
A Set of Single YOLO Modalities to Detect Occluded Entities via Viewpoint Conversion



Abstract
:1. Introduction
2. Related Works
2.1. Preliminaries on YOLO
2.2. Detecting Partially Occluded Objects
3. Methodology
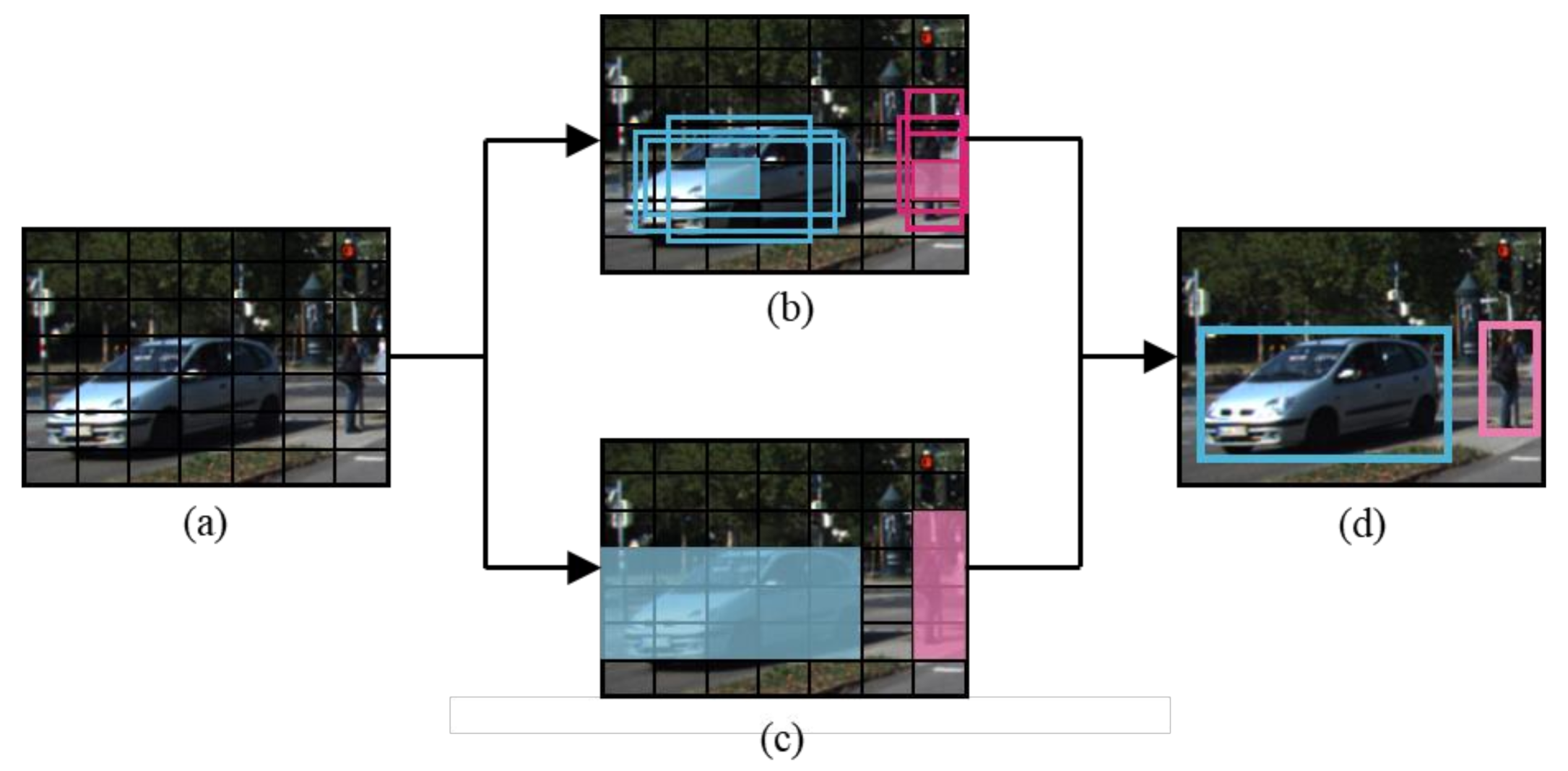
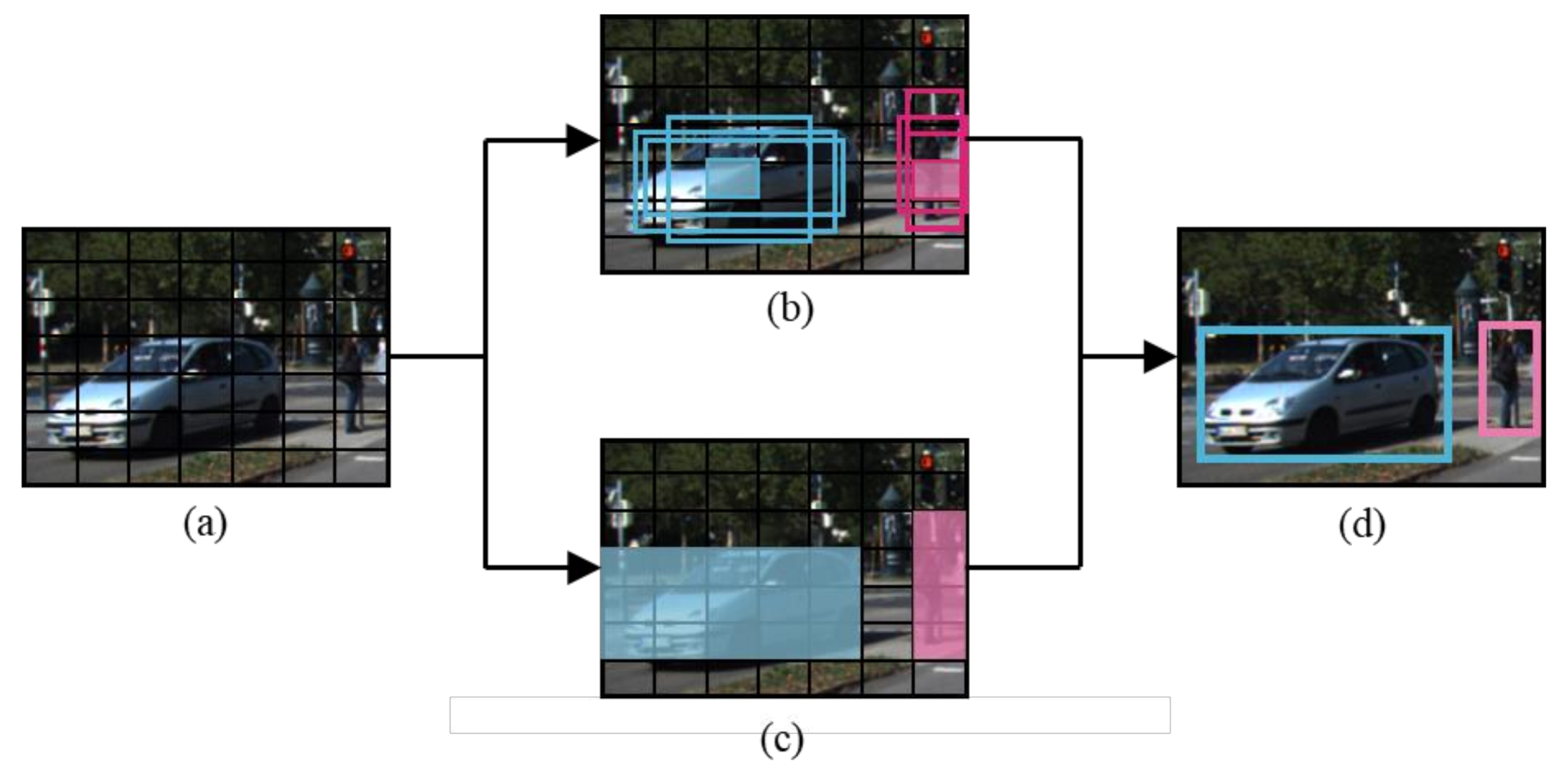
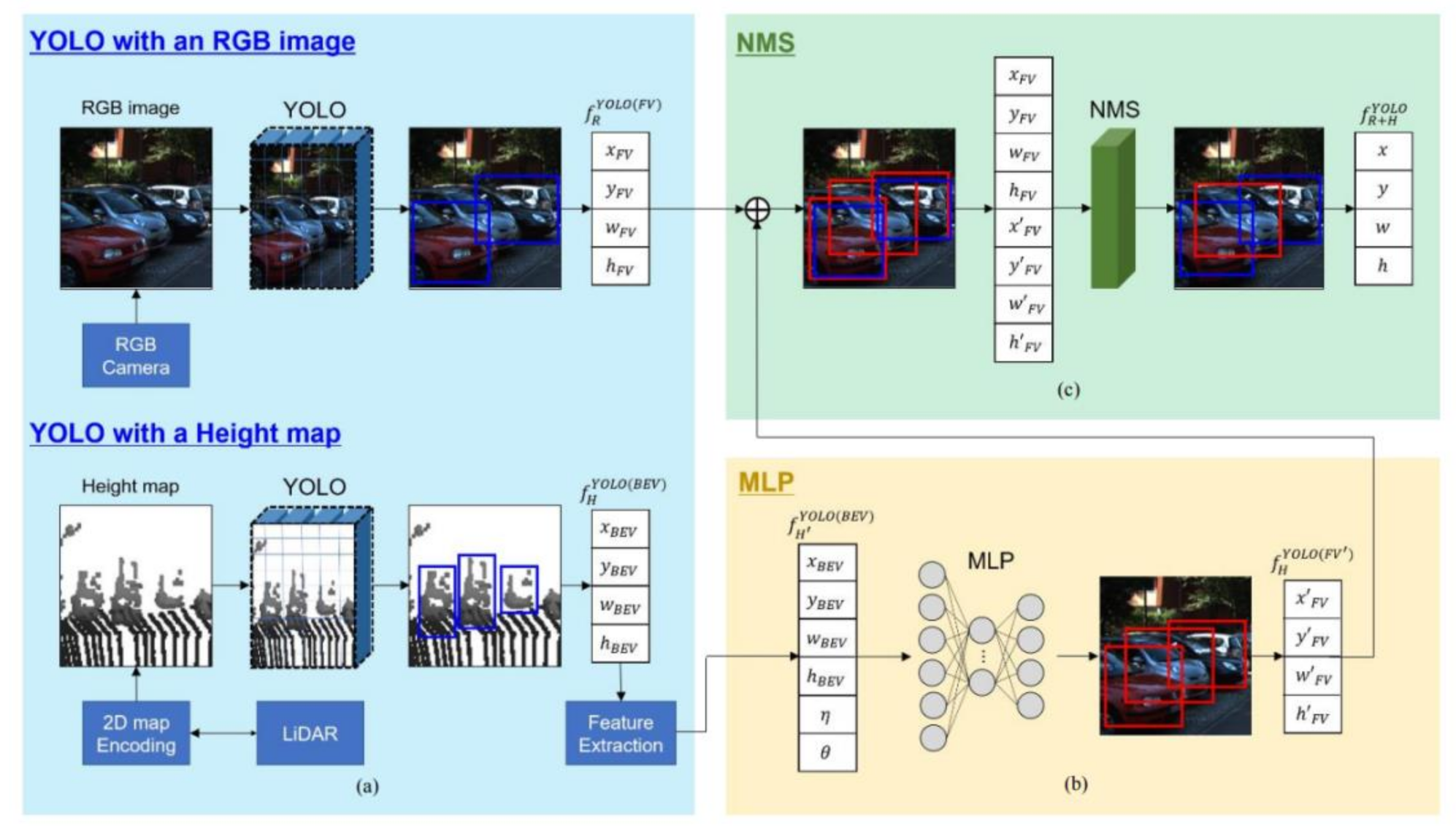
3.1. System Overview
3.2. Object Detection Using YOLOs in Parallel
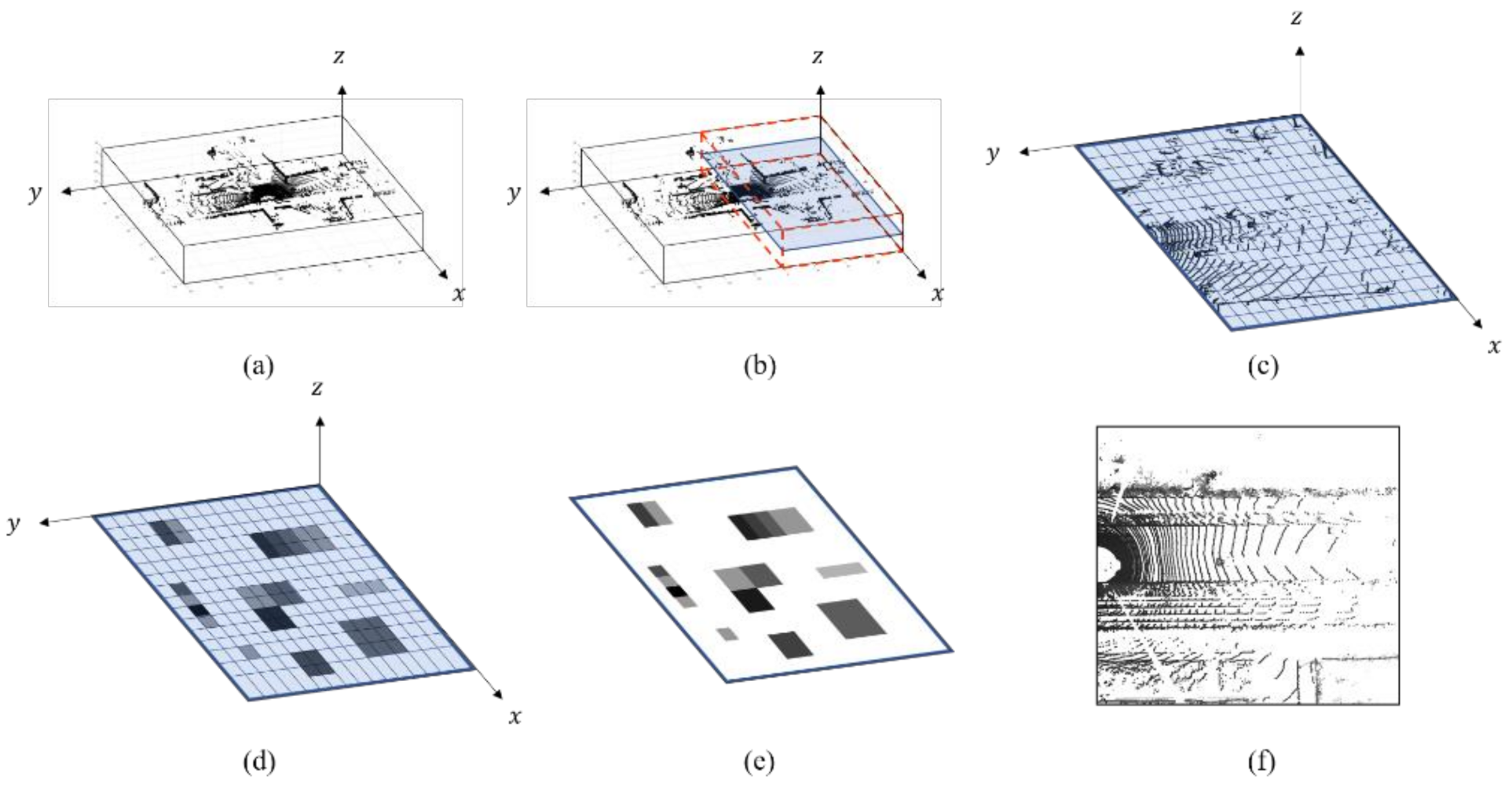
3.3. Conversion of Image Viewpoint Using MLP
3.4. Region Proposals through NMS
4. Experimental Results
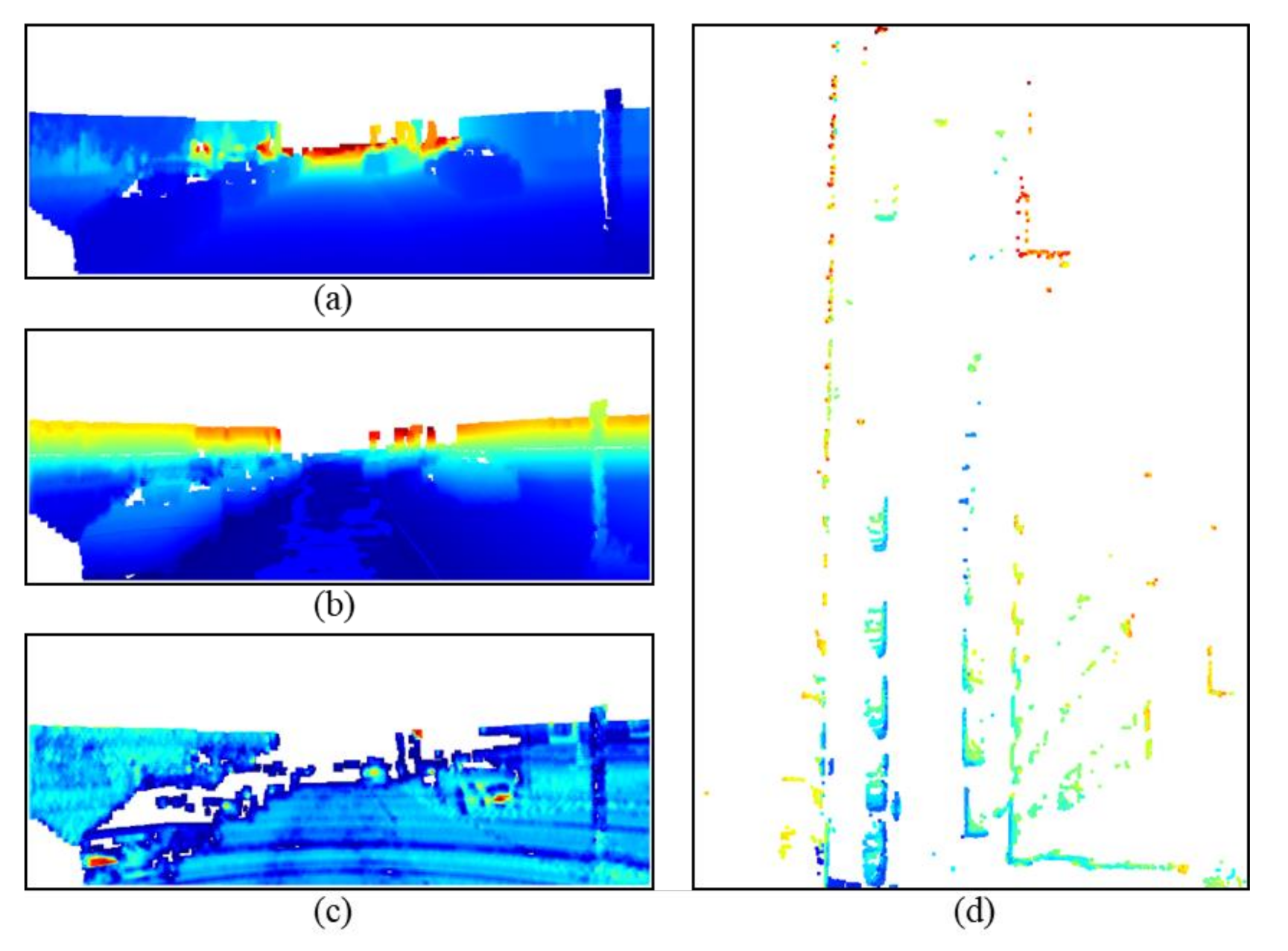
4.1. Assessment Details
4.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, Y.; Yu, J.; Cai, J.; Luo, J. End-to-end multi-modal multi-task vehicle control for self-driving cars with visual perceptions. In Proceedings of the International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2289–2294. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.; Monfort, M.; Muller, U.; Zhang, X.