
Nonlinear Random Forest Classification, a Copula-Based Approach



Abstract
:1. Introduction
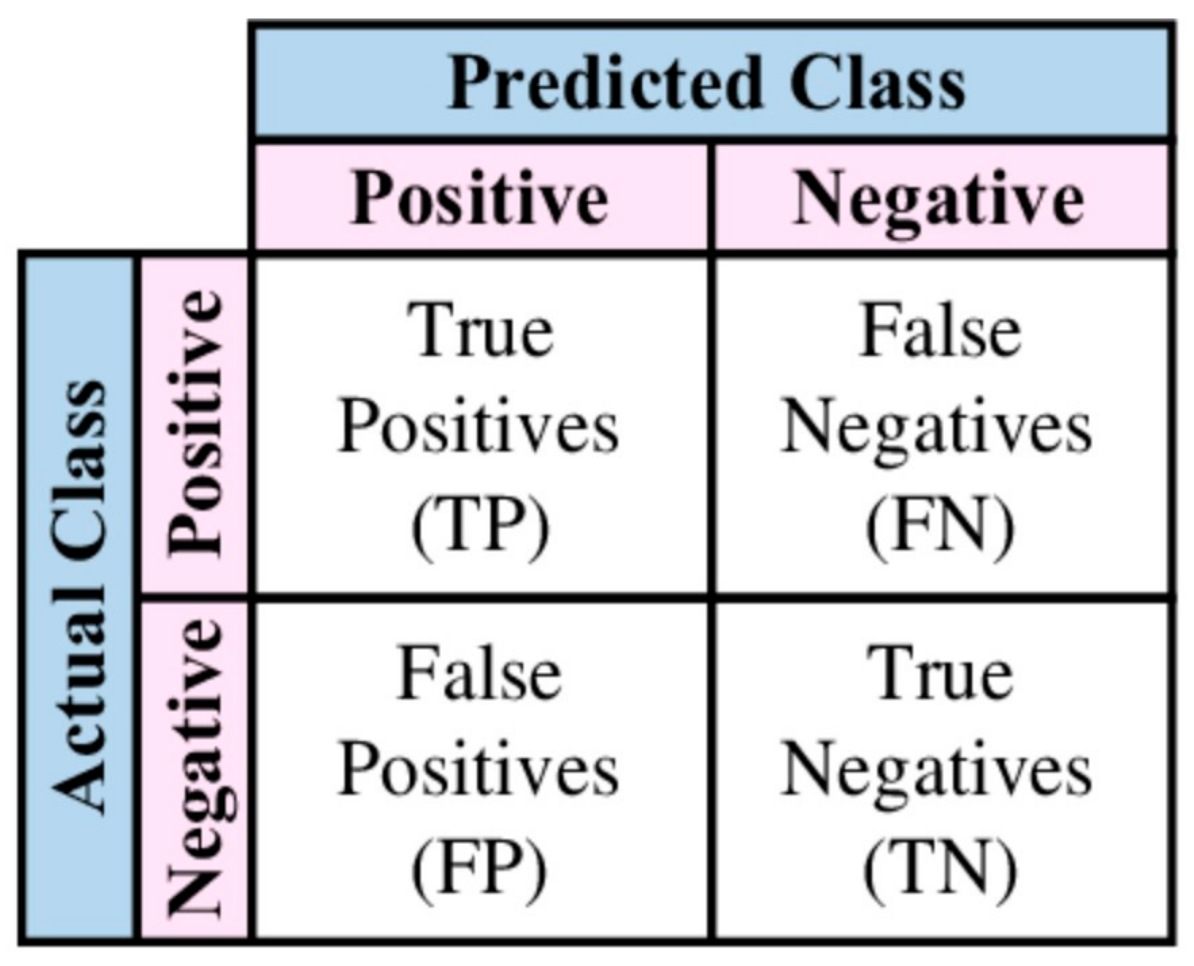
2. Preliminaries and Related Works
3. Copula-Based Random Forest
| Algorithm 1. Algorithm of copula-based random forest classification. |
| Result Data: data set , thereshold value . |
| Result: Selected feature set , Classification results. |
| 1 Initialization: = 0, accuracy = 0, = all features, |
| 2 while accuracy do |
| 3 ; |
| 4 ; |
| 5 |
| 6 Perform a random Forrest classification; |
| 7 the accuracy of random forest classification using 13; |
| 8 accuracy = Accnew + accuracy; |
| 9 end |
4. Numerical Results
4.1. Simulation Study
4.2. COVID-19 Dataset
4.3. Diabetes 130-US Hospitals Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, M.; Liu, X. Feature selection techniques with class separability for multivariate time series. Neurocomputing 2013, 110, 29–34. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Chakraborty, B. Feature selection for multivariate time series. In Proceedings of the IASC 2008 4th World Conference of IASC on Computational Statistics and Data Analysis, Yokohama, Japan, 5–8 December 2008; pp. 227–233. [Google Scholar]
- Paul, D.; Su, R.; Romain, M.; Sébastien, V.; Pierre, V.; Isabelle, G. Feature selection for outcome prediction in oesophageal cancer using genetic algorithm and random forest classifier. Comput. Med. Imaging Graph. 2017, 60, 42–49. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. 2017, 50, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning; Springer: Berlin, Germany, 2012; pp. 157–175. [Google Scholar]
- Lall, S.; Sinha, D.; Ghosh, A.; Sengupta, D.; Bandyopadhyay, S. Stable feature selection using copula-based mutual information. Pattern Recognit. 2021, 112, 107697. [Google Scholar] [CrossRef]
- Chen, Z.; Pang, M.; Zhao, Z.; Li, S.; Miao, R.; Zhang, Y.; Feng, X.; Feng, X.; Zhang, Y.; Duan, M.; et al. Feature selection may improve deep neural networks for the bioinformatics problems. Bioinformatics 2020, 36, 1542–1552. [Google Scholar] [CrossRef]
- Kabir, M.M.; Islam, M.M.; Murase, K. A new wrapper feature selection approach using neural network. Neurocomputing 2010, 73, 3273–3283. [Google Scholar] [CrossRef]
