
Learning Attention-Aware Interactive Features for Fine-Grained Vegetable and Fruit Classification



Abstract
:1. Introduction
2. Related Work
2.1. Methods Based on Localization–Classification Subnetworks
2.2. Methods Based on End-to-End Feature Encoding
2.3. Methods Using Data Augmentation
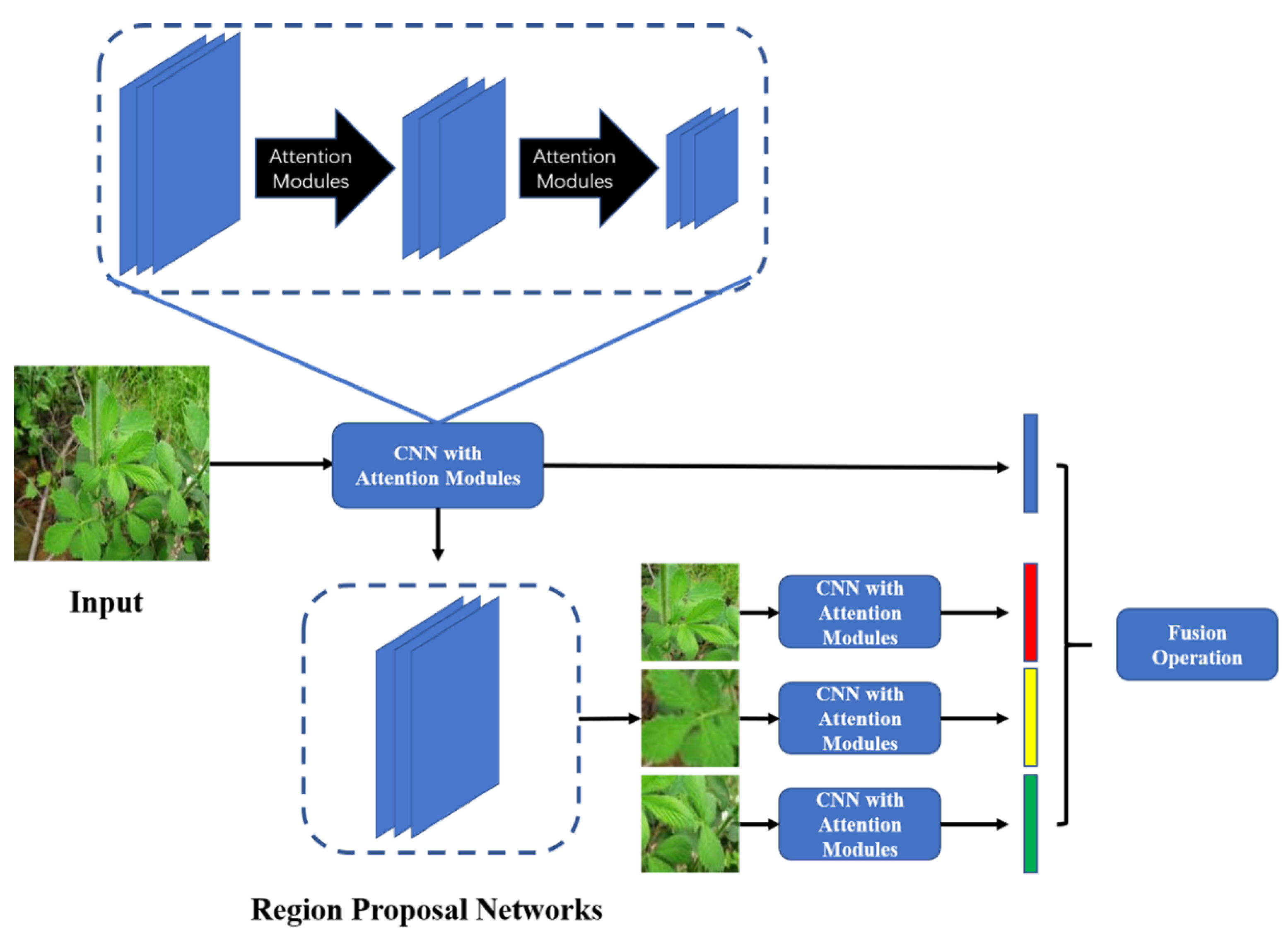
3. The Attention-Aware Interactive Features Network
3.1. Attentive Feature Extraction
