4.2.1. Threshold Estimation
An experiment was conducted to estimate the similarity comparison threshold. If a threshold is set to a low value, two different videos are considered to be equal. If the threshold is set too high, a manipulated video is considered to be unrelated. Because this experiment focused on the detection of all crime videos, a threshold was set, even if different videos were recognized as similar. Although the videos used during the experiment were not based on actual crime videos, they reflected the features of illegally filmed videos. As shown in
Table 3, the videos were classified according to the criteria of brightness, object perspective, and shooting angle.
Table 4 shows the eight environments created through the intersection of the features. All videos were classified into eight experimental environments. Each environment had 311 frames of similar videos. Therefore, the experiment used frames with a total of 2488 frames, and the threshold for each environment was set.
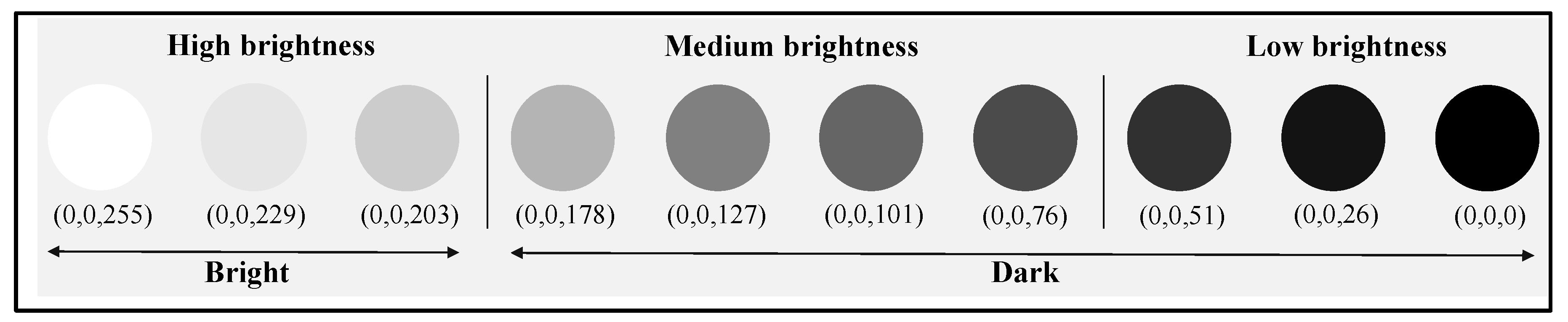
The brightness of an image is based on the value of V in the HSV, which ranges from zero to 255. As shown in
Figure 4, brightness is classified as high, medium, or low. In this experiment, if a video’s V value ranged from 203 to 255, the video was considered bright; if the V value was between 0 and 202, the video was considered dark.
Figure 5 illustrates the criteria for perspective and shooting angle. The comparison in terms of perspective was based on how far or near an object is. The target object must be determined by an investigator. Because the perspective is a qualitative area, an investigator should determine how far or near an object is. During this experiment, a nearby object was shot within a 1 m distance from the camera; in addition, a distant object was shot at a distance of at least 1-m from the camera. The shooting angle is classified into a middle angle (the horizontal angle of a camera for an object) and high angle (from-top-to-bottom angle of a camera for an object). The shooting angle was also a qualitative area. Therefore, an investigator should select the shooting angle type based on judgment.
Figure 6a illustrates a graph of correlation similarities for similar videos in an BNM environment. In the correlation algorithm-based histogram comparison, the comparison is evaluated into a number with a scale of 1 to −1, with 1 being identical, −1 being a perfectly reversed image frame, and zero being uncorrelated. To find appropriate thresholds, this study selected frames with noticeable changes of objects and used them as experimental data, rather than the frames that look similar with the naked eye. As for the experimental data used in this study, exceptional situations arising in illegally filmed videos, such as shifting an object horizontally, making an object disappear temporarily, or adding a different object to its surroundings while the shooting angle remains unchanged in a single space, were taken into consideration. To find a minimum threshold, this study moved an object as much as possible in the comparative experiment. Even if two frames look totally different with the naked eye, they are sometimes considered similar in similarity comparisons. In such a case, a comparison similarity becomes an outlier. With the similarities of the frames, variance of a sample was calculated. Among 311 frames, outliers were removed, and their mean was calculated. In this way, a threshold was estimated. The threshold of the correlation algorithm was set as 0.47 or more.
