1. Introduction
The electrocardiogram (ECG), the electrical activity of the heart, has been studied extensively because of its high relevance in clinical practice. In most cases, it can provide insights into the heart condition. Common but important events physicians track are the arrhythmias, which are any disturbance in rate, regularity, site of origin, or conduction of the heart signal activity. An arrhythmia can be a single aberrant beat or a sustained rhythmic disturbance that can be present through a time period. The ECG is the best tool to diagnose these irregularities from the heart signals [
1].
ECG signal is represented in a waveform graph shape, and it is considered the heart’s primary source of information, as well as the primary source for detection of cardiac irregularities [
2]. An arrhythmia may lead to severe heart disease such as atrial premature contraction (APC), premature ventricular contraction (PVC), right bundle branch block (RBBB), etc. [
3,
4]. At present, a topic that is becoming highly relevant in the application of deep learning (AI) in health are the so-called computer-aided detection (CADe) and diagnosis (CADx) in which, through a system based on recognition of patterns in images, meaning lesions in complex structures can be identified and classified through the different shapes and intensity levels in the pixels; some examples of this are the CADe/CADx systems developed for detection of lung and breast cancer, colonoscopy, etc. [
5,
6,
7,
8], but there are still no applications thus far for the classification and diagnosis of cardiac arrhythmias.
As an example of arrhythmia, we have the ventricular extrasystoles, which are a reflection of the activation of the ventricles from a site below the AV node. Its outcome is linked to an underlying disease, and there could be three causes for it: reentry, increased automatism, and triggered activity.
The increased automatism suggests an ectopic group of cells in the ventricle. This process is the underlying mechanism of arrhythmias secondary to hyperkalemia. Reentry occurs in patients with underlying scarring ischemic heart disease or myocardial ischemia. This mechanism can produce isolated ectopic beats or trigger ventricular tachycardia and eventually sudden cardiac death [
9,
10]. Moreover, nowadays, a new trend is emerging in the deep learning (DL))-based ECG heartbeat classification, and several scientists present their efforts in this field. Although extensive experimental work is carried out on this topic, it is not suitable yet for real-time scenarios. Their approaches are not optimally efficient to cover the inter-patient variability issue in ECG signals [
11,
12].
Although ECG signals have been used for diagnosis for over a century, manually tracking these arrhythmias over even a thousand heartbeats is an infeasible task, even for expert physicians, because of the amount of time required to perform such endeavors. These kinds of tasks require automated mechanisms to detect and classify all these events. This is why AI is now an extremely relevant and important part of the algorithms for automated learning in electrocardiographic signals [
13,
14,
15].
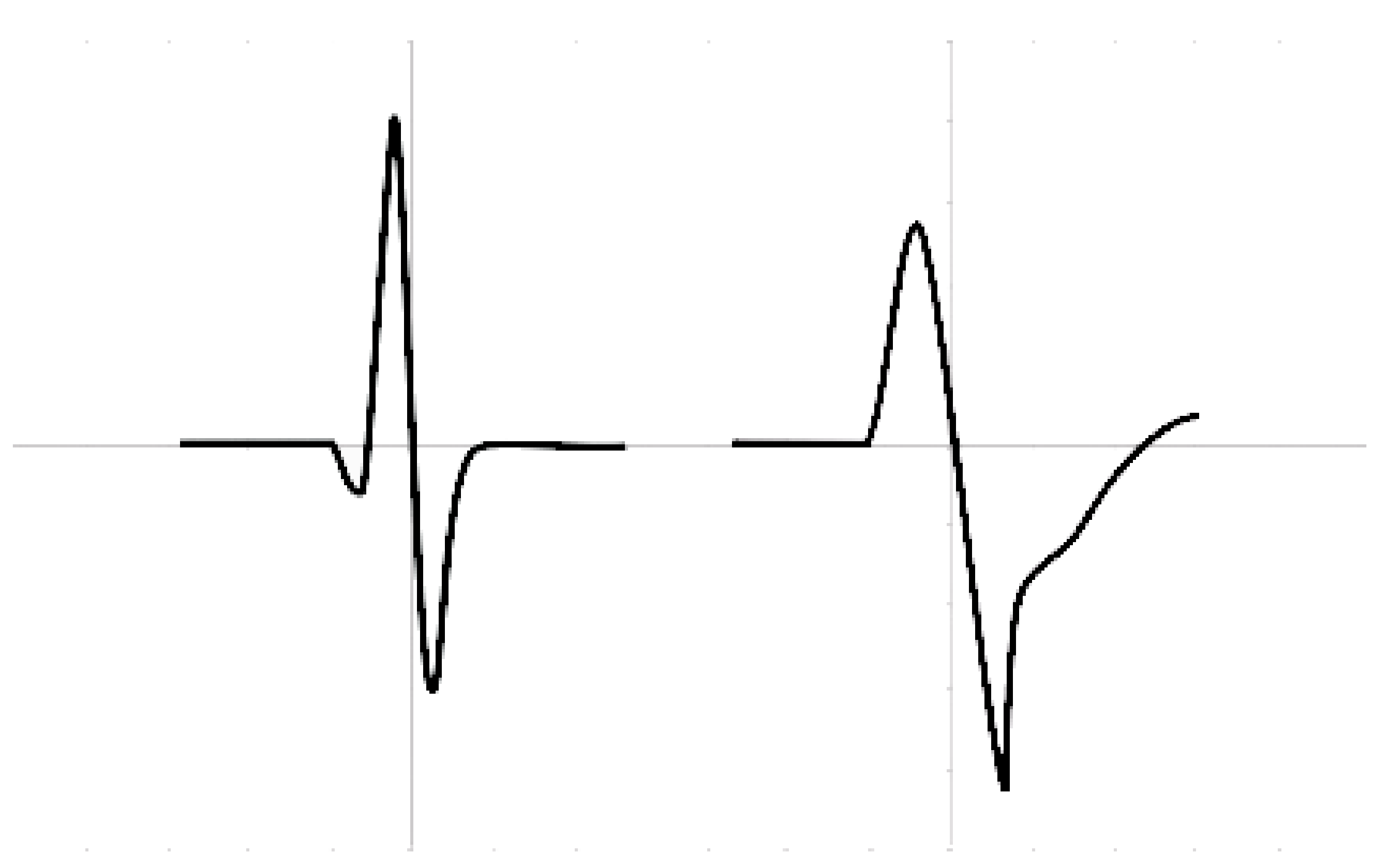
On an ECG, rhythm refers to the part of the heart that is controlling the initiation of electrical activity. Under normal circumstances, the sinoatrial node (SAN) initiates electrical activity because it undergoes spontaneous depolarization first at a rate of 60–100 bpm. When a rhythm originates from above the ventricles in the atria, it is termed a supraventricular (SVB) rhythm (narrow QRS or <120 ms), and when a rhythm originates from within the ventricles, it is termed a ventricular (VB) rhythm (broad QRS or >120 ms); these characteristics are represented in
Figure 1.
The Association for the Advancement of Medical Instrumentation (AAMI) provides guidelines to classify heartbeats in an ECG signal into normal beats (N), supraventricular beats (SVB), ventricular beats (VB), fusion beats (FB), and unclassified beats (QB) [
16,
17]. However, because of their rarity in patients, the last two types of heartbeats are not usually included, and both QB and FB are relabeled simply as VB, leaving the task to classify only between NB, SVB, and VB.
An issue is the way research approaches the use of data sets. There are two accepted approaches to the problem, namely, inter- and intra-patient methodologies [
18].
Works related to the inter-patient paradigm have lower performance against intra-patient works because of the use of different patients’ heartbeats in training, validation, and testing sets. However such works reflect the reality accurately since the inevitable variabilities among patients are incorporated in their results.
In this research, we present a review of previous work wherein it is shown that until nowm it has not been possible to overcome the variabilities among patients and train a generalized model from the databases available. The guidance of a physician is still needed to develop a patient adaptive model. This means that in the future, physicians would need to label new data because the signal for every individual patient changes in shape and heart rate, and the old parameters of the algorithm may need to be updated.
In this article, a novel unsupervised method is introduced that classifies between beats of supraventricular origin (SVBo), formed by the NB and SVB classes, and beats of ventricular origin (VBo), formed by the VB and FB. This approach does not require the assistance of a physician since it tries to capture the inherent patterns in the signal, and it uses heartbeat features from previous works across patients. Based on our experiments, it was concluded that this methodology works best when they are at least 40 VBo. The present approach may be used as a first step to distinguish between the remaining NB and SVB in future experiments.
The silhouette coefficient was implemented in MATLAB and used at the beginning to evaluate the quality of the clustering based on some parameters. For the experiments, an algorithm for clustering was implemented in MATLAB, and since this is an adaptive model for self-organizing maps, meaning that we could not use the silhouette score in general, and we would have to use it for every particular case or patient, which would yield just a distribution with no information worth for our purposes, as explained in
Section 3.7, we chose between some parameters from the outcome that we derived from the comparison against the labels. In a future study with a modified algorithm, we aim to use the silhouette coefficient for the fine-tuning of the algorithm and better parameters.
2. Previous Research
Chazal et al. [
19] extracted features in the time domain including heart rate and waveform descriptors of the ECG signal on both leads available in the MITBIH Arrhythmia Database. They used a linear discriminant classifier that outperforms their past work at that time. Llamedo et al. [
20] presented a global classifier using the same training set as in Chazal et al. [
19] but included two more databases to further test their method. He used the heart rate and features extracted from discrete wavelet transforms. He tested various sets of features and two different Bayesian linear classifiers ending with the linear discriminant classifier. Llamedo et al. [
21] modified their past work to include more than two leads, using the same features and classifier. He used the INCART database in which every record has 12 leads. Using all the leads available, he outperformed their past work using this database. This is the only database available with 12 leads. Ye et al. [
22] classified all types of heartbeats in the MITBIH database using the AAMI classification scheme. The morphological features used are coefficients of DWT and the result of applying independent components analysis, reducing the dimensionality with principal components analysis. The heart rate was also used as a feature. The classifier used is a support vector machine that combines the two leads of the MITBIH database. Once the features are extracted, the patients’ heartbeats are used for training and testing resulting in overoptimistic results of nearly 100%. However, the same model trained and tested as Chazal et al. [
19] and Llamedo et al. [
20,
21] produced lower performance because of the variabilities among patients. Their results are comparable to Chazal et al. [
19] and Llamedo et al. [
20,
21]. Mar et al. [
23] principally worked on feature selection to classify ECG signals. They used a number of features in the temporal domain, morphological waveform features, statistical features, and features from the temporal–frequency domain using the DWT. The sequential forward floating search algorithm was used to determine relevant features, along with a linear discriminant classifier.
