
Regularized Chained Deep Neural Network Classifier for Multiple Annotators

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
3. Methods
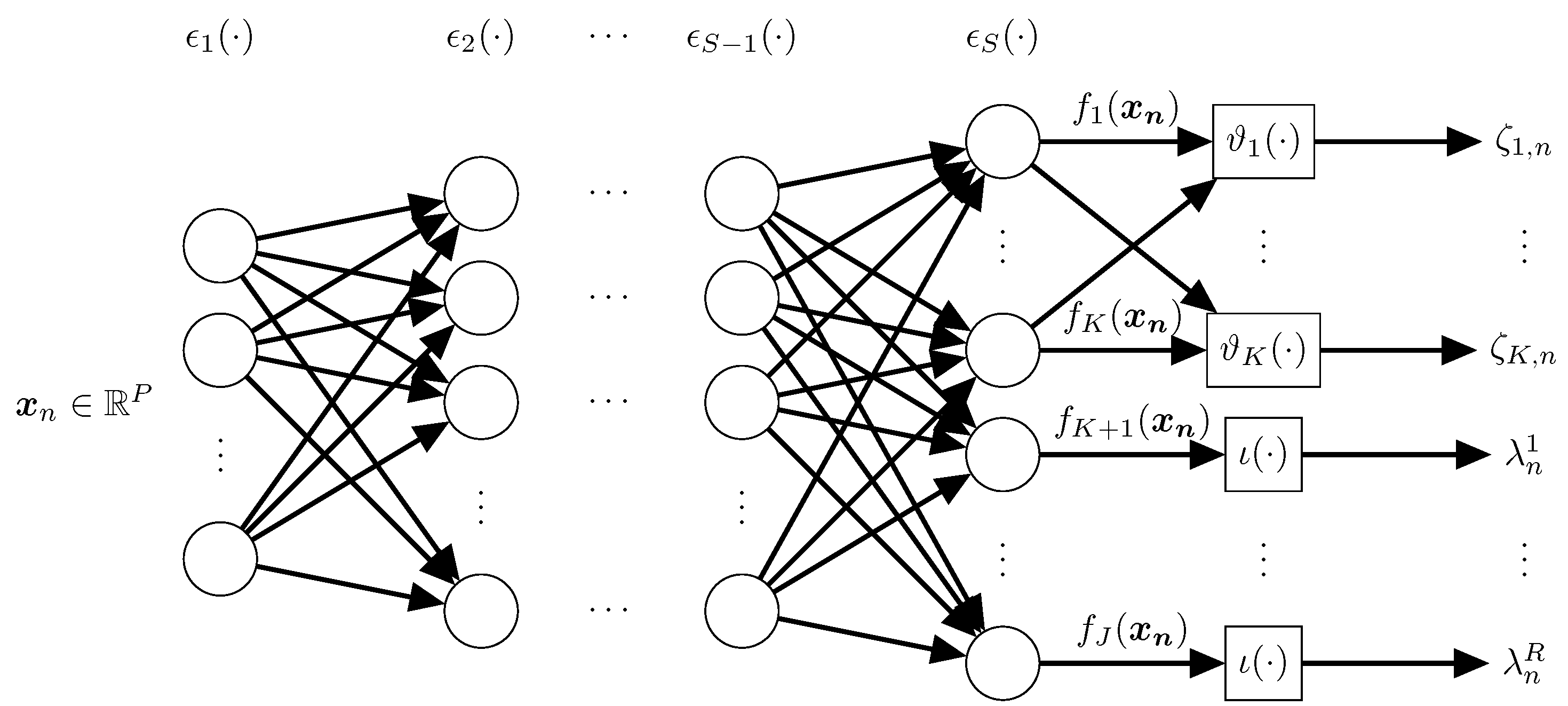
3.1. Chained Deep Neural Network
3.2. Regularized Chained Deep Neural Network for Multiple Annotators
4. Experimental Set-Up
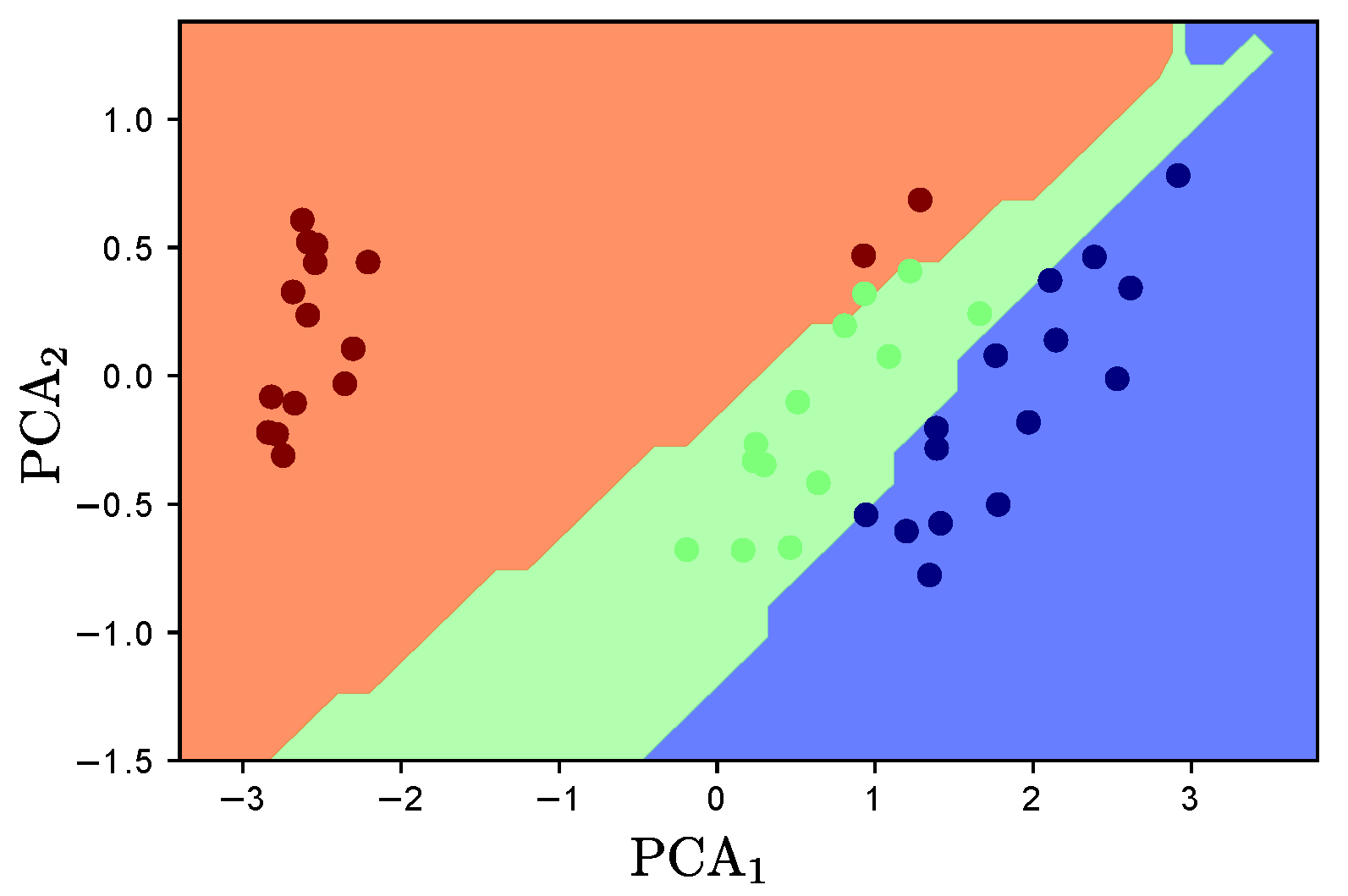
4.1. Tested Datasets
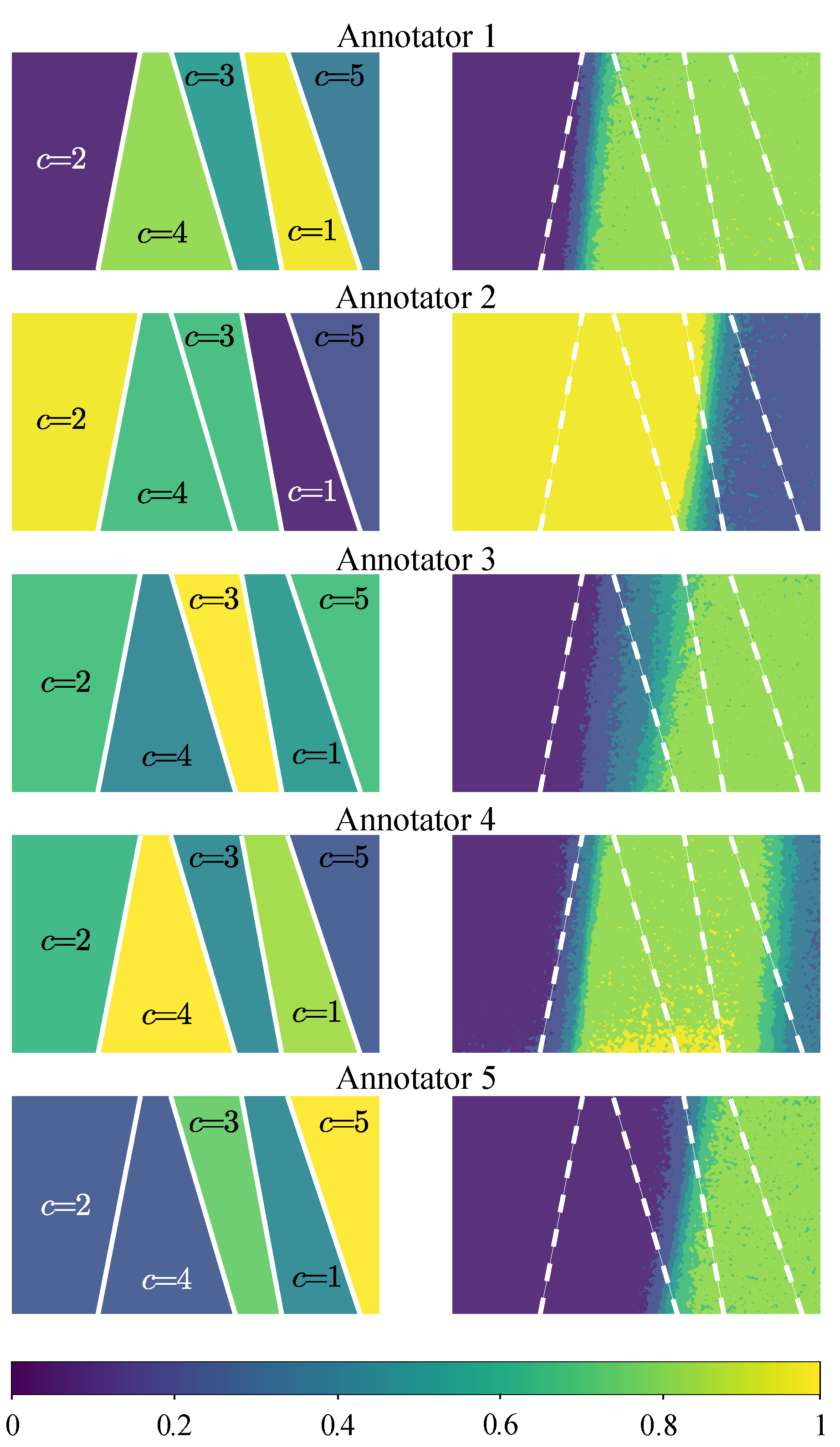
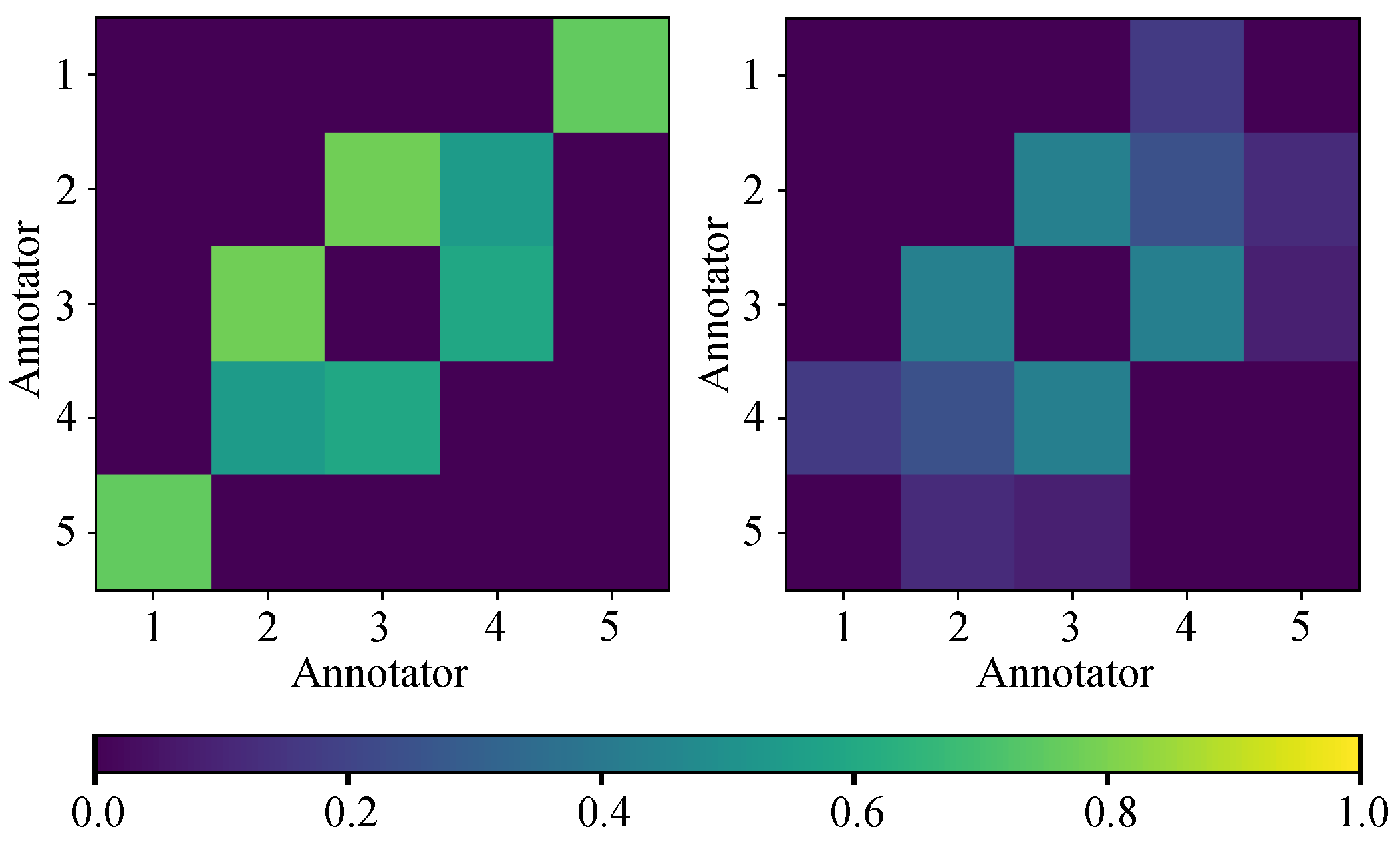
4.2. Provided and Simulated Annotations
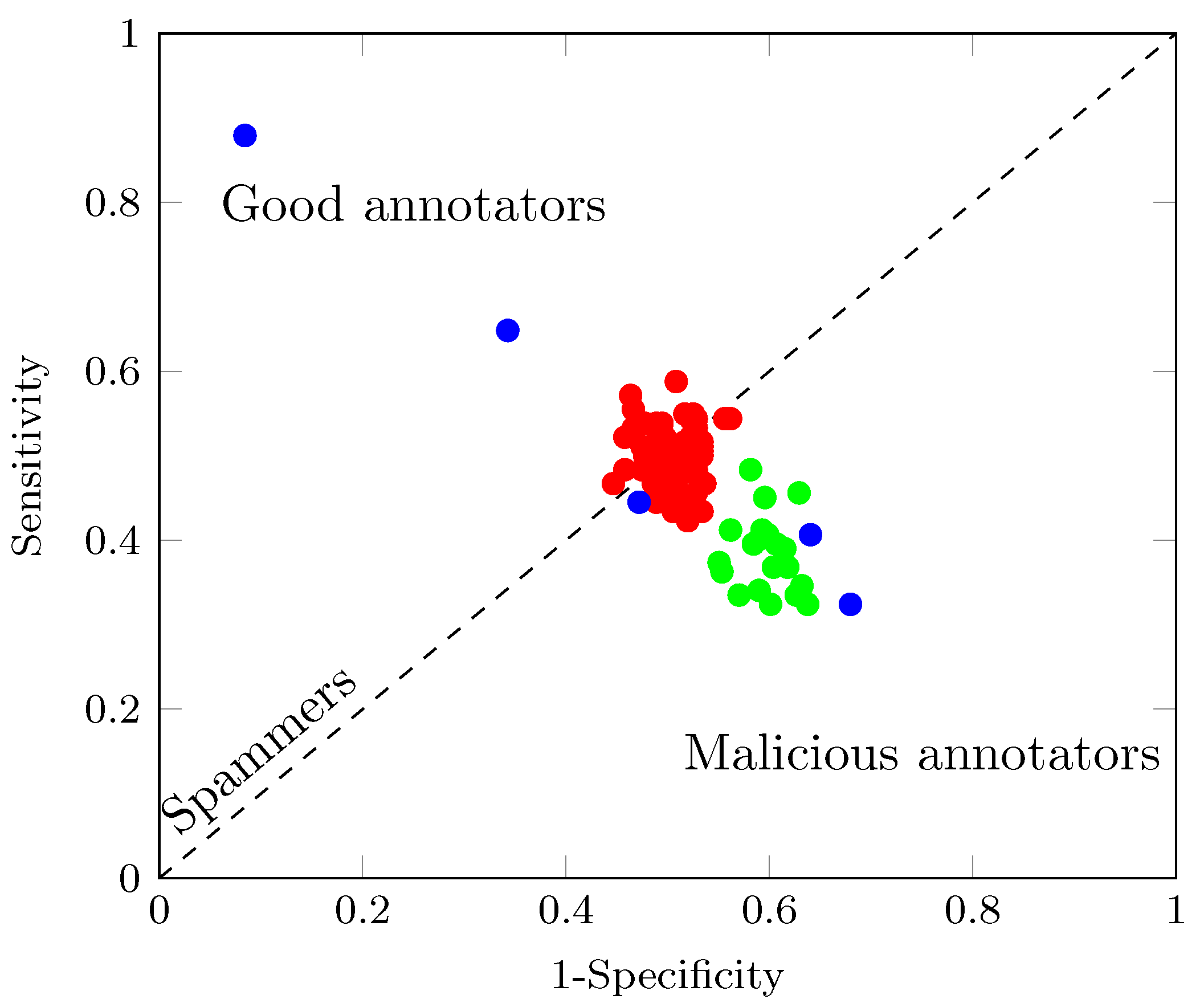
4.3. Method Comparison and Quality Assessment
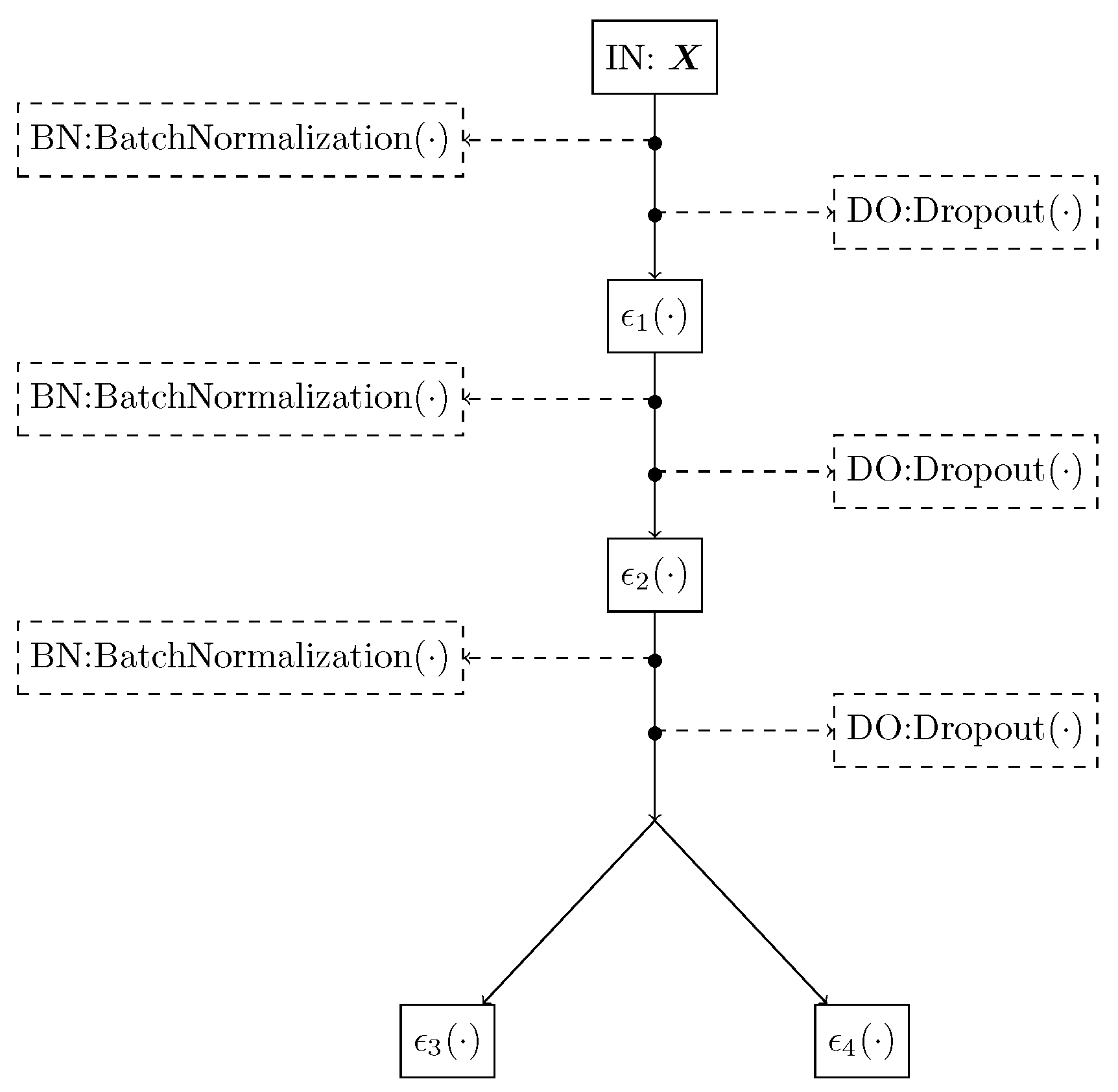
4.4. RCDNN Detailed Architecture and Training
- –
- IN: An input layer fed by the input samples ;
- –
- : A dense layer coding relevant patterns from input features to perform. The number of neurons is set as , where is chosen empirically; a linear-based activation function is used to code input data linear dependencies;
- –
- : A dense layer fixing a tanh-based activation function with neurons to reveal non-linear relationships;
- –
- : A fully-connected layer with K neurons and a softmax-based activation function, which is employed to estimate the hidden ground truth ;
- –
- : A dense layer with R neurons and a sigmoid-based activation function, which is used to compute the annotators’ reliability in ;
- –
- For all provided layers l1 plus l2-based regularization strategy is used, searching the regularization weights within the range {1e-3,1e-2,1e-1};
- –
- Batch Normalization and Dropout layers are included between layers to avoid vanishing and exploding gradient issues. Additionally, it favors the RCDNN’s generalization capability as exposed in Section 3.2. See Figure 2 for details;
- –
- The optimization problem in Equation (7) is solved by using a Back-propagation algorithm as usual. Moreover, to favor scalability, we utilize a mini-batch-based gradient descent approach with automatic differentiation (RMSprop-based optimizer is fixed).
