1. Introduction
Malware, short for Malicious Software, is a compiled binary file that interrupts computer systems or networks aiming to steal data, modify/delete or encrypt sensitive information, and hijack core computing functions. Malware includes several types such as worms, trojans, spyware, and ransomware [
1]. Recently, there has been a tremendous increase in malware development by an average of 588 cyber threats per minute according to McAfee report 2021 [
2]. Consequently, Malware classification and detection have become one of the most important research fields. Malware detection is mainly performed by implementing static-based analysis or dynamic-based analysis [
3,
4]. In the static-based analysis, the original source code of the malware is statically scanned without executing the code. Even though this approach is inexpensive, it is insufficient in the case of encrypted or obfuscated malware attacks. However, the dynamic-based approach analyzes the behavioral features of the malicious software by executing the code in isolated or virtual environments. Hence, this approach consumes time and resources.
Another alternative to malware classification is the visualization approach. Many recent works have been used the malware visualization analysis approach [
5,
6,
7] as an efficient solution for malicious software classification since it analyzes the malware executable file as a whole. Malware visualization is a method in which malicious software is converted into an image by extracting its binaries [
8]. Since the malicious code is visualized, each malicious family presents a special texture pattern of the generated images of the malware applications that belong to the same family. An additional advantage of the malware visualization analysis that it does not require static decompilation or dynamic running of malware software. After the malware visualization, the training classifier could be implemented by deploying the texture features of the malware image. Consequently, even if the attacker has employed obfuscation or modification techniques, the texture representing the malicious software will be exhibited in the malware image [
5].
One of the most prominent neural network models is Convolutional Neural Networks (CNNs) which are used in image classification. CNN provides a superior data representation, thus features engineering can be avoided. Initially, the input image is converted into an array of pixels. Subsequently, the image is processed by several convolutional layers to finally generate a predicted output [
9]. To train the CNN models, huge and well-illustrated datasets are used, such as ImageNet [
10]. However, to enhance the malware classification and detection, the gained knowledge out of CNNs can be transferred to a different learning task [
11]. The core advantage of transfer learning is that it enables training a task with a limited dataset by using a pre-trained model with a large-scale dataset.
This research proposes a vision-based malware multi-classification framework that aims to overcome the shortcomings of the existing malware detection mechanisms. The proposed framework recruits the advantages of CNN models trained on large-scale datasets by transferring their knowledge to fine-tuning phase to improve the detection accuracy without building the training models from scratch. Moreover, the proposed framework does not need to run expensive processes applied by conventional ML and DL techniques, including features extraction and data augmentation to balance the malware datasets under study.
Therefore, the main contributions of this research work can be summarized as follows:
Developing eight different fine-tuned CNN-based transfer learning (TL) models for vision-based malware multi-classification applications.
Using CNN models for vision-based malware classification, which do not require features engineering such as binary disassembly or reverse engineering to detect visual malware samples.
Employing fine-tuned CNN models to function properly on 9341 images of 25 different malware families of 8 malware types.
Achieving high classification accuracy with fewer epochs and iterations for the developed CNN models than recent related work.
Succeeding to develop CNN models that can efficiently perform malware detection on imbalanced datasets (e.g., Malimg dataset [
12]).
Applying extensive performance analysis in terms of 15 different evaluation metrics to assess the examined fine-tuned CNN models accurately.
Conducting in-depth comparative analysis among the employed fine-tuned models and the recent related ML and DL models in terms of the obtained classification accuracy and other detection metrics.
The rest of this paper is structured as follows.
Section 2 presents a comprehensive summary of the recent related malware-based detection approaches. The proposed visualized malware multi-classification framework is explained in
Section 3. The simulation results and comparisons are discussed in
Section 4. Concluding remarks and some future directions are presented in
Section 5.
2. Literature Survey
Many malware classification and identification research works have been investigated based on different analysis approaches such as static-based, dynamic-based, and machine learning-based [
13,
14,
15,
16]. This section provides a comprehensive survey of several malware classification methods. Static-based analysis deploys functional call-graph [
17], features of portable executable (PE) malware files [
18], function length frequencies [
19], and opcode sequences [
20]. Almomani et al. [
21,
22,
23] implemented a static analysis to extract several static features from Android malware binary files such as permissions and API calls. Subsequently, they performed machine learning techniques to detect malware applications [
24]. The authors of [
25] developed a static analysis with Tensorflow (SAT) malware detection system. The proposed system performs a static analysis by employing a signature-based method on both known and new/modified malware. However, static-based analysis is not sufficient in the case of code obfuscation and zero-day malware [
5].
In the dynamic-based analysis, the behavioral characteristics of malware are obtained, such as API calls [
26], network activities [
27], and log files [
28]. In [
27], Mohaisen et al. developed an automated malware and labeling scheme (AMAL). In the proposed system, several behavior-based features were extracted during the dynamic analysis, such as network activities, file systems, and registers. The authors of [
28] integrated memory forensics techniques with a dynamic analysis approach. Initially, malicious artifacts were extracted from the memory. Subsequently, the Cuckoo Sandbox was deployed to monitor the malware behavior during its execution. Finally, the malicious artifacts and the behavioral report were combined to create the features dataset for further classification. However, malicious software may alter its behavior during its execution in a virtual environment; thus, the dynamic-based analysis might fail to capture the actual behavior of the malicious software.
Recently, extensive research on malware classification has been made by deploying the vision-based approach [
6,
7,
8,
29,
30,
31]. Some authors developed CNN solutions from scratch in which they did not use any pre-trained models [
7,
9,
29,
30]. In [
7], the authors developed a visualized malware classification system based on Artificial Neural Network (ANN). The proposed classification system used the extracted features of the Malimg database to train ANN. Subsequently, the trained model is further employed in classifying different samples of the Malimg database. The accuracy of applying one hidden layer was 96%. However, implementing two hidden layers achieved an accuracy of 99.135%. Gibert et al. have also visualized malware as gray-scale images to develop a file agnostic deep learning scheme based on CNN [
29]. The proposed scheme extract patterns to classify malicious software allowing the malicious software to be classified in a real-time environment. Besides patterns, different features could be deployed in the malware visualization process. In [
30], they have included the local features in visualizing the malware application by using the FastText model. Consequently, each malware family has a unique generated local malware image since the proposed system mainly includes the local features of each malicious software.
Furthermore, the authors of [
32] proved that combining deep CNN with an entropy graph contributes to enhancing the malware pattern classification process. In [
33], the authors have investigated the classification on a different color scale in which they converted the malware APK files into colored images instead of gray-scale images. However, they have compared applying the classification between gray-scale and colored images and proved that applying the classification on colored images outperformed the gray-scale classification. Vasan et al. have also deployed colored images in which they have implemented IMCFN, an image-based malware classification system using Fine-tuned CNN [
31]. Initially, they have converted malware into colored images using a colored map algorithm. To overcome the imbalanced dataset issue, they applied data augmentation during the fine-tuning process. Furthermore, they have also compared applying the classification between gray-scale and colored images and achieved the same result of having better classification performance in the case of using colored images. Even though IMCFN accomplished an accuracy of 98.82% in the Malimg dataset, the proposed system bears an extra complexity due to the used augmentation techniques and colored map algorithm.
Some researchers might choose to combine several training models to improve the classification process [
8,
34,
35,
36,
37]. In [
8], the SFTA (scale feature texture analyzer) is combined with two models of deep CNN (DCNN), AlexNet and Inception-v3 techniques, to enhance the accuracy of malware detection. Another combination of CNN models was proposed by [
35] in which the authors have uses VGG16 and ResNet50 for features extraction. However, in the ensemble of CNN architectures, two classifiers have been deployed SoftMax and Multiclass SVMs. Following that, a PCA (principal component analysis) process was applied to decrease the dimensionality of the features, while a fusion process was used before the classification process. Moreover, the CNNs might be combined with other techniques such as Long Short-Term Memory (LSTM) [
36]. The proposed solution by [
36] implemented an ensemble classification scheme based on recurrent and convolutional neural networks by using the complied and the assembled malware files. They have classified the visualized image of the complied malware files using CNN while the LSTM was used to classify Assembly files of malicious software.
In other scenarios, the CNN might be applied to extract features while machine learning techniques are deployed in the malware classification process [
38,
39,
40]. In [
38], the visualized malware was classified by deploying a sequential multilayered Random Forest ensemble technique. The suggested solution is performed in two stages. Initially, the raw features were analyzed using different sizes of sliding windows. Subsequently, four different machine learning (ML) techniques were applied including, Random forests (RF), Xgboost, Extra trees classifier (ETC), and Logistic regression (LR). The authors of [
39] developed an image feature descriptor to extract the similarities among the malware images. Then, they have deployed the k-Nearest Neighbor (KNN) algorithm to perform the classification process. Another machine learning-based classification system was proposed by [
40] in which they deployed the local and global malicious patterns (LGMP) to extract the features of the visualized malware.
