
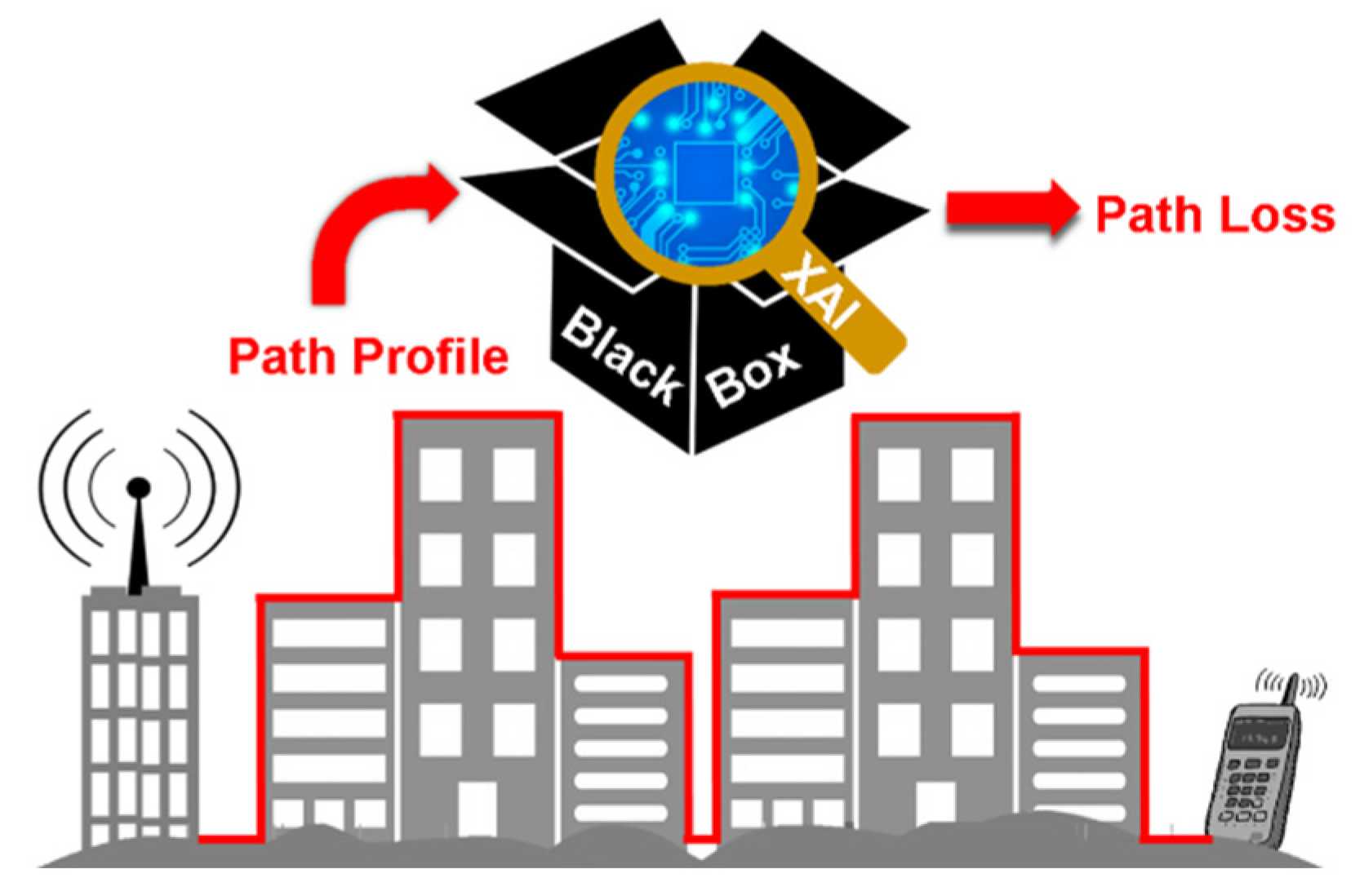
Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments


Abstract
:1. Introduction
- A deep-learning-based path loss model utilizing path profiles is presented for 5G mobile communication systems in urban propagation environments;
- The internal behavior of the proposed deep learning model is explored using an explainable linear model, which considers some selected geometric features of the path profile;
