
Driving Behavior Modeling Based on Consistent Variable Selection in a PWARX Model


Abstract
:1. Introduction
2. Methodology
2.1. Overview
2.2. PWARX Model
2.3. Data Clustering
2.3.1. Feature Vector Extraction
2.3.2. Clustering Algorithm
2.4. Optimal Number of Sub-Models
| Algorithm 1 Deciding the optimum number of sub-models |
| Input: sets of clusters, for Output: Optimal number of sub-models, Initialisation:
|
2.5. Variable Selection and Identification of Parameters and Hyperplanes
3. Analysis and Modeling of Driving Behavior
3.1. Acquisition of Driving Data
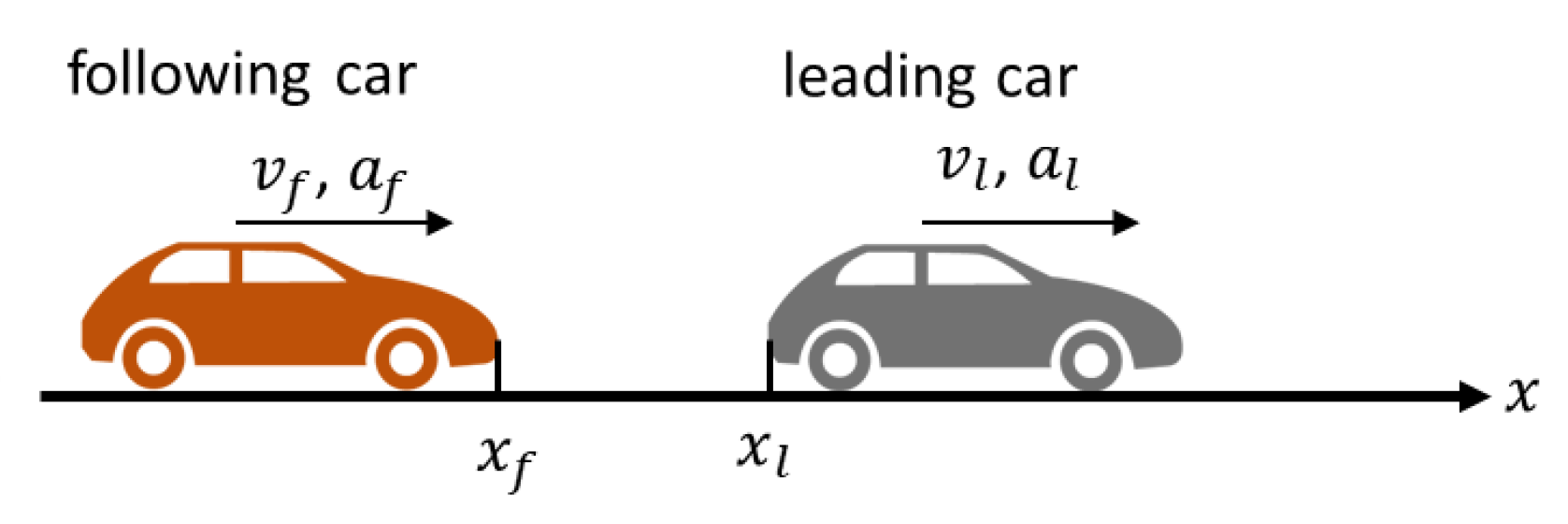
3.2. Definition of Input Candidates and Output
- Range (m): = ;
- Range rate (m/s): = ;
- KdB: ;
- Jerk (m/s): =
- Inverse of time to collision (rate of increase in visual angle to leading car) (s): = ;
- Time headway (time deference between cars) (s): = .
- Speed (m/s): y = .
3.3. Hyper-Parameters Used in the System Identification Process
- PWARX model: Input data are range, range rate, KdB, jerk, inverse of time collision, and time headway (). The Model output y is speed, and the number of data points N is approximately 4200 with a time step of 0.1 s for each driver. The first-order dynamics is considered as the controller model; thus, the regressor vector is .