Figure 6b illustrates the graph of intersection similarities for similar videos in the BNM environment. In the intersection algorithm-based similarity comparison, if two frames to be compared are completely matched, the resulting value is 1, and if not matched completely, the value is zero. The selection of experimental data and the experiment process are the same as in
Figure 4. As a result, the similar frame threshold determined by the intersection algorithm is 0.48 or more.
Figure 6c illustrates the graph of Bhattacharyya similarities for similar videos within the BNM environment. In the Bhattacharyya distance-based comparison, if two frames to be compared are matched completely, the resulting value is zero, whereas the less similar they are, the closer the distance value is to 1. The selection of the experimental data and experiment process are the same as in
Figure 6a. As a result, the similar frame threshold determined by the Bhattacharyya algorithm is 0.52 or less. Seven other environments were also implemented in the same way.
Table 5 shows the thresholds in eight different environments.
In
Section 4.2.2 and
Section 4.2.3, scenarios based on the above thresholds are presented. In the experiments, similar videos were identified according to whether the investigator’s reference video was original or manipulated.
4.2.2. Scenario 1
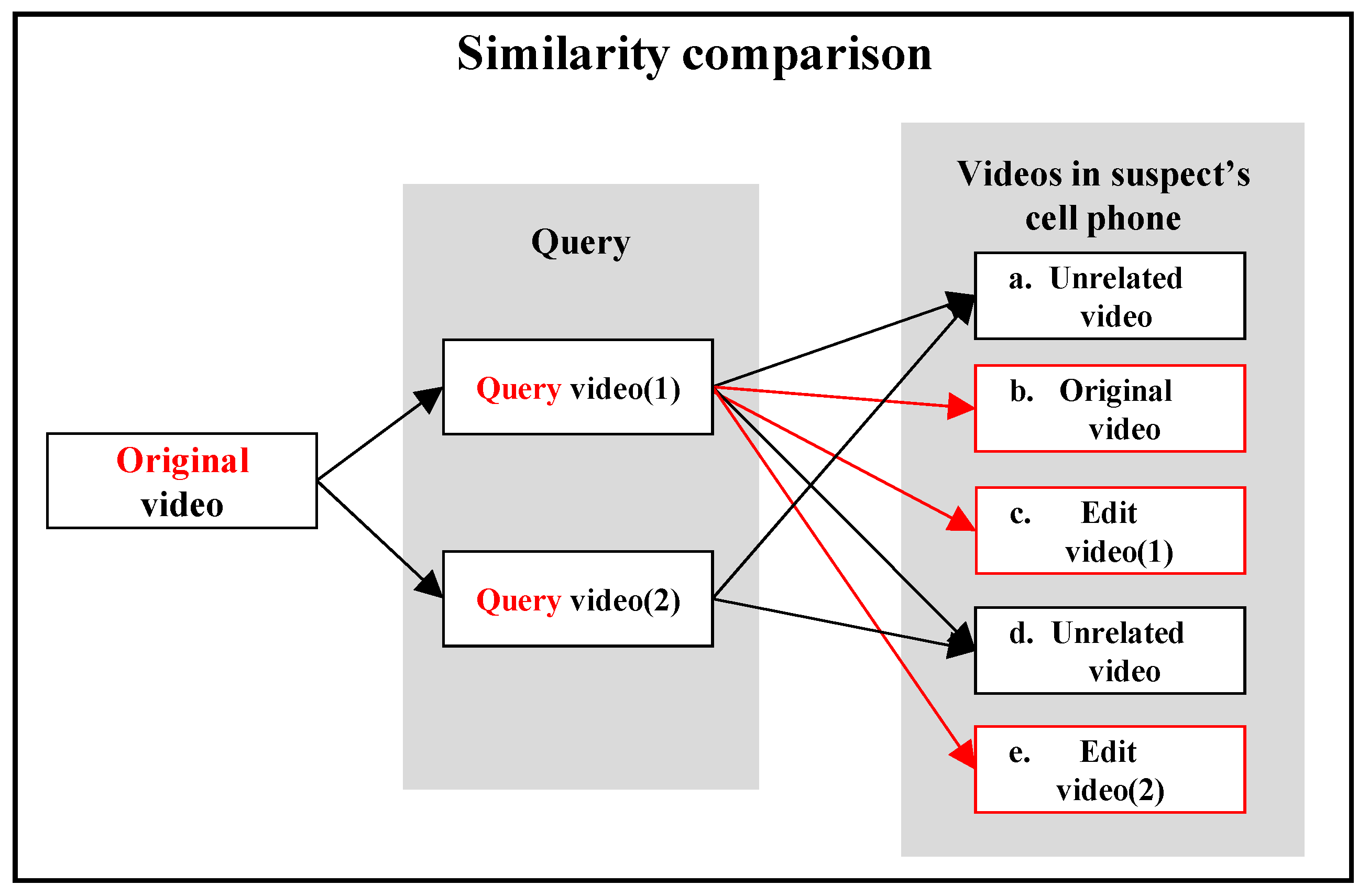
In scenario 1, the investigators secured manipulated videos and detected original and manipulated videos from a suspect’s mobile device.
Table 6 shows the manipulated video secured by investigators (BNM_E) and the query video, which is the query section selected by the investigators within BNM_E. Under this scenario, the investigator set the whole BNM_E as a query section and ran the test. The video names in
Table 4 show the video criteria. If a video is original, it is labeled ‘O’ (original) after the underscore (_); if manipulated, it is labeled ‘E’ (edit); and if unrelated to an original video, it is labeled ‘D’ (different).
Table 7 shows videos of a suspect’s mobile device. As shown in
Figure 7, these videos were used for an optimized comparison with the query video.
The similarity comparison between videos is applied to scenario 1, and each of the following steps is applied:
- Step 1.
Determine a query section in a reference video.
In scenario 1, the entire reference video is a query section.