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Jackel, L.D.; Sharman, D.; Stenard, C.E.; Strom, B.I.; Zuckert, D. Optical character recognition for self-ervice Banking. ATT Tech. J. 1995, 74, 16–24. [Google Scholar] [CrossRef] [Green Version]
- Manghat, S.K.; El-Sharkawy, M. Forward Collision Prediction with Online Visual Tracking. In Proceedings of the IEEE International Conference on Vehicular Electronics and Safety (ICVES), Cairo, Egypt, 4–6 September 2019; pp. 1–5. [Google Scholar]
- Banerjee, S.S.; Jha, S.; Cyriac, J.; Kalbarczyk, Z.T.; Iyer, R.K. Hands off the wheel in autonomous vehicles?: A systems perspective on over a million miles of field data. In Proceedings of the Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Luxembourg, 25–28 June 2018; pp. 586–597. [Google Scholar]
- Ren, L.; Yin, H.; Ge, W.; Meng, Q. Environment Influences on Uncertainty of Object Detection for Automated Driving Systems. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Huaqiao, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Bagloee, S.A.; Tavana, M.; Asadi, M.; Oliver, T. Autonomous vehicles: Challenges, opportunities, and future implications for transportation policies. J. Mod. Transp. 2016, 24, 284–303. [Google Scholar] [CrossRef] [Green Version]
- Stocco, A.; Weiss, M.; Calzana, M.; Tonella, P. Misbehaviour prediction for autonomous driving systems. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Korea, 27 June–19 July 2020; pp. 359–371. [Google Scholar]
- Göhring, D.; Wang, M.; Schnürmacher, M.; Ganjineh, T. Radar/lidar sensor fusion for car-following on highways. In Proceedings of the International Conference on Automation, Robotics and Applications, Wellington, New Zealand, 6–8 December 2011; pp. 407–412. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Yoneda, K.; Suganuma, N.; Yanase, R.; Aldibaja, M. Automated driving recognition technologies for adverse weather conditions. IATSS Res. 2019, 43, 253–262. [Google Scholar] [CrossRef]
- Royo, S.; Ballesta-Garcia, M. An overview of lidar imaging systems for autonomous vehicles. Appl. Sci. 2019, 9, 4093. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7345–7353. [Google Scholar]
