Abstract
For the question regarding the relationship between personal factors and location selection, many researches support the effect of personal features for personal location favorite. However, it is also found that not all of personal factors are effective for location selection. In this research, only distinguished personal features excluding meaningless features are used in order to predict visiting ratio of specific location categories by using three different machine learning techniques: Random Forest, XGBoost, and Stacking. Through our research, the accuracy of prediction of visiting ratio to a specific location regarding personal features are analyzed. Personal features and visited location data had been collected by tens of volunteers for this research. Different machine learning methods showed very similar tendency in prediction accuracy. As well, precision of prediction is improved by application of hyperparameter optimization which is a part of AutoML. Applications such as location based service can utilize our result in a way of location recommendation and so on.
1. Introduction
Prior researches show that human personality and favorite visiting place have considerable relationship . Coefficient of Determination is used in the relation between personality and favored locations [1]. By use of probability models such as Poisson distribution, the relation between personality and favored locations are identified and personal mobility model is predicted in [2,3]. These are traditional methods of analysis based on statistics. A trail to use machine learning in order to these analysis can be found in [4] in terms of back propagation network. Nowadays, a lot of new methods including machine learning technologies can be adopted for such sort of analysis. In this research, we will show the relation between personal factors and favorite locations using various machine learning techniques, especially ensemble techniques, and will verify the consensus of results from machine learning methods.
Ensemble techniques combines the result of each independent model and thus shows more preciseness comparing to single model only. By introducing up to date machine learning techniques, ensemble techniques of several machine learning models are used in this research. Two representative ensemble techniques are used: bagging and boosting. For bagging techniques, random forest is used since it is widely used. For boosting techniques, we used XGBoost since it has high performance and fast in training time, which is also widely used. Both of two methods, random forest and XGBoost have base model of decision tree. We also used stacking as shown in Section 2.4 in order to verify that various regression models other than decision tree also effective in our research in a form of meta learning. Different from previous researches, our focus is that common belief of relationship between personality and location selection is proved by state of the art technologies. As well personal features other than personality such as age, religion, method of transportation, salary, and so on, are also used for this relationship analysis. In addition, the results of ensemble methods will be presented in numerical manner. For the inputs of analysis, as well as personalities, other personal factors such as salary, method of transportation, religion, and so on are found to be related with favorite locations [5,6]. However not all of these personal factors are meaningful factors for location preference. In other words, meaningless features for the input of analysis degrades the prediction accuracy of the relationship. Therefore feature selection [7] was executed for each location category. And then, prediction accuracy was improved through hyperparameter optimization. Hyperparameter optimization was done in three different ways: grid search, random search [8] and bayesian optimization [9] from the current advancement of AutoML. Grid search and random search are two representative methods of hyperparameter optimization. Grid search takes long time since it checks performance for every possible candidates of parameters. Random search is faster than grid search since it checks several samples randomly while shows less precision comparing to grid search. These two methods has shortages that current search information cannot be transferred to next step. Bayesian optimization overcomes this shortage: it utilizes prior knowledge for new search of optimized value with smaller search time and higher precision. In this research, all three of hyperparameter optimization methods are used. In this research, Big Five Factors (BFF) of personality such as Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism are used as well as the highest level of education, religion, salary, method of transportation, commute time, the frequency of journey in one year, social media usage status, time spent on social media per day, and nature of personaly hobby. BFF is taxonomy for personality characteristics presented by Costa & McCrae in 1992, and it is found useful for personality related research. In this research, numerical features of BFF is utilized and BFF is regarded as parts of input data. With these selected inputs of relationship analysis, we will use machine learning techniques for the analysis. Basically, three machine learning methods were used: Random Forest, XGBoost, and Stacking. Each of three methods is sort of ensemble techniques. From various aspects of researches, ensemble method is proven to compensate the weakness of single model and improve the performance of generalization [10]. Random Forest, especially, prevents overfitting by using bagging techniques. For XGBoost, boosting technique is used to repeated random sampling for weighted sequential learning. It is also possible to reduce bias with boosting technique. Stacking combines multiple machine learning methods in order to exploit of strength of multiple models and complement weakness of two different models in a way of multistage learning. Stacking has better performance comparing to other models while it requires high computational cost. With these three different ensemble methods with different characteristics, the results of three techniques must be verified each other in order to show the consensus of three result sets. In Section 2, we will show related techniques. In addition to machine learning technique used in this research, considerations of personality factors will be discussed. Section 3 will show details of the data and the experiment. The handling of personal factors and location categories will be discussed. As well, SMAPE will be addressed which stands for prediction error along with search space for hyperparameter optimization. Section 4 will show results of analysis by Random Forest, XGBoost, and Stacking and evaluate the results. Results of all three techniques were verified and discussed. As well, results of feature selection and hyperparameter optimization will be discussed. For Random forest and XGBoost, we can apply both of feature selection and hyperparameter optimization however for Stacking, hyperparamter optimization was omitted due to the high computational cost. However, feature selection solely improved prediction accuracy for most of location category. There is high similarity among three result sets and thus consensus can be addressed for the relationship between location categories and personal features. Section 5 will conclude this research with future works.