- Feature vector extraction: The constant c (number of neighboring data points) is chosen as 200. This value was chosen by trial and error based on the data. As a general rule, 10% of the number of data points, N, is a good number for this constant.
- Optimal Number of Sub-models: K, P and n (folds) are chosen to be 10, 100 and 3, respectively. These values were chosen intuitively mainly based on the number of data points.
4. Modeling Results
4.1. Mode Segmentation
4.2. Variable Selection
5. Model Evaluation
5.1. Prediction Performance
5.2. Car-Following Simulation
- Step 1:
- Initialize the states of the ego car and leading car, in this case, position and velocity.
- Step 2:
- Based on the states, the input data of the driver model (∼) are computed.
- Step 3:
- The mode is decided based on SVM and the corresponding input data of the driver model are updated.
- Step 4:
- Using the identified driver model, the output (speed of ego car) is computed.
- Step 5:
- Update the states of the ego and leading cars based on the output of Step 3 and the leading car’s velocity pattern.
- Step 6:
- Go to Step 2.
6. Discussion
- The method presented in this study which is a combination of underlying dynamics identification and statistical model selection is well suited for understanding complex human driving behavior. The methodology proposed here was able to identify the variables responsible for the decision-making of the drivers in the car-following driving task. These variables as discussed in Section 4.1 are KdB () and range rate (). In other words, the values of these variables decide how the motion dynamics are controlled by the driver or what variables to use for the vehicle’s motion control. In addition, the variables range () and time headway () were identified using variable selection as the most influential variables in expressing the motion dynamics of the vehicle-following tasks for all the drivers. Furthermore, the model was able to identify the similarities (i.e., the decision-making variables and the influential motion dynamics variables) among the drivers, as well as the differences (i.e., the magnitudes of the decision-making variables and the differences in variable selection results) between drivers. Therefore, the direct application of this study is in designing controllers that can reflect drivers’ preferences and characteristics for automated driving. For example, looking at Table 4, to design the control dynamics of the cruising region (mode 3) for driver B, the variable jerk () must be paid attention to, whereas it is not necessary to consider this for driver A. These preferences in form of variable differences and the magnitudes of the parameters can be used for a personalized approach towards designing automated systems and ADAS. In addition, this method can be applied in order to gain knowledge about how the automation system/ADAS cooperate considering the human driver. Furthermore, by introducing flexibility in form of variable selection (i.e., using only the most influential variables) in the model, computational cost can be reduced, thereby facilitating online applications.
- This study presented a novel method for deciding the optimal number of behavioral segments (modes or clusters) from data based on consistent variable selection, thereby making it suitable for application in clustering or segmenting problems, particularly, where structural consistency of the identified clusters is of interest.
- Compared to the Gipps driver model, the proposed methodology was better both in prediction performance and in the car-following simulation, thereby, making it very suitable as a microscopic driver model in traffic flow applications, especially where expressing the actual driver behavior or personalized behavior generation is of importance.
- In the design of advanced driving assistance systems (ADAS) for car-following driving task, by using the work presented here, the driving situation (i.e., the mode) such as dangerous region, safe region, or cruising region could be identified either by using the specific explanatory variable’s value or by looking at the values of the decision variables (i.e., KdB and range rate). The assistance system can be tuned appropriately based on the identified driving situation, hence enabling a better and more reliable system that is able to complement the human driver efficiently.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sousa, N.; Almeida, A.; Coutinho-Rodrigues, J.; Natividade-Jesus, E. Dawn of autonomous vehicles: Review and challenges ahead. Proc. Inst. Civ. Eng. Munic. Eng. 2018, 171, 3–14. [Google Scholar] [CrossRef]
- Bartneck, C.; Lütge, C.; Wagner, A. Autonomous Vehicles. In An Introduction to Ethics in Robotics and AI; Springer Briefs in Ethics; Springer: Cham, Switzerland; Available online: https://doi.org/10.1007/978-3-030-51110-4_10 (accessed on 18 May 2021).
