1. Introduction
During the last decade, the ease of access and ubiquity of online social media and online social networks (OSNs) has rapidly changed how we are used to searching, gathering, and discussing any kind of information. Such a revolution, as the promise of equality carried by the World Wide Web since its first appearance, has enriched us all. It has made geographical distances vanish and empowered all internet users, letting their voices be heard [
1,
2]. However, at the same time, it has also increased our chances of encountering misleading behaviors. Indeed, the unlimited freedom of generating contents and the unprecedented information flooding we are used today are seeds that, if improperly managed, can make online platforms into fertile grounds for polluted realities [
3,
4]. Among them, several studies [
5,
6,
7] claim that overpersonalization enhanced by OSNs, leveraging the human tendency to interact with like-minded individuals, might lead to a self-reinforcing loop confining users in echo chambers. Although a formal definition of the phenomenon is still missing, an echo chamber (EC) is commonly defined as a polarized situation in which beliefs are amplified or reinforced by communication repetition inside a closed system and insulated from rebuttal.
Such phenomenon might prevent the dialectic process of “thesis–antithesis–synthesis” that stands at the basis of a democratic flow of opinions, fostering several related alarming episodes [
8] (e.g., hate speech, misinformation, and ethnic stigmatization). Furthermore, since discussions, campaigns, and movements taking place in online platforms also resonate in the physical world, it is no more possible to relegate their effect only to the virtual realm. For such reasons, a large body of scientific works [
9,
10,
11,
12,
13,
14] has addressed the issue of echo chamber detection over the last decade, moving from content-only characterization toward a structural/topological analysis of the phenomenon. However, the lack of an actionable definition of echo chambers and a standard strategy to support their identification has led to conflicting experimental observations [
15]. Further, most of the abovementioned works leverage platform-specific features or resources to identify ECs, thus strongly limiting their generalizability to the entire range of social media platforms.
Moving from such literature, the purpose of this paper is twofold. Firstly, we propose a general framework to identify echo chamber on OSNs built on top of features they commonly share. Secondly, we aim to enrich the body of knowledge on EC detection, presenting a detailed case study on Reddit (i.e., the least explored social platform from an EC point of view).
Starting from online social platform data, the approach to detect echo chambers presented in this paper can be summarized into a four-stage pipeline. (i) Since opinion polarization generally arises in the presence of topics that trigger a significant difference of opinions, we propose starting from controversial issue identification. (ii) Then, because an EC key feature is the homogeneous group thinking, the second step consists of inferring users’ ideology on the controversy from posts shared on the platform. (iii) People inside an EC tend to interact with like-minded individuals, thus insulating themselves from rebuttal. To assess this requirement, we propose to define the users debate network retrieving all posts’ comments and labeling users with their leaning on the controversy. (iv) Lastly, the fourth step consists of homogeneous meso-scale users’ clusters identification. In other words, we look for areas of the network that are homogeneous from an ideological and topological point of view.
Subsequently, we provide a case study of the proposed framework on Reddit. We focus on the debate between Pro-Trump supporters and Anti-Trump citizens during the first two and a half years of Donald Trump’s presidency and look for ECs among three sociopolitical topics (i.e., gun control, minorities discrimination, and political discussions). We find that Gun Control users, even if they show a strong tendency toward Pro-Trump beliefs, do not mostly insulate themselves in polarized communities. On the other hand, for the topics of minorities discrimination and Political Sphere, we are able to detect homogeneous ECs among different semesters. Moreover, we assess their stability and consistency over contiguous semesters, finding that ECs members have a high probability of interacting with like-minded individuals over time.
The rest of the paper is organized as follows. In
Section 2, we discuss the literature involving echo chamber detection first in more general terms, then focusing on the echo and chamber dimension of the phenomenon.
Section 3 provides an overview of our four-step framework for EC detection, describing its rationale and providing examples of its applicability to multiple platforms. Then, in
Section 4, we test such a framework in a specific case study involving the identification and analysis of echo chambers on Reddit. We conclude in
Section 5 with a discussion on results and directions for future work.
3. Detecting Echo Chambers in Online Social Platforms
The lack of a formal and actionable echo chamber definition and of a standard strategy to support their identification has, over the years, led to conflicting experimental observations, namely scientific studies whose comparison is rather unfair due to their hard-wiring to platforms’ specific characteristics. In this regard, here we propose a general framework to detect echo chambers built on top of features commonly shared by most of online social platforms.
Before discussing our framework, it is important to fix—in an actionable way—the object of our investigation along with its expected properties.
Definition 1 (Echo Chamber). Given a network describing users’ interactions centered on a controversial topic, an echo chamber is a subset of the network nodes (users) who share the same ideology and tend to have dense connections primarily within the same group.
Following 1, to assess an EC’s existence we cannot rely on a single user’s digital traces (i.e., following a micro-scale approach), nor suppose that all users in the network belong to a polarized community (i.e., assuming a macro-scale approach). The proposed EC definition relies on meso-scale topologies. We focus on this particular definition of EC since we are interested in the role that group dynamics play in the increase in polarization. Moreover, we believe that it is quite unrealistic that all the users involved in a controversial debate insulate themselves in an echo chamber. Our framework composes of four steps to identify EC starting from online social platform data, namely (i) controversial issue identification; (ii) users’ ideology inference; (iii) debate network construction; (iv) homogeneous meso-scale users’ clusters identification.
In this section, we provide an overview of each of such steps, describing their rationale and supporting our claim of framework generality by providing examples of its applicability to multiple platforms. Subsequently, in
Section 4 we propose a specific case study involving the identification and analysis of echo chambers in a well-known online social platform, Reddit. There, we describe a specific instance of the proposed framework and discuss the choices made while implementing its pipeline.
3.1. Step 1. Controversial Issue Identification
The first step in our pipeline consists in identifying a controversial issue. With this terminology, we refer to questions, subjects, or problems that can create a great difference of opinion among people discussing it. Of course, they can include topics that may have political, social, environmental, or personal impacts on a community. We rely on controversial issues due to the fact that the polarization of opinions generally emerges in such situations, turning divergent attitudes into ideological extremes [
3].
