Correction: Huang et al. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426


1. Changes in Tables
2. Changes in the Statements Corresponding to the Tables
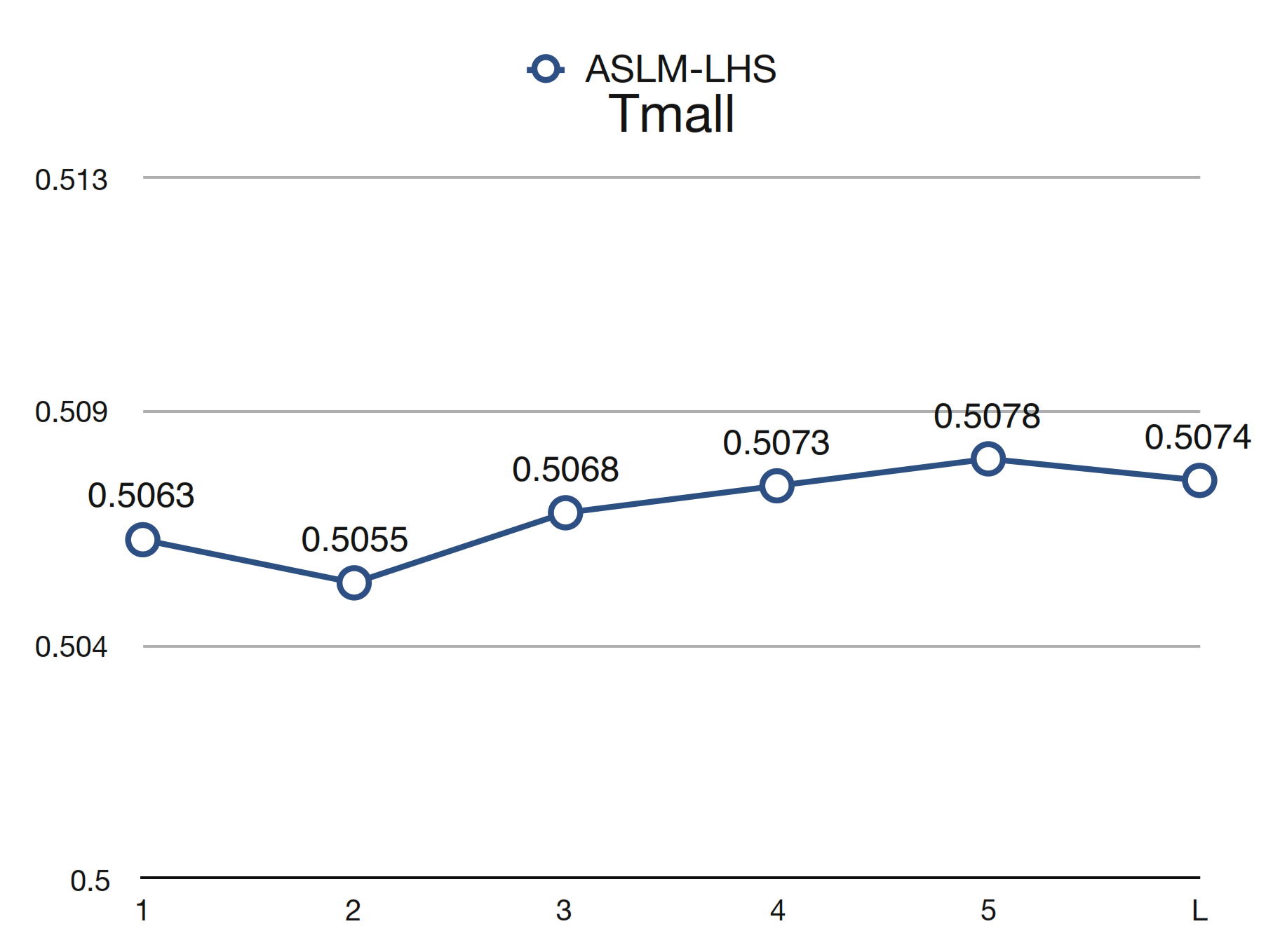
3. Changes in Figures
4. Changes in the Statements Corresponding to the Figures
5. Change in the Description of the Last.fm Dataset
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Reference
- Huang, R.; McIntyre, S.; Song, M.; E, H.; Ou, Z. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
|---|---|---|---|---|---|---|
| Most Popular | 0.1241 | 0.1799 | 0.2499 | 0.0817 | 0.0890 | 0.0940 |
| II-RNN-AP | 0.2943 | 0.3717 | 0.4527 | 0.1920 | 0.2024 | 0.2080 |
| II-RNN-LHS | 0.3112 | 0.3904 | 0.4709 | 0.2025 | 0.2131 | 0.2186 |
| ASLM-AP | 0.3162 | 0.3879 | 0.4643 | 0.2277 | 0.2373 | 0.2426 |
| (+1.62%) | (−0.63%) | (−1.40%) | (+12.44%) | (+11.36%) | (+10.95%) | |
| ASLM-LHS | 0.3396 | 0.4100 | 0.4843 | 0.2473 | 0.2567 | 0.2619 |
| (+9.12%) | (+5.04%) | (+2.85%) | (+22.10%) | (+20.48%) | (+19.79%) | |
| (a) Reddit Dataset (Test). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
| Most Popular | 0.0569 | 0.0689 | 0.0866 | 0.0470 | 0.0487 | 0.0499 |
| II-RNN-AP | 0.1009 | 0.1341 | 0.1784 | 0.0682 | 0.0725 | 0.0755 |
| II-RNN-LHS | 0.0855 | 0.1142 | 0.1555 | 0.0588 | 0.0625 | 0.0654 |
| ASLM-AP | 0.1053 | 0.1387 | 0.1837 | 0.0732 | 0.0776 | 0.0806 |
| (+4.36%) | (+3.46%) | (+3.01%) | (+7.33%) | (+6.99%) | (+6.75%) | |
| ASLM-LHS | 0.1042 | 0.1415 | 0.1914 | 0.0693 | 0.0742 | 0.0776 |
| (+3.34%) | (+5.52%) | (+7.31%) | (+1.66%) | (+2.34%) | (+2.78%) | |
| (b) Last.fm Dataset (Test). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
|---|---|---|---|---|---|---|
| Most Popular | 0.1451 | 0.2155 | 0.2882 | 0.0966 | 0.1060 | 0.1111 |
| II-RNN-AP | 0.1484 | 0.2161 | 0.2928 | 0.0969 | 0.1058 | 0.1112 |
| II-RNN-LHS | 0.1614 | 0.2292 | 0.3062 | 0.1061 | 0.1151 | 0.1204 |
| ASLM-AP | 0.1904 | 0.2507 | 0.3245 | 0.1256 | 0.1336 | 0.1387 |
| (+17.96%) | (+9.38%) | (+5.98%) | (+18.37%) | (+16.07%) | (+15.17%) | |
| ASLM-LHS | 0.1886 | 0.2488 | 0.3251 | 0.1234 | 0.1314 | 0.1366 |
| (+16.83%) | (+8.55%) | (+6.19%) | (+16.27%) | (+14.13%) | (+13.48%) | |
