
Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems



Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Related Works
- Safety-rated monitored stop, stopping the robot in case the robot operations are halted when safety zones are violated;
- Hand guiding, allowing the operator to teach new positions without the need of a teaching interface;
- Speed and separation monitoring, changing the robots speed in relation to the position of the operator;
- Power and force limiting mode, restricting the contact force in collaborative work.
1.2. Previous Work
1.3. Our Approach
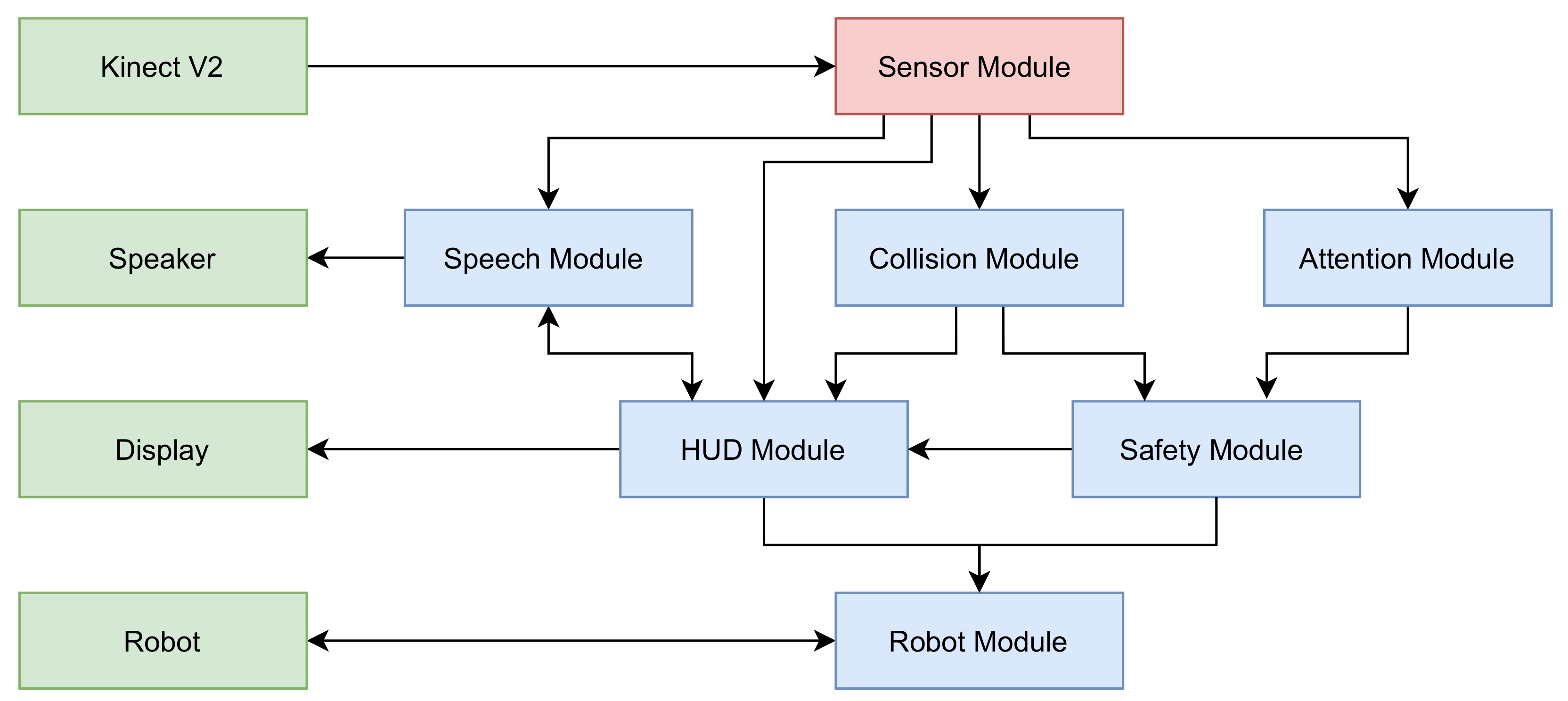
2. System Setup
2.1. Hardware
2.2. Software
3. Modules
3.1. Sensor Module and Calibration
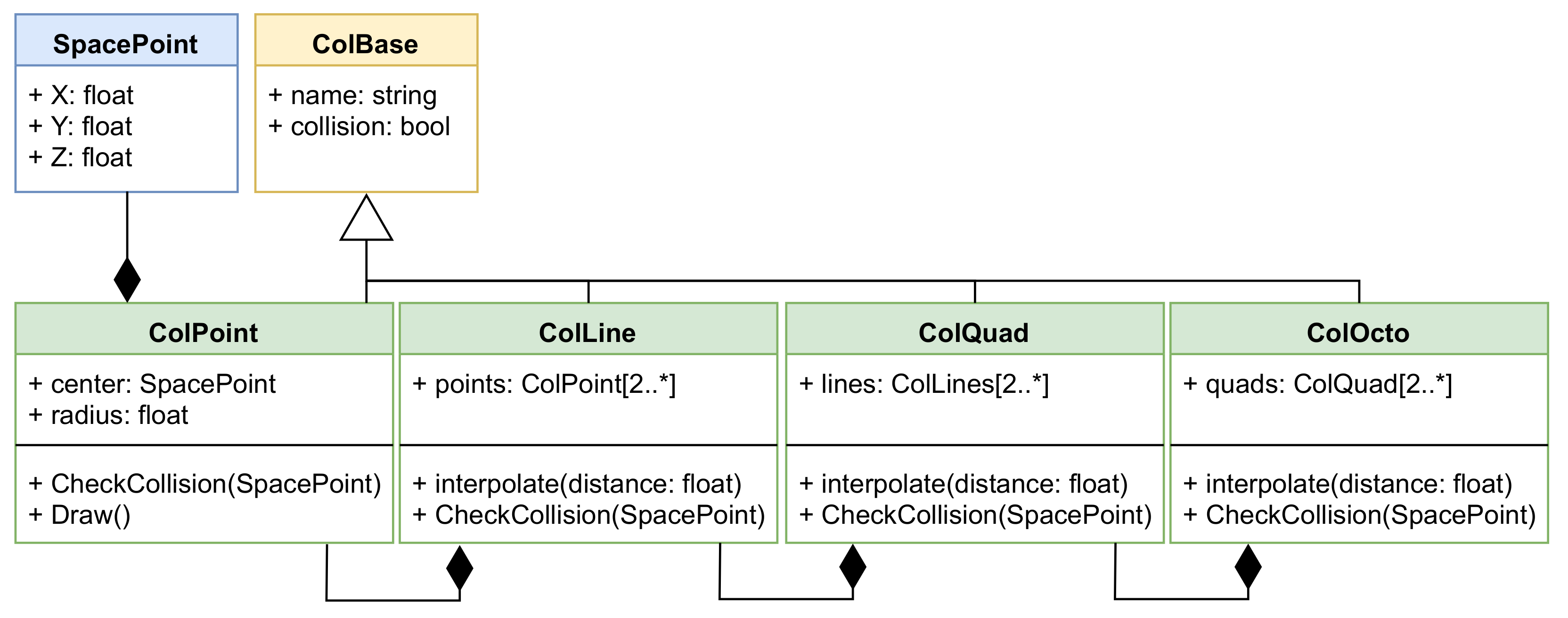
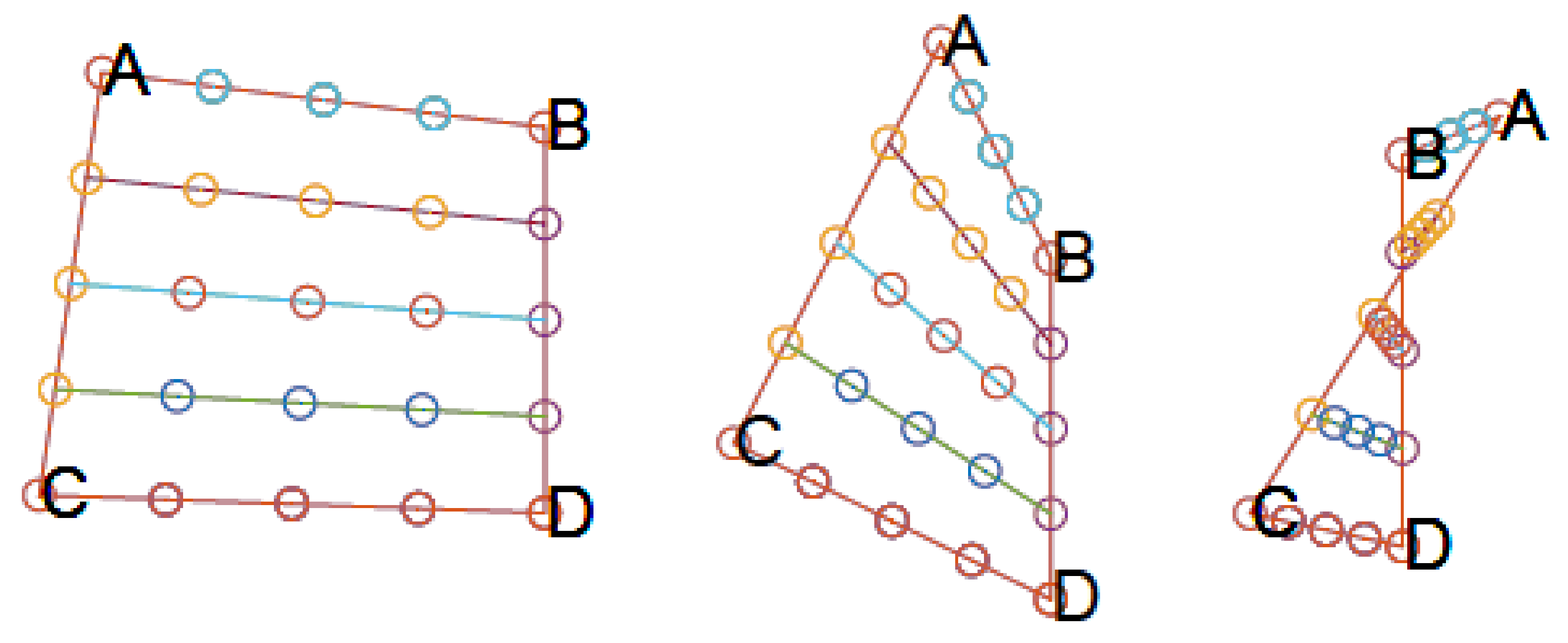
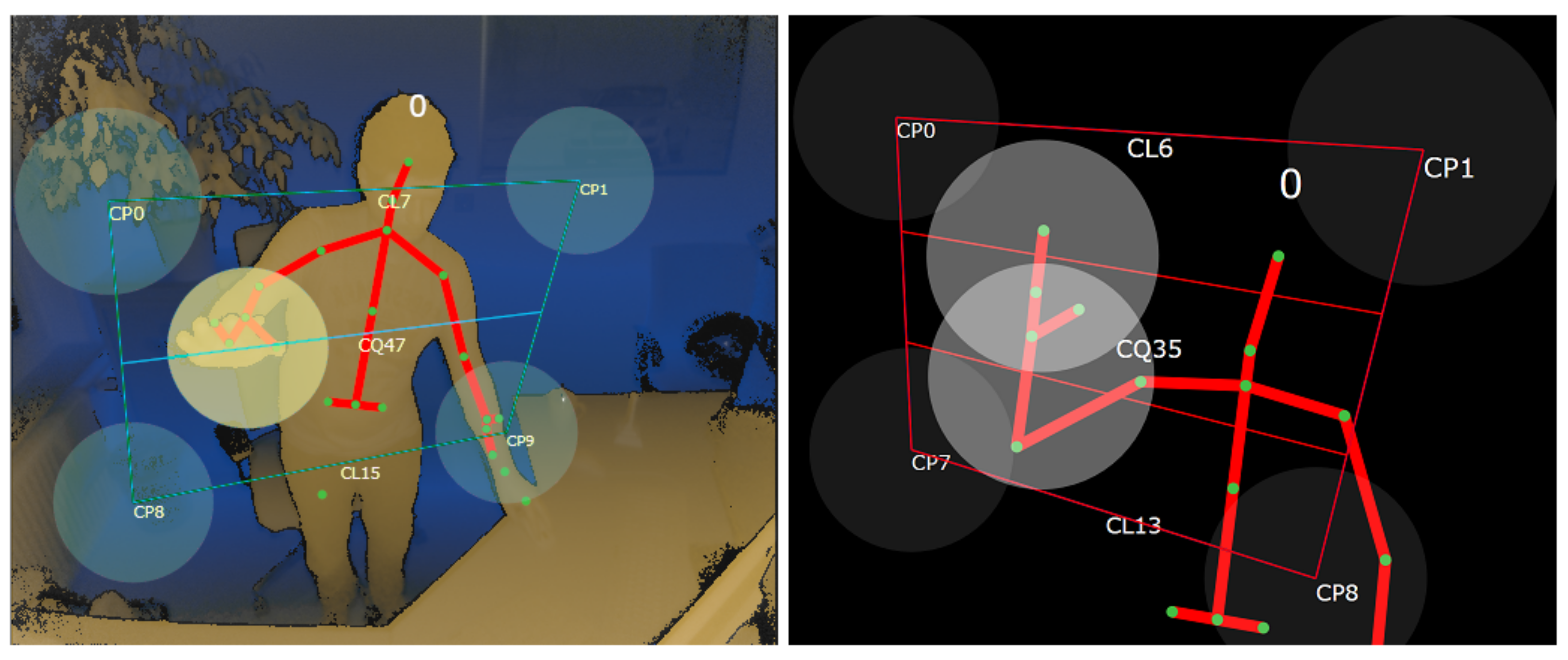
3.2. Collision Module
3.3. HUD Module
3.4. Attention Module
3.5. Safety Module
3.6. Speech Module
3.7. Robot
