
Development of Parameters towards Voice Bifurcations

Abstract
1. Introduction
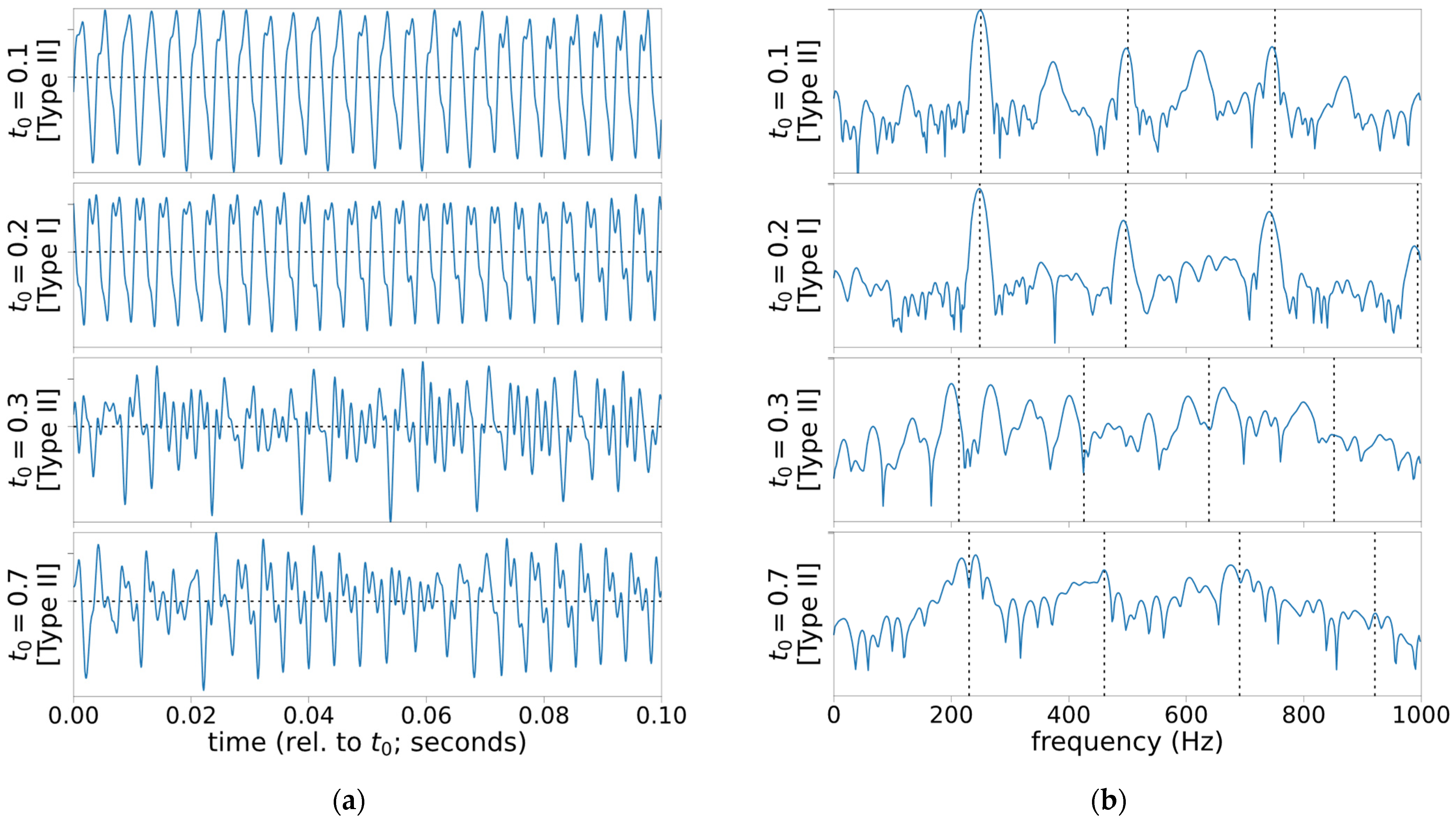
- Type I—nearly periodic;
- Type II—contain intermittency, strong subharmonics, or modulations; and
- Type III—chaotic or random.
