1. Introduction
Infertility is a worldwide problem that affects more than 10% of couples, among which about 30% to 50% are found to be related to men [
1]. Sperm quality is the most important criterion for measuring male reproductive ability. The quality of human sperm not only affects the probability of conception but also profoundly impacts the physical and mental health of offspring. Sperm analysis is an essential step to identify sperm quality in clinical diagnosis. Generally, analysis of sperm cells includes sperm motility detection and sperm morphology examination. Sperm morphology is a proven indicator of male fertility [
2], and morphology assessment classifies the sperm in multiple categories [
3,
4]. Previous studies have shown that teratozoospermia (i.e., the increased concentration of abnormal sperms) is affected by various factors, such as aging and genetics [
5,
6]. Therefore, morphological classification of sperm is helpful to promote pathological research in human reproduction. Besides, in vitro fertilization also needs to find sperm with excellent quality quickly, which further requires the rapid and accurate classification of sperm.
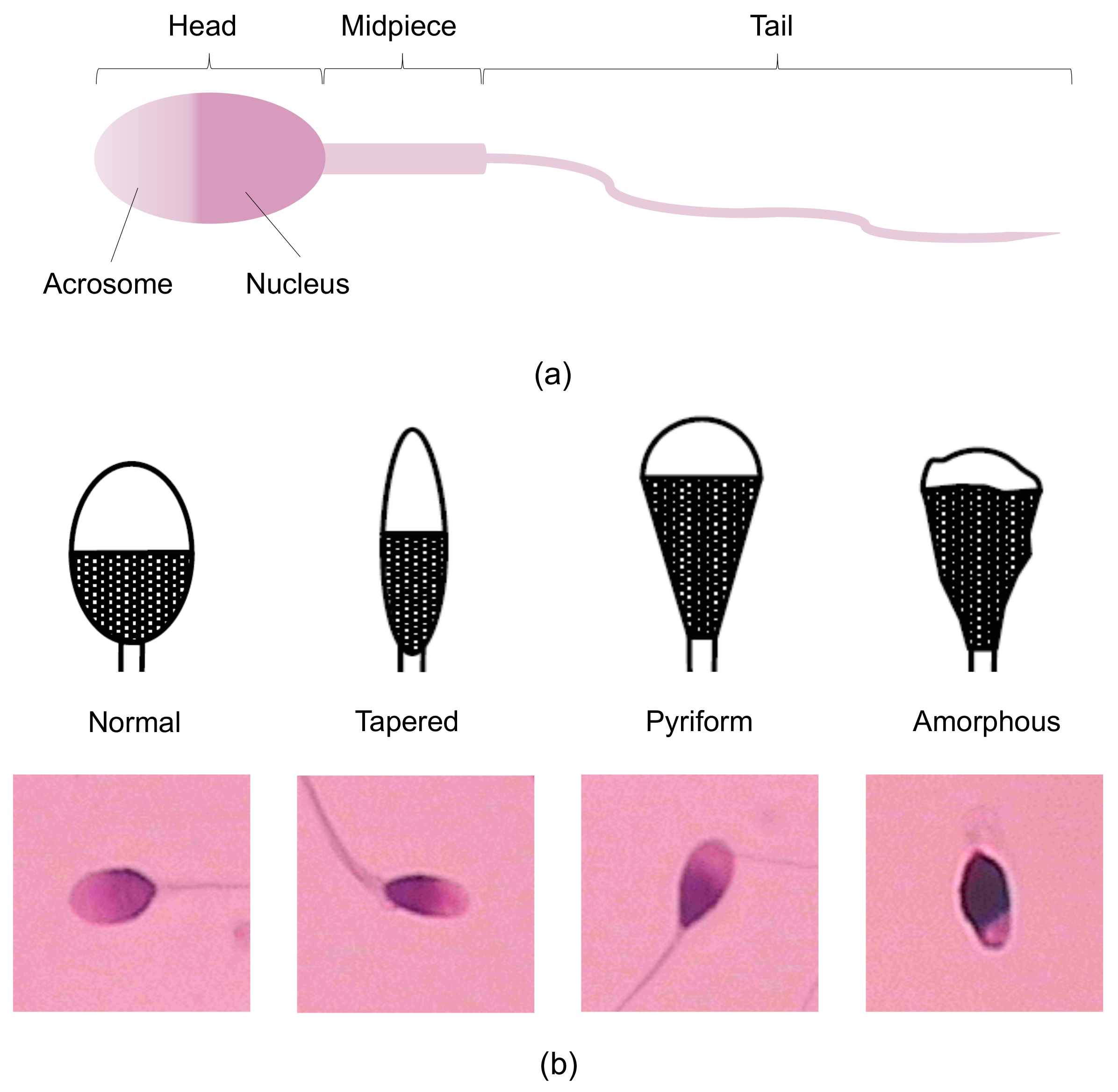
Human sperm consists of three main parts: head, midpiece and tail (
Figure 1a) [
7]. According to the World Health Organization, human sperm can be divided into normal sperm and abnormal sperm, and the abnormal sperm can be further classified into four sub-categories: head defects, neck and midpiece defects, tail defects, and excess residual cytoplasm [
8]. Among these defects, head defects, including tapered, pyriform, no acrosome, small, amorphous, vacuolated and small acrosomal areas, have the most significant impact on sperm quality [
8]. Herein, we mainly focus on the head malformations in this research. Although the Computer-Assisted Semen Analysis (CASA) system has been applied in various scenarios for semen analysis, it has not yet been able to classify human sperm morphologically [
9]. In clinical applications, human sperm morphology analysis is conducted manually by experienced physicians, which is laborious, time-consuming, and highly subjective [
10,
11].