Once the optimal features are extracted, they are used to classify through a multilayer perceptron. The results are comparable to Chazal et al. [
19], Llamedo et al. [
20,
21], and Ye et al. [
22].
It is mentioned in [
24] that general classification models are highly unreliable with ECG signals and are not widely used in practice. In order to overcome this problem faced by the intra-patient methodology, an adaptive patient model may be more effective because the patterns within a single patient are much easier to capture than in the inter-patient methodology. Such work involves the use of a certain number of beats previously labeled by a physician to train a learning algorithm. Works presented in [
24,
25] obtain results above 95% in almost all the cases, and some very close to 100%, in both precision and recall for the AAMI types of heartbeats.
Only Llamedo et al. [
26] and Al Rahhal et al. [
27] showed results without initial expert labeling. Wiens et al. [
24] tested their algorithm developed using active learning with the same patients’ beats against the software from HAMILTON and with the advantage that it does not require data from the patient, but it only recognizes premature ventricular beats. Wiens et al. [
24] outperformed HAMILTON. Llamedo et al. [
26] modified their previous work in [
21], which uses a general classifier by including a clustering algorithm, the K-means method. This modification slightly improves the performance, compared to their previous work, and also allows an expert to contribute to the output of the algorithm. The final results are around 95% with the help of the expert for each patient record. Al Rahhal et al. [
27] used active classification through the deep learning approach. They suppressed the low frequency parts of the heartbeat and processed those employing an autoencoder algorithm to represent the signal in a lower dimension. A final softmax function is recorded similar to that in Chazal et al. [
19], Llamedo et al. [
20,
21,
27], Ye et al. [
22], and Mar et al. [
23]. Their results with beats labeled by an expert is close to 100% for every database they tested, while the automatic results when they used only the trained algorithm are much lower, representing the variability among patients. The only drawback is that a physician is needed to locate these labels on the ECG signal and as the heart’s beats rhythm and signals may change over time, future relabeling may be required to tune the trained model. Other interesting and related approaches are proposed in [
15,
28,
29,
30]; these deal with abnormalities in ECG segments based on supervised learning.
3. Materials and Methods
3.1. ECG Databases
All experiments were performed using selected records from public databases available in Physionet [
31]. Each database has different files that correspond to the digitized signals, the information about the patients’ annotations, and the labels for heartbeats in the records. The following databases were used:
- (a)
MIT-BIH Arrhythmia database (MITBIH), consisting of 48 half-hour signals recorded with two channels each one sampling at 360 samples per second with 11-bit resolution over 10 mV. The annotations for each heartbeat were made by cardiologists.
- (b)
MIT-BIH Supraventricular Arrhythmia database (SUPRA), made up of 78 records, each 30 min long. Each record has two-lead signals, sampled at 120 Hz, with annotation files produced automatically first and then corrected by a medical student.
- (c)
St. Petersburg Institute of Cardiological Technics (INCART) 12-lead Arrhythmia database, built up of 75 annotated records, each consisting of 12-lead signals sampled at 257 Hz for 30 min.
Following the labels suggested by the AAMI and the subsequent classification proposed in Llamedo and other works [
20,
21,
26], the heartbeats were relabeled to NB, SB, and VB. For the purpose of this first unsupervised work, the later labels were changed to their anatomic origin in the heart as SVBo and VBo.
3.2. Summary Approach
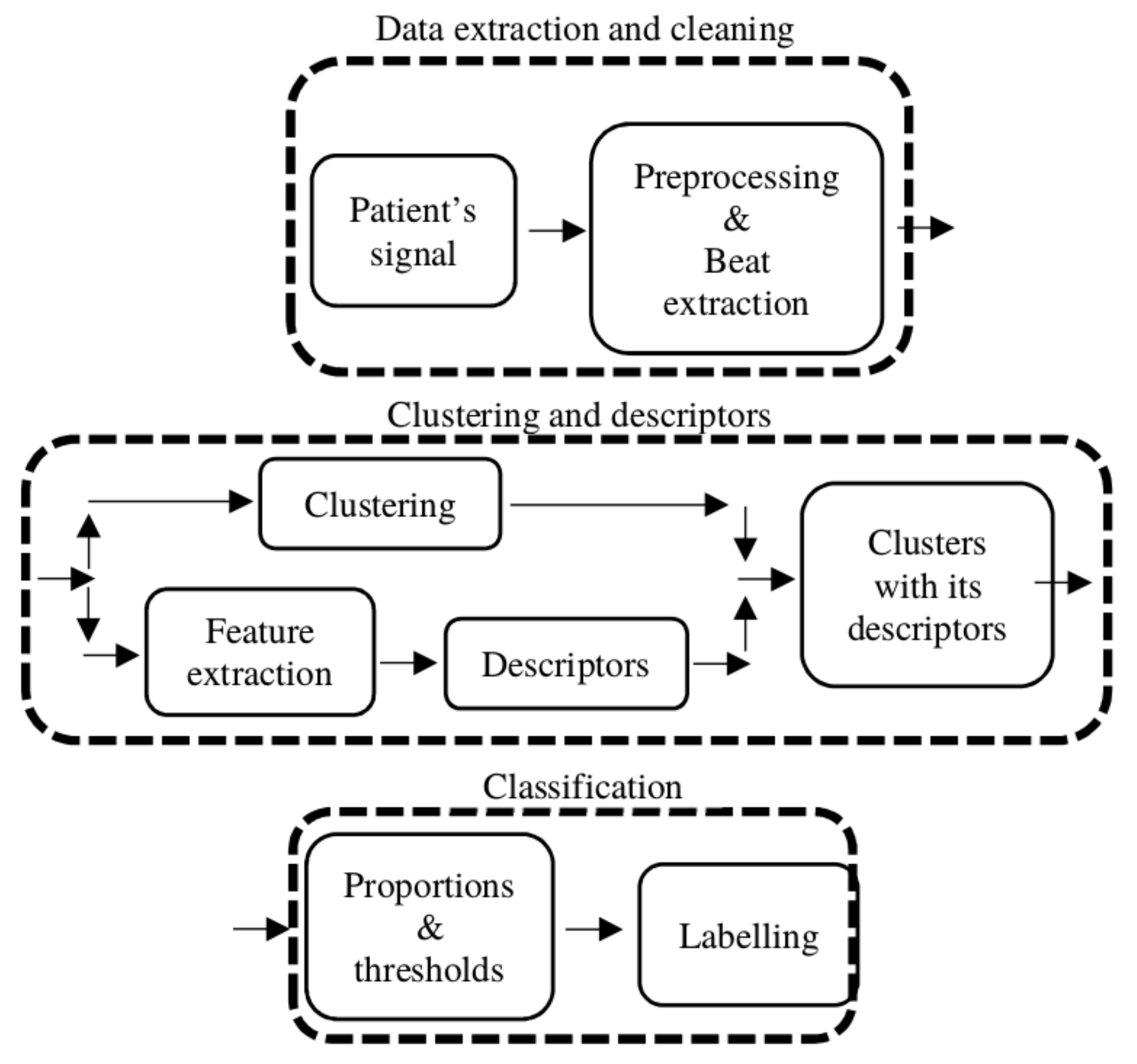
The algorithm requires a series of preprocessing and processing steps in order to cluster and distinguish the beats of supraventricular and ventricular origin.