3.1.1. Attention Modules in AIF-Net
3.1.2. Region Proposal Network
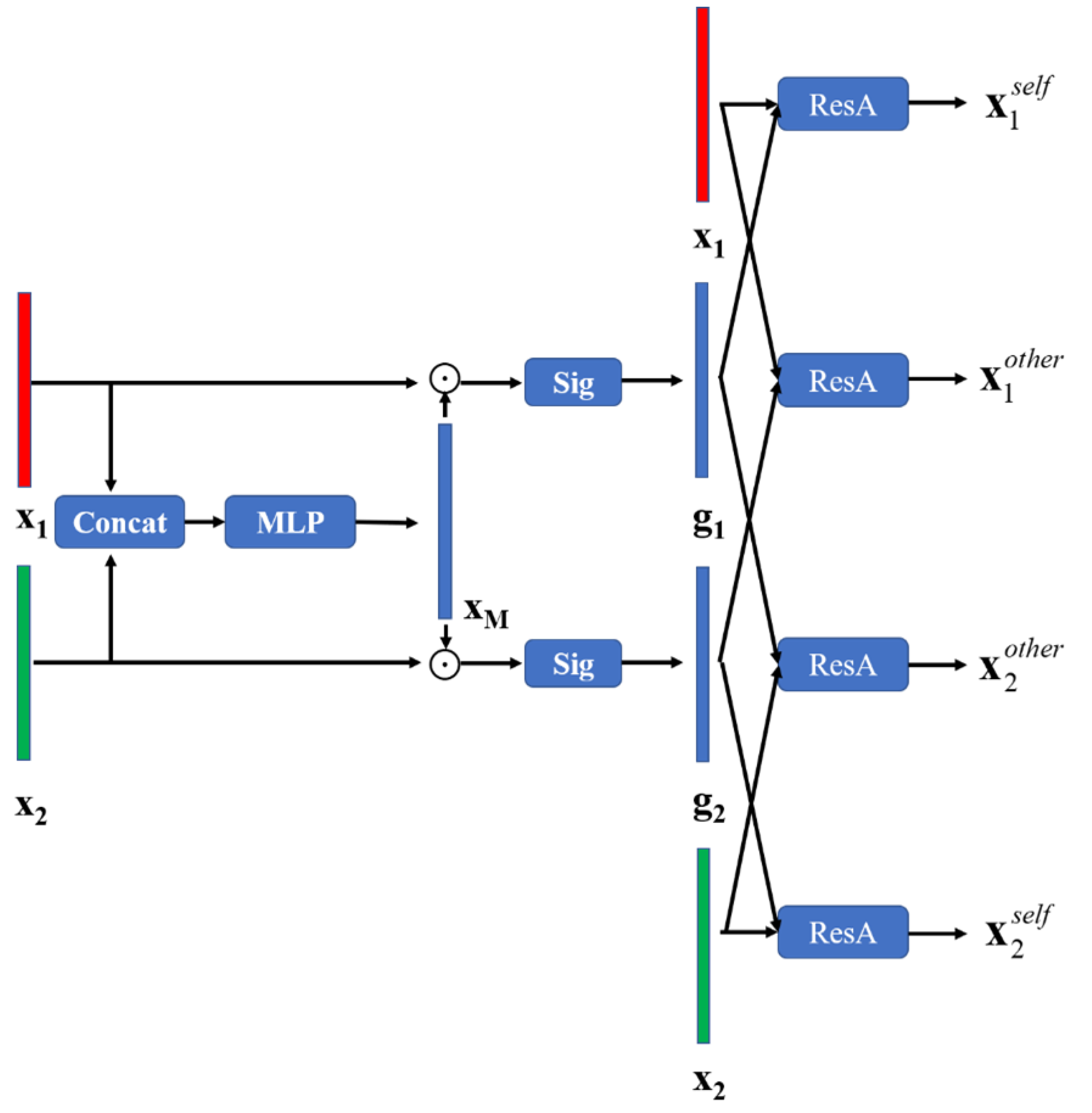
3.2. Interactive Feature Learning
3.3. Softmax Classifier with Individual and Pair Regularization Terms
4. Experiments
4.1. Data Set
4.2. Implementation Details
4.3. Performance Metric
4.4. Benchmarks
- For ResNet50, the initial learning rate was set to 0.001, with an exponential decay of 0.1 after every 30 epochs.