Table 1 presents a comprehensive comparison among the most recent related studies that have deployed the imbalanced Malimg dataset in their proposed systems. After observing the limitations of state-of-the-art malware classification approaches, different fine-tuned CNN-based TL architectures are introduced in this paper to significantly reduce the misclassification rate without increasing the complexity. Thus, different from the prior malware detection approaches, this work implemented eight CNN models for visualized malware multi-classification purposes. First, the PE (portable executable) malware samples are converted to gray-scale images to build the malware dataset in a proper format that suits the input type of the developed CNN models. An image processing stage is then introduced to the obtained malware images to resize them appropriately to meet the input size conditions of the used CNN models. After that, the fine-tuning process is performed for the pre-trained CNN-based TL models that were trained on ImageNet database. Consequently, avoiding the expected misclassification in testing the imbalanced Malimg dataset by transferring the obtained optimum weights of the pre-trained CNN-based TL models to the malware classification tasks. Subsequently, these developed fine-tuned CNN-based TL models are utilized to classify 25 malware families of the imbalanced Malimg dataset. The fine-tuning process of the CNN layers and hyperparameter values assists in identifying different malicious software families and enhancing the pre-trained models’ classification performance without employing data augmentation techniques.
3. Proposed Visualized Malware Multi-Classification Framework
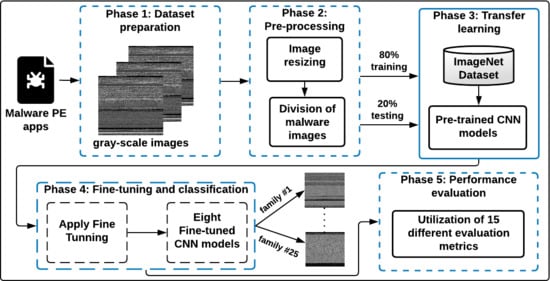
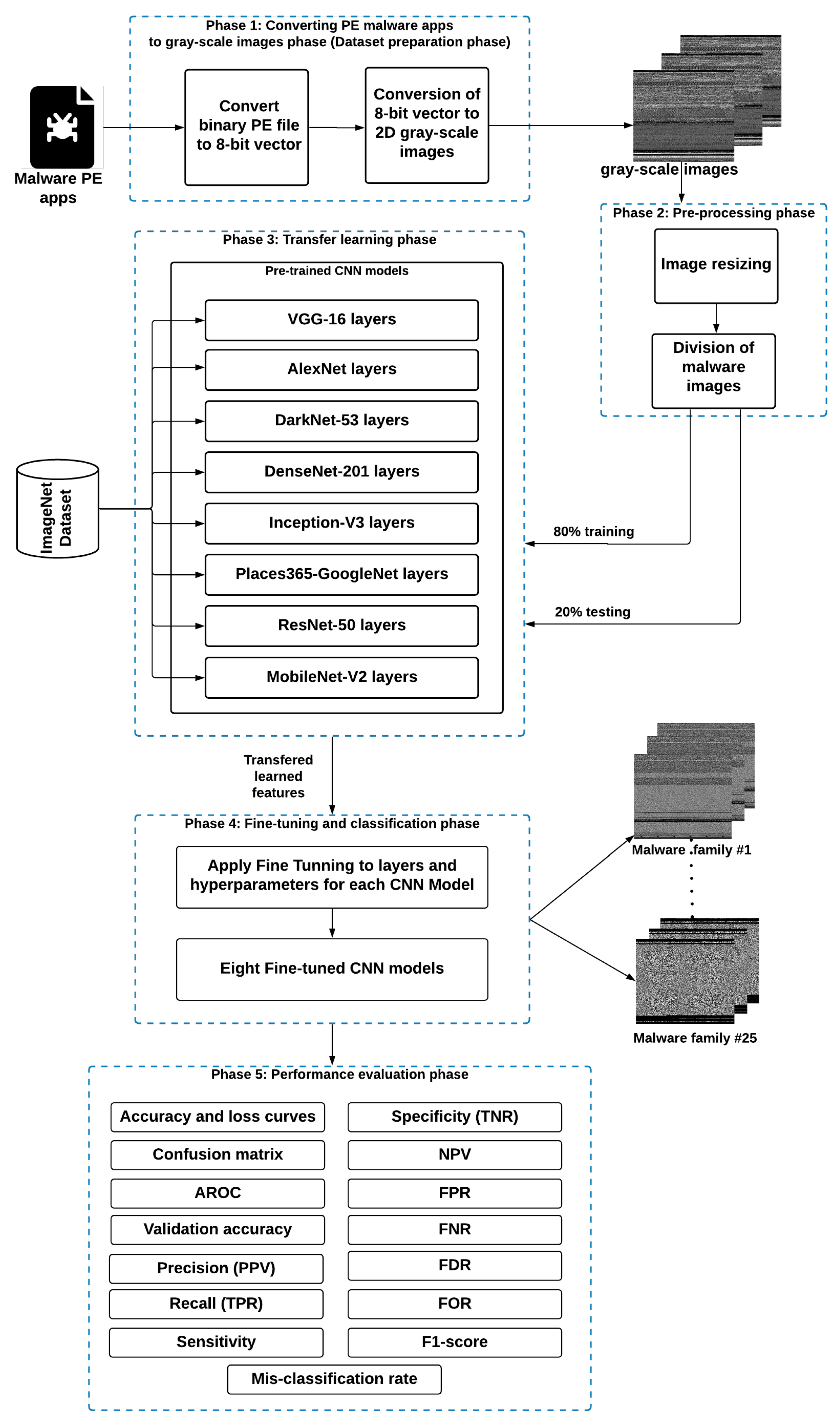
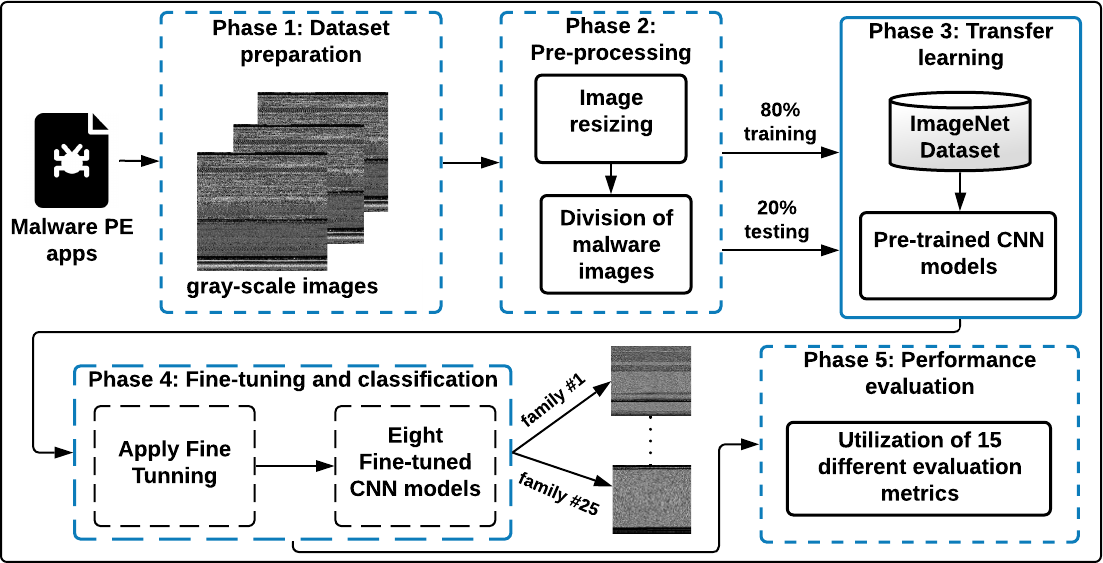
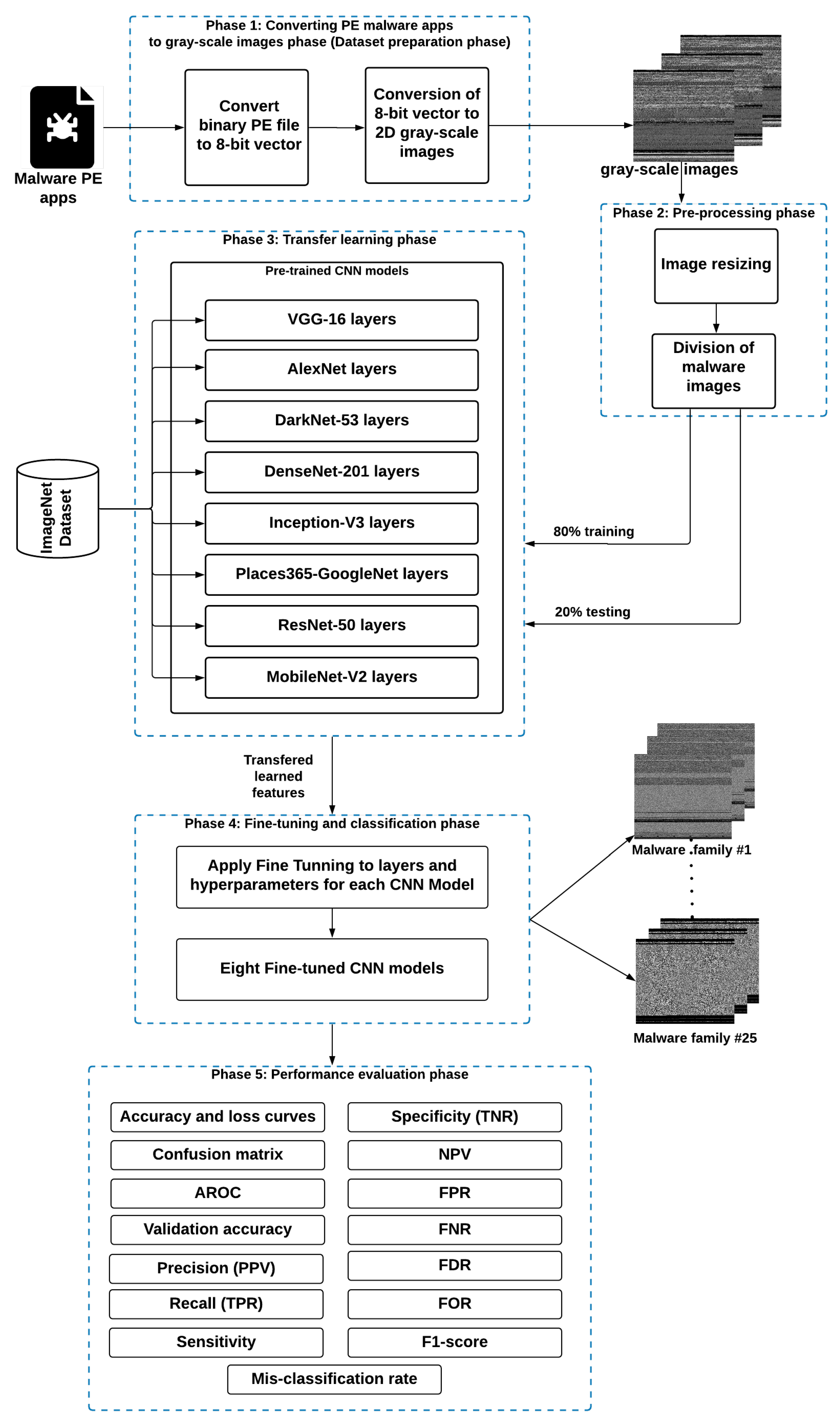
Effective detection of windows malware families is a mandatory aspect in Internet security applications. Rather than employing the conventional features extraction-based ML approaches that require high computational processing in texture analysis, in this paper, efficient visualized malware multi-classification models are introduced based on deep learning (DL) approaches. Therefore, to efficiently identify malware images with reduced computations and achieve maximum identification accuracy, different fine-tuned CNN-based TL models are developed and used, as shown in the proposed malware multi-classification framework in
Figure 1.
