1. Introduction
With the rapid development of the mobile Internet and the Internet of things in recent years, the functions of the mobile terminals (MTs) are becoming much more rich than ever before. The character of mobile terminals has gradually evolved from a simple communication tool to a powerful station integrating communication, computing, entertainment and office. Various applications, such as augmented reality, virtual reality, and location-based service (LBS), have been contained in one mobile terminal as required by the consumers. These typical applications with high computing complexity and long time delay sensitivity not only aggravate the load of the mobile cloud (C) in computing and storage resources, but they also lead to system network congestion and service quality decline.
In order to alleviate the computing load of the mobile cloud, the concept of Mobile Edge Computation (MEC) is proposed [
1], which provides the IT service environment and the cloud computing capability on the mobile network edge [
2]. By deploying the mobile edge computing-enabled base station (MEC-BS) of MTs in a community and the neighbor mobile edge computing-enabled base stations of the MEC-BS (MEC-NBS) on the edge of the mobile network, the computing can sink to the mobile edge node, which can effectively reduce the load of the mobile cloud and reduce the demand for the data transmission bandwidth.
In our research, we define the MEC stations consists of five units: (1) receiving unit: which is used to receive service requests from its covering MTs and the surrounding MEC stations; (2) control unit: which is used to determine whether the received task is further offloaded and whether cache the data required for the corresponding task from C based on the Cooperative Resource Management Algorithm; (3) caching unit: which is used to cache the data required for the corresponding task based on the Cooperative Resource Management Algorithm to reduce the time delay in data access to C; (4) computing unit: which is used to calculate the computing tasks offloading from its covering MTs; (5) sending unit: which is used to send the calculation result to the MT, send the offloading request to further MEC stations and send the data request of the corresponding task to C. It is worth noting that MEC stations have limited computation and storage resources, so that they cannot provide computing and caching services for all the tasks like C. However, the MEC-BS will be still overloaded if there are too many tasks offloaded from the MTs. In existing algorithms, they try to ease the load of MEC stations through refusing, delaying or queuing the offloading requests of MTs. However, these algorithms will lead to poor QoS of the system. Thus, a new model of resource management is urgently needed.
In this paper, our research is concerned with a local system under mobile cloud, which includes a mobile edge computing-enabled base station (MEC-BS), the mobile terminals covered by this MEC-BS, and the neighbor mobile edge computing-enabled base stations within a certain distance from MEC-BS. Our goal is to offload the mobile cloud computing and storage pressure through MEC stations. Because of the poor computing capability of every MTs, we ignore MT as a offloading object to guarantee the quality of service. All tasks of MT need to go through the MT’s MEC-BS to offload to mobile cloud or any neighbor mobile edge computing-enabled base station.
Figure 1 is the overall architecture of our model.
As shown in
Figure 1, the mobile edge computing can enhance the performance of multiple computation-intensive and delay-sensitive applications, such as virtual reality, augmented reality, pattern recognition, automatic pilot, intelligent transportation, video acceleration, video surveillance, smart home, indoor positioning, remote medical surgery, unmanned aerial vehicle control, online live and interaction, smart building, etc. The users can experience higher real-time performance of applications, and run more complex applications in their resource-constrained MTs. The steps for computing offloading and data caching under the mobile edge computing environments are as follows: (1) when MT has a new computing task, it will upload the offloading request (OL-REQ) to its MEC-BS; (2) if the task is determined to be executed in MEC-BS by the Cooperative Resource Management Algorithm and MEC-BS has cached data of the task, the task will be executed directly in MEC-BS, then the offloading response (OL-RSP) will be returned to MT; (3) if the task is determined to be executed in MEC-BS and there is no cached data in it, MEC-BS will send the data request (DA-REQ) of the task to C, then C will return the data response (DA-RSP) to MEC-BS. The next process of executing and delivering is the same as 2); (4) if the task is decided to be executed in MEC-NBS by the algorithm, MEC-BS will send the offloading request to a MEC-NBS. If MEC-NBS has cached the computing data before, it will execute the task and return the offloading response to MEC-BS, and then MEC-BS will return the offloading response to MT; (5) if MEC-NBS is decided to execute the task and it has not cached the computing data of the task in advance, it will send the data request to C, then C will return the data response to it. The next process of executing and delivering is the same as (4); (6) if the task is resolved to be offloaded to C by the algorithm, MEC-BS will send the offloading request to C, then C will execute the task and return the offloading response to MEC-BS, and then the offloading response will be returned to MT.
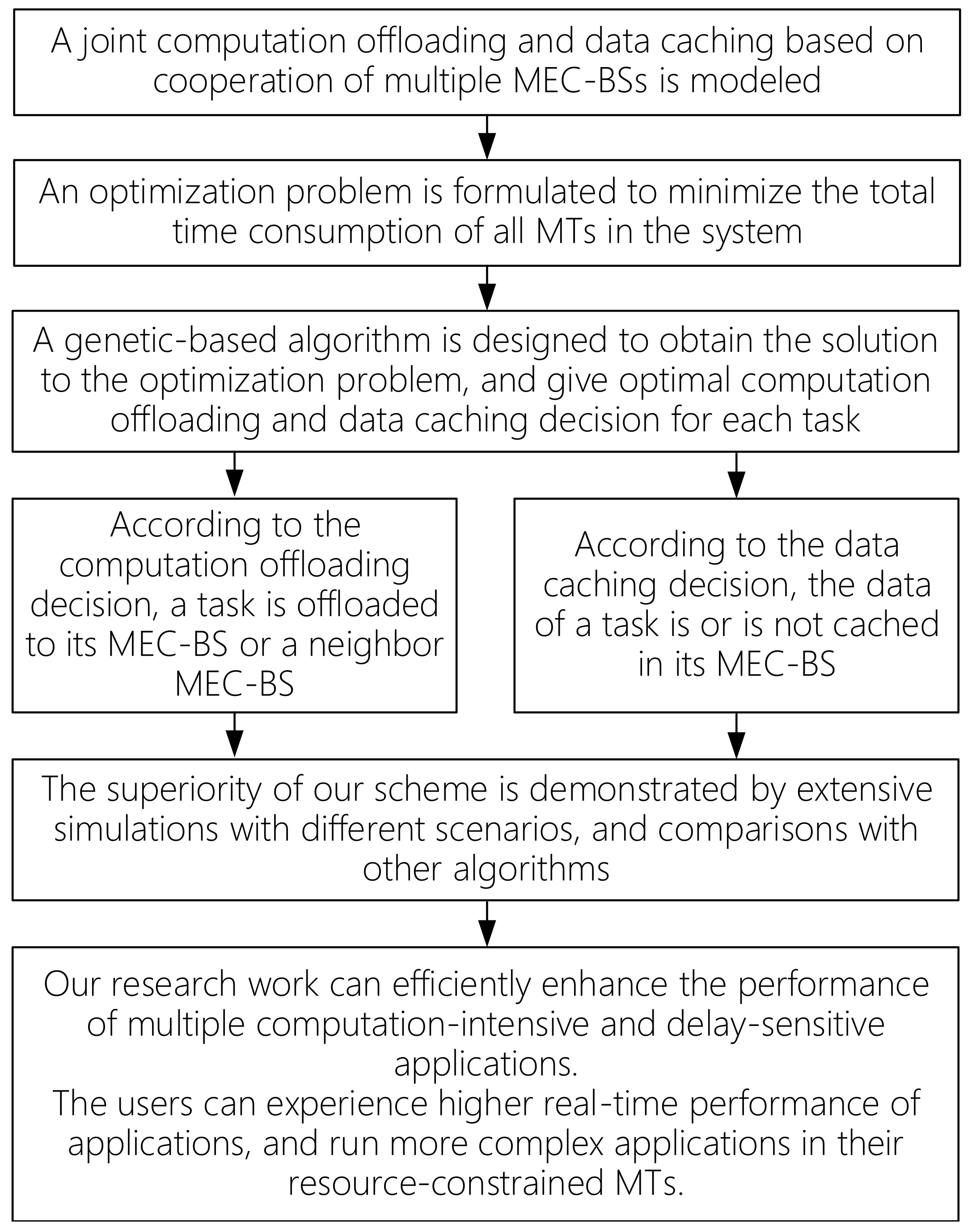
Our research work can be described briefly by a block diagram, as shown in
Figure 2.