Main Concept
2. Materials and Methods
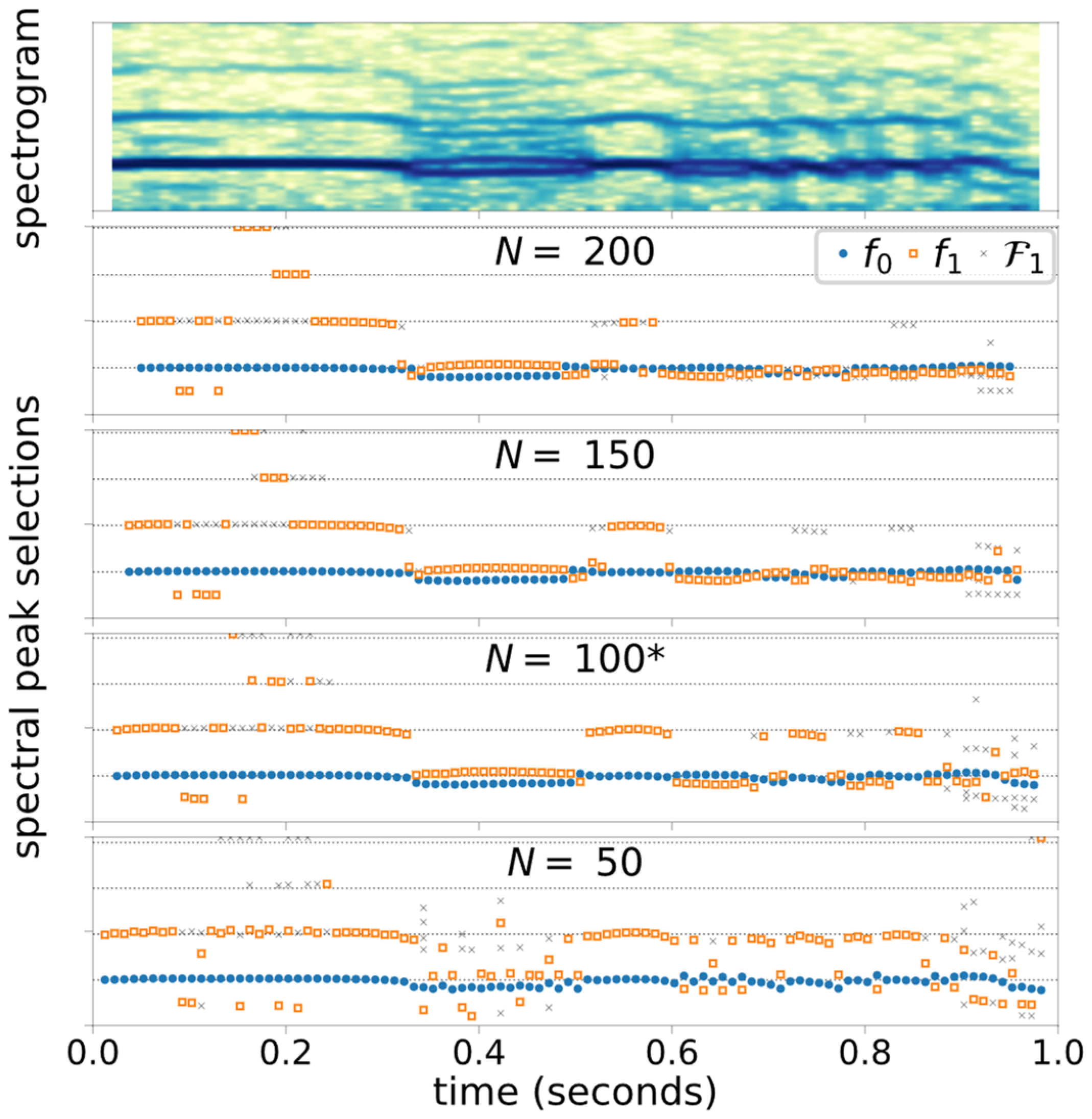
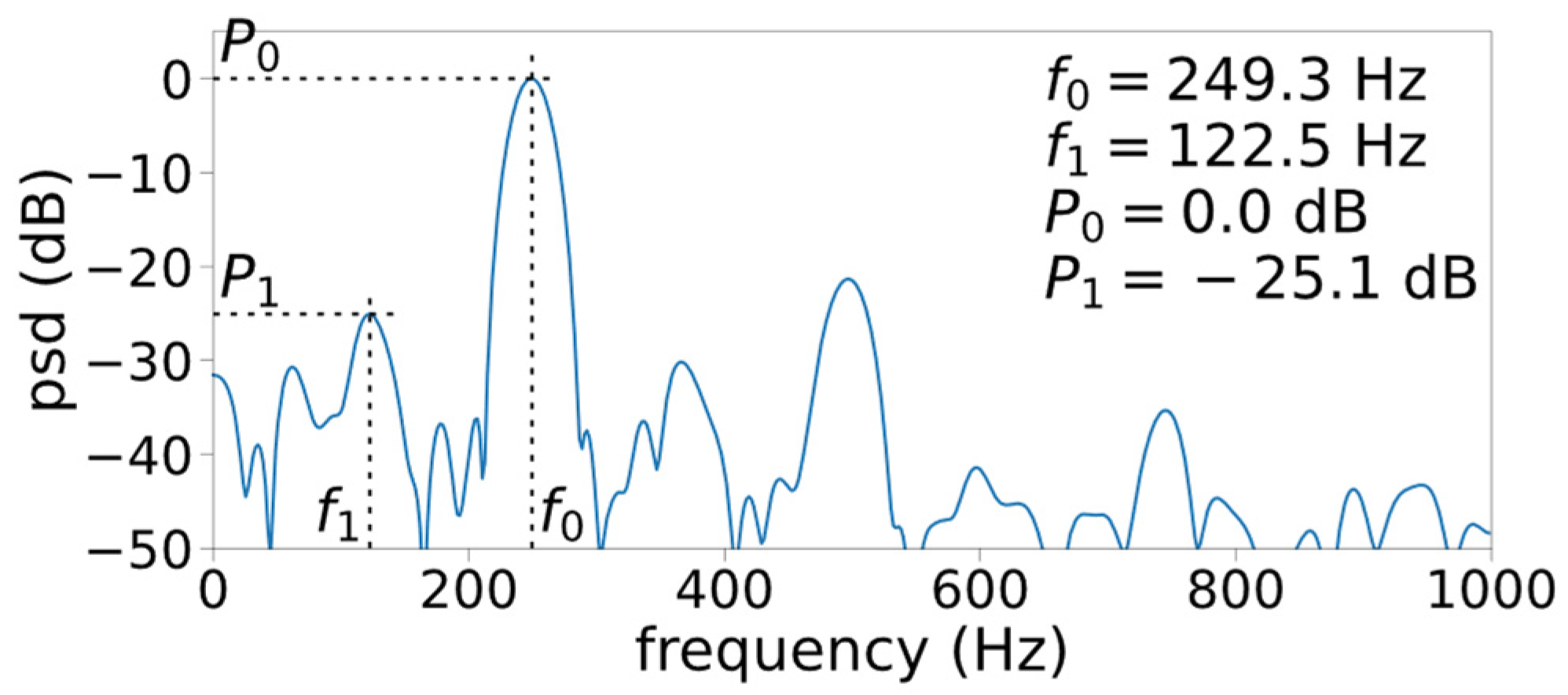
2.1. Tonal Frequency Selection Algorithm for Glottal Source Signals
2.1.1. Signal Preparation
2.1.2. Main Algorithm
2.2. Experiment Configurations