2. Related Works
2.1. Ensemble Techniques
Ensemble model is a technique to generate one strong prediction model with combinations of existing several machine learning models, which usually shows better prediction performance comparing to single model approach. Three distinguished models of ensemble methods are bagging, boosting and Stacking. Bagging reduces variance, boosting reduces bias, and stacking shows improved prediction performance. For example, ensemble methods are highly ranked at the machine learning competition such as Netflix competition, KDD 2009, and Kaggle [11]. Random Forest is a typical model using bagging. Boosting algorithm has improved to XGBoost which is usual selection with guaranteed performance nowadays. Stacking combines different models while bagging or boosting depends on single base model. In such way, strength of different algorithms are exploited while weakness of each algorithms can be compensated. We will use all three methods: Random Forest, XGBoost, and Stacking in order to show the relationship between personal features and favorite location categories [10].
2.2. Random Forest
Random Forest is suggested by Leo Breiman in 2001 [12]. Random Forest a combination of different decision trees. Each decision tree can predict well while there is possibility of overfitting for train data. But combination of various independent decision trees and average of the results can show prediction performance excluding overfitting effect. Bootstrap is usually used in order to generate multiple independent trees. Each nodes utilizes part of input features. Each branch of decision tree uses subset of different features. Such a process of learning enables every decision tree in Random Forest be unrelated. Then the final result of regression analysis is average of the results from each decision tree. In this research, we use average while in case of classification problem, the final value can be voted from the results of each decision tree. It is resistant to noise. In addition, the degree of effect of input feature can be numerically represented as importance value. With feature importance, important and effective input features can be selected. It also works well on very large datasets and can parallelize the train simply. It is also appropriate to deal with many input features [13]. Random Forest is one of widely used machine learning algorithm with excellent performance. It works well even without much hyperparameter tuning, and does not need to scale data. However, some of hyperparameters are optimized in order to figure out the effect of hyperparameter. Due to this advantage and performance, a Random Forest was used for this study.
2.3. XGBoost
XGBoost use boosting instead of bagging in terms of ensemble. Boosting is a technique of binding weak leaner in order to build powerful predictor. Other than bagging, which aggregates result of independent models, boosting generates booster which stands for base model sequentially. Bagging is to generate model with general performance while boosting is concentrated on solving difficult problems. Therefore, boosting put high weight on difficult problems, by assigning high weight on incorrect answers while assigning low weight on correct answers. Boosting is prone to be weak with outlier values even though it shows high prediction accuracy.
XGBoost stands for Extreme Gradient Boosting and is developed by Tianqi Chen [14]. XGBoost is a performance upgraded version of Gradient Boosting Machine (GBM). XGBoost is widely used by various challenges such as the Netflix prize. For example, 17 prize winners out of 29 solutions of Kaggle in 2015 is implemented by XGBoost [11]. XGBoost is supervised learning algorithm and is an ensemble method such as Random Forest. It is suitable to regression, classification and so on. XGBoost is aim for scalability, portability, and accurate library. In other words, XGBoost utilizes parallel processing and has high flexibility. It has automatic pruning facility with greedy-algorithm and thus shows less chance of overfitting. XGBoost has various hyperparameters and learning rate, max depth of booster, selection of boosters, number of booster are very effective parameters for performance. For boosters of XGBoost, there are gbtree, gblinear, and dart. Gbtree utilizes weak learner as regression tree which is a decision tree with continuous real number object values. Gblinear utilizes weak learner as linear regression model, and dart has base model of regression tree with dropout which is usually used in neural network.
2.4. Stacked Generalization (Stacking)
Stacking is one of ensemble method of machine learning method supposed by D. H. Wolperk dates in the year of 1992 [15]. The key of Stacking is training various machine learning models independently, and then meta model does machine learning with the result of the models as inputs, thus Stacking has stack of two or more learning phases. Stacking method combines various machine learning models so that it solves high variance problem fulfilling to the basic purpose of ensemble method, different from other machine learning methods such as bagging, boosting, and voting. In addition, combinations were made in a way that to obtain the strength of each models and compensates the weakness of each models.