3. System Model
We assume the number of all MTs and MEC-NBS is M and K, respectively. The ith () MT is defined as , and kth () MEC-NBS is defined as . An MT can run multiple mobile applications at the same time, and each application may contain multiple tasks. The number of all types of tasks is assumed to be R, the jth () type of tasks is defined as . Moreover, the data storage of MEC-BS and is defined as d and (), respectively.
We consider that the request from each MT is a Poisson process, and represents the request rate of , that is, tasks are generated by per second. The request ratio of to the task is (), and the proportion is different for different tasks. Note that because actually represents the proportion of in the tasks generated by .
We assume that the request message length and the response message length are fixed and roughly equal in the offloading signal transmission or data caching transmission among the MT, MEC-BS, MEC-NBS, and C. Each task is profiled by an ordered vector , which is characterized by: (1) , the amount of computation needed to complete ; (2) , the size of the offloading request (including necessary description and parameters of ) for ; (3) , the size of the offloading response (including the result of ’s execution) for ; (4) , the size of the data caching request (including necessary description and parameters of the data required to execute ) for ; (5) , the size of the data caching response (including the data required to execute ) for .
The computing task has 2 ways to completing: execute it at C or offload it to MEC stations. If task is determined to execute at C, it will increase the computing load of the mobile cloud and affect the performance of the cloud server. It will also suffer the offloading-signal transmission delay from the MT to the MEC-BS and the MEC-BS to C. If the MEC-BS chooses to offload to MEC stations, it will greatly alleviate the cloud pressure, and MEC stations have a certain degree of computational power, the efficiency of the computing task can also be guaranteed, but, at the same time, it may suffer from the time consumption caused by data request and response transmission between MEC stations and C. If the MEC-BS chooses to cache the data at MEC stations in advance, it will avoid the time consumption of the offloading-signal and data-signal transmission. However, data caching will take time, and MEC stations have limited storage space.
When is offloaded to MEC stations, it can be executed at MEC-BS, or be further offloaded to a MEC-NBS( the offloading probability of all the is equal). For task , we define the offloading probability from to MEC-BS as and from to as , so that the offloading probability from to C is . Moreover, we define the caching probability from C to MEC-BS as , from C to MEC-NBS as .
There are many symbols used by our system model, so we add notions to distinguish them. “O” means “Offloading”, “D” means “Data caching”, and “2” means “to”. For example, “ONBS2BS” expresses the symbol is related to the issue “computation Offloading from a MEC-NBS to the MEC-BS”. “DC2NBS” expresses the symbol is related to the issue “Data caching from the Cloud to a MEC-NBS”.
3.1. Computation Model
(1) Execution at C
All the tasks which executed at C share the computation resources of it.
By defining the service rate of C as
, if
is selected to be executed at C, the time consumed by completing
is
where the denominator is the stable processing speed [
35] (amount of computation processed per second) of C.
is the total amount of computation of C’s tasks executed per second which was determined to be offloaded to C. It can be observed that, with the increase of the tasks executed at C, the processing speed of C is decreasing. Note that
is the hard constraint [
35] of Formula (
3), which means the tasks’ arriving rate cannot exceed C’s service rate.
(2) Execution at MEC-BS
All the tasks which offloaded to a MEC-BS from C share the computation resources of the MEC-BS.
By defining the service rate of MEC-BS as
, if
is selected to be executed at MEC-BS, the time consumed by completing
is
where the denominator is the stable processing speed [
35] (amount of computation processed per second) of MEC-BS.
is the total amount of computation of MEC-BS’s tasks executed per second which was determined to be offloaded to MEC-BS. It can be observed that, with the increase of the tasks executed at the MEC-BS, the processing speed of MEC-BS is decreasing. Note that
is the hard constraint [
35] of Formula (
3), which means the tasks’ arriving rate cannot exceed MEC-BS’s service rate.
(3) Execution at MEC-NBS
All the tasks which offloaded to a MEC-NBS from C share the computation resources of the MEC-NBS.
By defining the service rate of
as
, if
is selected to be executed at
, the time consumed by completing
is
where the denominator is the stable processing speed [
35] (amount of computation processed per second) of
.
is the total amount of computation of
’s tasks executed per second which was determined to be offloaded to MEC-NBS. It can be observed that, with the increase of the tasks executed at the MEC-NBS, the processing speed of
is decreasing. Note that
is the hard constraint [
35] of Formula (
3), which means the tasks’ arriving rate cannot exceed
’s service rate.
3.2. Transmission Model
(1) Communications between C and MEC-BS
All the MEC stations, including MEC-BS and MEC-NBS, under a C’s coverage share the wireless resources of it. In this paper, the impacts of inter-station and intra-station interferences caused by computation offloading have been ignored because of the extremely tiny sizes of them. There are two types of communications between C and MEC-BS (offloading-signal transmission and data-signal transmission, respectively).
We define the data-signal transmission rate from MEC-BS to C as
. Then, the time consumed by sending the offloading request of
from MEC-BS to C can be defined as follows, if
is selected to be offloaded.
The data transmission rate from C to MEC-BS is denoted by
. Then, we have the time consumed by receiving the offloading response of
from C to MEC-BS:
As for data caching transmission, MEC-BS uses the Cooperative Resource Management Algorithm to determine the most profitable data caching which is required by task
, the time consumed by sending the data caching request of
from MEC-BS to C can be defined as follows:
Similarly, we have the time consumed by receiving the data caching response of
from C to MEC-BS:
(2) Communications between C and MEC-NBS
MEC-NBS can also use the Cooperative Resource Management Algorithm to determine the most profitable data caching which is required by task
. We define the data-signal transmission rate from
to C as
the time consumed by sending the data caching request of
from
to C can be defined as follows:
The data transmission rate from C to
is denoted by
. Then, we have the time consumed by receiving the data caching response of
from C to
:
(3) Communications between MEC-BS and MEC-NBS
For the sake of data security, we assume that data-signal cannot be transmitted between the MEC stations, including MEC-BS and MEC-NBS. Accordingly, there is only one type of communications between MEC-BS and , which is the offloading-signal transmission. We define the offloading-signal transmission rate from MEC-BS to through the wired connection between them as . Reversely, represents the offloading-signal transmission rate from to MEC-BS through the connection.
The time consumed by transmitting the offloading request of
from MEC-BS to
is expressed as
Similarly, the time consumed by transmitting the offloading response of
from
to MEC-BS is expressed as
(4) Communications between MEC-BS and MTs
All the MTs under a MEC-BS’s coverage share the wireless resources of it. In this paper, we ignore the computing power of every MTs, so that there is only one type of communications between MTs and MEC-BS which is the offloading-signal data transmission.
We define the uplink data transmission rate from
to MEC-BS as
. Then, the time consumed by sending the offloading request of
from
to MEC-BS can be defined as follows, if
is selected to be offloaded.