- Kumar, G.A.; Lee, J.H.; Hwang, J.; Park, J.; Youn, S.H.; Kwon, S. LiDAR and camera fusion approach for object distance estimation in self-driving vehicles. Symmetry 2020, 12, 324. [Google Scholar] [CrossRef] [Green Version]
- Zhao, K.; Liu, L.; Meng, Y.; Gu, Q. Feature Deep Continuous Aggregation for 3D Vehicle Detection. Appl. Sci. 2019, 9, 5397. [Google Scholar] [CrossRef] [Green Version]
- Lingtao, Z.; Jiaojiao, F.; Guizhong, L. Object Viewpoint Classification Based 3D Bounding Box Estimation for Autonomous Vehicles. arXiv 2019, arXiv:1909.01025. [Google Scholar]
- Kim, J.; Cho, J. Exploring a multimodal mixture-of-YOLOs framework for advanced real-time object detection. Appl. Sci. 2020, 2, 612. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–16 June 2005; pp. 886–893. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Vedaldi, A.; Zisserman, A. Structured output regression for detection with partial truncation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1928–1936. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 32–39. [Google Scholar]
- Gao, T.; Packer, B.; Koller, D. A segmentation-aware object detection model with occlusion handling. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 20–25 June 2011; pp. 1361–1368. [Google Scholar]
- Pepikj, B.; Stark, M.; Gehler, P.; Schiele, B. Occlusion patterns for object class detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2013; pp. 3286–3293. [Google Scholar]
- Kim, J.U.; Kwon, J.; Kim, H.G.; Lee, H.; Ro, Y.M. Object bounding box-critic networks for occlusion-robust object detection in road scene. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1313–1317. [Google Scholar]
- Palazzi, A.; Borghi, G.; Abati, D.; Calderara, S.; Cucchiara, R. Learning to map vehicles into bird’s eye view. In Proceedings of the International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; pp. 233–243. [Google Scholar]