5. Results and Discussion
5.1. Synthetic Dataset Results
5.2. Semi-Synthetic Datasets Results
5.3. Real-World Datasets Results
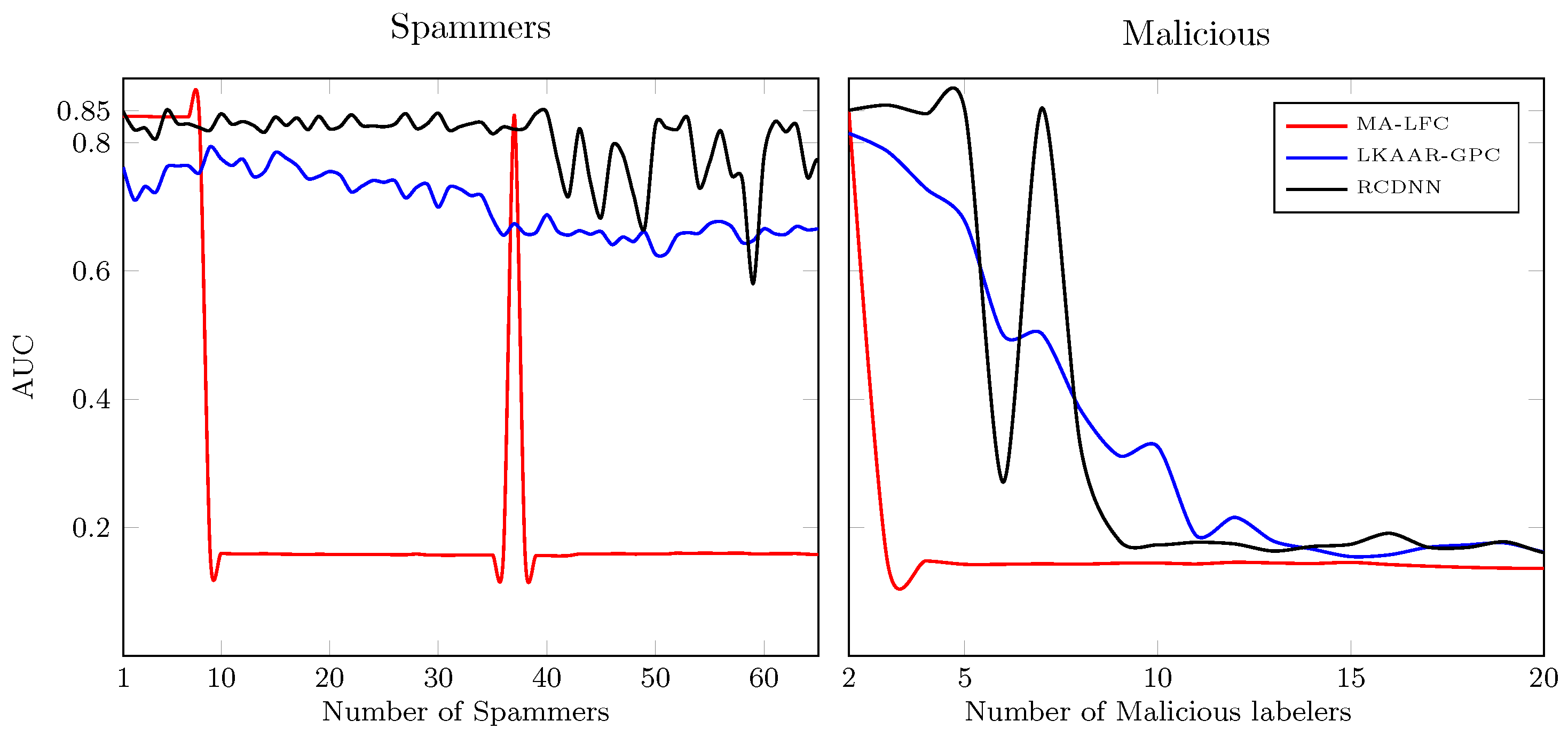
5.4. Introducing Spammers and Malicious Annotators
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gil-Gonzalez, J.; Orozco-Gutierrez, A.; Alvarez-Meza, A. Learning from multiple inconsistent and dependent annotators to support classification tasks. Neurocomputing 2021, 423, 236–247. [Google Scholar] [CrossRef]
- Raykar, V.C.; Yu, S.; Zhao, L.H.; Valadez, G.H.; Florin, C.; Bogoni, L.; Moy, L. Learning from crowds. J. Speech Lang. Hear. Res. 2010, 11, 1297–1322. [Google Scholar]
- Liu, Y.; Zhang, W.; Yu, Y. Truth inference with a deep clustering-based aggregation model. IEEE Access 2020, 8, 16662–16675. [Google Scholar]
- Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A. Cheap and fast—but is it good? Evaluating non-expert annotations for natural language tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 254–263. [Google Scholar]
- Zhang, J.; Wu, X.; Sheng, V.S. Learning from crowdsourced labeled data: A survey. Artif. Intell. Rev. 2016, 46, 543–576. [Google Scholar] [CrossRef]
- Sung, H.E.; Chen, C.K.; Xiao, H.; Lin, S.D. A Classification Model for Diverse and Noisy Labelers. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2017; pp. 58–69. [Google Scholar]
- Tao, D.; Cheng, J.; Yu, Z.; Yue, K.; Wang, L. Domain-weighted majority voting for crowdsourcing. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 163–174. [Google Scholar] [CrossRef]
- Rizos, G.; Schuller, B.W. Average Jane, Where Art Thou?–Recent Avenues in Efficient Machine Learning Under Subjectivity Uncertainty. In International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 42–55. [Google Scholar]