- Li, W.T.; Ma, J.; Shende, N.; Castaneda, G.; Chakladar, J.; Tsai, J.C.; Apostol, L.; Honda, C.O.; Xu, J.; Wong, L.M.; et al. Using machine learning of clinical data to diagnose COVID-19. medRxiv 2020, 20, 247. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Berlin, Germany, 2012; Volume 454. [Google Scholar]
- Chao, G.; Luo, Y.; Ding, W. Recent advances in supervised dimension reduction: A survey. Mach. Learn. Knowl. Extr. 2019, 1, 341–358. [Google Scholar] [CrossRef] [Green Version]
- Sheikhpour, R.; Sarram, M.A.; Gharaghani, S.; Chahooki, M.A.Z. A survey on semi-supervised feature selection methods. Pattern Recognit. 2017, 64, 141–158. [Google Scholar] [CrossRef]
- Peng, X.; Li, J.; Wang, G.; Wu, Y.; Li, L.; Li, Z.; Bhatti, A.A.; Zhou, C.; Hepburn, D.M.; Reid, A.J.; et al. Random forest based optimal feature selection for partial discharge pattern recognition in hv cables. IEEE Trans. Power Deliv. 2019, 34, 1715–1724. [Google Scholar] [CrossRef]
- Yao, R.; Li, J.; Hui, M.; Bai, L.; Wu, Q. Feature selection based on random forest for partial discharges characteristic set. IEEE Access 2020, 8, 159151–159161. [Google Scholar] [CrossRef]
- Haug, S.; Klüppelberg, C.; Kuhn, G. Copula structure analysis based on extreme dependence. Stat. Interface 2015, 8, 93–107. [Google Scholar]
- Zhang, Y.; Zhou, Z.H. Multilabel dimensionality reduction via dependence maximization. ACM Trans. Knowl. Discov. Data 2010, 4, 1–21. [Google Scholar] [CrossRef]
- Zhong, Y.; Xu, C.; Du, B.; Zhang, L. Independent feature and label components for multi-label classification. In 2018 IEEE International Conference on Data Mining (ICDM); IEEE: Piscataway, NJ, USA, 2018; pp. 827–836. [Google Scholar]
- Shin, Y.J.; Park, C.H. Analysis of correlation based dimension reduction methods. Int. J. Appl. Math. Comput. Sci. 2011, 21, 549–558. [Google Scholar] [CrossRef] [Green Version]
- Iwendi, C.; Bashir, A.K.; Peshkar, A.; Sujatha, R.; Chatterjee, J.M.; Pasupuleti, S. COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health. 2020, 8, 357. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Zhang, P.; Zhang, L.; Meng, W.; Li, J.; Tong, C.; Li, Y.; Cai, J.; Yang, Z.; Zhu, J.; et al. Rapid and accurate identification of covid-19 infection through machine learning based on clinical available blood test results. medRxiv 2020. [Google Scholar] [CrossRef]
- Ceylan, Z. Estimation of COVI-19 prevalence in Italy, Spain, and France. Sci. Total Environ. 2020, 729, 138817. [Google Scholar] [CrossRef]