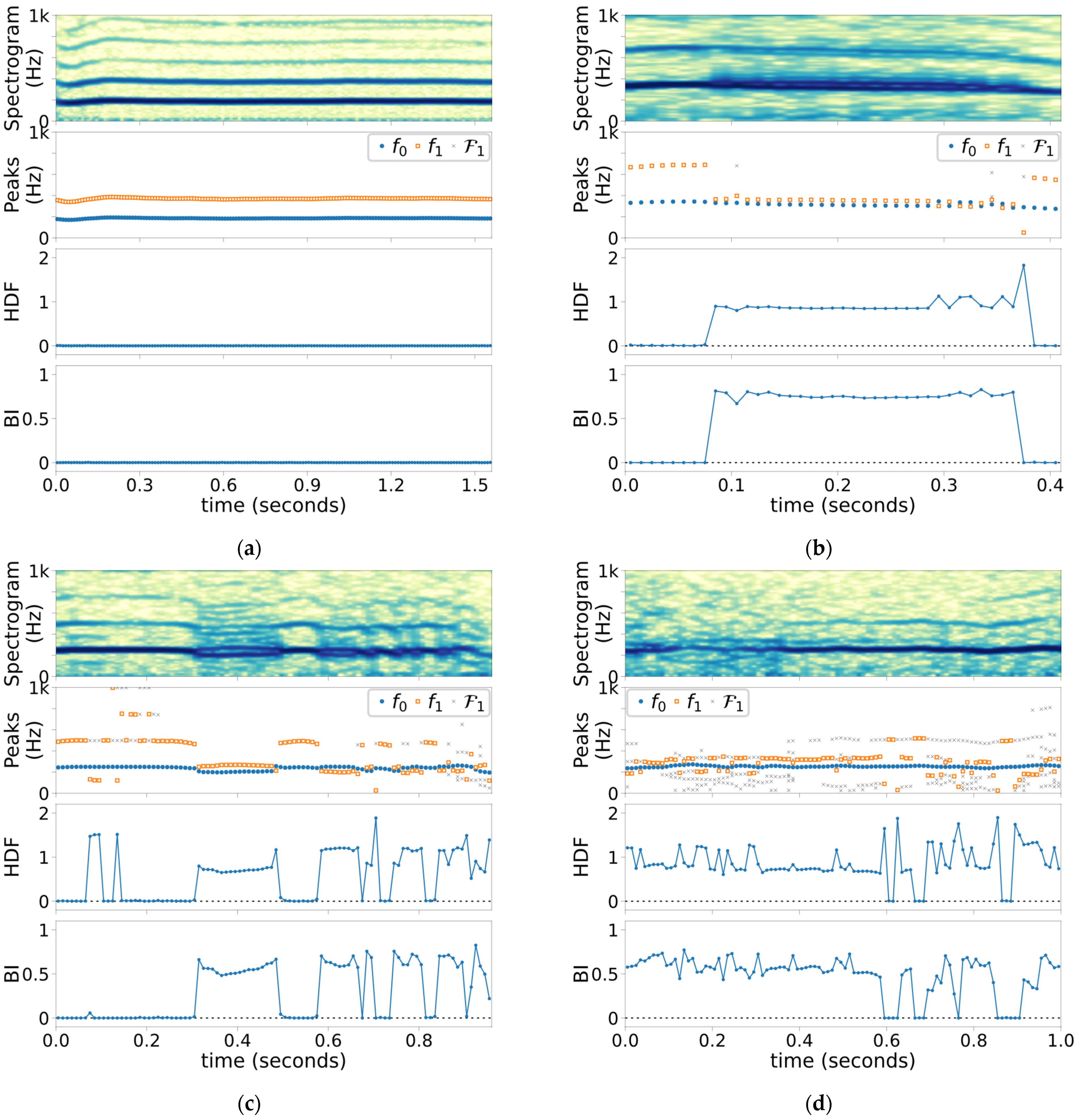
2.3. Case Study Samples and Study Outcomes
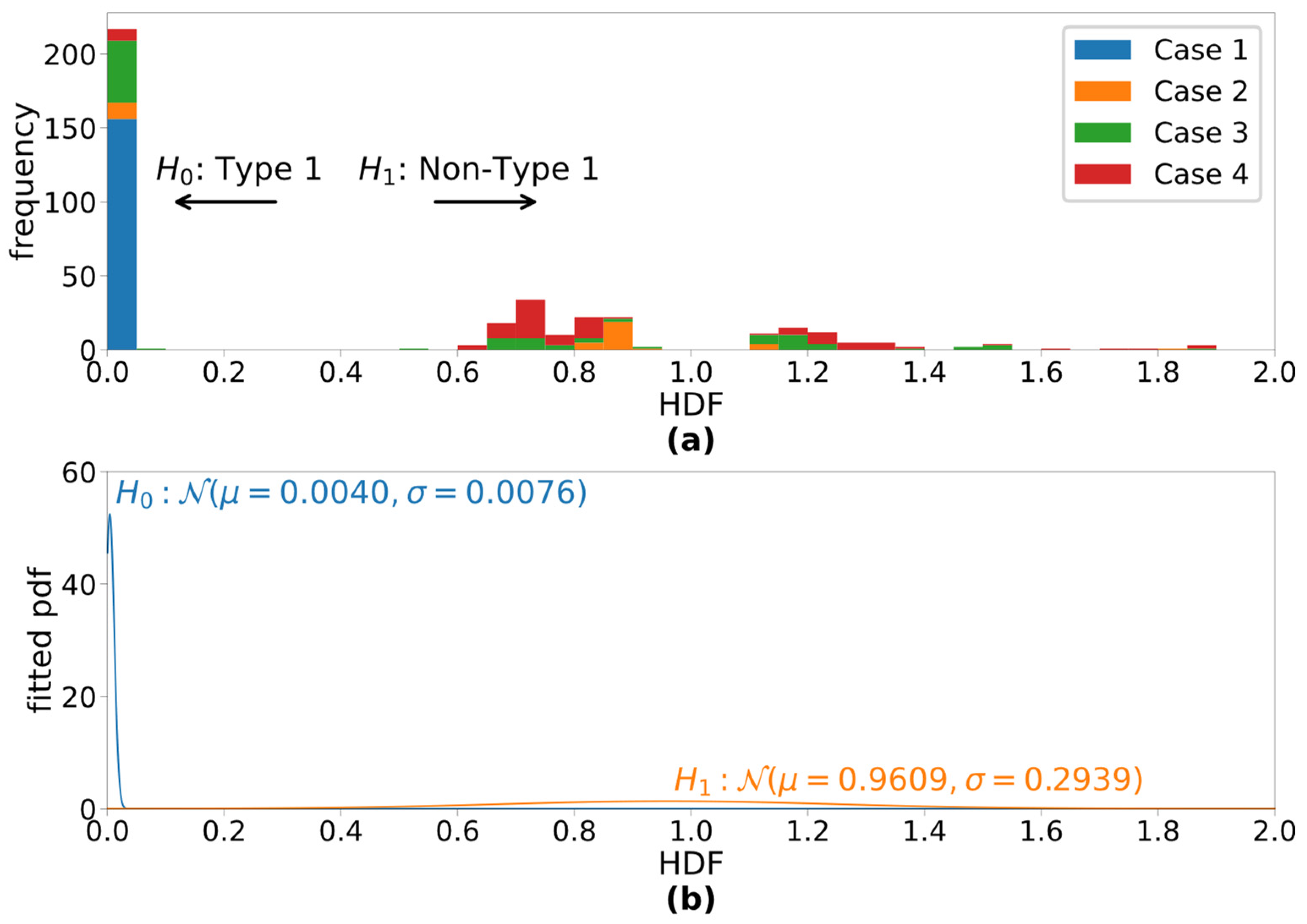
3. Results
4. Discussion
4.1. Overall Impression of HDF and BI
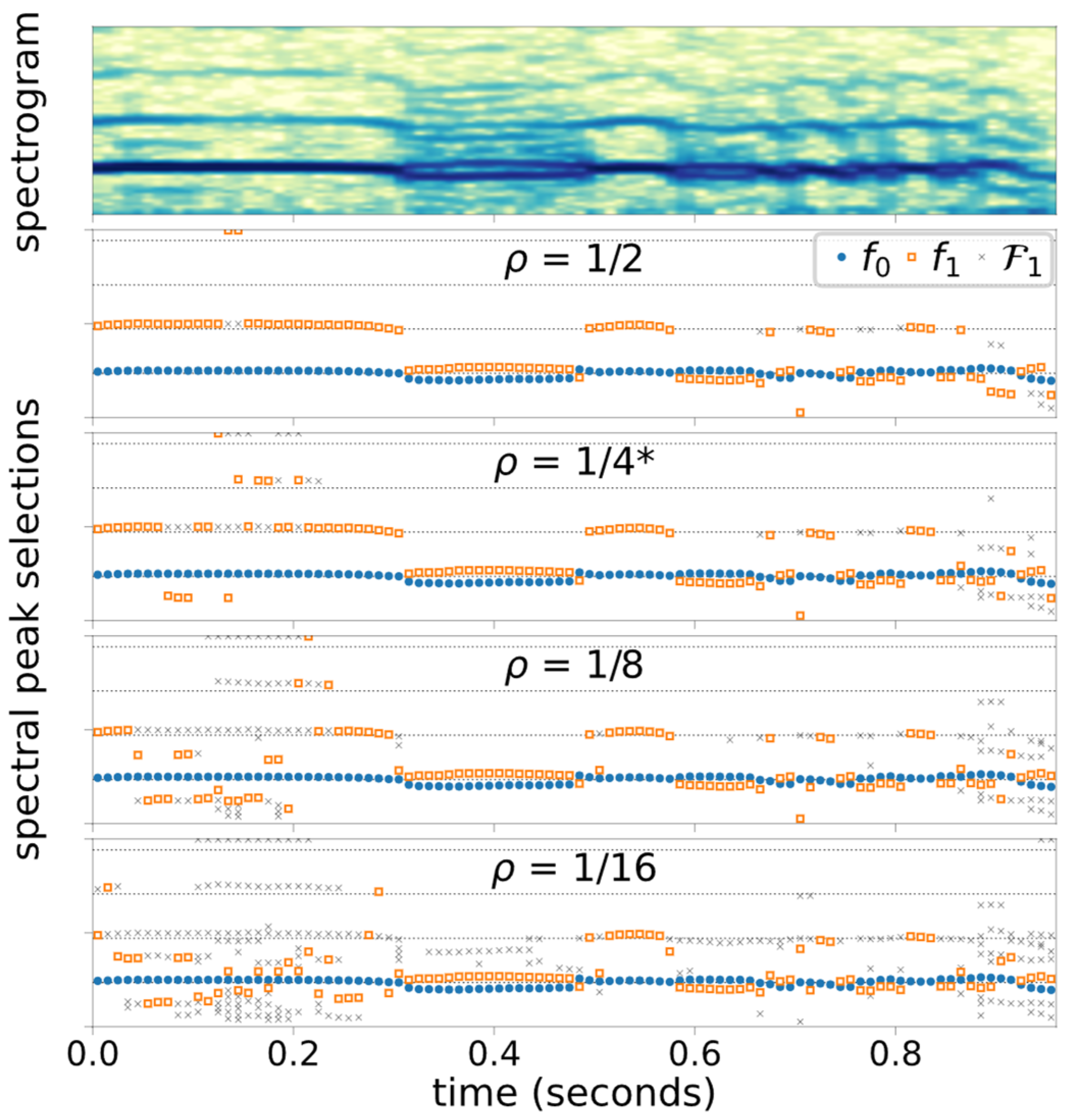
4.2. Sensitivity of HDF and the Proposed Frequency Selection Algorithm
4.3. Clinical Applications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Description of High-speed Videoendoscopy (HSV) Data and Preparation of Glottal Area Waveforms
References
- Bless, D.M.; Hirano, M.; Feder, R.J. Videostroboscopic evaluation of the larynx. Ear. Nose. Throat J. 1987, 66, 289–296. [Google Scholar] [PubMed]
- Poburka, B.J.; Patel, R.R.; Bless, D.M. Voice-Vibratory Assessment with Laryngeal Imaging (VALI) form: Reliability of rating stroboscopy and high-speed videoendoscopy. J. Voice 2017, 31, 513.e1–513.e14. [Google Scholar] [CrossRef]
- Titze, I.R. Workshop on Acoustic Voice Analysis: Summary Statement; National Center for Voice and Speech: Denver, CO, USA, 1994. Available online: http://www.ncvs.org/freebooks/summary-statement.pdf (accessed on 23 February 2021).
