
Remote Sensing Road Extraction by Road Segmentation Network

Abstract
1. Introduction
- (1)
- To enhance road context features, an end-to-end road segmentation network is designed, since road connectivity is easily disturbed by noise.
- (2)
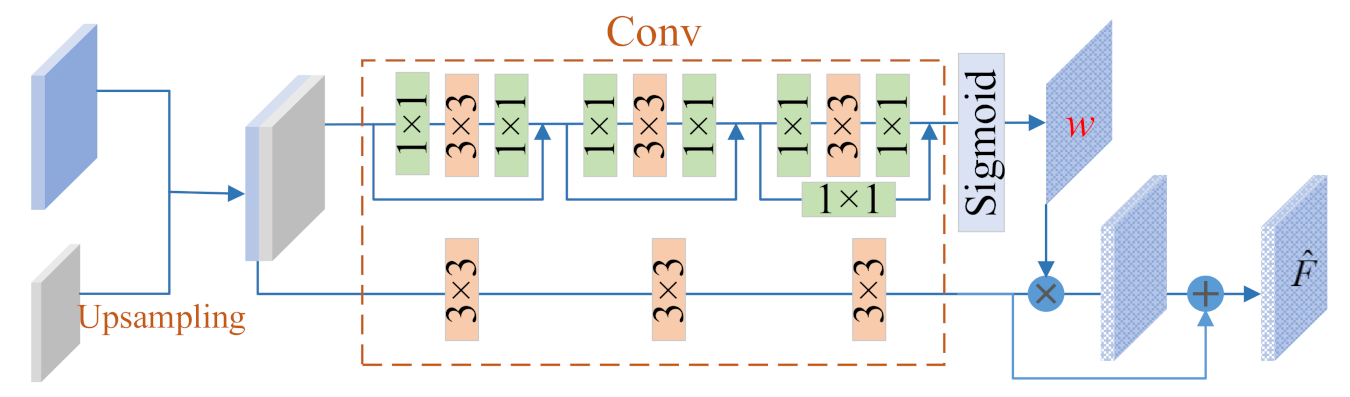
- To strengthen the context information belonging to the road, an inter-layer self-attention mechanism is introduced to generate weight maps.
- (3)
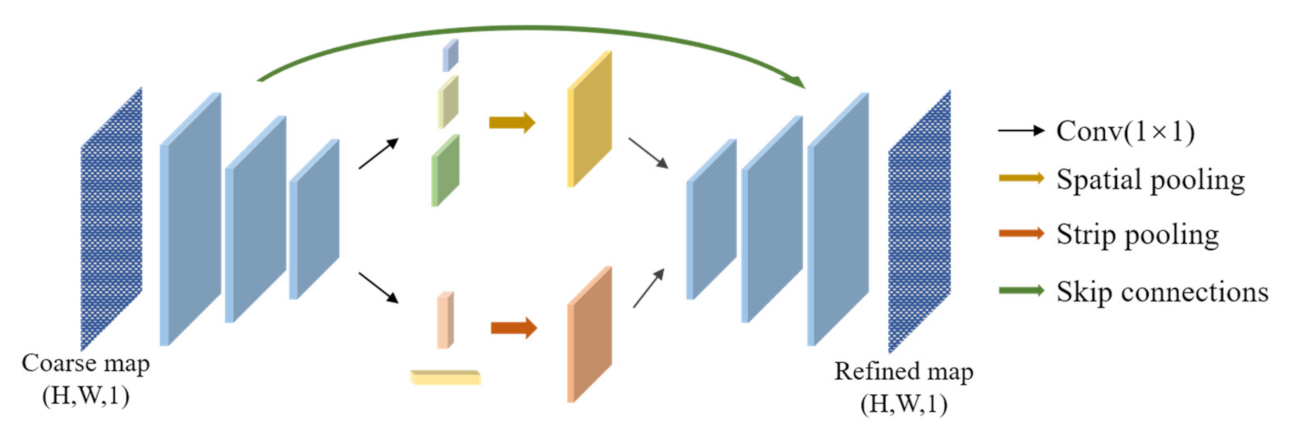
- To hold the strip information of the road, a refine network with the striping pooling is introduced to refine the results of the segmentation network.