Controversial issues are debated both in offline and online realms. However, online social platforms are probably the most frequently used open space for discussions. Further, their structure and functionalities make quite easy to identify online debates about a wide range of different issues. For instance, on Twitter, it is possible to search for a specific hashtag to discover users debating a topic. Further, both Reddit and Gab, thanks to their structure divided into subreddits or groups, make it even simpler. Additionally, they allow searching for topic-related communities (e.g., gaming, politic, entertainment) via several lists available on the platforms. Accordingly, it is also possible to retrieve such kinds of data, leveraging platforms API (e.g., Twitter (Twitter API:
https://developer.twitter.com/en/docs/twitter-api (accessed on 1 June 2021)), Reddit and Gab (Reddit and Gab API:
https://github.com/pushshift/api) (accessed on 1 June 2021)), or external released datasets (DocNow Catalog of Twitter Datasets:
https://catalog.docnow.io/ (accessed on 1 June 2021)).
3.2. Step 2: Users’ Ideology Inference
Throughout the slightly different definitions of echo chambers given over the years, the concept of homogeneous group thinking always emerges. Indeed, once we have identified a controversial issue and users discussing it, the second step of our approach consists of estimating users’ leaning on the controversy. Following the rationale explained in
Section 2.2, we rely on users’ posts and comments to infer users’ ideology. Indeed, all online social platforms provide some sort of text publishing as a basic functionality to their users (e.g., Twitter, Facebook, Reddit, Gab). Thus, we model the task of predicting the ideology of a user on a controversy as a text classification problem. In other words, given a controversial topic (e.g., the debate around Gun Control), we encode the textual content of users’ posts into a low-dimensional vector representation and use it to train a classifier aimed at predicting users’ ideology (e.g.,
Anti-Gun,
Pro-Gun). Notice that the selection of one text classification model over the other strictly depends on data source peculiarities. Accordingly, it is of utmost importance to perform ad hoc model selection and fine-tuning to consider context-specific features. For instance, the size of available data is a crucial part of selecting a model. Usually, Deep Learning models need a huge amount of data to learn model parameters as well as impart generalization. However, pre-trained models such as Transformers are able to target the classification task even with low data resources thanks to their extensive pre-training. Another aspect to consider is whether we are interested in capturing sentence-level semantics or, rather, in extracting specific information from the sentence. In the first case, methods able to model long-range dependencies are the most suitable (e.g., LSTM, Transformer models), while in the second, architecture able to extract position-invariant features (e.g., CNN) are preferable [
47].
Moreover, a controversy may not necessarily induce binary opinions about it, e.g., wrong/right, pro/against. Suppose, for instance, that we are interested in exploring the political debate in the US. Beyond the simple Republican–Democrat analysis, we can identify other popular ideologies such as Liberalism, Conservatism, Libertarianism, and Populism. Accordingly, in such a scenario, our framework can be instantiated with a multi-class text classifier.
Since we tackle a supervised approach, it requires a ground truth of sample posts labeled with respect to their opinion on the controversy. Even if it seems a tricky step in our pipeline, it is not so difficult to find among different online social platforms, publicly known polarized user collectors in which subscribed users support a specific leaning. For instance, we may rely on Twitter lists, Facebook pages, Reddit subreddits, or Gab groups. Further, on those online platforms in which the majority of users do not use a nickname (e.g., Twitter and Facebook), we may also rely on public figures supporting a specific idea to define a ground truth. For example, following the previous example on the US political debate, we may retrieve all posts shared by the most prominent exponents of those parties.
3.3. Step 3: Debate Network Construction
Once we have identified a set of users labeled with respect to their ideology on the controversy, the next step consists of defining their interaction network. The concepts of exposure, affiliation, and interaction with like-minded individuals is a crucial aspect of echo chambers. Accordingly, it becomes necessary to define when an interaction between two users takes place. Most of the previous approaches [
19,
20,
48] rely on the follow or friend relationship to define the connections among users. However, not all online social platforms allow discovering who follows whom and, thus, retrieving such information, e.g., Reddit. Further, we believe that it is quite unrealistic that a user has a direct relationship with all the users they follow or that consume all their contents.
For such reason, we build the interaction graph among the previously labeled users through the who–comment–whom relation, since such a feature is available across all the main online platforms, as in the case of textual contents. Formally, we define the interaction network as a graph where each node represents a user, and two nodes u and v are connected if and only if u directly replies to a post or a comment of v or vice versa. Each node u is also associated with a discrete label where n is the number of sides/ideologies in the considered controversy. Further, each edge is described by a weight that represents the number of interactions between two users. In our case study, we model the interaction network as an undirected graph. Depending on the specific task it would make sense to use a directed network instead; however, such a choice mainly depends on how strict is the given definition of echo chamber. In our rationale, we believe that the echo chamber components should somehow be insulated from opposite views. Thus, neither incoming information from the rest of the network nor outgoing ones are allowed to a certain extent.
3.4. Step 4: Homogeneous, Meso-Scale, Users’ Clusters Identification
Up to this step, we have described how to label a set of users with respect to their leaning on controversy and how to define their interaction network. In other words, we have identified the basic bricks to discuss both the echo and the chamber dimensions of a given phenomenon. However, conforming to the proposed Definition 1, we handle echo chambers as meso-scale topologies. Thus, we aim to detect subsets of nodes in the network that are homogeneous from an ideological and topological point of view.
As stated in
Section 2.3, we model such a problem relying on a specific instance of the CD problem, namely Labeled Community Detection. Among the LCD algorithms, we leverage Eva [
49], a bottom-up low complexity algorithm designed to identify network meso-scale topologies by optimizing structural and attribute-homophilic clustering criteria. From a structural point of view, Eva leverages the modularity score (Definition 2) to incrementally update community membership. Such an update is then weighted in terms of cluster Purity (Definition 3), another function tailored to capture the ideological cohesion of a community.
Definition 2 (Modularity). Modularity is a quality score that measures the strength of the division of a network into modules. Formally:where m is the number of graph edges, is the entry of the adjacency matrix for the degree of and identifies an indicator function taking value 1 iff belong to the same community c, 0 otherwise. Definition 3 (Purity). Given a community , its Purity is the product of the frequencies of the most frequent labels carried by its nodes. Formally: where A is the label set, is a label, is an indicator function that takes value 1 iff .
Once Eva has identified the candidate communities, we now discuss how to evaluate them to determine to what extent a community qualifies as an echo chamber. Since the analyzed phenomenon consists both of the echo and the chamber dimensions, we propose to evaluate them relying respectively on Purity and on Conductance (Definition 4).