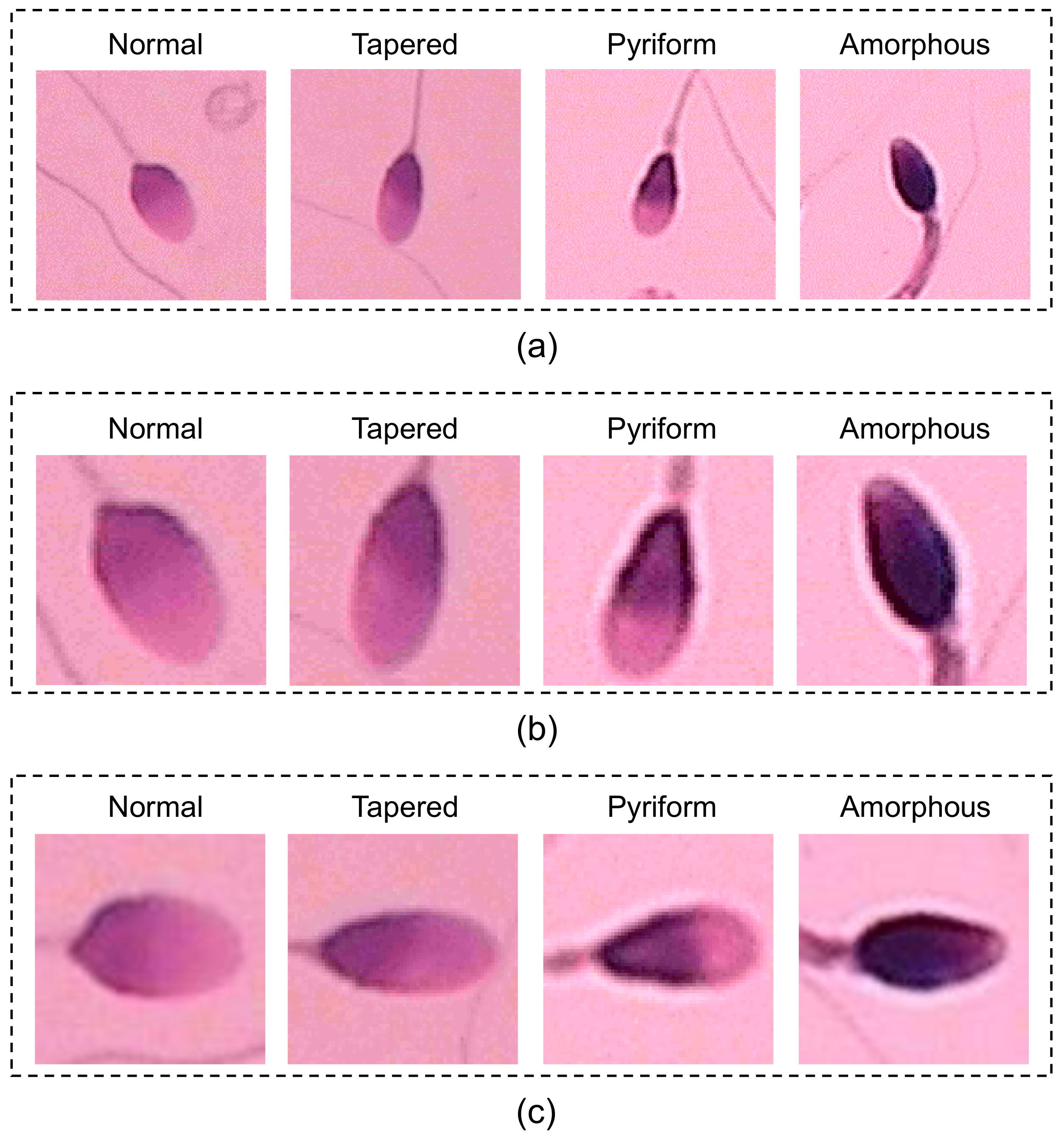
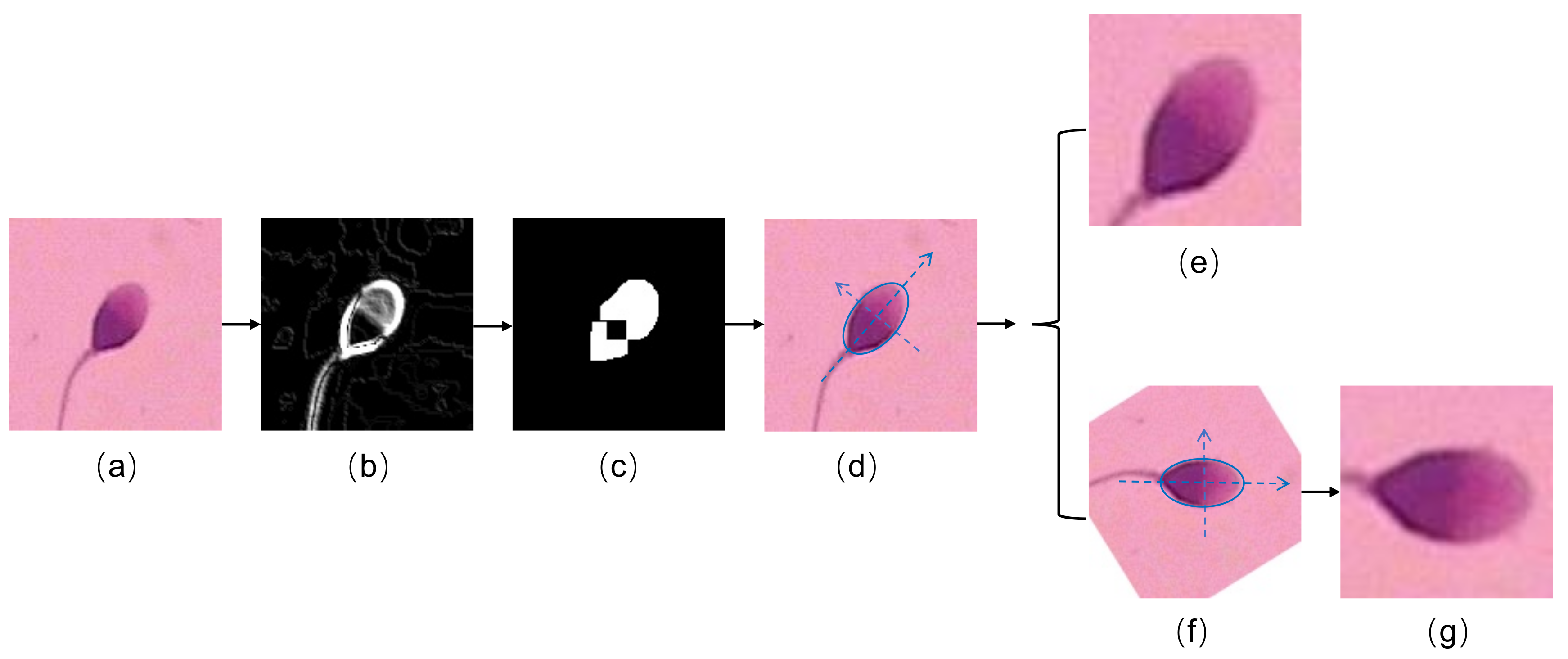
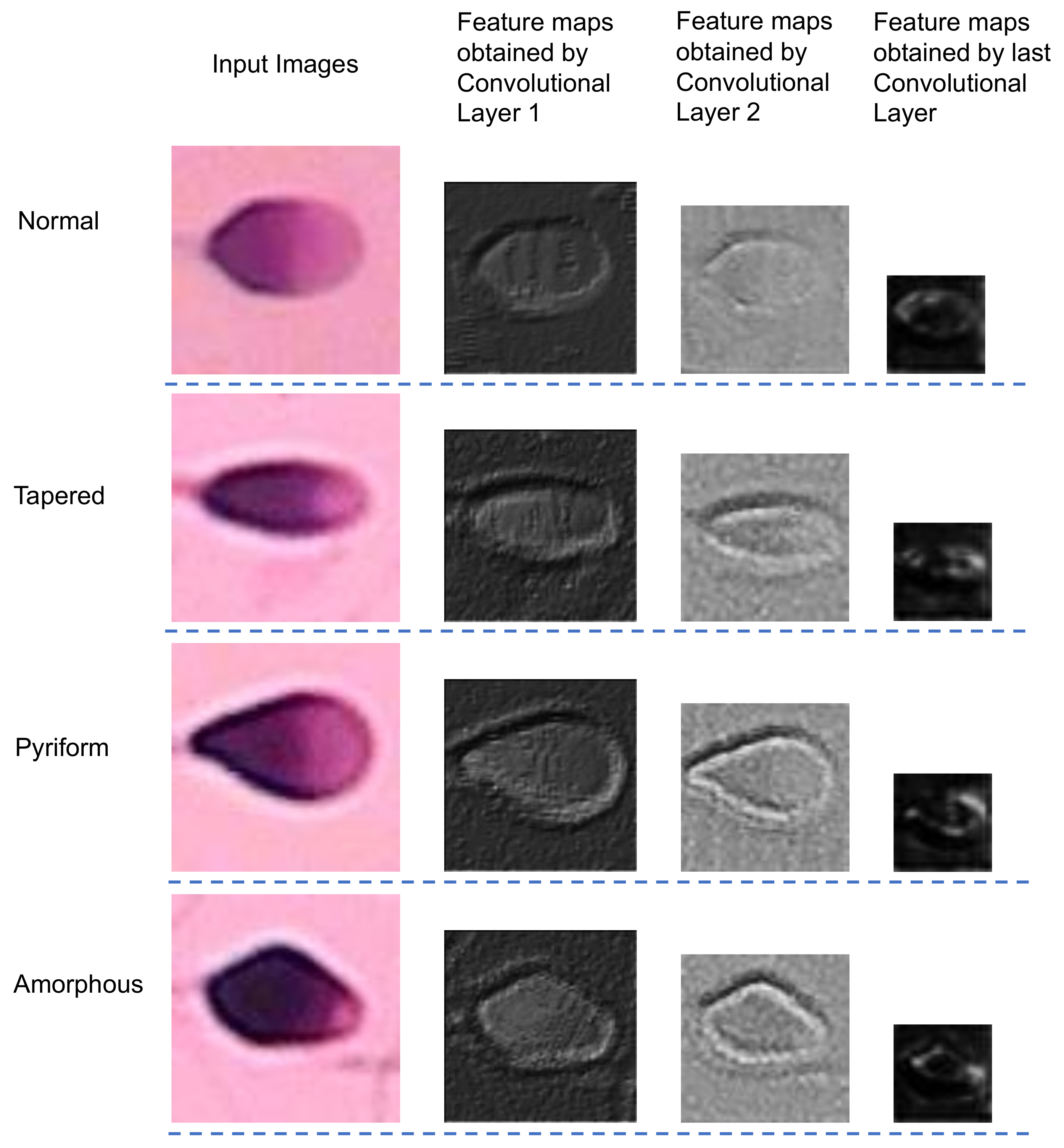
To address the limitations of manual human spermatozoon classification, researchers have recently developed various automatic sperm morphology classifiers. According to WHO criteria, the four classes of sperm heads, namely tapered, pyriform, amorphous, and normal sperm (as shown in
Figure 1b), are almost indistinguishable by embryologists because they have limited differences. Therefore, the classification algorithms are mainly focused on the classification of these four categories.
The earliest algorithms for sperm head classification were based on traditional machine learning methods. In 2017, Chang et al. introduced a gold-standard tool (SCIAN-MorphoSpermGS dataset) to evaluate and compare the classification approaches for human sperm heads [
12]. The SCIAN dataset consists of 1854 sperm cell images and includes five different expert-classification categories: normal, tapered, pyriform, small, and amorphous. Subsequently, they proposed a two-stage algorithm to classify sperm heads into the five aforementioned classes of the SCIAN dataset and achieved an average classification accuracy of 58% [
13]. In the first stage, the amorphous sperm cells are filtered out, while the remaining four classes are also preliminarily classified. The second stage works as a verifier to verify the results of the previous stage. In another study, Shaker et al. employed an adaptive patch-based dictionary learning (APDL) approach to improve the average true positive rate to be 62% on the SCIAN dataset and achieve an average true positive rate of 92.3% on the HuSHeM dataset for automatic sperm head classification [
14]. In the APDL scheme, small square patches are acquired from the sample sperm head images to train the algorithm and the patches of the test images from class-specific dictionaries are recreated to match the test data to the corresponding class.
