
Restoring Raindrops Using Attentive Generative Adversarial Networks


Abstract
:1. Introduction
2. Related Works
2.1. Time- and Frequency-Domain-Based Methods
2.2. Low-Rank Representation and Sparsity-Based Methods
2.3. Gaussian Mixture Model
2.4. Deep-Learning-Based Methods
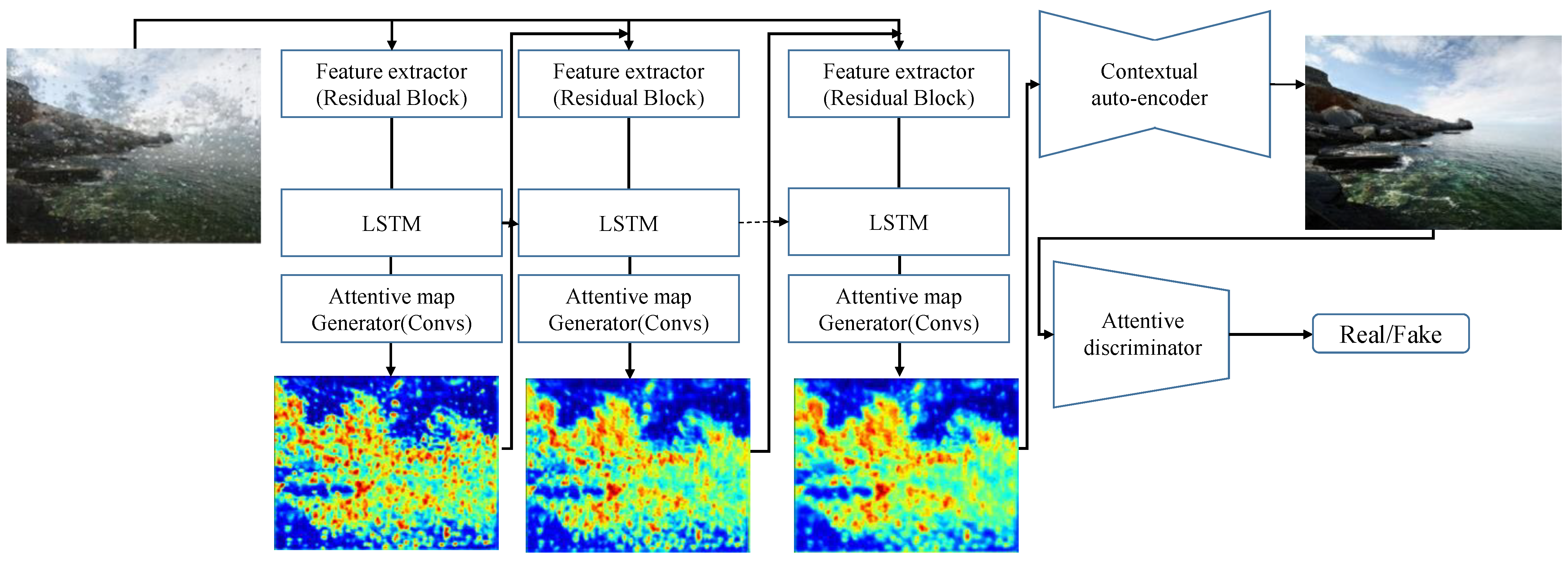
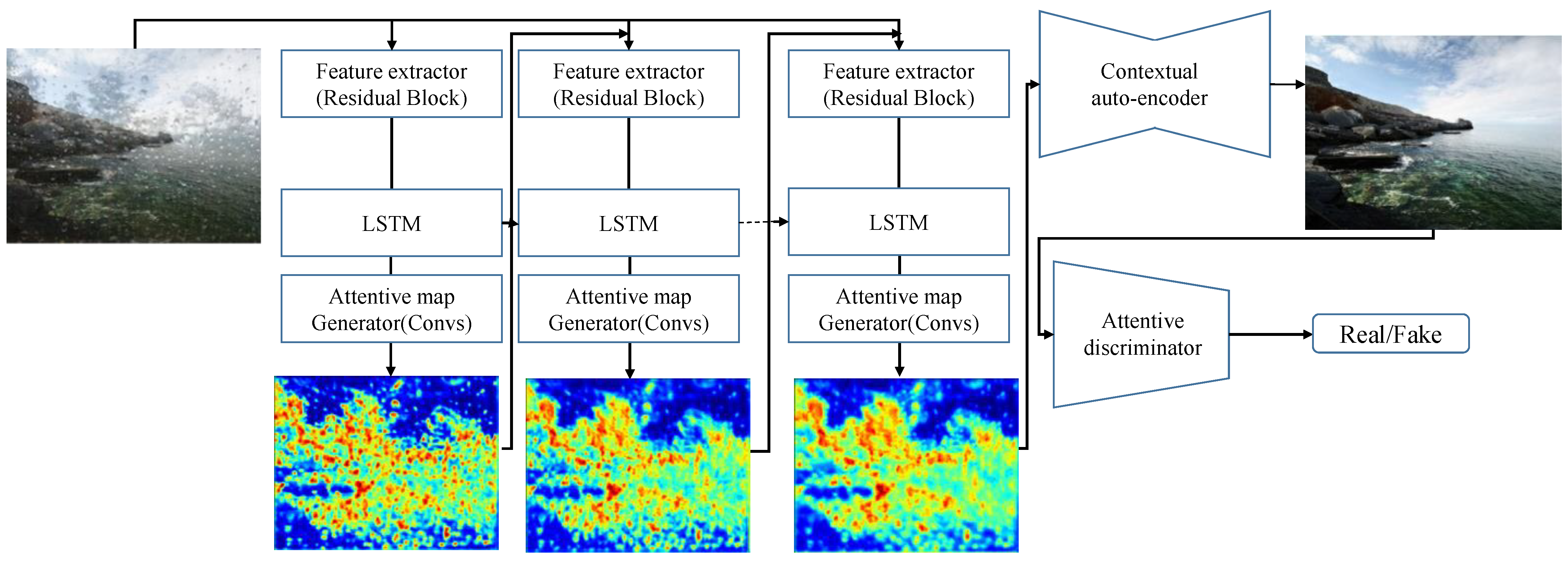
3. Raindrop Removal with an ATTGAN
3.1. Formation of a Single Waterdrop Image
3.2. Generative Network
3.2.1. Attentive-Recurrent Network
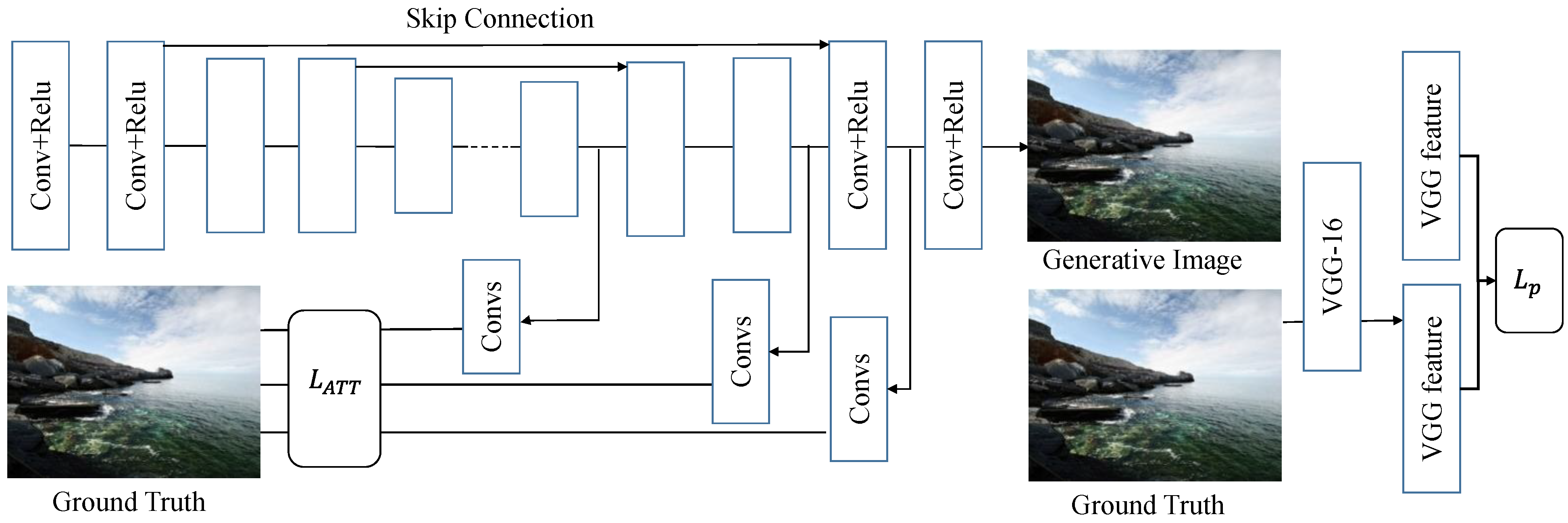
3.2.2. Generative Autoencoder
3.3. Discriminative Network
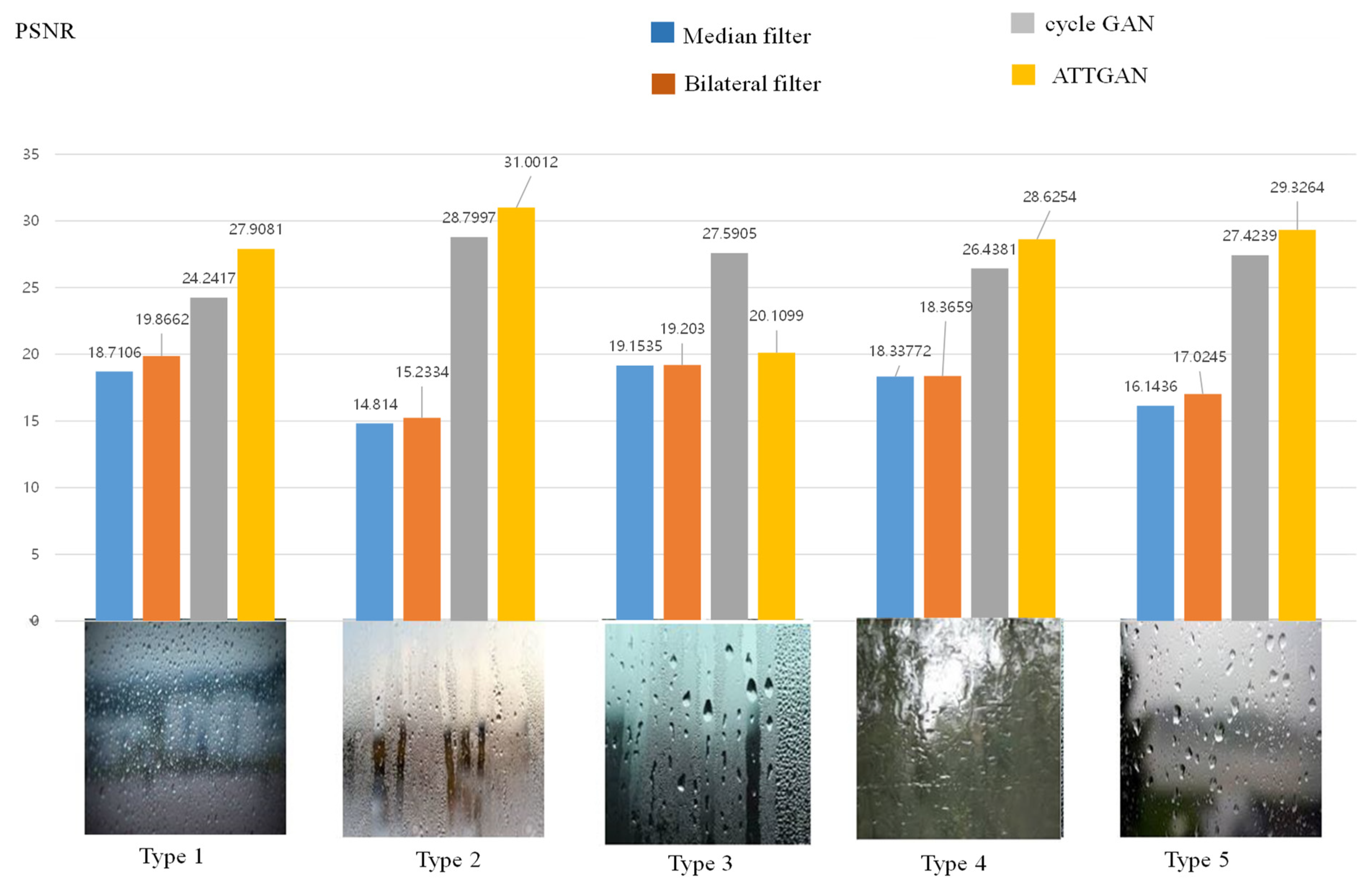
4. Experimental Results and Analysis
4.1. Experimental Environment
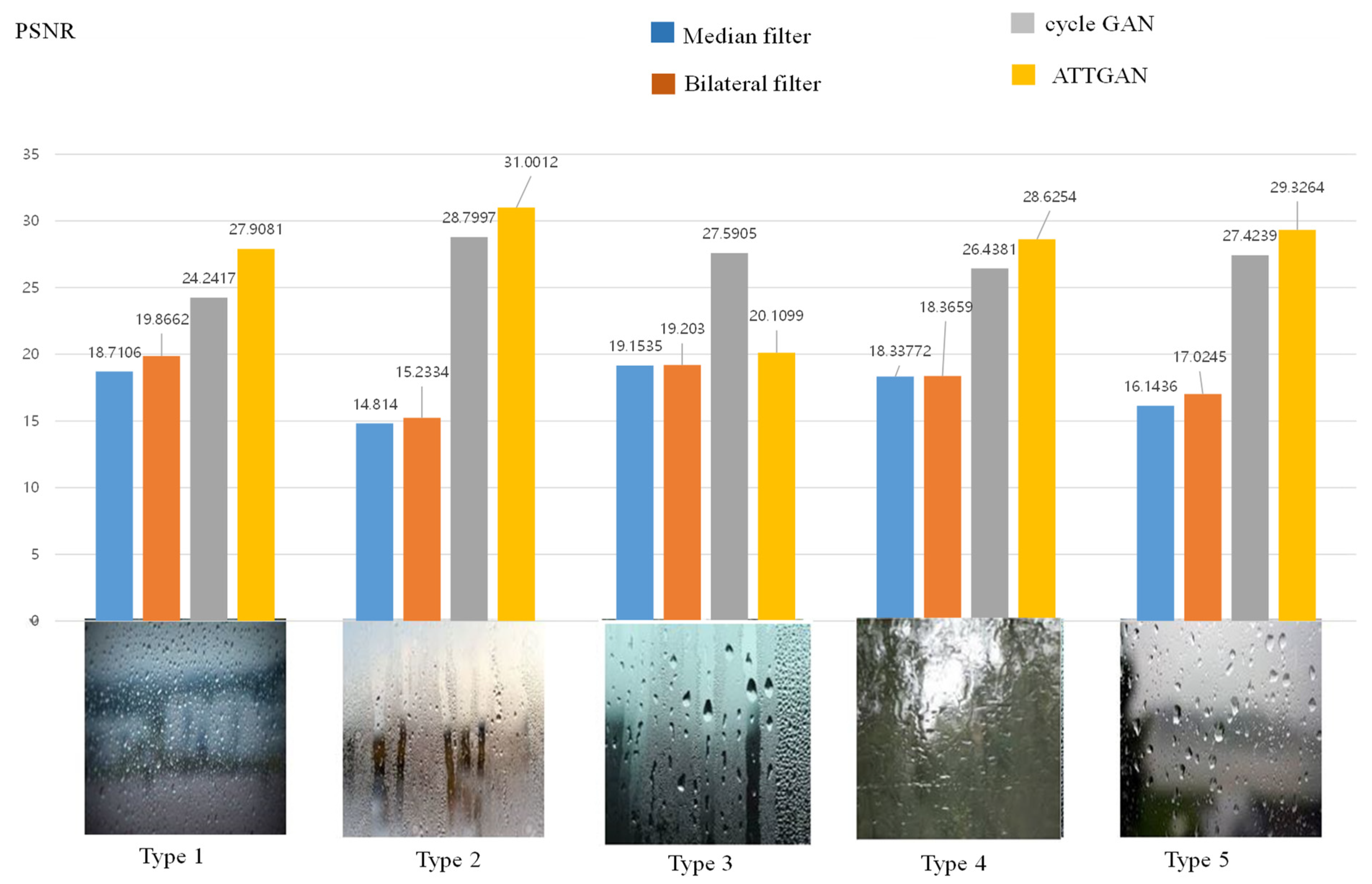
4.2. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 23 June 2018; pp. 2482–2491. [Google Scholar]
- Li, X.; Liu, Z.; Li, B.; Feng, X.; Liu, X.; Zhou, D. A novel attentive generative adversarial network for waterdrop detection and removal of rubber conveyor belt image. Math. Probl. Eng. 2020, 2020, 1–20. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Y.; Li, M.; Zhao, Q.; Meng, D. A survey on rain removal from video and single image. arXiv 2019, arXiv:1909.08326. [Google Scholar]
