1. Introduction
Many modern devices are equipped with voice control. Still, high-quality speech recognition requires many computational resources, which means that a voice-controlled device needs a network connection to remote servers to perform recognition. On the other hand, it is not practical to stream all the audio to the remote servers, both due to privacy and network usage reasons.
That is why some voice-controlled devices (e.g., Android-powered mobile phones) use voice activation before actual speech recognition. A voice activation system is a system that detects a pre-defined keyword or key phrase (e.g., “OK, Google”) in the audio stream. The problem of creating a high-quality voice activation system (or a keyword spotting system) with low resource consumption is heavily investigated by both research and industry [
1]. Low resource consumption is dictated by the use of embedded devices. For example, Google researchers presented their work about a server-side automatic speech recognition model that uses 58 million trainable parameters [
2], and a keyword spotter model that uses 300–350 thousand parameters [
3]. The problem of general speech recognition is more complex than the problem of finding a pre-defined keyword, but still the voice activation system must be fast, robust to noise and speech perturbations and accurate with a very limited amount of computational resources. This makes the problem of building high-quality voice activation quite challenging.
Voice-activation systems find their applications in various areas. For example, it can be used to detect sensitive terms in telephone tapping and audio monitoring device recordings for easier crime analysis [
4]. Another example is speeding up the command transmission for the aerospace field [
5]. Voice activation is widely used for triggering voice control in personal voice assistants [
6].
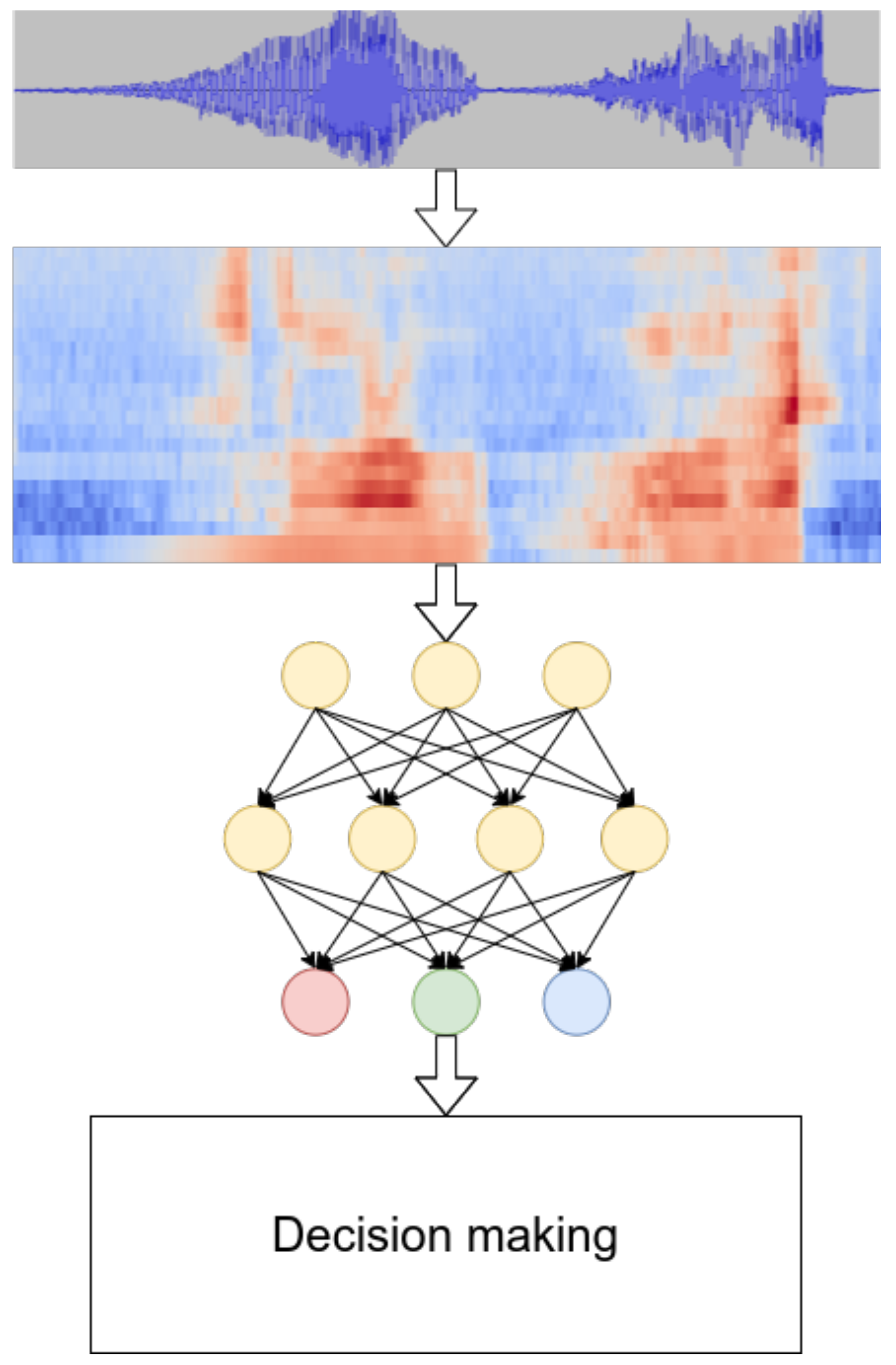
The majority of modern voice activation systems consist of the following parts (see
Figure 1 for illustration):
In the first part, the acoustic features are extracted from the source audio. Typically, it is done by segmenting the audio in short, possibly overlapping, frames, then computing the features in each frame. Many research studies have used log-mel filterbanks [
7,
8,
9,
10,
11].
The acoustic model is used to compute the probability of some acoustic event, given the observed audio. There are several popular choices for acoustic events: phonemes [
6,
12,
13] and words [
14,
15] are widely used. Usually, this module is the most resource demanding in the voice activation system.
Finally, the decision-making module is used to choose between several options: whether there is a keyword in the processed audio segment and if so, which one it is. This module can be quite complicated, especially in the case of phoneme-based spotters [