The downlink data transmission rate from MEC-BS to
is denoted by
. Then, we have the time consumed by receiving the offloading response of
from MEC-BS to
:
3.3. Optimization Model
The total time consumption for completing includes: (1) the time consumed by executing in the mobile cloud, if is selected to be executed at C; (2) the time consumed by computation offloading, if is selected to be offloaded to MEC-BS; (3) the time consumed by computation offloading, if is selected to be further offloaded to .
In (1), the time consumption is generated by transmitting the offloading request of from to MEC-BS, transmitting the offloading request of from MEC-BS to C, executing at C, transmitting the offloading response of from C to MEC-BS, and transmitting the offloading response of from MEC-BS to , that is, .
In (2), the time consumption needs to be divided into two situations: (1) MEC-BS has the data caching required by task ; (2) MEC-BS does not have the data caching required by task , and it needs to send the data caching request to C to get the data. The two cases are discussed separately as follows:
(1) The time consumption is generated by transmitting the offloading request of from to MEC-BS, executing at MEC-BS, and transmitting the offloading response of from MEC-BS to , that is, .
(2) The time consumption is generated by transmitting the offloading request of from to MEC-BS, transmitting the data caching request of from MEC-BS to C, transmitting the data caching response of from C to MEC-BS, executing at MEC-BS, and transmitting the offloading response of from MEC-BS to , that is, .
In (3), the time consumption needs to be divided into two situations: (1) has the data caching required by task ; (2) does not have the data caching required by task , and it needs to send the data caching request to C to get the data. The two cases are discussed separately as follows:
(1) The time consumption is generated by transmitting the offloading request of from to MEC-BS, transmitting the offloading request of from MEC-BS to , executing at , transmitting the offloading response of from to MEC-BS, and transmitting the offloading response of from MEC-BS to , that is, .
(2) The time consumption is generated by transmitting the offloading request of from to MEC-BS, transmitting the offloading request of from MEC-BS to , transmitting the data caching request of from to C, transmitting the data caching response of from C to , executing at , transmitting the offloading response of from to , and transmitting the offloading response of from MEC-BS to , that is, .
In summary, we have the total time consumption for completing
:
Therefore, the total time consumption of all MTs covered by MEC-BS can be formulated as
t:
4. Cooperative Resource Management Algorithm
4.1. Optimization Problem
The aim of our algorithm is to minimize the total time consumption
t gained by all MTs in
, while ensuring all constraints are not violated. Thus, the corresponding optimization problem can be formulated as
where constraint (
17) is the value range of each
, constraint (
18) is the value range of each
, constraint (
20) is the value range of each
, and constraint (
21) is the value range of each
. As aforementioned, Constraint (
19) is the value range of the total probability that
is offloaded from C. Constraint (
22)–(
24) is hard constraint of the offloading queuing systems of C, MEC-BS, and
, respectively. Constraint (
25) and (
26) is hard constraint of the caching queuing systems of MEC-BS and
, respectively.
We define the total time consumption without computation offloading and data caching as
, and we expand
as
We can come to this conclusion that the sufficient condition of
is that
must hold. By comparing the condition with constraint (
22), we have
Thus, constraint (
22) always holds.
4.2. Optimization Algorithm Using Genetic algorithm
To determine the feasible domain of the problem, we transform all the independent variables into one-dimensional column vectors and combine them into a whole one-dimensional column vector. Thus, is converted to a vector . Similarly, = , = , = . So, we can combine them into in order of , where H is the feasible region of the problem.
In combination with (
16) and constraints above, we derive the convexity and concavity of (
16). By splitting (
16) and judging the positive definiteness of each part of Hessian matrix, we obtain that (
16) is a non-convex and non-concave function due to the existence of several saddle points. Therefore, if we use the traditional numerical optimization algorithm (such as interior point method) to get the optimal solution of (
16), it is easy to fall into local minimum. The “dead cycle” phenomenon occurs because of the minimal part trap, which makes the iteration impossible, and only the local optimal solution is obtained instead of global optimal solution.
Genetic algorithm overcomes this shortcoming very well, which is a global optimization algorithm. Due to the evolutionary characteristics of genetic algorithm, the intrinsic properties of the optimization problem in the process of searching element have little effect on the final optimization result. Moreover, the ergodicity of the evolutionary operator of genetic algorithm makes it very effective to search element with probabilistic global significance, which matches the optimization object and optimization goal of our paper very well.
In addition, compared with the accurate algorithm, the approximate algorithm has less time consumption and space consumption, so that it can guarantee the overall system performance. In this paper, we choose the genetic algorithm to solve the optimization problem.
We use as the initial generation, and should strictly adhere to the above constraints.
Now, we can give the optimization algorithm using Genetic algorithm, which is shown in Algorithm 1.
| Algorithm 1: Algorithm Solving Optimization Problem |
Parameters - Population Size = 150
- GA Generations = 100
- Crossover ratio = 1.2
Selection Function: Chooses parents by simulating a roulette wheel, in which the area of the section of the wheel corresponding to an individual is proportional to the individual’s expectation. The algorithm uses a random number to select one of the sections with a probability equal to its area.
Crossover Function: Returns a child that lies on the line containing the two parents, a small distance away from the parent with the better fitness value in the direction away from the parent with the worse fitness value. You can specify how far the child is from the better parent by the parameter Ratio, which appears when you select Heuristic. The default value of Ratio is 1.2.
Mutate Function: Randomly generate directions that are adaptive with respect to the last successful or unsuccessful generation. The mutation chooses a direction and step length that satisfies bounds and linear.
Begin
T = 0;
Initialize H(t);
Evaluate H(t);
While not finished do
Begin
T = t + 1;
Select H(t) from H(t − 1);
Crossover in H(t);
Mutate in H(t);
Evaluate H(t);
End
End |
4.3. Cooperative Resource Management Algorithm
The data cached from C and the computation offloading for each MT is managed by MEC-BS using Cooperative Resource Management Algorithm, which is responsible for monitoring and collecting the information (computation offloading requests and responses, data caching requests and responses, parameters of MTs, MEC-NBS, and C), running the optimization algorithm, and sending the optimization result to C and each MT.
MEC-BS will send the selection probability in the optimization result to the MT and C to determine the place (C, MEC-BS, or MEC-NBS), which is selected to execute the task or cache the data. At initialization of the system, all MTs in upload their required parameters, including , , , , and the information of all its tasks (), to MEC-BS. MEC-BS also collects the required parameters of MEC-NBS, including , , and . The required paramenters of C need to be sent to MEC-BS, as well, including , , and , and parameters between C and MEC-NBS and should also be sent.
During the system running, as for MTs, MEC-NBS, and C, once the value of any parameters of them has changed, they need to report the new value to MEC-BS. So, it can ensure the real-time and correctness of the parameter values in MEC-BS.
MEC-BS monitors periodic observation of changes in all parameters. It will run Algorithm 1 in the next period, if any parameter has changed. Periodic monitoring reduces the execution frequency of the algorithm, while ensuring the timeliness of the optimization results.