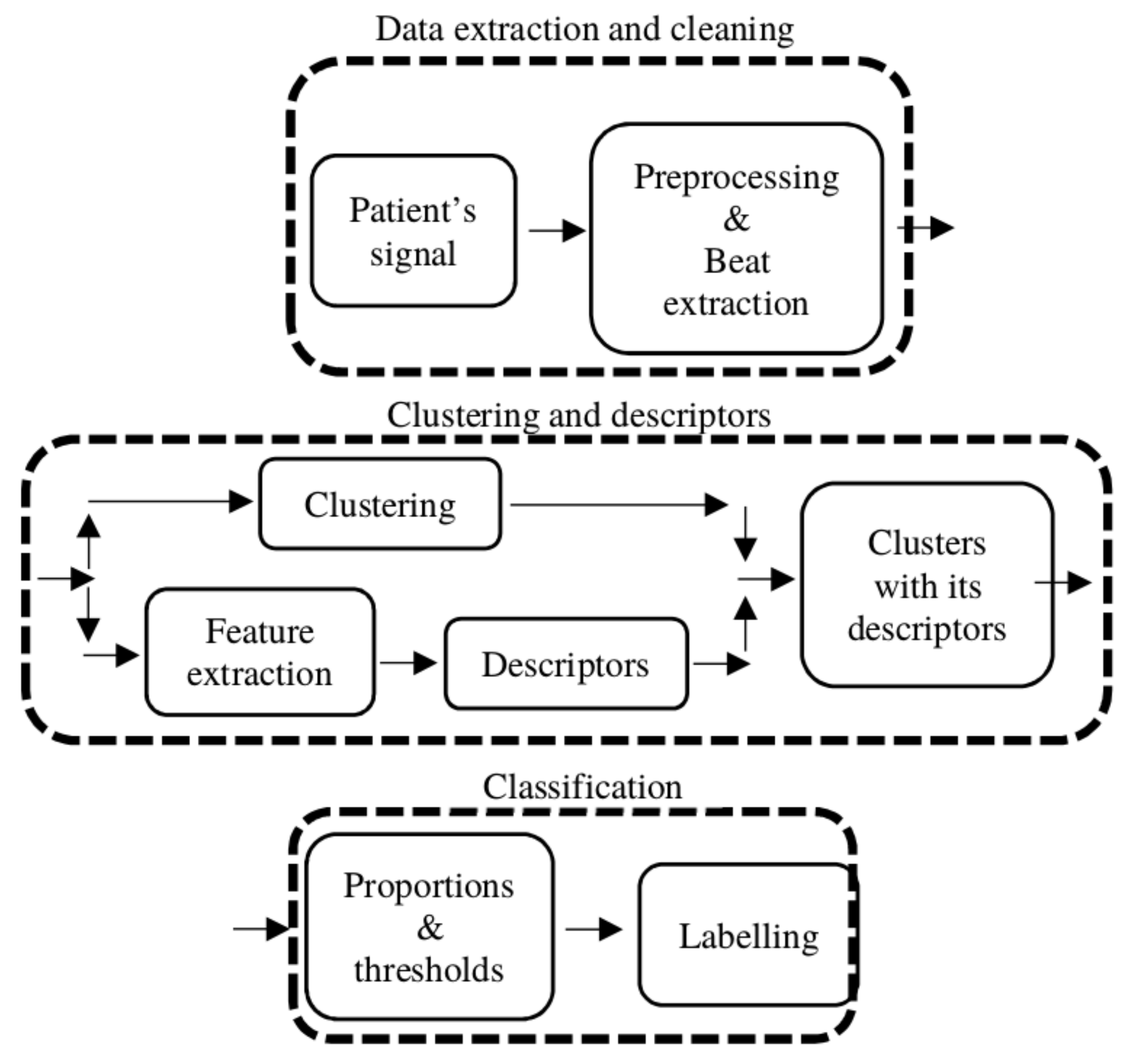
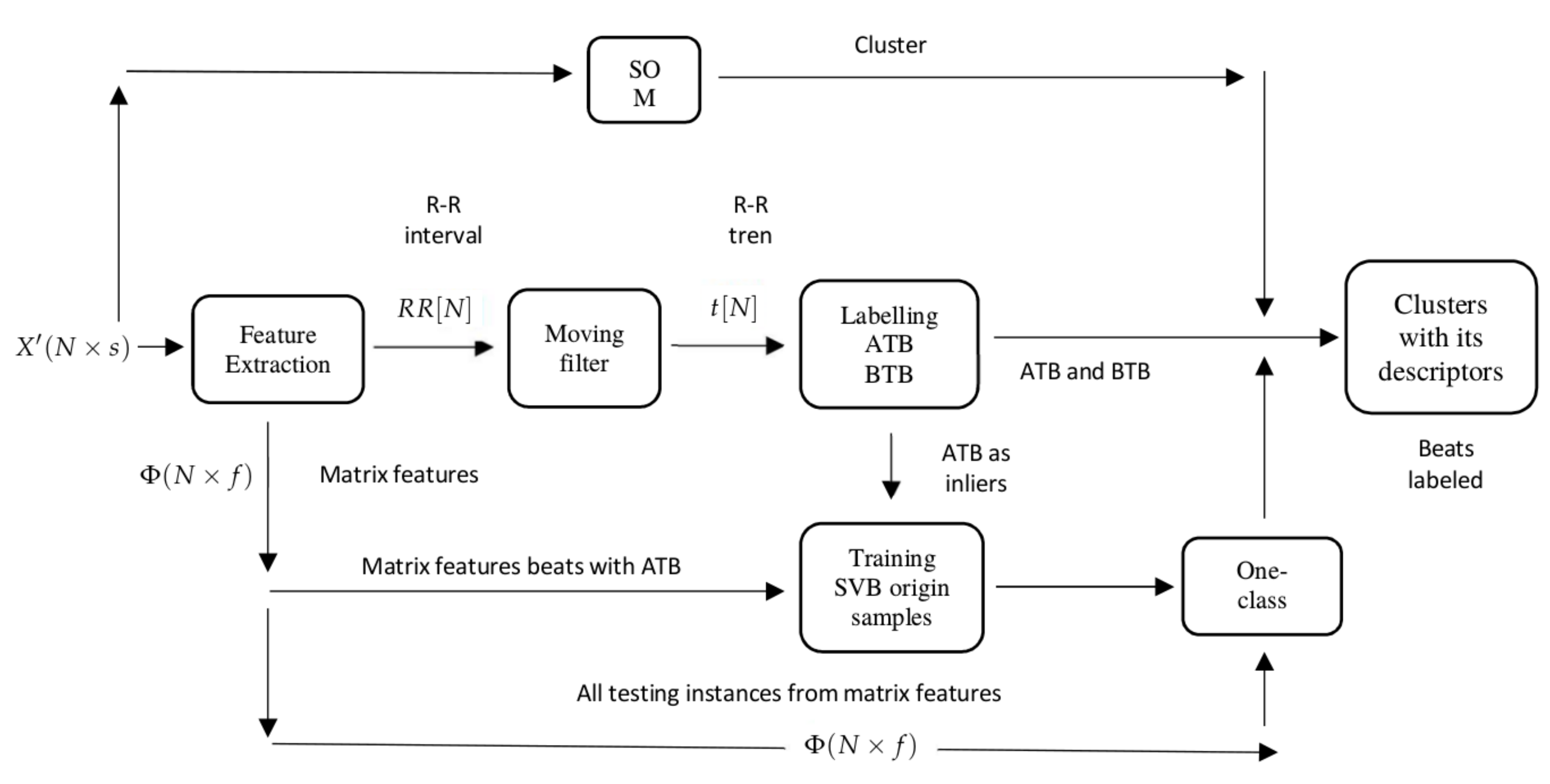
Figure 2 provides a high-level illustration of the processing pipeline divided into stages. In the first stage, Data extraction and cleaning, the patient signal is preprocessed and every beat of each record is sliced to form a matrix to work on. In stage 2, Clustering and descriptors, the clustering is performed and a set of different descriptors are computed to characterize each cluster (the expanded version of this stage is shown in
Figure 3). The labeling processing is in stage 3, Classification, where the descriptors are used to compute a series of proportions for each cluster, and if these proportions reach a certain threshold, the cluster is classified as SVBo; otherwise, it is classified as VBo.
Three important assumptions for the algorithm are as follows:
- (a)
With a significant number of VBo, the clustering algorithm is able to separate the signals;
- (b)
If a trend is computed on the R–R interval signal, almost all the beats above this trend are going to be SVBo and most of the VBo occur below the trend, along with the rest of SVBo;
- (c)
In the feature space, the SVBo signals are grouped together because they share similar waveform shapes, and the VBo signals are spread all over the feature space.
These assumptions were used to compute the descriptors and subsequently the proportions for the labeling of the clusters.
3.3. Data Extraction and Cleaning
The preprocessing of the signals is an important task to allow the extraction of useful information from them and for further analysis. The following four preprocessing procedures were performed:
- (a)
Baseline wander removal;
- (b)
Beat extraction;
- (c)
Normalization;
- (d)
Resample of signals.
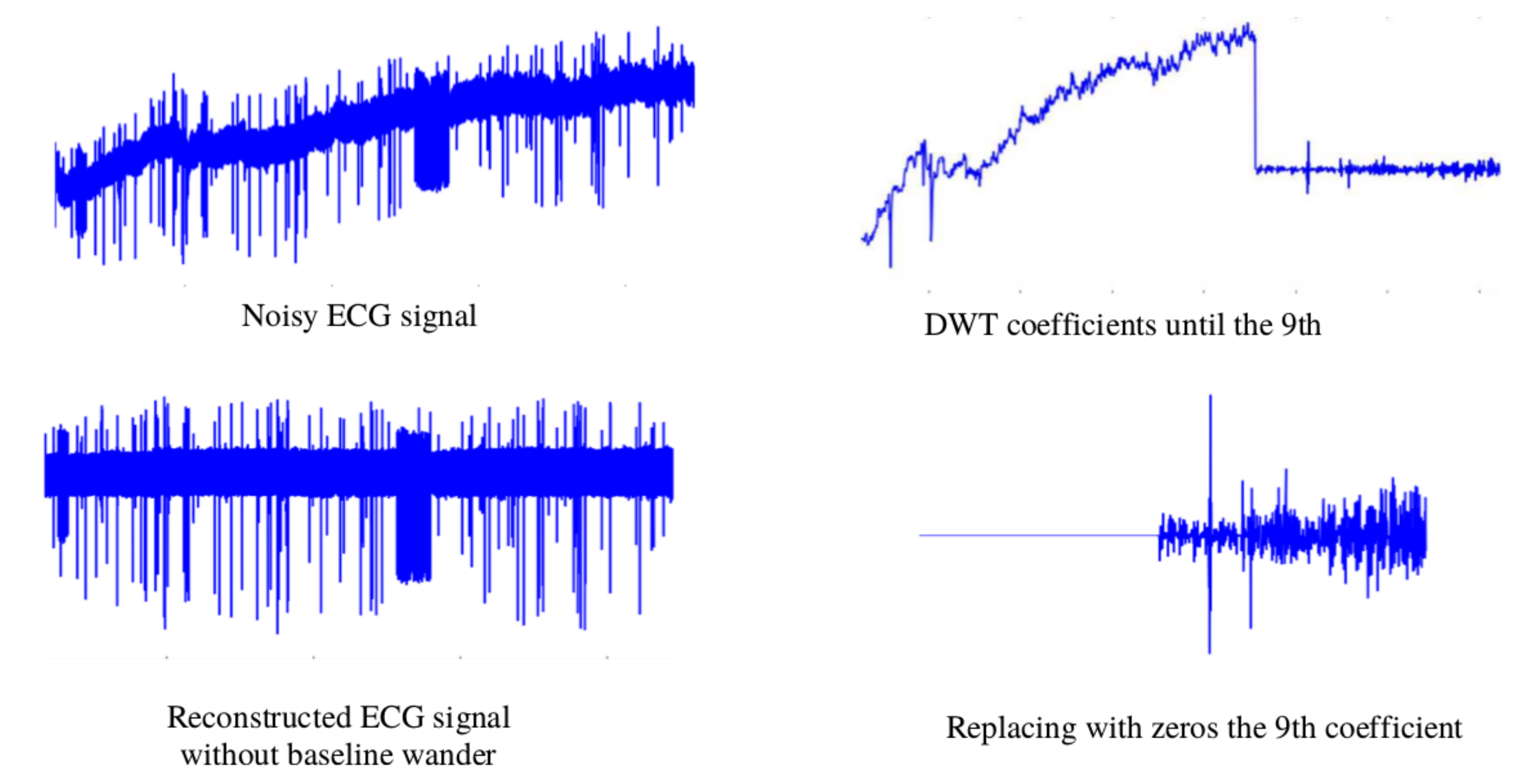
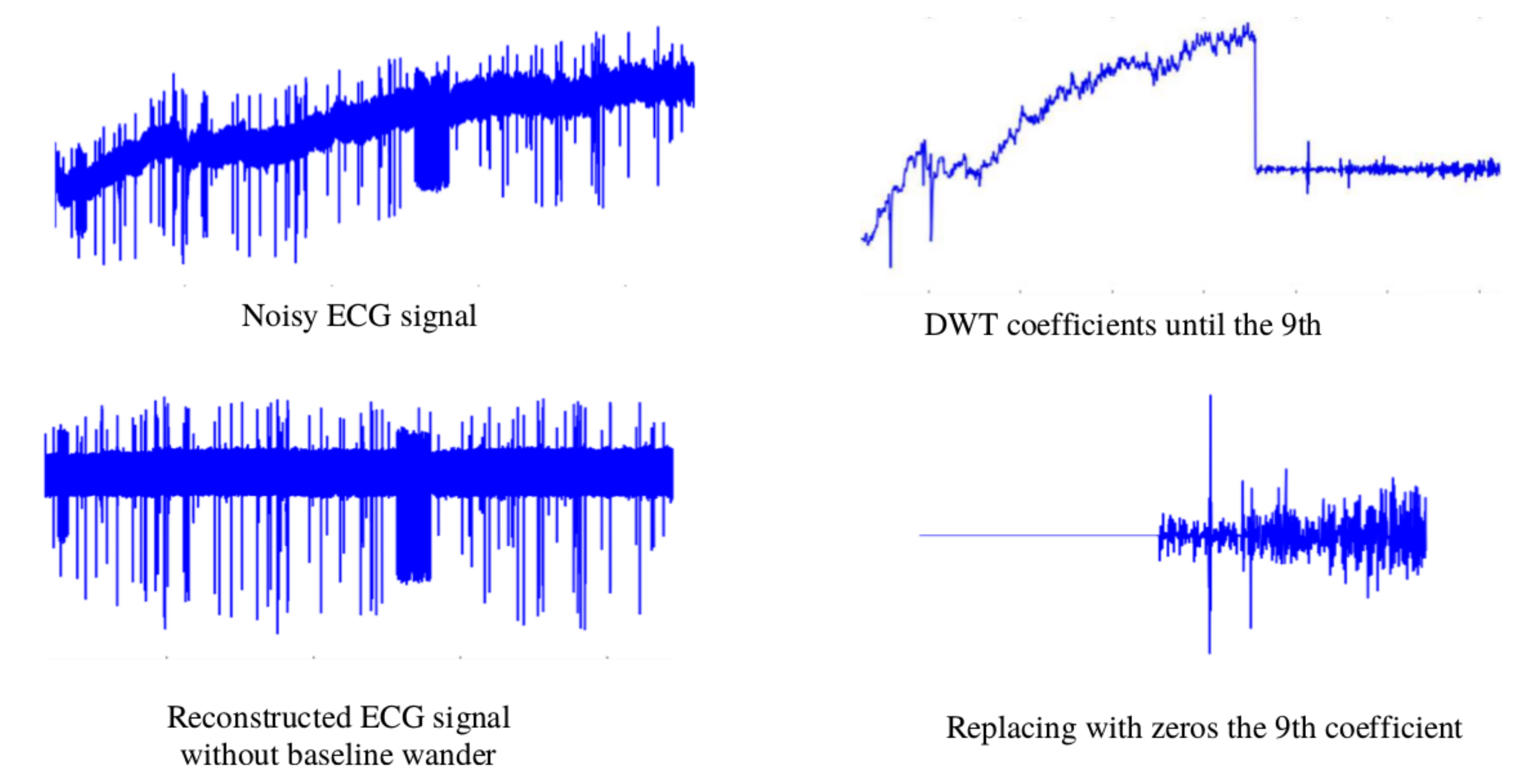
The baseline wander is generated by a low-frequency signal. Removing this noise benefits the extraction of time-domain features. For this task, the Discrete wavelet transform (DWT) is employed. Via the DWT coefficients, the ECG signal can be described in both time and frequency. The values of the coefficients are the results of passing the ECG signal through a series of high pass filters (HPFs) and low pass filters (LPFs). Depending on the wavelet applied, the LPF has specific coefficient values. The HPF is derived from the LPF as follows:
where
L is the length of the filter in the number of samples, and
k are the coefficients of the filter. Each pair of filters can be represented as follows:
The filter has a half downsample after it to make the DWT efficient, represented as follows:
where
n is the length of the signal produced. The DWT sends the signal through a cascade of HPF and LPF, resulting in an average signal detailed and differentiated for classification.
Following the recommendations in [
32], the signal was decomposed into the ninth level using Daubechies wavelet family and the wavelet Daubechies 6 (db6), where the frequency in this level was about 0–0.351 Hz [
32] levels of resolution. The signal proceeds through all the necessary levels to isolate the energy of the noise. To eliminate the baseline wander from the ECG, the signal was constructed from the eighth coefficient to the first, replacing the coefficients of the ninth with zeros.
Figure 4 shows the denoising process of the ECG signal.
The heartbeats were extracted from the denoised signal. Every record had a file indicating the heartbeat location in the sample and its type. After analyzing the research and results of Martis et al. [
32], which uses a window of approximately 552 ms and the research and results of Marinucci et al. [
33] that uses a window of 700 ms, in our case, we considered a slightly wider window, i.e., 730 ms–330 ms before the R peak and 400 ms after it—which were enough to cover the heartbeats of our test signals, making sure the whole beat and its characteristic waveform are totally covered. Every beat has a length of 0.73 s but because the sampling frequency varies among the databases, the length in samples varies depending on the database employed:
- (a)
MITBIH ECG signals consisted of 263 samples;
- (b)
INCART consisted of 188 samples;
- (c)
SUPRA had 93 samples.
Finally, the signal values were normalized between 0 and 1 and resampled at 360 Hz, the sampling frequency of the MITBIH database signals. This was carried out following the recommendations of Llamedo et al. [
26].
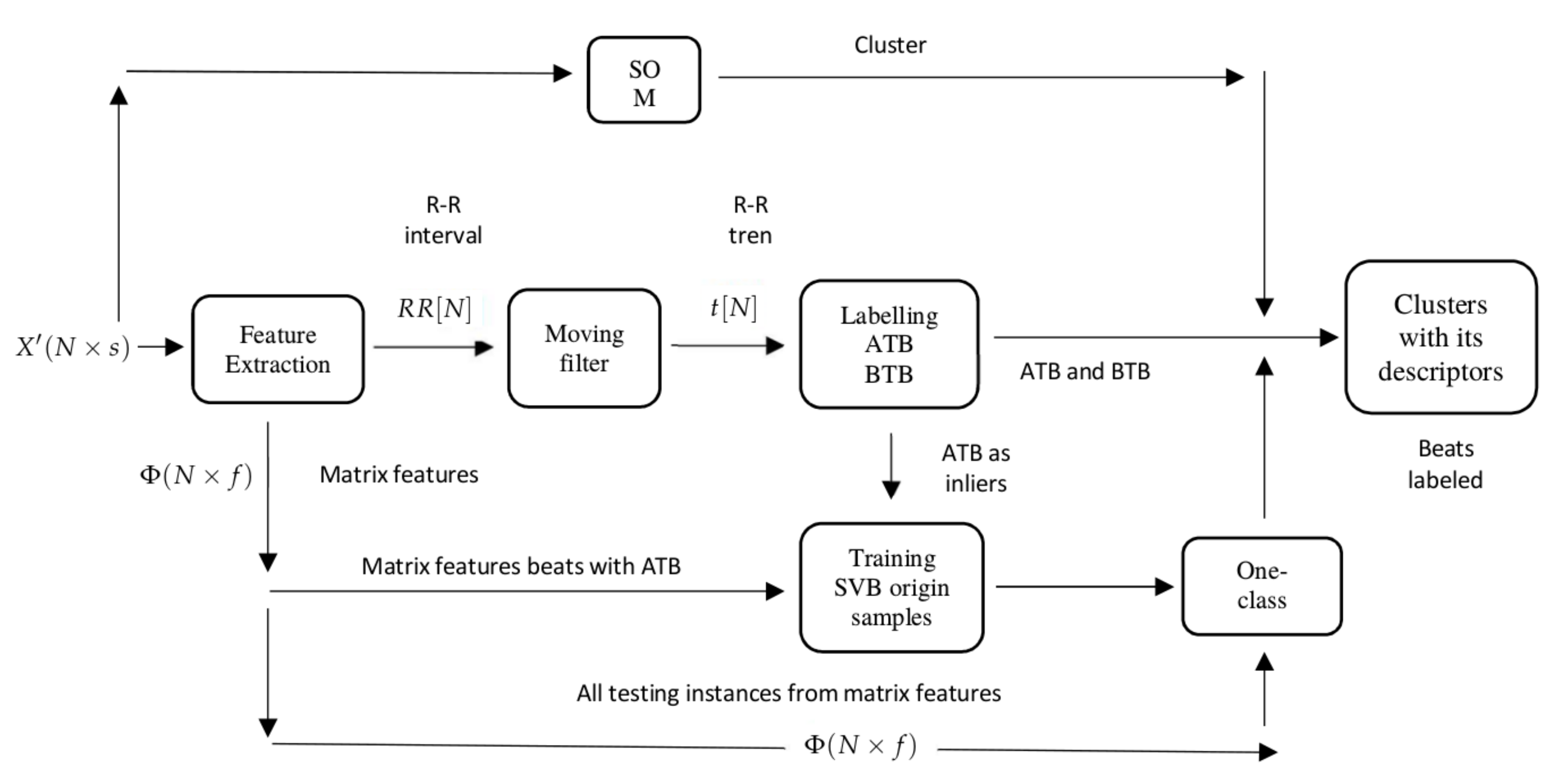
3.4. Clustering and Descriptors
In the clustering and descriptors step, three major procedures were performed according to the assumptions previously stated.