16]. In the case of using the whole keywords as acoustic events, the decision-making module is usually just comparing the resulting probabilities with a threshold.
Historically, voice activation systems were based on hidden Markov models [
17] or pattern matching approaches, such as dynamic time wrapping [
18]. However, since 1990, top-performing voice activation systems have been using (almost exclusively) neural networks as an acoustic model [
16,
19,
20,
21,
22].
Neural networks are powerful approximators and widely used in many areas. One of the drawbacks of using neural networks is that in many cases, a large labeled data set is needed to train such a model. For example, the authors of [
16] use hundreds of thousands of samples per keyword and the authors or [
23] use millions.
However, in some cases, it is not practical or even hardly possible to collect a large data set. In the case of designing a voice activation system for custom, user-defined keywords, it might hurt the user experience if it is necessary to repeat the custom keyword many times before real usage. Another example is quickly adapting the system to a new sensitive keyword in the aforementioned crime analysis application. Creating a voice activation system for low-resource languages, such as Lithuanian or Latvian, could be another example when the effective use of a small data set is needed, because it is difficult to find enough native speakers for creating a large audio database.
In this work, we investigate several known and new ways to improve the quality of a voice activation system on a low-resource labeled data set, comparing to the standard supervised way of acoustic model training. We use a small Lithuanian data set [
24] in order to compare the investigated methods. In all our experiments, we use the same neural network architecture but introduce some changes to audio features (
Section 3.4.1), use different kinds of pre-training (
Section 3.4.2 and
Section 3.4.3) or modify the training procedure (
Section 3.4.4 and
Section 3.4.5).
2. Related Works
This work concerns the problem of training a highly accurate voice activation system in a low-resource data set setup. This problem is tackled in several related works, most often connected to work with low-resourced languages.
One of the most productive ideas is to use a bigger out-of-domain data set in one way or another. For instance, the authors of [
25] use an English corpus to improve the quality of keyword spotter for the under-resourced Luganda corpus. The authors use a neural network trained as an autoencoder in two scenarios:
The neural network accepts audio features as input and is trained to output the same audio features.
The neural network accepts audio features as input and is trained to output the audio features of another audio file, but with same keyword as that in the input file.