The used fine-tuned CNN models do not use reverse engineering for the malware multi-classification process. The basic procedure of the proposed malware multi-classification framework is shown in
Figure 1. It consists of five different phases: (1) Dataset preparation, (2) Pre-processing, (3) Transfer learning, (4) Fine-tuning and classification, and (5) Performance evaluation. The details of these phases are as follows:
3.1. Dataset Preparation Phase
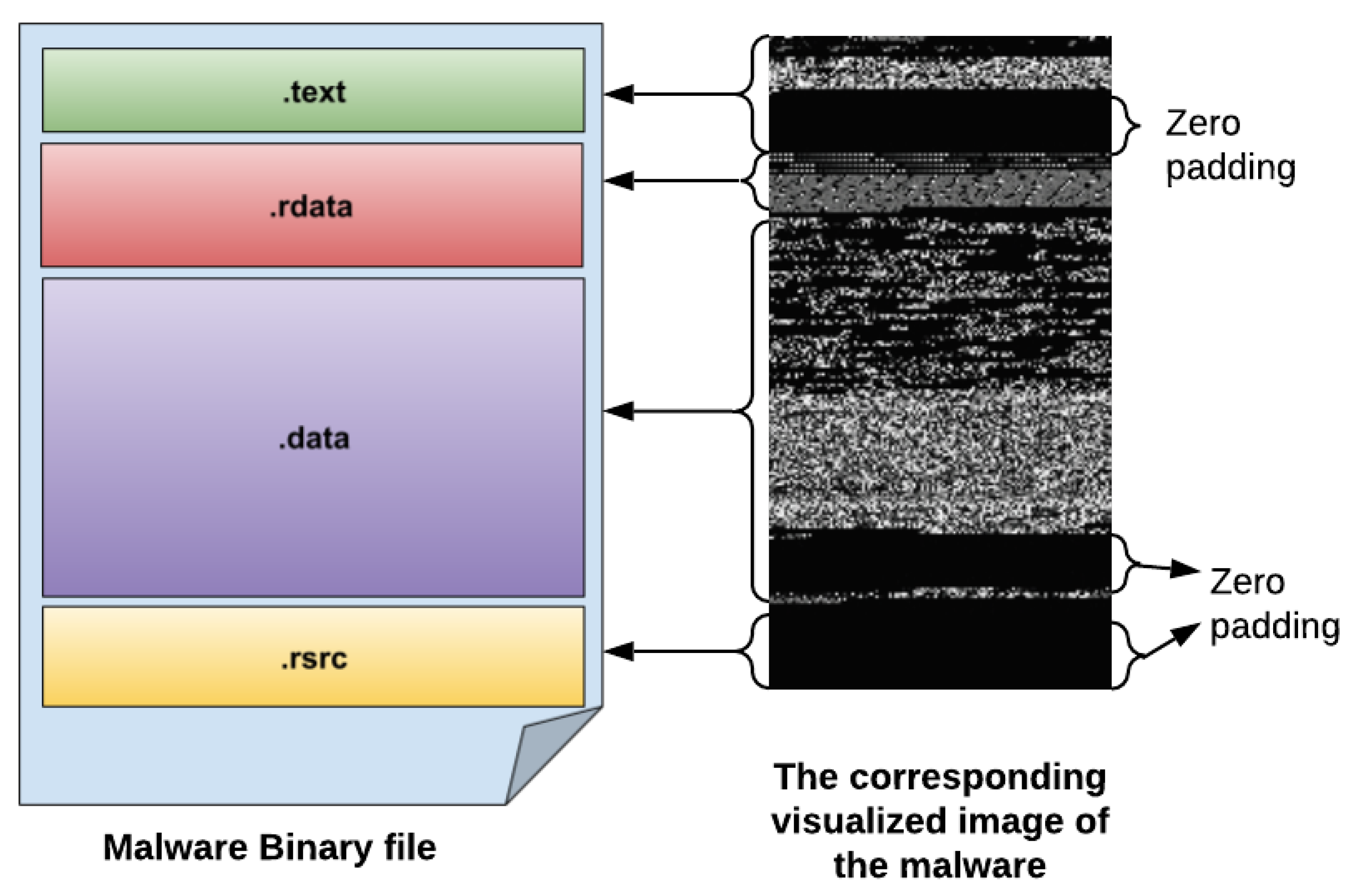
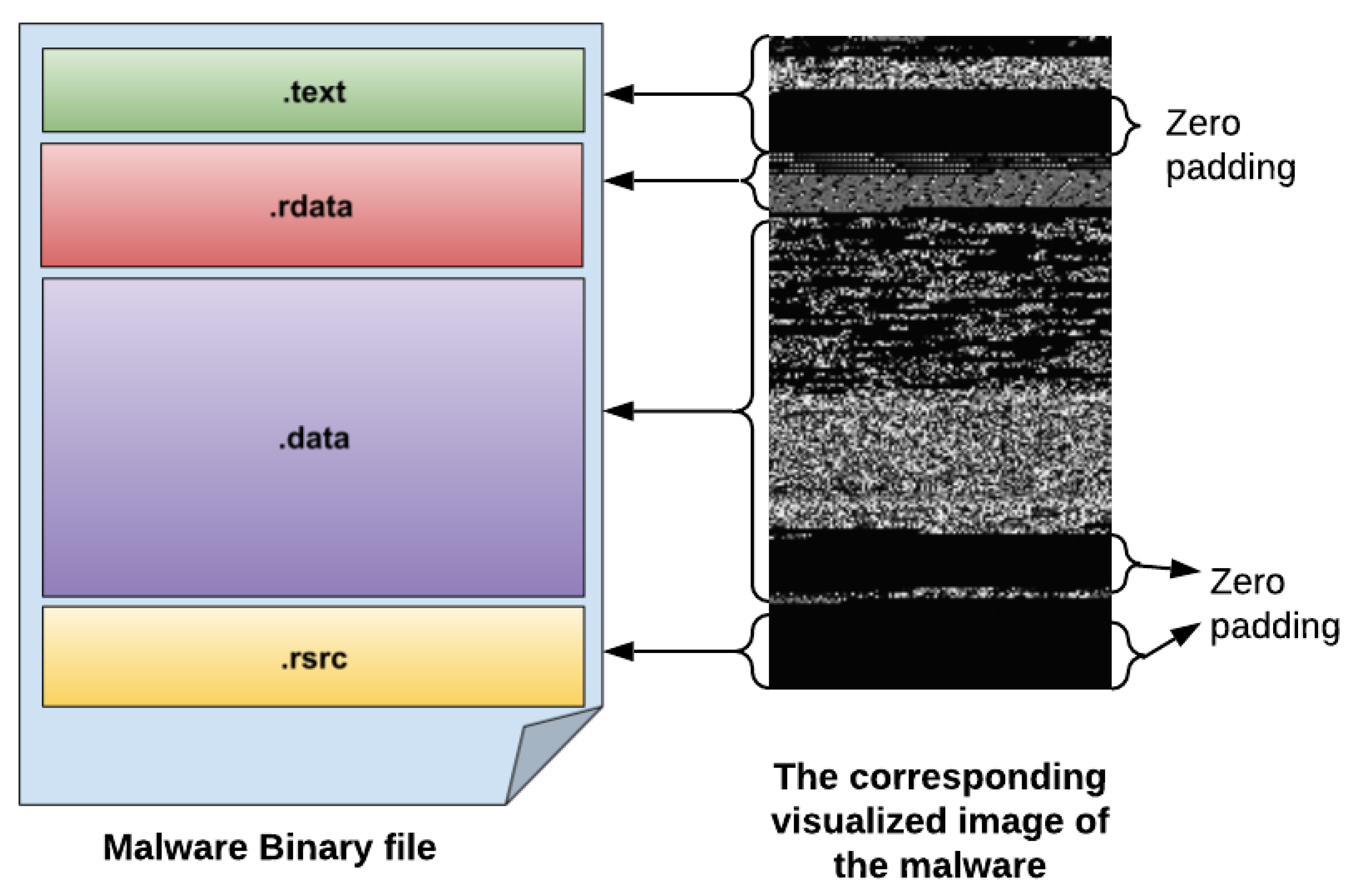
This phase is concerned with converting PE (portable executable) malware apps to gray-scale images. A PE malware binary is converted to a visual image to obtain and extract the main features and details of the malware apps. As shown in
Figure 1, the malware PE application is first converted to a 1D 8-bit binary vector (unsigned integers). Then, this obtained 8-bit vector is transformed into a visual 2D gray-scale image. The main advantage of converting PE malware app to visual malware image is that it does not necessitate any domain expertise or feature engineering knowledge.