- For VGG, CBP and HybridNet, the results are referenced from [13].
- For DCL, the division number for Region Confusion Mechanism (RCM) was set to 7.
- For API-Net, the experimental settings were the same as ours.
- For WS-DAN, the last convolutional layer was chosen as the feature map. The SGD with momentum of 0.9, a weight decay of 0.00001 were used. The initial learning rate was set to 0.001 with a exponential decay of 0.9 after every 2 epochs.
4.5. Ablation Study
4.5.1. Fusion Operation for Global and Local Feature Maps
4.5.2. Number of Local Informative Regions
4.6. Overall Performance Comparison
- AIF-Net presents the best performance in both top-1 and top-5 Acc on the VegFru292 set, outperforming the second-best, ResNet50, by 2.83% in top-1 and 0.627% in top-5. On Veg200, AIF-Net outperforms ResNet50 in top-1 Acc (89.154% vs. 88.195%) but slightly underperforms ResNet50 in top-5 Acc (98.045% vs. 98.187%). On Fru92, our AIF-Net outperforms the second-best API-Net by 1.14% in top-1 Acc, and also outperforms the second-best ResNet50 by 0.1% in top-5 Acc. It is observed that ResNet50, as a generic deep learning model, can achieve superior performance in this task, demonstrating its potential in FGVC. Additionally, the proposed AIF-Net presents its superior predictive power through interactive feature learning combined with a fusion of global and local attentive feature maps.
- Surprisingly, the SOTA methods (DCL, API-Net, and WS-DAN) that use ResNet50 as a backbone underperform ResNet50 in both top-1 and top-5 Acc on the VegFru292 set. Although API-Net demonstrated superior performance in other data sets [14], its performance in VegFru is sightly worse than its backbone network ResNet50, except on Fru92, where API-Net posts a top-1 Acc of 89.914%, with a 0.59% improvement over ResNet50. The results show that with interactive feature learning alone, the model does not present consistent performance improvement on the VegFru data set.
- The proposed AIF-Net, on the other hand, demonstrates a consistent improvement over both ResNet50 and API-Net, which means that a combination of an attentive feature aggregation and interactive feature learning can effectively push a model to learn subtle and fine-grained patterns from both local and global attentive feature maps, leading to consistent performance boost.
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pu, J.; Jiang, Y.G.; Wang, J.; Xue, X. Which looks like which: Exploring inter-class relationships in fine-grained visual categorization. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 425–440. [Google Scholar]
- Zhang, L.; Huang, S.; Liu, W. Intra-class Part Swapping for Fine-Grained Image Classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021; pp. 3209–3218. [Google Scholar]
- Wei, X.S.; Wu, J.; Cui, Q. Deep learning for fine-grained image analysis: A survey. arXiv 2019, arXiv:1907.03069. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Montreal, QC, Canada, 2015; Volume 2. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sun, M.; Yuan, Y.; Zhou, F.; Ding, E. Multi-Attention Multi-Class Constraint for Fine-grained Image Recognition. In Proceedings of the Computer Vision—ECCV 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to Navigate for Fine-Grained Classification. In Proceedings of the Computer Vision—ECCV 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lin, T.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-Grained Visual Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact Bilinear Pooling. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kong, S.; Fowlkes, C. Low-Rank Bilinear Pooling for Fine-Grained Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.; RoyChowdhury, A.; Maji, S. Bilinear Convolutional Neural Networks for Fine-Grained Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1309–1322. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Zhao, X.; Zheng, Q.; Zhang, P.; You, X. Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition. In Proceedings of the Computer Vision—ECCV 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hou, S.; Feng, Y.; Wang, Z. VegFru: A Domain-Specific Dataset for Fine-Grained Visual Categorization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhuang, P.; Wang, Y.; Qiao, Y. Learning Attentive Pairwise Interaction for Fine-Grained Classification. arXiv 2020, arXiv:2002.10191. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Branson, S.; Van Horn, G.; Belongie, S.; Perona, P. Bird species categorization using pose normalized deep convolutional nets. arXiv 2014, arXiv:1406.2952. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Destruction and Construction Learning for Fine-Grained Image Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hu, T.; Qi, H. See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification. arXiv 2019, arXiv:1901.09891. [Google Scholar]