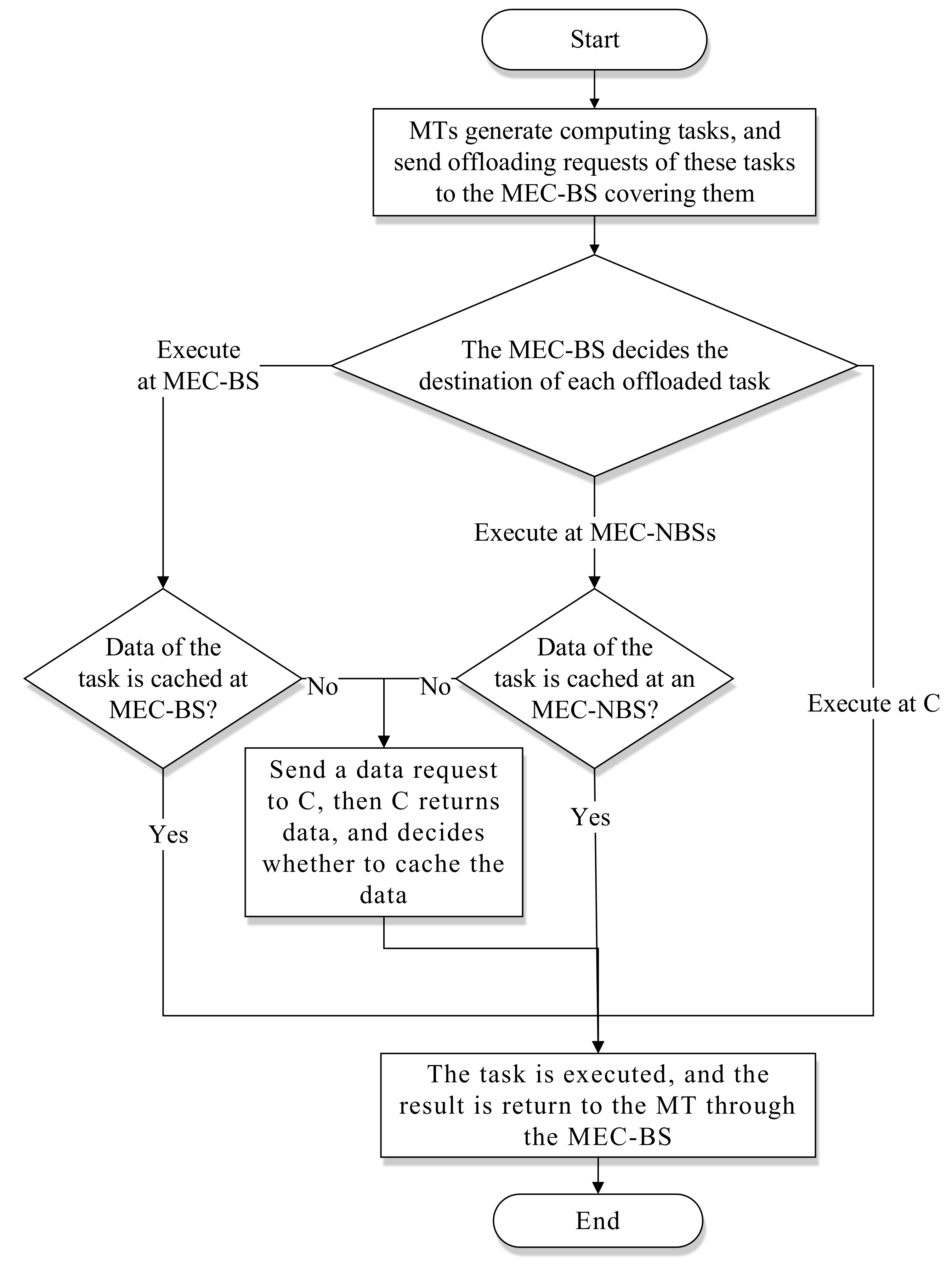
The flowchart of the Cooperative Resource Management Algorithm is shown in
Figure 3. The details of the algorithm are described in Algorithm 2 for MT side, Algorithm 3 for C side, Algorithm 4 for MEC-NBS side, and Algorithm 5 for MEC-BS side. The four algorithms are composed of twelve loops,
L1-L12; these loops are deployed into separate processes and executed in parallel during the running period of the system.
| Algorithm 2: Cooperative Resource Management Algorithm at side
|
Initial: set , send , , , and the profiles of all its tasks to MEC-BS.
L1:
if any required parameters of changes then
sends the new value of the parameter to MEC-BS;
end if
L2:
if receives from MEC-BS then
updates the value of stored in ;
end if
L3:
if has a new then
generates a random number based on Uniform distribution;
;
for to do
if then
if then ;
else ;
end if
break;
end if
end for
if then
executes at C;
else if then
offloads to MEC-BS;
else
offloads to ;
end if
L4:
if has a new then
generates a random number based on Uniform distribution;
;
for b= to do
if then
if then ;
else ;
end if
break;
end if
end for
if then
the data required by does not be cached anywhere;
else if then
the data required by is cached in MEC-BS from C;
else
the data required by is cached in from C;
end if
end if
|
| Algorithm 3: Cooperative Resource Management Algorithm at C side |
Initial: send , , , and to MEC-BS.
L5:
if any required parameters of C changes then
C sends the new value of the parameter to MEC-BS;
end if
L6:
if is decided to be offloaded to C then
C executes ;
C returns the offloading response of to MEC-BS;
end if
L7:
if the data required by should be cached in MEC-BS from C then
MEC-BS sends the data caching request of to C;
C returns the data caching response of to MEC-BS;
end if
L8:
if the data required by should be cached in from C then
sends the data caching request of to C;
C returns the data caching response of to ;
end if |
| Algorithm 4: Cooperative Resource Management Algorithm at side () |
Initial: send , and to MEC-BS.
L9:
if any required parameters of changes then
sends the new value of the parameter to MEC-BS;
end if
L10:
if is decided to be offload to and cached the data of in advance then
executes ;
returns the offloading response of to MEC-BS;
else if is decided to be offload to and did not cache the data of in advance then
sends the data request of to C;
C returns the data response of to ;
executes ;
sends the offloading response of to MEC-BS;
end if
end if |
| Algorithm 5: Cooperative Resource Management Algorithm at MEC-BS side |
Initial: collect required parameters from MTs, MEC-NBS, C, and itself, then store their values. L11 (runs periodically): if MEC-BS receives a new value of the required parameters then
MEC-BS runs Algorithm 1 and get optimal result ;
for each in do
if the value of is updated then
MEC-BS sends the new value of to ;
end if
end for
end if
L12:
if MEC-BS receives the offloading request of from then
if is decided to be offload to MEC-BS and MEC-BS cached the data of in advance then
MEC-BS executes ;
MEC-BS sends the offloading response of to ;
else if is decided to be offload to MEC-BS and MEC-BS did not cache the data of in advance then
MEC-BS sends the data request of to C;
C returns the data response of to MEC-BS;
MEC-BS executes ;
MEC-BS sends the offloading response of to ;
end if
end if
L13:
if MEC-BS receives the offloading response of sent from C then
MEC-BS forwards the offloading response to ;
end if
L14:
if MEC-BS receives the offloading response of sent from () then
MEC-BS forwards the offloading response to ;
end if |
(L1): if any one of , , , and the profiles of all its tasks to MEC-BS changes, will send the new value of the parameter to MEC-BS;
(L2): if receives from MEC-BS, it will update the value of stored in ;
(L3): when has a new , as for computing offloading, firstly, it produces a random number based on Uniform distribution. Then, it compares h with the offloading probabilities in H. If h falls into the interval representing , then will offload to MEC-BS by sending offloading request and receiving offloading response. Similarly, if h falls into the interval representing , then will offload to . Else, will be offloaded to C.
(L4): when has a new , as for data caching, firstly, it produces a random number based on Uniform distribution. Then, it compares c with the data caching probabilities in H. If c falls into the interval representing , then will cache the data requested by in MEC-BS by sending data caching request and receiving data caching response. Similarly, if c falls into the interval representing , then will cache the data requested by in . Else, the data requested by will not be cached.