Despite the great progress in human sperm classification tasks, these approaches require the features of sperm heads to be extracted manually and then fed into the classifier for training purposes, making it extremely difficult to classify the cells end-to-end. In the past few years, the emergence of deep learning has dramatically boosted the performance of state-of-art techniques in computer vision tasks [
15,
16,
17,
18,
19,
20]. In terms of automatic image classification, deep convolutional neural networks (CNNs) have demonstrated higher classification accuracy than traditional machine learning algorithms. More importantly, the CNNs are able to process raw data without extracting data features manually. In 2019, Riordon et al. applied a CNN-based method to the sperm cell classification task for the first time and achieved an average accuracy of 94.1% on the HuSHeM dataset and an average accuracy of 62% on the SCIAN dataset [
21]. In their study, the original VGG16 network [
22] was optimized for the sperm head classification task. Although the classification results are improved, the high complexity of the network structure requires large computational resources that are not available in typical IVF clinics.
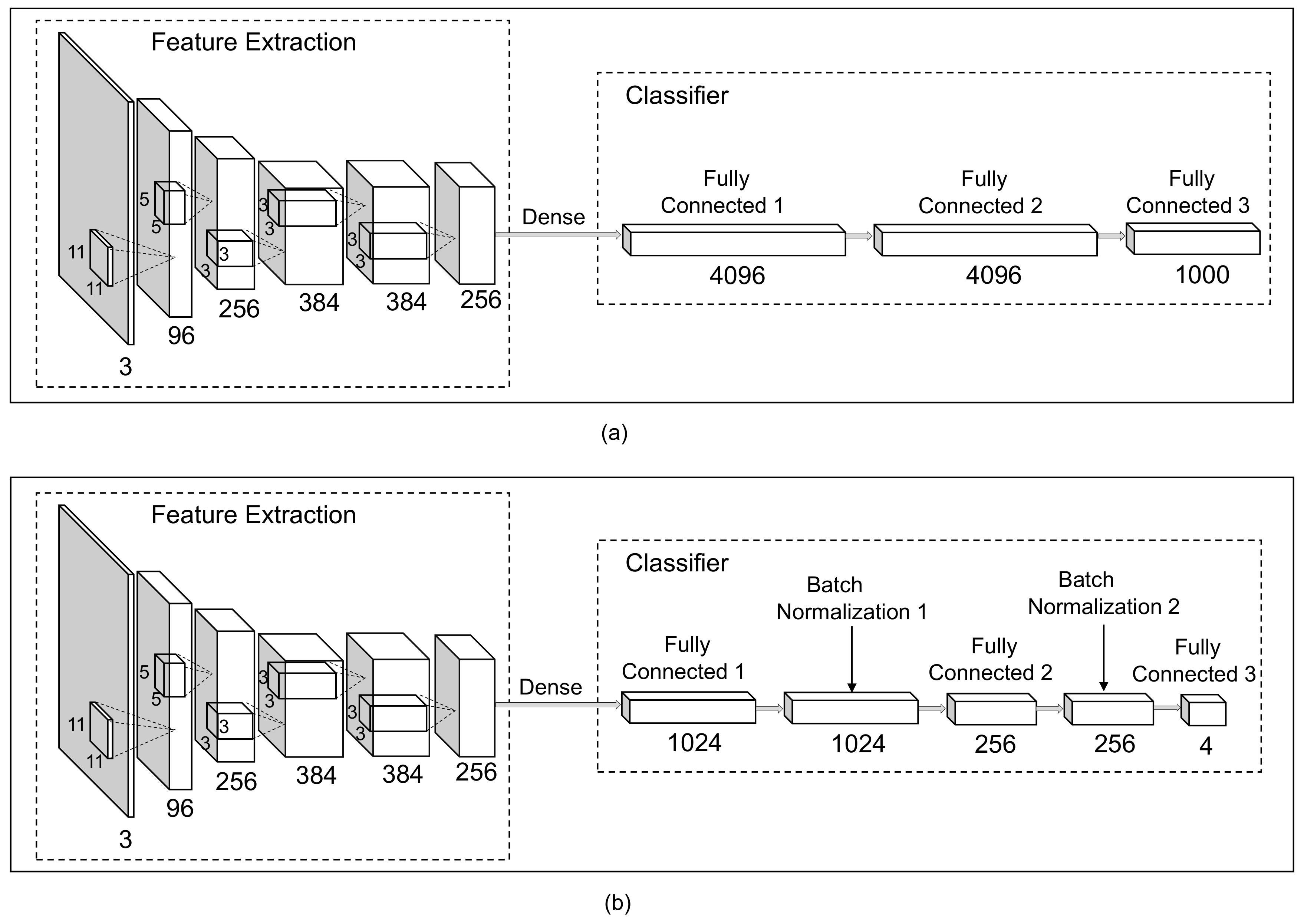
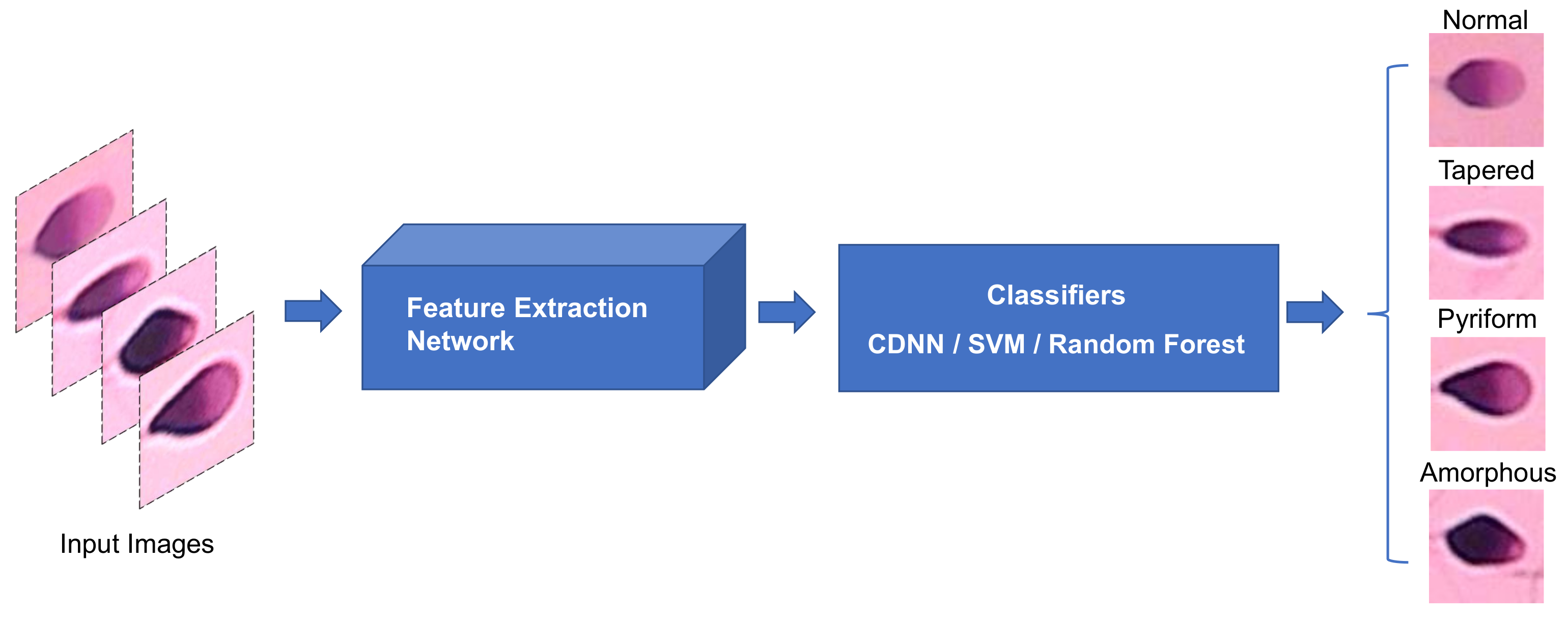
In this paper, we propose to use a different deep learning approach to classify sperm heads automatically. Instead of building the deep CNN from scratch, we modify the original AlexNet [
23] by adding the Batch Normalization layers for sperm head classification for the HuSHeM dataset. Simultaneously, the pre-training parameters obtained from the training of the ImageNet dataset [
24] for the feature extraction are adopted to reduce computational and time costs. The experiment results indicate our approach outperforms the state-of-the-art in terms of average classification accuracy (96.0% vs. 94.0%), average precision (96.4% vs. 94.7%), average recall (96.1% vs. 94.1%) as well as average F-score (96.0% vs. 94.1%) on the HuSHeM dataset. Moreover, compared with the VGG16-based approach presented in [
21], the pre-training part our method does not require any fine tuning, and the number of parameters in the feature extraction part is less than one-sixth of those using VGG16. Accordingly, our method is relatively computer-resource-saving and has a low computational cost.