Definition 4 (Conductance). Given a community , its Conductance is the fraction of total edge volume that points outside the community.where is the number of community nodes and is the number of community edges. Thus, we propose to set ideological and topological constraints on and by means of two thresholds i.e., and where and can be tuned according to the strictness of the definition of echo chamber. For instance, in the Reddit case study, we set the Purity score to make sure that most of the users in an echo chamber share the same ideological label. Meanwhile, for Conductance, we set a threshold equal to 0.5 to ensure that more than half of the total edges remain within the community boundaries.
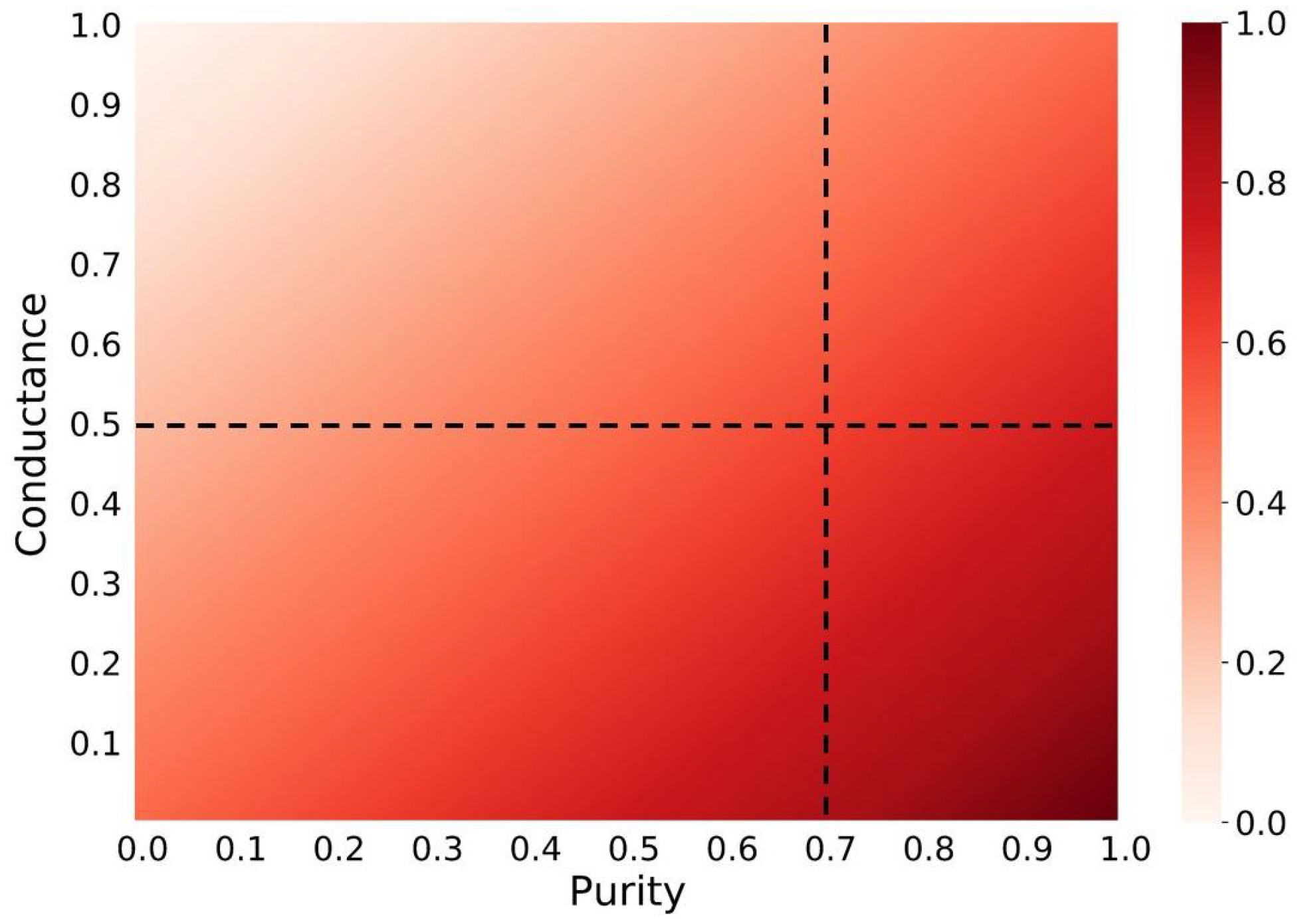
Further, we can also define the risk for a community to be an echo chamber through a function that takes into account both Purity and Conductance. The most straightforward function is the difference between the two terms. In
Figure 1 we show the results obtained by subtracting Conductance from Purity and then normalizing values in a range from 0 to 1. Intuitively, we notice that such a risk is maximized when Purity is equal to 1 and Conductance equal to 0.
Given the theoretical foundation set in this section, in the following we test our proposed framework on Reddit and discuss each of the pipeline steps.
4. Reddit: Politics, Gun Control, and Minorities Discrimination
This section discusses how to apply our proposed approach to Reddit data and provide further insights on the results. As stated by its slogan
‘The front page of the internet’, Reddit is a social platform that allows its users to post content to individual forums called
subreddits, each dedicated to a specific topic. Currently, it is the nineteenth most visited website on the internet and the seventh in the USA (
https://www.alexa.com/topsites (accessed on 1 June 2021)). We decide to build our approach upon Reddit mainly because it is the least explored from an echo chamber point of view. Further, since users can write anonymously and posts are not limited in length, this platform is particularly active in controversial discussions [
50]. The data and the code used for this case study are available on a dedicated Github repository (
https://github.com/virgiiim/EC_Reddit_CaseStudy (accessed on 1 June 2021)).
4.1. Controversial Issue Identification
To proceed with our approach, we first have to select a controversial topic, i.e., an issue in which single attitudes tend to diverge into ideological extremes. For such a purpose, we decide to focus on the debate between Trump supporters and Anti-Trump citizens during the first two and half years of Donald Trump’s presidency (i.e., January 2017–July 2019). Indeed, the political rise of Donald Trump has further exacerbated the divide between Republicans and Democrats, making the debate even more polarized and uncivil [
51]. To deal with this, we built a ground truth of polarized posts with respect to Pro-Trump and Anti-Trump beliefs, then we identified discussions themes likely to favor the formation of chambers related to such dichotomic attitude. In particular, we look for subreddits related to sociopolitical issues—
Gun Control,
minorities discrimination—and general discussions on the
Political Sphere.