- Ruiz, P.; Morales-Álvarez, P.; Molina, R.; Katsaggelos, A.K. Learning from crowds with variational Gaussian processes. Pattern Recognit. 2019, 88, 298–311. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, X.; Sheng, V.S. Imbalanced multiple noisy labeling. IEEE Trans. Knowl. Data Eng. 2014, 27, 489–503. [Google Scholar] [CrossRef]
- Dawid, A.; Skene, A. Maximum likelihood estimation of observer error-rates using the EM algorithm. Appl. Stat. 1979, 20–28. [Google Scholar] [CrossRef]
- Groot, P.; Birlutiu, A.; Heskes, T. Learning from multiple annotators with Gaussian processes. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2011; pp. 159–164. [Google Scholar]
- Xiao, H.; Xiao, H.; Eckert, C. Learning from multiple observers with unknown expertise. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 595–606. [Google Scholar]
- Rodrigues, F.; Pereira, F.C.; Ribeiro, B. Gaussian Process Classification and Active Learning with Multiple Annotators. In Proceedings of the 31st International Conference on Machine Learning, Bejing, China, 22–24 June 2014; pp. 433–441. [Google Scholar]
- Morales-Álvarez, P.; Ruiz, P.; Coughlin, S.; Molina, R.; Katsaggelos, A.K. Scalable Variational Gaussian Processes for Crowdsourcing: Glitch Detection in LIGO. arXiv 2019, arXiv:1911.01915. [Google Scholar]
- Gil-Gonzalez, J.; Alvarez-Meza, A.; Orozco-Gutierrez, A. Learning from multiple annotators using kernel alignment. Pattern Recognit. Lett. 2018, 116, 150–156. [Google Scholar] [CrossRef]
- Morales-Álvarez, P.; Ruiz, P.; Santos-Rodríguez, R.; Molina, R.; Katsaggelos, A.K. Scalable and efficient learning from crowds with Gaussian processes. Inf. Fusion 2019, 52, 110–127. [Google Scholar] [CrossRef]
- Rodrigues, F.; Pereira, F.; Ribeiro, B. Sequence labeling with multiple annotators. Mach. Learn. 2014, 95, 165–181. [Google Scholar] [CrossRef]
