
A Personalized Machine-Learning-Enabled Method for Efficient Research in Ethnopharmacology. The Case of the Southern Balkans and the Coastal Zone of Asia Minor

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
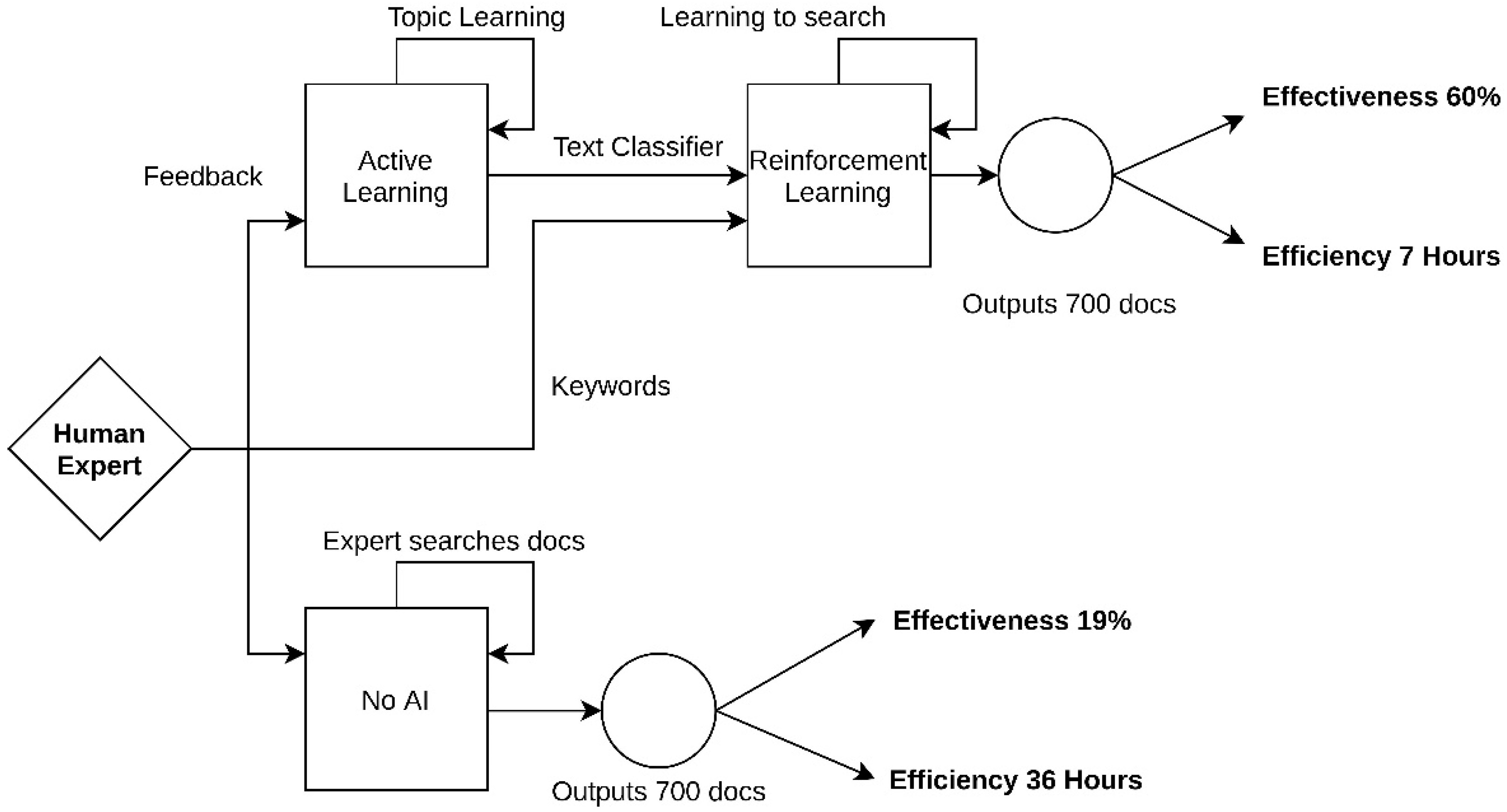
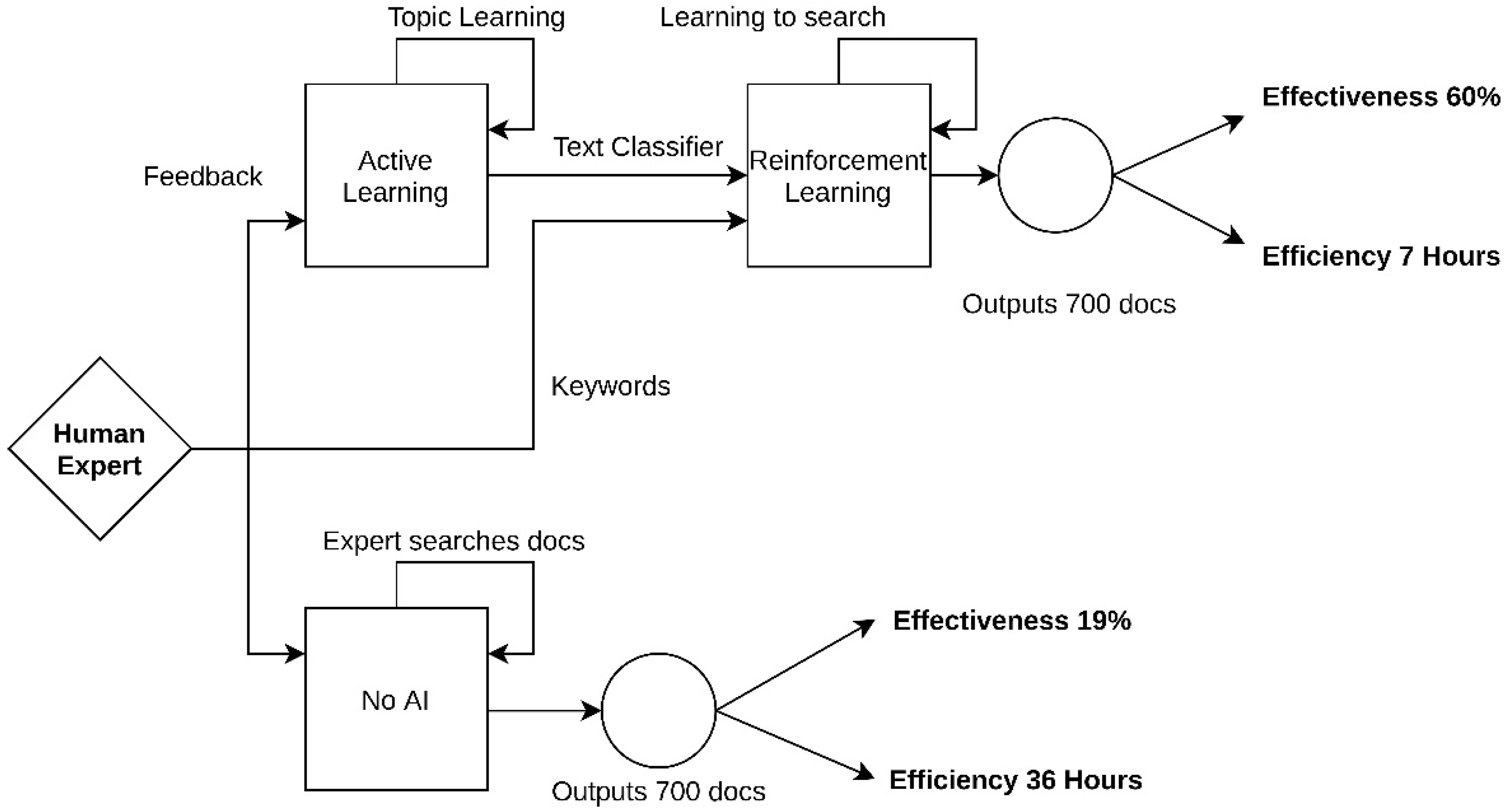
2.1. Method Overview
2.2. Defining the Relevant Topics
2.3. Dataset
2.4. Using Active Learning to Infer Expert Interest
2.5. Reinforcement Learning
3. Results
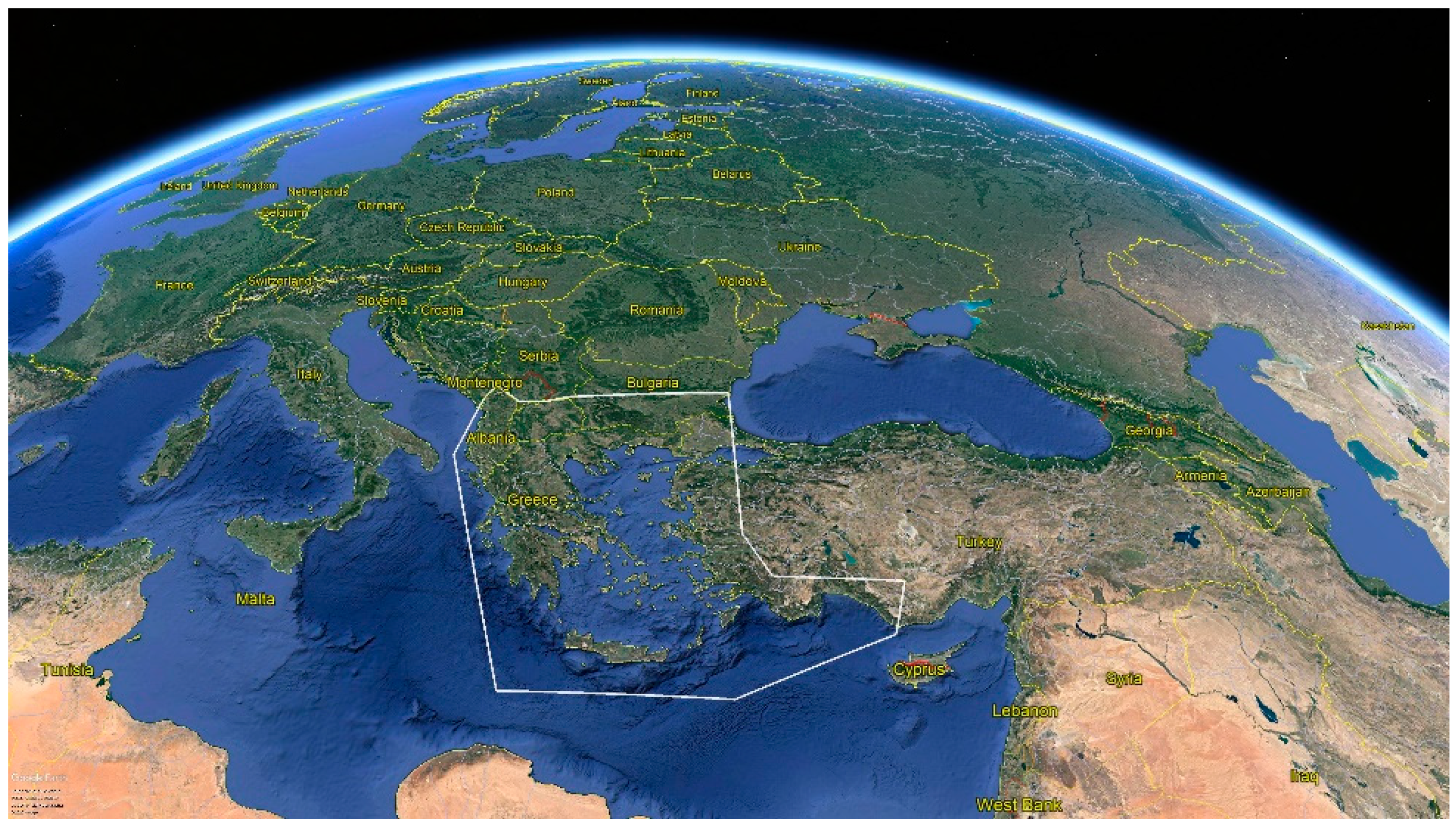
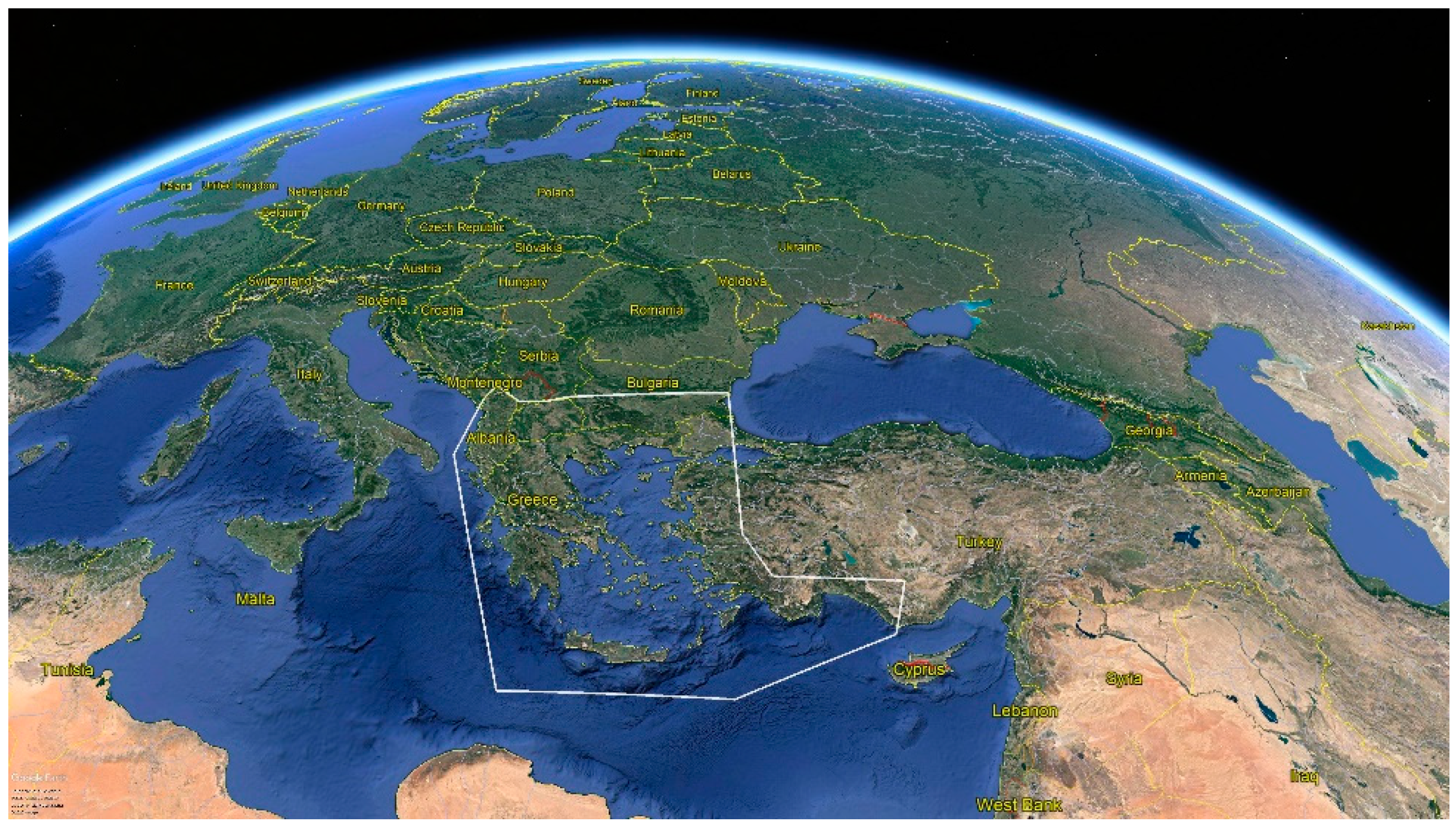
3.1. Ethnopharmacological Inference
3.2. Crawling Results
- -
- in the first 25 documents, we had approximately 850 references to visit;
- -