- Simulation results as well as field measurements in a 5G New Radio (NR) network are shown.
2. Review of Conventional Path Loss Models
2.1. Walfisch–Ikegami Model
2.2. ABG Model
2.3. CI Model
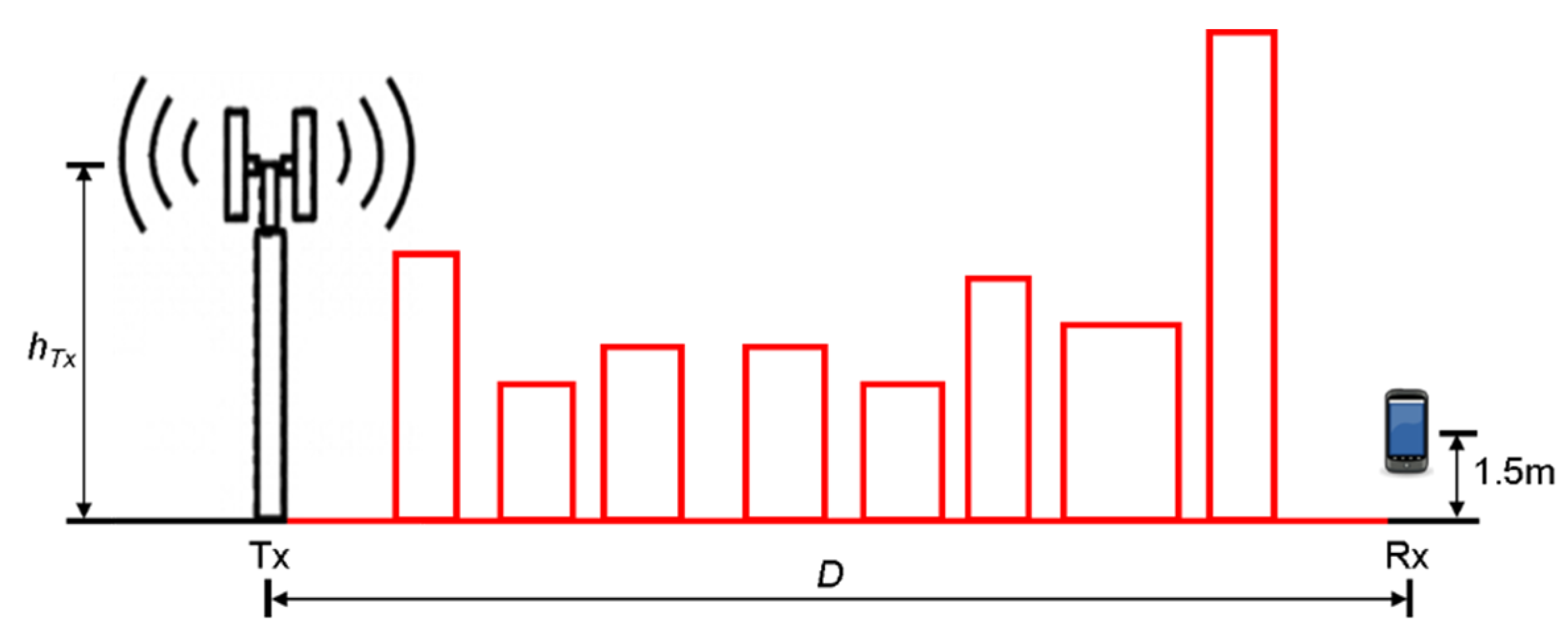
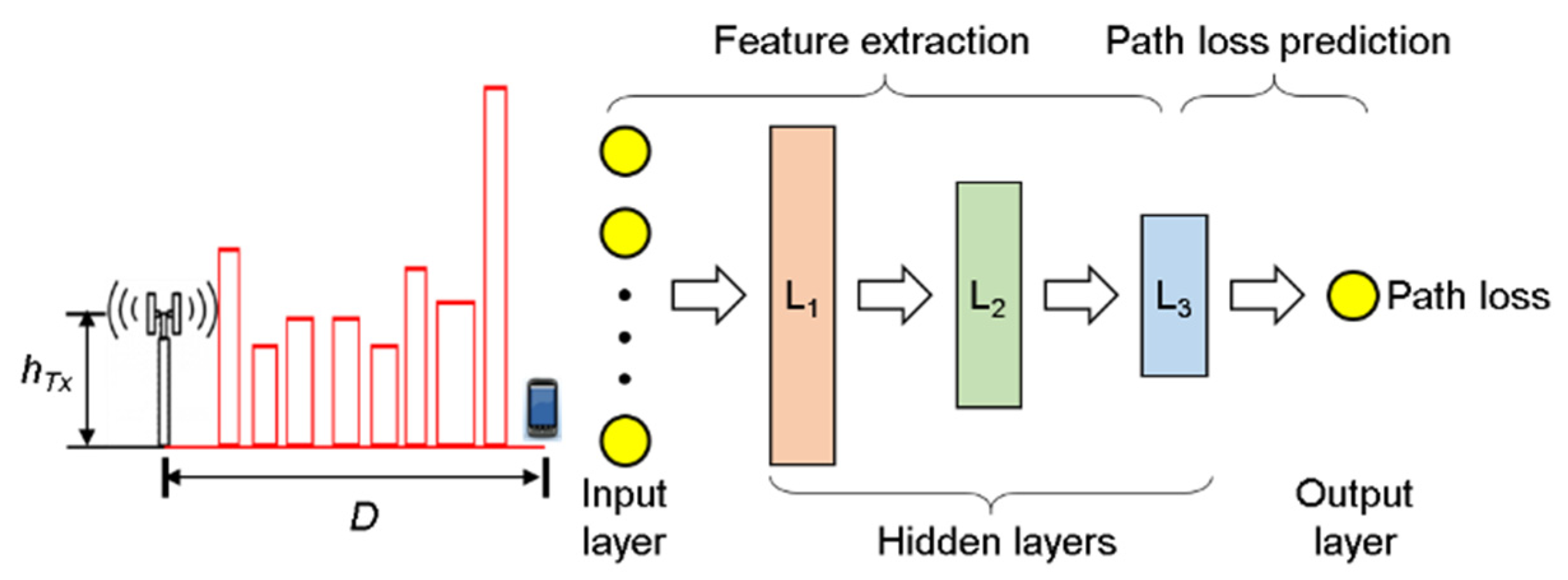
3. Problem Formulation and the Proposed Path Loss Model
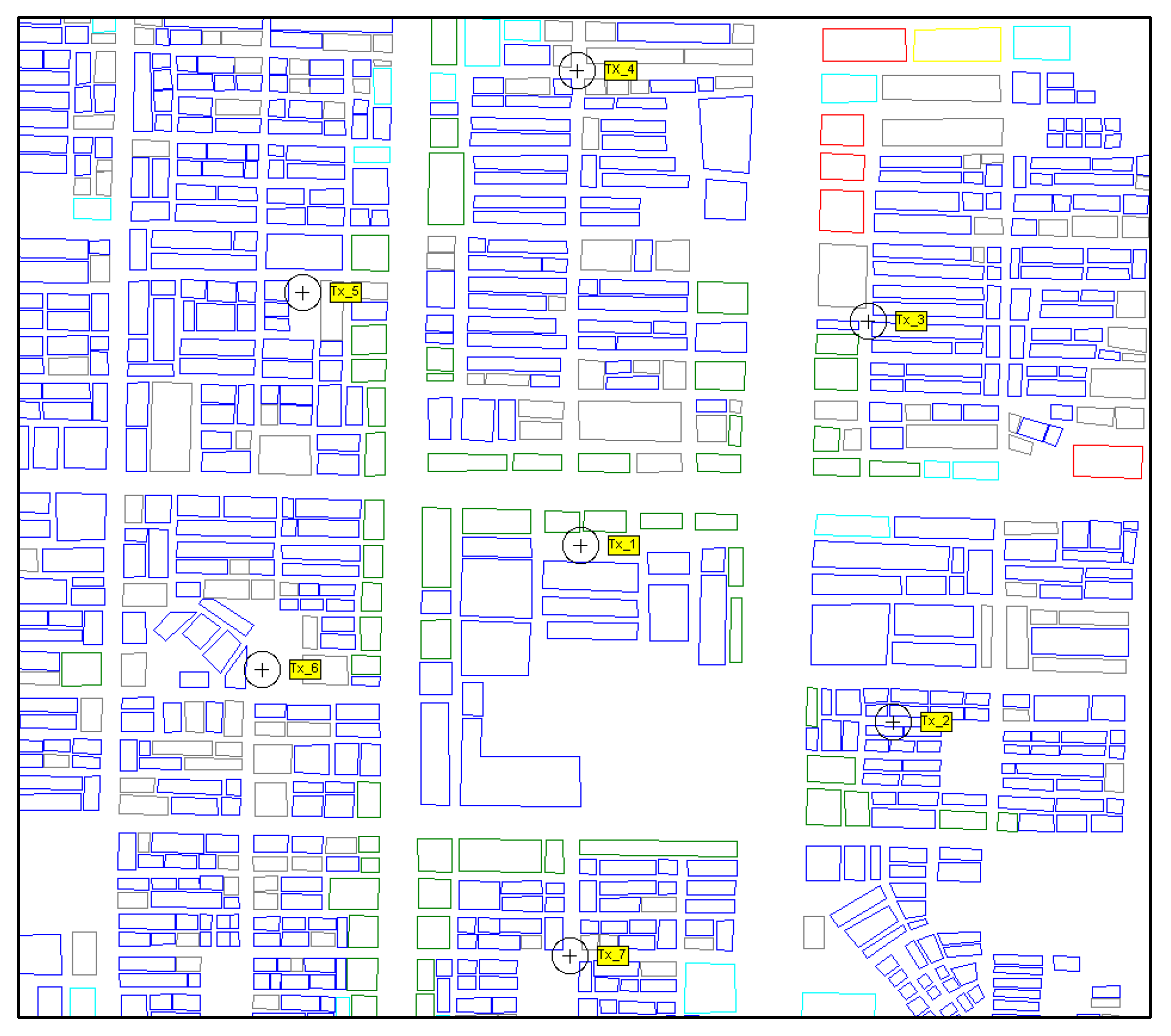
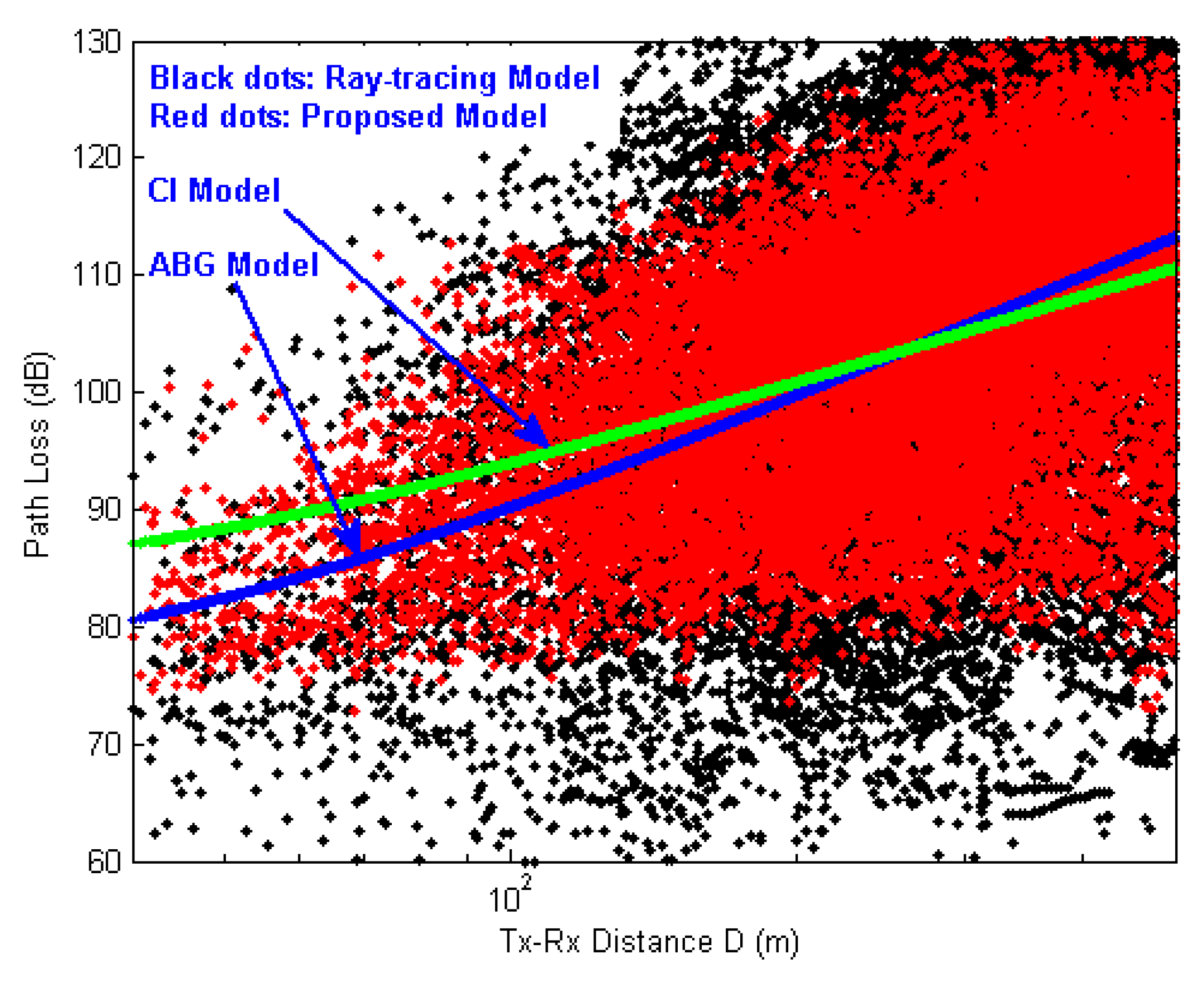
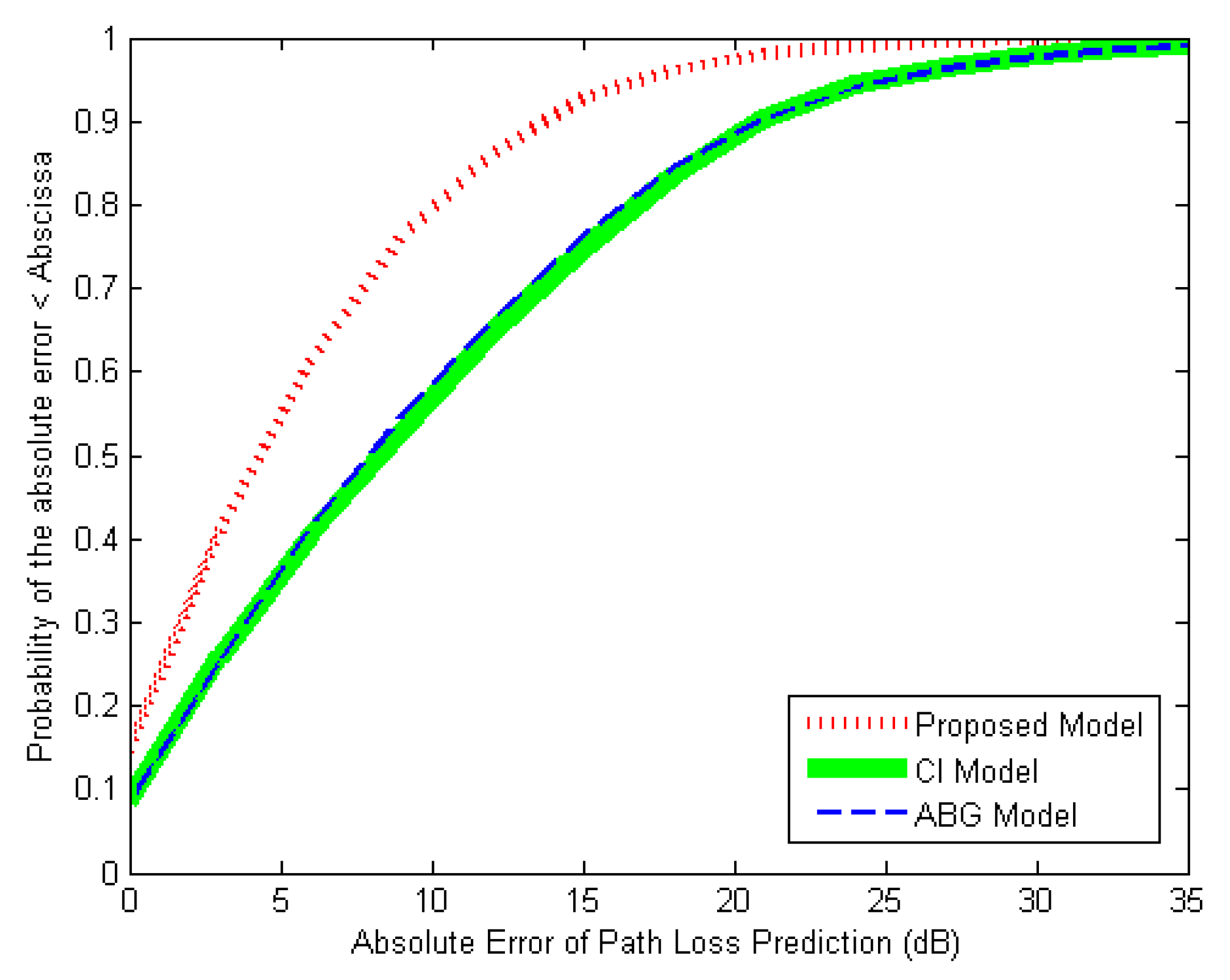
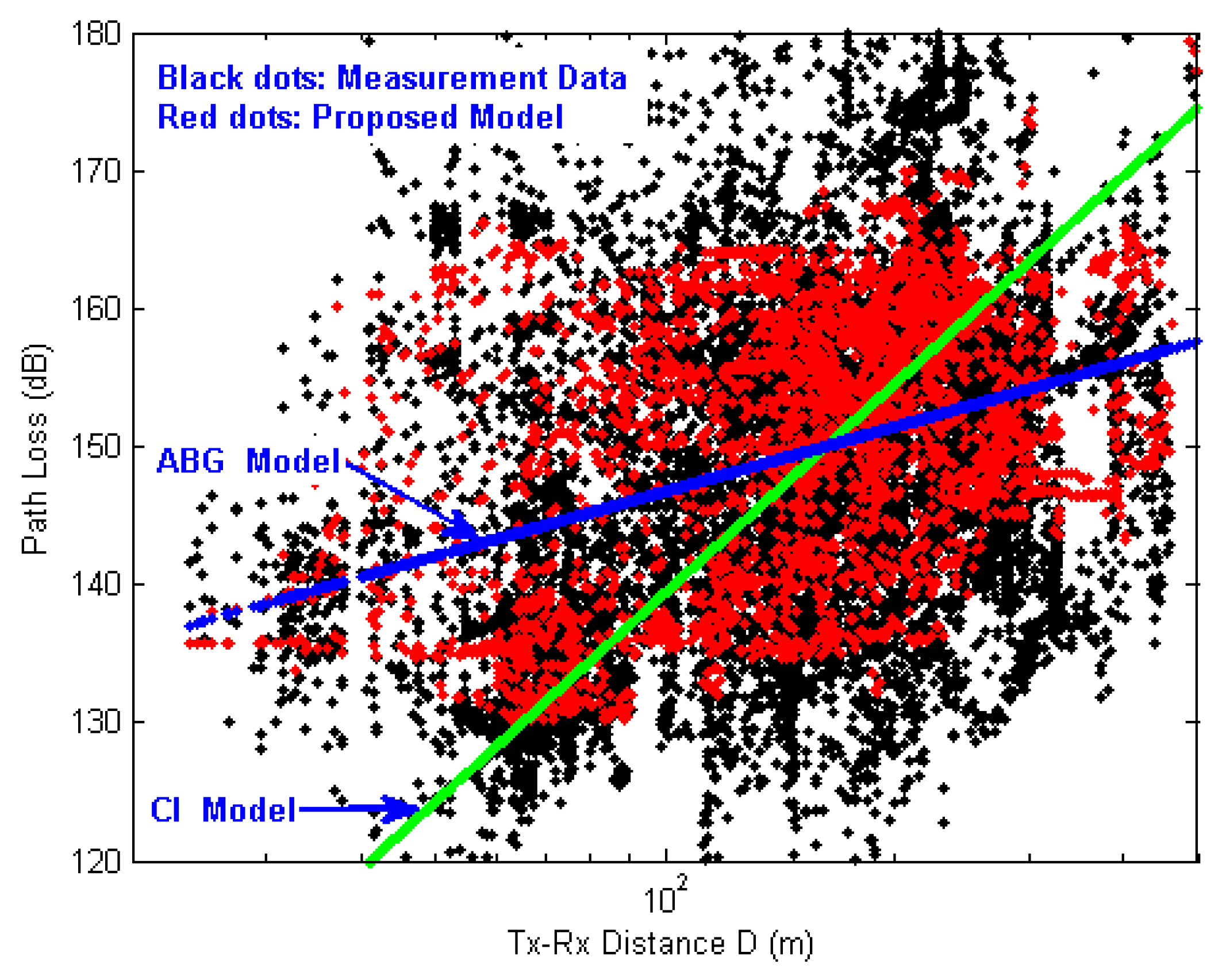
4. Analysis of Simulation Results