- Campbell, S.; O’Mahony, N.; Krpalcova, L.; Riordan, D.; Walsh, J.; Murphy, A.; Ryan, C. Sensor Technology in Autonomous Vehicles: A review. In Proceedings of the IEEE 2018 29th Irish Signals and Systems Conference (ISSC), Belfast, UK, 21–22 June 2018. [Google Scholar] [CrossRef]
- SAE International. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles, J3016-202104; SAE: Warrendale, PA, USA, 2021; Available online: https://www.sae.org/standards/content/j3016_202104/ (accessed on 18 May 2021).
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Rong, G.; Shin, B.H.; Tabatabaee, H.; Lu, Q.; Lemke, S.; Možeiko, M.; Boise, E.; Uhm, G.; Gerow, M.; Mehta, S.; et al. LGSVL Simulator: A High Fidelity Simulator for Autonomous Driving. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Artuñedo, A.; Godoy, J.; Villagra, J. A decision-making architecture for automated driving without detailed prior maps. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1645–1652. [Google Scholar]
- Hubmann, C.; Becker, M.; Althoff, D.; Lenz, D.; Stiller, C. Decision making for autonomous driving considering interaction and uncertain prediction of surrounding vehicles. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1671–1678. [Google Scholar] [CrossRef]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous Vehicles. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Angkititrakul, P.; Miyajima, C.; Takeda, K. Modeling and adaptation of stochastic driver-behavior model with application to car following. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 814–819. [Google Scholar]
- Keen, S.D.; Cole, D.J. Bias-free identification of a linear model- predictive steering controller from measured driver steering behavior. IEEE Trans. Syst. Man Cybern. B Cybern. 2012, 42, 434–443. [Google Scholar] [CrossRef]
- Pariota, L.; Bifulco, G.N.; Brackstone, M. A Linear Dynamic Model for Driving Behavior in Car Following. Transp. Sci. 2016, 50, 763–1138. [Google Scholar] [CrossRef]
- Yulei, J.; Cheng, R.; Hongxia, G. A New Continuum Model considering Driving Behaviors and Electronic Throttle Effect on a Gradient Highway. Math. Probl. Eng. 2020, 2020, 2172156. [Google Scholar]
- Hu, J.; Zhang, Y.; Zhao, R. Considering prevision driving behavior in car-following model. In Proceedings of the 2016 4th International Conference on Sensors, Mechatronics and Automation (ICSMA), Zhuhai, China, 12–13 November 2016; pp. 409–412. [Google Scholar]
- Wang, J.; Sun, F.; Cheng, R.; Ge, H. An extended car-following model considering the self-stabilizing driving behavior of headway. Phys. A Stat. Mech. Its Appl. 2018, 507, 347–357. [Google Scholar] [CrossRef]
- Zhu, W.-X.; Zhange, L.-D. A new car-following model for autonomous vehicles flow with mean expected velocity field. Phys. A Stat. Mech. Its Appl. 2018, 492, 2154–2165. [Google Scholar]
- Zhu, W.-X.; Zhang, H.M. Analysis of mixed traffic flow with human-driving and autonomous cars based on car-following model. Phys. A Stat. Mech. Its Appl. 2018, 496, 274–285. [Google Scholar] [CrossRef]