- in the first 700 fetched documents, the identified references were approximately 10,000.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heinrich, M.; Jäger, A.K. Ethnopharmacology; John Wiley & Sons: Chichester, UK, 2015. [Google Scholar]
- Lukman, S.; He, Y.; Hui, S.-C. Computational methods for Traditional Chinese Medicine: A survey. Comput. Methods Programs Biomed. 2007, 88, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Quave, C.L.; Pardo-De-Santayana, M.; Pieroni, A. Medical ethnobotany in Europe: From field ethnography to a more culturally sensitive evidence-based cam? Evid.-Based Complement. Altern. Med. 2012, 2012, 156846. [Google Scholar] [CrossRef] [PubMed]
- Chakrabarti, S.; Van den Berg, M.; Dom, B. Focused crawling: A new approach to topic-specific Web resource discovery. Comput. Netw. 1999, 31, 1623–1640. [Google Scholar] [CrossRef] [Green Version]
- Yadong, Z.; Kongfa, H.; Tao, Y. Mining effect of Famous Chinese Medicine Doctors on Lung-cancer based on Association rules. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 2036–2040. [Google Scholar]
- Naseem, U.; Khushi, M.; Khan, S.K.; Shaukat, K.; Moni, M.A. A Comparative Analysis of Active Learning for Biomedical Text Mining. Appl. Syst. Innov. 2021, 4, 23. [Google Scholar] [CrossRef]
- Chen, Y.; Mani, S.; Xu, H. Applying active learning to assertion classification of concepts in clinical text. J. Biomed. Inform. 2012, 45, 265–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Chapman & Hall/CRC: London, UK, 1989. [Google Scholar]
- Flora of Greece. Vascular Plant Checklist of Greece. Available online: http://portal.cybertaxonomy.org/flora-greece/ (accessed on 16 June 2021).
