
Stamping Tool Conditions Diagnosis: A Deep Metric Learning Approach



Abstract
:1. Introduction
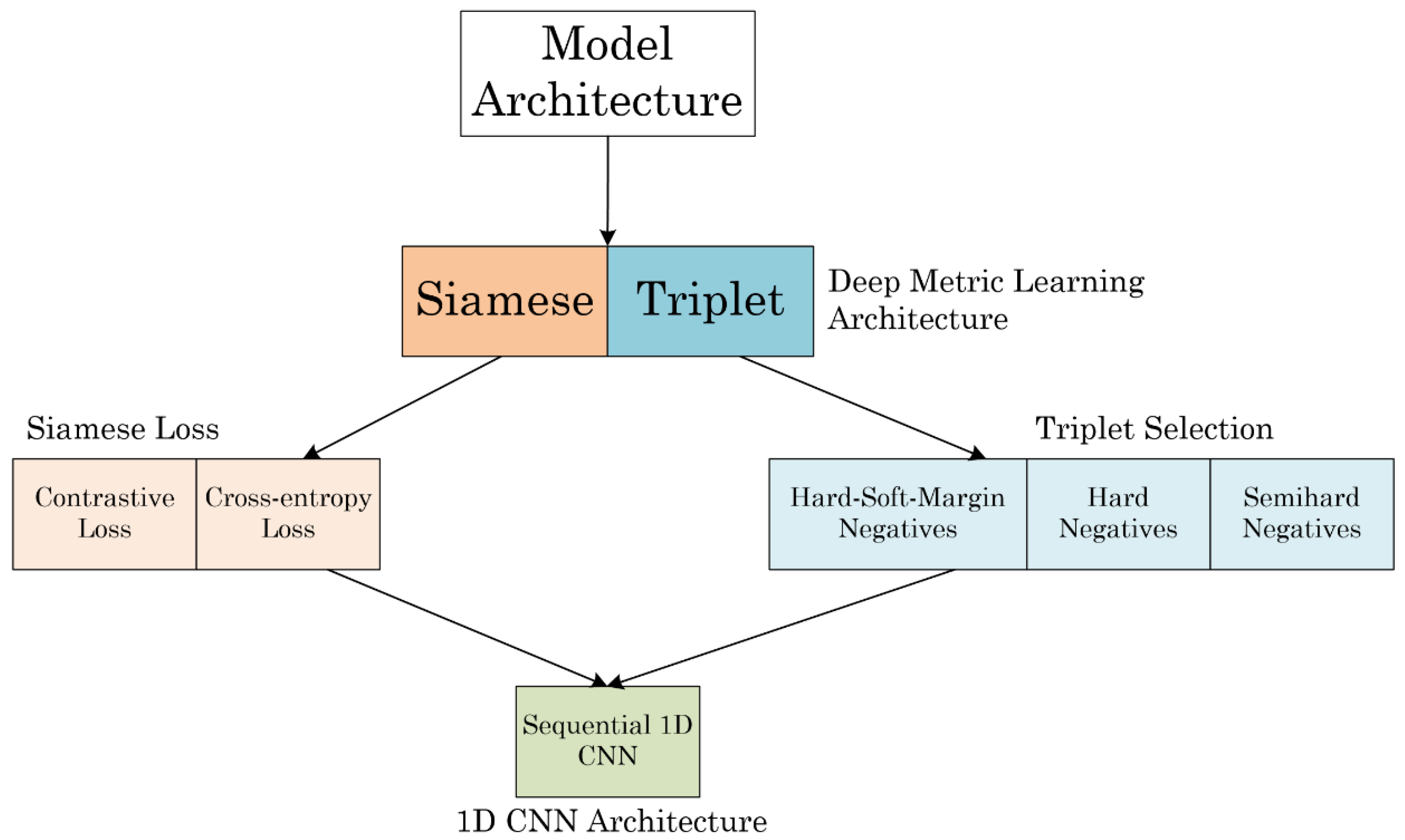
- We developed a DML method for stamping tool condition diagnosis that incorporates several distance metric loss and batch strategies.
- We investigated the performance of each distance metric loss and batch selection method.
- We investigated the robustness of each loss and mining method based on the degree of training data variation, noise injection, and capability of adding new classes.
2. Materials and Methods
2.1. Metric Learning and Deep Metric Learning (DML)
- (1)
- Negativity: ,
- (2)
- Symmetry: ,
- (3)
- Triangular inequality: ,
- (4)
- Identity of indiscernible: .