5. Explainability of the Proposed Model
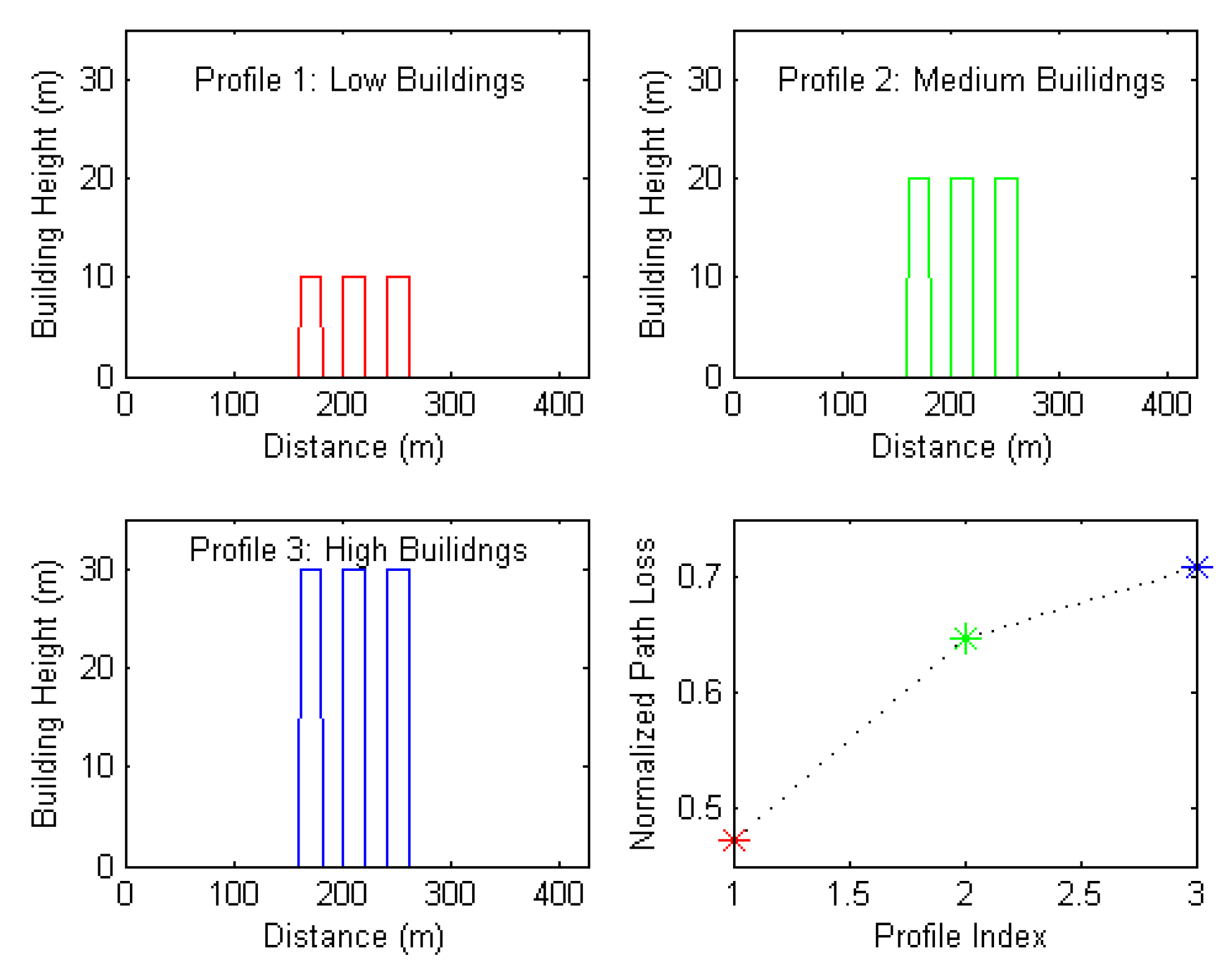
- Mean value of building height: the obstruction of buildings results in propagation loss; therefore, this feature is the arithmetic mean of building heights along the profile. Figure 7 shows three selected path profiles with low, medium, and high values of this feature. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 7 shows the relationship between the path losses and the path profiles. The x-axis in the subfigure is the index of the path profile, and the y-axis is the output of the proposed deep learning model, which is a normalized path loss. This subfigure can be interpreted as the mean value of building height being relevant to outcomes of the proposed path loss model. Note that although the three classes, namely, low, medium and high, may not be sufficient to derive the exact relationship, e.g., linear, cubic, quadratic, etc., they are sufficient to verify the relevance between the feature and the path loss.