- Albarqouni, S.; Baur, C.; Achilles, F.; Belagiannis, V.; Demirci, S.; Navab, N. Aggnet: Deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1313–1321. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, F.; Pereira, F.C. Deep learning from crowds. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Venanzi, M.; Guiver, J.; Kazai, G.; Kohli, P.; Shokouhi, M. Community-based Bayesian aggregation models for crowdsourcing. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014; pp. 155–164. [Google Scholar]
- Tang, W.; Yin, M.; Ho, C.J. Leveraging Peer Communication to Enhance Crowdsourcing. In The World Wide Web Conference; ACM: New York, NY, USA, 2019; pp. 1794–1805. [Google Scholar]
- Zhang, P.; Obradovic, Z. Learning from inconsistent and unreliable annotators by a Gaussian mixture model and Bayesian information criterion. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2011; pp. 553–568. [Google Scholar]
- Hahn, U.; von Sydow, M.; Merdes, C. How Communication Can Make Voters Choose Less Well. Top. Cogn. Sci. 2018, 11, 194–206. [Google Scholar] [CrossRef] [PubMed]
- Saul, A.; Hensman, J.; Vehtari, A.; Lawrence, N. Chained Gaussian processes. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 1431–1440. [Google Scholar]
- Rodrigo, E.; Aledo, J.; Gámez, J. Machine learning from crowds: A systematic review of its applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1288. [Google Scholar] [CrossRef]
- Yan, Y.; Rosales, R.; Fung, G.; Subramanian, R.; Dy, J. Learning from multiple annotators with varying expertise. Mach. Learn. 2014, 95, 291–327. [Google Scholar] [CrossRef]
- Wang, X.; Bi, J. Bi-convex optimization to learn classifiers from multiple biomedical annotations. IEEE ACM Trans. Comput. Biol. Bioinform. 2016, 14, 564–575. [Google Scholar] [CrossRef]