- Jiang, J.J.; Zhang, Y.; McGilligan, C. Chaos in voice, from modeling to measurement. J. Voice 2006, 20, 2–17. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Polce, E.; Jiang, J. Application of local intrinsic dimension for acoustical analysis of voice signal components. Ann. Otol. Rhinol. Laryngol. 2018, 127, 588–597. [Google Scholar] [CrossRef]
- Liu, B.; Polce, E.; Raj, H.; Jiang, J. Quantification of voice type components present in human phonation using a modified diffusive chaos technique. Ann. Otol. Rhinol. Laryngol. 2019, 128, 921–931. [Google Scholar] [CrossRef]
- Liu, B.; Polce, E.; Jiang, J. An objective parameter to classify voice signals based on variation in energy distribution. J. Voice 2019, 33, 591–602. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Raj, H.; Klein, L.; Jiang, J.J. Evaluating the voice type component distributions of excised larynx phonations at three subglottal pressures. J. Speech Lang. Hear. Res. 2021, 64, 1447–1456. [Google Scholar] [CrossRef]
- Bergan, C.C.; Titze, I.R. Perception of pitch and roughness in vocal signals with subharmonics. J. Voice 2001, 15, 165–175. [Google Scholar] [CrossRef]
- Herzel, H.; Knudsen, C. Bifurcations in a vocal fold model. Nonlinear Dyn. 1995, 7, 53–64. [Google Scholar] [CrossRef]
- Zañartu, M.; Mehta, D.D.; Ho, J.C.; Wodicka, G.R.; Hillman, R.E. Observation and analysis of in vivo vocal fold tissue instabilities produced by nonlinear source-filter coupling: A case studya). J. Acoust. Soc. Am. 2011, 129, 326–339. [Google Scholar] [CrossRef] [PubMed]
- Behrman, A.; Baken, R.J. Correlation dimension of electroglottographic data from healthy and pathologic subjects. J. Acoust. Soc. Am. 1997, 102, 2371–2379. [Google Scholar] [CrossRef]
- Steinecke, I.; Herzel, H. Bifurcations in an asymmetric vocal-fold model. J. Acoust. Soc. Am. 1995, 97, 1874–1884. [Google Scholar] [CrossRef] [PubMed]
- Berry, D.A.; Herzel, H.; Titze, I.R.; Story, B.H. Bifurcations in excised larynx experiments. J. Voice 1996, 10, 129–138. [Google Scholar] [CrossRef]
- Mergell, P.; Herzel, H.; Titze, I.R. Irregular vocal-fold vibration—High-speed observation and modeling. J. Acoust. Soc. Am. 2000, 108, 2996–3002. [Google Scholar] [CrossRef] [PubMed]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer [Computer program]. Version 6.1.38. Available online: http://www.praat.org/ (accessed on 4 February 2021).
- Hermes, D.J. Measurement of pitch by subharmonic summation. J. Acoust. Soc. Am. 1988, 83, 257–264. [Google Scholar] [CrossRef] [PubMed]
- Sun, X. Pitch determination and voice quality analysis using Subharmonic-to-Harmonic Ratio. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 1, pp. I-333–I-336. [Google Scholar] [CrossRef]
- Herbst, C.T. Performance evaluation of subharmonic-to-harmonic ratio (SHR) computation. J. Voice 2021, 35, 365–375. [Google Scholar] [CrossRef] [PubMed]
- Deliyski, D. Acoustic Model and Evaluation of Pathological Voice Production; EUROSPEECH: Berlin, Germany, 1993. [Google Scholar]
- Aichinger, P.; Roesner, I.; Schneider-Stickler, B.; Leonhard, M.; Denk-Linnert, D.M.; Bigenzahn, W.; Fuchs, A.K.; Hagmüller, M.; Kubin, G. Towards Objective Voice Assessment: The Diplophonia Diagram. J. Voice 2017, 31, 253.e17–253.e26. [Google Scholar] [CrossRef]
- Awan, S.N.; Awan, J.A. A two-stage cepstral analysis procedure for the classification of rough voices. J. Voice 2020, 34, 9–19. [Google Scholar] [CrossRef] [PubMed]
- Kramer, E.; Linder, R.; Schönweiler, R. A study of subharmonics in connected speech material. J. Voice 2013, 27, 29–38. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, Y. Nonlinear dynamic analysis of speech from pathological subjects. Electron. Lett. 2002, 38, 294–295. [Google Scholar] [CrossRef]