Table 2 illustrates some samples of the visualized malware images after rearranging the 1D bit vectors of the malware binaries into 2D visual arrays. It can be observed from these malware images that the image width is variant for each malware family, which depends on the malware app size.
Table 3 presents different widths for the malware images due to different sizes of malware files. Additionally, we can conclude from
Table 2 that the obtained visual images of a variety of malware families exhibited differently in style, layout, and form. Therefore, each malware family has its own visual characteristics and similarities that are different from other malware families, where each family has various visualization features and distinct stripes. Such observations have motivated this research to adapt and tune the general CNN algorithms used for digital image classification into malware detection tasks.
3.2. Pre-Processing Phase
As discussed in the first phase, the malware binaries are converted to 2D malware images with different sizes that are not fixed among images of the tested 25 families. Thus, a pre-processing step for malware data are a mandatory stage to be introduced to reformate the input image size corresponding to the CNN algorithms’ settings. Therefore, the objective of this phase is to resize the malware images obtained in the first phase to an appropriate size to be compatible with the input size of the employed CNN model, where each fine-tuned CNN model from the eight examined models has its own standard size for the input image, as shown in
Table 4. The foremost advantage of the resizing process is reducing the input image sizes, which is very beneficial in accelerating the training process and decreasing the computational overhead of the employed CNN model. Moreover, the main texture features of the malware images are preserved during the re-dimensionality process.
Furthermore, in this phase, the malware images dataset is divided into two different ratios for training and testing purposes. In this work, several simulation experiments were conducted to choose the proper ratios regarding detection accuracy and execution performance. The experiments’ results revealed that allocating 80% of the malware samples for training and 20% for testing have achieved the superior and recommended malware detection accuracy compared to the other training and testing ratios for the examined CNN models. Both 20% and 80% of the samples were selected randomly by our proposed framework.
3.3. Transfer Learning (TL) Phase
TL refers to transferring the CNN parameters of a specified detection task with a specific image database to a new classification challenge with a different detection task for another image database. Almost all deep CNN models trained and learned on natural digital images have a common phenomenon: they understand and discover the general features of the input images through their first CNN layers, where these features are not specific to a particular task or dataset. However, they can be applied to many classification tasks and different image datasets. Therefore, the benefit of TL can be a formidable solution when the target database is considerably smaller than the original database; this is to avoid the overfitting occurrence, especially in the case of imbalanced datasets.
Consequently, the malware classification task can be considered to be an image classification task, especially when the malware binary samples are converted into visual malware images. Thus, the standard CNN models used for natural image classification can be exploited to classify the visualized malware images. In this regard, the TL-based CNN models trained on the benchmark ImageNet database [
41] can be efficiently adapted to detect malware families. This database is updated through an annual competition called the “ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)” which is created for visual object detection challenges.
Many CNN models were already trained on natural images such as VGG16 [
42], AlexNet [
43], DarkNet-53 [
44], DenseNet-201 [
45], Inception-V3 [
46], Places365-GoogleNet [
47], ResNet-50 [
48], and MobileNet-V2 [
49]. In this paper, to obtain and extract the main features of the malware images, we used these eight pre-trained CNN models on the ImageNet database to identify general objects. Therefore, these models can be retrained and tested quickly using malware images to extract the main features from the input malware images; this is the great benefit of the TL concept. Thus, TL-based CNN architectures have started recently to be employed for intrusion detection and malware classification research. This is because TL can offer effective and promising detection solutions through knowledge transfer from standard image detection tasks to malware image detection tasks.
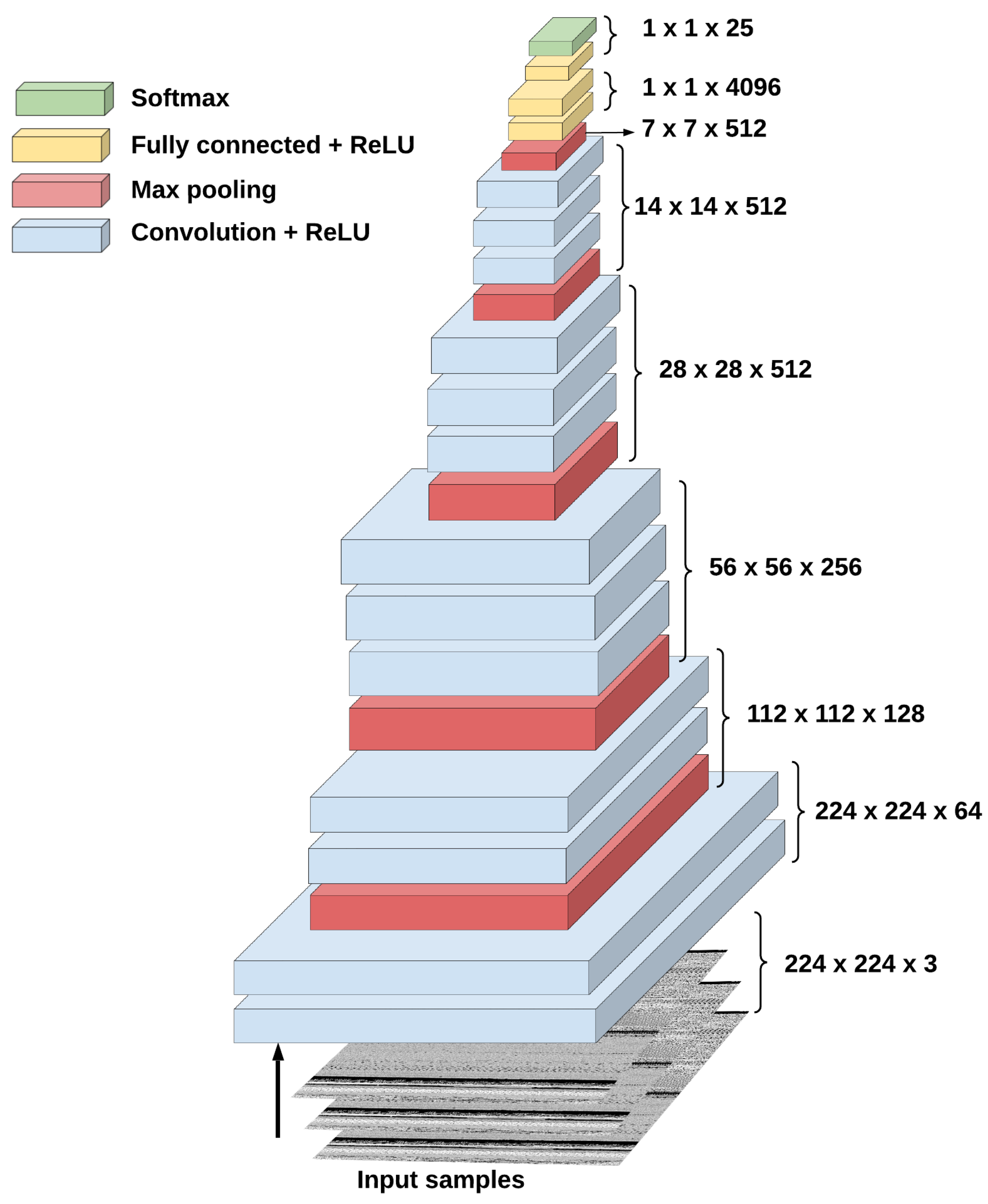
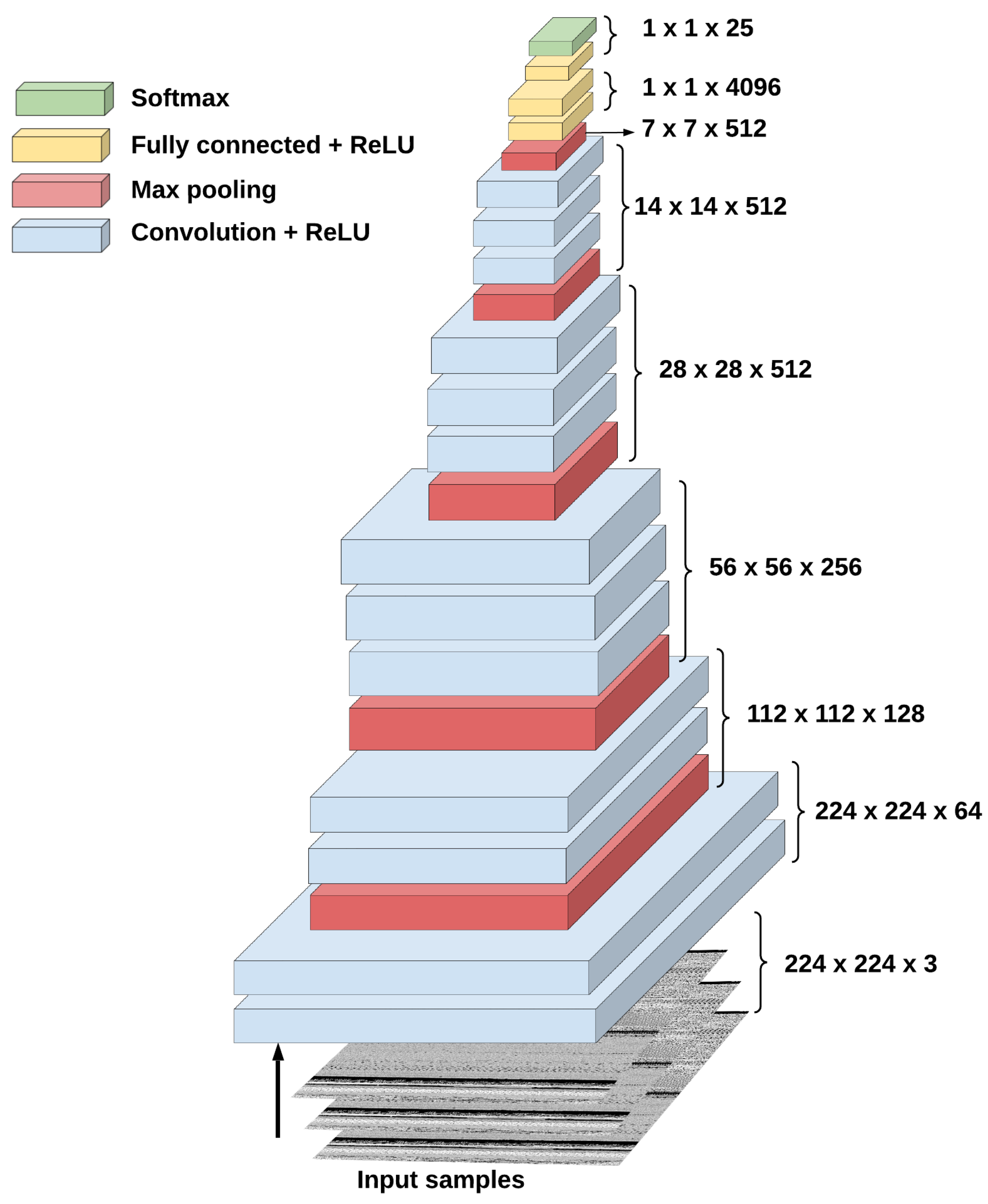
Among all TL-based CNN models examined in this paper, the fine-tuned VGG16 model accomplishes the best superior and promising results for visual malware multi-classification compared to other models. Therefore, we provide deep insights into its architecture, behavior, parameters, and simulation results. Thus, the proposed multi-classification framework has implemented the fine-tuned version of the pre-trained VGG16 CNN architecture model shown in