- Zhu, T.; Pimentel, M.A.; Clifford, G.D.; Clifton, D.A. Unsupervised Bayesian Inference to Fuse Biosignal Sensory Estimates for Personalising Care. IEEE J. Biomed. Health 2019, 23, 47. [Google Scholar] [CrossRef]
- Rodrigues, F.; Lourenco, M.; Ribeiro, B.; Pereira, F. Learning supervised topic models for classification and regression from crowds. IEEE Trans. PAMI 2017, 39, 2409–2422. [Google Scholar] [CrossRef]
- Hua, G.; Long, C.; Yang, M.; Gao, Y. Collaborative Active Visual Recognition from Crowds: A Distributed Ensemble Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 582–594. [Google Scholar] [CrossRef]
- Rodrigues, F.; Pereira, F.; Ribeiro, B. Learning from multiple annotators: Distinguishing good from random labelers. Pattern Recognit. Lett. 2013, 34, 1428–1436. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Hernández-Muriel, J.A.; Bermeo-Ulloa, J.B.; Holguin-Londoño, M.; Álvarez-Meza, A.M.; Orozco-Gutiérrez, Á.A. Bearing Health Monitoring Using Relief-F-Based Feature Relevance Analysis and HMM. Appl. Sci. 2020, 10, 5170. [Google Scholar] [CrossRef]
- Arias, J.; Godino, J.; Gutiérrez, J.; Osma, V.; Sáenz, N. Automatic GRBAS assessment using complexity measures and a multiclass GMM-based detector. In Proceedings of the 7th International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA 2011), Florence, Italy, 25–27 August 2011; pp. 111–114. [Google Scholar]
- Gil, J.; Álvarez, M.; Orozco, Á. Automatic assessment of voice quality in the context of multiple annotations. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 6236–6239. [Google Scholar]
- Yan, Y.; Rosales, R.; Fung, G.; Schmidt, M.W.; Valadez, G.H.; Bogoni, L.; Moy, L.; Dy, J.G. Modeling annotator expertise: Learning when everybody knows a bit of something. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 932–939. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Data Type/Application | Perspective | Expertise as a Function of the Input Space | Modeling the Annotators’ Interdependencies |