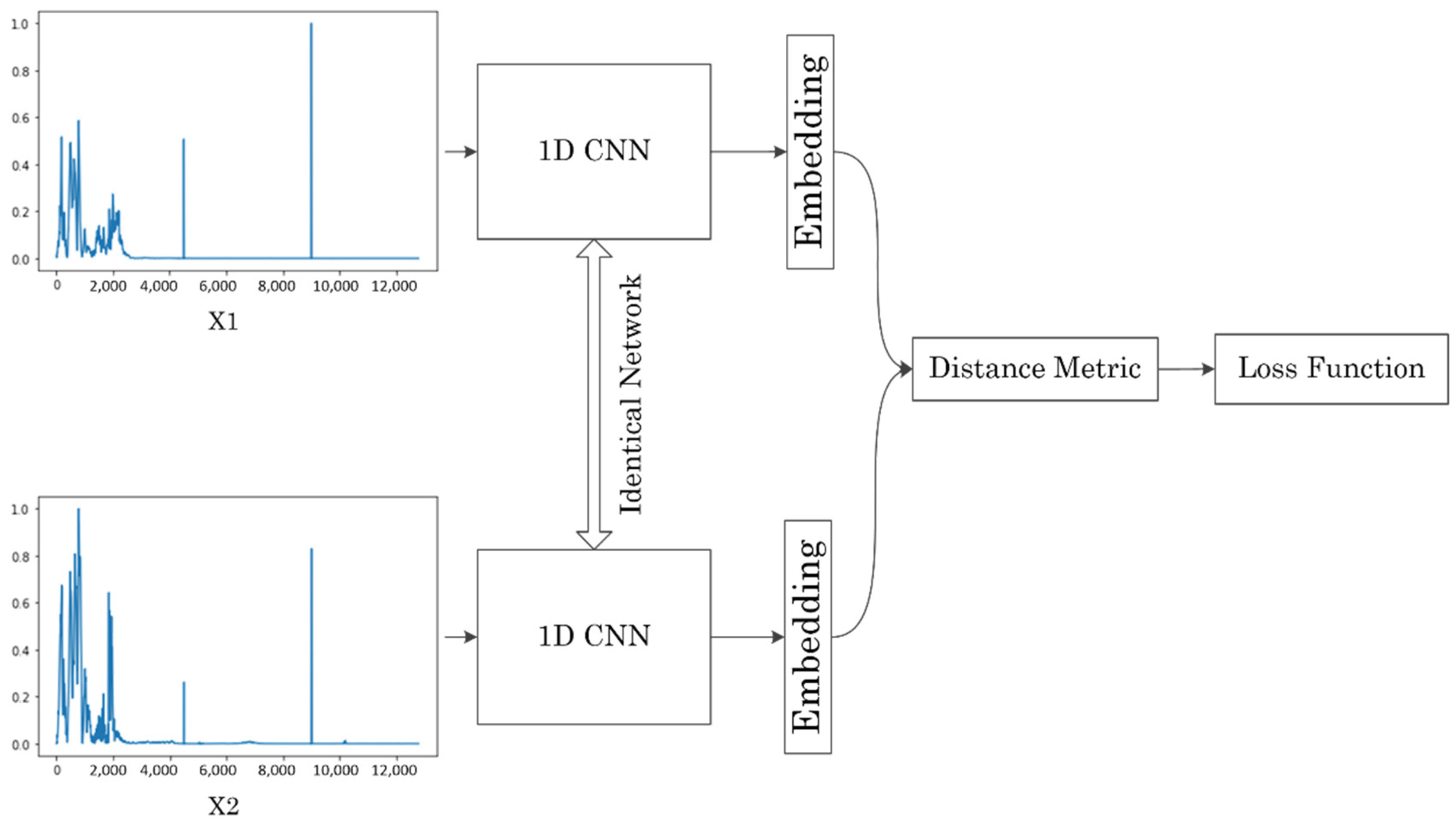
2.2. Siamese Neural Network
2.2.1. Probability Method
2.2.2. Contrastive Method
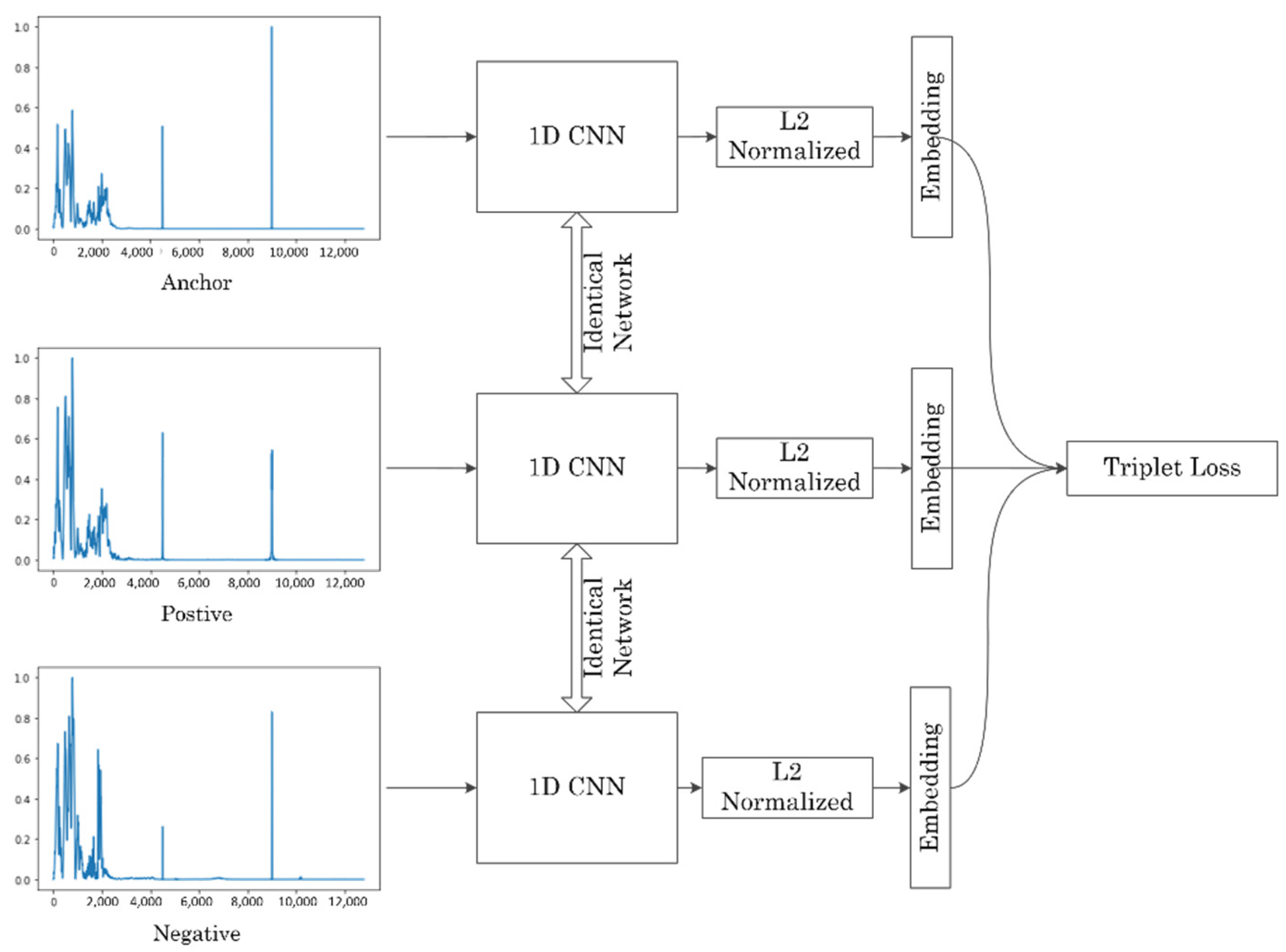
2.3. Triplet Network
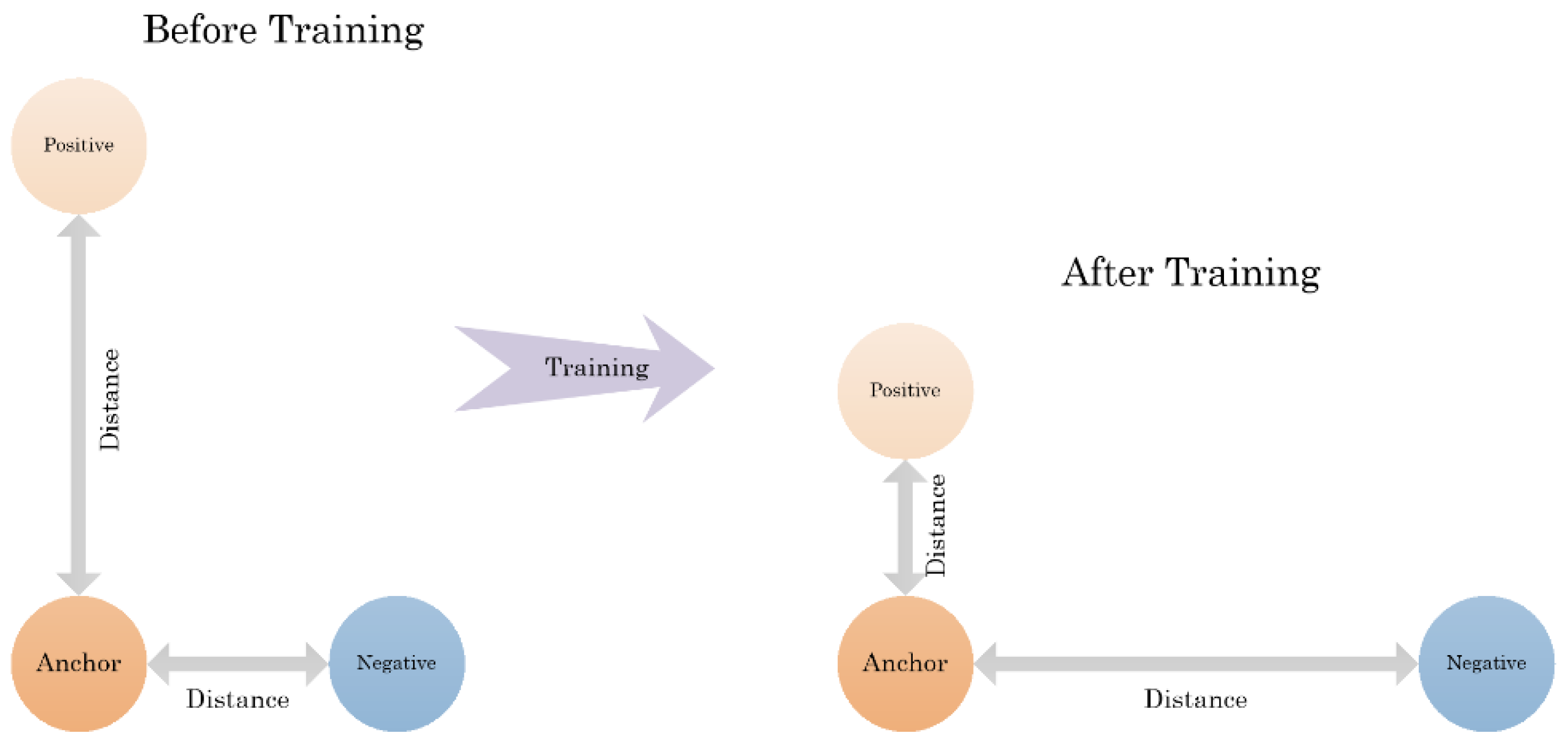
2.3.1. Triplet Loss
2.3.2. Triplet Selection
2.3.3. Hard Triplet Soft Margin
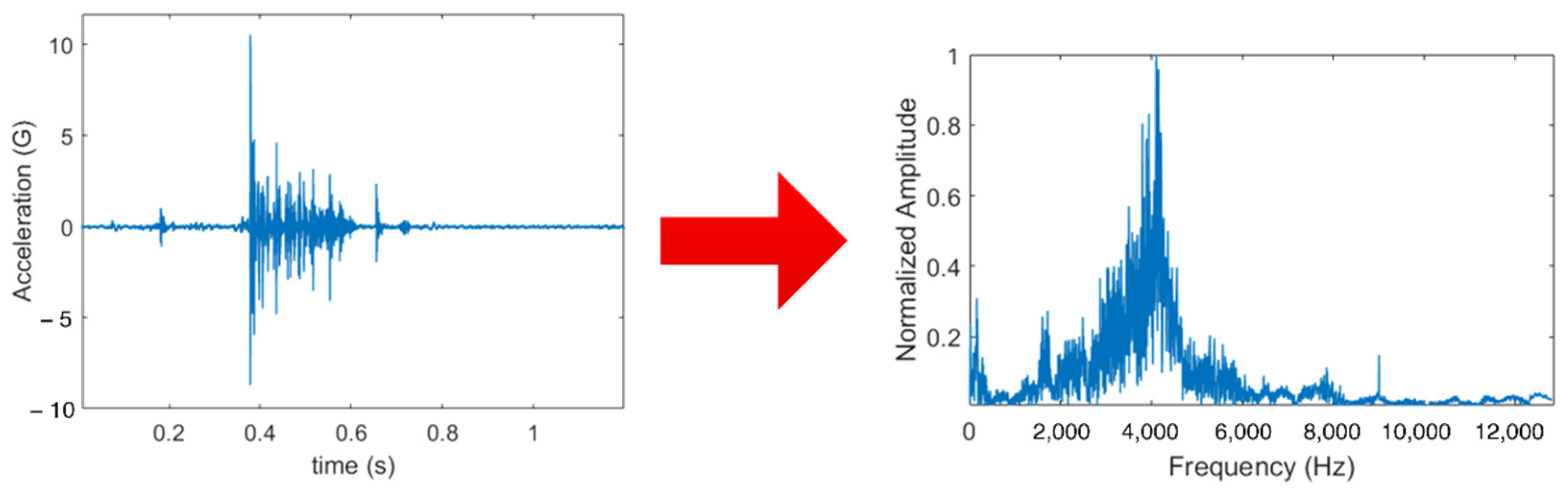
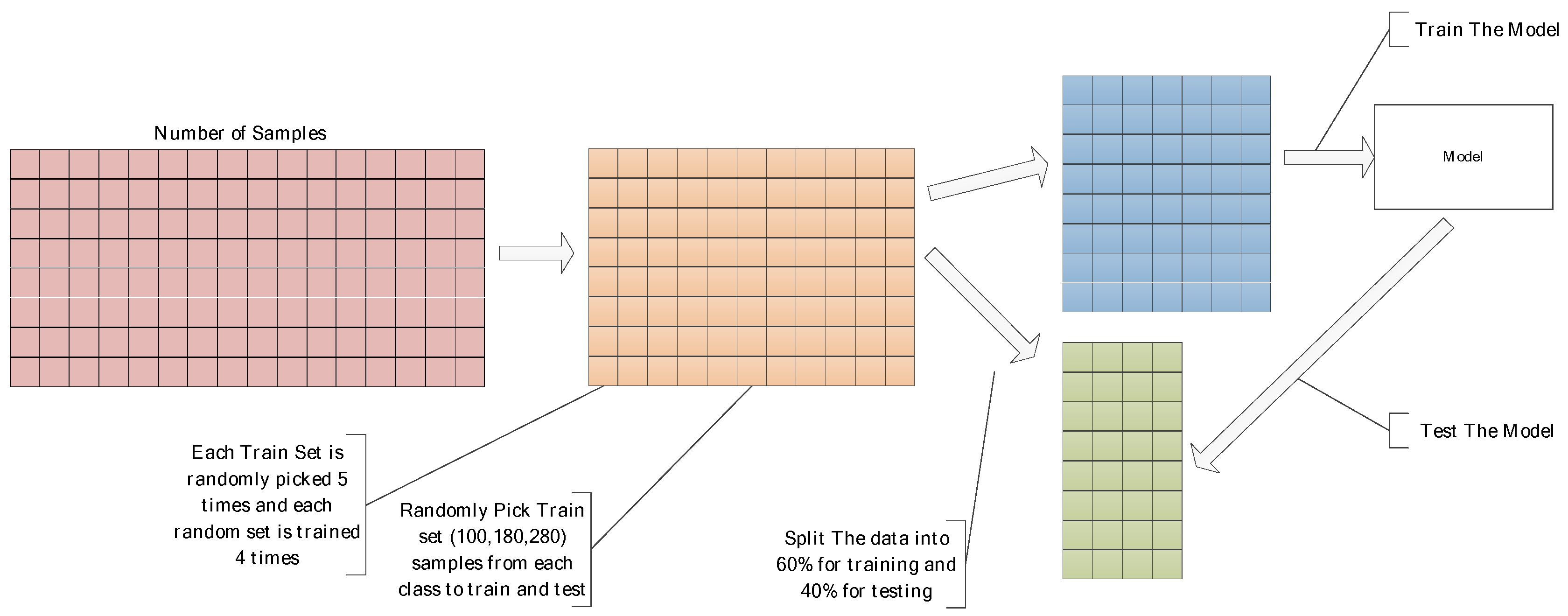
2.4. Dataset
2.5. One-Shot K-Way Testing
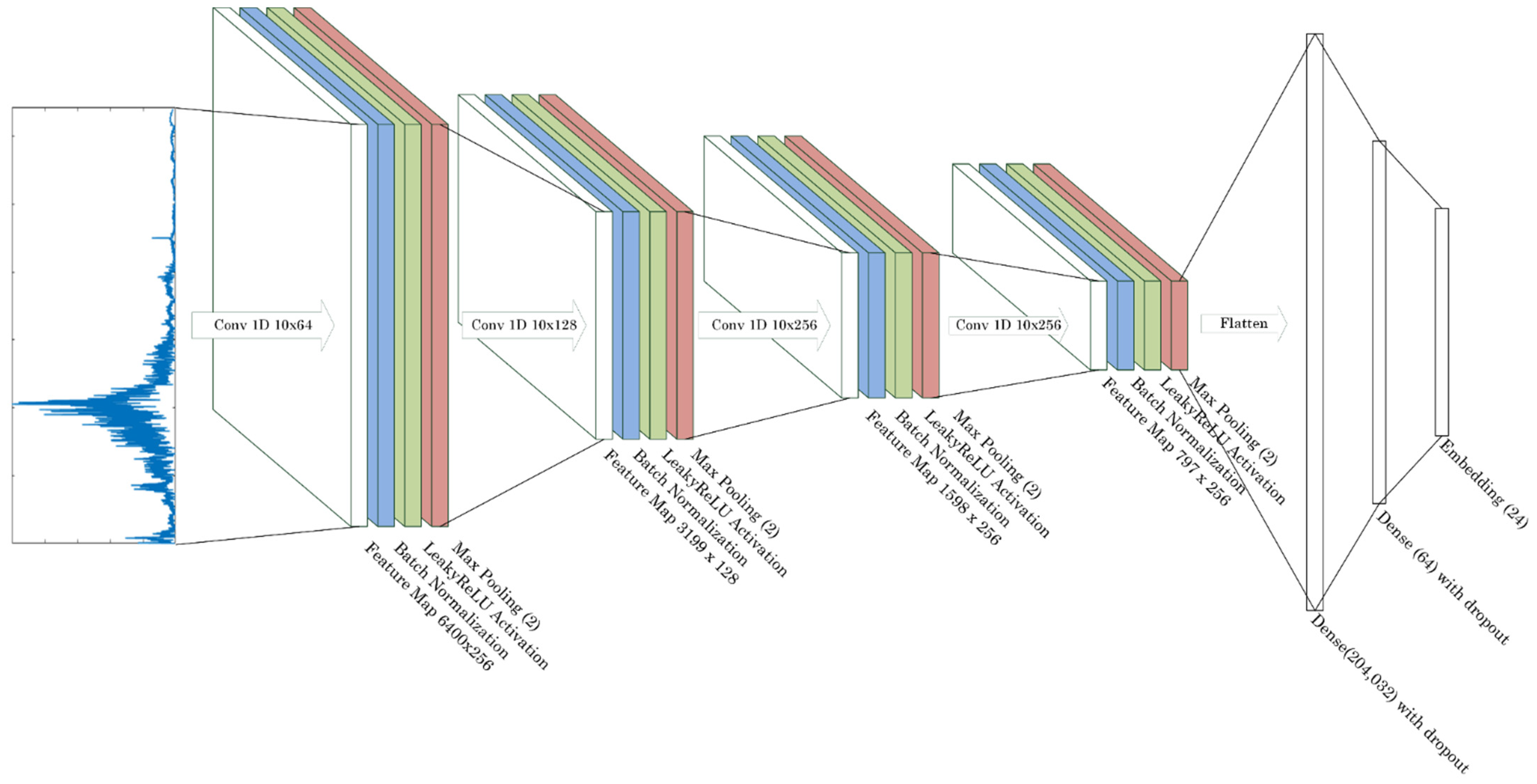
2.6. 1D CNN Architecture
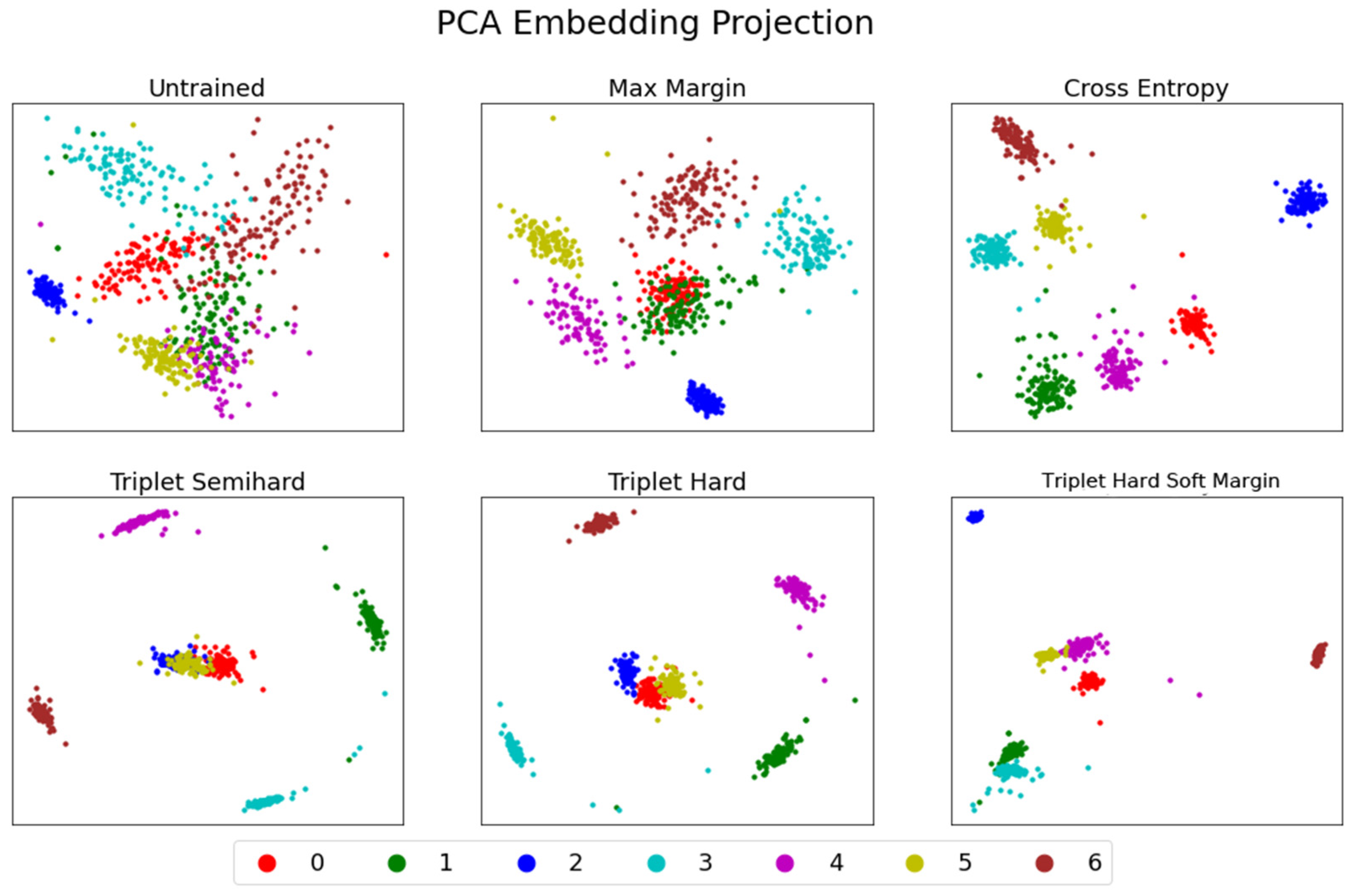
3. Results and Discussions
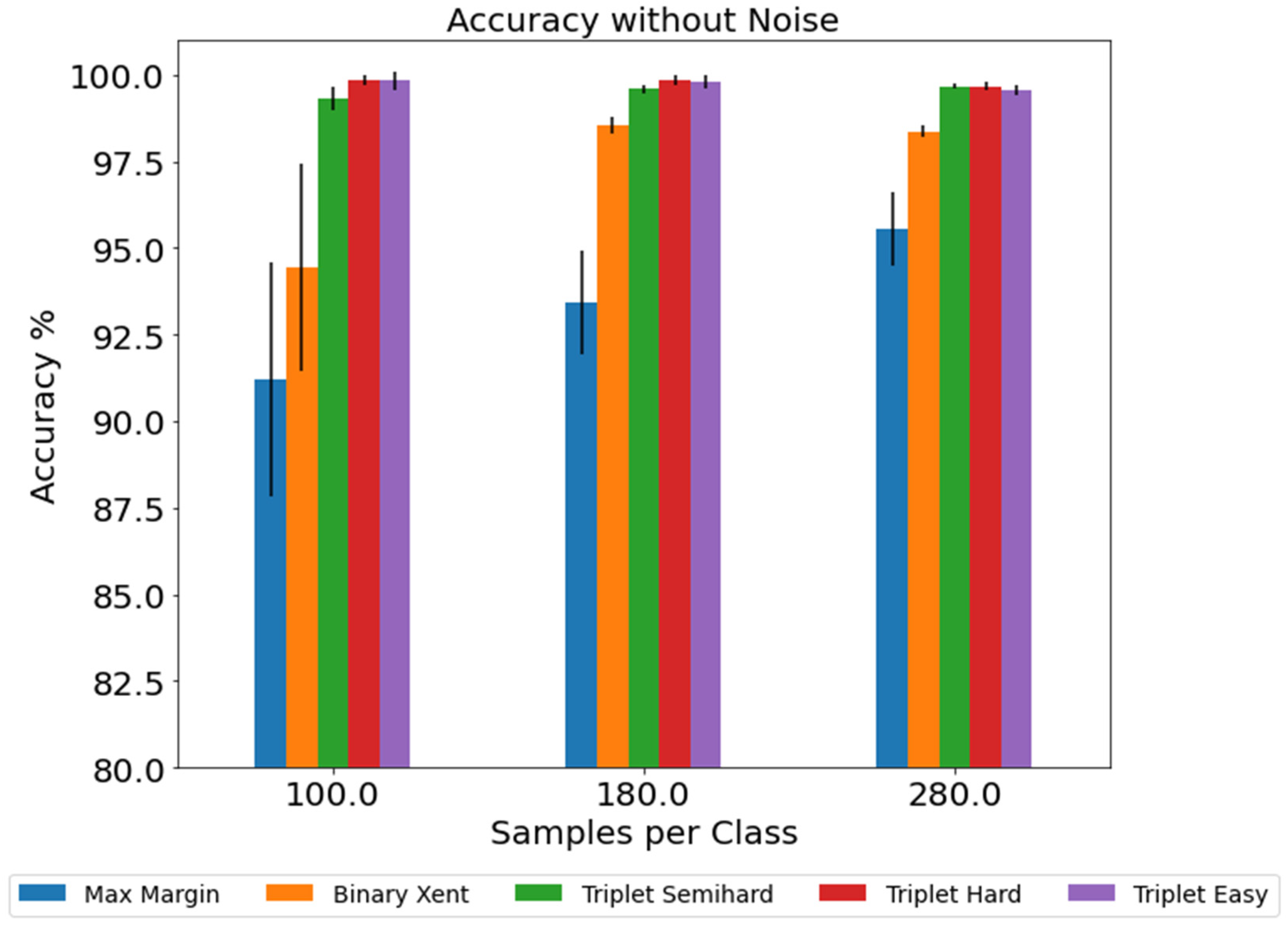
3.1. Model Performance According to The Number of Training Samples
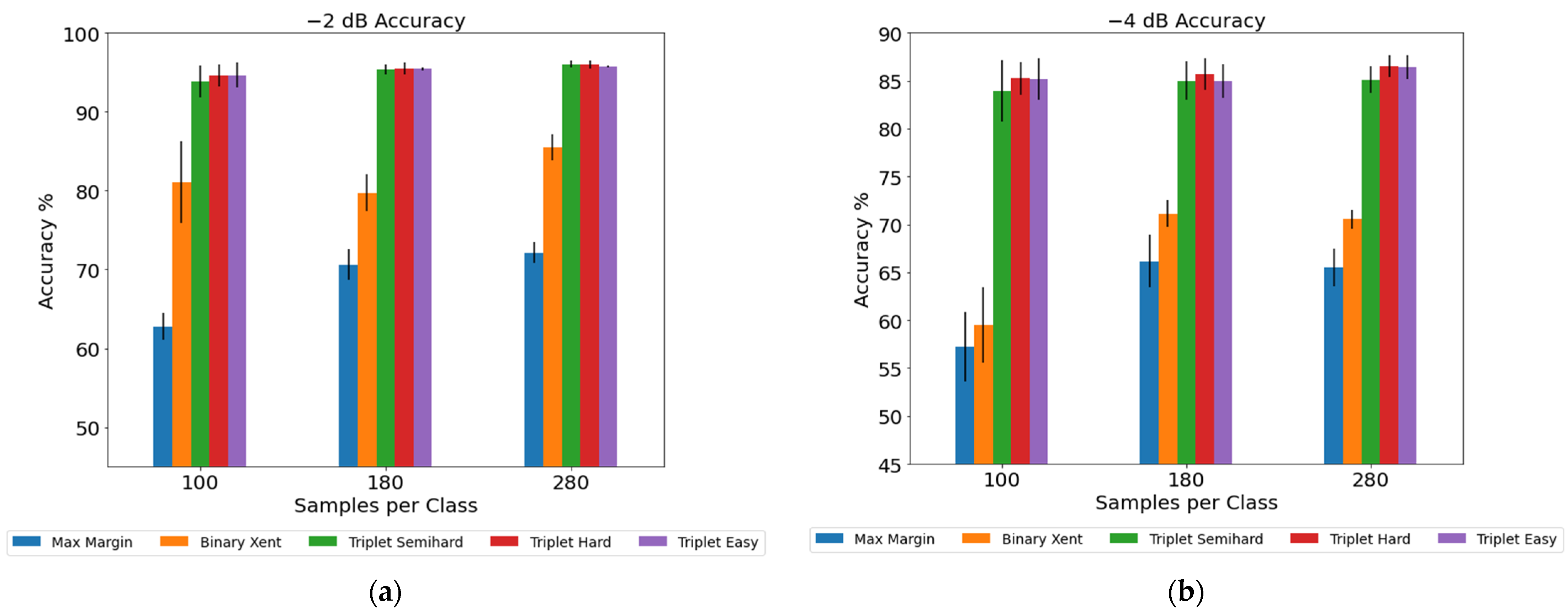
3.2. Model Performance under Noised Test Samples
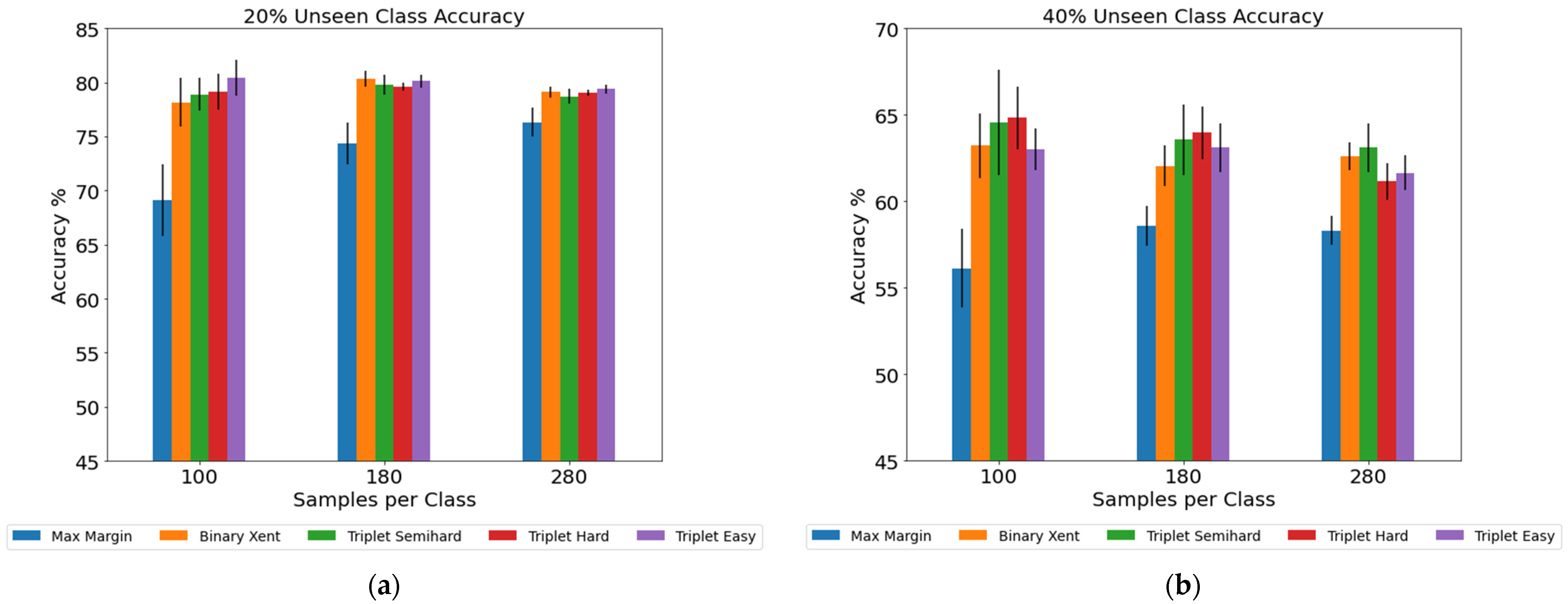
3.3. Performance under New Classes
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Industrial Metal Stamping Continues to Grow in 2019–2020. Available online: http://www.americanindust.com/blog/metal-stamping-continues-to-grow-2019-2020/ (accessed on 25 January 2021).
- Ambhore, N.; Kamble, D.; Chinchanikar, S.; Wayal, V. Tool Condition Monitoring System: A Review. Mater. Today Proc. 2015, 2, 3419–3428. [Google Scholar] [CrossRef]