We retrieve Reddit data through the Pushshift API [
52] that offers aggregation endpoints to explore Reddit activity from June 2005 to nowadays. More details about the ground truth dataset as well as the sociopolitical ones are given below. Further, in
Table 2 we provide a description of each dataset in terms of number of selected subreddits, number of posts, and number of users.
For each selected submission, we collect the , , , and fields, respectively, the identifier, the author username, the content, and the title of the submission ( and where were pseudonymised through the adoption of an irreversible hash function during data collection). We merge contents and titles in a unique set to use as input for text classifier, because the of a post may be empty or just a reference to the itself. By doing so, we make sure to have text capturing what the user is actually trying to convey. Then, we assign to each post a label of 1 if it belongs to the Pro-Trump subreddit, 0 otherwise. Further, we notice that several posts are composed of only a few words. This is probably because, during data extraction, we only select textual data, removing all multimedia content related to each submission. To avoid affecting classifier performance, we remove all posts shorter than six words from our original dataset.
Sociopolitical Topics. For each of the three topics in which we want to find evidence of an EC, we selected several subreddits via Reddit List. In such a way, we attempt to cover different points of view. For instance, for Gun Control we select both subreddits that expressly support gun legalization and those against it. Meanwhile for minorities discrimination, we identify groups that promote gender/racial/sexual equality and those showing more conservative attitudes. Last, concerning Political Sphere we try to cover different US political ideologies such as Republicans, Democrats, Liberals, and Populists. Then, for each of them, we define two datasets composed of all the posts and comments shared from January 2017 to July 2019. Regarding posts, we apply the same pre-processing of the ground truth, while for comments, we retrieve all the fields necessary to define the interaction network. These include , , , , respectively, the comment’s identifier, its author, the identifier of the post that this comment is in, the identifier of the parent of this comment.
4.2. Users’ Ideology Inference
Once we have gathered data, the second step consists of inferring users’ ideology on the controversy. As stated in
Section 3.2, we model the task of predicting the political alignment of users’ posts as a text classification problem. Since we consider two sides of the controversy in this case study (i.e., Pro-Trump and Anti-Trump), we model the text classification task as a binary problem.
Among the suitable NLP approaches discussed in
Section 2.2, we test two different Deep Learning models (i.e., LSTM and BERT) which have been widely used to predict the political leaning both of OSN contents [
53,
54,
55] and news articles [
56,
57]. Concerning LSTM, we have already carried out some experiments in a preliminary work [
58]. In the following, for both models, we discuss the updated experimental setup, the model evaluation phase, and the prediction results on sociopolitical topics.
Experimental Setup. To train and test both models, we rely on the Polarized Ground Truth dataset defined in
Section 4.1. To create the training and validation sets, we randomly select
of the whole dataset (242,762 posts) in such a way to guarantee the balancing between the Pro-Trump and Anti-Trump classes. The remaining
(60,000 posts) is used as the test set. During model selection, we perform a 3-fold Cross-Validation trying different hyper-parameters configurations of both models. For LSTM, we varied the number of LSTM units
as well as the type of word embeddings with a fixed dimension of 100, i.e., GloVe pre-trained word embeddings and embeddings directly learned from the texts. In both scenarios, we vectorize each input submission creating a lexicon index based on word frequency, where 0 represents padding: indexes are assigned in descending order of frequency. Moreover, since the Out-of-Vocabulary (OOV) rate is rather low (i.e., 1.36%), we mark OOV tokens with a reserved index. In all settings, we use a dropout regularization of
, adam optimizer, the sigmoid activation function, and as loss function, the binary cross-entropy. We obtain the best performances on the validation set using GloVe word embeddings and 128 LSTM units, obtaining an average accuracy of
. For BERT, we leverage the pre-trained model
presented by Devlin et al. [
39]. Specifically, we rely on the PyTorch implementation publicly released by Hugging Face [
59]. Then, we varied the length of the input
, the learning rate
, and the type of text pre-processing, i.e., with or without punctuation. We obtain the best results on the validation set, leaving punctuation, 512-token input (note that 512 tokens is also the maximum input length supported by BERT; nevertheless, in this case study, we deal with OSN posts that tend to be relatively short, i.e., only 0.4% of total posts are longer than the 512 limit), and a learning rate of
, reaching an average accuracy of
. Comparing the two models’ validation results, we notice that BERT reaches a definitely higher accuracy than LSTM. Thus, we select such a model for this case study.
Model Evaluation. We assess BERT performances on the test set, obtaining an accuracy of
. Then, to verify to what extent the model is able to generalize on less polarized posts, we further evaluate it on the sociopolitical datasets. However, in this scenario, we do not have any labeled data with respect to Trump’s beliefs. Thus, we search for users belonging to our ground truth datasets, label them accordingly, and then apply the model to their posts.
Table 3 shows model evaluation results for the test set and the three topics. Even if the model suffers from the domain change, it can generalize quite well, reaching an accuracy greater than
among all sociopolitical datasets. Despite the task of predicting the political affiliation of user/post having been successfully performed on popular OSNs (e.g., Facebook [
60], Twitter [
53,
54,
55]), we have not found any similar work on Reddit with which to compare our results.