In both scenarios, the intermediate layers of neural network have fewer neurons than the number of audio features. This helps to build bottleneck features (the activation of neurons of intermediate levels), which hopefully contain useful information about the audio signal and less noise than the original audio features. In the second scenario, the additional property is achieved: the information about non-keyword traits (such as the gender of the speaker, the speed of pronunciation, and so on) is not necessary for the optimal model (because the model predicts the audio features of another pronunciation of the same keyword). The research studies show, experimentally, that the resulting features are better than popular mel-frequency cepstral coefficients. The neural networks are trained on relatively small data sets (still at least 10 times bigger than the setup in this work). The extracted features are used for the voice activation system, which is trained on the data sets with a size comparable to the size of the data set used in this work. The use of multilingual data is related to the methods of this research, but our setup is a bit simpler (we train the whole model on multiple data sets, not only the feature extractor, which means that the training procedure is the same for both pre-training and training, and only the data sets are different). Additionally, for some of our proposed methods, there is no need for a relatively big annotated data set in the target domain.
The authors of [
26] present another example of the use of multilingual data for extracting the bottleneck features. The researchers train tandem acoustic modeling for phone recognition of several languages and use bottleneck features of this model as acoustic features for speech recognition as well as keyword spotting for a low-resource target language. This idea is extended in [
27] for the pre-training of hybrid speech recognition systems. The authors of [
28] propose to create phone mapping between languages (namely, English and Spanish in their experiments) in order to transfer a model pre-trained on a big data set for use on a smaller data set in another language. Comparing to these methods, the methods that are investigated in our work do not require phone transcription for a corpus used for pre-training and do not require the existence of phone mapping between languages.
An entirely different way to improve the quality of a keyword spotter in a low-resource setup is to generate synthetic data and use it in training. The authors of [
29] use a model pre-trained on 200 million 2-second audio clips in order to extract bottleneck features. This extractor is used to train a result keyword spotter on a small data set augmented with samples generated with speech synthesis. The authors show that synthetic data are enough to build a high-quality keyword spotter, if the pre-trained feature extractor is good enough. Unfortunately good speech synthesis might not be available for some languages.
Another method is to pre-train the model in an unsupervised manner. In such a way, the pre-training data set can be unlabeled, which hopefully makes it easier to obtain. A very successful way of unsupervised pre-training for automatic speech recognition is proposed in [
30]. The authors use a large unlabeled audio corpus to train a model that predicts audio features from the audio features of neighboring frames (similar to a language modeling task). The features extracted from this “language model” are experimentally very useful for speech recognition, even for very small data sets (1 h of labeled speech, compared to hundreds of hours of a typical speech recognition data set). Several researchers propose to use a similar method for voice activation problem with limited data sets [
31,
32]. We use the results of [
31] as one of the baselines for our methods. Some disadvantage of this method might be a possibly heavy feature extractor for use in a low-resource consumption setup.
Many methods have been proposed to apply deep learning in a low-resource data set setup for other problems, specifically for speech recognition and image classification. In our work, we try to adapt some of these methods for the voice activation problem.
Unsupervised pre-training [
33] is an example of a general framework, which can be applied when the in-domain labeled data set is small, but there is a possibility to get a bigger unlabeled data set. In an unsupervised pre-training scenario, the model is trained on a large corpus of data without target labels (possibly on some artificial problem) and then the model parameters are used to initialize training on the target data set. Such pre-training can be used in speech recognition [
34].
A popular way of pre-training for image classification is proposed in [
35]. The authors choose several seed images without labels, generate many other samples from the chosen images by using augmentations, and pre-train the classifier on this data set. The original seed image and the images generated from it form a classifer for a pre-training classification problem. The classifier trained on this task shows good results on the downstream problem. To the best of our knowledge, our work is the first attempt to adapt this pre-training method to a keyword-spotting task.
Semisupervised learning and, specifically, self-training is another method to improve the quality of a resulting model [
36,
37] by using unlabeled data. The general framework of self-training is as follows:
Train a model on a small labeled data set.
Use the current model to label bigger unlabeled data set.
Form a new data set with newly labeled samples by applying the augmentations to the input features, but leaving the target labels as predicted on the uncorrupted samples.
Uptrain the model from the previous step on both the original data set and the samples from the new data set.
Repeat steps 2–4 until the quality is no longer improved.
In this work, we try to apply the method proposed in [
37] for speech recognition for a voice activation problem (see
Section 3.4.4 for more details).
4. Discussion
The results of all our experiments are summarized in
Table 16. For each architecture and for each investigated method, we show the test accuracy of the best model (models are chosen by their performance on the validation set). As you can see, there are several ways to improve the baseline quality of voice activation in a low-resource setup.