- Ge, M.; Du, R.; Xu, Y. Hidden Markov Model Based Fault Diagnosis for Stamping Processes. Mech. Syst. Signal Process. 2004. [Google Scholar] [CrossRef]
- Bassiuny, A.M.; Li, X.; Du, R. Fault Diagnosis of Stamping Process Based on Empirical Mode Decomposition and Learning Vector Quantization. Int. J. Mach. Tools Manuf. 2007, 47, 2298–2306. [Google Scholar] [CrossRef]
- Ubhayaratne, I.; Pereira, M.P.; Xiang, Y.; Rolfe, B.F. Audio Signal Analysis for Tool Wear Monitoring in Sheet Metal Stamping. Mech. Syst. Signal Process. 2017, 85, 809–826. [Google Scholar] [CrossRef]
- Shanbhag, V.V.; Rolfe, B.F.; Pereira, M.P. Investigation of Galling Wear Using Acoustic Emission Frequency Characteristics. Lubricants 2020, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Shanbhag, V.V.; Pereira, P.M.; Rolfe, F.B.; Arunachalam, N. Time Series Analysis of Tool Wear in Sheet Metal Stamping Using Acoustic Emission. J. Phys. Conf. Ser. 2017, 896, 012030. [Google Scholar] [CrossRef] [Green Version]
- Sari, D.Y.; Wu, T.L.; Lin, B.T. Study of Sound Signal for Online Monitoring in the Micro-Piercing Process. Int. J. Adv. Manuf. Technol. 2018, 97, 697–710. [Google Scholar] [CrossRef]