(L5): if any one of , , , and changes, C will send the new value of the parameter to MEC-BS;
(L6): if C receives the offloading request of from MEC-BS, C will execute , then return the offloading response to MEC-BS;
(L7): if C receives the data caching request of to MEC-BS, C will return the data caching response of to MEC-BS;
(L8): if C receives the data caching request of to , C will return the data caching response of to ;
(L9): if any one of , and changes, will send the new value of the parameter to MEC-BS;
(L10): if receives the offloading request of from MEC-BS and cached the data of in advance, will execute , then return the offloading response to MEC-BS. If receives the offloading request and did not cache the data of in advance, will send the data request of to C, then C will return the data response of to . After that will execute , then return the offloading response to MEC-BS.
(L11): L11 runs periodically. If MEC-BS receives any new values of the required parameters from MTs, MEC-NBS, C, and itself, in last period, MEC-BS will run Algorithm 1 and obtains the optimal solution . Then, MEC-BS checks each element in . MEC-BS will send the new value to the corresponding MT, if is updated.
(L12): if MEC-BS receives the offloading request of offloaded from and MEC-BS cached the data of before, MEC-BS will execute , then return the offloading response to . If MEC-BS receives the offloading request and it did not cache the data of before, MEC-BS will send the data request of to C, then C will return the data response of to MEC-BS. After that MEC-BS will execute , then return the offloading response to .
(L13): if MEC-BS receives the offloading response of sent from C, MEC-BS will forward the offloading response to .
(L14): if MEC-BS receives the offloading response of sent from (), MEC-BS will forward the offloading response to .
5. Simulations and Performance Evaluations
We carried out extensive simulation of the system, and adopted the strategy of averaging multiple sets of random data to eliminate the measurement errors in the simulation process. We have adopted two contrasting strategies, one of which is the strategy without data cache, and the other is the strategy of neither data cache nor computation offloading. The three strategies are compared to analyze the effect of each strategy on the response time delay of the system from (1) M, the number of MTs; (2) R, the number of a ’s ; (3) K, the number of MEC-NBS; (4) , the service rate of ; (5) , data transmission rate between C and MEC-NBS; (6) , data transmission rate between MEC-NBS and C; (7) and , data transmission rate between MEC-BS and MEC-NBS. The result in each of the 8 scenarios is obtained from 50 repeated simulations using different random seeds. The simulation results verify the effectiveness of our strategy. It can well meet the requirements of minimizing the service response delay and improving the service quality of the resource scheduling.
Table 1 lists the settings of the parameters used in simulations. Parameter values are configured based on the table unless stated clearly.
Table 2 lists the three schemes in MATLAB simulation. We use genetic algorithm to get the minimum system delay of OMEC, and simulate the three strategies mentioned above. The results of simulating are shown in the figures.
5.1. Different Numbers of MTs
As shown in
Figure 4, we measured the total time consumption by the system in completing all tasks under the 3 strategies with different numbers of MTs. In simulations, we increase
M from 30 to 100, while other settings are listed in
Table 1, except fixed values
,
,
MBPS,
MB/s,
MB/s,
MB/s,
.
When M increases, the total time for the system to complete the tasks increases correspondingly, these 3 strategies are in accordance with the law. At the same time, the total time consumed by OMEC and OCMEC is always lower than NMEC, OCMEC is always lower than OMEC. So, computing offloading and data caching can reduce the system delay.
With the increase of M, the total load of the system increases. When , because of the low task load, the gain effect of OCMEC on reducing the delay is relatively low; when , the task load increases continuously, and the total time-consuming gap between OCMEC and NMEC is increasing, and the gain effect of reducing the delay is getting better and better. When , the total load exceeds the capacity of MEC-BS and MEC-NBS, and they cannot fully meet the calculation requirements of the tasks, so the total time gap gradually narrows, and the gain effect for reducing the delay gradually decreases.
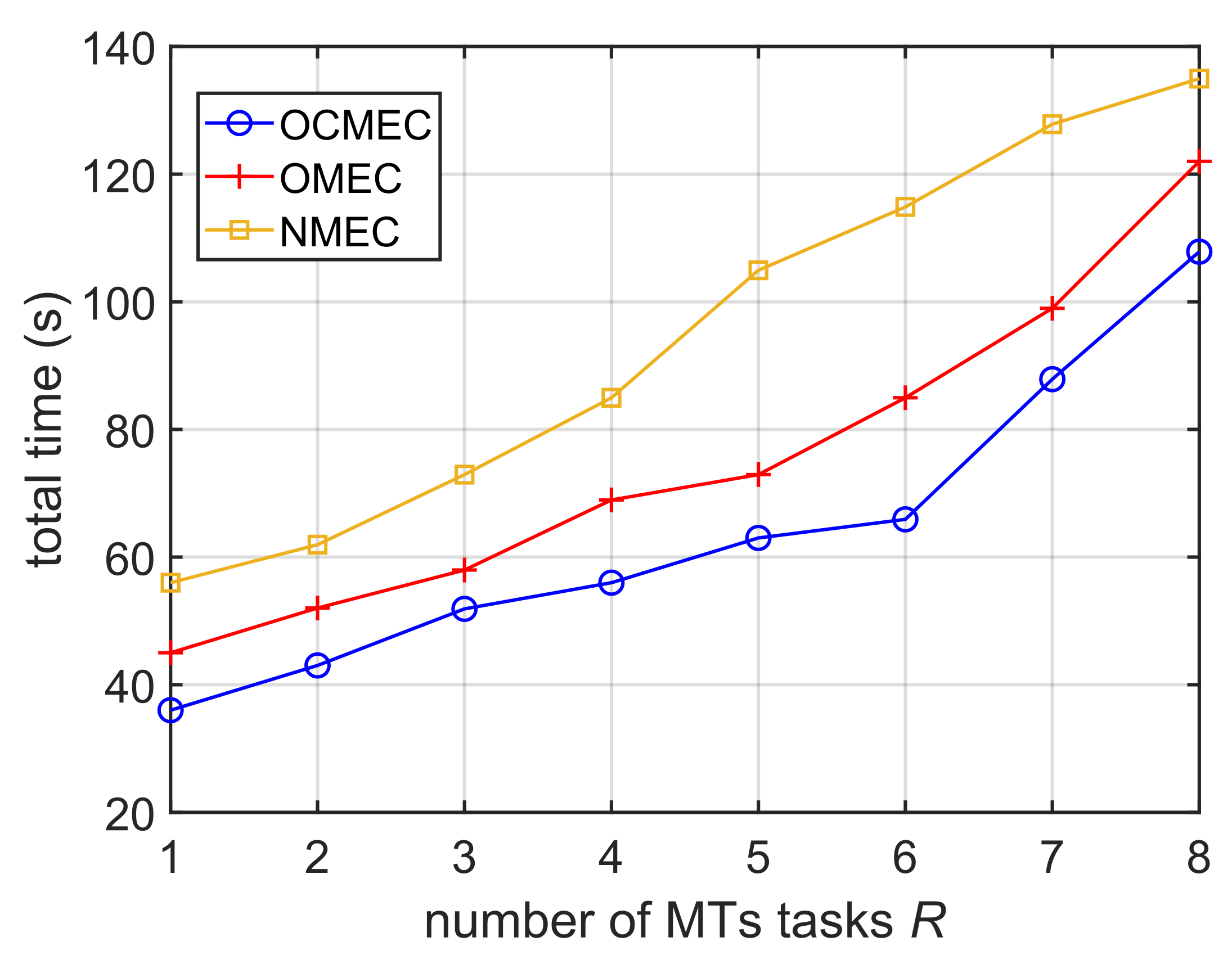
5.2. Different Numbers of MTs’ Tasks
As shown in
Figure 5, we measured the total time consumption by the system in completing all tasks under the 3 strategies with different numbers of MTs’ Tasks. In simulations, we increase
R from 1 to 8, while other settings are listed in
Table 1, except fixed values
,
,
MBPS,
MB/s,
MB/s,
MB/s,
. When
R increases, the total time for the system to complete the tasks increases correspondingly, these 3 strategies are in accordance with the law. At the same time, the total time consumed by OMEC and OCMEC is always lower than NMEC, and OCMEC is always lower than OMEC. So, computing offloading and data caching can reduce the system delay.
