
Early Neighbor Rejection-Aided Tabu Search Detection for Large MIMO Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- 1.
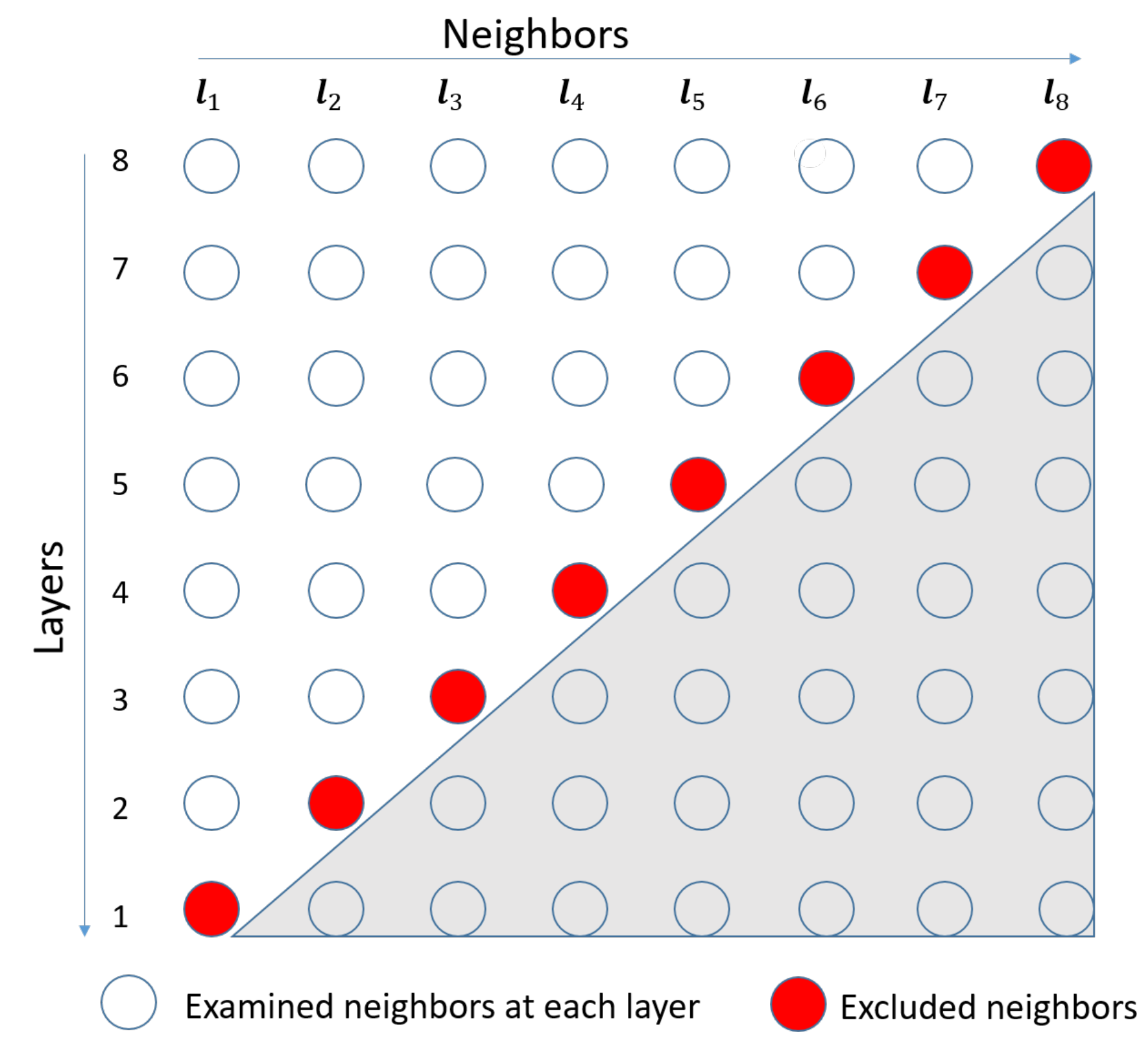
- We develop a novel early neighbor rejection ENR-TS scheme. The TS algorithm computes the cumulative ML metrics of all the neighbors in each layer and rejects k neighbors whose cumulative metrics are larger than the others. The rejected neighbors are excluded from the computation of ML metrics in further layers, which reduces complexity.
- 2.
- To mitigate the risk of excluding the best neighbor in early layers, we apply a layer ordering scheme, which sorts the layers of each neighbor in descending order of their expected metrics.
- 3.