Figure 2; to classify visualized malware images. The TL-based VGG16 model is already trained on more than 14 million digital images of the ImageNet dataset. It is primarily introduced to resolve various identification challenges such as plant image, plankton, lung nodules classifications [
42]. As observed in
Figure 2, the DL VGG16 architecture comprises different connected CNN layers (16 layers) that are (1) five max-pooling (MP) layers, (2) five groups of convolutional (Conv.) layers, (3) three fully connected (FC) layers, and (4) a SoftMax output layer. Its input image size is
, and its output layer includes the SoftMax classifier used for detection purposes.
First, the malware images are resized to 224 × 224 × 3 to meet the input size of the first layer of the VGG16 model. Then, these images are passed to a group of convolutional layers with filter sizes of 3 × 3 and 1 × 1. In the convolution layers, the convolution stride is fixed to 1 padding for each 1 pixel. This is to ensure similar spatial dimensions among the included activation maps of the whole model layers. The rectified linear unit (ReLU) is used in all hidden layers to speed up the training process. The non-padding kernel filters of size 2 × 2 with two strides are applied in the max-pooling layers. For the output SoftMax layer, a classifier is used to classify the 25 malware families of the tested Malimg dataset. In the proposed model, all upper layers are frozen, and the last three connected layers are equipped to detect the malware family.
The prominent benefit of the VGG16 model is that it enhances the performance of CNNs without the necessity of doing deeper training with a high number of convolutional layers. This means that each convolutional layer will have various kernels that can learn and discover distinct image features with fewer iterations. Thus, it is computationally effective in malware image detection due to its low number of layers and iterations. More details about the architectures and explanations of the other seven pre-trained CNN models (AlexNet, DarkNet-53, DenseNet-201, Inception-V3, Places365-GoogleNet, ResNet-50, MobileNet-V2), could be explored in [
43,
44,
45,
46,
47,
48,
49].
3.4. Fine-Tuning and Classification Phase
In general, TL can be performed in three different ways [
50]: (1) shallow tuning: the last layer in the model is assigned to a new task, and the constraints of the other model’s layers are frozen, (2) deep tuning: the whole end-to-end parameters of the pre-trained CNN architecture are retrained, and (3) fine-tuning: the CNN layers are gradually trained by fine-tuning the learning hyperparameters till a remarkable performance enhancement is accomplished. This paper applied fine-tuning, which is a compromised approach between the other two tuning types. Fine-tuning takes advantage of efficient classification tasks in the case of imbalanced datasets. Additionally, it causes lower complexity than the deep tuning and better classification accuracy than the shallow tuning.
The employed eight CNN models previously trained on the ImageNet dataset that contains 1000 different classes are adapted to our malware detection challenge. This adaptation is implemented through fine-tuning their layers’ parameters and weights. In these models, the output layer that contains 1000 classes is modified and fine-tuned to comprise 25 classes (25 malware families). Additionally, as will be discussed, the original weights of the primary pre-trained CNN models of the ImageNet dataset were initially used, and after that, they were optimized and fine-tuned based on the back-propagation technique [
51].
The fine-tuning process of the layers’ weights is an iterative optimization procedure that is performed and repeated until determining the best value of the filter weights (
w) that achieve a minimum error rate. The used cost function is expressed in Equation (
1)
where
m refers to the malware images contained in the training dataset
K,
p(
,
w) is the CNN prediction function that predicts the class
of
by assuming the value of
w,
is the proper class of the
malware image,
is the
malware image of
K, and
f(
,
) is the logistic error function that predicts
rather than
.
During the fine-tuning process, the performance efficiency of three different optimizers [
52]: (1) RMSprop (Root Mean Square Propagation), (2) SGDM (Stochastic Gradient Descent with Momentum), and (3) ADAM (Adaptive Moment Estimation Optimizer) were examined to select the best optimizer for estimating the optimal filter weights of the CNN layers. As a result, the ADAM optimizer was used for finding the optimal
w due to its superior performance compared to other optimizers. ADAM optimizer combines the main advantages and benefits of the other two SGDM and RMSprop optimizers, where it establishes adaptive learning rates for each parameter in the training process. Hence, the significant improvement of the ADAM optimizer is that it retains an exponentially decaying average of the past squared gradient descent to reach a minimum value faster. Further details, mathematical expressions, and descriptions of the ADAM optimizer can be found in [
53].