With the increase of R, the total load of the system increases. When , because of the low task load, the gain effect of OCMEC on reducing the delay is relatively low; when , the task load increases continuously, and the total time-consuming gap between OCMEC and NMEC is increasing, and the gain effect of reducing the delay is getting better and better. When , the total load exceeds the capacity of MEC-BS and MEC-NBS, and they cannot fully meet the calculation requirements of the tasks, so the total time gap gradually narrows, and the gain effect for reducing the delay gradually decreases.
Therefore, the strategy proposed in this paper can perform better when the number of users is larger, and the proposed base stations data caching and computational offloading strategies can effectively reduce the end-user service response latency.
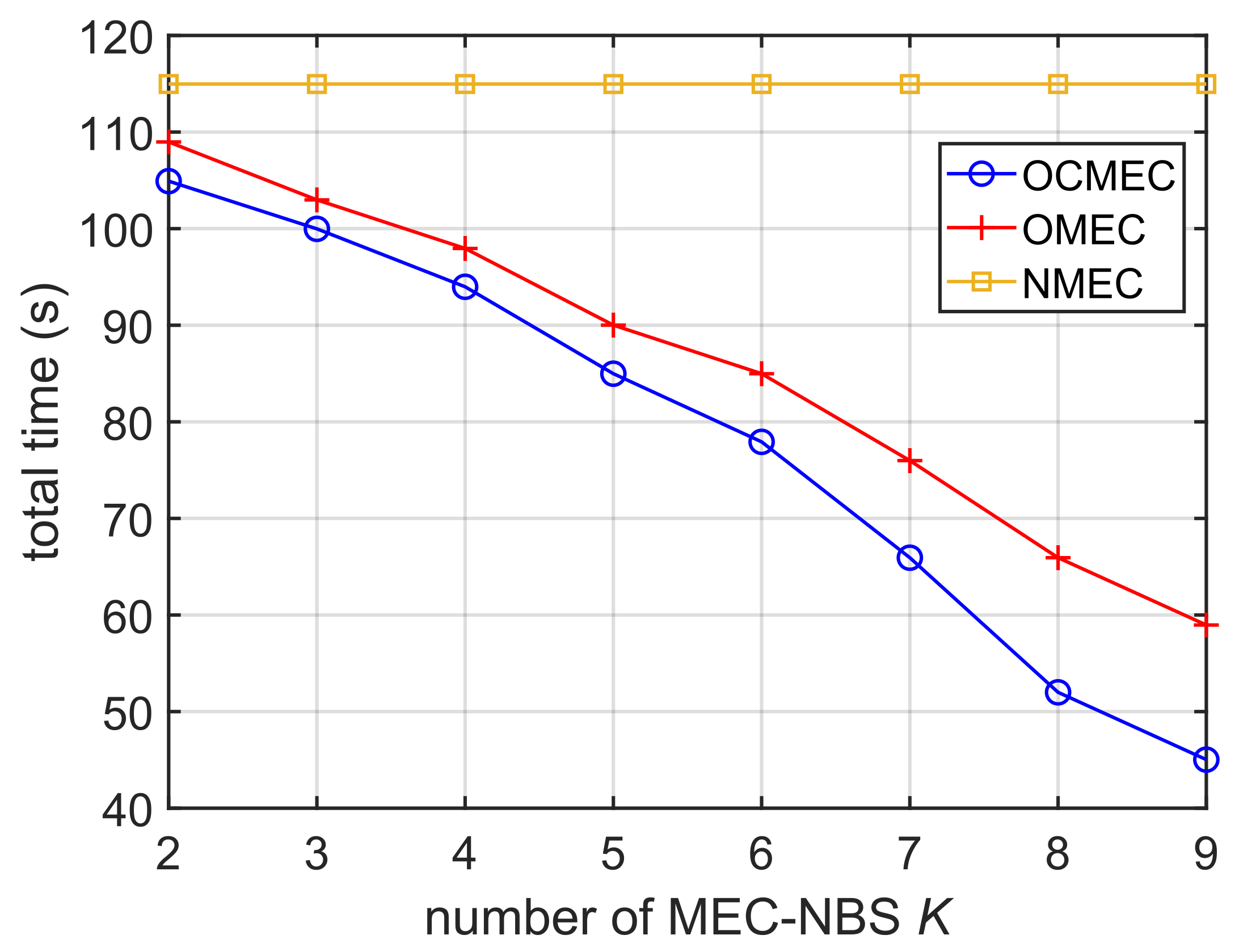
5.3. Different Numbers of MEC-NBS
As shown in
Figure 6, we measured the total time consumption by the system in completing all tasks under the 3 strategies with different numbers of MEC-NBS. In simulations, we increase
K from 2 to 9, while other settings are listed in
Table 1, except fixed values
,
,
MBPS,
MB/s,
MB/s,
MB/s,
.
When K is increased, the total time to complete tasks is decreased correspondingly under OMEC and OCMEC strategies. The curve of NMEC is flat since the further offloading and data caching are disabled, so K has no effect on NMEC. At the same time, the total time consumed by OMEC and OCMEC is always lower than NMEC, and OCMEC is always lower than OMEC. So, computing offloading and data caching can reduce the system delay.
With the increase of K, the system can accept more tasks and provide better performance through computing offloading and data caching, the total time-consuming gap between OCMEC and NMEC is increasing, and the gain effect of reducing the delay is getting better and better. But we still observe that, when the number of K increases to a certain threshold, the optimization effect for time consumption slows down gradually.