- Ge, M.; Du, R.; Zhang, G.; Xu, Y. Fault Diagnosis Using Support Vector Machine with an Application in Sheet Metal Stamping Operations. Mech. Syst. Signal Process. 2004, 18, 143–159. [Google Scholar] [CrossRef]
- Zhang, G.; Li, C.; Zhou, H.; Wagner, T. Punching Process Monitoring Using Wavelet Transform Based Feature Extraction and Semi-Supervised Clustering. Procedia Manuf. 2018, 26, 1204–1212. [Google Scholar] [CrossRef]
- Zhou, C.; Zhang, W. A New Process Monitoring Method Based on Waveform Signal by Using Recurrence Plot. Entropy 2015, 17, 6379–6396. [Google Scholar] [CrossRef] [Green Version]
- Sah, S.; Gao, R.X. Process Monitoring in Stamping Operations through Tooling Integrated Sensing. J. Manuf. Syst. 2008, 27, 123–129. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep Learning and Its Applications to Machine Health Monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Guo, L.; Gao, H.; Hong, X.; Song, H. A New Bearing Fault Diagnosis Method Based on Modified Convolutional Neural Networks. Chin. J. Aeronaut. 2020, 33, 439–447. [Google Scholar] [CrossRef]
- Wu, J. Sensor Data-Driven Bearing Fault Diagnosis Based on Deep Convolutional Neural Networks and s-Transform. Sensors 2019, 19, 2750. [Google Scholar] [CrossRef] [Green Version]