Predictions on Sociopolitical Topics. Once the expected accuracy of our model was evaluated, we applied it to each of the sociopolitical datasets in order to infer posts’ leaning on the controversy for the entire population. For each post, we obtain model predictions ranging from 0 to 1 (i.e., the model confidence), where 1 means that the post aligns itself with Pro-Trump ideologies while 0 with Anti-Trump ones. Lastly, for each user
u belonging to a specific topic we compute their
leaning score,
, as the average value of their post’s leaning as follows:
where
is a post shared by a user
u and
is the cardinality of the set of
u’s posts. In
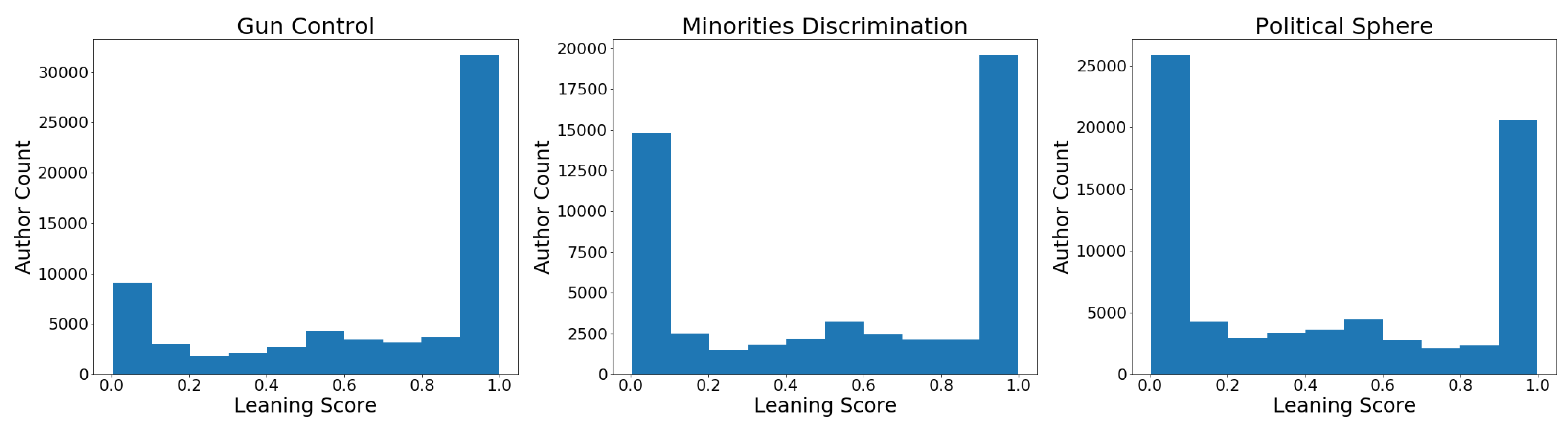
Figure 2 we show the authors’ leaning score distribution for each topic. Both
minorities discrimination and
Political Sphere follow the typical U-shaped distribution of polarized issue, i.e., underlying a neat prevalence of extreme values. Thus, we can assert that in these two topics, we can find both sides of the controversy. On the other hand,
Gun Control users are strongly polarized with respect to Pro-Trump ideas and less sided with Anti-Trump citizens.
4.3. Debate Network Construction
During the previous step, we observed that, across different sociopolitical issues, most users tend to assume a polarized position on the controversy rather than a moderate one. Starting from such insight provided by the analyzed data, we now have to answer a more specific question: Do the observed polarized users also tend to interact prevalently with like-minded individuals, or are they open to discussion with peers sharing opposing views?
To answer such a question we define, for each topic, a proper users’ debate network. To take into account the evolution of ideologies in time, we look for echo chambers on semester basis rather than in the whole period. Indeed, users may change their opinion on the controversy during two and a half years.
Accordingly, we define users’ interaction network for each topic and semester following the approach proposed in
Section 3.3. Each node of the network represents a user, and an edge between two users exists if one directly replies to a post or a comment of the other. We set each edge weight to represent the total number of comments exchanged between two users. We also label users (i.e., nodes) with their
leaning score . To do so, we discretize such leanings into three intervals:
Anti-Trump if
0.3;
Pro-Trump if
0.7; while
Neutral if 0.3 <
< 0.7. We add the third label, mainly because it is quite possible that some posts are not politically charged and thus not openly sided in the controversy. In
Table 4, for each topic we provide average statistics of the networks across the five considered semesters.
4.4. Homogeneous, Meso-Scale, Users’ Clusters Identification
Once we have defined labeled interaction networks, we focus on discovering if they present cohesive meso-scale topologies both from a structural and ideological perspective. Following the rationale in
Section 3.4, we rely on Eva, a CD algorithm belonging to Labeled Community Detection approaches. Eva is tailored to detect communities both maximizing their internal density through Modularity (see Definition 2) and their labels homogeneity relying on Purity (see Definition 3).
Accordingly, we apply Eva to each topic and semester, thus identifying our candidate communities. Then, we evaluate them by means of Conductance (see Definition 4) and Purity. In this case study, we set the Conductance score
to ensure that more than half of the total edges remain within the community boundaries. Meanwhile, for Purity, we set a threshold equal to 0.7 to make sure that most of the users in an echo chamber share the same ideological label. In
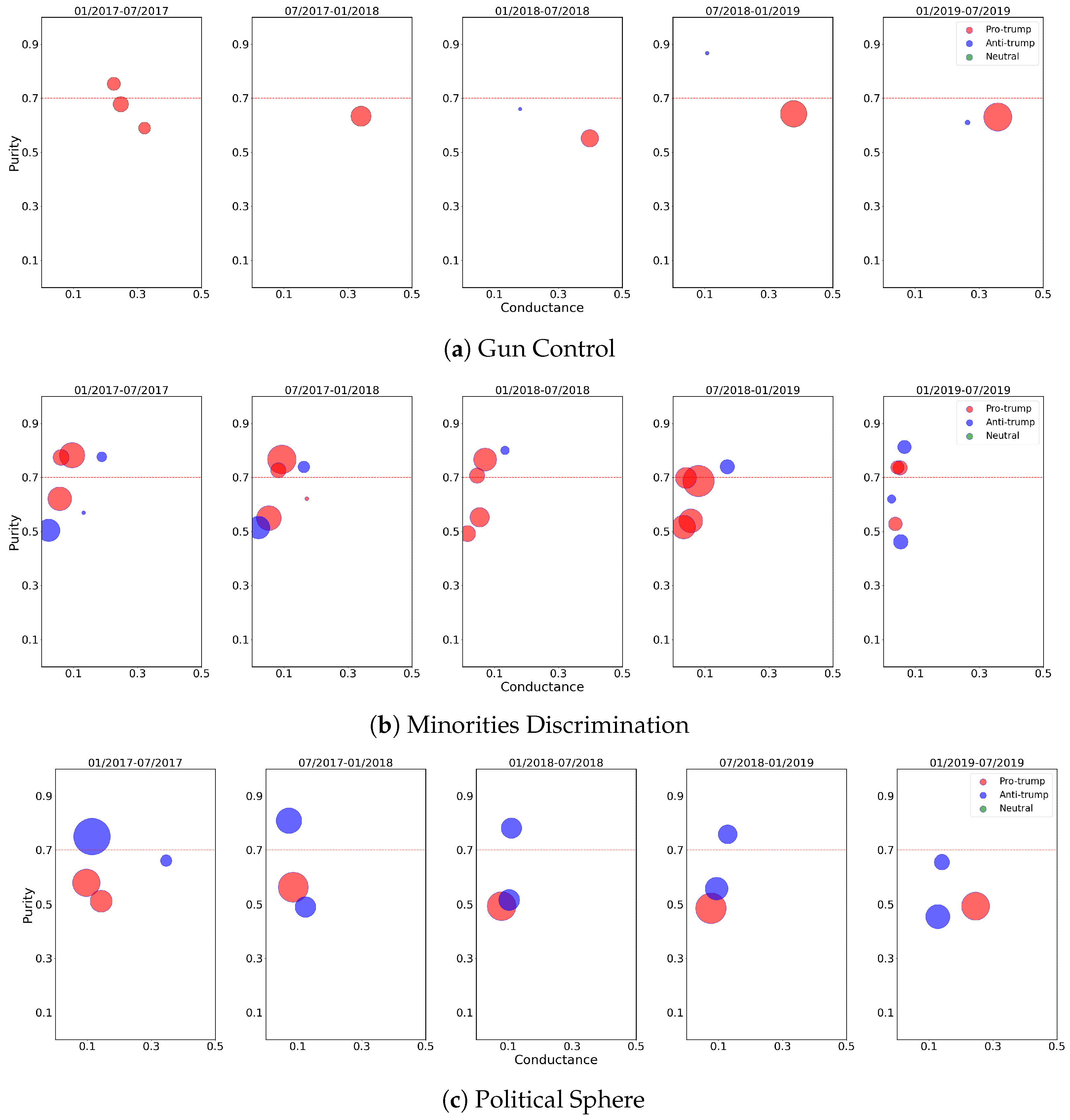
Figure 3 we show the communities evaluation process for
Gun Control,
minorities discrimination, and
Political Sphere topics. In each scatter plot, we can classify as echo chambers those communities that lie above the horizontal red line.