- Speed and separation monitoring, where the robot is moving between predefined points and slows down if the user looks away;
- Hand guiding/Freedrive mode, allowing the operator to manipulate the robot manually;
- Direct control, allowing the user to move the robot arm directly via the menu.
4. Results and Discussion
4.1. Industrial Use
- concern for fatigue for prolonged use;
- need for height adjustment, as taller persons had minor difficulties with the HUD;
- users trying to “click” the buttons instead of “hover and holding”;
- users extending their arms too far, instead of holding, thus resulting in leaving the predefined menu ColPoint resulting in abortion of the wanted action;
- quick adaption to the system and the ability to control the robot within minutes;
- overall positive feedback for the user experience;
- good use-case for inspection tasks and operation in difficult environments where contactless operation is advantageous (high voltage, acid, sharp pieces).
4.2. Collision
4.3. Safety
4.4. UI
4.5. Future Works and Author Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Flacco, F.; De Luca, A. Safe physical human-robot collaboration. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; IEEE: Piscataway, NJ, USA, 2013; p. 2072. [Google Scholar]
- Fast-Berglund, Å.; Palmkvist, F.; Nyqvist, P.; Ekered, S.; Åkerman, M. Evaluating cobots for final assembly. Procedia CIRP 2016, 44, 175–180. [Google Scholar] [CrossRef]
- Chen, Q.; Heydari, B.; Moghaddam, M. Levering Task Modularity in Reinforcement Learning for Adaptable Industry 4.0 Automation. J. Mech. Des. 2021, 143, 1–35. [Google Scholar] [CrossRef]
- Saenz, J.; Elkmann, N.; Gibaru, O.; Neto, P. Survey of Methods for Design of Collaborative Robotics Applications—Why Safety Is a Barrier to More Widespread Robotics Uptake; ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2018; Volume Part F137690, pp. 95–101. [Google Scholar] [CrossRef]
- Peshkin, M.; Colgate, J.E. Cobots. Industrial Robot. Int. J. 1999, 26, 335–341. [Google Scholar] [CrossRef]
- Pasinetti, S.; Nuzzi, C.; Lancini, M.; Sansoni, G.; Docchio, F.; Fornaser, A. Development and Characterization of a Safety System for Robotic Cells Based on Multiple Time of Flight (TOF) Cameras and Point Cloud Analysis. In Proceedings of the 2018 Workshop on Metrology for Industry 4.0 and IoT, Brescia, Italy, 16–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Magrini, E.; Ferraguti, F.; Ronga, A.J.; Pini, F.; De Luca, A.; Leali, F. Human-robot coexistence and interaction in open industrial cells. Robot. Comput.-Integr. Manuf. 2020, 61, 1–55. [Google Scholar] [CrossRef]
- Lentini, G.; Falco, P.; Grioli, G.; Catalano, M.G.; Bicchi, A. Contactless Lead-Through Robot Interface; Technical Report; I-RIM: Pisa, Italy, 2020; Available online: https://i-rim.it/wp-content/uploads/2020/12/I-RIM_2020_paper_114.pdf (accessed on 1 April 2021).