The goal of our research is to find methods of improving the detection quality of a voice activation system in a low-resource data set setup, comparing to standard training on the data set in a supervised manner (log-mel filterbanks baseline from
Section 3.4.1).
Using unsupervised pre-trained audio features is one such way, as was discussed in [
31]. Fine-tuning a model, which was pre-trained on a similar data set but in another language improves the results as expected.
The exemplar-like pre-training [
35] on surrogate audio patches produces comparable results to the baseline, but is unable to get a significant margin. We think that it is because our chosen augmentations do not cause invariance to the change of a speaker, which is crucial for voice activation. We also try to pre-train the model on the target training set itself, and obtain some improvement for some models, but a quality loss for others.
Self-training also helps, especially for the models with a lower capacity. Still, using wav2vec is almost always better. We think that it is because of not very useful data sets for pseudo-labels generation: there is no actual pronunciation for more than half of the target words in our lecture data set. It is not just an experiment drawback, but also a practical limitation: it is difficult to find a good source data set for pseudo-labels if the target words are rare. In other cases, we think that the investigation of iterative pseudo-labeling [
45] might be an interesting choice for future research.
Finally, we try to use the Google Speech Commands data set [
38] in the training process itself, not only as a pre-training dataset. We hope that adding the data set as unknown samples will help the classifier to learn more patterns, but there is no success. Making English commands an additional target helps the resulting classifier, but the results on only Lithuanian commands are horrible. We find out that it is because the Lithuanian part of the data set is small, compared to the Google Speech Commands part, so it is favorable for the classifier to focus on the English part. After that, we scale up the Lithuanian part by simply repeating the samples several times. The resulting metrics are better than the log-mel filterbanks baseline in all models and better than the wav2vec baseline in all models except
res8.
The accuracy is not the best metric for assessing the detection quality of a voice activation system because it does not reflect the balance between the two different types of errors [
1]:
False alarms.
False rejects.
Many researchers and practitioners use a false alarm rate (the rate of false detections over the samples without a keyword) and false reject rate (the rate of skipping the detection over the samples with a keyword). Still, the researchers that use the Google Speech Commands data set [
38] (and collected with the same principles Lithuanian dataset [
24]) use the test accuracy as a final metric (see, for example, [
15,
46,