The rest of the paper is organized as follows. The model and the dataset used to test the algorithm are introduced in
Section 2.
Section 3 presents the experimental results, the ablation analysis of the classifier, as well as the influence of data preprocessing on the performance of the model. Finally,
Section 4 concludes this work.
4. Conclusions
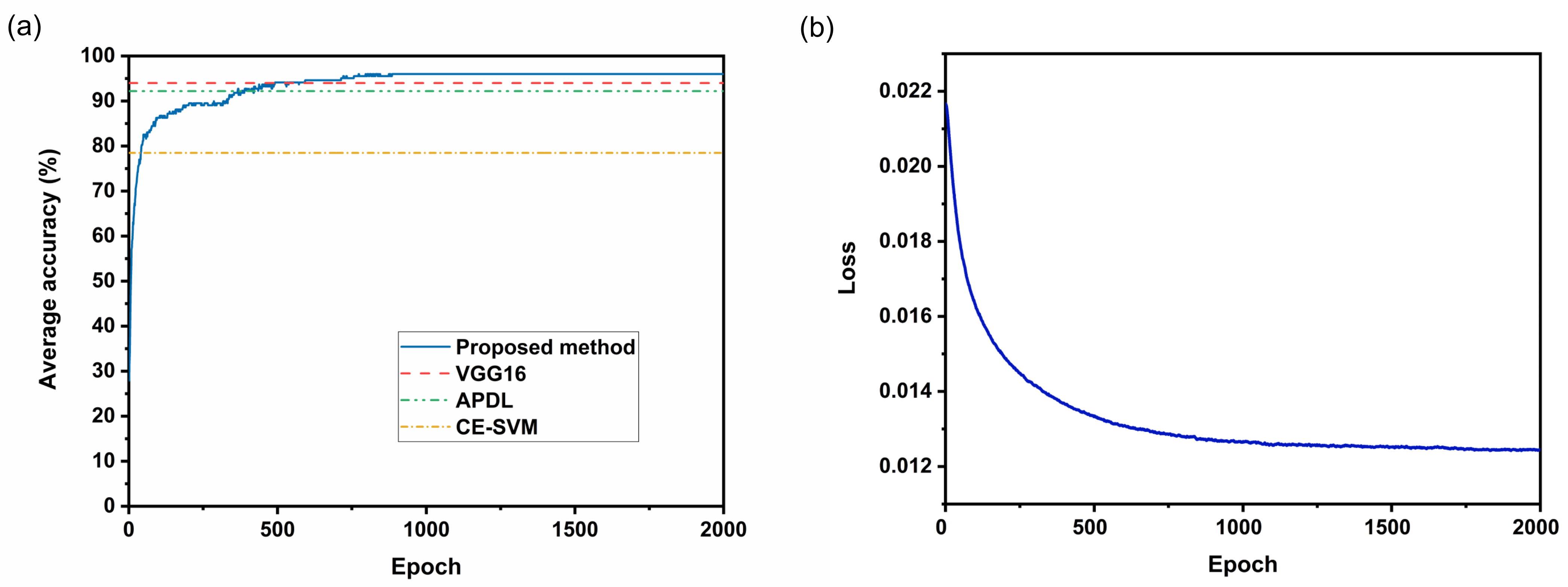
In this research, a deep Convolutional Neural Network using AlexNet structure was modified by adding Batch Normalization layers to classify sperm automatically. The proposed approach was trained and tested on the HuSHeM dataset, a publicly available sperm dataset that contains four distinct categories. Cross-validation was conducted in the experiment to evaluate the performance. The experiment results show that our method outperforms the state-of-the-art algorithms in the given metrics: classification accuracy (96.0% vs. 94.0%), average precision (96.4% vs. 94.7%), average recall (96.1% vs. 94.1%) and average F-score (96.0% vs. 94.1%).