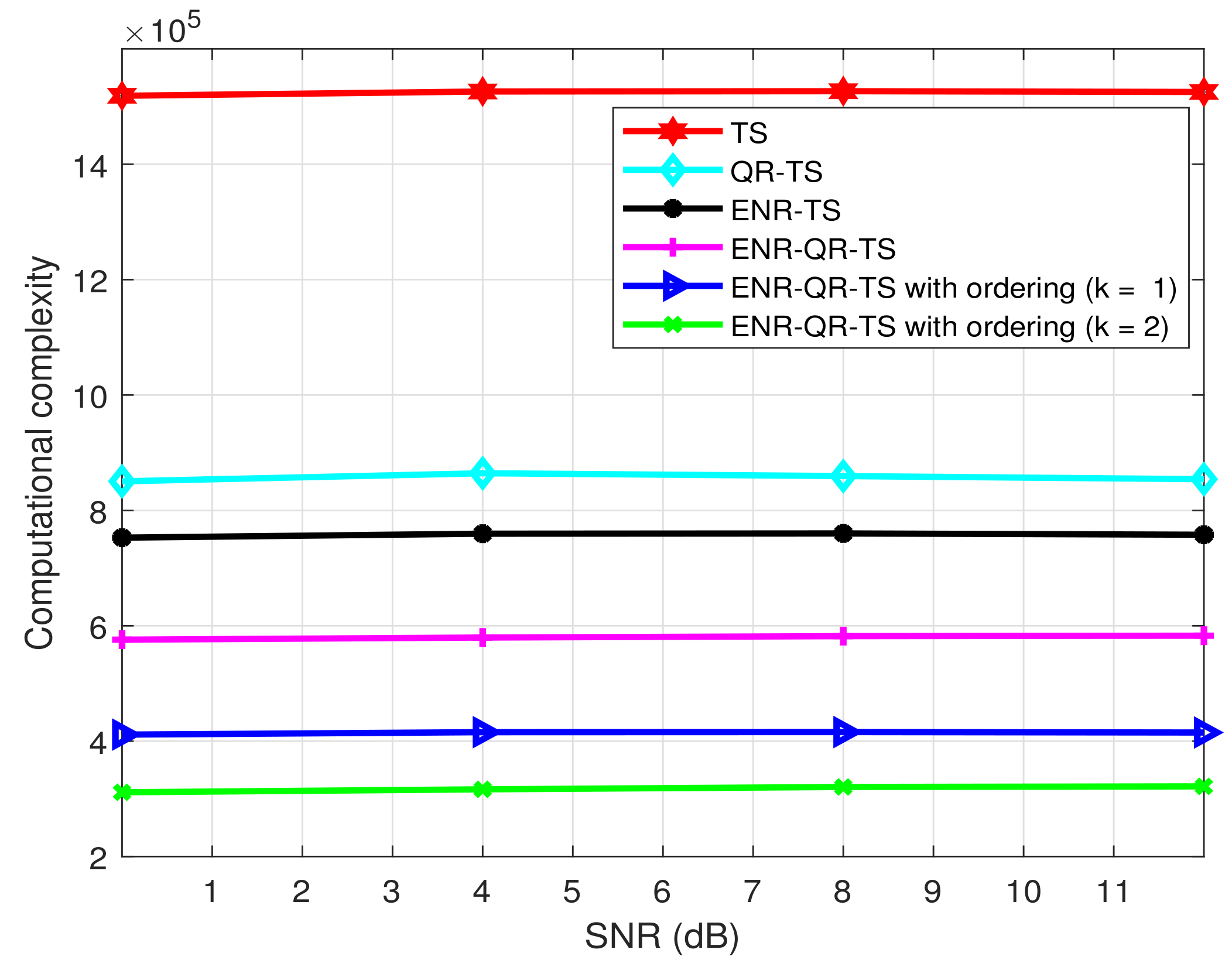
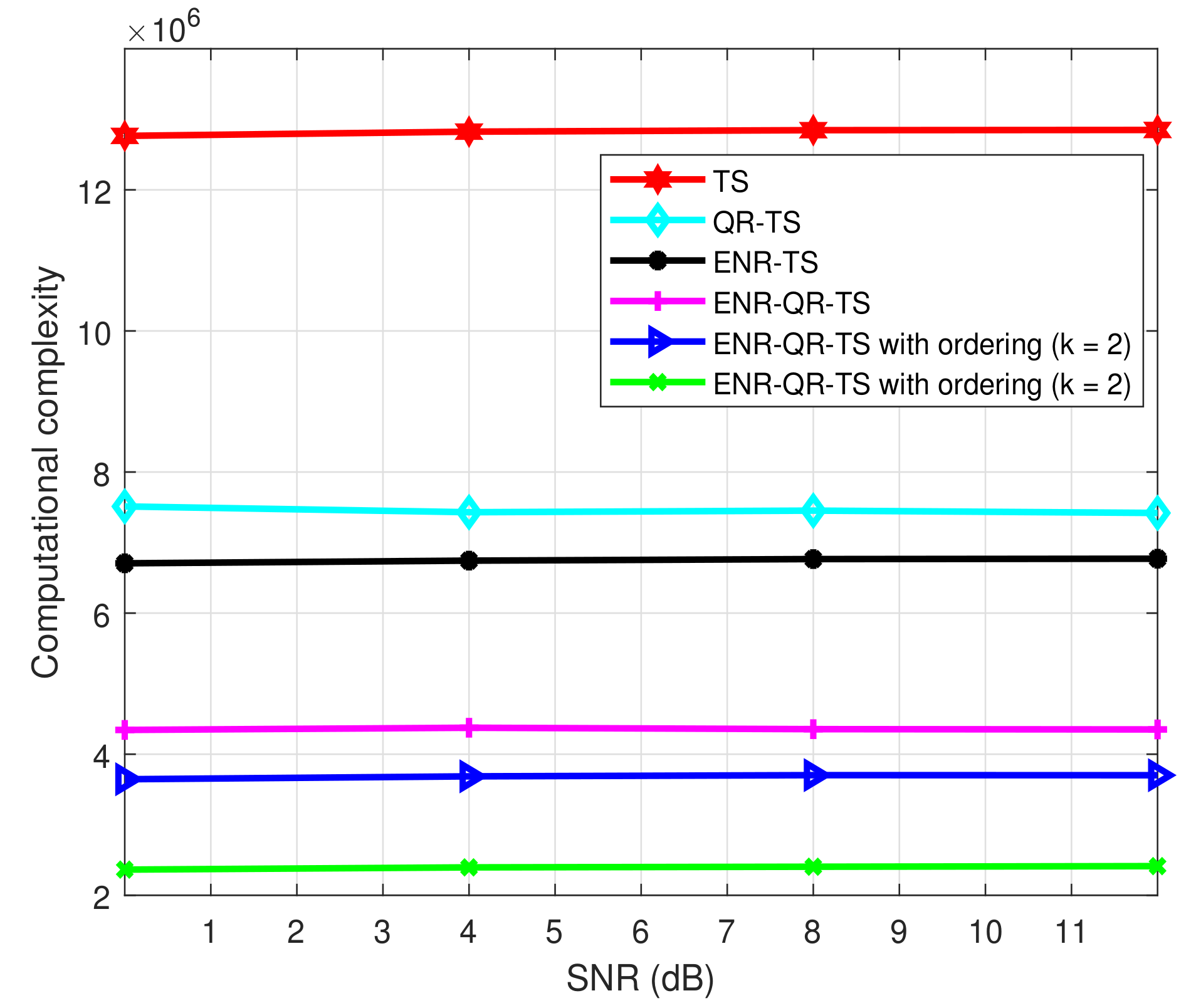
- To evaluate the performance and complexity of the proposed scheme, we perform numerical analysis. The simulation results show that when the ERN scheme is incorporated into QR-TS (ENR-QR-TS), it reduces complexity by approximately 74% compared to the original TS scheme, while attaining almost the same BER performance.