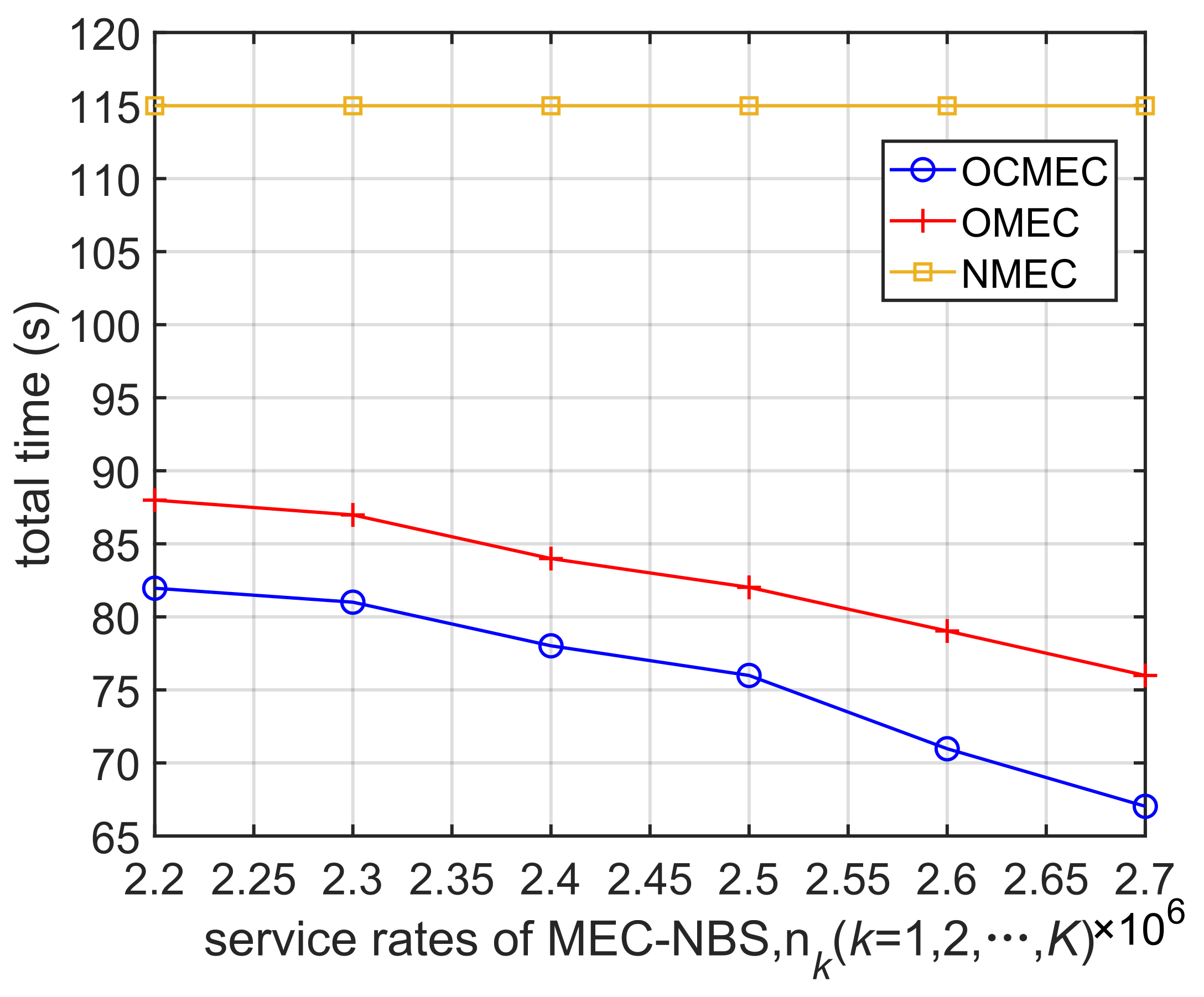
5.4. Different Service Rates of MEC-NBS
As shown in
Figure 7, we measured the total time consumption by the system in completing all tasks under the 3 schemes with different service rates of MEC-NBS. In simulations, we increase
from 2.2
to 2.7
MIPS, while other settings are listed in
Table 1, except fixed values
,
,
,
MB/s,
MB/s,
MB/s,
.
represents the computation capability of MEC-NBS. Similar to
Figure 6, when
is increased, total utilization time of the system is decreased under OMEC and OCMEC strategies. The line of NMEC is straight since
has no effect on it. The total time consumed by OMEC and OCMEC is always lower than NMEC, OCMEC is always lower than OMEC. So, computing offloading and data caching can reduce the system delay.
With the increase of , the system can accept more tasks and provide better performance through computing offloading and data caching, the total time-consuming gap between OCMEC and NMEC is increasing, and the gain effect of reducing the delay is getting better and better. When increases to a certain threshold, the optimization effect for time consumption slows down gradually.
It is worth noting that the gain of to total time optimization is far less than K.
Therefore, MEC-NBS can effectively reduce the system delay, in which the combination of data caching and computational offloading than one separate computational offloading brings more delay benefits.
5.5. Different Data Transmission Rates between C and MEC-NBS
As shown in
Figure 8, we measured the total time consumption by the system in completing all tasks under the 3 schemes with different data transmission rates between C and MEC-NBS. In simulations, we increase the
from 50 to 90 MB/s, while other settings are listed in
Table 1, except fixed values
,
,
,
MBPS,
MB/s,
MB/s,
.
The data transmission rates between C and MEC-NBS impact the time consumptions of transmission processes in further offloading and data caching. As the transmission rates increase, the time consumptions decrease, so the time benefits gained by further offloading and data caching grows. As shown in
Figure 8, the curves of our scheme and OMEC appear a downward trend as
increase, whereas the curve of NMEC is unchanged since further offloading and data caching are disabled.
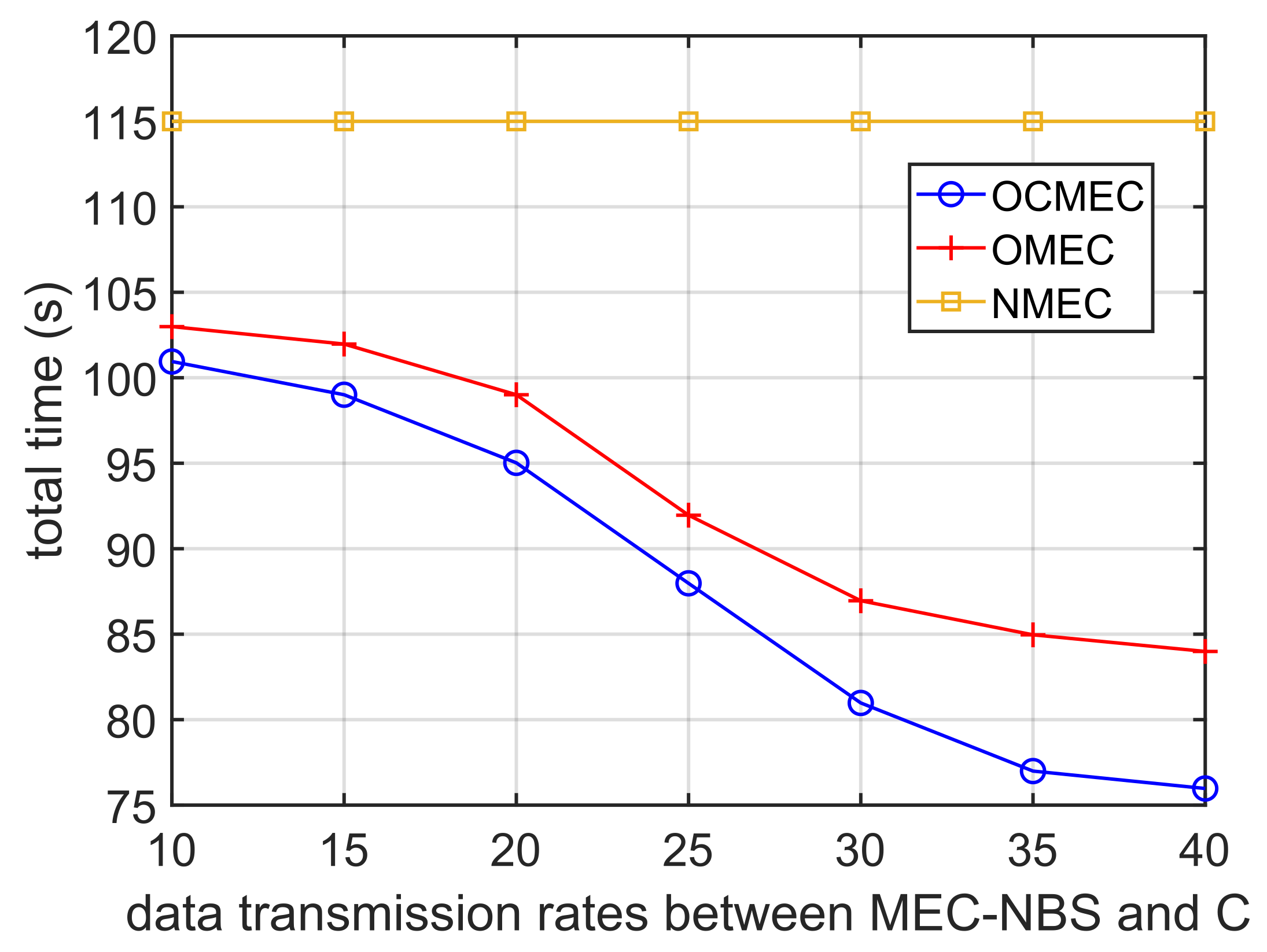
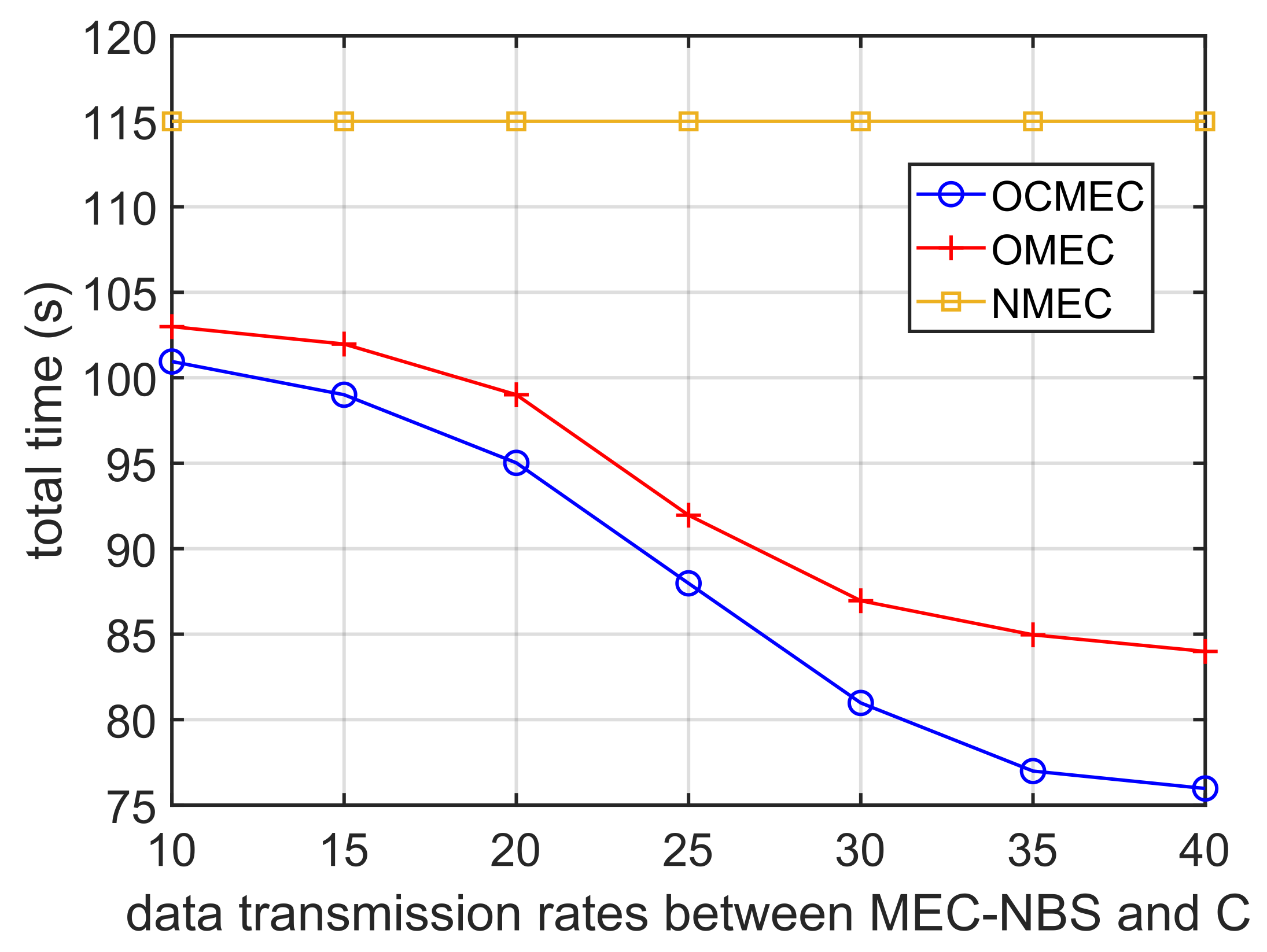
5.6. Different Data Transmission Rates between MEC-NBS and C
As shown in
Figure 9, we measured the total time consumption by the system in completing all tasks under the 3 schemes with different data transmission rates between C and MEC-NBS. In simulations, we increase the
from 10 to 40 MB/s, while other settings are listed in
Table 1, except fixed values
,
,
,
MBPS,
MB/s,
MB/s,
.
Similar to the data transmission rates between C and MEC-NBS, impacts the time consumptions of transmission processes in further offloading and data caching. Although the curves of our scheme and OMEC are not very smooth, we can still notice that the overall trend of the curves are decreasing. Similarly, the curve of NMEC is still unchanged because further offloading and data caching are disabled.
5.7. Different Data Transmission Rates between MEC-BS and MEC-NBS
As shown in
Figure 10, we measured the total time consumption by the system in completing all tasks under the 3 schemes with different data transmission rates between MEC-BS and MEC-NBS. In simulations, we increase the
