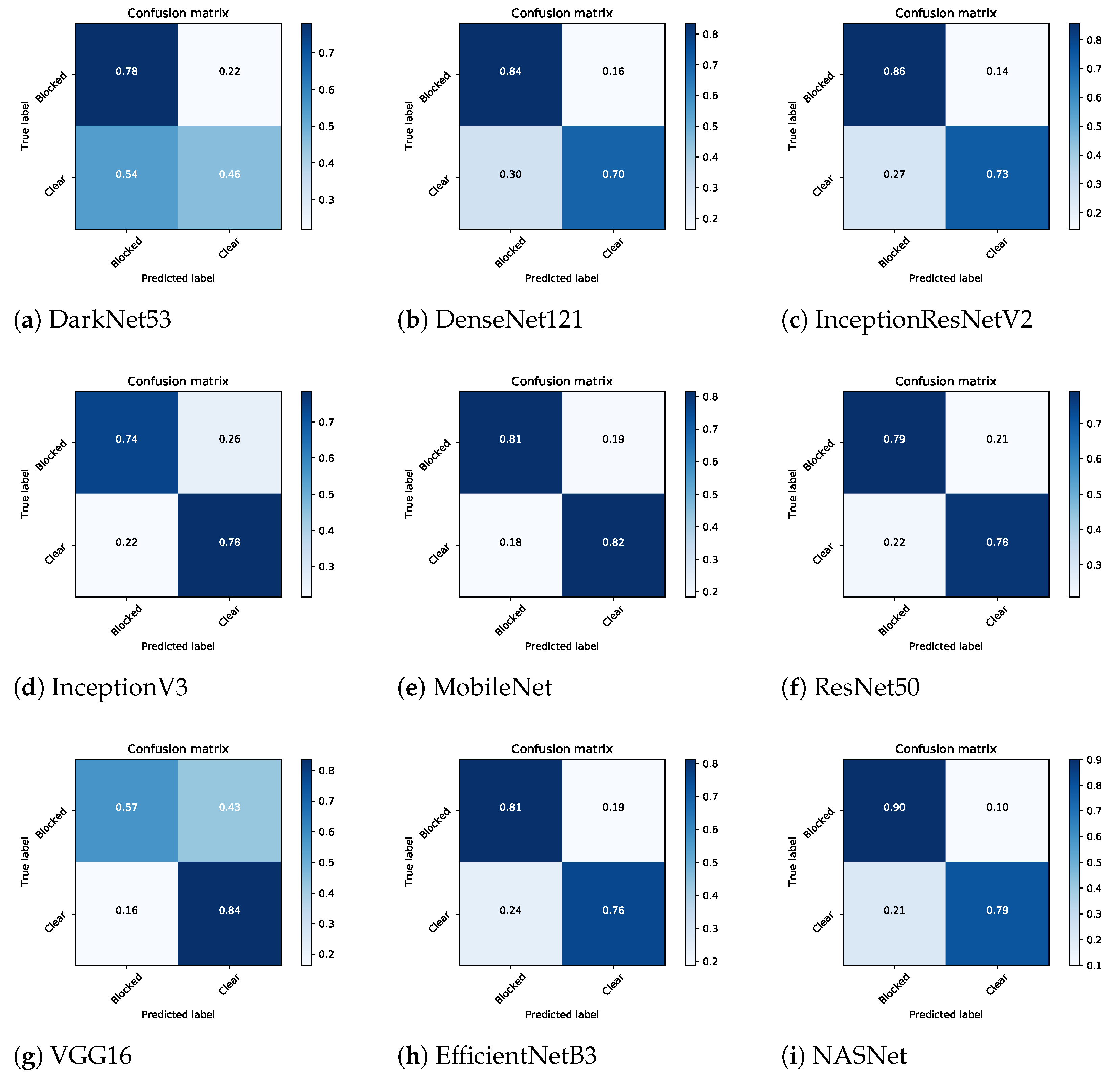
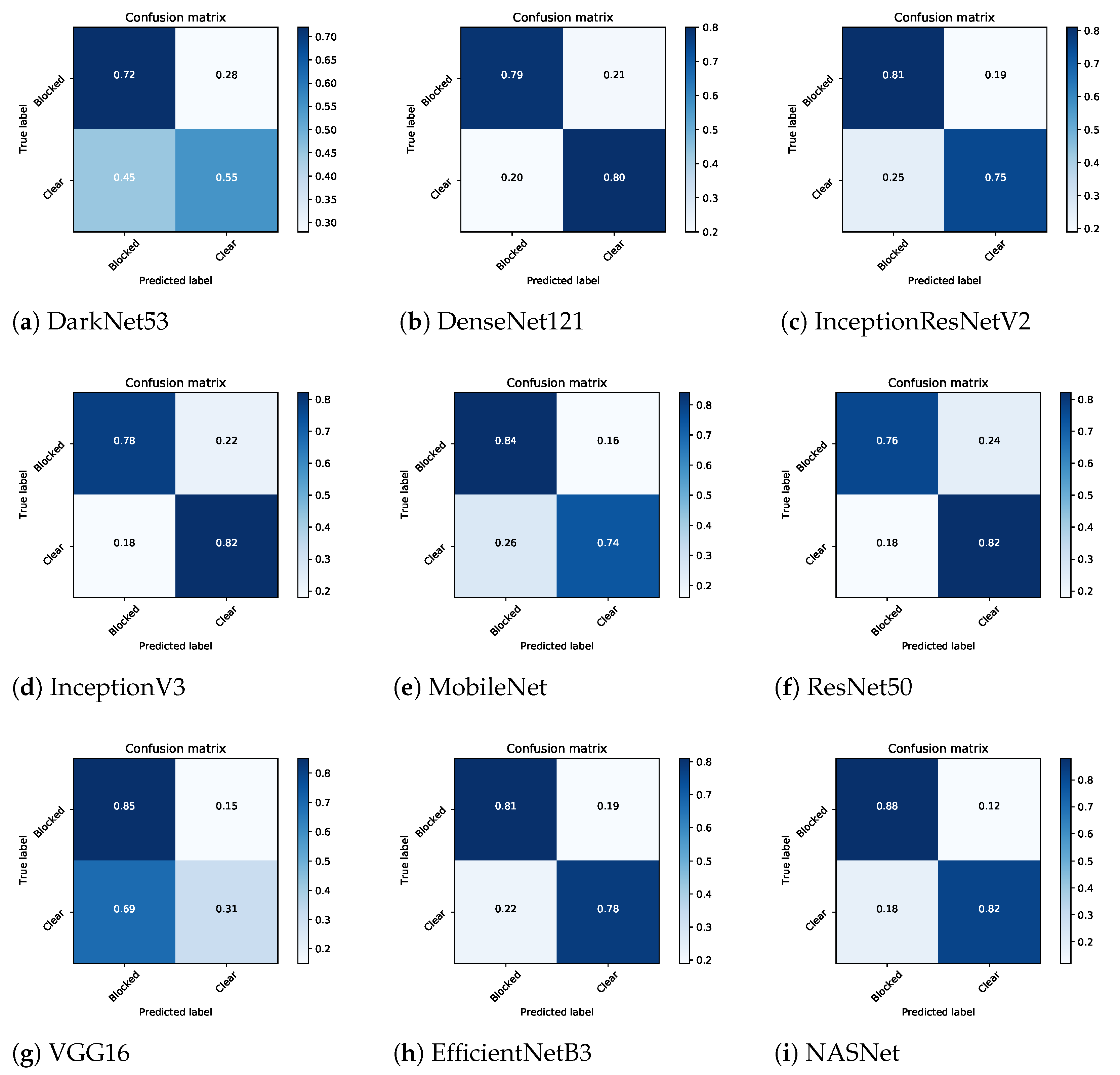
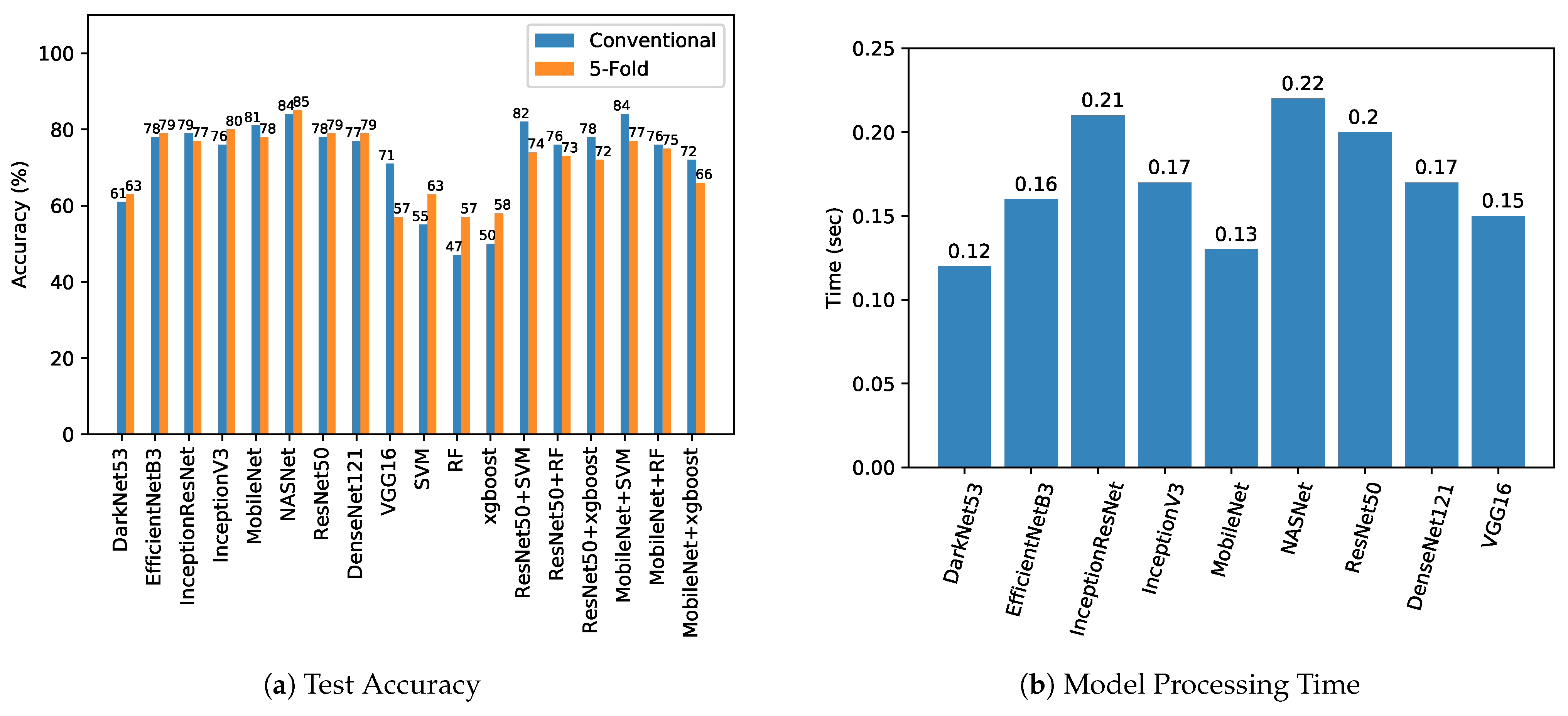
5. Results and Discussion
6. Detection-Classification Pipeline for Visual Blockage Detection
7. Conclusions and Future Directions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- French, R.; Jones, M. Culvert blockages in two Australian flood events and implications for design. Australas. J. Water Resour. 2015, 19, 134–142. [Google Scholar] [CrossRef]
- French, R.; Rigby, E.; Barthelmess, A. The non-impact of debris blockages on the August 1998 Wollongong flooding. Australas. J. Water Resour. 2012, 15, 161–169. [Google Scholar] [CrossRef]
- Blanc, J. An Analysis of the Impact of Trash Screen Design on Debris Related Blockage at Culvert Inlets. Ph.D. Thesis, School of the Built Environment, Heriot-Watt University, Edinburgh, UK, 2013. [Google Scholar]
- Weeks, W.; Witheridge, G.; Rigby, E.; Barthelmess, A.; O’Loughlin, G. Project 11: Blockage of Hydraulic Structures; Technical Report P11/S2/021; Engineers Australia, Water Engineering: Barton, ACT, Australia, 2013. [Google Scholar]
- Roso, S.; Boyd, M.; Rigby, E.; VanDrie, R. Prediction of increased flooding in urban catchments due to debris blockage and flow diversions. In Proceedings of the 5th International Conference on Sustainable Techniques and Strategies in Urban Water Management (NOVATECH), Lyon, France, 6–10 June 2004; Water Science and Technology: Lyon, France, 2004; pp. 8–13. [Google Scholar]
- Wallerstein, N.; Thorne, C.R.; Abt, S. Debris Control at Hydraulic Structures, Contract Modification: Management of Woody Debris in Natural Channels and at Hydraulic Structures; Technical Report; Department of Geography, Nottingham University (United Kingdom): Nottingham, UK, 1996. [Google Scholar]