Firstly, the signals were clustered in groups. This work proposes that the clustering algorithm, self-organizing maps (SOM), is able to distinguish between SVBo and VBo, then the problem is reduced to classifying the clusters in SVBo or VBo using a set of descriptors. The SOM is an arrangement of neurons connected in a single-layer network, with most of the cases presented in a two-dimensional network. It is characterized by soft competition between neurons in the output layer, where a winner neuron and its neighbors are updated at every iteration in the training. The SOM learns the distribution and topology of the input vectors, generally mapping data
onto a regular bidimensional grid. A parametric reference vector
is associated with every node
i in the map. Every input
x is compared with every node, and the closest match is selected, and then the input is mapped onto that location
. Nodes topographically close to others in the array will learn from the same input with the following formula:
The heartbeats extracted are sliced from the 60th to 170th sample and clustered, using the self-organizing map (SOM) algorithm. The time frame extracted from the heartbeats ensures that the hearbeat QRS complex is used for clustering, which is an important differentiator between the SVBo and VBo.
Secondly, this work stated that if we computed the trend of the heart rate in a window time, most of the heartbeats above the trend are SVBo, and most of the VBo will be located below the trend. The heart rate is computed taking the distance in samples from the heartbeats that the R peak selected and the previous one. All databases identify a heartbeat with its R peak location; thus, every R peak is already identified in the data. The trend
is computed using a moving average filter as follows:
where
k represents the index terms of the signal,
represents the window signal,
is the signal value that is being filtered shifting
k terms, and
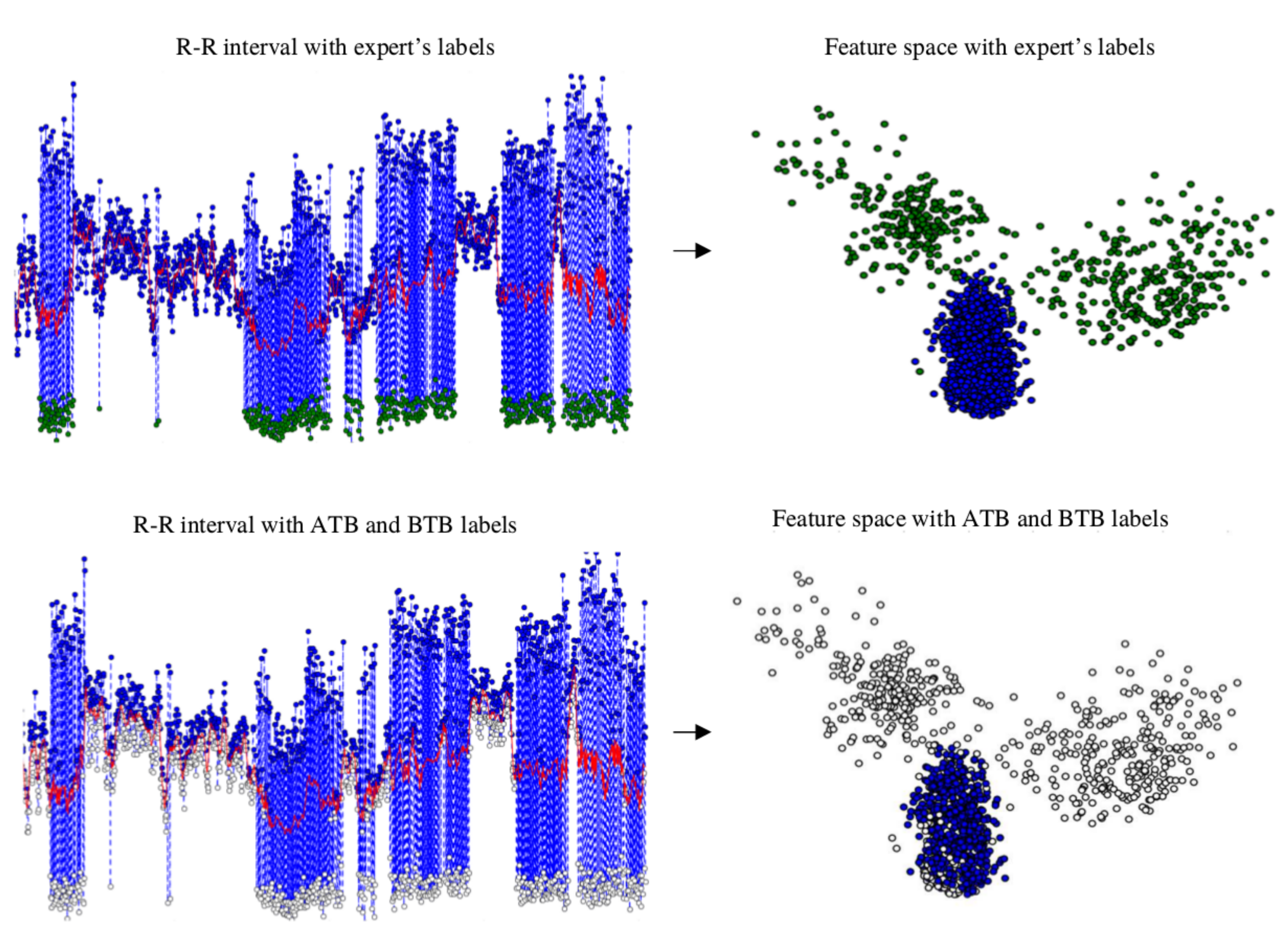
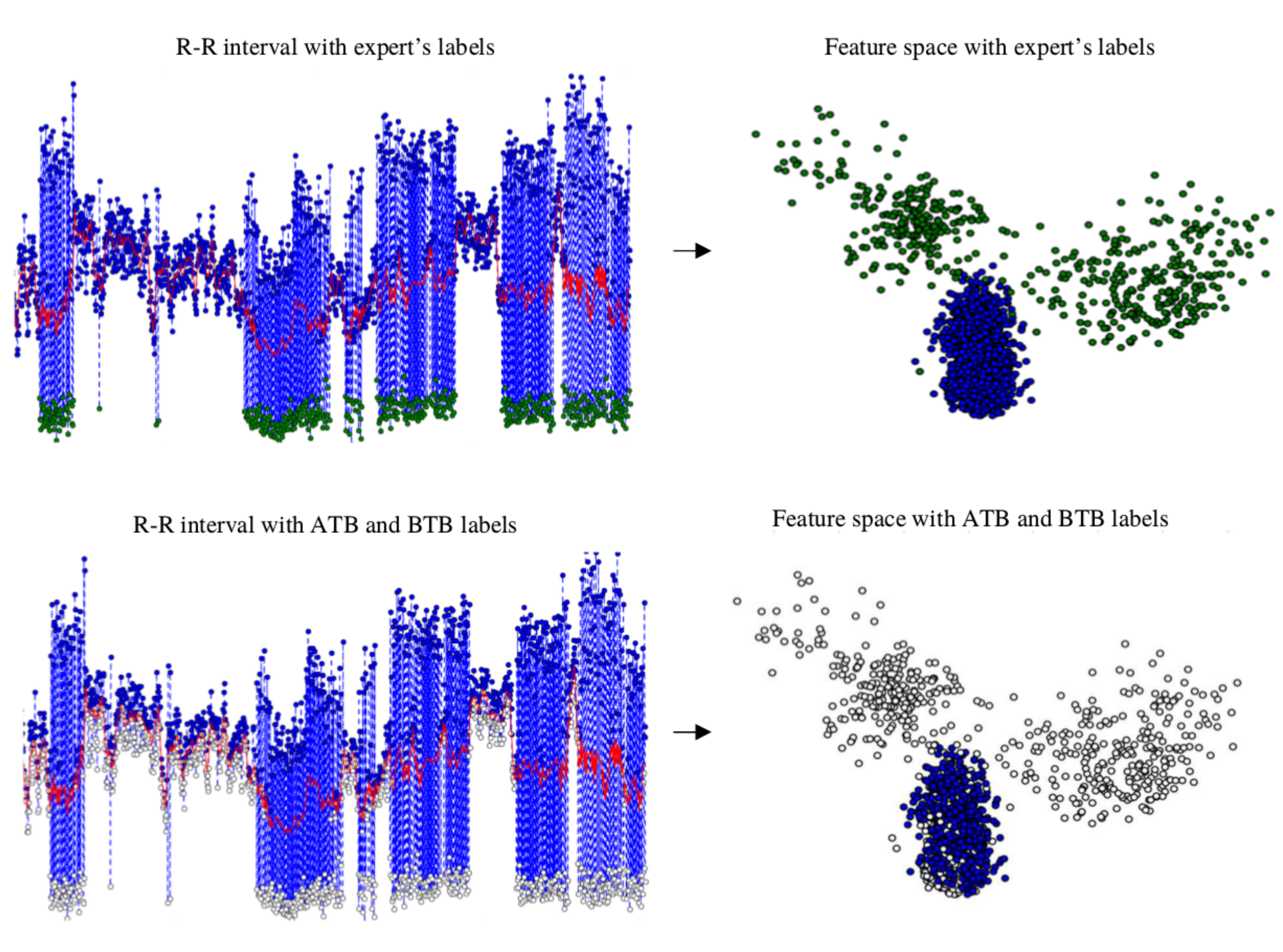
is the filtered output signal. RR features such as mean, kurtosis, and SD were not part of the inputs for final clustering. RR intervals as features were used as an initial reference to preclassify the clusters as “normal” if they were above the red trend line, as can be seen in
Figure 5 and explained in
Section 3.4.
The beats above the trend level are labeled as above-the-trend beats (ATBs), and they are used in the third step as SVBo, and all those below are labeled as below-the-trend beats (BTBs). These labels become descriptors for each cluster. In
Figure 5, a patient’s R–R interval, its trend, and the labeling of ATB and BTB in the heart rate are shown.