- Azar, A.T.; Elshazly, H.I.; Hassanien, A.E.; Elkorany, A.M. A random forest classifier for lymph diseases. Comput. Methods Programs Biomed. 2014, 113, 465–473. [Google Scholar] [CrossRef]
- Subasi, A.; Alickovic, E.; Kevric, J. Diagnosis of chronic kidney disease by using random forest. In CMBEBIH 2017; Springer: Berlin, Germany, 2017; pp. 589–594. [Google Scholar]
- Açıcı, K.; Erdaş, Ç.B.; Aşuroğlu, T.; Toprak, M.K.; Erdem, H.; Oğul, H. A random forest method to detect parkinsons disease via gait analysis. In International Conference on Engineering Applications of Neural Networks; Springer: Berlin, Germany, 2017; pp. 609–619. [Google Scholar]
- Jabbar, M.A.; Deekshatulu, B.L.; Chandra, P. Prediction of heart disease using random forest and feature subset selection. In Innovations in Bio-Inspired Computing and Applications; Springer: Berlin, Germany, 2016; pp. 187–196. [Google Scholar]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef]
- Sun, L.; Yin, T.; Ding, W.; Qian, Y.; Xu, J. Multilabel feature selection using ml-relieff and neighborhood mutual information for multilabel neighborhood decision systems. Inf. Sci. 2020, 537, 401–424. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Durante, F.; Sempi, C. Principles of Copula Theory; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Snehalika, L.; Debajyoti, S.; Abhik, G.H.; Debarka, S.; Sanghamitra, B. Feature selection using copula-based mutual information. Pattern Recognit. 2021, 112, 107697. [Google Scholar]
- Chang, Y.; Li, Y.; Ding, A.; Dy, J. A robust-equitable copula dependence measure for feature selection. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 84–92. [Google Scholar]
- Ozdemir, O.; Allen, T.G.; Choi, S.; Wimalajeewa, T.; Varshney, P.K. Copula-based classifier fusion under statistical dependence. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2740–2748. [Google Scholar] [CrossRef]
- Salinas-Gutiérrez, R.; Hernández-Aguirre, A.; Rivera-Meraz, M.J.; Villa-Diharce, E.R. Using gaussian copulas in supervised probabilistic classification. In Soft Computing for Intelligent Control and Mobile Robotics; Springer: Berlin, Germany, 2010; pp. 355–372. [Google Scholar]
- Martal, D.F.L.; Durante, F.; Pappada, R. Copula—Based clustering methods. In Copulas and Dependence Models with Applications; Springer: Cham, Switzerland, 2017; pp. 49–67. [Google Scholar]
