Based on the above discussion on the advantages and disadvantages of different feature and classification techniques, this section starts by explaining the dataset utilized and details the methodology and process we used to carry out this study.
3.1. Synthetic Domestic Acoustic Database
Synthesizing our own database allows the production of data that address issues commonly faced in a certain environment and recreates scenarios that could occur in real life. This includes noisy environments, as well as various source-to-receiver distances. Furthermore, this also provides the exact locations of the sound sources.
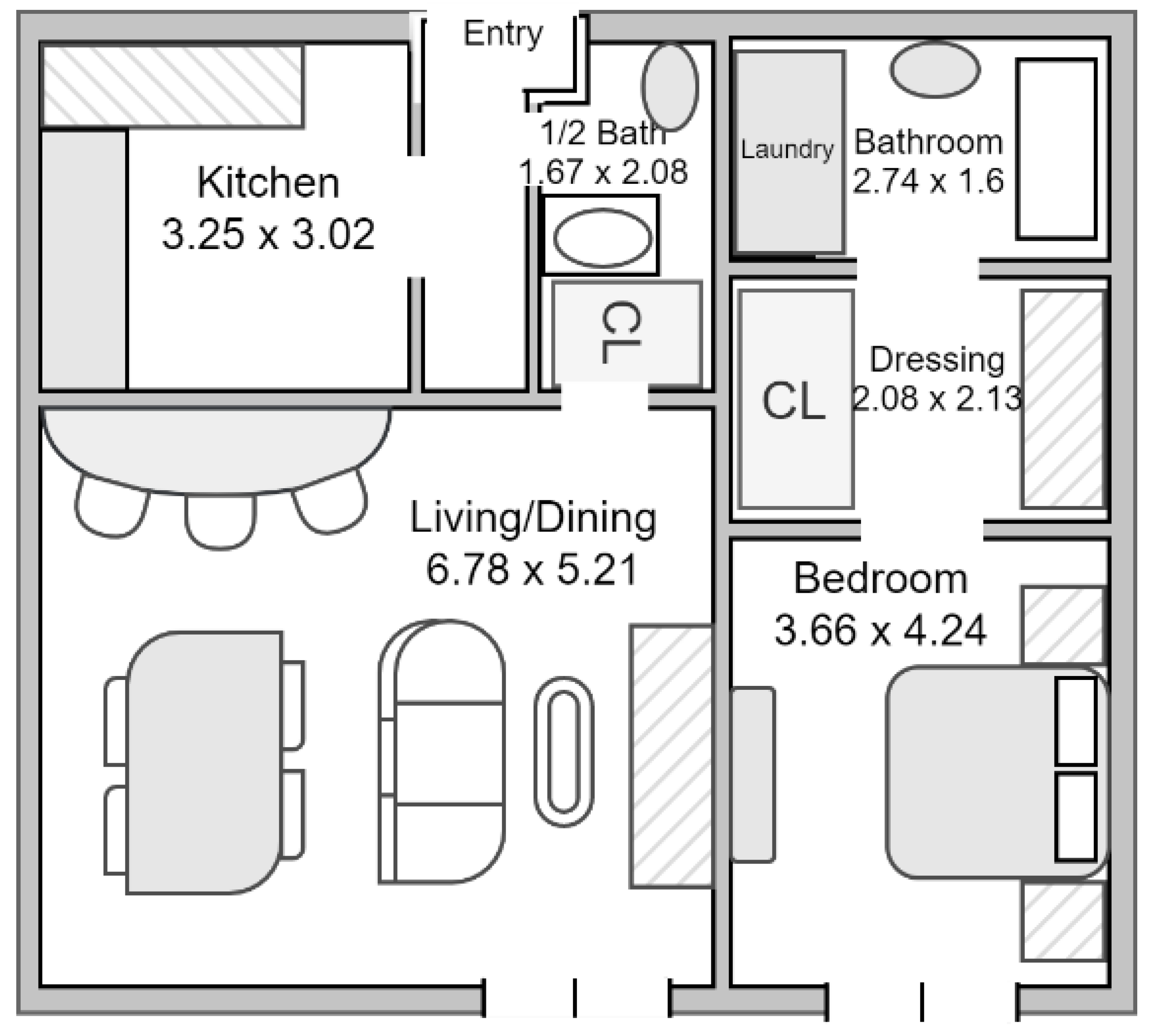
For this work, the generation of the synthetic database was done based on a 92.81 m
2 one-bedroom apartment modelled after the Hebrew Senior Life Facility [
47], illustrated in
Figure 2. We assumed a 3 m height for the ceiling. Multi-channel recordings were aimed for; hence, microphone arrays were placed on each of the four corners of the six rooms at 0.2 m below the ceiling. This produced four recordings, one from each of the receiver nodes.