Training stage is composed of two phases. At level 1, prediction of sub models are trained with train data similar to other methods. Usually various sub models are utilized in order to generate various prediction. At level 2, prediction generated at level 1 are regarded as input features, and then meta learner or blender, which is final predictor, generates final prediction result. In this stage, overfitting and bias are reduced since level 2 uses different train data from level 1 [16]. Since Stacking does not provide feature selection, input features selected by Random Forest model were used. In our research, ExtraTreesRegressor, RandomForestRegressor, XGBRegressor, LinearRegressor, and KNeighborsRegressor are used at level 1, and final results were selected with low error rate from the result of XGBoost and Random Forest depending on each location categories.
2.5. Feature Selection
Usually, machine learning is a linear or non-linear function of input data. The selection of train data in order to learn a function is not negligible for better model construction. The volume of data does not guarantee better models however, incorrect results could be misled. For example, linear function with large number of independent variable does not guarantee high prediction of expected value of dependent variable. In other words, the performance of machine learning is highly dependent on input data set, as meaningless input data hinders learning result from being better one. Therefore, it is required to select meaningful features of collected data in advance to model learning, and it is so called feature selection. Subsets of data is used to test the validity of features, i.e., feature selection. For example, importance of feature is higher as the feature sits near root of tree. Then it is possible to imply the importance of a specific feature. In case of regression model, it is possible to do feature selection with use of forward selection and/or backward elimination. In addition to improve performance of model, feature selection has another benefit of reducing the dimension of input data. Through the feature selection, input data set which is smaller than real observation space however which has better explainability, and it is useful for very big data, or for restricted resource or time [7].
2.6. Hyperparameter Optimization
Apart from parameters dependent on data or model, hyperparameter is dependent on machine learning model. Learning rate for deep learning or max depth for decision tree are prominent examples. It is very important to find optimal value for each hyperparameter since hyperparameters significantly affects the performance of model. Manual search of hyperparameters usually requires intuition of skillful researchers, luck and consumes too much time. There exists two famous systematic methodology called grid search and random search [8]. Grid Search searches hyperparameter values in predefined regular intervals and decide values of highest performance, even though human actions are also required. Such uniform and global nature of grid search is a better than manual search however, also requires much time in case of combination for hyperparameters increase. Random search, a random sampling approach of grid search shows increased speed of hyperparameter search. However, these two search methods does repetitive unnecessary search since they does not utilize prior knowledge of hyperparameter search. Bayesian Optimization is another useful method with systematic use of prior knowledge [9]. Bayesian Optimization assumes an objective function f of input value x, where objective function f is a blackbox and requires time to compute. Searching for f with small number of input values as small as possible is main purpose. Surrogate Model and Acquisition Function are also required. Surrogate Model does probabilistic estimation for unknown objective function based on known input values and function values pair of . Probability models for surrogate model are Gaussian Processes (GP), Tree-structured Parzen Estimators (TPE), Deep Neural Networks and so on. Acquisition Function recommends next useful input value of based on current estimations of objective function in order to search optimal input value of . Two strategies are famous: exploration and exploitation. Exploration recommends points with high standard deviation since may exist in uncertain region. Exploitation recommends points around the point with highest function value. Two strategies are equally important in order to search optimal input value, . However, calibrating ratio of two strategy is very important since these two strategies show trade off. Expected Improvement (EI) is the most frequently used as acquisition function since EI contains both of exploration and exploitation. Probability of improvement (PI) is a probability of a certain input value x which function value is bigger than among current estimations of . Then EI calculates the effect of x considering PI and magnitude between and . EI can consider Probability of Improvement (PI), and another strategies such as Upper Confidence Bound (UCB), Entropy Search (ES), and so on are exist.
2.7. Big Five Factors (BFF)
BFF is a factor of personality suggested by P.T. Costa and R.R. McCrae in 1992 [17]. It has five factors of Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. Set of questionnaires is answered by participants and each five factors will be valued as a score from 1 to 5points. Since BFF can numerically represent conceptual human personality, many of research adopts BFF [18,19,20,21,22,23].