2. Background
2.1. MIMO System Description
2.2. System Model
2.3. Conventional TS Algorithm
2.4. QR-TS
3. Proposed Low Complexity TS Algorithms
3.1. ENR with QR-TS
3.2. ENR-QR-TS with Layer Ordering
| Algorithm 1 ENR-QR-TS with layer ordering. |
| INPUT:, , M |
|
3.3. Complexity Analysis
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rusek, F.; Persson, D.; Lau, B.K.; Larsson, E.G.; Marzetta, T.L.; Edfors, O.; Tufvesson, F. Scaling up MIMO: Opportunities and challenges with very large arrays. IEEE Signal Process. Mag. 2013, 30, 40–60. [Google Scholar] [CrossRef] [Green Version]
- Zanella, A.; Chiani, M.; Win, M.Z. MMSE reception and successive interference cancellation for MIMO systems with high spectral efficiency. IEEE Trans. Wirel. Commun. 2005, 4, 1244–1253. [Google Scholar] [CrossRef] [Green Version]
- Hassibi, B.; Vikalo, H. On the sphere-decoding algorithm I. Expected complexity. IEEE Trans. Signal Process. 2005, 53, 2806–2818. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Nilsson, P. Algorithm and implementation of the K-best sphere decoding for MIMO detection. IEEE J. Sel. Areas Commun. 2006, 24, 491–503. [Google Scholar]
- Ummatov, U.; Lee, K. Adaptive Threshold-Aided K-Best Sphere Decoding for Large MIMO Systems. Appl. Sci. 2019, 9, 4624. [Google Scholar] [CrossRef] [Green Version]
- Albreem, M.A.; Juntti, M.; Shahabuddin, S. Massive MIMO detection techniques: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3109–3132. [Google Scholar] [CrossRef] [Green Version]
- Tseng, S.M.; Lee, H.L. An adaptive partial parallel multistage detection for MIMO systems. IEEE Trans. Commun. 2005, 53, 587–591. [Google Scholar] [CrossRef]
- Yang, S.; Hanzo, L. Fifty years of MIMO detection: The road to large-scale MIMOs. IEEE Commun. Surv. Tutor. 2015, 17, 1941–1988. [Google Scholar] [CrossRef] [Green Version]
- Datta, T.; Srinidhi, N.; Chockalingam, A.; Rajan, B.S. Random-restart reactive tabu search algorithm for detection in large-MIMO systems. IEEE Commun. Lett. 2010, 14, 1107–1109. [Google Scholar] [CrossRef]
- Srinidhi, N.; Datta, T.; Chockalingam, A.; Rajan, B.S. Layered tabu search algorithm for large-MIMO detection and a lower bound on ML performance. IEEE Trans. Commun. 2011, 59, 2955–2963. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Lee, K. Groupwise Neighbor Examination for Tabu Search Detection in Large MIMO Systems. IEEE Trans. Veh. Technol. 2019, 69, 1136–1140. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, N.T.; Lee, K.; Dai, H. QR-Decomposition-Aided Tabu Search Detection for Large MIMO Systems. IEEE Trans. Veh. Technol. 2019, 68, 4857–4870. [Google Scholar] [CrossRef]
- Srinidhi, N.; Mohammed, S.K.; Chockalingam, A.; Rajan, B.S. Low-complexity near-ML decoding of large non-orthogonal STBCs using reactive tabu search. IEEE Int. Symp. Inf. Theory 2019, 17, 1993–1997. [Google Scholar]
- Srinidhi, N.; Mohammed, S.K.; Chockalingam, A.; Rajan, B.S. Near-ML signal detection in large-dimension linear vector channels using reactive tabu search. arXiv 2009, arXiv:0911.4640. [Google Scholar]
- Zhao, H.; Long, H.; Wang, W. Tabu search detection for MIMO systems. In Proceedings of the IEEE 18th International Symposium on Personal, Indoor and Mobile Radio Communications, Athens, Greece, 3–7 September 2007; pp. 1–5. [Google Scholar]
- Glover, F. Tabu search—Part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef] [Green Version]
- Golub, G.H.; Van Loa, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2012; Volume 3. [Google Scholar]
- Sedgewick, R. Implementing quicksort programs. Commun. ACM 1978, 21, 847–857. [Google Scholar] [CrossRef]
- Agrell, E.; Eriksson, T.; Vardy, A.; Zeger, K. Closest point search in lattices. IEEE Trans. Inf. Theory 2002, 48, 2201–2214. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ummatov, U.; Park, J.-S.; Jang, G.-J.; Lee, J.-D. Early Neighbor Rejection-Aided Tabu Search Detection for Large MIMO Systems. Appl. Sci. 2021, 11, 7305. https://doi.org/10.3390/app11167305
Ummatov U, Park J-S, Jang G-J, Lee J-D. Early Neighbor Rejection-Aided Tabu Search Detection for Large MIMO Systems. Applied Sciences. 2021; 11(16):7305. https://doi.org/10.3390/app11167305
Chicago/Turabian StyleUmmatov, Uzokboy, Jin-Sil Park, Gwang-Jae Jang, and Ju-Dong Lee. 2021. "Early Neighbor Rejection-Aided Tabu Search Detection for Large MIMO Systems" Applied Sciences 11, no. 16: 7305. https://doi.org/10.3390/app11167305
APA StyleUmmatov, U., Park, J.-S., Jang, G.-J., & Lee, J.-D. (2021). Early Neighbor Rejection-Aided Tabu Search Detection for Large MIMO Systems. Applied Sciences, 11(16), 7305. https://doi.org/10.3390/app11167305