- Tölgyessy, M.; Dekan, M.; Duchoň, F.; Rodina, J.; Hubinský, P.; Chovanec, L. Foundations of Visual Linear Human–Robot Interaction via Pointing Gesture Navigation. Int. J. Soc. Robot. 2017, 9, 509–523. [Google Scholar] [CrossRef]
- Alvarez-Santos, V.; Iglesias, R.; Pardo, X.M.; Regueiro, C.V.; Canedo-Rodriguez, A. Gesture-based interaction with voice feedback for a tour-guide robot. J. Vis. Commun. Image Represent. 2014, 25, 499–509. [Google Scholar] [CrossRef]
- Fang, H.C.; Ong, S.K.; Nee, A.Y. A novel augmented reality-based interface for robot path planning. Int. J. Interact. Des. Manuf. 2014, 8, 33–42. [Google Scholar] [CrossRef]
- Ong, S.K.; Yew, A.W.; Thanigaivel, N.K.; Nee, A.Y. Augmented reality-assisted robot programming system for industrial applications. Robot. Comput. Integr. Manuf. 2020, 61, 101820. [Google Scholar] [CrossRef]
- Gadre, S.Y.; Rosen, E.; Chien, G.; Phillips, E.; Tellex, S.; Konidaris, G. End-user robot programming using mixed reality. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2707–2713. [Google Scholar] [CrossRef]
- Kousi, N.; Stoubos, C.; Gkournelos, C.; Michalos, G.; Makris, S. Enabling human robot interaction in flexible robotic assembly lines: An augmented reality based software suite. Procedia CIRP 2019, 81, 1429–1434. [Google Scholar] [CrossRef]
- Stetco, C.; Muhlbacher-Karrer, S.; Lucchi, M.; Weyrer, M.; Faller, L.M.; Zangl, H. Gesture-based contactless control of mobile manipulators using capacitive sensing. In Proceedings of the I2MTC 2020—International Instrumentation and Measurement Technology Conference, Dubrovnik, Croatia, 25–28 May 2020; pp. 21–26. [Google Scholar] [CrossRef]
- Mühlbacher-Karrer, S.; Brandstötter, M.; Schett, D.; Zangl, H. Contactless Control of a Kinematically Redundant Serial Manipulator Using Tomographic Sensors. IEEE Robot. Autom. Lett. 2017, 2, 562–569. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, A.; Zhou, M.; Wang, W.; Yang, X. A Novel Detection and Recognition Method for Continuous Hand Gesture Using FMCW Radar. IEEE Access 2020, 8, 167264–167275. [Google Scholar] [CrossRef]
- Strazdas, D.; Hintz, J.; Felßberg, A.M.; Al-Hamadi, A. Robots and Wizards: An Investigation Into Natural Human–Robot Interaction. IEEE Access 2020, 8, 207635–207642. [Google Scholar] [CrossRef]
- Williams, T.; Hirshfield, L.; Tran, N.; Grant, T.; Woodward, N. Using augmented reality to better study human-robot interaction. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Swizerland, 2020; Volume 12190, pp. 643–654. [Google Scholar] [CrossRef]
- Billinghurst, M.; Clark, A.; Lee, G. A survey of augmented reality. Found. Trends Hum. Comput. Interact. 2014, 8, 73–272. [Google Scholar] [CrossRef]
- Werner, P.; Saxen, F.; Al-Hamadi, A. Landmark based head pose estimation benchmark and method. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3909–3913. [Google Scholar]
- Bee, N.; André, E.; Tober, S. Breaking the Ice in Human-Agent Communication: Eye-Gaze Based Initiation of Contact with an Embodied Conversational Agent. In Intelligent Virtual Agents; Ruttkay, Z., Kipp, M., Nijholt, A., Vilhjálmsson, H.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 229–242. [Google Scholar]
- Fischer, K.; Jensen, L.C.; Suvei, S.D.; Bodenhagen, L. Between legibility and contact: The role of gaze in robot approach. In Proceedings of the 25th IEEE International Symposium on Robot and Human Interactive Communication, RO-MAN 2016, New York, NY, USA, 26–31 August 2016; pp. 646–651. [Google Scholar] [CrossRef]
- Nord, T. Certificate; Test Report No. 3520 1327; TÜV NORD CERT GmbH: Essen, Germany, 2018. [Google Scholar]
- Duda, A.; Frese, U. Accurate Detection and Localization of Checkerboard Corners for Calibration. In Proceedings of the BMVC, Birmingham, UK, 3–6 September 2018; p. 126. [Google Scholar]
- Vehar, D.; Nestler, R.; Franke, K.H. 3D-EasyCalib™-Toolkit zur geometrischen Kalibrierung von Kameras und Robotern Journal 22. In Anwendungsbezogener Workshop zur Erfassung, Modellierung, Verarbeitung und Auswertung von 3D-Daten, 3D-NordOst; GFaI Gesellschaft zur Förderung angewandter Informatik: Berlin, Germany, 2019; pp. 15–26. [Google Scholar]