3. Preparation of Experiments
Previous research results showed that various personal factors effect the favorite visiting place [5,6]. In addition, effective personal factors vary widely according to each location category [5]. In this research, more precise experiments were designed including feature selection and hyperparameter optimization with three different machine learning methodology. More than 60 volunteers had been collected their own data for this research. However, some parts of data from volunteers are too small for this research, therefore only meaningful data sets are survived. From the data of 34 volunteers, personal factors used in the experiments were:
- The highest level of education
- Religion
- Salary
- Method of transportation
- Commute time
- The frequency of journey in one year
- Social media usage status
- Time spent on social media per day
- Category of personaly hobby
- BFF
These input features and location visiting data from SWARM [24] application are treated as inputs for Random Forest, XGBoost, and Stacking. The primary result is ratio of visiting to specific location categories. For Stacking, ExtraTreesRegressor, RandomForestRegressor, XGBRegressor, LinearRegressor, and KNeighborsRegressor are used in level 1, and XGBoost and Random Forest are used in level 2, result with the smallest error rate is selected. In order to compare experiment result, Symmetric Mean Absolute Percentage Error (SMAPE) discussed in Section 3.4. SMAPE usually represented in a range of 0 to 200% while we normalized the value in a range of 0 to 100% by revising the formula for intuitive comparison. As a result, prediction accuracy is difference between 100% and value of SMAPE.
3.1. Personal Factors
BFF stands for Big Five Factors where the five factors are Openness (O), Conscientiousness (C), Extraversion (E), Agreeableness (A), and Neuroticism (N). Each factors is measured as numerical numbers so that factors can be easily applied to training process. Table 1 shows BFF of participants. We can figure out personality of a person through these values. Person with high Openness is creative, emotional and interested in arts. Person with high Conscientiousness is responsible, achieving, and restraint. Person with high Agreeableness is agreeable to other person, altruistic, thoughtfulness and modesty. While person with high Neuroticism is sensitive to stress, impulsive, hostile and depressed. For example, as shown in Table 1, person 4 is creative, emotional, responsible, restraint. Also considering person 4’s Neuroticism, person 4 is not impulsive and resistant to stress. The personality shown in Table 1 will be used our experimental basis with other personal factors.

Table 1.
BFF of Participants.
In the Table 2, the number corresponding to the response is as follows:
Table 2.
Personal Factors: Person 1.
The highest level of education
- Middle school graduate
- High school graduate
- College graduate
- Master
- Doctor
Religion
- Atheism
- Christianity
- Catholic
- Buddhism
Salary
- Less than USD 500
- USD 500 to 1000
- USD 1000 to 2000
- USD 2000 to 3000
- over USD 3000
Method of transportation
- Walking
- Bicycle
- Car
- Public transport
Commute time
- Less than 30 min
- 30 min to 1 h
- 1 h to 2 h
- Over 2 h
The frequency of journey in one year
- Less than one time
- 2 to 3 times
- 4 to 5 times
- Over six times
Social media usage status (SNS1)
- Use
- Not use
Time spent on social media per day (SNS2)
- Less than 30 min
- 30 min to 1 h
- 1 h to 3 h
- Over 3 h
Category of personaly hobby
- Static activity
- Dynamic activity
- Both
In case of Person 1, high school graduate, no religion, income in USD 500 to 1000, public transport, commute in 1 to 2 h, two or three travels per year, 1 to 3 h spent for social media per day, and both dynamic and static hobby. Static activity has examples of movie and play watching, reading a book and so on while dynamic activity has examples of sports, food tour, and so on.
3.2. Location Category Data
SWARM application is used to collect geo-positioning data installed on smartphones [24]. Users actively check in visited places with SWARM. These actively collected location data are used as part of our analysis. The location data is in a form of location such as restaurant, home, bus stop and so on and timestamp for a specific person. Volunteers collected their own location visiting data by their own smartphones. The location category data was used as label (target data) for the supervised learning such as Random Forest, XGBoost and Stacking. The location category data is checked in to the visiting places using the SWARM application. Afterwards, the number of visits and visiting places were identified from web page of SWARM. Part of the location data of person 16 is shown in the Table 3.
Table 3.
Sample Location Data: Person 16.
The data collected were classified into 10 categories. Table 4 shows the classification of person 16’s location data into a category.
Table 4.
Sample Categorized Location Data: Person 16.
To input categorized location data to machine learning models, visiting ratio of location categories are used as labels. The Formula (1) is as follows.
3.3. Hyperparameter Search Space
Table 5 shows hyperparameter search space for this research. For example, booster of XGBoost stands for base model, which is either of ‘gblinear’, ‘gbtree’ or ‘dart’. Tree based model are dart and gbtree, but gblinear is based on linear function. The ‘dart’ has additional dropout for deep learning model. In case of tree based models, additional parameters such as min_sample_leaf and min_sample_split are also introduced. Of course, these hyperparameters must be set as adequate values in order to prune the overfitting. In this research, these values are not set since we have relatively smaller number of data and minute hyperparameters, which are found to be less effective for accuracy, were left as default values.