In the training process, a massive capacity of hardware memory is required to store the filter weights
w of the CNN layers, so a mini-batch size is set to 64. The learning rate is regularly altered until the optimal value is reached; where high learning rates cause overfitting, while slow learning rates limit the error variants among epochs. Therefore, the initial learning rate was set to 0.00001; to efficiently regulate the update of the weight sizes. The CNN layers’ weights were updated in each iteration, and the mini-batches were iterated for every epoch. The max-epoch was set to 20, where this value was selected through observing validation errors throughout fine-tuning process using various learning rates. Furthermore, the L2-regularization (ridge regression) technique [
54] with weight decay (L2-regularizer) = 0.01; was adopted to enhance and optimize the performance of the CNN models and avoid overfitting problem while analyzing small training samples. Therefore, it achieves robust and faster classification of malware images. For all examined models, the FC and SoftMax classifiers were used to detect the 25 malware images.
3.5. Performance Evaluation Phase
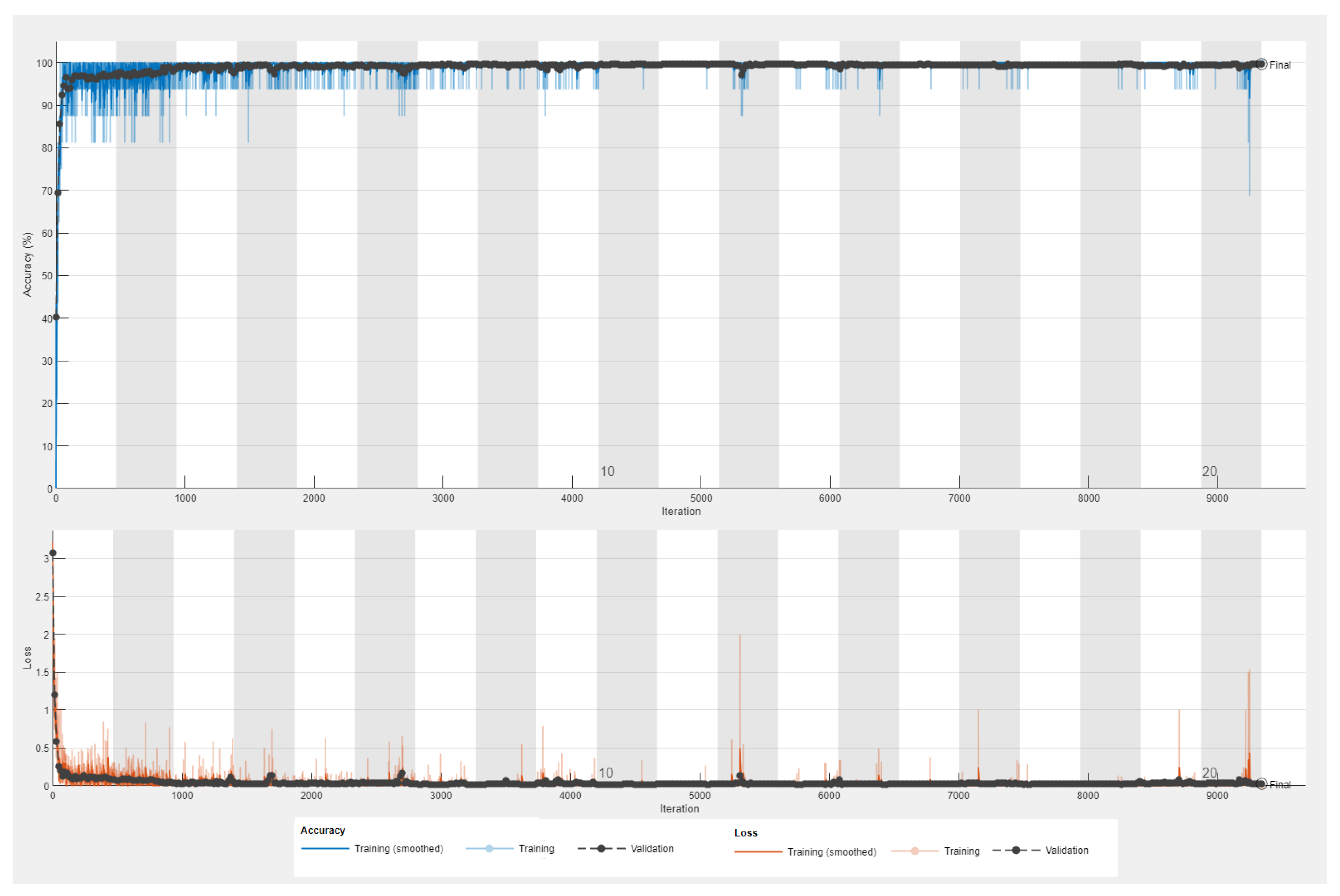
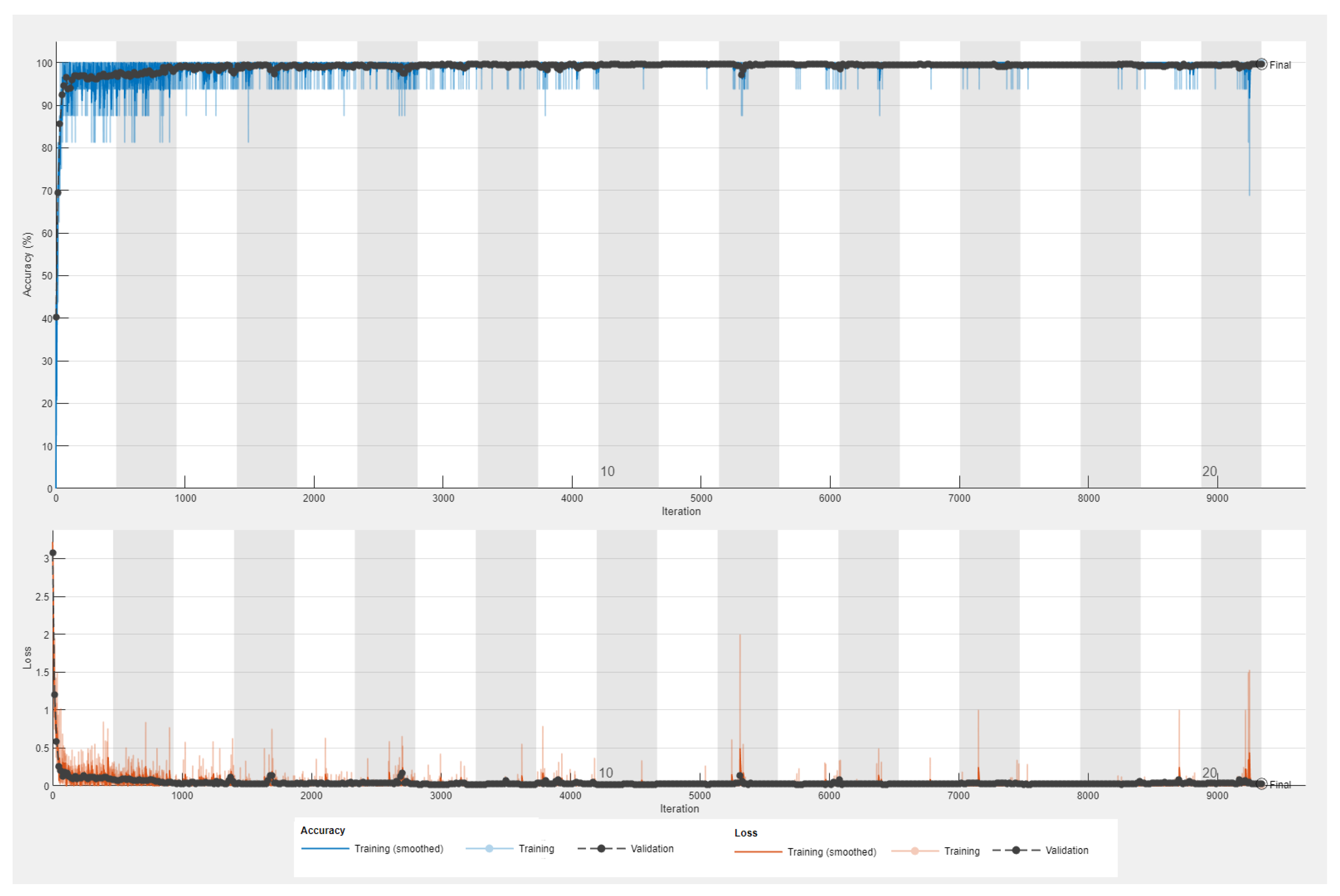
In this phase, extensive performance analysis in terms of 15 different evaluation metrics is presented to assess the examined models. Thus, the performance of the eight fine-tuned CNN classifiers was evaluated through detection assessment metrics, including accuracy and loss curves, specificity (TNR) (true negative rate), confusion matrix, NPV (negative predictive value), AROC (Area under the receiver operating characteristic curve), FPR (false positive rate), validation accuracy, FNR (false negative rate), precision (PPV) (positive predictive value), FDR (false discovery rate), recall (TPR) (true positive rate), FOR (false omission rate), sensitivity, F1-Score, and misclassification rate. These classification performance metrics have been comprehensively used in the research community to offer exhaustive evaluations of classification approaches [
55,
56].