|---|---|---|---|---|
| Raykar et al., 2010 [2] | Regression-Binary-Categorical | Frequentist | ✗ | ✗ |
| Zhang and Obradovic, 2011 [23] | Binary | Frequentist | ✓ | ✗ |
| Xiao et al., 2013 [13] | Regression | Frequentist | ✓ | ✗ |
| Yan et al., 2014 [27] | Binary | Frequentist | ✓ | ✗ |
| Wang and Bi, 2016 [28] | Binary | Frequentist | ✓ | ✗ |
| Rodrigues et al., 2017 [30] | Regression-Binary-Categorical | Frequentist | ✗ | ✗ |
| Gil-Gonzalez et al., 2018 [16] | Binary | Frequentist | ✗ | ✓ |
| Hua et al., 2018 [31] | Binary-Categorical | Frequentist | ✗ | ✗ |
| Ruiz et al., 2019 [9] | Binary | Bayesian | ✗ | ✗ |
| Morales- Alvarez et al., 2019 [15] | Binary | Bayesian | ✗ | ✗ |
| Zhu et al., 2019 [29] | Regression | Bayesian | ✗ | ✓ |
| Gil-Gonzalez et al., 2021 [1] | Binary-Categorical | Frequentist | ✓ | ✓ |
| Proposal-(RCDNN) | Binary-Categorical | Frequentist | ✓ | ✓ |
| Name | Number of | Number of | Number of | |
|---|---|---|---|---|
| Features (P) | Instances (N) | Classes (K) | ||
| synthetic | 2D-PCA Iris | 2 | 150 | 3 |
| semi-synthetic | Breast | 9 | 683 | 2 |
| Bupa | 6 | 345 | 2 | |
| Ionosphere | 34 | 351 | 2 | |
| Pima | 8 | 768 | 2 | |
| Tic-tac-toe | 9 | 958 | 2 | |
| Iris | 4 | 150 | 3 | |
| Wine | 13 | 178 | 3 | |
| Segmentation | 18 | 2310 | 7 | |
| Western | 7 | 3413 | 4 | |
| real-world | Voice | 13 | 218 | 2 |
| Music | 124 | 1000 | 10 | |
| Polarity | 1200 | 10,306 | 2 |
| Approach | Brief Description |
|---|---|
| GPC-GOLD | A GPC using the real labels (upper bound). |
| GPC-MV | A GPC using the majority voting of the labels as the ground truth. |
| MA-LFC [2] | A LRC with constant parameters across the input space. |
| MA-DGRL [32] | A multi-labeler approach that considers as latent variables the annotator performance. |