- Ou, H.; Tang, T.Q. An extended two-lane car-following model accounting for inter-vehicle communication. Phys. A Stat. Mech. Its Appl. 2018, 495, 260–268. [Google Scholar] [CrossRef]
- Treiber, M.; Kesting, A. The Intelligent Driver Model with Stochasticity—New Insights Into Traffic Flow Oscillations. In Proceedings of the 22nd International Symposium on Transportation and Traffic Theory, Chicago, IL, USA, 24–26 July 2017. [Google Scholar]
- Aoude, G.S.; Desaraju, V.R.; Stephens, L.H.; How, J.P. Driver behavior classification at intersections and validation on large naturalistic data set. IEEE Trans. Intell. Transp. Syst. 2012, 13, 724–736. [Google Scholar] [CrossRef]
- Tanaka, D.; Baba, Y.; Kashima, H.; Okubo, Y. Large-scale Driver Identification Using Automobile Driving Data. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3441–3446. [Google Scholar]
- Marchegiani, L.; Posner, I. Long-Term Driving Behaviour Modelling for Driver Identification. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 913–919. [Google Scholar]
- Jafarnejad, S.; Castignani, G.; Engel, T. Towards a real-time driver identification mechanism based on driving sensing data. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 November 2017; pp. 1–7. [Google Scholar]
- Martínez, M.V.; Echanobe, J.; del Campo, I. Driver identification and impostor detection based on driving behavior signals. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 372–378. [Google Scholar]
- Hongyu, H.; Jiarui, L.; Zhenhai, G.; Pin, W. Driver identification using 1D convolutional neural networks with vehicular CAN signals. IET Intell. Transp. Syst. 2020, 14, 1799–1809. [Google Scholar]
- Bethge, J.; Moribito, B.; Rewald, H.; Ahsan, A.; Sorgatz, S.; Findeisen, R. Modelling Human Driving Behavior for Constrained Model Predictive Control in Mixed Traffic at Intersections. IFAC-PapersOnLine 2020, 53, 14356–14362. [Google Scholar] [CrossRef]
- Akai, N.; Hirayama, T.; Morales, Y.; Akagi, Y.; Liu, H.; Murase, H. Driving Behavior Modeling Based on Hidden Markov Models with Driver’s Eye-Gaze Measurement and Ego-Vehicle Localization. In Proceedings of the IEEE Intelligent Vehicles Symposium 2019, Paris, France, 9–12 June 2019; pp. 949–956. [Google Scholar]
- Tejada, A.; Manders, J.; Snijders, R.; Paardekooper, J.P.; de Hair-Buijssen, S. Towards a Characterization of Safe Driving Behavior for Automated Vehicles Based on Models of “Typical” Human Driving Behavior. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Martínez-García, M.; Zhang, Y.; Gordon, T. Modeling Lane Keeping by a Hybrid Open-Closed-Loop Pulse Control Scheme. IEEE Trans. Ind. Inform. 2016, 12, 2256–2265. [Google Scholar] [CrossRef] [Green Version]
- Codevilla, F.; Müller, M.; López, A.; Koltun, V.; Dosovitskiy, A. End-to-end Driving via Conditional Imitation Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4693–4700. [Google Scholar]
- Zec, E.L.; Mohammadiha, N.; Schliep, A. Statistical Sensor Modelling for Autonomous Driving Using Autoregressive Input-Output HMMs. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1331–1336. [Google Scholar]