- GitLab Repository. Available online: https://gitlab.com/andr_kontog/seed_urls/-/blob/main/seeds_25.txt (accessed on 16 June 2021).
- Arstein, R. Inter-annotator Agreement. In Handbook of Linguistic Annotation; Pustejovsky, J., Ed.; Springer: Dordrecht, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Biomedical Natural Language Processing Tools and Resources. Available online: https://bio.nlplab.org/ (accessed on 16 June 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Han, M.; Wuillemin, P.-H.; Senellart, P. Focused Crawling Through Reinforcement Learning. In Web Engineering. ICWE. Lecture Notes in Computer Science; Mikkonen, T., Klamma, R., Hernández, J., Eds.; Springer: Cham, Switzerland, 2018; Volume 10845. [Google Scholar] [CrossRef] [Green Version]
- Souid, A.; Sakli, N.; Sakli, H. Classification and Predictions of Lung Diseases from Chest X-rays Using MobileNet V2. Appl. Sci. 2021, 11, 2751. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Python Software Foundation. Python Language Reference, Version 3. Available online: https://www.python.org/ (accessed on 16 June 2021).
- Chollet, F. Keras Github. 2015. Available online: https://github.com/fchollet/keras (accessed on 16 June 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th $USENIX$ Symposium on Operating Systems Design and Implementation ($OSDI$16), Savannah, GA, USA, 2–4 November 2016; Version 2. pp. 265–283. Available online: https://www.tensorflow.org/ (accessed on 16 June 2021).