The third assumption is that, in the feature space, most of SVBo are grouped and VBo are scattered. With the help of the second assumption, most heartbeats identified above the trend are labeled as SVBo and with this one class, the one-class SVM (OC-SVM) classifier algorithm is trained to create a nonlinear discriminant function to include more SVBo, and the rest of the heartbeats are classified as VBo. The OC-SVM separates the data using a subset of the class identified as reference for outliers by some prior value specified
. The solution is to estimate a function
f, which is a discriminant between the points marked as outliers and the insiders. The function
f can be seen as
where the
are identified as the subset inside the function and VBo outside. For this, it is necessary to resolve the quadratic programming function
subject to
where
represents a kernel map, which transforms the training examples to another space,
N is the maximum number of training samples,
w and
are the weight and offset parameterizing the hyperplane in the feature space, and
is the classic slack variable from the standard support vector machines to prevent over-fitting.
Resolving the quadratic problem, the decision boundary is as follows:
The matrix
containing the heartbeats is converted into feature space
, where
f is the feature dimension used. In this work, different sets of features were used in experimentation and will be explained in the next sections. In order to help to distinguish which clusters are SVBo or VBo, a partial number of SVBo are identified utilizing One-Class SVM. The ATBs are used as SVBo class, the only class in this step, and the OC-SVM creates a discriminant function to englobe similar heartbeats. Furthermore,
Figure 5 shows the beats above the trend located in a feature space.
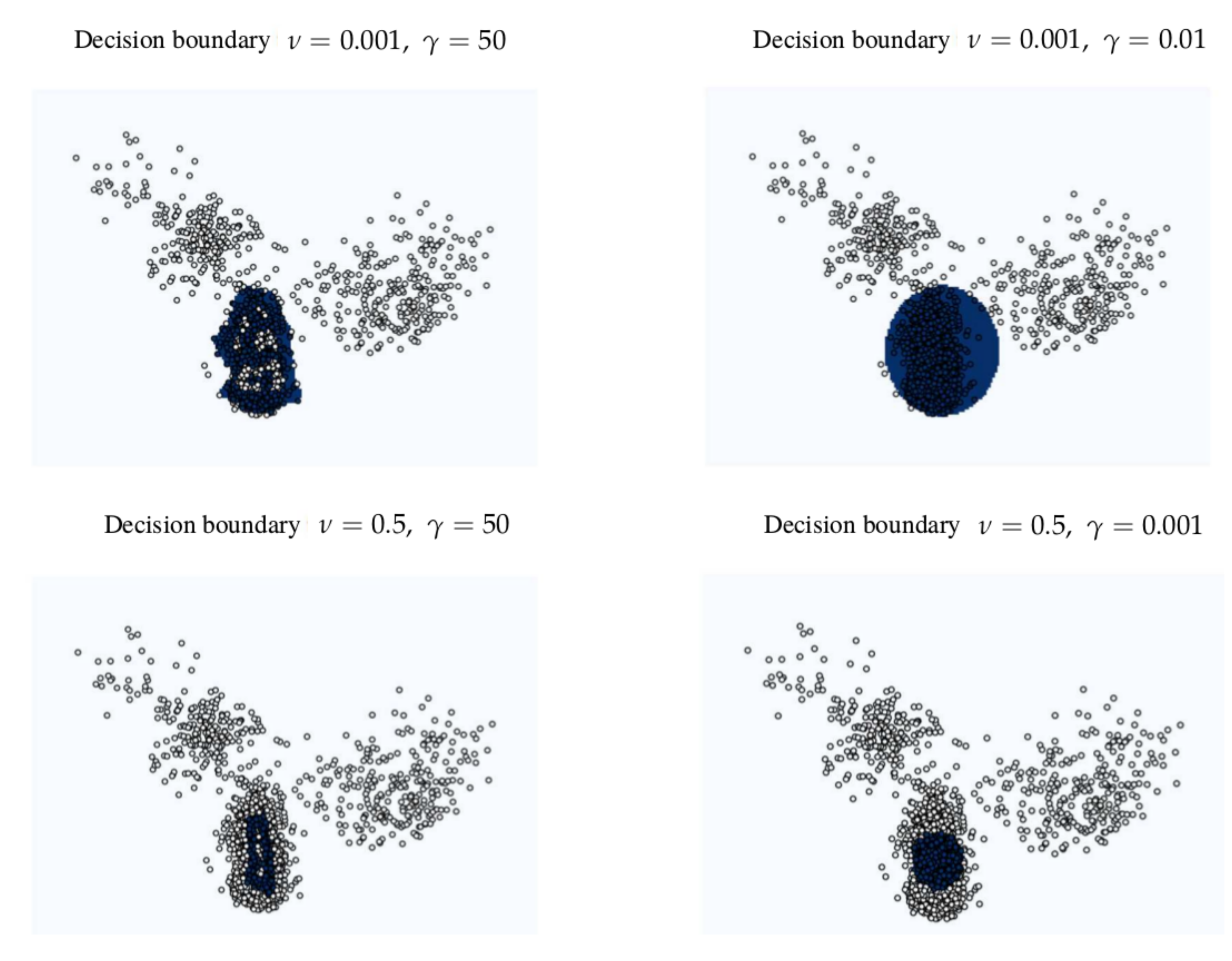
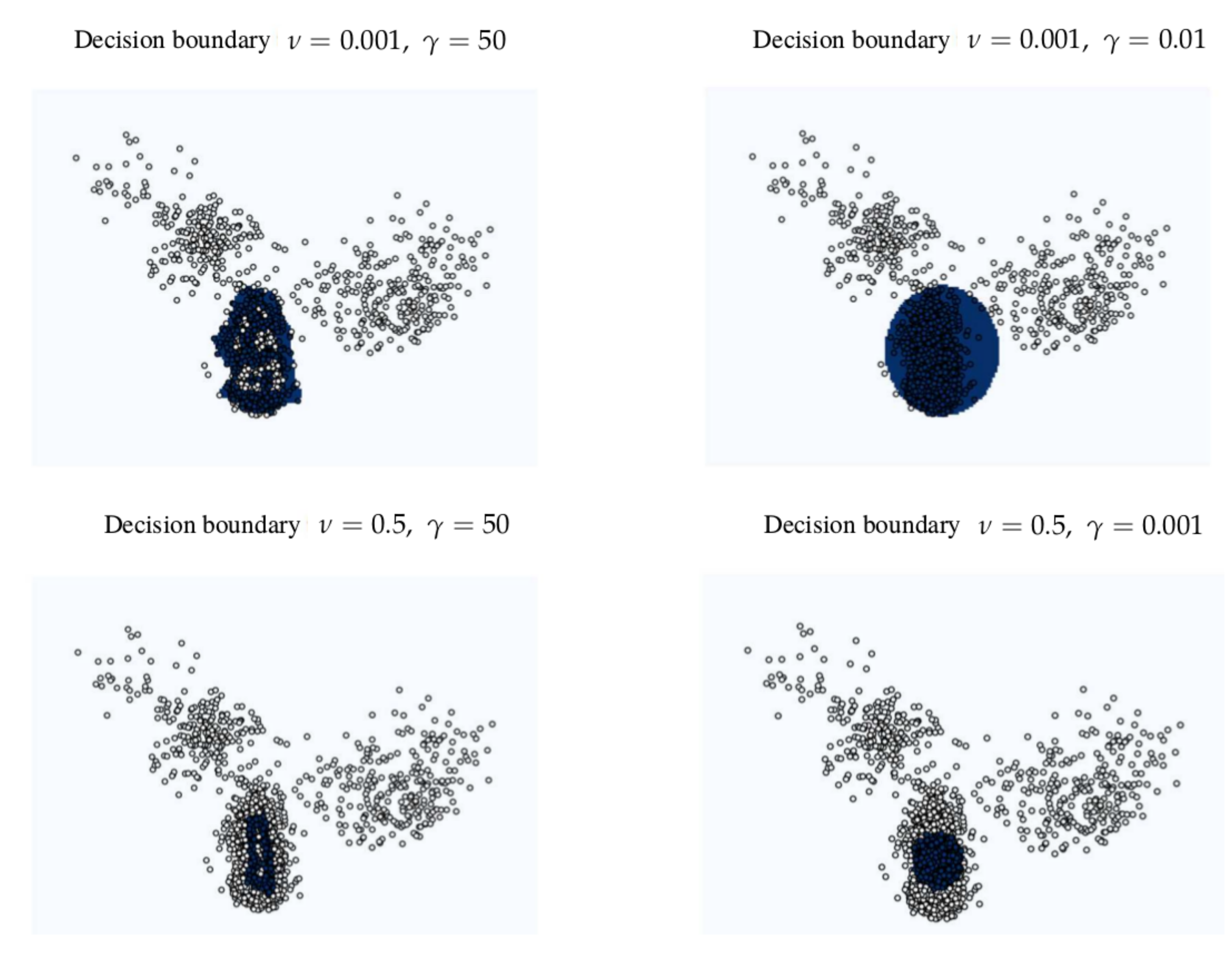
Figure 6 shows different decision boundaries in a feature space created with different hyperparameters in the OC-SVM. The beats identified as SVBo from the one-class SVM serve as well as descriptors to characterize each cluster.
In
Table 1, an example of data separated in clusters with its descriptors is displayed; this is from the same signal used for
Figure 5 and
Figure 6.
3.5. Classification
To determine if a cluster
is SVBo or VBo, three proportions
, where
and
is a cluster, are computed using the descriptors previously defined. Each proportion
is compared with its corresponding
threshold and the results from the comparisons are used to label that
as SVBo or VBo. The first proportion,
is computed as follows in Equation (
11):
This proportion is the percentage of SVBo identified in the cluster by the one-class SVM algorithm. If the proportion surpasses the threshold , then the is labeled as being SVBo.
The second proportion,
is shown in the next Equation (
12).