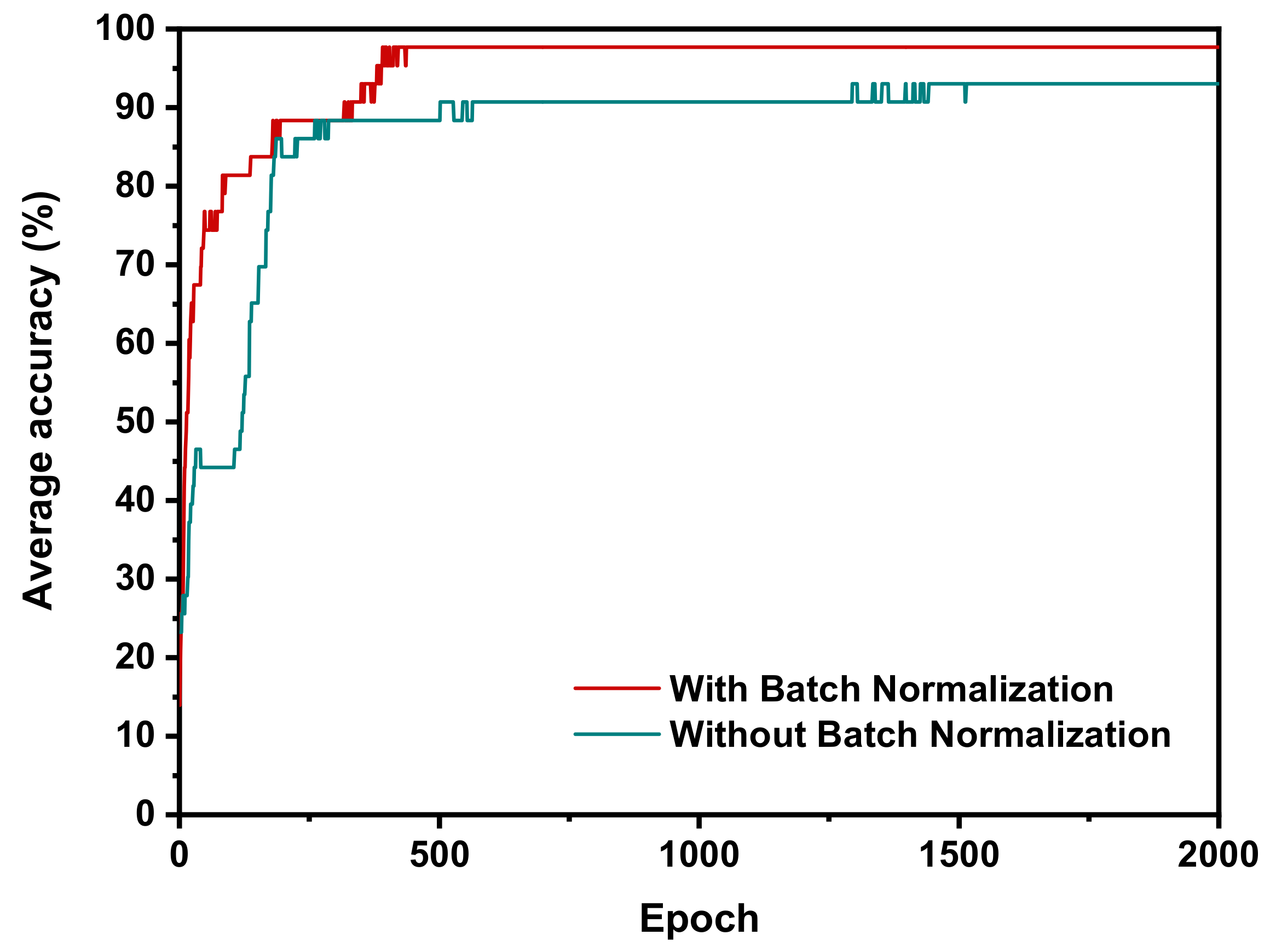
Compared with the method using VGG structure, the proposed method applies the pre-training parameters without fine turning, which could accelerate the training process and save computing resources.Although the more advanced deep learning architectures usually achieve better performance when facing with complex scenarios (such as the ImageNet dataset), a concise network architecture might perform better if the dataset is relatively small and the feature information is not very diverse. The comparison results confirm the simple network structure is able to extract the feature effectively without overfitting. It is also worth mentioning that Batch Normalization in the proposed method can not only accelerate the learning of the network, but also improve the final sperm classification results on the HuSHeM dataset. In addition, data preprocessing can improve algorithm performance by improving data quality. In a nutshell, this research applies the transfer learning technique and presents a new deep learning model for sperm classification. The improved classification performance with reduced computational burden enables to fully automate the semen analysis in IVF applications.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}