2. Materials and Methods
2.1. Materials
2.2. The Proposed Method
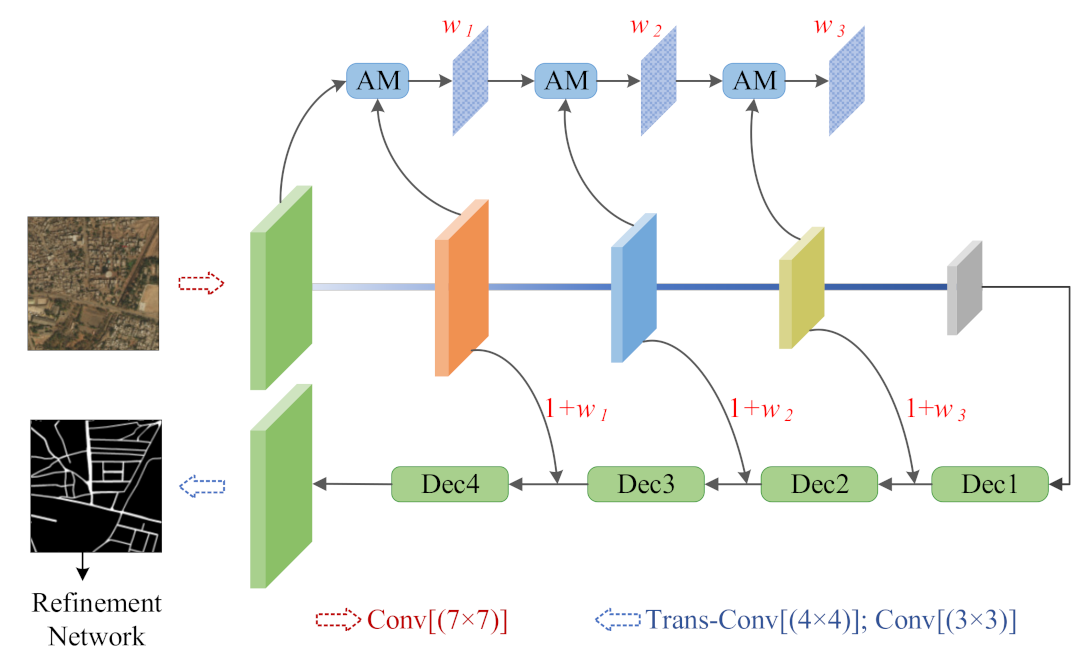
2.2.1. Network Architecture
2.2.2. Segmentation Step
2.2.3. Refinement Step
3. Experiments
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, Z.; Yang, L. Advances in method on road extraction from high resolution remote sensing images. Remote Sens. Technol. Appl. 2017, 32, 20–26. [Google Scholar]
- Zheng, X.; Yuan, Y.; Lu, X. Hyperspectral Image Denoising by Fusing the Selected Related Bands. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2596–2609. [Google Scholar] [CrossRef]
- Barzohar, M.; Cooper, D. Automatic finding of main roads in aerial images by using geometric-stochastic models and estimation. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 707–721. [Google Scholar] [CrossRef]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road Network Extraction and Intersection Detection from Aerial Images by Tracking Road Footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Song, M.; Civco, M. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, Y.; Lu, X. Deep balanced discrete hashing for image retrieval. Neurocomputing 2020, 403, 224–236. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Li, P.; Zang, Y.; Wang, C.; Li, J.; Cheng, M.; Luo, L.; Yu, Y. Road network extraction via deep learning and line integral convolution. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1599–1602. [Google Scholar] [CrossRef]
- Mattyus, G.; Luo, W.; Urtasun, R. DeepRoadMapper: Extracting Road Topology from Aerial Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3458–3466. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, X.; Lu, X. A Joint Relationship Aware Neural Network for Single-Image 3D Human Pose Estimation. IEEE Trans. Image Process. 2020, 29, 4747–4758. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Yuan, Y.; Lu, X. A Deep Scene Representation for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4799–4809. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4003–4012. [Google Scholar]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3376–3385. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, X.; Lu, X.; Sun, B. Unsupervised Change Detection by Cross-Resolution Difference Learning. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual Attention Inception Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| FCN | 97.42 | 77.98 | 51.16 | 61.78 |
| UNet | 97.68 | 74.68 | 60.44 | 66.81 |
| CasNet | 97.66 | 75.72 | 63.41 | 69.02 |
| ResUNet | 98.02 | 79.76 | 62.76 | 70.24 |
| D-LinkNet | 98.10 | 76.57 | 71.46 | 73.93 |
| Our | 98.25 | 79.99 | 70.00 | 74.66 |
| Method | OA (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| FCN | 97.35 | 74.83 | 53.36 | 62.29 |
| UNet | 97.55 | 75.06 | 55.47 | 63.79 |
| CasNet | 97.49 | 77.22 | 51.60 | 61.86 |
| ResUNet | 97.43 | 76.21 | 54.62 | 63.63 |
| D-LinkNet | 97.54 | 78.34 | 56.69 | 65.78 |
| Our | 97.68 | 79.58 | 56.66 | 66.19 |
| Method | OA (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| Base | 97.43 | 75.51 | 54.64 | 63.40 |
| Base + AM | 97.57 | 78.77 | 55.52 | 65.13 |
| Base + AM + DRN | 97.62 | 79.37 | 56.67 | 66.12 |
| Our | 97.68 | 79.58 | 56.66 | 66.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Gao, M.; Yang, K.; Duan, T. Remote Sensing Road Extraction by Road Segmentation Network. Appl. Sci. 2021, 11, 5050. https://doi.org/10.3390/app11115050
Tan J, Gao M, Yang K, Duan T. Remote Sensing Road Extraction by Road Segmentation Network. Applied Sciences. 2021; 11(11):5050. https://doi.org/10.3390/app11115050
Chicago/Turabian StyleTan, Jiahai, Ming Gao, Kai Yang, and Tao Duan. 2021. "Remote Sensing Road Extraction by Road Segmentation Network" Applied Sciences 11, no. 11: 5050. https://doi.org/10.3390/app11115050
APA StyleTan, J., Gao, M., Yang, K., & Duan, T. (2021). Remote Sensing Road Extraction by Road Segmentation Network. Applied Sciences, 11(11), 5050. https://doi.org/10.3390/app11115050