
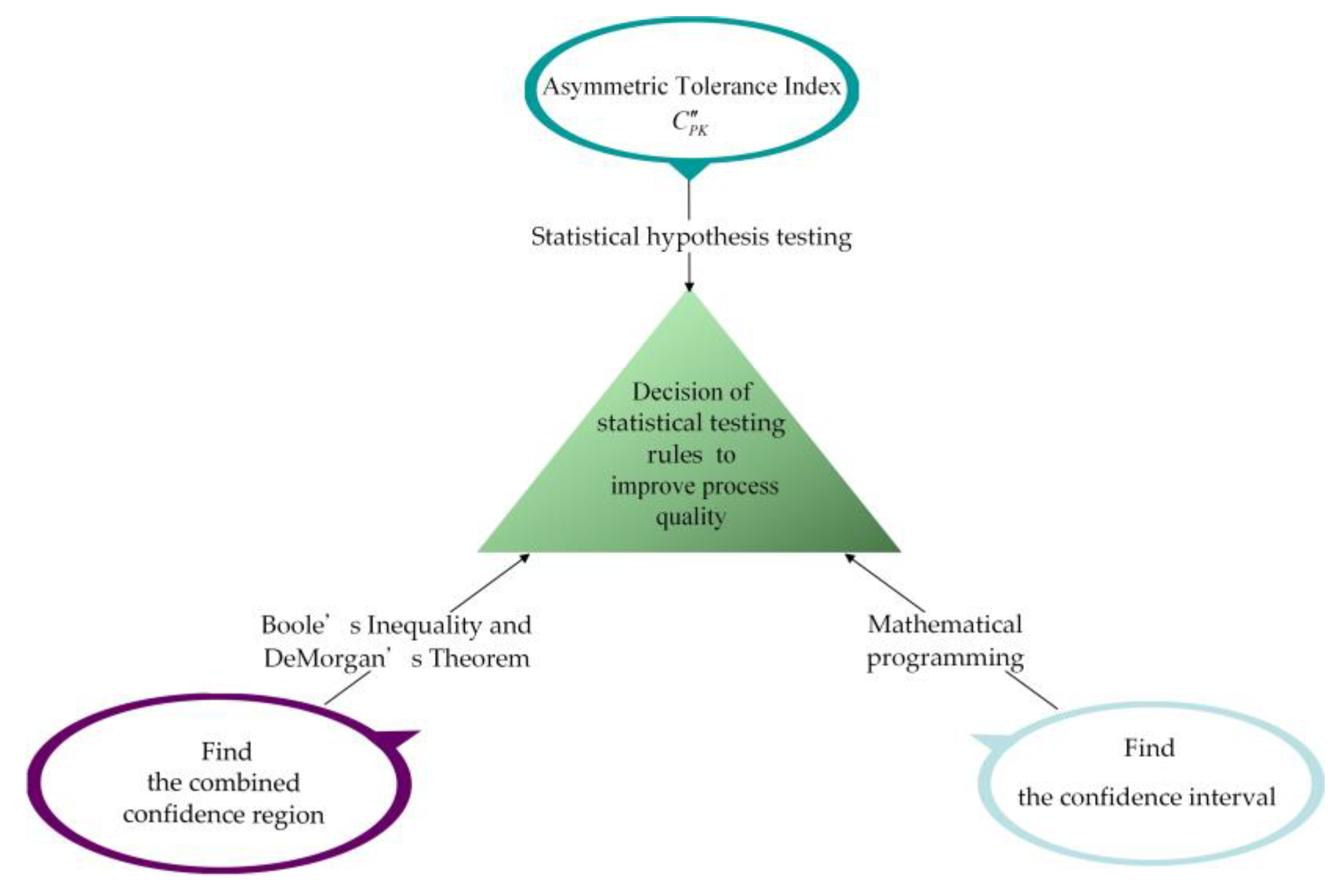
Statistical Hypothesis Testing for Asymmetric Tolerance Index


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Confidence Region
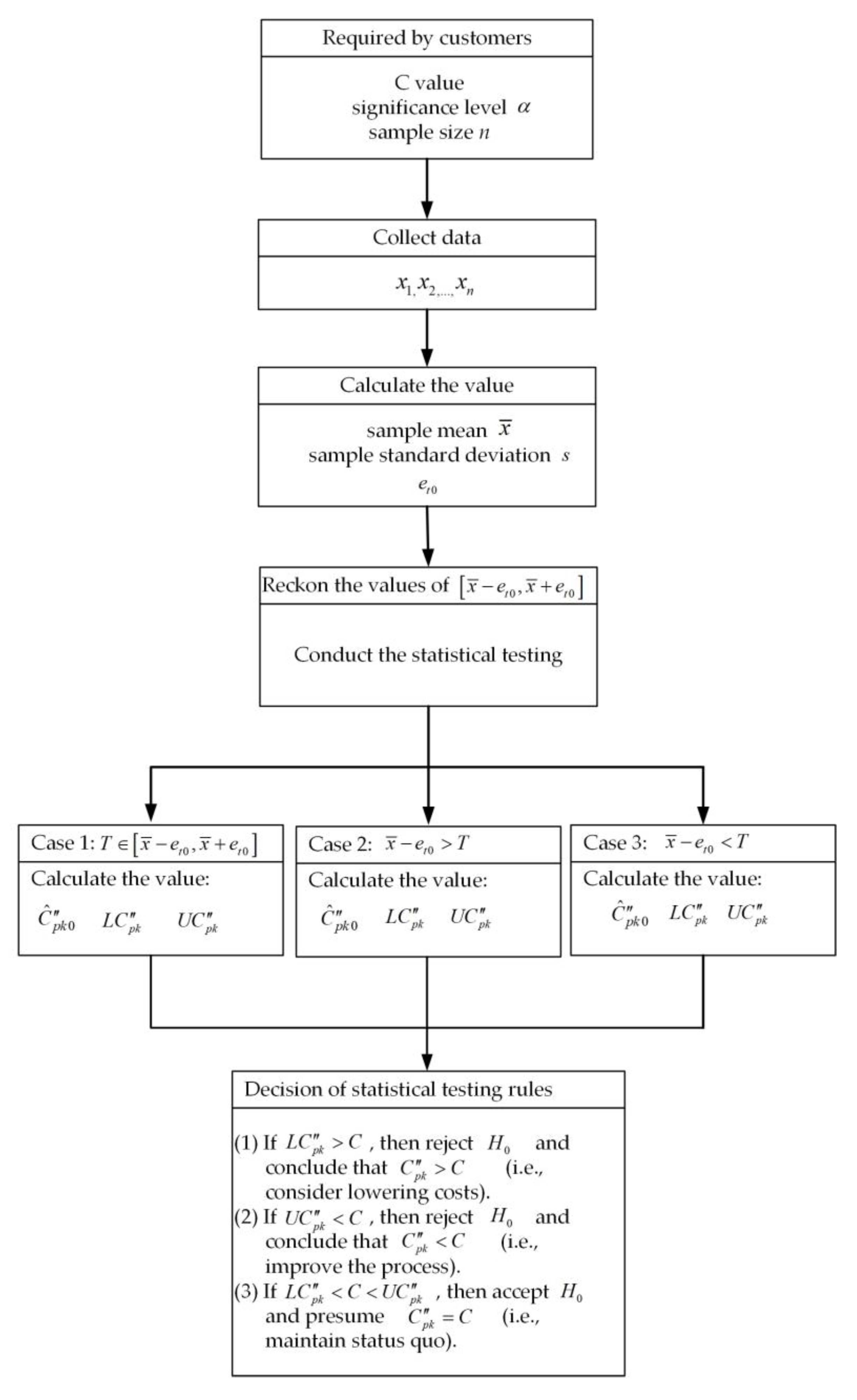
3. Statistical Hypothesis Testing
- (1)
- Process capability is considered “inadequate” when 1.00.
- (2)
- Process capability is considered “capable” when 1.00 1.33
- (3)
- Process capability is considered “satisfactory” when 1.33 1.5
- (4)
- Process capability is considered “excellent” when 1.50 2.00
- (5)
- Process capability is considered “superb” when 2.00
- (1)
- If , then reject and conclude that (i.e., consider lowering costs).
- (2)
- If , then reject and conclude that (i.e., improve the process).
- (3)
- If , then accept and presume (i.e., maintain status quo).
4. An Illustrative Example
5. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Lin, K.P.; Yu, C.M.; Chen, K.S. Production data analysis system using novel process capability indices-based circular economy. Ind. Manag. Data Syst. 2019, 119, 1655–1668. [Google Scholar] [CrossRef]
- Chien, C.F.; Hong, T.Y.; Guo, H.Z. An empirical study for smart production for TFT-LCD to empower Industry 3.5. J. Chin. Inst. Eng. 2017, 40, 552–561. [Google Scholar] [CrossRef]
- Chen, K.S.; Wang, C.H.; Tan, K.H. Developing a fuzzy green supplier selection model using Six Sigma quality indices. Int. J. Prod. Econ. 2019, 212, 1–7. [Google Scholar] [CrossRef]
- Prahalad, C.K.; Hamel, G. The Core Competence of the Corporation. Harv. Bus. Rev. 1990, 68, 79–91. [Google Scholar]
- Grossman, G.M.; Helpman, E. Integration versus outsourcing in industry equilibrium. Q. J. Econ. 2002, 117, 85–120. [Google Scholar] [CrossRef]
- Chen, K.S. Incapability index with asymmetric tolerances. Stat. Sin. 1998, 8, 253–262. [Google Scholar]
- Pearn, W.L.; Lin, P.C.; Chen, K.S. The C′′pk index for asymmetric tolerances: Implications and inference. Metrika 2004, 60, 119–136. [Google Scholar] [CrossRef]