- Iqbal, U.; Perez, P.; Li, W.; Barthelemy, J. How Computer Vision can Facilitate Flood Management: A Systematic Review. Int. J. Disaster Risk Reduct. 2021, 53, 102030. [Google Scholar] [CrossRef]
- Barthelmess, A.; Rigby, E. Culvert Blockage Mechanisms and their Impact on Flood Behaviour. In Proceedings of the 34th World Congress of the International Association for Hydro-Environment Research and Engineering, Brisbane, Australia, 26 June–1 July 2011; Engineers Australia: Barton, ACT, Australia, 2011; pp. 380–387. [Google Scholar]
- Rigby, E.; Silveri, P. Causes and effects of culvert blockage during large storms. In Proceedings of the Ninth International Conference on Urban Drainage (9ICUD), Portland, OR, USA, 8–13 September 2002; Engineers Australia: Portland, OR, USA, 2002; pp. 1–16. [Google Scholar]
- Van Drie, R.; Boyd, M.; Rigby, E. Modelling of hydraulic flood flows using WBNM2001. In Proceedings of the 6th Conference on Hydraulics in Civil Engineering, Hobart, Australia, 28–30 November 2001; Institution of Engineers Australia: Hobart, Australia, 2001; pp. 523–531. [Google Scholar]
- Davis, A. An Analysis of the Effects of Debris Caught at Various Points of Major Catchments during Wollongong’s August 1998 Storm Event. Bachelor’s Thesis, University of Wollongong, Wollongong, Australia, 2001. [Google Scholar]
- WBM, B. Newcastle Flash Flood 8 June 2007 (the Pasha Bulker Storm) Flood Data Compendium; Prepared for Newcastle City Council; BMT WBM: Broadmeadow, Australia, 2008. [Google Scholar]