and
from 10 to 40 MB/s, while other settings are listed in
Table 1, except fixed values
,
,
,
MBPS,
MB/s,
MB/s,
.
Similar to the data transmission rates between MEC-NBS and C, and impacts the time consumptions of transmission processes in further offloading and data caching. The overall trend of the curves of OCMEC and OMEC are decreasing. Similarly, the curve of NMEC is still unchanged because further offloading and data caching are disabled.
5.8. Comparison with Other Optimization Algorithms
As shown in
Figure 11, we compare our algorithm with two other ones, including the Particle Swarm Optimization (PSO) algorithm and the Simulated Annealing (SA) algorithm. The convergence speeds of the 3 algorithms are measured to find the solution of our optimization problem with
,
,
,
MBPS,
MB/s,
MB/s,
MB/s,
, while other settings are listed in
Table 1. The simulation results show that although all of the 3 algorithm can converge after multiple iterations, our Genetic algorithm has the fastest convergence speed (our Genetic algorithm is converged at iteration 252, PSO algorithm is converged at iteration 281, and SA algorithm is converged at iteration 297). It demonstrates that our algorithm is more suitable for our optimization problem.
6. Conclusions
As one of the key research directions in the future mobile network, mobile edge computing technology can effectively alleviate the computing pressure and data interaction pressure of mobile cloud, reduce the response delay of mobile terminals, and improve the overall efficiency of the system.
In this paper, the characteristics of computing offloading and data caching in mobile edge computing are deeply studied, and a new resource management scheme based on the cooperation of multiple MEC base stations is proposed. In our scheme, MEC-BS and MEC-NBS can perform computational tasks offloaded from the cloud and cache the data needed to compute tasks from the cloud, minimizing the time consumed to perform all tasks.
In our research, various computing tasks of mobile terminals are defined by computing load and data load, and resource management problem is transformed into optimization problem with the objective of minimizing system time consumption. The Cooperative Resource Management Algorithm proposed in this paper consists of several separate and parallel running cycles. The performance of our scheme is evaluated and compared with the following two schemes: (1) schemes without data caching function; and (2) schemes without data caching and computing offloading. Compared with the other two schemes, our scheme shows obvious superiority in three different situations, and greatly improves the performance of the system.
Our scheme provides a new resource management method leveraging the cooperation of multiple MEC-BS. It can efficiently enhance the performance of computation-intensive and delay-sensitive applications, and improve the user experience and device supports on them.
In our future works, we plan to extend our research to the area of IoT applications, such Internet of Vehicles, Industrial Internet of Things, etc. The joint computation offloading and data caching problem will be studied to efficiently exploit the joint utilization of the resources of all BSs and the cloud to enhance the performance of task processing in these applications.
The following abbreviations are used in this manuscript:










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}