Table 5.
Hyperparameter Search Space.
3.4. Symmetric Mean Absolute Percentage Error
We used SMAPE as an accuracy measure. SMAPE is an abbreviation for Symmetric Mean Absolute Percentage Error. It is an alternative to Mean Absolute Percent Error when there are zero or near-zero demand for items [25,26,27]. SMAPE by itself limits to error rate of 200%, reducing the influence of these low volume items. It is usually defined as Formula (2) where is the actual value and is the forecast value. The Formula (2) provides a result between 0% and 200%. However, Formula (3) is often used in practice since a percentage error between 0% and 100% is much easier to interpret, and we also use the formula.
4. Analysis of Results
We will show experimental result in this section mainly in forms of tables and graphs. Table 6 shows selected features according to learning model and the corresponding prediction accuracy for each location category. Prediction accuracy is represented as 100% minus SMAPE. Random Forest and Stacking uses the same set of feature since feature selection was done with Random Forest. The abbreviations for each machine learning algorithm is as follows:
Table 6.
Results of Feature Selection.
- RF: Random Forest
- XGB: XGBoost
- STK: Stacking
From the results, of course, selected features from Random Forest and XGBoost are overlapped but not in total. This is due to the purpose of learning between these two models. From the view of big data, feature selection can reduce noise and reduces the effect of overfitting with increased accuracy.
However, Figure 1 and Figure 2 shows that the accuracy is a little bit degraded. This is maybe due to the restricted size and nature of data used in this experiments. In case of XGBoost, prediction accuracy is increased for location categories such as foreign institutions, hospital or location categories with various subcategories. We found that foreign institutions and hospital has inherently small number of data, and location categories with various subcategories which aggregate various, nonrelated nature of subcategories.
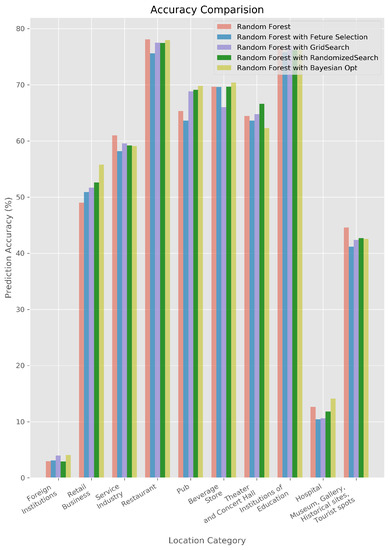
Figure 1.
Accuracy Graph of Random Forest.
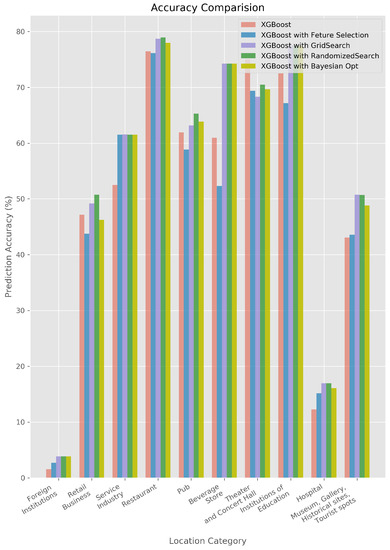
Figure 2.
Accuracy Graph of XGBoost.
In addition, Figure 3 shows that Stacking with feature selection resulted in high prediction accuracy. Maybe aggregation of five different models of Stacking reduces noise of data. In case of foreign institutions and hospital which has very small number of visit, five different models may lead to low accuracy in level 1 of Stacking and the aggregated results lead to low accuracy. It is notable that several of BFF were always included in selected features. It is proven that personality is highly related with visiting places.
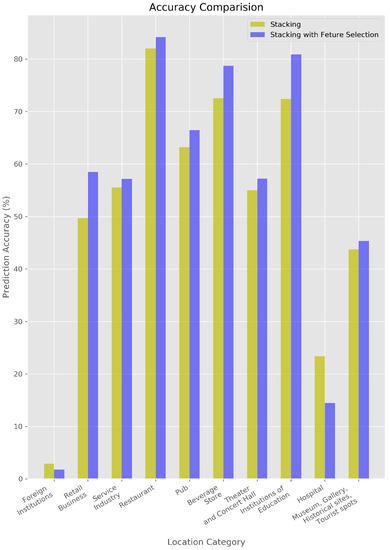
Figure 3.
Accuracy Graph of Stacking.