This proportion represents the error of the one-class SVM in labeling the SVBo or the error of SOM clustering SVBo with VBo. It is expected that clusters that are VBo only have mostly BTB and much less ATB. However, some of SVBo may be mixed in a cluster of VBo, and the one-class SVM may identify them as VBos. In such cases, comparing the rate between the number of SVBo in this cluster and the total number of BTB with its threshold
tells us what type of cluster it is. A majority of BTB will not let the proportion reach the threshold. If the cluster does not contain any BTB, this proportion is not computed.
is shown in (
13).
Lastly, as mentioned before, because it is hypothesized that most of the ATBs are SVBo because a great number of beats are NB in many signals, this rate represents the relation between the ATB and the number of beats in this cluster. The values of the thresholds are determined experimentally, as will be explained. If any of these thresholds are reached, the cluster is labeled as SVBo; otherwise, it is represented as VB.
3.6. Hyperparameters and Features
The approach has a great number of hyperparameters, changing their values may change the output of the approach. The SOMs parameters include the following:
As the SOM is a clustering algorithm, in this case, a reproducibility experiment was performed to ensure that the results can be reproduced multiple times to guarantee its use outside this study.
The one-class SVM has the hyperparameter , which determines the proportion of beats outside of the decision function. The kernel employs the radial basis function (RBF) that uses the hyperparameter, which plays an important role in determining the decision boundary.
Additionally, the threshold to determine if a cluster is SVBo or VBo needs to be specified as well.
The default hyperparameters used for SOM training have a neighbor size of 3 and a hexagonal grid topology with 200 iterations.
Furthermore, the hyperparameters whose values are determined experimentally are as follows:
Different subsets of features were extracted and merged together to form the final features set to be experimented with to reach the highest classification performance. The first feature subset is the DWT db3 coefficients of the QRS complex; the second feature subset is DWT db6 coefficients of the whole beat; the third feature subset feature is statistical computations of the sections before, after, and within the QRS complex; the fourth feature subset is the statistical computations of the QRS complex. The statistical computations are the mean, the standard deviation, the maximum, the minimum, the skewness, and the kurtosis. The final feature sets to experiment with were as follows: feature set 1 is the PCA transformation of the first features subset; feature set 2 is the PCA transformation of the second feature subset; feature set 3 is the merged of the first and fourth feature subsets; feature set 4 is the fourth feature subset; feature set 5 is the PCA transformation of the third feature subset; feature set 6 is the merged of the first and third feature subsets; features set 7 is the merge of the second and fourth feature subsets.
Table 2 summarizes the basic features and the set of features created with all these.
3.7. Experimentation Setup
Figure 7 shows the experimental setup. First, five types of topologies were used in SOM to determine which one is more appropriate for the given data:
,
,
,
, and
. Each type of SOM was run five times using the set of the default hyperparameters (
,
,
,
, and
) and with the default set of features (DWT + PCA of the QRS complex of the signals) to determine the reproducibility of the results. These parameter values and features were selected because they produce good results in the first trials. Experimenting with these variables as defaults gave us an insight into the proper topology to use for this task.
Once a topology was selected, the set of features and parameters were determined first using three different values for each hyperparameter for each set of features for each database, and the best three sets of features were selected. Then, we experimented with five different values of hyperparameters and the best one was selected to obtain the final results to compare it with prior works.
3.8. Evaluation
Because of the high imbalance among the classes, the results are in terms of sensitivity (
S) also known as recall and positive predictive value (
) also known precision, as presented in [
26]. In addition, the F-score is presented here, which is the harmonic mean of these two parameters. F-score is computed as given in Equation (
14).
The F-score (F) can be seen as a measure of combined performance involving both S and . With values between 0 and 1, highest performance with 1, each S and needs to be high to have a high F-score. In other words, it involves a balance between these two performance measures.
The searches for the best SOM topology and the best set of features and parameters values possible result in a great number of results in terms of S, , and F. As for specific values of parameters and specific selection of features, the performance varies for each database, and changing these can cause increased or decreased performances.
The purpose of these experiments is to set the hyperparameters’ values that can maintain the best balance possible among the performance for the three databases. To achieve this, a modification of the F-score formula is made to compare the performance of each F-score for each database. We call it F-general (
), and the equation is shown in (
15).
This equation is motivated by the way F-score is computed, from a precision value and recall. It is also a harmonic mean of the three F-scores for the three databases. The reason we used this equation is that we looked for hyperparameters and features not biased towards any of the databases. The purpose is to have a generalized set of hyperparameters and features that could balance the performance among the databases. This equation was applied to select the SOM network, the hyperparameters, and set of features.
4. Results
Table 3 shows the results of inserting every patients’ signal through the algorithm for each network topology proposed with the default hyperparameters and set of features.
In order to ensure the reproducibility of the results, in terms of S and , the mean and the standard deviation were taken from the five runs of every database for every network topology.
It can be seen that the standard deviation from the runs of every topology of every database has a value near zero, which means minimum or insignificant changes between the results within the topology but not between topologies.
In order to select one,
Table 4 presents the F of the VB origin because the results in the SVB origin are nearly 1 in every database. For the SUPRA database, the two F highest values are obtained with the topologies
, and
with 0.8427 and 0.8309, respectively. With the MITBIH database, the highest valued topologies are
,
and
, with F-scores of 0.8689, 0.8745, and 0.8663, respectively. The INCART database produces the highest values with the
and
topologies, with 0.9204 and 0.9198 F-scores values, respectively. The
topology has the highest performances for SUPRA and MITBIH databases compared to other topologies, while for INCART, the
topology is just slightly above
. However, the
of each database shows that the
topology has the highest performance for the three databases, and because of that, this SOM network was used to run the next experiments involving the selection of the parameters and set of features.
As the default parameters gave good results in the first tests, other similar and close values were tested as upper and lower bound values, with sets of features as presented before, in order to find better combination of hyperparameters and features to improve our results. The test values for each parameter are as follows:
, 0.1, 0.5;
, 1.5, 3;
, 0.5, 0.6;
, 0.6, 0.7;
, 0.3, 0.4. Each parameter has three different values, giving rise to 243 experiments for each set of features for each record in every database. In each experiment, the
S,
, and
F for each set of features (for each database) were computed, and only the highest performance in terms of
F are shown in
Table 5.
Results with the highest values are in
Table 5, and these are presented for each set of features. For example, parameters for feature set
,
,
,
,
. The
is computed from with each VBos
F of every database for every set of features. The best three were set of features 1, 3, and 4. It is important to mention that these features involve only the QRS complex, which, in fact, is very accurate medically in distinguishing the heartbeat between SVBo and VBo.
As the hyperparameters values for the three different sets of features were nearly the same, just varying in feature set 4 and in feature set 1 and 3, the final hyperpameter values to experiment with were as follows: , 0.1, 0.15, 0.25, 0.3; , 1.25, 1.5, 2, 2.5; , 0.35, 0.4, 0.45, 0.5; , 0.575, 0.6, 0.625, 0.65; , 0.275, 0.3, 0.325, 0.35. In this case, 3125 experiments were performed for each set of features for each database.
In order to select the best set of features with parameters,
Table 6 presents the
values computed with the highest
F for each database for each set of features. The hyperparameters of each feature set presented the best
F were as follows: feature set 1 =
,
,
,
,
; feature set 3 =
,
,
,
,
; feature set 4 =
,
,
,
,
. It has to be noticed that even though these set of features were selected with almost the same parameters values, they ended up with completely different and
values. The best set of features with its parameters was feature set 4, with 0.8220%. With this, the experimentation concludes with a SOM network of
neurons, with feature set 4 and the parameters
,
,
,
,
.
The results of all the databases are compared with similar works in
Table 7. The approach was tested also with two databases derived from the MITBIH database, as in [
21,
27]. Even though some other authors such as Kiranyaz et al. [
34] claim that the average detection accuracies of both VB and SPV ectopic beats were over 97% using the MIT-BIH arrhythmia database, for both training and testing of the algorithm, this shows that the supervised algorithms so far continue being of higher precision or accuracy.