- Otte, K.; Kayser, B.; Mansow-Model, S.; Verrel, J.; Paul, F.; Brandt, A.U.; Schmitz-Hübsch, T. Accuracy and Reliability of the Kinect Version 2 for Clinical Measurement of Motor Function. PLoS ONE 2016, 11, e0166532. [Google Scholar] [CrossRef] [PubMed]
- Abbondanza, P.; Giancola, S.; Sala, R.; Tarabini, M. Accuracy of the Microsoft Kinect System in the Identification of the Body Posture; Springer: Cham, Germany, 2017; Volume 192, pp. 289–296. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. TIST 2011, 2, 1–27. [Google Scholar] [CrossRef]
- King, D.E. dlib C++ Library: High Quality Face Recognition with Deep Metric Learning Knuth: Computers and Typesetting. Available online: http://blog.dlib.net/2017/02/high-quality-face-recognition-with-deep.html (accessed on 1 April 2021).
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
Short Biography of Authors
 | Dominykas Strazdas was born in Vilnius, Lithuania, in 1989. He received his B.Sc. and M.Sc degrees in mechatronics from Otto-von-Guericke University Magdeburg and is currently pursuing his Ph.D. degree in electrical engineering at the Otto-von-Guericke University Magdeburg. His research interests include human–machine interaction, especially natural, intuitive, and contact-less communication between humans and robots. Since 2017 he has been a Research Assistant with the Neuro-Information Technology research group at the Otto-von-Guericke University Magdeburg. |
 | Jan Hintz was born in Brunswick, Lower-Saxony, Germany, in 1996. He received his B.Sc. degree in electrical engineering and information technology from the Otto-von-Guericke University Magdeburg. He is currently pursuing his M.Sc. degree in electrical engineering and information technology at the Otto-von-Guericke University Magdeburg. His research interests include computer vision, image processing, machine learning, and human– machine interaction. Since 2018 he has been a Research Assistant with the Neuro-Information Technology research group at the Otto-von-Guericke University Magdeburg. |
 | Ayoub Al-Hamadi received his Masters Degree in Electrical Engineering & Information Technology in 1997 and his PhD. in Technical Computer Science at the Otto-von-Guericke-University of Magdeburg, Germany in 2001. Since 2003 he has been Junior-Research-Group-Leader at the Institute for Electronics, Signal Processing and Communications at the Otto-von-Guericke-University Magdeburg. In 2008 he became Professor of Neuro-Information Technology at the Otto-von-Guericke University Magdeburg. In May 2010 Prof. Al-Hamadi received the Habilitation in Artificial Intelligence and the Venia Legendi in the scientific field of "Pattern Recognition and Image Processing" from Otto-von-Guericke-University Magdeburg, Germany. Prof. Al-Hamadi is the author of more than 360 articles in peer-reviewed international journals, conferences and books. His research interests include human–robot interaction, computer vision, pattern recognition, and AI. See www.nit.ovgu.de for more details. |









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strazdas, D.; Hintz, J.; Al-Hamadi, A. Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems. Appl. Sci. 2021, 11, 5366. https://doi.org/10.3390/app11125366
Strazdas D, Hintz J, Al-Hamadi A. Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems. Applied Sciences. 2021; 11(12):5366. https://doi.org/10.3390/app11125366
Chicago/Turabian StyleStrazdas, Dominykas, Jan Hintz, and Ayoub Al-Hamadi. 2021. "Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems" Applied Sciences 11, no. 12: 5366. https://doi.org/10.3390/app11125366
APA StyleStrazdas, D., Hintz, J., & Al-Hamadi, A. (2021). Robo-HUD: Interaction Concept for Contactless Operation of Industrial Cobotic Systems. Applied Sciences, 11(12), 5366. https://doi.org/10.3390/app11125366