| (a) 1/10 Reddit Dataset (Test). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
| Most Popular | 0.0371 | 0.0493 | 0.0596 | 0.0290 | 0.0308 | 0.0314 |
| II-RNN-AP | 0.0349 | 0.0448 | 0.0604 | 0.0282 | 0.0294 | 0.0305 |
| II-RNN-LHS | 0.0361 | 0.0459 | 0.0608 | 0.0285 | 0.0298 | 0.0308 |
| ASLM-AP | 0.0388 | 0.0496 | 0.0656 | 0.0308 | 0.0323 | 0.0334 |
| (+4.38%) | (+0.57%) | (+7.95%) | (+6.18%) | (+4.93%) | (+6.13%) | |
| ASLM-LHS | 0.0388 | 0.0503 | 0.0674 | 0.0309 | 0.0324 | 0.0336 |
| (+4.38%) | (+1.92%) | (+10.97%) | (+6.52%) | (+5.37%) | (+6.98%) | |
| (b) 1/80 Last.fm Dataset (Test). | ||||||
| R@10 | R@20 | MRR@20 | |
|---|---|---|---|
| Most Popular | 0.0234 | 0.0420 | 0.0123 |
| SWIWO-I | 0.3177 | 0.3810 | 0.1903 |
| SWIWO | 0.3082 | 0.3703 | 0.1885 |
| ASLM-AP | 0.5412 | 0.5661 | 0.4037 |
| (+70.34%) | (+48.57%) | (+112.12%) | |
| ASLM-LHS | 0.5428 | 0.5679 | 0.4082 |
| (+70.86%) | (+49.06%) | (+114.50%) |
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
|---|---|---|---|---|---|---|
| Most Popular | 0.1269 | 0.1830 | 0.2529 | 0.0835 | 0.0908 | 0.0957 |
| II-RNN-AP | 0.3024 | 0.3827 | 0.4653 | 0.1971 | 0.2079 | 0.2136 |
| II-RNN-LHS | 0.3191 | 0.4013 | 0.4837 | 0.2073 | 0.2182 | 0.2239 |
| ASLM-AP | 0.3255 | 0.3991 | 0.4768 | 0.2336 | 0.2434 | 0.2488 |
| (+2.02%) | (−0.54%) | (−1.43%) | (+12.72%) | (+11.55%) | (+11.10%) | |
| ASLM-LHS | 0.3489 | 0.4218 | 0.4982 | 0.2527 | 0.2624 | 0.2677 |
| (+9.34%) | (+5.12%) | (+3.00%) | (+21.90%) | (+20.26%) | (+19.56%) | |
| (a) Reddit Dataset (Validation). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
| Most Popular | 0.0563 | 0.0685 | 0.0862 | 0.0460 | 0.0477 | 0.0489 |
| II-RNN-AP | 0.1082 | 0.1460 | 0.1962 | 0.0703 | 0.0753 | 0.0787 |
| II-RNN-LHS | 0.0921 | 0.1249 | 0.1705 | 0.0614 | 0.0658 | 0.0689 |
| ASLM-AP | 0.1147 | 0.1526 | 0.2027 | 0.0776 | 0.0826 | 0.0860 |
| (+6.07%) | (+4.50%) | (+3.33%) | (+10.44%) | (+9.69%) | (+9.36%) | |
| ASLM-LHS | 0.1179 | 0.1613 | 0.2186 | 0.0760 | 0.0818 | 0.0857 |
| (+9.00%) | (+10.48%) | (+11.42%) | (+8.21%) | (+8.63%) | (+8.94%) | |
| (b) Last.fm Dataset (Validation). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