- Step 2.
Cut a video frame-by-frame based on
Table 1.
- Step 3.
Cut a comparison video frame-by-frame based on
Table 1.
The number of frames is checked, and the unit of frame continuity is determined based on
Table 2.
- Step 4.
Process similarity comparison from the middle of the running time of the comparison video based on the frame continuity unit.
- Step 5.
Detect a video that ends up being similar on the basis of the thresholds in
Table 5, and then go to the next video. If not similar, go to the next video.
- Step 6.
In the next video, repeat the process from Step 3.
Figure 8a illustrates the result from the correlation similarity comparison with the videos in a suspect’s mobile device under scenario 1. The suspect’s mobile device has five videos: three videos irrelevant to the query video (DNM_D, Dark+Near+Middle_Different videos; BNM_D, Bright+Near+Middle_Different video; and BNH_D, Brighy+Near+High_Different video), one original video of the query video (BNM_O, Bright+Near+Middle_Original video), and one manipulated video (BNM_E, Bright+Near+Middle_Edit video). Because these five videos have a different running times, their total number of extracted frames are different. A comparison was carried out in the order of videos listed in
Table 7. Beginning with the middle of the total frame number for each video, a frame was compared with the query frame in accord with the pseudocode shown in
Figure 3. After that, a similar video was identified based on the BNM threshold of
Table 5. If all results from the three algorithms for one frame were within the range of thresholds for over 10 separate trials, the comparison process stopped and the video was identified as identical or manipulated. For the three videos irrelevant to the query video (DNM_D, BNM_D, BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frames had a similarity of 0.47 or more in terms of the threshold of the correlation algorithm under the BNM environment. For this reason, after all frames were searched, the comparison process moved to the next video. For the original video BNM_O and the manipulated video BNM_E, the comparison was processed from the middle of the total extracted frames in each of the two videos in accord with the pseudocode shown in
Figure 3. Within an extremely short time, it was concluded that they were similar, and thus the search stopped.