| MA-MAE [37] | A LRC where the sources parameters depend on the input space. |
| MA-GPC [14] | A multi-labeler GPC, which is an extension of MA-LFC by using a non-linear approach. |
| KAAR [16] | A kernel-based approach that employs a convex combination of GPC, it codes the labelers dependencies. |
| LKAAR-(LR,SVM,GPC) [16] | A localized kernel alignment-based annotator relevance analysis using a combination of LRC, SVM, GPC respectively. It models both the annotators dependencies and the relationship between the labelers’ behavior and the input features. |
| Method | Breast | Bupa | Ionosphere | Pima | Tic-Tac-Toe | Iris | Wine | Segmentation | Western | Average AUC-Acc | Average Ranking | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPC-GOLD | AUC[%] | - | ||||||||||
| Acc[%] | - | |||||||||||
| GPC-MV | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| MA-LFC | AUC[%] | |||||||||||
| Acc[%] | * | * | * | |||||||||
| MA-DGRL | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| MA-MAE | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| MA-GPC | AUC[%] | |||||||||||
| Acc[%] | * | * | * | |||||||||
| KAAR | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| LKAAR-LR | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| LKAAR-SVM | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| LKAAR-GPC | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| RCDNN (ours) | AUC[%] | |||||||||||
| Acc[%] | * | * | * |
| Method | Breast | Bupa | Ionosphere | Pima | Tic-Tac-Toe | Iris | Wine | Segmentation | Western | Average AUC-Acc | Average Ranking | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPC-GOLD | AUC[%] | - | ||||||||||
| Acc[%] | - | |||||||||||
| GPC-MV | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| MA-LFC | AUC[%] | 6.22 | ||||||||||
| Acc[%] | * | 6.11 | ||||||||||