- Shu, M.H.; Chen, K.S. Estimating process capability indices based on subsamples for asymmetric tolerances. Commun. Stat. Theory Methods 2005, 34, 485–505. [Google Scholar] [CrossRef]
- Chuang, C.J.; Wu, C.W. Determining optimal process mean and quality improvement in a profit-maximization supply chain model. Qual. Technol. Quant. Manag. 2019, 16, 154–169. [Google Scholar] [CrossRef]
- Shafer, S.M.; Moeller, S.B. The effects of Six Sigma on corporate performance: An empirical investigation. J. Oper. Manag. 2012, 30, 521–532. [Google Scholar] [CrossRef]
- Anderson, N.C.; Kovach, J.V. Reducing welding defects in turnaround projects: A lean six sigma case study. Qual. Eng. 2014, 26, 168–181. [Google Scholar] [CrossRef]
- Yang, C.M.; Chen, K.S.; Hsu, T.H.; Hsu, C.H. Supplier selection and performance evaluation for high voltage power film capacitors in fuzzy environment. Appl. Sci. 2019, 9, 5253. [Google Scholar] [CrossRef] [Green Version]
- Abbasi Ganji, Z.; Sadeghpour Gildeh, B. A new multivariate process capability index. Total Qual. Manag. Bus. Excell. 2017, 30, 525–536. [Google Scholar] [CrossRef]
- Nikzad, E.; Amiri, A.; Amirkhani, F. Estimating total and specific process capability indices in three-stage processes with measurement errors. J. Stat. Comput. Simul. 2018, 88, 3033–3064. [Google Scholar] [CrossRef]
- Besseris, G.J. Evaluation of robust scale estimators for modified Weibull process capability indices and their bootstrap confidence intervals. Comput. Ind. Eng. 2019, 128, 135–149. [Google Scholar] [CrossRef]
- de-Felipe, D.; Benedito, E. Monitoring high complex production processes using process capability indices. Int. J. Adv. Manuf. Technol. 2017, 93, 1257–1267. [Google Scholar] [CrossRef] [Green Version]
- Kane, V.E. Process capability indices. J. Qual. Technol. 1986, 18, 41–52. [Google Scholar] [CrossRef]
- Boyles, R.A. Process capability with asymmetric tolerances. Commun. Stat. Simul. Comput. 1994, 23, 615–643. [Google Scholar] [CrossRef]
- Pearn, W.L.; Chen, K.S. New generalization of the process capability index Cpk. J. Appl. Stat. 1998, 25, 801–810. [Google Scholar] [CrossRef]