- Yang, W.; Tan, R.T.; Wang, S.; Fang, Y.; Liu, J. Single image deraining: From model-based to data-driven and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1–18. [Google Scholar] [CrossRef]
- Li, S.; Ren, W.; Wang, F.; Araujo, I.B.; Tokuda, E.K.; Junior, R.H.; Cesar, J.R., Jr.; Wang, Z.; Cao, X. A comprehensive benchmark analysis of single image deraining: Current challenges and future perspectives. Int. J. Comput. Vision 2021, 129, 1301–1322. [Google Scholar] [CrossRef]
- Garg, K.; Nayar, S.K. Detection and removal of rain from videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 July 2004; pp. 526–535. [Google Scholar]
- Zhang, X.; Li, H.; Qi, Y.; Leow, W.K.; Ng, T.K. Rain removal in video by combining temporal and chromatic properties. In Proceedings of the IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 461–464. [Google Scholar]
- Barnum, P.; Kanade, T.; Narasimhan, S. Spatio-temporal frequency analysis for removing rain and snow from videos. In Proceedings of the International Workshop on Photometric Analysis for Computer Vision, Rio de Janeiro, Brazil, 14 October 2007; pp. 1–8. [Google Scholar]
- Chen, Y.-L.; Hsu, C.-T. A generalized low-rank appearance model for spatio-temporally correlated rain streaks. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1968–1975. [Google Scholar]
- Hu, X.; Fu, C.W.; Zhu, L.; Heng, P.A. Depth-attentional features for single-image rain removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, California, CA, USA, 15–20 June 2019; pp. 8022–8031. [Google Scholar]
- Zhu, L.; Fu, C.; Lischinski, D.; Heng, P. Joint bilayer optimization for single-image rain streak removal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2545–2553. [Google Scholar]
- Deng, L.J.; Huang, T.Z.; Zhao, X.L.; Jiang, T.X. A directional global sparse model for single image rain removal. Appl. Math. Model. 2018, 59, 662–679. [Google Scholar] [CrossRef]
- Li, Y.; Tan, R.T.; Guo, X.; Liu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 2736–2744. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 21–26 July 2017; pp. 1685–1694. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Guo, Z.; Yan, S.; Liu, J. Joint rain detection and removal from a single image with contextualized deep networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1377–1393. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Liu, J.; Feng, J. Frame-consistent recurrent video deraining with dual-level flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, California, CA, USA, 15–20 June 2019; pp. 1661–1670. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.H.; Ryu, E.; Kim, J.O. Progressive rain removal via a recurrent convolutional network for real rain videos. IEEE Access 2020, 8, 203134–203145. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half instance normalization network for image restoration. arXiv 2021, arXiv:2105.06086. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Liu, J. Uformer: A general U-shaped transformer for image restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xingjian, S.H.I.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- ImageNet. Available online: http://image-net.org/ (accessed on 3 May 2021).
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. rui1996/DeRaindrop. Available online: https://github.com/rui1996/DeRaindrop (accessed on 20 May 2021).
- Goo, S. Restoring Water Drop on Window using on Conditional Generative Adversarial Network. Master’s Thesis, Department of Computer Engineering, Chosun University, Gwangju, Republic of Korea, 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description |
|---|---|
| 1 | medium water mist |
| 2 | weak water stream and small water mist |
| 3 | strong water drop |
| 4 | strong water stream |
| 5 | large water drop and strong water fog |
| Name | Bilateral Filter | Cycle GGAN | ATTGAN | Proposed Method |
|---|---|---|---|---|
| SSIM | 0.562 | 0.8752 | 0.9018 | 0.9124 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goo, S.; Yang, H.-D. Restoring Raindrops Using Attentive Generative Adversarial Networks. Appl. Sci. 2021, 11, 7034. https://doi.org/10.3390/app11157034
Goo S, Yang H-D. Restoring Raindrops Using Attentive Generative Adversarial Networks. Applied Sciences. 2021; 11(15):7034. https://doi.org/10.3390/app11157034
Chicago/Turabian StyleGoo, Suhan, and Hee-Deok Yang. 2021. "Restoring Raindrops Using Attentive Generative Adversarial Networks" Applied Sciences 11, no. 15: 7034. https://doi.org/10.3390/app11157034
APA StyleGoo, S., & Yang, H.-D. (2021). Restoring Raindrops Using Attentive Generative Adversarial Networks. Applied Sciences, 11(15), 7034. https://doi.org/10.3390/app11157034