- Di Lascio, F.M.L. Coclust: An R package for copula-based cluster analysis. Recent Appl. Data Clust. 2018, 93, 74865. [Google Scholar]
- Houari, R.; Bounceur, A.; Kechadi, M.T.; Tari, A.K.; Euler, R. Dimensionality reduction in data mining: A copula approach. Expert Syst. Appl. 2016, 64, 247–260. [Google Scholar] [CrossRef]
- Klüppelberg, C.; Kuhn, G. Copula structure analysis. J. R. Stat. Soc. Ser. B 2009, 71, 737–753. [Google Scholar] [CrossRef]
- Ma, J.; Sun, Z. Mutual information is copula entropy. Tsinghua Sci. Technol. 2011, 16, 51–54. [Google Scholar] [CrossRef]
- Demarta, S.; McNeil, A.J. The t copula and related copulas. Int. Stat. Rev. 2005, 73, 111–129. [Google Scholar] [CrossRef]
- Wang, L.; Guo, X.; Zeng, J.; Hong, Y. Using gumbel copula and empirical marginal distribution in estimation of distribution algorithm. In Third International Workshop on Advanced Computational Intelligence; IEEE: Piscataway, NJ, USA, 2010; pp. 583–587. [Google Scholar]
- Strack, B.; DeShazo, J.P.; Gennings, C.; Olmo, J.L.; Ventura, S.; Cios, K.J.; Clore, J.N. Impact of HbA1c Measurement on Hospital Readmission Rates: Analysis of 70,000 Clinical Database Patient Records. BioMed Res. Int. 2014, 2014, 781670. [Google Scholar] [CrossRef]
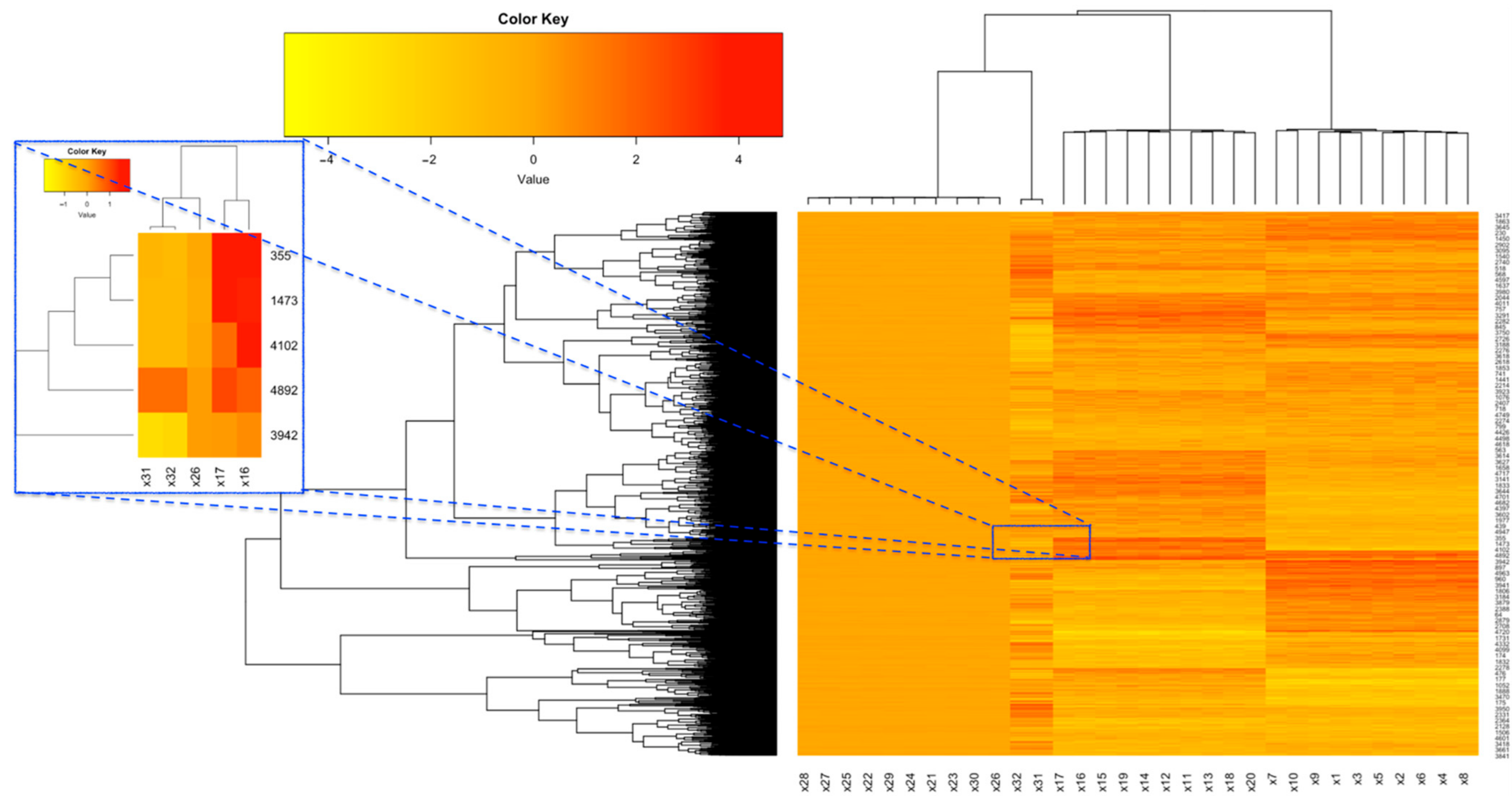

{kind=link}
{kind=link}
| n | Relevant Attributes | Sensitivity | Specificity | Accuracy | Running Time |
|---|---|---|---|---|---|
| 2 | x26, x32 | 0.869 | 0.867 | 0.875 | 4.51 |
| 3 | x26, x32, x31 | 0.879 | 0.869 | 0.879 | 4.91 |
| 4 | x26 x32 x31 x16 | 0.880 | 0.873 | 0.880 | 5.12 |
| 5 | x26, x32, x31, x16, x13 | 0.881 | 0.878 | 0.881 | 5.55 |
| 6 | x26, x32, x31, x16, x13, x12 | 0.888 | 0.880 | 0.886 | 5.83 |
| 7 | x26, x32, x31, x16, x13, x12, x20 | 0.891 | 0.888 | 0.891 | 6.33 |
| 8 | x26, x32, x31, x16, x13, x12, x20, x18 | 0.893 | 0.892 | 0.892 | 6.55 |
| 10 | x26, x32, x31, x16, x13, x20, x12, x18, x17, x14 | 0.898 | 0.895 | 0.893 | 6.92 |
| 15 | x26, x32, x31, x16, x13, x12, x20, x18, x14, x17 x15, x11, x19, x3, x7 | 0.908 | 0.896 | 0.901 | 8.34 |
| 20 | x26, x32, x31, x16, x13, x12, x20, x18, x14, x17 x11, x15, x19, x3, x7, x9, x8, x5, x6, x1 | 0.918 | 0.909 | 0.917 | 11.30 |
| 25 | x26, x32, x31, x16, x13, x12, x20, x18, x17, x14, x11, x15, x19, x3, x7, x8, x9, x6, x5, x1 x4, x2, x10, x27, x29 | 0.929 | 0.939 | 0.934 | 13.61 |
| 32 | All attributes: x1, x2,…,x32 | 0.982 | 0.979 | 0.981 | 16.75 |