- Eren, L.; Ince, T.; Kiranyaz, S. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Eren, L. Bearing Fault Detection by One-Dimensional Convolutional Neural Networks. Math. Probl. Eng. 2017, 2017, 8617315. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yang, H.; Yuan, X.; Shardt, Y.A.W.; Yang, C.; Gui, W. Deep Learning for Fault-Relevant Feature Extraction and Fault Classification with Stacked Supervised Auto-Encoder. J. Process Control 2020, 92, 79–89. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Gao, L.; Chen, W.; Li, P. Ensemble Deep Contractive Auto-Encoders for Intelligent Fault Diagnosis of Machines under Noisy Environment. Knowl. Based Syst. 2020, 196, 105764. [Google Scholar] [CrossRef]
- Zhao, X.; Jia, M.; Liu, Z. Semisupervised Deep Sparse Auto-Encoder With Local and Nonlocal Information for Intelligent Fault Diagnosis of Rotating Machinery. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Mallak, A.; Fathi, M. Sensor and Component Fault Detection and Diagnosis for Hydraulic Machinery Integrating LSTM Autoencoder Detector and Diagnostic Classifiers. Sensors 2021, 21, 433. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A Sparse Auto-Encoder-Based Deep Neural Network Approach for Induction Motor Faults Classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, L. A Two-Stage Approach for Predicting the Remaining Useful Life of Tools Using Bidirectional Long Short-Term Memory. Measurement 2020, 164, 108029. [Google Scholar] [CrossRef]
- Liang, J.; Wang, L.; Wu, J.; Liu, Z.; Yu, G. Elimination of End Effects in LMD by Bi-LSTM Regression Network and Applications for Rolling Element Bearings Characteristic Extraction under Different Loading Conditions. Digit. Signal Process. 2020, 107, 102881. [Google Scholar] [CrossRef]
- Jalayer, M.; Orsenigo, C.; Vercellis, C. Fault Detection and Diagnosis for Rotating Machinery: A Model Based on Convolutional LSTM, Fast Fourier and Continuous Wavelet Transforms. Comput. Ind. 2021, 125, 103378. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep-Convolution-Based LSTM Network for Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2021, 17, 1658–1667. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to Monitor Machine Health with Convolutional Bi-Directional LSTM Networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.-Y.; Dzulfikri, Z. Stamping Monitoring by Using an Adaptive 1D Convolutional Neural Network. Sensors 2021, 21, 262. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. In Proceedings of the 6th International Conference on Neural Information Processing Systems, Virtual-Only, 6–12 December 2020; Available online: https://dl.acm.org/doi/10.5555/2987189.2987282 (accessed on 24 July 2021).
- Ahmed, S.; Basher, A.; Reza, A.N.R.; Jung, H.Y. A Brief Overview of Deep Metric Learning Methods; Korea Next Generation Computing Society: Jeju, Korea, 2018; Volume 4, p. 5. [Google Scholar]
- Kaya, M.; Bilge, H.Ş. Deep Metric Learning: A Survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef] [Green Version]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q. A Robust Intelligent Fault Diagnosis Method for Rolling Element Bearings Based on Deep Distance Metric Learning. Neurocomputing 2018, 310, 77–95. [Google Scholar] [CrossRef]
- Wang, S.; Wang, D.; Kong, D.; Wang, J.; Li, W.; Zhou, S. Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors 2020, 20, 6437. [Google Scholar] [CrossRef]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited Data Rolling Bearing Fault Diagnosis with Few-Shot Learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Liu, J.; Gibson, S.J.; Mills, J.; Osadchy, M. Dynamic Spectrum Matching with One-Shot Learning. Chemom. Intell. Lab. Syst. 2019, 184, 175–181. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv Preprint 2017, arXiv:1703.07737. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Class Type | Number of Samples |