- Ball, J.; Babister, M.; Nathan, R.; Weinmann, P.; Weeks, W.; Retallick, M.; Testoni, I. Australian Rainfall and Runoff—A Guide to Flood Estimation; Commonwealth of Australia: Barton, ACT, Australia, 2016. [Google Scholar]
- French, R.; Jones, M. Design for culvert blockage: The ARR 2016 guidelines. Australas. J. Water Resour. 2018, 22, 84–87. [Google Scholar] [CrossRef]
- Rigby, E.; Silveri, P. The impact of blockages on flood behaviour in the Wollongong storm of August 1998. In Proceedings of the 6th Conference on Hydraulics in Civil Engineering: The State of Hydraulics, Hobart, Australia, 28–30 November 2001; Engineers Australia: Barton, ACT, Australia, 2001; pp. 107–115. [Google Scholar]
- Ollett, P.; Syme, B.; Ryan, P. Australian Rainfall and Runoff guidance on blockage of hydraulic structures: Numerical implementation and three case studies. J. Hydrol. 2017, 56, 109–122. [Google Scholar]
- Jones, R.H.; Weeks, W.; Babister, M. Review of Conduit Blockage Policy Summary Report; WMA Water: Sydney, NSW, Australia, 2016. [Google Scholar]
- Barthelemy, J.; Amirghasemi, M.; Arshad, B.; Fay, C.; Forehead, H.; Hutchison, N.; Iqbal, U.; Li, Y.; Qian, Y.; Perez, P. Problem-Driven and Technology-Enabled Solutions for Safer Communities: The case of stormwater management in the Illawarra-Shoalhaven region (NSW, Australia). In Handbook of Smart Cities; Augusto, J.C., Ed.; Springer: Berlin, Germany, 2020; pp. 1–28. [Google Scholar]
- Arshad, B.; Ogie, R.; Barthelemy, J.; Pradhan, B.; Verstaevel, N.; Perez, P. Computer Vision and IoT-Based Sensors in Flood Monitoring and Mapping: A Systematic Review. Sensors 2019, 19, 5012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Banerjee, A.; Chitnis, U.; Jadhav, S.; Bhawalkar, J.; Chaudhury, S. Hypothesis testing, type I and type II errors. Ind. Psychiatry J. 2009, 18, 127. [Google Scholar] [CrossRef] [PubMed]