- Gavves, E.; Fernando, B.; Snoek, C.G.; Smeulders, A.W.; Tuytelaars, T. Fine-grained categorization by alignments. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1713–1720. [Google Scholar]
- Zheng, H.; Fu, J.; Mei, T.; Luo, J. Learning Multi-attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kim, J.-H.; On, K.W.; Lim, W.; Kim, J.; Ha, J.; Zhang, B.-T. Hadamard Product for Low-rank Bilinear Pooling. arXiv 2016, arXiv:1610.04325. [Google Scholar]
- Dubey, A.; Gupta, O.; Guo, P.; Raskar, R.; Farrell, R.; Naik, N. Pairwise confusion for fine-grained visual classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 70–86. [Google Scholar]
- Zhang, C.; Yao, Y.; Liu, H.; Xie, G.S.; Shu, X.; Zhou, T.; Zhang, Z.; Shen, F.; Tang, Z. Web-supervised network with softly update-drop training for fine-grained visual classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12781–12788. [Google Scholar]
- Zhang, C.; Yao, Y.; Zhang, J.; Chen, J.; Huang, P.; Zhang, J.; Tang, Z. Web-supervised network for fine-grained visual classification. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Sun, X.; Chen, L.; Yang, J. Learning from web data using adversarial discriminative neural networks for fine-grained classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 273–280. [Google Scholar]
- Yang, B.; Xiao, Z. A Multi-Channel and Multi-Spatial Attention Convolutional Neural Network for Prostate Cancer ISUP Grading. Appl. Sci. 2021, 11, 4321. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Data Set | Fusion Operation | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| Veg200 | Concatenation | 89.154% | 98.045% |
| Summation | 87.137% | 96.724% | |
| Fru92 | Concatenation | 91.058% | 98.809% |
| Summation | 88.653% | 97.913% | |
| VegFru292 | Concatenation | 90.832% | 98.619% |
| Summation | 89.317% | 97.805% |
| Data Set | Number of Regions | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| Veg200 | 2 | 87.132% | 97.513% |
| 3 | 89.154% | 98.045% | |
| 4 | 88.019% | 97.861% | |
| Fru92 | 2 | 90.629% | 97.917% |
| 3 | 91.058% | 98.809% | |
| 4 | 90.681% | 98.051% | |
| VegFru292 | 2 | 86.795% | 97.513% |
| 3 | 90.832% | 98.619% | |
| 4 | 88.019% | 97.861% |
| Data Set | Method | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| Veg200 | ResNet50 | 88.195% | 98.187% |
| VGG16 | 78.50% | - | |
| CBP | 81.59% | - | |
| DCL | 85.98% | 97.53% | |
| API-Net | 86.953% | 97.210% | |
| WS-DAN | 84.17% | 96.71% | |
| AIF-Net | 89.154% | 98.045% | |
| Fru92 | ResNet50 | 89.323% | 98.710% |
| VGG16 | 79.80% | - | |
| DCL | 85.07% | 96.17% | |
| API-Net | 89.914% | 98.021% | |
| WS-DAN | 87.32% | 98.21% | |
| AIF-Net | 91.058% | 98.809% | |
| VegFru292 | ResNet50 | 88.002% | 97.992% |
| VGG16 | 77.12% | - | |
| CBP | 82.21% | - | |
| HybridNet | 83.51% | - | |
| DCL | 87.13% | 97.26% | |
| API-Net | 87.241% | 97.711% | |
| WS-DAN | 85.72% | 97.17% | |
| AIF-Net | 90.832% | 98.619% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xiao, Z.; Meng, L. Learning Attention-Aware Interactive Features for Fine-Grained Vegetable and Fruit Classification. Appl. Sci. 2021, 11, 6533. https://doi.org/10.3390/app11146533
Wang Y, Xiao Z, Meng L. Learning Attention-Aware Interactive Features for Fine-Grained Vegetable and Fruit Classification. Applied Sciences. 2021; 11(14):6533. https://doi.org/10.3390/app11146533
Chicago/Turabian StyleWang, Yimin, Zhifeng Xiao, and Lingguo Meng. 2021. "Learning Attention-Aware Interactive Features for Fine-Grained Vegetable and Fruit Classification" Applied Sciences 11, no. 14: 6533. https://doi.org/10.3390/app11146533
APA StyleWang, Y., Xiao, Z., & Meng, L. (2021). Learning Attention-Aware Interactive Features for Fine-Grained Vegetable and Fruit Classification. Applied Sciences, 11(14), 6533. https://doi.org/10.3390/app11146533