- Chen, T.; Han, D.; Au, F.; Than, L. Acceleration of Levenberg-Marquadt training of neural networks with variable decay rate. IEEE Trans. Neural Netw. 2003, 3, 1873–1878. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 18–20 June 2012; pp. 3354–3361. [Google Scholar]
- Asvadi, A.; Garrote, L.; Premebida, C.; Peixoto, P.; Nunes, U.J. Multimodal vehicle detection: Fusing 3D-LIDAR and color camera data. Pattern Recognit. Lett. 2018, 115, 20–29. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Probability | Case | Confidence Score |
|---|---|---|
| If the bounding box is included in the background area | ||
| If the bounding box is included in the area where the object exists |
| Detection Model | YOLO Version | Viewpoint | 2D AP (%) | ||
|---|---|---|---|---|---|
| Difficulty (IOU = 0.7) | |||||
| Easy | Moderate | Hard | |||
| [40] | V2 V2 | FV | 73.93 | 61.69 | 54.00 |
| [40] | FV | 75.13 | 62.74 | 55.10 | |
| [22] | V2 | FV | 88.78 | 76.20 | 50.77 |
| [22] | V2 | FV | 90.89 | 81.67 | 52.78 |
| V3 | FV | 95.01 | 87.52 | 77.43 | |
| V3 | FV + BEV | 95.06 | 89.41 | 81.73 | |
| Detection Model | YOLO Version | Viewpoint | 2D AP (%) | ||
|---|---|---|---|---|---|