The mathematical expressions of these evaluation metrics are formulated as follows:
where
TP (true positive) implies that both actual and predicted malware types are positive,
TN (true negative) means that both actual and predicted malware types are negative,
FP (false positive) implies that the actual malware type is negative, while the predicted malware type is positive, and
FN (false negative) means that the actual malware type is positive, while the predicted malware type is negative.
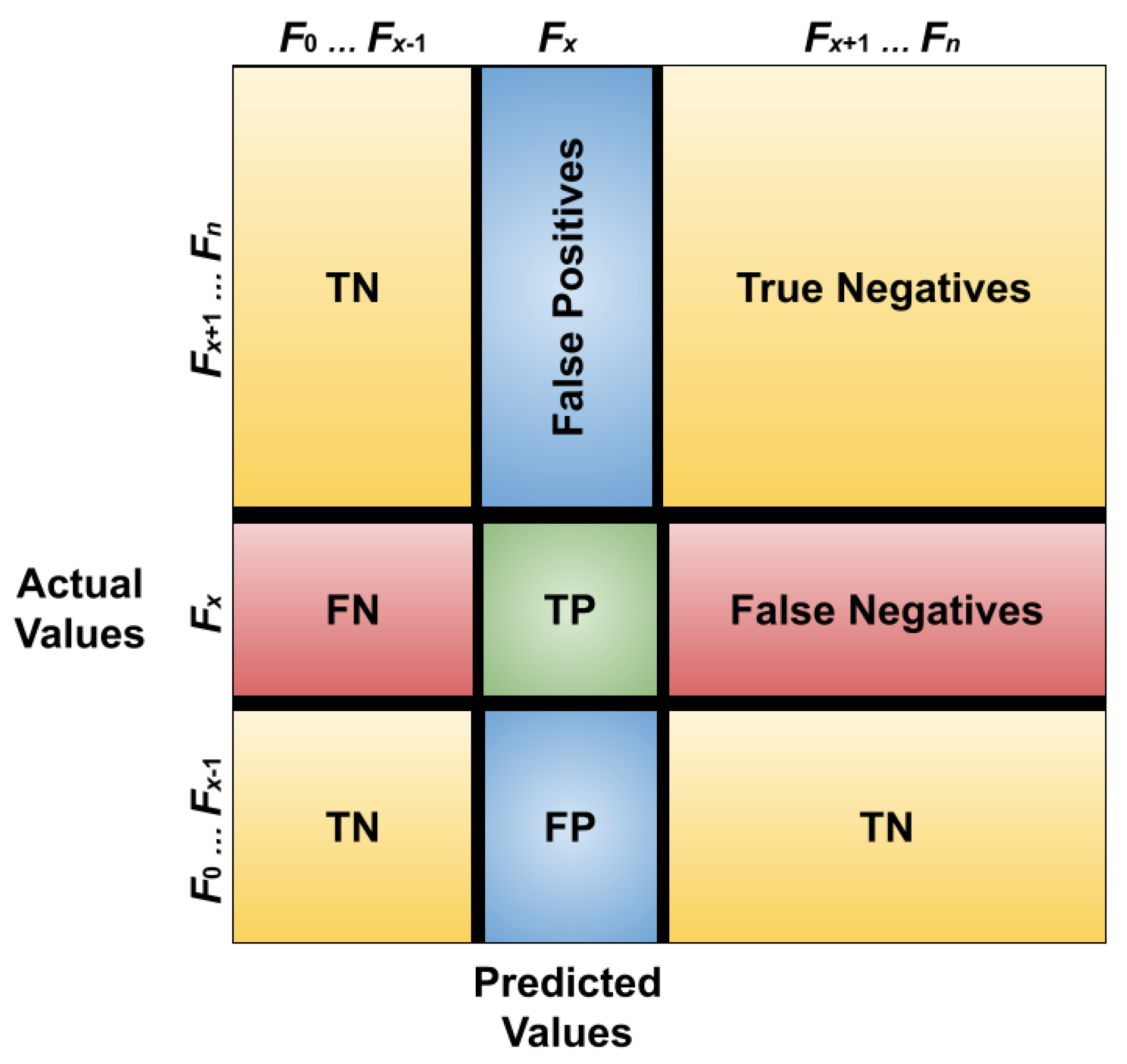
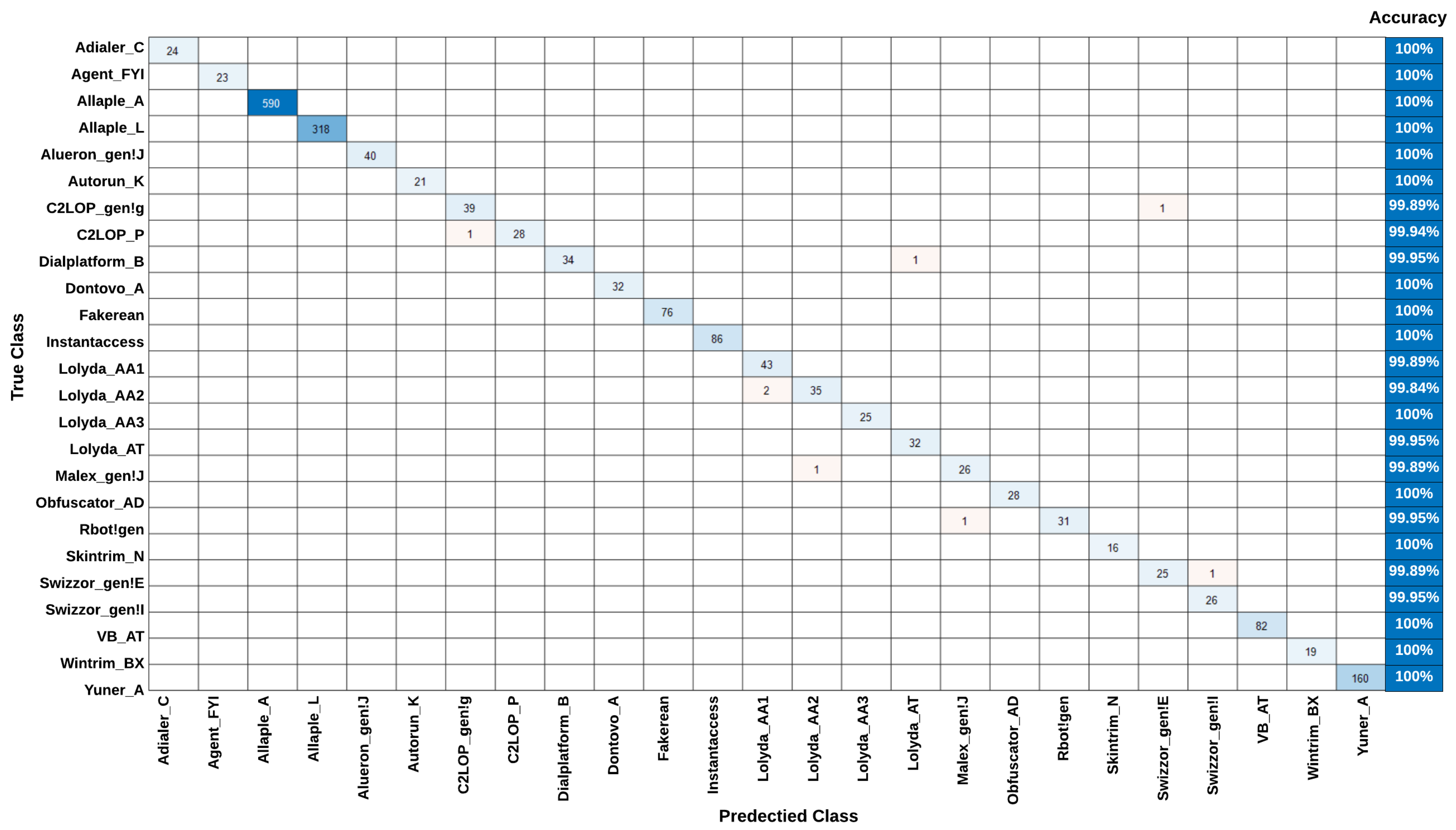
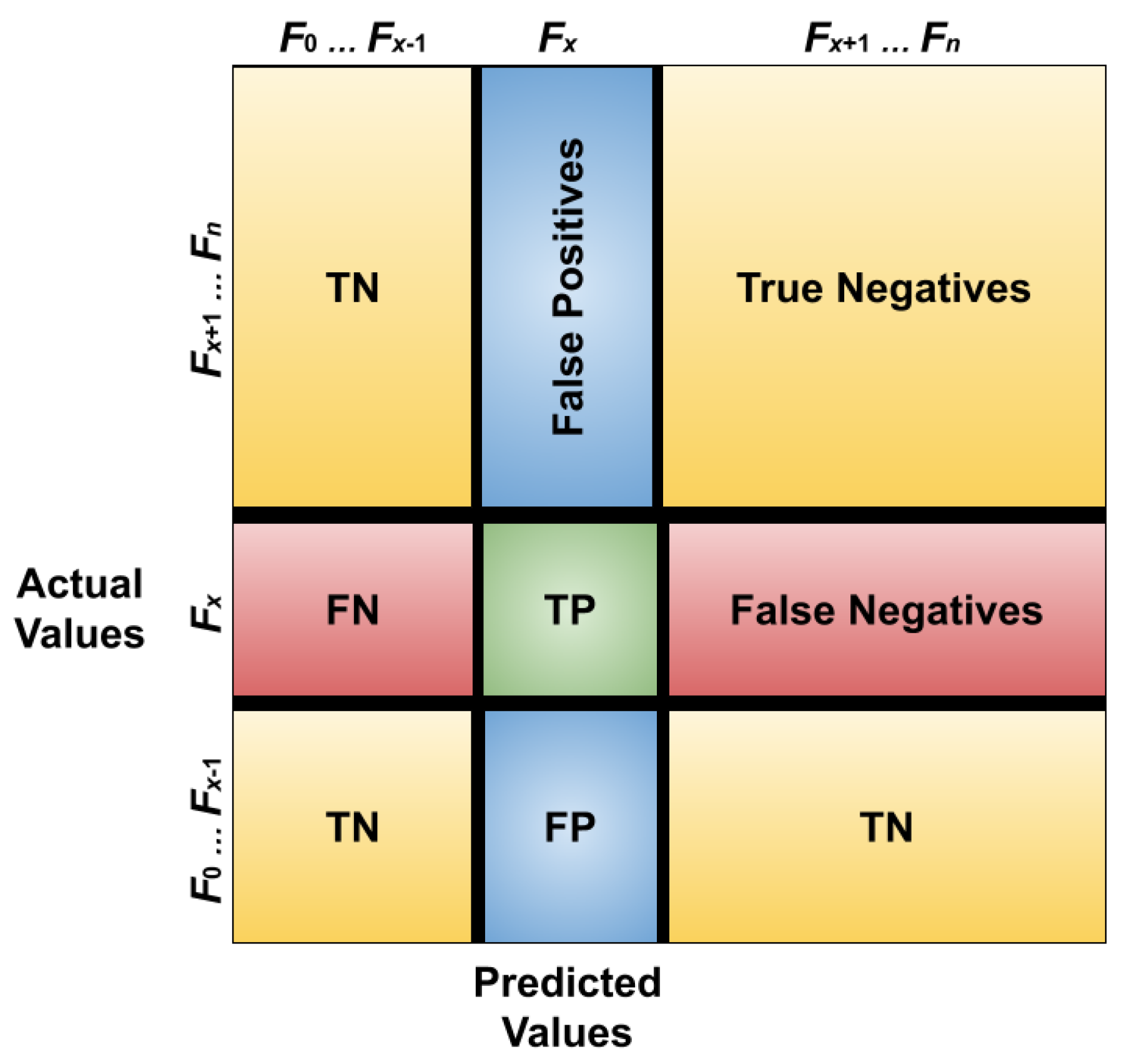
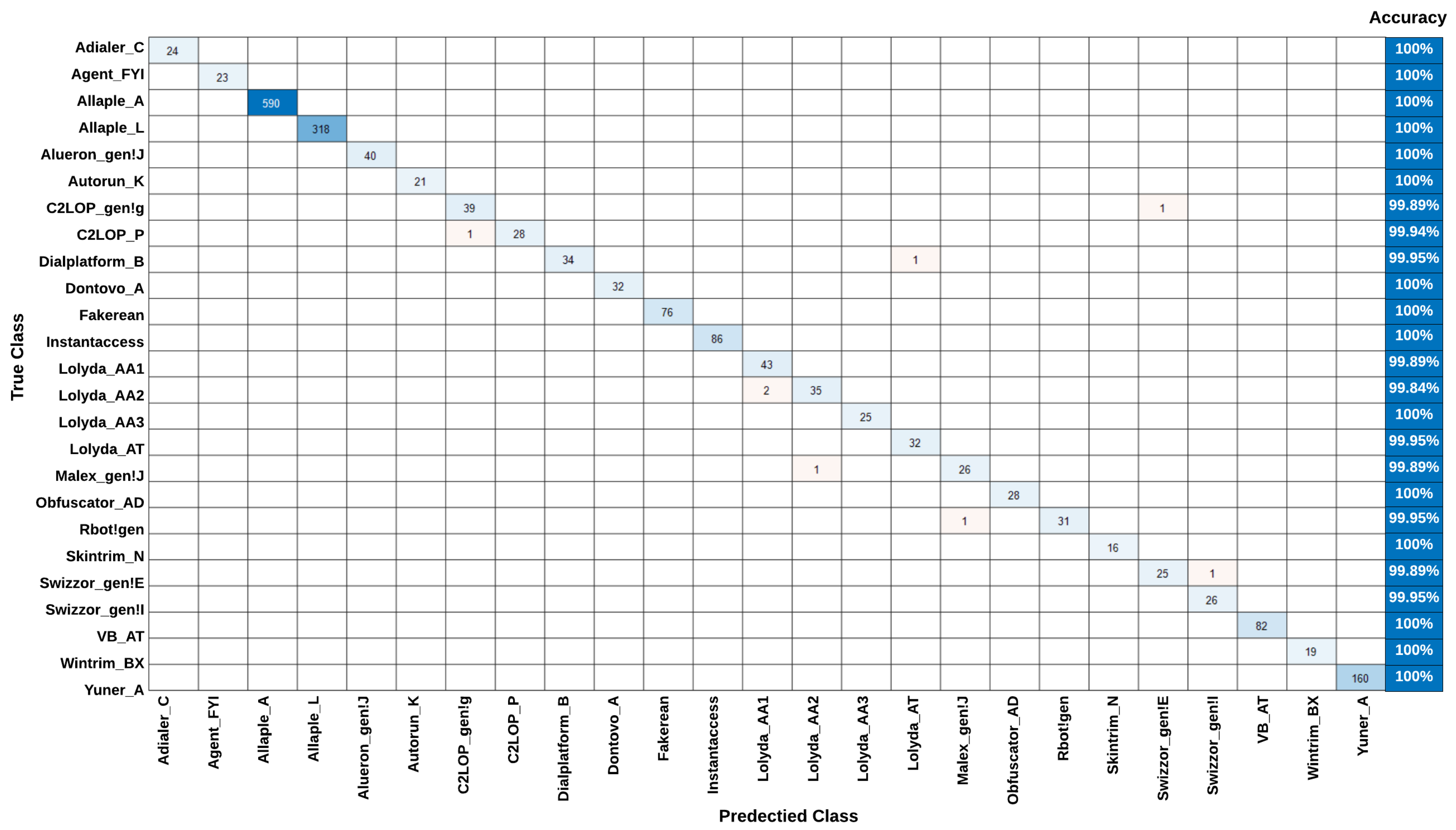
The
TP,
TN,
FP, and
FN values can be estimated as shown in
Figure 3, which is the confusion matrix of multi-classification tasks, which is different from the traditional confusion matrix of binary classification tasks. In this paper, we have a confusion matrix of classification with
N malware families (classes). For example, considering a specific malware family
where both the actual and predicted values are given, the four different classification results that can be obtained are: true positive (green), true negative (yellow), false positive (blue), and false negative (red).
More details, debates, and explanations about these evaluation metrics can be explored in [
57].
5. Conclusions and Future Work
There is an ongoing competition between anti-malware software and cyber-attackers’ methods. Malware is one of the most widespread cyber-attacks on the Internet. Consequently, it is essential to continue building innovative, intelligent security tools to mitigate these security attacks. Thus, efficient artificial intelligence (AI) tools are designed and used to detect malicious software. Unfortunately, AI-based anti-malware solutions based on ML algorithms introduce considerable development costs by generating an extensive set of handcrafted features identification and extraction, which requires the time and expertise of data scientists and malware analysts.