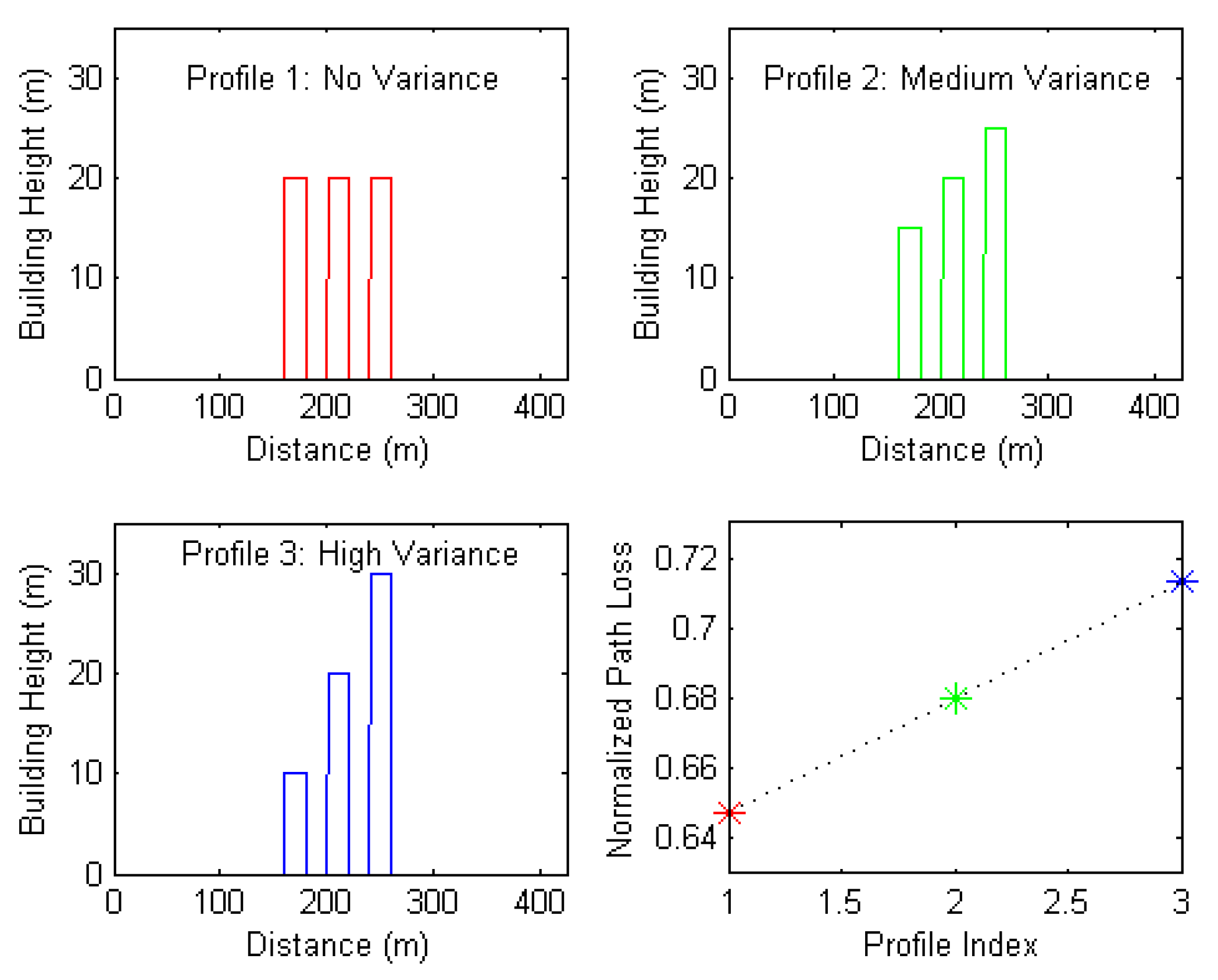
- Standard deviation of building height: this feature refers to the standard deviation of building heights along the profile. Figure 8 shows three selected path profiles with zero, medium, and high values of this feature. These three profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 8 suggests a positive linear correlation between this feature and the predicted path loss.
- Normalized mean value of building distance: analogously to the two aforementioned features which take the statistics in the vertical axis, this feature and the subsequent one take the statistics in the horizontal axis. This feature is the arithmetic mean of the distances from the Tx to the buildings along the profile. The mean value is normalized by the Tx–Rx separation distance. Figure 9 shows three selected path profiles with buildings that are near the Tx, far from the Tx, and in between the Tx–Rx pair. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 9 indicates a non-linear relationship between this feature and the predicted path loss.
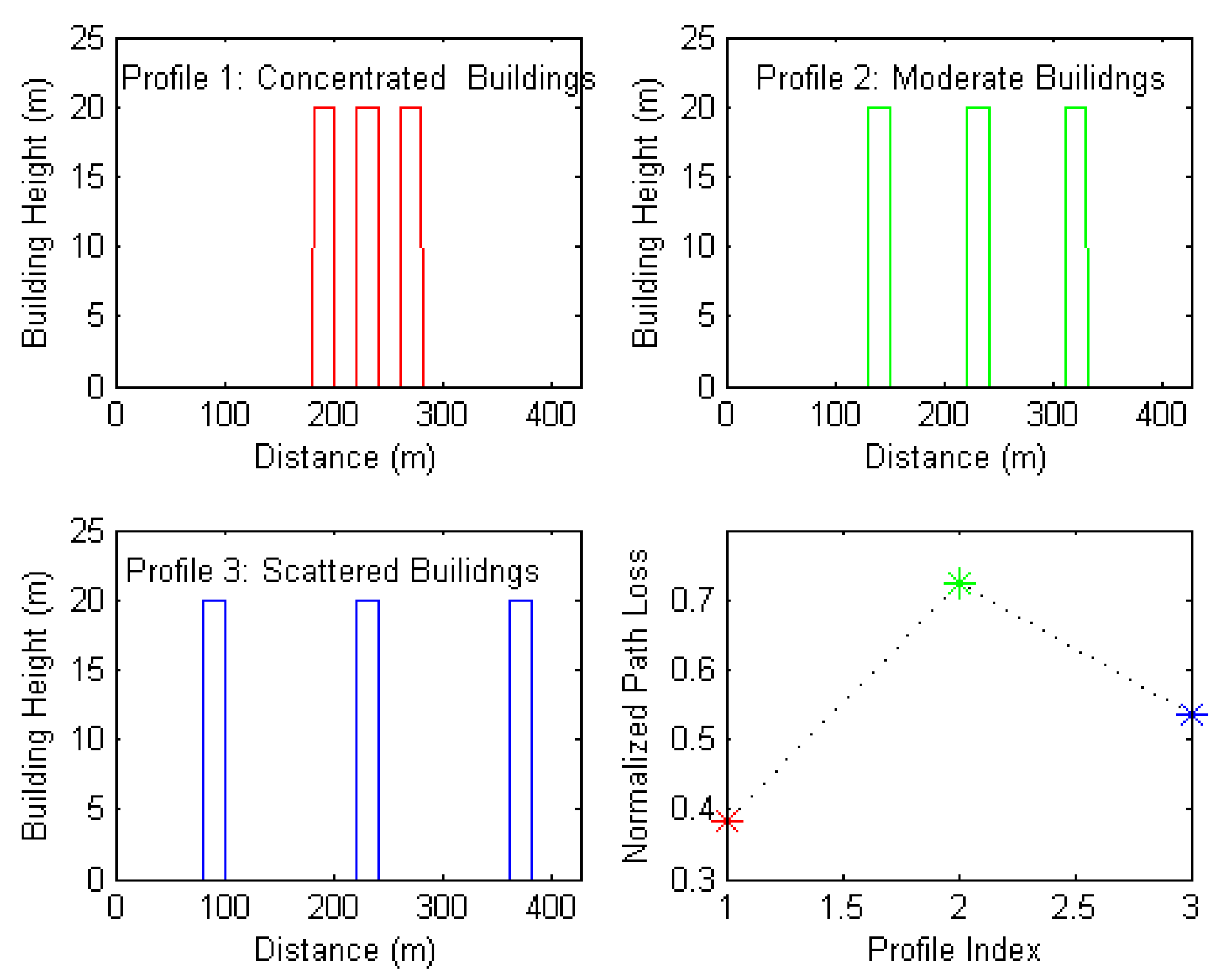
- Normalized standard deviation of building distance: this feature refers to the standard deviation of the distances from the Tx to the buildings along the profile. The standard deviation is normalized by the Tx–Rx separation distance. Figure 10 shows three selected path profiles with concentrated buildings, scattered buildings, and moderate buildings. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 10 indicates a non-linear relationship between this feature and the predicted path loss.
- Building density: in addition to the above two statistics in the horizontal axis, this feature describes the percentage of buildings along the profile. Figure 11 shows three selected path profiles with low, medium, and high values of this feature. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 11 shows that this feature and the predicted path loss have a positive relationship that can be approximated in a linear form.