47]) because it is easier to compare in the case of many keywords, and because a relatively big and diverse speech data set is required in order to get a reasonable estimate for a false alarm rate.
Still, it is possible to compute the false alarm rate and the false reject rate, even for a multiclass models. The obvious method is to compute these metrics for each keyword, but for our experiments it is not very practical: each keyword has a handful of test samples. Additionally, comparing two models by 15 pairs of false alarm rates and false reject rates is not a trivial task. Because of that, we use the same method as proposed in
scikit-learn tutorials [
48]: we convert this multiclass problem to a binary classification. For a sample with a target label
t out of
n classes with predicted probabilities
we consider
negative samples with predicted probabilities
and one positive sample with a predicted probability
. After that, we can compute false alarm rate and false reject rate. The values of these metrics for different values of classifying thresholds are presented in
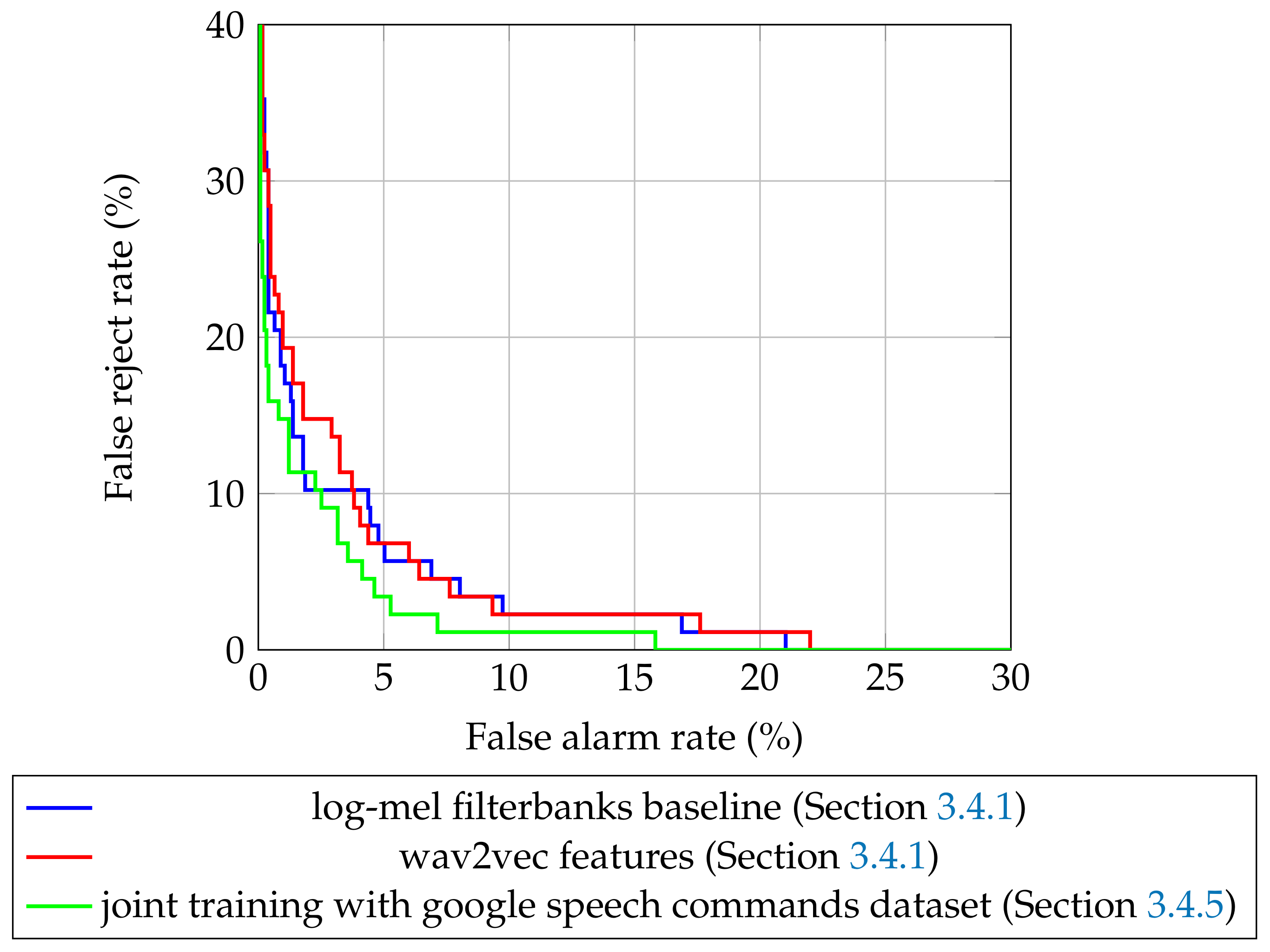
Figure 5 for the best models for baseline methods and joint training (
Section 3.4.5).
As you can see, the model with the highest quality (trained with joint training on both data sets) is almost everywhere better than all the competitors, which supports our findings. It is interesting to see that, though the wav2vec model is better than the log-mel filterbanks one in terms of accuracy, it is significantly worse in operating points, with a low false alarm rate. The equal error rate (EER, the minimal value that both false alarm rate and false reject rate can accept at the same time for a some value of threshold) also shows that the best log-mel filterbanks model () can be better than a wav2vec () for some scenarios. The best model from the proposed joint training method has an equal error rate .
5. Conclusions
In this work, we investigated several ways to improve the voice activation system quality in a low-resource language setup. The experiments on the Lithuanian data set [
31] showed that the use of unsupervised pre-trained audio features and joint training with a bigger annotated data set could beat a popular baseline of fine-tuning the model trained on a high-resource data set. For example, in our experiments, the proposed joint training on the Lithuanian [
31] and Google Speech Commands data sets [
38] showed a relative improvement from 7% (
ff-model) to 25% (
res26-narrow model) for the Lithuanian part of the test-set, compared to a simple fine-tuning. In addition, we improved the best test accuracy on the Lithuanian data set across all architectures to 93.85% from 90.77%, reported in [
31].
In future works, the combinations of investigated methods could be researched. Additionally, better augmentations causing speaker invariance can be studied in order to improve the quality of exemplar-like pre-training.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}