Figure 8b illustrates the results of the intersection similarity comparison with the videos in the suspect’s mobile device under scenario 1. The intersection algorithm also searched for a similar video on the basis of the BNM threshold shown in
Table 5. For three videos irrelevant to the query video (DNM_D, BNM_D, and BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of 0.48 or more, which is the threshold of the intersection algorithm within the BNM environment. Therefore, after all frames were searched, the comparison process went to the next video. For the original video BNM_O and the manipulated video BNM_E, a comparison was carried out from the middle of the total extracted frames in each of the two videos in accord with the pseudocode shown in
Figure 3. As with the correlation algorithm, the intersection algorithm determined within an extremely short time that they were similar, and thus the search stopped.
Figure 8c illustrates the results from the Bhattacharyya similarity comparison on the videos in the suspect’s mobile device under scenario 1. A similar video was identified based on the BNM threshold in
Table 5. For the three videos irrelevant to the query video (DNM_D, BNM_D, and BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of ≤0.52, which is the threshold of the Bhattacharyya algorithm in the BNM environment. Therefore, once all frames were searched, the comparison process moved to the next video. As for the original video BNM_O and the manipulated video BNM_E, the comparison was carried out from the middle of the total extracted frames in each of the two videos in accord with the pseudocode shown in
Figure 3. Similar to the correlation and intersection algorithms, the Bhattacharyya algorithm determined within an extremely short time that they were similar, and thus the search stopped.
For readability, the graphs in
Figure 8 do not show the parts without data after adjusting the y-axis. Using a manipulated video, a forensic investigation was applied to the suspect’s mobile device. As a result, it was possible to find not only a manipulated video but also the original video. Only 30% of the total frames of the original and manipulated videos were investigated. Nevertheless, it is possible to identify that they were similar. Once an original video is secured, if victims are shown or certain scenes in the original video are edited separately, it is possible to find all edited videos and reveal other crimes. This experiment is applicable to various real-world cases, such as the gradually increasing amount of revenge pornography, threatening acquaintances over social media, and the SNS distribution of illegally filmed videos after file size reduction.
4.2.3. Scenario 2
Under scenario 2, an investigator secured an original video and detected all edited and manipulated videos to be distributed in the suspect’s mobile device.
The comparison process under this scenario has the same steps as in Scenario 1. Nevertheless, when a query section is set in step 1, all parts considered to be crimes are included in the query section and are compared with a comparison video. If any of them is determined to be similar to the comparison video, the query video is identified as a manipulated video. Under scenario 2, two parts of the original video were set as a query section.
Table 8 presents the original video secured by an investigator and two query videos determined based on the query section selected by the investigator. All video names also show the criteria for the videos, as listed in
Table 4. In other words, if a video is original, its name has an ‘O’ (original) after the underscore (_); if manipulated, it has an ‘E’ (edit); and if unrelated to an original video, it has a ‘D’ (different).
Table 9 shows the videos of a suspect’s mobile device. As presented in
Figure 9, these videos were compared with query videos using an optimized comparison search. The suspect’s mobile device has five videos: two videos irrelevant to the query videos (DNM_D, Dark+Near+Middle_Different video; and BNH_D, Bright+Near+High_Different video), one original video of the query videos (BNM_O, Bright+Near+Middle_Original video), and two manipulated videos (BNM_E2; Bright+Near+Middle_Edit video1; and BNM_E2, Bright+Near+Middle_Edit video2).