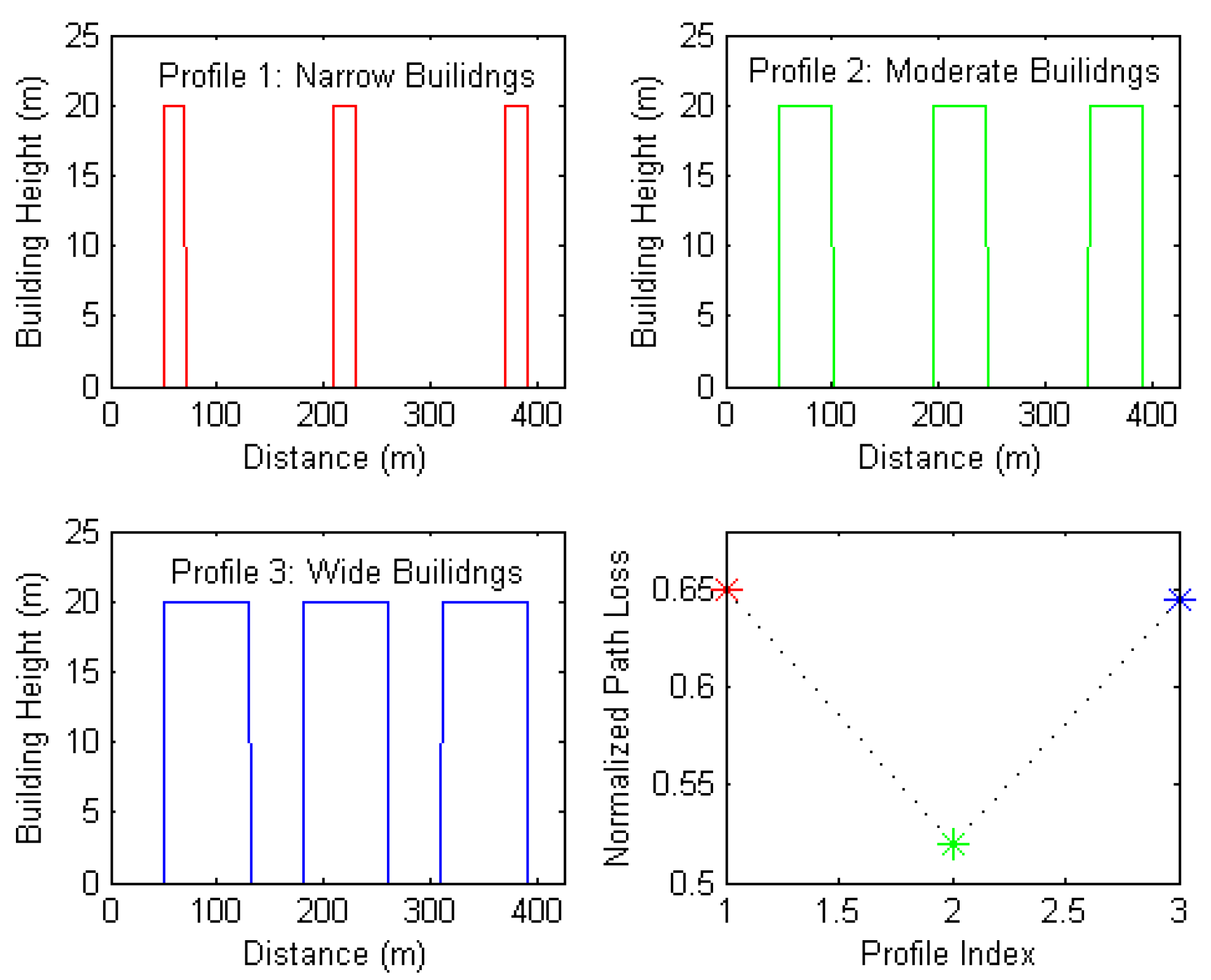
- Average building width: this feature refers to the arithmetic mean building width along the profile. It also implies the average street width. Figure 12 shows three selected path profiles with narrow buildings, wide buildings, and moderate buildings. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 12 indicates a non-linear relationship between this feature and the predicted path loss
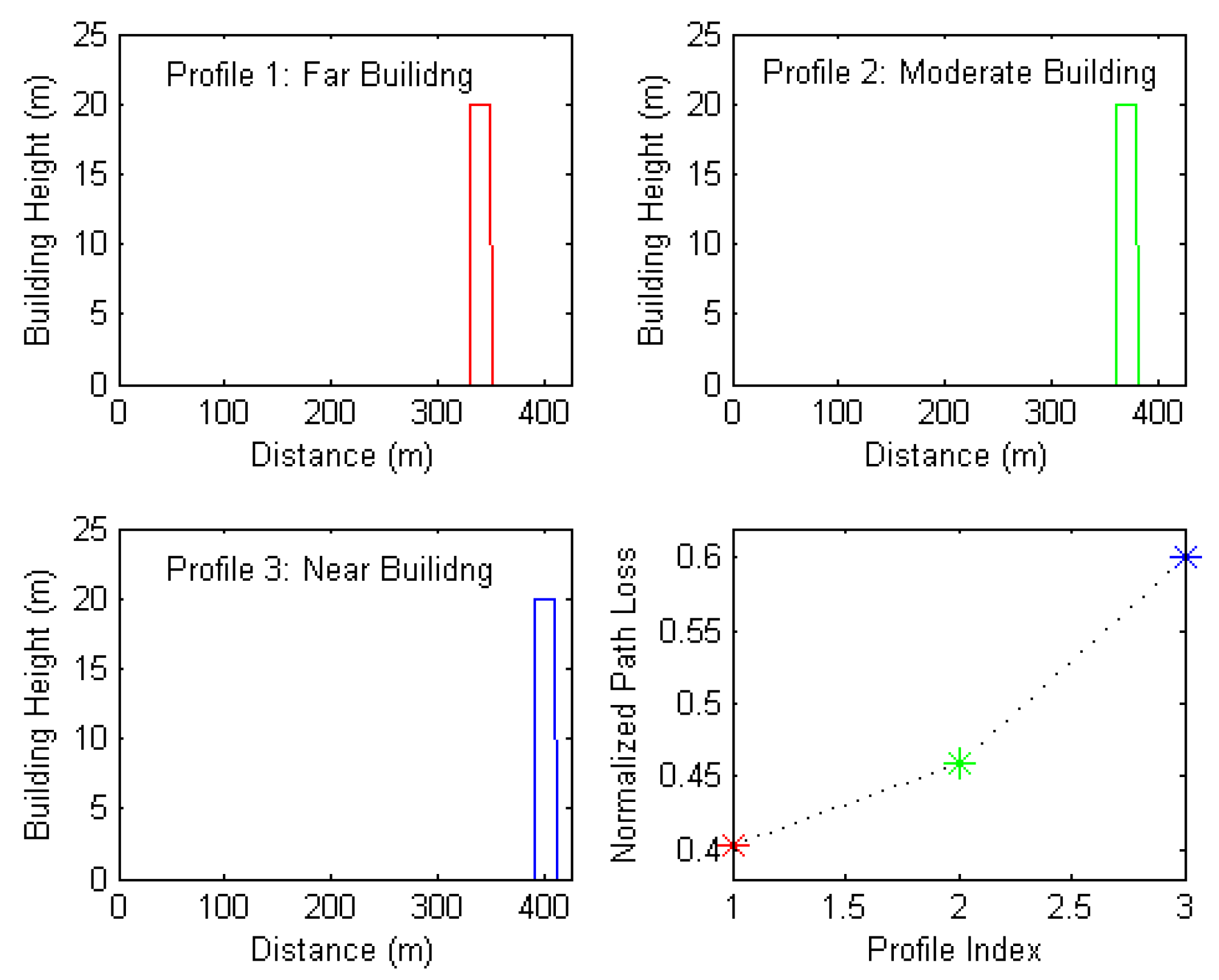
- Distance to the nearest building from the Rx: in general, the path loss tends to be high when a high building is close to the Rx. This feature refers to the distance from the Rx to the nearest building along the profile. Figure 13 shows three selected path profiles with a building far from the Rx, near the Rx, and at a moderate distance. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 13 indicates that this feature is relevant to the path loss prediction.