The difference in results between the three topics is stark.
Gun Control (
Figure 3a) does not present strongly polarized communities among different semesters. Indeed, on average, only 6.7% of total users fall in an echo chamber. Among them, 97.1% of members show a Pro-Trump tendency (i.e., in the first semester), while only the 2.9% have an Anti-Trump leaning (i.e., in the fourth semester). Moreover, we can observe that Pro-Trump users tend to form communities composed of like-minded individuals, even if not sufficiently ideologically homogeneous. Instead, Anti-Trump users mainly interact with the opposite side of the controversy, probably because they are a minority with respect to the totality of users (see
Table 4). As regards
minorities discrimination (
Figure 3b), the overall scenario is definitely different. Indeed, on average, more than half of total users (i.e., 53.8%) are trapped in echo chambers. Further, we can observe in all semesters both Pro-Trump and Anti-Trump ECs, even if the first group outnumbered the second (i.e., 85% of Pro-Trump ECs members and 15% of Anti-Trump ones). Moreover, different from the other two topics, this one presents more than one EC of the same ideological leaning. On the other hand,
Political Sphere (
Figure 3c) shows a strong tendency toward Anti-Trump polarization (i.e., 23.3% of total users belong to Anti-Trump ECs). Indeed, Pro-Trump individuals are not ideologically homogeneous enough to be classified as echo chambers.
Furthermore, we have also noticed an interesting trend among all topics and semesters: Neutral users do not fall either in an EC or form a community with a Neutral majority. We further investigate such an aspect to verify if they tend to communicate prevalently with Pro-Trump or Anti-Trump users. We found that both in minorities discrimination and Political Sphere topics, ~80% of Neutral users join Pro-Trump communities while, concerning Gun Control, they are equally distributed among opposite-side communities. Following such results, we can assume that in this case study, having a Neutral leaning score means being somewhat undecided.
4.5. EC Analysis: Stability and Persistence over Time
Up to this point, we have explored users’ leanings on the controversy (see
Figure 2) and echo chambers (see
Figure 3) in static temporal snapshots. Now, we are interested in analyzing their stability and consistency through time. In other words, we aim to answer the following questions:
- i.
How do users’ ideology evolve over time? Are users stable and consistent with the same ideology, or do they tend to change opinion?
- ii.
How do echo chambers evolve over time? Do members tend to fall again in a polarized community, or are they open to debate with opposite-leaning users?