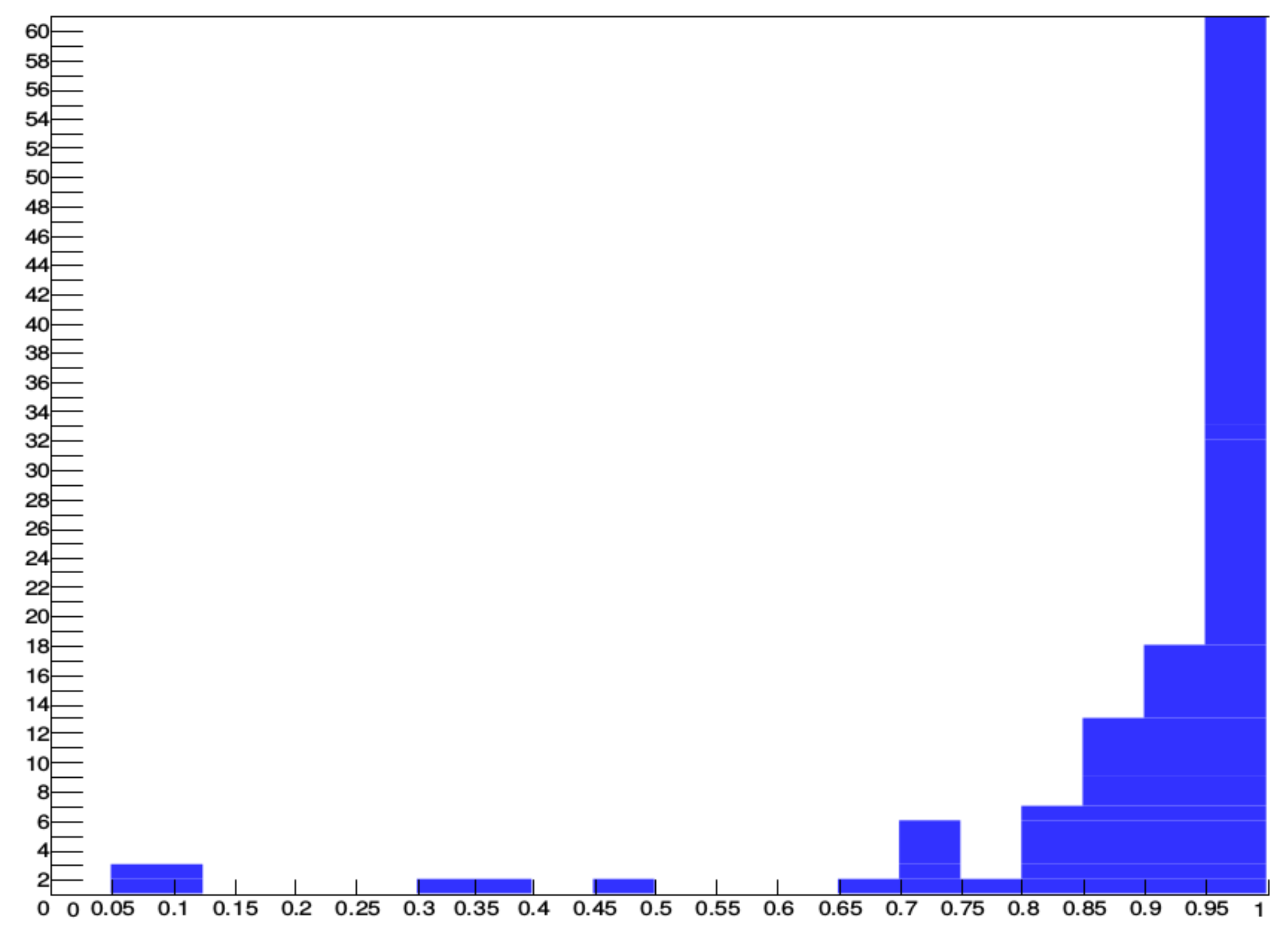
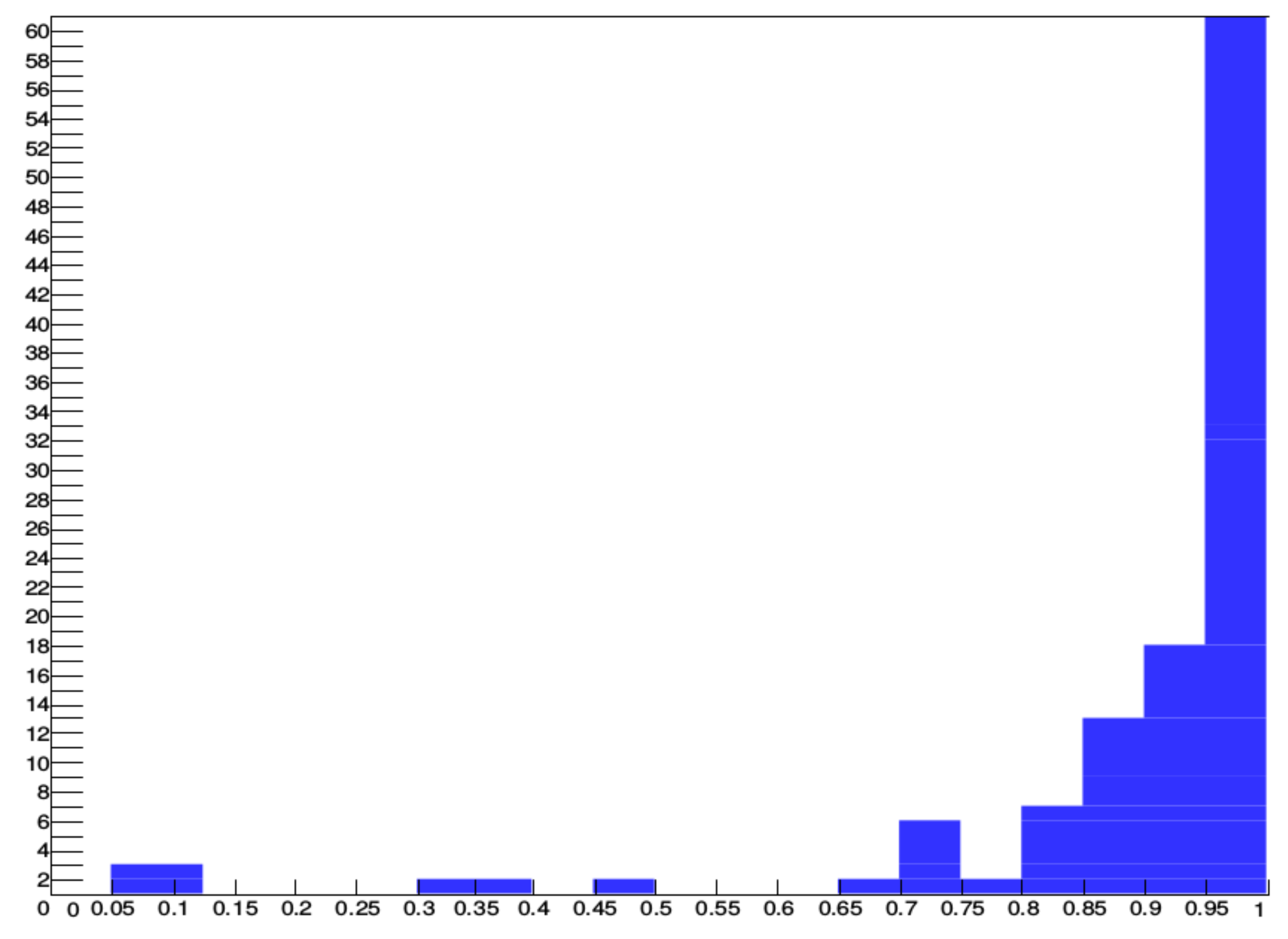
In
Figure 8, the performance of the algorithm for 109 records that have at least 40 VBos is shown. The histogram shows that 89 out of 109 records have at least a 0.85 F-score, and 60 out of 109 are over 0.95 F-score. These records are 30 min long; in other words, there are approximately 1500 and up to 2500 heartbeats depending on the heart rate. These records represent most of the VBos in the three databases.
5. Discussion
One of the main differences among all works is the percentage of in VBo, where our approach produces percentages above 90%, with the exception of the SUPRA database with 0.8930%. This means that a great number of beats classified as VBo are indeed VBo.
The F-score of this work outperforms the general classifier models. Martis et al. [
23] and Ye et al. [
22] present the lowest F-score because of their
around 0.60, plunging the F-score value, while Chazal et al. [
19] and Llamedo et al. [
20] maintain similar values for both
S and
, with F-score of 0.79 and 0.83 respectively. The inevitable variability between patients lowers the performance of these general classifiers. The results for this work are higher, with 0.88, because it presents a
near 100%.
An additional comparison is made with works where they present models that can be adapted to a patient. The results to be compared are the models before physician’s help is provided for the adaptive algorithms, otherwise, their results are nearly 95%. Only Llamedo et al. [
26] and Al Rahhal et al. [
27] presented this type of results, and Wiens et al. [
24] presented the performance of the HAMILTON software on the MITBIH database for comparative results. As in the general models, the performance on the F-score for VBo in the algorithm proposed was superior over these methods. No patterns in their results exist showing misclassification measurements, which vary depending on the database. For example, Llamedo presents balanced results in the MIIBIH database, while a very low 0.54 in
is presented in the SUPRA database, and in the INCART database, the
is 0.96 against a 0.88 for
S. Meanwhile, Al Ranhal et al. [
27] have very similar results with the HAMILTON software, with a low performance of 0.79% for the MITBIH database in
, 0.93 for the SUPRA database for the same measurement, and very lower, 0.37, in the INCART database. Our approach has higher performance because it maintains an
S always above 0.9 for
in every database; in this way, the derived F-score presents a superior performance. Overall, our approach has produced better results in F-score for VBo, compared to these studies.
The physicians’ need for constant monitoring of the arrhythmias presented the opportunity for the creation of algorithms or methodologies that perform automatic measurements of arrythmia. Different approaches have been used by the scientific community, such as the intra- and inter-patient paradigms. Such approaches have historically employed manual data tagging by an expert. The works of Llamedo et al. [
20] and Al Rahhal et al. [
27] were the first to show results from prelabeled data.
Those studies showed progress, compared to previous studies, but they maintained the limitation of not being able to overcome the variations between patients or to train a general model that uses the available databases, as explained in
Section 3.1. Our work introduces a new unsupervised method that classifies beats of SVBo origin, formed by classes NB and SVB, and beats of ventricular origin VBo, formed by VB and FB. This method does not require the assistance of an expert physician, as it captures the inherent patterns found in the captured signal and makes use of the heartbeat characteristics captured from previous patient studies.
Previous works need labels in order to create a heartbeat classifier. A general classifier, created by heartbeat samples from other patients, may not be the best solution as the inevitable variability lowers the performance of the classifier. Even though the adaptive patient classifiers are a promising solution in classifying arrhythmias, it needs a physician to identify a certain number of heartbeats to feed the algorithm for every patient.
In this work, a new unsupervised algorithm was proposed to classify between supraventricular and ventricular heartbeats in a single patient, in a window time, without previous labels provided by a physician.
Three assumptions were proposed to implement this algorithm. A never used one was that most of the heartbeats above a computed trend in the heart rate are of supraventricular nature. This can be used as a new feature in future works.
6. Conclusions
In this work, a new unsupervised algorithm was proposed to classify between supraventricular and ventricular heartbeats without the need for any labeling by a physician. A new feature is using as a reference the trend in the heart rate to classify the heartbeats above that trend as of “supraventricular” nature.
The results of this algorithm show better performance against other generalized models and/or adaptive patient models without the need for a physician’s assistance.
These results show a promising path for unsupervised models to classify these types of heartbeats, and it can be seen as a milestone to develop further stages for classification between supraventricular heartbeats and normal heartbeats.
This comes from the fact that this model adapts itself to the patient’s heartbeats waveform. Our algorithm works better without the need for a large number of VBo heartbeats. These results show a promising path for unsupervised models to be used as classifying indicators for SVBo and VBo types of heartbeats.
No other similar work has been developed thus far, though some improvements in the algorithm are needed to reach higher performance in precision and recall metrics. Although the purpose of this research is to develop an adaptive system granting better results, compared to those from other authors, we also concluded that the silhouette criterion can be applied in a new research study or proposal in the classification of ECG signals, which, to the best of our knowledge, nobody has performed thus far.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}