- Sama, K.; Morales, Y.; Akai, N.; Liu, H.; Takeuchi, E.; Takeda, K. Driving Feature Extraction and Behavior Classification Using an Autoencoder to Reproduce the Velocity Styles of Experts. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1337–1343. [Google Scholar]
- AbuAli, N.; Abou-zeid, H. Driver Behavior Modeling: Developments and Future Directions. Int. J. Veh. Technol. 2016, 2016, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Vidal, R.; Ma, Y.; Sastry, S.S. Hybrid System Identification. In Generalized Principal Component Analysis. Interdisciplinary Applied Mathematics; Springer: New York, NY, USA, 2016; Volume 40. [Google Scholar]
- Zhao, P. A Review on Machine Learning and Gesture Recognition. In Proceedings of the International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; pp. 425–428. [Google Scholar]
- Vignesh Kanna, J.S.; Ebenezer Raj, S.M.; Meena, M.; Meghana, S.; Mansoor Roomi, S. Deep Learning Based Video Analytics for Person Tracking. In Proceedings of the International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–6. [Google Scholar]
- Zhang, J.; Felsen, P.; Kanazawa, A.; Malik, J. Predicting 3D Human Dynamics from Video. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7113–7122. [Google Scholar]
- Ferrari-Trecate, G.; Muselli, M.; Liberati, D.; Morari, M. A clustering technique for the identification of piecewise affine system. Automatica 2003, 39, 205–217. [Google Scholar] [CrossRef]
- Hamada, R.; Kubo, T.; Ikeda, K.; Zhang, Z.; Shibata, T.; Bando, T.; Hitomi, K.; Egawa, M. Modeling and Prediction of Driving Behaviors Using a Non-parametric Bayesian Method with AR Models. IEEE Trans. Intell. Veh. 2016, 1, 131–138. [Google Scholar] [CrossRef]
- Jianhong, J. Zonotope parameter identification for piecewise affine systems. J. Syst. Eng. Electron. 2020, 31, 1077–1084. [Google Scholar] [CrossRef]
- Du, Y.; Liu, F.; Qiu, J.; Buss, M. A Semi-Supervised Learning Approach for Identification of Piecewise Affine Systems. IEEE Trans. Circuits Syst. Regul. Pap. 2020, 67, 3521–3532. [Google Scholar] [CrossRef]
- Sun, X.; Cai, Y.; Xu, X.; Chen, L. Piecewise Affine Identification of Tire Longitudinal Properties for Autonomous Driving Control Based on Data-Driven. IEEE Access 2018, 6, 47424–47432. [Google Scholar] [CrossRef]
- Mejari, M.; Breschi, V.; Piga, D. Recursive Bias-Correction Method for Identification of Piecewise Affine Output-Error Models. IEEE Control Syst. Lett. 2020, 6, 970–975. [Google Scholar] [CrossRef]
- Zhang, P.; She, K. A Novel Hierarchical Clustering Approach Based on Universal Gravitation. Math. Probl. Eng. 2020, 2020, 1–20. [Google Scholar] [CrossRef]
- Patil, C.; Baidari, I. Estimating the Optimal Number of Clusters k in a Dataset Using Data Depth. J. Data Sci. Eng. 2019, 4, 132–140. [Google Scholar] [CrossRef] [Green Version]
- Fu, W.; Perry, P.O. Estimating the Number of Clusters Using Cross-Validation. J. Comput. Graph. Stat. 2020, 29, 162–173. [Google Scholar] [CrossRef]
- Terada, R.; Okuda, H.; Suzuki, T.; Isaji, K.; Tsuru, N. Multi-scale driving behavior modeling using hierarchical PWARX model. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Madeira Island, Portugal, 19–22 September 2010; pp. 1638–1644. [Google Scholar]