- Cui, H.; Dahnoun, N. Real-Time Stereo Vision Implementation on Nvidia Jetson TX2. In Proceedings of the 2019 8th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 10–14 June 2019; pp. 1–5. [Google Scholar]
- Basulto-Lantsova, A.; Padilla-Medina, J.A.; Perez-Pinal, F.J.; Barranco-Gutierrez, A.I. Performance comparative of OpenCV Template Matching method on Jetson TX2 and Jetson Nano developer kits. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0812–0816. [Google Scholar]
- Barthélemy, J.; Verstaevel, N.; Forehead, H.; Perez, P. Edge-computing video analytics for real-time traffic monitoring in a smart city. Sensors 2019, 19, 2048. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arshad, B.; Barthelemy, J.; Pilton, E.; Perez, P. Where is my Deer?—Wildlife Tracking And Counting via Edge Computing And Deep Learning. In Proceedings of the 2020 IEEE Sensors, Rotterdam, The Netherlands, 25–28 October 2020; pp. 1–4. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Accuracy | Test Loss/Log Loss | Precision Score | Recall Score | F1 Score | Jaccard Index | FLOPs | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Conventional | 5-Fold | Conventional | 5-Fold | Conventional | 5-Fold | Conventional | 5-Fold | Conventional | 5-Fold | Conventional | 5-Fold | ||
| Deep Learning Models | |||||||||||||
| DarkNet53 | 0.61 | 0.63 | 1.20 | 1.21 | 0.63 | 0.65 | 0.62 | 0.61 | 0.61 | 0.61 | 0.44 | 0.46 | 14.2 G |
| DenseNet121 | 0.77 | 0.79 | 0.47 | 0.57 | 0.77 | 0.80 | 0.77 | 0.79 | 0.77 | 0.79 | 0.62 | 0.66 | 5.7 G |