To answer both questions, we model such issues in terms of transition probabilities. In other words, for each user, we compute their probability to move from statei to j over contiguous semesters. In the first question, state stands for user ideology (i.e., Pro-Trump, Anti-Trump, and Neutral). In the second one, with state we refer to the leaning of community the user belongs to (e.g., Pro-Trump EC, Anti-Trump EC, Pro-Trump community, ...).
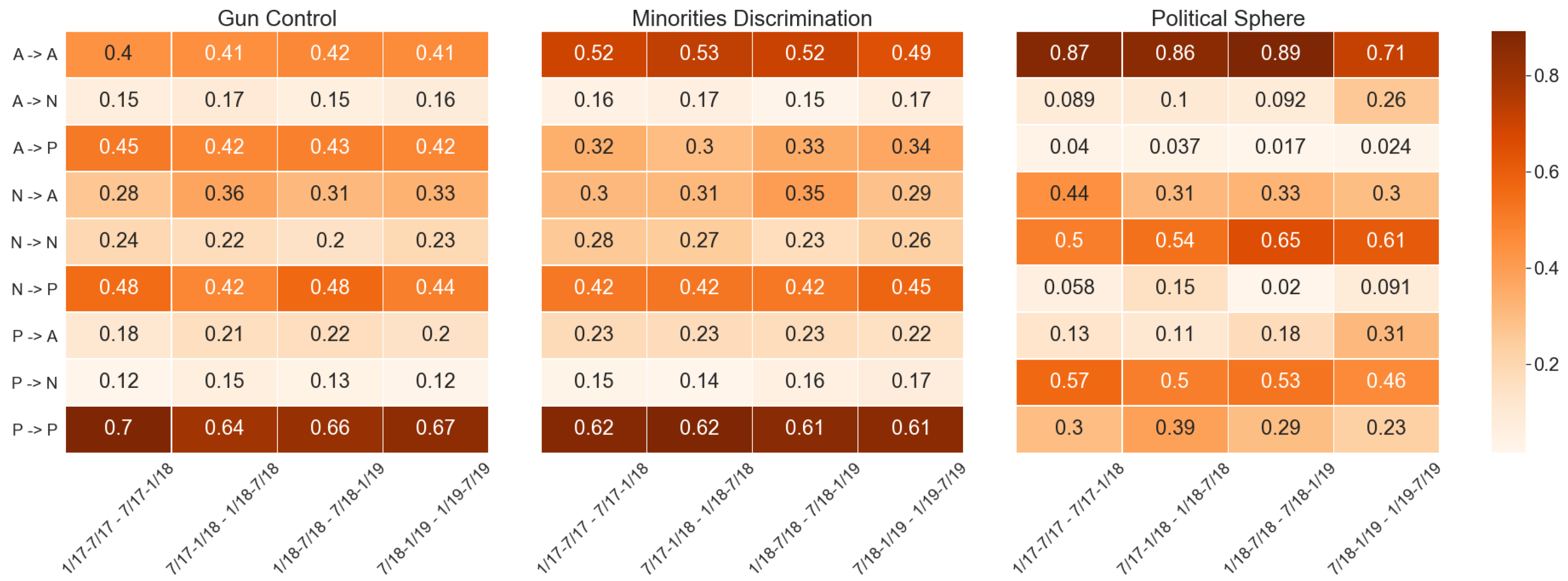
i. Ideology Stability over Time. In the heat maps in
Figure 4, we show the stability of users’ ideology over contiguous semesters. As regards
Gun Control, transition probabilities could explain why we have not found ECs or communities composed by a majority of Anti-Trump users. Indeed, users have an equal probability of remaining in their position and changing their leaning toward a Pro-Trump one, thus proving to be not strongly polarized. On the contrary, most Pro-Trump users seem to be rooted in their position, with a probability to remain in their state greater than 0.64 in all semesters. For
minorities discrimination, the scenario is quite similar. Indeed, even if Anti-Trump users are more polarized across semesters (i.e.,
), some of them change their opinion in favor of the opposite side of the controversy. On the contrary,
Political Sphere users aligned with Trump have a strong tendency to move to a Neutral position. However, except for the last couple of semesters, it is pretty unlikely that they change their leaning to Anti-Trump. Instead, with the exception of the last couple of semesters, Anti-Trump users are the ones with both the highest probability to remain in their state and lower to change in favor of Pro-Trump ideas (i.e., respectively
and
). Lastly, for what concerns Neutral users, both
Gun Control and
minorities discrimination insights confirm our hypothesis that they are somewhat undecided. Indeed, in both cases, they have a higher probability of changing state instead of remaining Neutral. On the other hand,
Political Sphere Neutral users are definitely more rooted in their position with a tendency toward Anti-Trump beliefs.
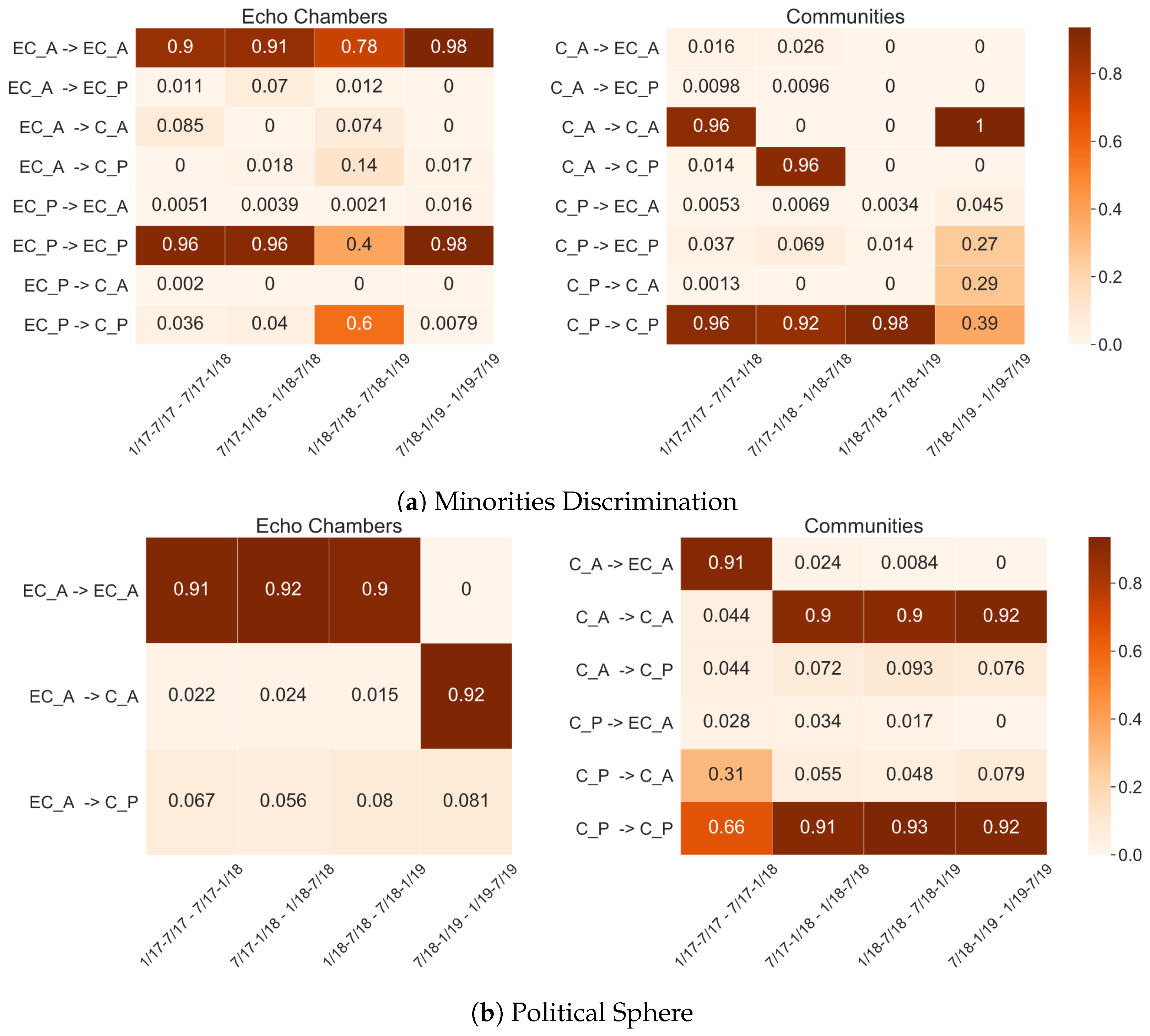
ii. Echo Chamber Stability over Time. To analyze ECs’ consistency over time, we only take into account those two topics (i.e., minorities discrimination, Political Sphere) in which we have detected an EC across different semesters. Indeed, Gun Control users fall in a Pro-Trump EC only in the first semester, thus proving to be not stable over time. Additionally, in this analysis, we do not consider the Neutral group of users since they never form an EC or aggregate in a community with a Neutral majority.