Table 7 shows the results numerically: hyperparameter optimization and prediction accuracy. In Table 7, hyperparameter value of RF are chosen as n_estimators, max_depth, bootstrap, respectively and in case of XGB, n_estimators, max_depth, learning_rate, booster are shown. It is notable that feature selection leads to accuracy decrease however prediction accuracy can be increased with hyperparameter optimization. For most of Random Forest optimization, bootstrap is used for the most of location categories. Bootstrap is useful for smaller number of input data. In addition, different method of optimization for the same location categories leads to similar value of max_depth or n_estimators. Interestingly, different hyperparameters can lead to similar accuracy. Maybe the big structure generated in the leaning process by Random Forest and XGBoost enables convergence of accuracy. Especially, XGB is highly dependent on the selection of booster. It is important to select adequate booster for XGB. In addition, selection of number of iteration for bayesian optimization is also important. In case of theater and concert hall, low number of iteration for bayesian optimization leads to booster of ‘gblinear’. And the accuracy is reduced in 20% comparing to that of grid search or random search. Linear function of ’gblinear’ shows big gap in accuracy comparing to ‘gbtree’ and ‘dart’ which is based on tree structure. In addition, extra number of iteration leads to low prediction accuracy due to overfitting. We concluded that the number of iteration is in the range of 50 to 60.
Table 7.
Optimized Hyperparameters.
As predicted, execution time for three different optimization is quite different. Table 8 shows execution time with hyperparameter optimization. Figure 4 is for RF and Figure 5 is for XGB, respectively. Even though grid search and random search shows similar performance, however, there is big difference in execution time. In addition, bayesian optimization is a little bit slower than random search but quite faster than grid search. We guess bayesian search is the choice due to the balance of execution time and performance. As well, prior knowledge is reflected in bayesian optimization.
Table 8.
Hyperparameter Optimization Execution Time.
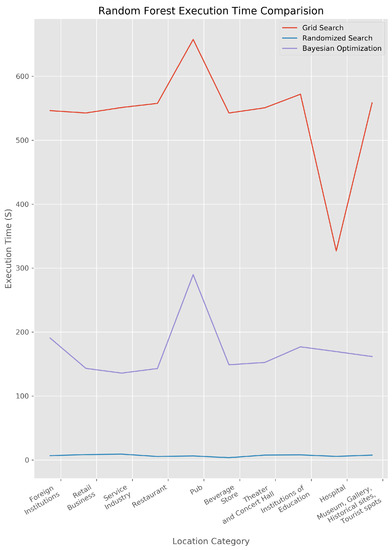
Figure 4.
Execution Time Graph of Random Forest.

Figure 5.
Execution Time Graph of XGBoost.
The total representation of accuracy of three different models can be found in Table 9, Table 10 and Table 11. Figure 1, Figure 2 and Figure 3 aforementioned shows the accuracy of each experimental condition. For the Stacking, hyperparameter optimization cannot be made due to the nature of Stacking, meta learning. Once hyperparameter optimization is applied to Stacking, every model in level 1 of Stacking must contain hyperparameter optimization which will result in drastic increase of execution time. Actually, Stacking with feature selection shows the prediction accuracy as high as RF and XGB with hyperparameter optimization. Figure 6 shows prediction accuracy for each location category. The cases of foreign institutions and hospital are somewhat incredible due to low accuracy, and due to smaller number of raw data. For other location categories, prediction accuracy is in the range of 50% to 80%. As aforementioned, too various subcategories shows somewhat low accuracy while ramification of subcategories could lead to higher prediction accuracy. For instance, distinct location categories such as restaurant, pub, beverage store, theater and concert hall show high accuracy.
Table 9.
Accuracy of Random Forest.
Table 10.
Accuracy of XGBoost.
Table 11.
Accuracy of Stacking.