- Chen, K.S.; Huang, C.F.; Chang, T.C. A mathematical programming model for constructing the confidence interval of process capability index Cpm in evaluating process performance: An example of five-way pipe. J. Chin. Inst. Eng. 2017, 40, 126–133. [Google Scholar] [CrossRef]
- Lo, W.; Yang, C.M.; Lai, K.K.; Li, S.Y.; Chen, C.H. Developing a Novel Fuzzy Evaluation Model by One-Sided Specification Capability Indices. Mathematics 2021, 9, 1076. [Google Scholar] [CrossRef]
- Pearn, W.L.; Chen, K.S. Estimating process capability indices for non-normal pearsonian populations. Qual. Reliab. Eng. Int. 1995, 11, 386–388. [Google Scholar] [CrossRef]
- Liao, S.J.; Chen, K.S.; Li, R.K. Capability evaluation for processes of the larger-the-better type for non-normal populations. Adv. Appl. Stat. 2002, 2, 189–198. [Google Scholar]
- Erfanian, M.; Sadeghpour Gildeh, B. A new capability index for non-normal distributions based on linex loss function. Qual. Eng. 2021, 33, 76–84. [Google Scholar] [CrossRef]
- Farokhnia, M.; Niaki, S.T.A. Principal component analysis-based control charts using support vector machines for multivariate non-normal distributions. Commun. Stat. Simul. Comput. 2020, 49, 1815–1838. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.-S.; Chen, S.-C.; Hsu, C.-H.; Chen, W.-Z. Statistical Hypothesis Testing for Asymmetric Tolerance Index. Appl. Sci. 2021, 11, 6249. https://doi.org/10.3390/app11146249
Chen K-S, Chen S-C, Hsu C-H, Chen W-Z. Statistical Hypothesis Testing for Asymmetric Tolerance Index. Applied Sciences. 2021; 11(14):6249. https://doi.org/10.3390/app11146249
Chicago/Turabian StyleChen, Kuen-Suan, Shui-Chuan Chen, Chang-Hsien Hsu, and Wei-Zong Chen. 2021. "Statistical Hypothesis Testing for Asymmetric Tolerance Index" Applied Sciences 11, no. 14: 6249. https://doi.org/10.3390/app11146249
APA StyleChen, K.-S., Chen, S.-C., Hsu, C.-H., & Chen, W.-Z. (2021). Statistical Hypothesis Testing for Asymmetric Tolerance Index. Applied Sciences, 11(14), 6249. https://doi.org/10.3390/app11146249