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, L. Openai gym. arXiv 2016, Preprint. arXiv:1606.01540. Available online: http://gym.openai.com/ (accessed on 16 June 2021).
- Pubmed [Internet]. Bethesda (MD): National Library of Medicine (US). Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 16 June 2021).
- Medline [Internet]. Bethesda (MD): National Library of Medicine (US). Available online: https://www.nlm.nih.gov/medline/medline_overview.html (accessed on 16 June 2021).
- Titipat Achakulvisut.Titpata Python Parser. 2020. Available online: https://github.com/titipata/pubmed_parser (accessed on 16 June 2021).
- Pieroni, A. Local plant resources in the ethnobotany of Theth, a village in the Northern Albanian Alps. Genet. Resour. Crop. Evol. 2008, 55, 1197–1214. [Google Scholar] [CrossRef]
- Miskoska-Milevska, E.; Stamatoska, A.; Jordanovska, S. Traditional uses of wild edible plants in the Republic of North Macedonia. Phytol. Balc. 2020, 26, 155–162. [Google Scholar]
- Ivanova, T.A.; Bosseva, Y.Z.; Ganeva-Raycheva, V.G.; Dimitrova, D. Ethnobotanical knowledge on edible plants used in zelnik pastries from Haskovo province (Southeast Bulgaria). Phytol. Balc. 2018, 24, 389–395. [Google Scholar]
- Vokou, D.; Katradi, K.; Kokkini, S. Ethnobotanical survey of Zagori (Epirus, Greece), a renowned centre of folk medicine in the past. J. Ethnopharmacol. 1993, 39, 187–196. [Google Scholar] [CrossRef]
- Axiotis, E.; Halabalaki, M.; Skaltsounis, L.A. An ethnobotanical study of medicinal plants in the Greek islands of North Aegean Region. Front. Pharmacol. 2018, 9, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Tsioutsiou, E.E.; Giordani, P.; Hanlidou, E.; Biagi, M.; De Feo, V.; Cornara, L. Ethnobotanical Study of Medicinal Plants Used in Central Macedonia, Greece. Evid.-Based Complement. Altern. Med. 2019, 2019, 4513792. [Google Scholar] [CrossRef] [PubMed]
- Ugulu, I.; Baslar, S.; Yorek, N.; Dogan, Y. The investigation and quantitative ethnobotanical evaluation of medicinal plants used around Izmir province, Turkey. J. Med. Plants Res. 2009, 3, 345–367. [Google Scholar] [CrossRef]
- Kargıoğlu, M.; Cenkci, S.; Serteser, A.; Konuk, M.; Vural, G. Traditional uses of wild plants in the middle Aegean region of Turkey. Hum. Ecol. 2010, 38, 429–450. [Google Scholar] [CrossRef]
- Polat, R.; Satıl, F. An ethnobotanical survey of medicinal plants in Edremit Gulf (Balikesir-Turkey). J. Ethnopharmacol. 2012, 139, 626–641. [Google Scholar] [CrossRef] [PubMed]
- Ballinger, P. Definition Dilemmas: Southeastern Europe as a «Culture Area»? Balkanologie 1999, III, 2. [Google Scholar] [CrossRef]
- Carter, F.W. An Historical Geography of the Balkans; Academic Press: New York, NY, USA, 1977; p. 580. [Google Scholar]
- Legakis, A.; Constantinidis, T.; Petrakis, P.V. Biodiversity in Greece. In Global Biodiversity; Apple Academic Press: Boca Raton, FL, USA, 2018. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, Z.; Li, L.; Lu, K.; Liu, R.; Liu, Z.; Yan, J. An Ontology-Based Artificial Intelligence Model for Medicine Side-Effect Prediction: Taking Traditional Chinese Medicine as an Example. Comput. Math. Methods Med. 2019, 2019, 8617503. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Plant Families | Part of Plant Used | Uses/Recipes | MeSH Terms | Geographical Regions |