On the other hand, AI-based anti-malware solutions based on DL algorithms and CNN architectures have exhibited outstanding performance in identifying malware quickly and efficiently. Therefore, this paper introduced a DL-based visualized malware multi-classification framework to classify different unbalanced families of malware images. This framework was built based on malware visualization, fine-tuning, and CNN-based transfer learning phases that were well-developed to accurately detect different categories of malware families.
The proposed framework comprises eight fine-tuned CNN models, VGG16, AlexNet, DarkNet-53, DenseNet-201, Inception-V3, Places365-GoogleNet, ResNet-50, and MobileNet-V2, that were already pre-trained on the ImageNet database. The main contribution of the proposed framework is the cost-effectiveness in handling the imbalanced malware families while achieving high detection performance and without the need for data augmentation processes or complex features engineering. Extensive simulation experiments based on various evaluation metrics were conducted on the benchmark imbalanced Malimg dataset, which proved the outstanding classification capability and proficiency of the proposed framework.
Furthermore, a comprehensive comparative analysis among the proposed work and recent well-known ML and DL-based malware classification algorithms was presented and discussed. The comparison results demonstrated that the proposed framework achieved superior outcomes for all examined classification metrics.
For future work, different balanced and imbalanced malware datasets can be tested and explored. Additionally, building and testing a new malware dataset with the recent well-known malicious software is one of our aims to be considered. Moreover, we intend to investigate and examine the detection of cyber-attacks and malicious software in IoT cybersecurity applications.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