- Height of the nearest building from the Rx: this feature is the height of the nearest building along the profile from the Rx. Figure 14 shows three selected path profiles with low, medium, and high values of this feature. These profiles were inputted into the network and their corresponding outputs were reordered. The subfigure in the bottom right of Figure 14 suggests a positive linear correlation between this feature and the predicted path loss.
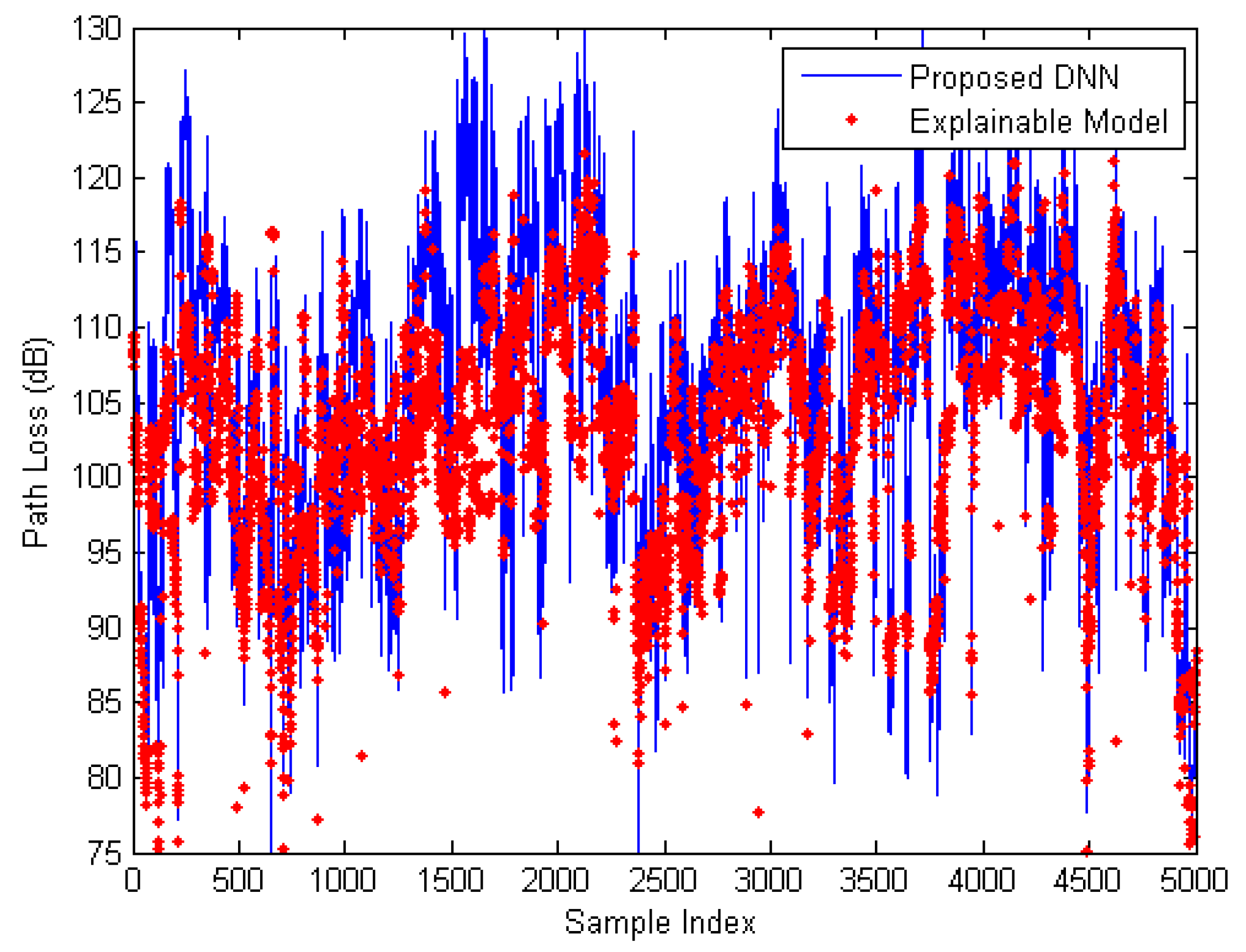
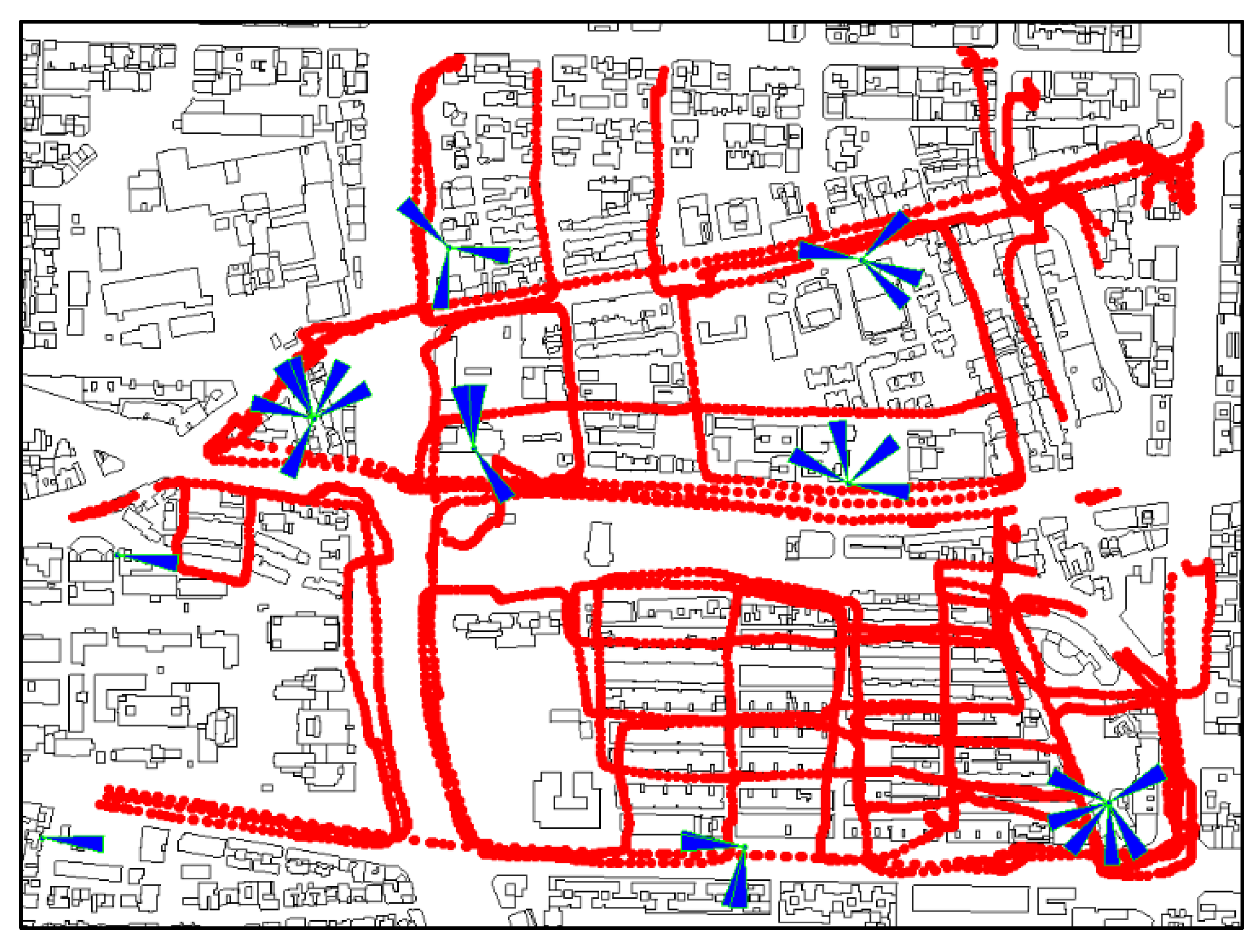
6. Verifying Performance using 5G NR Measurement Data
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Vannithamby, R.; Talwar, S. Towards 5G: Applications, Requirements and Candidate Technologies; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Popoola, S.I.; Atayero, A.A.; Arausi, O.D.; Matthews, V.O. Path loss Dataset for Modeling Radio Wave Propagation in Smart Campus Environment. ELSEVIER Data Brief 2018, 17, 1062–1073. [Google Scholar] [CrossRef]
- Salous, S.; Lee, J.; Kim, M.D.; Sasaki, M.; Yamada, W.; Raimundo, X.; Cheema, A.A. Radio Propagation Measurements and Modeling for Standardization of the Site General Path Loss Model in International Telecommunications Union Recommendations for 5G Wireless Networks. Radio Sci. 2020, 55, e2019RS006924. [Google Scholar] [CrossRef] [Green Version]
- Shabbira, N.; Kütta, L.; Alamb, M.M.; Roosipuub, P.; Jawadc, M.; Qureshic, M.B.; Ansarid, A.R.; Nawaze, R. Vision Towards 5G: Comparison of Radio Propagation Models for Licensed and Unlicensed Indoor Femtocell Sensor Networks. ELSEVIER Phys. Commun. 2021, 47, 101371. [Google Scholar] [CrossRef]
- Sun, S.; Rappaport, T.S.; Thomas, T.A.; Ghosh, A.; Nguyen, H.C.; Kovács, I.Z.; Rodriguez, I.; Koymen, O.; Partyka, A. Investigation of Prediction Accuracy, Sensitivity, and Parameter Stability of Large-Scale Propagation Path Loss Models for 5G Wireless Communications. IEEE Trans. Veh. Technol. 2016, 65, 2843–2860. [Google Scholar] [CrossRef]
- Casillas-Perez, D.; Camacho-Gómez, C.; Jiménez-Fernandez, S.; Portilla-Figueras, J.A.; Salcedo-Sanz, S. Weighted ABG: A General Framework for Optimal Combination of ABG Path-Loss Propagation Models. IEEE Access 2020, 8, 101758–101769. [Google Scholar] [CrossRef]
- Samimi, M.K.; Rappaport, T.S.; MacCartney, G.R., Jr. Probabilistic Omnidirectional Path Loss Models for Millimeter-Wave Outdoor Communications. IEEE Wirel. Commun. Lett. 2015, 4, 357–360. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, J.; Yang, G.; He, Z.; Wang, J. Path Loss Prediction Based on Machine Learning: Principle, Method, and Data Expansion. Appl. Sci. 2019, 9, 1908. [Google Scholar] [CrossRef] [Green Version]
- Moraitis, M.; Tsipi, L.; Vouyioukas, D. Machine Learning-Based Methods for Path Loss Prediction in Urban Environment for LTE Networks. In Proceedings of the IEEE International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Thessaloniki, Greece, 12–14 October 2020. [Google Scholar]
- Thrane, J.; Zibar, D.; Christiansen, H.L. Model-Aided Deep Learning Method for Path Loss Prediction in Mobile Communication Systems at 2.6 GHz. IEEE Access 2020, 8, 7925–7936. [Google Scholar] [CrossRef]
- Ates, H.F.; Hashir, S.M.; Baykas, T.; Gunturk, B.K. Path Loss Exponent and Shadowing Factor Prediction from Satellite Images using Deep Learning. IEEE Access 2019, 7, 101366–101375. [Google Scholar] [CrossRef]