| IOU Threshold | |||||
| 0.3 | 0.5 | 0.7 | |||
| V3 | FV | 87.67 | 85.89 | 72.56 | |
| FV | 88.17 | 86.40 | 73.58 | ||
| FV+BEV | 89.59 | 88.07 | 76.06 | ||
| (noise) | FV | 86.47 | 84.52 | 69.90 | |
| (noise) | FV+BEV | 89.11 | 87.43 | 73.14 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Cho, J. A Set of Single YOLO Modalities to Detect Occluded Entities via Viewpoint Conversion. Appl. Sci. 2021, 11, 6016. https://doi.org/10.3390/app11136016
Kim J, Cho J. A Set of Single YOLO Modalities to Detect Occluded Entities via Viewpoint Conversion. Applied Sciences. 2021; 11(13):6016. https://doi.org/10.3390/app11136016
Chicago/Turabian StyleKim, Jinsoo, and Jeongho Cho. 2021. "A Set of Single YOLO Modalities to Detect Occluded Entities via Viewpoint Conversion" Applied Sciences 11, no. 13: 6016. https://doi.org/10.3390/app11136016
APA StyleKim, J., & Cho, J. (2021). A Set of Single YOLO Modalities to Detect Occluded Entities via Viewpoint Conversion. Applied Sciences, 11(13), 6016. https://doi.org/10.3390/app11136016