- Akita, T.; Suzuki, T.; Hayakawa, S.; Inagaki, S. Analysis and Synthesis of Driving Behavior based on Mode Segmentation. In Proceedings of the International Conference on Control, Automation and Systems, Seoul, Korea, 14–17 October 2008; pp. 2884–2889. [Google Scholar]
- Sekizawa, S.; Inagaki, S.; Suzuki, T.; Hayakawa, S.; Tsuchida, N.; Tsuda, T.; Fujinami, H. Modeling and Recognition of Driving Behavior Based on Stochastic Switched ARX Model. IEEE Trans. Intell. Transp. Syst. 2007, 8, 593–606. [Google Scholar] [CrossRef] [Green Version]
- Konishi, S.; Kitagawa, G. Information Criteria and Statistical Modeling, 1st ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Nwadiuto, J.; Chin, H.; Okuda, H.; Suzuki, T. Analysis and Modeling of Real World Car-Following Driving in Downtown Area Based on Variable Structured Piecewise Linear Model. In Proceedings of the 22nd IEEE International Conference on Intelligent Transportation Systems, Auckland, New Zealand, 27–30 October 2019; pp. 1211–1216. [Google Scholar]
- Johannes, F. Round Robin Classification. J. Mach. Learn. Res. 2002, 2, 721–747. [Google Scholar]
- Escalera, S.; Pujol, O.; Radeva, P. Separability of ternary codes for sparse designs of error-correcting output codes. Pattern Recognit. Lett. 2009, 30, 285–297. [Google Scholar] [CrossRef]
- Wada, T.; Imai, K.; Tsuru, N.; Isaji, K.; Kaneko, H. Analysis of drivers’ behaviors in car following based on a performance index for approach and alienation. In Proceedings of the Society of Automotive Engineer (SAE) World Congress, Detroit, MI, USA, 16–19 April 2007. [Google Scholar]
- Gipps, P. Behavioural Car-Following Model for Computer Simulation. Transp. Res. Part B Methodol. 1981, 15, 105–111. [Google Scholar] [CrossRef]
Short Biography of Authors
 | Jude Chibuike Nwadiuto was born in Imo, Nigeria, in 1992. He received the B.E. and M.E. degrees in Automotive Engineering from Nagoya University in 2016 and 2018, respectively. |
| He is currently working towards the Doctor’s degree with the Department of Mechanical Systems Engineering, Nagoya University. His research interests include modeling and analysis of human driving behavior, and the design of personalized assistance systems for automated driving. | |
 | Hiroyuki Okuda was born in Gifu, Japan, in 1982. He received B.E. and M.E. degrees in Advanced Science and Technology from Toyota Technological Institute, Japan in 2005 and 2007, respectively, and he received a Ph.D. degree in Mechanical Science and Engineering from Nagoya University, Japan in 2010. |
| Currently, he is an associate professor in the Department of Mechanical Science and Engineering at Nagoya University. His research interests are in the areas of system identification of hybrid dynamical system and its application to the modeling and analysis of human behavior and human-centered system design of autonomous/human-machine cooperative system. | |
| Dr. Okuda is a member of the IEEE, IEEJ, SICE, and JSME. | |