- Cheng, H.; Ma, S.; Lee, H. CNN-Based mmWave Path Loss Modeling for Fixed Wireless Access in Suburban Scenarios. IEEE Antennas Propag. Lett. 2020, 19, 1694–1698. [Google Scholar] [CrossRef]
- Ahmadien, O.; Ates, H.F.; Baykas, T.; Gunturk, B.K. Predicting Path Loss Distribution of an Area from Satellite Images Using Deep Learning. IEEE Access 2020, 8, 64982–64991. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Guo, W. Explainable Artificial Intelligence for 6G: Improving Trust between Human and Machine. IEEE Commun. Mag. 2020, 58, 39–45. [Google Scholar] [CrossRef]
- Saunders, S.R. Antennas and Propagation for Wireless Communication Systems; Wiley: Hoboken, NJ, USA, 1999. [Google Scholar]
- Har, D.; Watson, A.M.; Chadney, A.G. Comment on Diffraction Loss of Rooftop-to-Street in COST 231-Walfisch–Ikegami Model, IEEE Trans. Veh. Technol. 1999, 48, 1451–1452. [Google Scholar] [CrossRef]
- Sun, S.; Rappaport, T.S.; Rangan, S.; Thomas, T.A.; Ghosh, A.; Kovacs, I.Z.; Rodriguez, I.; Koymen, O.; Partyka, A.; Jarvelainen, J. Propagation Path Loss Models for 5G Urban Micro- and Macro-Cellular Scenarios. In Proceedings of the IEEE Vehicular Technology Conference, Nanjing, China, 15–18 May 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Siddique, M.N.H.; Tokhi, M.O. Training neural networks: Backpropagation vs. genetic algorithms. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July 2001. [Google Scholar]
- Ai, B.; Guan, K.; He, R.; Li, J.; Li, G.; He, D.; Zhong, Z.; Huq, K.M.S. On Indoor Millimeter Wave Massive MIMO Channels: Measurement and Simulation. IEEE J. Sel. Areas Commun. 2017, 35, 1678–1690. [Google Scholar] [CrossRef]
- Zhu, M.; Singh, A.; Tufvesson, F. Measurement Based Ray Launching for Analysis of Outdoor Propagation. In Proceedings of the 6th European Conference Antennas and Propagation (EUCAP), Prague, Czech Republic, 26–30 March 2012. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Value |
|---|---|
| Input length | 502 |
| Output length | 1 |
| Number of hidden layers | 3 |
| Number of hidden neurons | 502, 128, 8 |
| Dropout rate | 0.18 |
| Batch size | 128 |
| Optimizer | Adam |
| Loss function | MSE |
| Activation function for feature extraction () | ReLU |
| Activation function for path loss regression () | Sigmoid |
| Mean Error (dB) | Standard Deviation (dB) | |
|---|---|---|
| ABG model | 0.05 | 13.84 |
| CI model | 0.15 | 13.97 |
| Proposed model | 0.04 | 9.13 |
| Improvement over the ABG model | - | 4.71 (34%) |
| Improvement over the CI model | - | 4.84 (34%) |
| Mean Error (dB) | Standard Deviation (dB) | |
|---|---|---|
| ABG model | 0.00 | 11.11 |
| CI model | −0.84 | 13.69 |
| Proposed model | 0.42 | 7.70 |
| Improvement over the ABG model | - | 3.41 (30%) |
| Improvement over the CI model | - | 5.99 (43%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juang, R.-T. Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments. Appl. Sci. 2021, 11, 6690. https://doi.org/10.3390/app11156690
Juang R-T. Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments. Applied Sciences. 2021; 11(15):6690. https://doi.org/10.3390/app11156690
Chicago/Turabian StyleJuang, Rong-Terng. 2021. "Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments" Applied Sciences 11, no. 15: 6690. https://doi.org/10.3390/app11156690
APA StyleJuang, R.-T. (2021). Explainable Deep-Learning-Based Path Loss Prediction from Path Profiles in Urban Environments. Applied Sciences, 11(15), 6690. https://doi.org/10.3390/app11156690