- Jiang, J.J.; Zhang, Y.; Ford, C.N. Nonlinear dynamics of phonations in excised larynx experiments. J. Acoust. Soc. Am. 2003, 114, 2198–2205. [Google Scholar] [CrossRef] [PubMed]
- Awan, S.N.; Roy, N.; Jiang, J.J. Nonlinear dynamic analysis of disordered voice: The relationship between the correlation dimension (D2) and pre-/post-treatment change in perceived dysphonia severity. J. Voice 2010, 24, 285–293. [Google Scholar] [CrossRef] [PubMed]
- Lopes, L.W.; Vieira, V.J.D.; Costa, S.L.d.N.C.; Correia, S.É.N.; Behlau, M. Effectiveness of recurrence quantification measures in discriminating subjects with and without voice disorders. J. Voice 2020, 34, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Vieira, V.J.D.; Costa, S.C.; Correia, S.L.N.; Lopes, L.W.; Costa, W.C.d.; de Assis, F.M. Exploiting nonlinearity of the speech production system for voice disorder assessment by recurrence quantification analysis. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 085709. [Google Scholar] [CrossRef] [PubMed]
- Neubauer, J.; Mergell, P.; Eysholdt, U.; Herzel, H. Spatio-temporal analysis of irregular vocal fold oscillations: Biphonation due to desynchronization of spatial modes. J. Acoust. Soc. Am. 2001, 110, 3179–3192. [Google Scholar] [CrossRef]
- Baken, R.J.; Orlikoff, R.F. Clinical Measurement of Speech and Voice, 2nd ed.; Singular: San Diego, CA, USA, 2000. [Google Scholar]
- Ikuma, T.; Kunduk, M.; McWhorter, A.J. Objective quantification of pre and post phonosurgery vocal fold vibratory characteristics using high-speed videoendoscopy and a harmonic waveform model. J. Speech Lang. Hear. Res. 2014, 57, 743–757. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voice Type | |||
|---|---|---|---|
| Type I | , | ||
| Type II—Period- Subharmonic | , | ||
| Type II—Biphonia | , near | ||
| Type III | if prevalent otherwise random | Random | Random |
| Type-II Voice | |||
|---|---|---|---|
| Period-2 subharmonic * | 1/2, 3/2 | 3/2, 1/2 | 0, 1/3 |
| Period-3 subharmonic * | 2/3, 4/3 | 4/3, 2/3 | 1/3, 1/2 |
| 2:3 biphonia ** | 2/3, 3/2 | 4/3, 1/2 | 1/3 *** |
| 3:5 biphonia ** | 3/5, 5/3 | 7/5, 1/3 | 1/5 *** |
| 7:9 biphonia ** | 7/9, 9/7 | 11/9, 5/9 | 5/9 *** |
| Name | Parameter | Value |
|---|---|---|
| Sampling rate | 2000 | |
| Window Size | 100 (50 milliseconds) | |
| Window Offset | 20 (10 milliseconds) | |
| Window Function | Hamming | |
| Number of PSD Samples | 1024 | |
| Relative Threshold | 1/4 (0.25) | |
| Minimum frequency | 25 Hz |
| Voice Description | # of Bifurcations | Notes | |
|---|---|---|---|
| Case 1 | Type I | 0 | No Pathology |
| Case 2 | Types I + II | 2 | UVFP, Biphonia |
| Case 3 | Types I + II | >10 | Polyp, Biphonia + Subharmonics |
| Case 4 | Types II + III | 4 | Polyp, mostly present throughout |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikuma, T.; McWhorter, A.J.; Adkins, L.; Kunduk, M. Development of Parameters towards Voice Bifurcations. Appl. Sci. 2021, 11, 5469. https://doi.org/10.3390/app11125469
Ikuma T, McWhorter AJ, Adkins L, Kunduk M. Development of Parameters towards Voice Bifurcations. Applied Sciences. 2021; 11(12):5469. https://doi.org/10.3390/app11125469
Chicago/Turabian StyleIkuma, Takeshi, Andrew J. McWhorter, Lacey Adkins, and Melda Kunduk. 2021. "Development of Parameters towards Voice Bifurcations" Applied Sciences 11, no. 12: 5469. https://doi.org/10.3390/app11125469
APA StyleIkuma, T., McWhorter, A. J., Adkins, L., & Kunduk, M. (2021). Development of Parameters towards Voice Bifurcations. Applied Sciences, 11(12), 5469. https://doi.org/10.3390/app11125469