Because these five videos have different run times, the total number of frames extracted is also different. A comparison was carried out in order of the videos listed in
Table 7. From the middle of the total frames of each video, a frame was compared with the query frame in accord with the pseudocode shown in
Figure 3. Subsequently, a similar video was identified based on the BNM threshold in
Table 5. If all results from the three algorithms for one frame are within the range of threshold for over 10 separate trials, the comparison process stops, and the video is identified as having been manipulated or identical.
Figure 10a illustrates the result from the correlation similarity comparison between Query Video_1 and the videos in the suspect’s mobile device under scenario 2. For two videos irrelevant to the Query video_1 (DNM_D and BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of 0.47 or higher, which is the threshold of the correlation algorithm in the BNM environment. Therefore, once all frames were searched, the comparison process moved to the next video. For the original video BNM_O and the manipulated videos BNM_E1 and BNM_E2, the comparison was processed from the middle frame of among all extracted frames in each of the videos in accord with the pseudocode shown in
Figure 3. Within an extremely short time, it was concluded that they were similar, and thus, the search process stopped.
Figure 10b illustrates the results from the intersection similarity comparison between Query Video_1 and the videos in the suspect’s mobile device under scenario 2. The intersection algorithm also searched for a similar video on the basis of the BNM threshold in
Table 5. For two videos irrelevant to the Query video_1 (DNM_D and BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of 0.48 or higher, which is the threshold of the intersection algorithm in the BNM environment. Therefore, once all frames were searched, the comparison process moved to the next video. For the original video BNM_O and the manipulated videos BNM_E1 and BNM_E2, the comparison was processed from the middle frame from among all extracted frames in each of the videos in accord with the pseudocode shown in
Figure 3. Within an extremely short time, it was concluded that they were similar, and thus the search process stopped.
Figure 10c illustrates the result from the Bhattacharyya similarity comparison between Query Video_1 and the videos in the suspect’s mobile device under scenario 2. The Bhattacharyya algorithm also searched for a similar video based on the BNM threshold, as shown in
Table 5. For two videos irrelevant to Query video_1 (DNM_D and BNH_D), the optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of ≤0.52, which is the threshold of the Bhattacharyya algorithm in a BNM environment. Therefore, once all frames were searched, the comparison process moved to the next video. For the original video BNM_O and the manipulated videos BNM_E1 and BNM_E2, a comparison was carried out from the middle of all extracted frames for each of the videos in accord with the pseudocode shown in
Figure 3. Within an extremely short time, it was concluded that they were similar, and thus the search process stopped. For readability, the graphs in
Figure 10 have no parts without data after adjusting the
y-axis.
The results of the experiment showed that BNM_O, BNM_E1, and BNM_E2 were similar. Except for similar videos, DNM_D was compared with BNH_D on the basis of the query video (2).
Figure 11a illustrates the correlation comparison between two videos (DNM_D and BNH_D) on the basis of Query Video_2. The optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of 0.47 or more, which is the threshold of the correlation algorithm in the BNM environment, similar to Query Video_1.
Figure 11b illustrates the intersection comparison between the two videos (DNM_D and BNH_D) based on Query Video_2. The optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of 0.48 or more, which is the threshold of the intersection algorithm in the BNM environment, similar to Query Video_1.
Figure 11c illustrates the Bhattacharyya comparison between the two videos (DNM_D and BNH_D) on the basis of Query Video_2. The optimization search began from the middle of the video in line with the pseudocode shown in
Figure 3. As a result, no frame had a similarity of ≥0.52, which is the threshold of the Bhattacharyya algorithm in the BNM environment, similar to Query Video_1. In terms of Query Video_2, the results from the comparison between DNM_D and BNH_D were not within the range of the thresholds. Therefore, there were no similar videos.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}