|---|---|---|
| Healthy Condition | Class 1 | 280 |
| Heavy Wear Position A | Class 2 | 280 |
| Heavy Wear Position B | Class 3 | 280 |
| Heavy Wear Position C | Class 4 | 280 |
| Mild Wear Position A | Class 5 | 280 |
| Mild Wear Position B | Class 6 | 280 |
| Mild Wear Position C | Class 7 | 280 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dzulfikri, Z.; Su, P.-W.; Huang, C.-Y. Stamping Tool Conditions Diagnosis: A Deep Metric Learning Approach. Appl. Sci. 2021, 11, 6959. https://doi.org/10.3390/app11156959
Dzulfikri Z, Su P-W, Huang C-Y. Stamping Tool Conditions Diagnosis: A Deep Metric Learning Approach. Applied Sciences. 2021; 11(15):6959. https://doi.org/10.3390/app11156959
Chicago/Turabian StyleDzulfikri, Zaky, Pin-Wei Su, and Chih-Yung Huang. 2021. "Stamping Tool Conditions Diagnosis: A Deep Metric Learning Approach" Applied Sciences 11, no. 15: 6959. https://doi.org/10.3390/app11156959
APA StyleDzulfikri, Z., Su, P.-W., & Huang, C.-Y. (2021). Stamping Tool Conditions Diagnosis: A Deep Metric Learning Approach. Applied Sciences, 11(15), 6959. https://doi.org/10.3390/app11156959