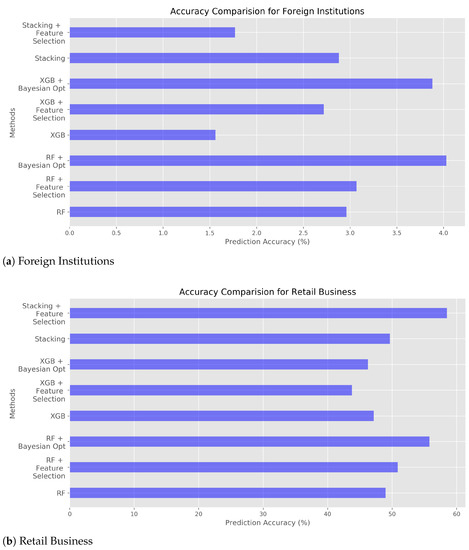
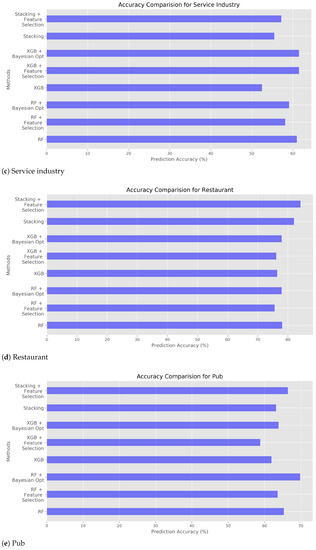
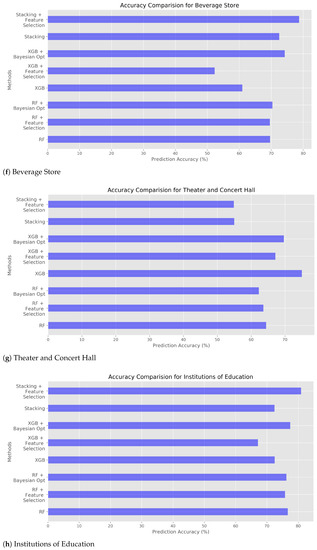
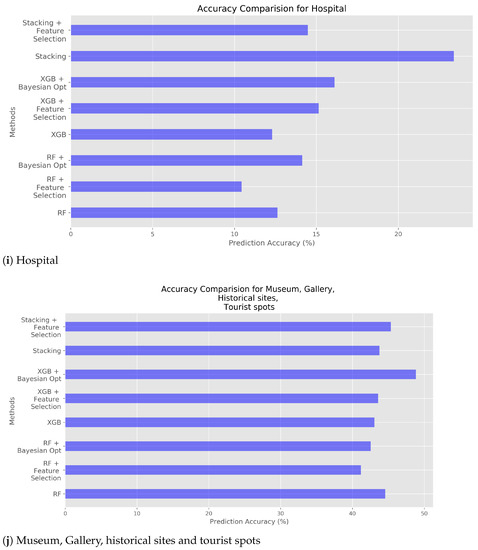
Figure 6.
Predict Accuracy Comparison of all methods.
5. Conclusions and Future Works
Location Based Service (LBS) and recommendation system are typical examples of personalized service. For example, contents providers such as Netflix opened a competition for recommendation system development. However, recommendation systems have cold start problem which makes recommendation difficult for the new users or new contents. In addition, personal information protection of history is another sort of problem. It could be possible if we can predict user preference based on basic user features regardless of history. From various research, it is discussed that human personality and location preference is highly related. Additionally, personal features other than personality also related with preference of location visiting. Of course, there are meaningful, distinguished personal features for personal location preference.
In this research, from three different methods of machine learning, we figured out the effects of distinguished personal features for personal location preference. As a result, eight location categories out of ten showed meaningful prediction accuracy: Retail Business, Service industry, Restaurant, Pub, Beverage Store, Theater and Concert Hall, Institutions of Education, and Museum, Gallery, Historical sites, Tourist spots. For each of three algorithms, prediction accuracy seem to be reliable with very similar tendency of analysis results. As well, input features were selected which affects location category selection with Random Forest and XGBoost, and of course, input features are dependent on location categories. Based on our research, visiting preference to such location categories can be highly predictable from personal features. In addition, hyperparameter optimization which is a sort of AutoML technology is introduced in order to increase prediction accuracy. Grid search, random search as well as bayesian optimization are applied and the results are compared.
In our research, we demonstrated a method for visiting place prediction. For large amount of input data, feature selection is applied in order to reduce dimension of data and increase quality of input data. In such cases, Stacking could be one of the best solution even without hyperparameter optimization. On the contrary, for smaller number of input data, bagging or boosting in addition with hyperparameter optimization could be a better solution since Stacking may show poor prediction accuracy. We need to research further, especially for location categories such as service industry, retail business since too many subcategories make the categorization vague. In addition, less sensitive personal features must exists for the prediction of visiting location. Such features will be able to be identified. From the aspect of volunteers’ data, we need to expand data collection for more number of data as well as wider span of data, since our data is clear limitations of volunteer pool; engineering students in his or her twenties.