 | Tatsuya Suzuki was born in Aichi, Japan, in 1964. He received the B.S., M.S. and Ph.D. degrees in Electronic Mechanical Engineering from Nagoya University, JAPAN in 1986, 1988 and 1991, respectively. Currently, he is a Professor of the Department of Mechanical Systems Engineering, Executive Director of Global Research Institute for Mobility in Society (GREMO), Nagoya University. |
| He won the best paper award in International Conference on Autonomic and Autonomous Systems 2017 and the outstanding paper award in International Conference on Control Automation and Systems 2008. He also won the journal paper award from IEEJ, SICE and JSAE in 1995, 2009 and 2010, respectively. His current research interests are in the areas of analysis and design of human-centric intelligent mobility systems, and integrated design of transportation and smart grid systems. | |
| Dr. Suzuki is a member of the SICE, ISCIE, IEICE, JSAE, RSJ, JSME, IEEJ and IEEE. |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Driver | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| Optimal Number of Modes | 3 | 3 | 4 | 3 | 3 | 3 |
| Driver | Mode (i) | y | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 14.7967 | −0.7365 | 82.9239 | −0.0947 | 0.0573 | 1.6321 | 9.0802 | |
| A | 2 | 10.1805 | 2.5240 | −115.3931 | −0.1916 | −0.2338 | 2.4917 | 4.5813 |
| 3 | 15.2099 | 0.9024 | −76.5456 | −0.0726 | −0.0564 | 1.7508 | 8.8569 | |
| 1 | 19.1161 | −1.0761 | 82.1025 | −0.1442 | 0.0599 | 2.8145 | 6.8006 | |
| B | 2 | 13.2032 | 3.0255 | −107.8165 | −0.0773 | −0.2275 | 5.1354 | 3.2444 |
| 3 | 25.3100 | 0.9317 | −55.9455 | −0.0544 | −0.0425 | 3.5853 | 7.1059 | |
| 1 | 22.5530 | −1.0362 | 75.2793 | −0.1437 | 0.0507 | 3.1521 | 7.2707 | |
| C | 2 | 12.4296 | 3.0010 | −111.8950 | 0.2716 | −0.2467 | 6.1057 | 2.6634 |
| 3 | 26.6439 | 1.7252 | −76.8184 | −0.0072 | −0.0784 | 4.7373 | 6.0309 | |
| 4 | 22.5461 | 0.7366 | −65.0536 | −0.0227 | −0.0341 | 2.9458 | 7.8383 | |
| 1 | 7.4822 | 1.4649 | −113.5721 | −0.1556 | −0.1883 | 3.9329 | 2.5935 | |
| D | 2 | 10.4366 | −0.6515 | 65.4002 | 0.0329 | 0.0567 | 2.4888 | 4.5814 |
| 3 | 19.3710 | 0.7052 | −56.4716 | 0.0466 | −0.0444 | 2.6940 | 7.4533 | |
| 1 | 17.9504 | −1.0276 | 80.6962 | −0.2128 | 0.0603 | 2.3383 | 7.7231 | |
| E | 2 | 10.6959 | 2.2784 | −112.2794 | −0.3386 | −0.2163 | 3.3595 | 3.8392 |
| 3 | 23.4378 | 0.8599 | −52.0313 | −0.0258 | −0.0424 | 2.9062 | 8.4229 | |
| 1 | 14.5640 | −0.7783 | 80.2988 | −0.1284 | 0.0632 | 1.6611 | 8.6957 | |
| F | 2 | 13.7065 | 1.2122 | −95.2759 | −0.0027 | −0.1033 | 2.0076 | 7.6085 |
| 3 | 18.1030 | 0.2739 | −25.9114 | −0.1185 | −0.0134 | 1.8595 | 9.6969 |
| Driver | Mode (i) | Mean | Median | Min | Max | Variance |
|---|---|---|---|---|---|---|
| 1 | −0.2138 | −0.0740 | −3.6593 | 0.6906 | 0.2388 | |
| A | 2 | 0.9392 | 0.9349 | 0 | 2.9056 | 0.1665 |
| 3 | 0.3748 | 0.3834 | −0.9020 | 1.4440 | 0.1115 | |
| 1 | −0.2615 | −0.2228 | −1.1884 | 0.7133 | 0.1079 | |
| B | 2 | 0.9344 | 0.9809 | 0 | 2.3506 | 0.1787 |
| 3 | 0.2500 | 0.1964 | −0.6297 | 1.0465 | 0.0890 | |
| 1 | −0.1870 | −0.2072 | −1.0996 | 0.6637 | 0.1017 | |
| C | 2 | 0.8761 | 0.8607 | 0.2885 | 1.4045 | 0.0354 |
| 3 | 0.4271 | 0.4203 | −0.4586 | 1.0572 | 0.0884 | |