| MA-DGRL | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| MA-MAE | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| MA-GPC | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| KAAR | AUC[%] | |||||||||||
| Acc[%] | ||||||||||||
| LKAAR-LR | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| LKAAR-SVM | AUC[%] | |||||||||||
| Acc[%] | * | |||||||||||
| LKAAR-GPC | AUC[%] | |||||||||||
| Acc[%] | * | * | ||||||||||
| RCDNN (ours) | AUC[%] | |||||||||||
| Acc[%] | * | * |
| AUC([%]) | |||||||
|---|---|---|---|---|---|---|---|
| Method | Voice Dataset | Polarity Dataset | Music | Average AUC | Average Ranking | ||
| G | R | B | |||||
| GPC-GOLD | - | ||||||
| GPC-MV | |||||||
| MA-LFC | |||||||
| MA-DGRL | |||||||
| MA-MAE | |||||||
| MA-GPC | |||||||
| KAAR | |||||||
| LKAAR-LR | |||||||
| LKAAR-SVM | |||||||
| LKAAR-GPC | |||||||
| RCDNN (ours) | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gil-González, J.; Valencia-Duque, A.; Álvarez-Meza, A.; Orozco-Gutiérrez, Á.; García-Moreno, A. Regularized Chained Deep Neural Network Classifier for Multiple Annotators. Appl. Sci. 2021, 11, 5409. https://doi.org/10.3390/app11125409
Gil-González J, Valencia-Duque A, Álvarez-Meza A, Orozco-Gutiérrez Á, García-Moreno A. Regularized Chained Deep Neural Network Classifier for Multiple Annotators. Applied Sciences. 2021; 11(12):5409. https://doi.org/10.3390/app11125409
Chicago/Turabian StyleGil-González, Julián, Andrés Valencia-Duque, Andrés Álvarez-Meza, Álvaro Orozco-Gutiérrez, and Andrea García-Moreno. 2021. "Regularized Chained Deep Neural Network Classifier for Multiple Annotators" Applied Sciences 11, no. 12: 5409. https://doi.org/10.3390/app11125409
APA StyleGil-González, J., Valencia-Duque, A., Álvarez-Meza, A., Orozco-Gutiérrez, Á., & García-Moreno, A. (2021). Regularized Chained Deep Neural Network Classifier for Multiple Annotators. Applied Sciences, 11(12), 5409. https://doi.org/10.3390/app11125409