Author Contributions
Conceptualization, H.Y.S.; methodology, Y.M.K.; software, Y.M.K.; validation, H.Y.S.; formal analysis, Y.M.K.; investigation, H.Y.S.; resources, H.Y.S.; data curation, Y.M.K.; writing—original draft preparation, Y.M.K.; writing—review and editing, H.Y.S.; visualization, Y.M.K.; supervision, H.Y.S.; project administration, H.Y.S.; funding acquisition, H.Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MEST) (NRF-2019R1F1A1056123).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Song, H.Y.; Lee, E.B. An analysis of the relationship between human personality and favored location. In Proceedings of the AFIN 2015, The Seventh International Conference on Advances in Future Internet, Venice, Italy, 23–28 August 2015; p. 12. [Google Scholar]
- Song, H.Y.; Kang, H.B. Analysis of Relationship Between Personality and Favorite Places with Poisson Regression Analysis. ITM Web Conf. 2018, 16, 02001. [Google Scholar] [CrossRef][Green Version]
- Kim, S.Y.; Song, H.Y. Determination coefficient analysis between personality and location using regression. In Proceedings of the International Conference on Sciences, Engineering and Technology Innovations, ICSETI, Bali, India, 22 May 2015; pp. 265–274. [Google Scholar]
- Kim, S.Y.; Song, H.Y. Predicting Human Location Based on Human Personality. In International Conference on Next Generation Wired/Wireless Networking, Proceedings of the NEW2AN 2014: Internet of Things, Smart Spaces, and Next Generation Networks and Systems, St. Petersburg, Russia, 27–29 August 2014; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 70–81. [Google Scholar] [CrossRef]
- Kim, Y.M.; Song, H.Y. Analysis of Relationship between Personal Factors and Visiting Places using Random Forest Technique. In Proceedings of the Federated Conference on Computer Science and Information Systems (FedCSIS), Leipzig, Germany, 1–4 September 2019; pp. 725–732. [Google Scholar]
- Song, H.Y.; Yun, J. Analysis of the Correlation Between Personal Factors and Visiting Locations With Boosting Technique. In Proceedings of the Federated Conference on Computer Science and Information Systems (FedCSIS), Leipzig, Germany, 1–4 September 2019; pp. 743–746. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Bennett, J.; Lanning, S. The netflix prize. In Proceedings of the KDD Cup and Workshop; Citeseer: New York, NY, USA, 2007; Volume 2007, p. 35. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression. UCSF: Center for Bioinformatics and Molecular Biostatistics. 2004. Available online: https://escholarship.org/uc/item/35x3v9t4 (accessed on 27 June 2021).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Costa, P.T.; McCrae, R.R. Four ways five factors are basic. Personal. Individ. Differ. 1992, 13, 653–665. [Google Scholar] [CrossRef]
- Hoseinifar, J.; Siedkalan, M.M.; Zirak, S.R.; Nowrozi, M.; Shaker, A.; Meamar, E.; Ghaderi, E. An Investigation of The Relation Between Creativity and Five Factors of Personality In Students. Procedia Soc. Behav. Sci. 2011, 30, 2037–2041. [Google Scholar] [CrossRef]
- Jani, D.; Jang, J.H.; Hwang, Y.H. Big five factors of personality and tourists’ Internet search behavior. Asia Pac. J. Tour. Res. 2014, 19, 600–615. [Google Scholar] [CrossRef]
- Jani, D.; Han, H. Personality, social comparison, consumption emotions, satisfaction, and behavioral intentions. Int. J. Contemp. Hosp. Manag. 2013, 25, 970–993. [Google Scholar] [CrossRef]
- John, O.P.; Srivastava, S. The Big Five trait taxonomy: History, measurement, and theoretical perspectives. In Handbook of Personality: Theory and Research; University of California: Berkeley, CA, USA, 1999; Volume 2, pp. 102–138. [Google Scholar]
- Amichai-Hamburger, Y.; Vinitzky, G. Social network use and personality. Comput. Hum. Behav. 2010, 26, 1289–1295. [Google Scholar] [CrossRef]
- Chorley, M.J.; Whitaker, R.M.; Allen, S.M. Personality and location-based social networks. Comput. Hum. Behav. 2015, 46, 45–56. [Google Scholar] [CrossRef]
- Foursquare Labs, Inc. Swarm App. 2019. Available online: https://www.swarmapp.com/ (accessed on 27 June 2021).
- Armstrong, J.S. Long-Range Forecasting; Wiley New York ETC.: New York, NY, USA, 1985. [Google Scholar]
- Flores, B.E. A pragmatic view of accuracy measurement in forecasting. Omega 1986, 14, 93–98. [Google Scholar] [CrossRef]
- Tofallis, C. A better measure of relative prediction accuracy for model selection and model estimation. J. Oper. Res. Soc. 2015, 66, 1352–1362. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).