| 4 | 0.2023 | 0.1794 | −0.6098 | 0.9715 | 0.0752 | |
| 1 | 1.0527 | −0.2552 | 0 | 0 | −0.0445 | |
| D | 2 | 1.2829 | 0.1571 | 0 | 0 | 0 |
| 3 | 0.9368 | 0.1388 | 0.0282 | 0 | 0.2396 | |
| 1 | −0.2177 | −0.2102 | −1.1146 | 0.5746 | 0.0899 | |
| E | 2 | 0.7833 | 0.8386 | −0.1192 | 1.7035 | 0.1054 |
| 3 | 0.2525 | 0.2473 | −0.7444 | 1.2167 | 0.1151 | |
| 1 | −0.3308 | −0.2750 | −1.5212 | 0.9163 | 0.1819 | |
| F | 2 | 0.6636 | 0.6305 | −0.8367 | 2.0976 | 0.2561 |
| 3 | 0.1177 | 0.0589 | −0.6595 | 1.0675 | 0.1290 |
| Driver | Mode (i) | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 1.4078 | −0.1736 | −0.0468 | 0 | −0.1989 | −3.3325 | ||
| A | 3 | 2 | 0.4244 | 0 | 0.9857 | 0 | −0.1722 | −0.7046 |
| 3 | 1.2801 | −0.0813 | 0 | 0 | 0 | −2.8269 | ||
| 1 | 1.1372 | −0.3606 | 0.0466 | 0 | −0.5636 | −3.6705 | ||
| B | 3 | 2 | 0.7422 | 0 | 0 | −0.0442 | 0 | −0.5291 |
| 3 | 0.8931 | 0.2098 | 0.0122 | 0.1740 | 0.2186 | −2.7398 | ||
| 1 | 1.0559 | 0.1846 | −0.1030 | −0.2635 | 0.2396 | −3.1566 | ||
| C | 4 | 2 | 0.2212 | 0.1369 | 0.4913 | −0.0262 | 0 | −0.4392 |
| 3 | 0.7282 | 0.0547 | 0.0798 | 0 | 0 | −1.5486 | ||
| 4 | 1.0575 | 0.2268 | 0 | 0 | 0.3105 | −3.6367 | ||
| 1 | 1.0527 | −0.2552 | 0 | 0 | −0.0445 | −0.6431 | ||
| D | 3 | 2 | 1.2829 | 0.1571 | 0 | 0 | 0 | −3.5322 |
| 3 | 0.9368 | 0.1388 | 0.0282 | 0 | 0.2396 | −5.7718 | ||
| 1 | 1.3472 | 0 | 0 | 0 | −0.0929 | −5.2117 | ||
| E | 3 | 2 | 0.7686 | −0.2376 | 0.4456 | −0.0301 | −0.1950 | −0.9302 |
| 3 | 0.9445 | 0 | 0 | 0 | 0 | −2.9450 | ||
| 1 | 0.9255 | −0.3834 | 0.0337 | 0 | −0.6098 | −1.5482 | ||
| F | 3 | 2 | 0.9039 | −0.1619 | 0.1191 | 0 | 0 | −1.0215 |
| 3 | 0.9646 | −0.1796 | 0 | −0.3678 | 0 | −1.8258 |
| Driver | Mode (i) | Gipps Model | Proposed Model |
|---|---|---|---|
| 1 | 6.8086 | 0.0426 | |
| A | 2 | - | - |
| 3 | 6.1663 | 0.3003 | |
| 1 | 0.4176 | 0.1144 | |
| B | 2 | 0.1421 | 0.2902 |
| 3 | 0.2351 | 0.0796 | |
| 1 | 1.7185 | 0.0711 | |
| C | 2 | - | - |
| 3 | 0.6308 | 0.0713 | |
| 4 | 1.8837 | 0.1043 | |
| 1 | 1.0527 | 0.1129 | |
| D | 2 | 1.2829 | 0.1011 |
| 3 | 0.9368 | 0.1187 | |
| 1 | 5.34527 | 0.0528 | |
| E | 2 | - | - |
| 3 | 5.0658 | 0.3154 | |
| 1 | 4.0194 | 0.1489 | |
| F | 2 | 3.5276 | 0.1669 |
| 3 | 4.9792 | 0.1377 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nwadiuto, J.C.; Okuda, H.; Suzuki, T. Driving Behavior Modeling Based on Consistent Variable Selection in a PWARX Model. Appl. Sci. 2021, 11, 4938. https://doi.org/10.3390/app11114938
Nwadiuto JC, Okuda H, Suzuki T. Driving Behavior Modeling Based on Consistent Variable Selection in a PWARX Model. Applied Sciences. 2021; 11(11):4938. https://doi.org/10.3390/app11114938
Chicago/Turabian StyleNwadiuto, Jude Chibuike, Hiroyuki Okuda, and Tatsuya Suzuki. 2021. "Driving Behavior Modeling Based on Consistent Variable Selection in a PWARX Model" Applied Sciences 11, no. 11: 4938. https://doi.org/10.3390/app11114938
APA StyleNwadiuto, J. C., Okuda, H., & Suzuki, T. (2021). Driving Behavior Modeling Based on Consistent Variable Selection in a PWARX Model. Applied Sciences, 11(11), 4938. https://doi.org/10.3390/app11114938