| InceptionResNetV2 | 0.79 | 0.77 | 0.58 | 0.65 | 0.79 | 0.78 | 0.80 | 0.78 | 0.80 | 0.77 | 0.66 | 0.64 | 13.3 G |
| InceptionV3 | 0.76 | 0.80 | 0.74 | 0.64 | 0.76 | 0.80 | 0.76 | 0.80 | 0.76 | 0.80 | 0.62 | 0.66 | 5.69 G |
| MobileNet | 0.81 | 0.78 | 0.51 | 0.59 | 0.81 | 0.79 | 0.81 | 0.79 | 0.81 | 0.78 | 0.69 | 0.65 | 1.15 G |
| ResNet50 | 0.78 | 0.79 | 0.70 | 0.62 | 0.78 | 0.76 | 0.78 | 0.76 | 0.78 | 0.79 | 0.64 | 0.65 | 7.75 G |
| VGG16 | 0.71 | 0.57 | 0.58 | 0.79 | 0.72 | 0.43 | 0.70 | 0.58 | 0.70 | 0.48 | 0.55 | 0.41 | 30.7 G |
| EfficientNetB3 | 0.78 | 0.79 | 0.46 | 0.57 | 0.78 | 0.80 | 0.78 | 0.79 | 0.78 | 0.79 | 0.64 | 0.66 | 1.97 G |
| NASNet | 0.84 | 0.85 | 0.58 | 0.55 | 0.85 | 0.85 | 0.84 | 0.85 | 0.84 | 0.85 | 0.73 | 0.73 | 47.8 G |
| Conventional Machine Learning Algorithms | |||||||||||||
| SVM | 0.55 | 0.63 | 15.53 | 12.61 | 0.70 | 0.64 | 0.57 | 0.63 | 0.46 | 0.63 | 0.38 | 0.47 | NA |
| RF | 0.47 | 0.57 | 18.27 | 14.80 | 0.47 | 0.57 | 0.48 | 0.57 | 0.40 | 0.56 | 0.31 | 0.40 | NA |
| xgboost | 0.50 | 0.58 | 17.18 | 14.62 | 0.58 | 0.58 | 0.52 | 0.57 | 0.40 | 0.57 | 0.34 | 0.41 | NA |
| Deep CNN Visual Features Classification using Conventional Machine Learning Approaches | |||||||||||||
| ResNet50 Features + SVM | 0.82 | 0.74 | 6.31 | 9.11 | 0.82 | 0.74 | 0.82 | 0.74 | 0.82 | 0.74 | 0.69 | 0.58 | NA |
| ResNet50 Features + RF | 0.76 | 0.73 | 8.24 | 9.29 | 0.78 | 0.73 | 0.76 | 0.73 | 0.76 | 0.73 | 0.61 | 0.58 | NA |
| ResNet50 Features + xgboost | 0.78 | 0.72 | 7.36 | 9.64 | 0.79 | 0.72 | 0.79 | 0.72 | 0.79 | 0.72 | 0.65 | 0.56 | NA |
| MobileNet Feature + SVM | 0.84 | 0.77 | 5.25 | 7.88 | 0.85 | 0.77 | 0.85 | 0.77 | 0.85 | 0.77 | 0.74 | 0.63 | NA |