|---|---|---|---|---|---|---|
| Most Popular | 0.1516 | 0.2206 | 0.2913 | 0.1004 | 0.1095 | 0.1145 |
| II-RNN-AP | 0.1551 | 0.2215 | 0.2966 | 0.1026 | 0.1113 | 0.1165 |
| II-RNN-LHS | 0.1702 | 0.2366 | 0.3116 | 0.1108 | 0.1196 | 0.1248 |
| ASLM-AP | 0.1982 | 0.2563 | 0.3282 | 0.1315 | 0.1392 | 0.1442 |
| (+16.47%) | (+8.33%) | (+5.32%) | (+18.68%) | (+16.42%) | (+15.58%) | |
| ASLM-LHS | 0.1935 | 0.2549 | 0.3302 | 0.1275 | 0.1356 | 0.1408 |
| (+13.71%) | (+7.76%) | (+5.96%) | (+15.04%) | (+13.38%) | (+12.82%) | |
| (a) 1/10 Reddit Dataset (Validation). | ||||||
| R@5 | R@10 | R@20 | MRR@5 | MRR@10 | MRR@20 | |
| Most Popular | 0.0360 | 0.0473 | 0.0626 | 0.0284 | 0.0299 | 0.0310 |
| II-RNN-AP | 0.0343 | 0.0411 | 0.0563 | 0.0286 | 0.0295 | 0.0306 |
| II-RNN-LHS | 0.0372 | 0.0454 | 0.0641 | 0.0317 | 0.0327 | 0.0340 |
| ASLM-AP | 0.0380 | 0.0476 | 0.0663 | 0.0318 | 0.0330 | 0.0343 |
| (+1.97%) | (+0.55%) | (+3.54%) | (+0.21%) | (+0.92%) | (+0.88%) | |
| ASLM-LHS | 0.0398 | 0.0482 | 0.0644 | 0.0321 | 0.0332 | 0.0343 |
| (+6.89%) | (+1.75%) | (+0.57%) | (+1.26%) | (+1.43%) | (+0.88%) | |
| (b) 1/80 Last.fm Dataset (Validation). | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.; McIntyre, S.; Song, M.; E, H.; Ou, Z. Correction: Huang et al. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426. Appl. Sci. 2021, 11, 6633. https://doi.org/10.3390/app11146633
Huang R, McIntyre S, Song M, E H, Ou Z. Correction: Huang et al. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426. Applied Sciences. 2021; 11(14):6633. https://doi.org/10.3390/app11146633
Chicago/Turabian StyleHuang, Ruo, Shelby McIntyre, Meina Song, Haihong E, and Zhonghong Ou. 2021. "Correction: Huang et al. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426" Applied Sciences 11, no. 14: 6633. https://doi.org/10.3390/app11146633
APA StyleHuang, R., McIntyre, S., Song, M., E, H., & Ou, Z. (2021). Correction: Huang et al. An Attention-Based Recommender System to Predict Contextual Intent Based on Choice Histories across and within Sessions. Appl. Sci. 2018, 8, 2426. Applied Sciences, 11(14), 6633. https://doi.org/10.3390/app11146633