We decide to compute transition probabilities both for echo chambers (
EC) and communities that do not satisfy ideological or topological constraints (
C). In the heat maps, we show obtained results for
minorities discrimination (
Figure 5a) and
Political Sphere (
Figure 5b). Differently from ideologies, in both topics, echo chambers prove to be strongly consistent over semesters.
Indeed, in most samples, ECs have a high probability to not change state, thus remaining in the same-leaning polarized systems. Further, in the few cases in which ECs change state, they never move to a community with most opposite-leaning users. On the contrary, communities are less stable over contiguous semesters. Moreover, with respect to echo chambers, they show a higher probability to change state in favor of the opposite side of the controversy.
5. Discussion, Conclusions and Future Works
In this work, we proposed a formal definition of echo chamber and a general framework to assess their existence in online social networks. In doing so, we performed two choices that make our study quite different from the previous. Firstly, we handle echo chambers as meso-scale topologies. In other words, to detect ECs we do not rely on a single user’s digital traces as in [
14,
16] (i.e., following a
micro-scale approach), nor suppose that all users in the network belong to a polarized community as in [
18,
19,
20,
21,
22] (i.e., assuming a
macro-scale approach). We focus on such peculiar EC since we are interested in the role that group dynamics play in increasing polarization. Further, we believe that it is quite unrealistic that all the users involved in a controversial debate insulate themselves in an echo chamber.
Secondly, our framework is built upon features and resources commonly shared by most social networks, thus allowing its applicability across different OSNs and domains. In detail, such an approach consists of four main steps, namely: (i) controversial issue identification; (ii) users’ ideology inference; (iii) debate network construction; (iv) homogeneous meso-scale users’ clusters identification. Consequently, the basic bricks that we should find on OSNs to apply such an approach are the presence of discussions about controversial topics; the post feature in order to infer users ideology on the controversy based on how they write about it; the comment feature to define users debate network. To the best of our knowledge, all of these requirements are satisfied by the most popular OSNs (e.g., Twitter, Facebook, Reddit, Gab).
Moreover, we applied our framework in a detailed case study on Reddit covering the first two and a half years of Donald Trump’s presidency (January 2017–July 2019). In such settings, our main aim was to assess the existence of Pro-Trump and Anti-Trump ECs among three sociopolitical issues. As concerns users’ ideology, we have found that in the overall period, users tend to assume strongly polarized positions on the controversy rather than moderate ones across all topics. However, analyzing the stability of users’ ideology over contiguous semesters, we noticed that users are not so rooted in their positions as expected. Indeed, an exception is made for Anti-Trump users discussing political issues, for which the majority of users have an ~ probability of changing their leaning.
Regarding echo chambers, we have found that for Gun Control, minorities discrimination, and Political Sphere only 6.7%, 53.8%, 23.3% of total users fall in polarized communities. Among them, we observed that both the first and the second topics have a stronger tendency toward Pro-Trump beliefs, while the third to Anti-Trump ones. Additionally, we also assess ECs’ stability and consistency over contiguous semesters, finding that EC members have a higher probability of interacting with like-minded individuals with respect to the other communities in the overall network.
Comparing our results to the ones obtained by the only EC detection work on Reddit [
20], we find both commonalities and differences. Even if the authors focus on a different period (i.e., 2016 presidential elections) and on a slightly different controversy (i.e., Republicans vs. Democrats), we also noticed that Reddit users, compared to those of other OSNs, show a lower tendency to insulate themselves from opposite viewpoints. This attitude could be attributable to the Reddit structure, which is more a social forum than a traditional social network (e.g., Twitter, Facebook). However, differently from us, they conclude that Reddit political interactions do not resemble an echo chamber at all. Such a difference could be imputable to the difference in scale between approaches. Indeed, authors have identified ECs looking at the users’ interaction network on an aggregated level, thus not considering differences within specific meso-scale network regions.
Approach weaknesses and limitations. As with all frameworks, our proposal suffers of a few known limitations and weaknesses that need to be carefully taken into account while instantiating it. A first limitation lies in the loss of contextual details derivable from platform-specific features. Indeed, we define and identify echo chambers by means of common features and resources shared by multiple platforms, thus providing, in some sense, a high-level representation of the EC phenomenon. However, generalizability does not come for free and, further, we believe that posts and comments are good proxies for respectively inferring users’ ideology and defining the debate network. Moreover, we acknowledge that different data sources, although possessing the set of features required by our framework, can require context-specific tuning for each proposed step. In particular, to infer the political leaning from textual data, we assume that ad hoc model selection and fine-tuning have to be performed to account for data source peculiarities. Political leaning classifiers are hardly transferable among different contexts, and we can assume that a “no free lunch” solution exists to this challenging task. Finally, another limitation of the proposed framework lies in the absence of a general rule to select the proper community discovery algorithm to identify ECs. Community Discovery is an ill-posed problem, and alternative algorithmic solutions are known to optimize different quality function differences that highly affect the resulting node clustering. In this paper, we opted for a model, Eva, designed to balance both topological and semantic information while partitioning the social graph. Indeed, such a choice, although reasonable, is not the only valid alternative to address node cluster identification.
On the other hand, the major weakness of the proposed framework lies in the structural absence of a strong result validation strategy. Such an issue—affecting the majority of EC detection and political polarization studies—lies in the absence of reliable ground truth for individuals’ political leaning labels. As in other works [
13,
16,
18,
19,
20,
21], leaning labels are assigned making strong assumptions on the political orientation of users that take part to the discussions of polarized clusters—not separating real supporters from their opponents and trolls, nor relying on users’ provided information. Indeed, the absence of a ground truth annotation does not allow making a final observation and, rather, to underline that—considering the chosen methodological proxy—ECs emerge.
Research outlooks. As future research directions, we have both short- and long-term plans. Firstly, to further support our claim of framework generalizability, we are currently designing other case studies on popular OSNs (e.g., Twitter, Facebook, Gab). Consequently, we would like to perform a comparative analysis of obtained results in such a way as to assess if some environments are more polarized than others. Secondly, given the information retrieved in the previous step, we would like to characterize ECs by describing their DNA (e.g., the characteristics of the users composing them in terms of online activities) and use such footprints to design an echo chamber-aware Recommendation System able to foster pluralistic viewpoints in suggestions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}