| 32 | Traditional random forest | 0.982 | 0.979 | 0.981 | 16.75 |
| n | Names of Attributes | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|
| 2 | Age, Fatigue | 0.755 | 0.864 | 0.836 |
| 3 | Age, Fatigue, Nausea/Vomiting | 0.840 | 0.886 | 0.873 |
| 4 | Age, Fatigue, Nausea/Vomiting, Diarrhea | 0.826 | 0.875 | 0.860 |
| 5 | Age, Fatigue, Nausea/Vomiting, Diarrhea, Sore Throat | 0.783 | 0.891 | 0.860 |
| 10 | Age, Fatigue, Nausea/Vomiting, Diarrhea, Sore Throat, X-ray Results, Shortness of Breath, Neutrophil, Serum Levels of White Blood Cell, Risk Factors | 0.735 | 0.922 | 0.865 |
| 15 | Age, Fatigue, Nausea/Vomiting, Diarrhea, Sore Throat, X-ray Results, Shortness of Breath, Neutrophil, Serum Levels of White Blood Cell, Risk Factors, Temperature, Coughing, Lymphocytes, Neutrophil Categorical, Sex | 0.873 | 0.929 | 0.914 |
| n | Names of Attributes | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|
| 2 | num_medications, num_procedures | 0.742 | 0.756 | 0.708 |
| 3 | num_medications, num_procedures, A1Cresult | 0.766 | 0.771 | 0.780 |
| 5 | num_medications, num_procedures, A1Cresult, epaglinide, max_glu_serum | 0.837 | 0.806 | 0.801 |
| 10 | num_medications, number_diagnoses, age, A1Cresult, repaglinide, max_glu_serum, weight, glimepiride, rosiglitazone, pioglitazone | 0.921 | 0.948 | 0.871 |
| 20 | num_medications, number_diagnoses, age, A1Cresult, repaglinide, max_glu_serum, weight, glimepiride, rosiglitazone, pioglitazone, glyburide, number_emergency, glipizide, number_outpatient, race, metformin, diag_2, readmitted, repaglinide, diag_3 | 0.981 | 0.977 | 0.972 |
| 50 | All attributes | 0.986 | 0.981 | 0.978 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mesiar, R.; Sheikhi, A. Nonlinear Random Forest Classification, a Copula-Based Approach. Appl. Sci. 2021, 11, 7140. https://doi.org/10.3390/app11157140
Mesiar R, Sheikhi A. Nonlinear Random Forest Classification, a Copula-Based Approach. Applied Sciences. 2021; 11(15):7140. https://doi.org/10.3390/app11157140
Chicago/Turabian StyleMesiar, Radko, and Ayyub Sheikhi. 2021. "Nonlinear Random Forest Classification, a Copula-Based Approach" Applied Sciences 11, no. 15: 7140. https://doi.org/10.3390/app11157140
APA StyleMesiar, R., & Sheikhi, A. (2021). Nonlinear Random Forest Classification, a Copula-Based Approach. Applied Sciences, 11(15), 7140. https://doi.org/10.3390/app11157140