|---|---|---|---|---|
| Alliaceae | Aerial Part | Decoction | Greek ethnopharmacology | Albania |
| Anacardiaceae | Flower | Infusion | Traditional greek medicine | FYROM or Northern Macedonia |
| Apiaceae | Chalices of flowers | Maceration | Natural product | Bulgaria (southern) |
| Asparagaceae | Seed | Powder | Medicinal plant | Greece |
| Asphodelaceae | Leaf | Juice | Plant extracts | coastal zone of Turkey or Asia Minor |
| Asteraceae | Fruit | Poultice | Pharmacological action | |
| Boraginaceae | Stem | tsp of oil | Disease | |
| Brassicaceae | Bark | Paste | Treatment | |
| Cactaceae | Root | Whole plant preparation | Antimicrobial activity | |
| Cannabaceae | Clove | Cook | Radical scavenging activity | |
| Capparaceae | Stigma | Raw | Antioxidant activity | |
| Cistaceae | Bulb | Milk | Ethnobotany | |
| Fabaceae | Foliage | Solvent/adjuvant used | Pharmacognosy | |
| Fagaceae | Shoot | Honey | Herbal medicine | |
| Gentianaceae | Branch | Wine/Water | Greek folk medicine | |
| Hypericaceae | Whole Plant | Filtrate | Home remedies | |
| Lamiaceae | Wooden | Pounded | Folk remedies | |
| Liliaceae | Kernel | Extract | Materia medica | |
| Malvaceae | Fiber | Dried | Phytotherapy | |
| Moraceae | Rhizome | Fresh | Southern Balkans | |
| Myrtaceae | Ground plant | Soup | Balkans | |
| Oleaceae | Petioles | Soaked in | Albanian ethnopharmacology | |
| Paeoniaceae | Stem bark | Milled | Bulgarian ethnopharmacology | |
| Platanaceae | Tuberous root | Mixed with | Southern Bulgary ethnopharmacology | |
| Rosaceae | Styles | Warm and smoke | FYROM ethnopharmacology | |
| Salicaceae | Latex | Chew | Northern Macedonia ethnopharmacology | |
| Scrophulariaceae | Gum | Swallow | Turkish ethnopharmacology | |
| Solanaceae | Peels | Bake | Turkish coastal zone ethnopharmacology |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Axiotis, E.; Kontogiannis, A.; Kalpoutzakis, E.; Giannakopoulos, G. A Personalized Machine-Learning-Enabled Method for Efficient Research in Ethnopharmacology. The Case of the Southern Balkans and the Coastal Zone of Asia Minor. Appl. Sci. 2021, 11, 5826. https://doi.org/10.3390/app11135826
Axiotis E, Kontogiannis A, Kalpoutzakis E, Giannakopoulos G. A Personalized Machine-Learning-Enabled Method for Efficient Research in Ethnopharmacology. The Case of the Southern Balkans and the Coastal Zone of Asia Minor. Applied Sciences. 2021; 11(13):5826. https://doi.org/10.3390/app11135826
Chicago/Turabian StyleAxiotis, Evangelos, Andreas Kontogiannis, Eleftherios Kalpoutzakis, and George Giannakopoulos. 2021. "A Personalized Machine-Learning-Enabled Method for Efficient Research in Ethnopharmacology. The Case of the Southern Balkans and the Coastal Zone of Asia Minor" Applied Sciences 11, no. 13: 5826. https://doi.org/10.3390/app11135826
APA StyleAxiotis, E., Kontogiannis, A., Kalpoutzakis, E., & Giannakopoulos, G. (2021). A Personalized Machine-Learning-Enabled Method for Efficient Research in Ethnopharmacology. The Case of the Southern Balkans and the Coastal Zone of Asia Minor. Applied Sciences, 11(13), 5826. https://doi.org/10.3390/app11135826