| MobileNet Feature + RF | 0.76 | 0.75 | 8.06 | 8.41 | 0.77 | 0.78 | 0.77 | 0.76 | 0.77 | 0.75 | 0.62 | 0.61 | NA |
| MobileNet Feature + xgboost | 0.72 | 0.66 | 9.64 | 11.74 | 0.73 | 0.66 | 0.72 | 0.66 | 0.72 | 0.66 | 0.56 | 0.49 | NA |
| Model Processing Time (s) | Total Execution Time (s) | |||
|---|---|---|---|---|
| Image 1 | Image 2 | Image 3 | ||
| DarkNet53 | 0.05 | 0.12 | 0.2 | 0.35 |
| DenseNet121 | 0.09 | 0.17 | 0.24 | 0.39 |
| InceptionResNetV2 | 0.14 | 0.21 | 0.29 | 0.44 |
| InceptionV3 | 0.09 | 0.17 | 0.24 | 0.39 |
| MobileNet | 0.06 | 0.13 | 0.21 | 0.36 |
| ResNet152 | 0.13 | 0.20 | 0.28 | 0.43 |
| ResNet50 | 0.08 | 0.15 | 0.23 | 0.38 |
| VGG16 | 0.08 | 0.15 | 0.23 | 0.38 |
| EfficientNetB3 | 0.09 | 0.16 | 0.24 | 0.39 |
| NASNet | 0.15 | 0.22 | 0.30 | 0.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iqbal, U.; Barthelemy, J.; Li, W.; Perez, P. Automating Visual Blockage Classification of Culverts with Deep Learning. Appl. Sci. 2021, 11, 7561. https://doi.org/10.3390/app11167561
Iqbal U, Barthelemy J, Li W, Perez P. Automating Visual Blockage Classification of Culverts with Deep Learning. Applied Sciences. 2021; 11(16):7561. https://doi.org/10.3390/app11167561
Chicago/Turabian StyleIqbal, Umair, Johan Barthelemy, Wanqing Li, and Pascal Perez. 2021. "Automating Visual Blockage Classification of Culverts with Deep Learning" Applied Sciences 11, no. 16: 7561. https://doi.org/10.3390/app11167561
APA StyleIqbal, U., Barthelemy, J., Li, W., & Perez, P. (2021). Automating Visual Blockage Classification of Culverts with Deep Learning. Applied Sciences, 11(16), 7561. https://doi.org/10.3390/app11167561