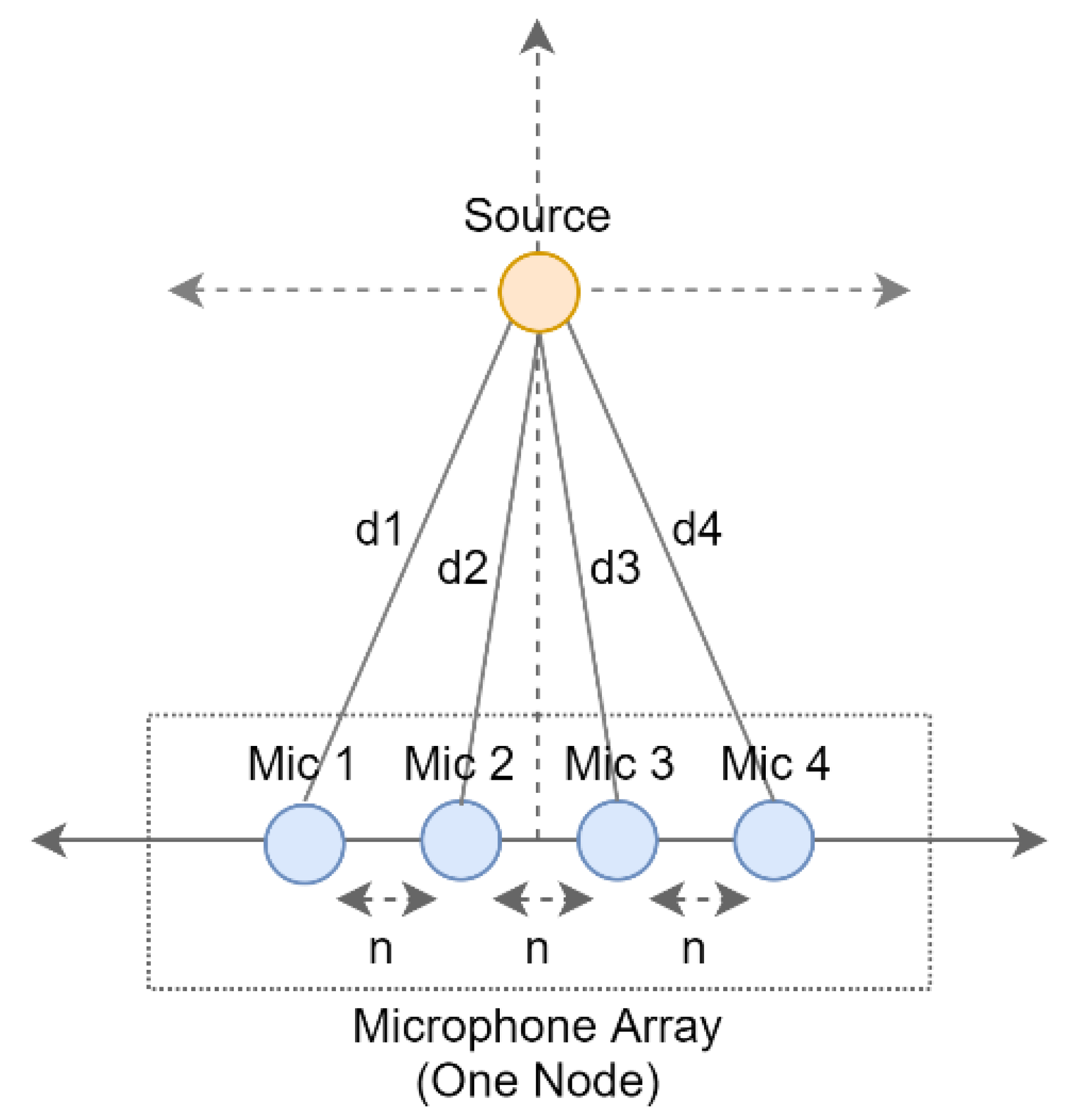
Accordingly, the microphone arrays were composed of four linearly arranged omnidirectional microphones with 5 cm inter-microphone spacing (
n), as per the geometry provided in
Figure 3, where
d refers to the distance from the sound source to the microphones.
Dry samples are taken from Freesound (FSD50K) [
48], Kaggle [
49], DESED Synthetic Soundscapes [
50], and Open SLR [
51], depending on the audio class. Due to the variations in sampling frequency, some of the audio signals were down sampled to 16 kHz for uniformity purposes. The room dimensions, source and receiver locations, wall reflectance, and other relevant information, were then used in order to calculate the impulse response for each room using the image method, incorporating source directivity [
52]. This was then convolved with the sounds, specifying their location, in order to create the synthetic data. The data generated included clean signals, as well as different types of noisy signals, including: children playing, air conditioner, and street music, added at three different SNR levels: 15 dB, 20 dB, and 25 dB. The duration of each audio signal was uniformly kept at 5-s, as this was found to provide satisfactory time resolution for the sound scenes and events detected in this work.
Table 2 describes this dataset. This data was curated such that the testing data consisted of one noise level for each node. Any instances of the data contained in the test set were then removed from the training data. The testing set content is summarized for a specific sound being recorded at four nodes:
Node 1: Clean Signal with 15 dB Noise
Node 2: Clean Signal with 20 dB Noise
Node 3: Clean Signal with 25 dB Noise
Node 4: Clean Signal
This ensures that even when the same sound is being recorded by the four nodes present, it reduces the chances of biasing through the addition of different types of noise at different SNR levels. Further, this was also designed to reflect real life recordings, where the sound from different microphones may differ based on their distance to the source and other sounds present in their surroundings.
As observed, audio classes used in the generation of this database focus on sound events and scenes that often occur, or require an urgent response, in dementia patients’ environment. Further, this was also generated through the room impulse responses of the HebrewLife Senior Facility [
47], in order to reflect a realistic patient environment. This is because assistance monitoring systems are real-world applications of deep-learning audio classifiers, such as the work presented in this paper. Nonetheless, this can also be extended to other application domains as previously discussed.
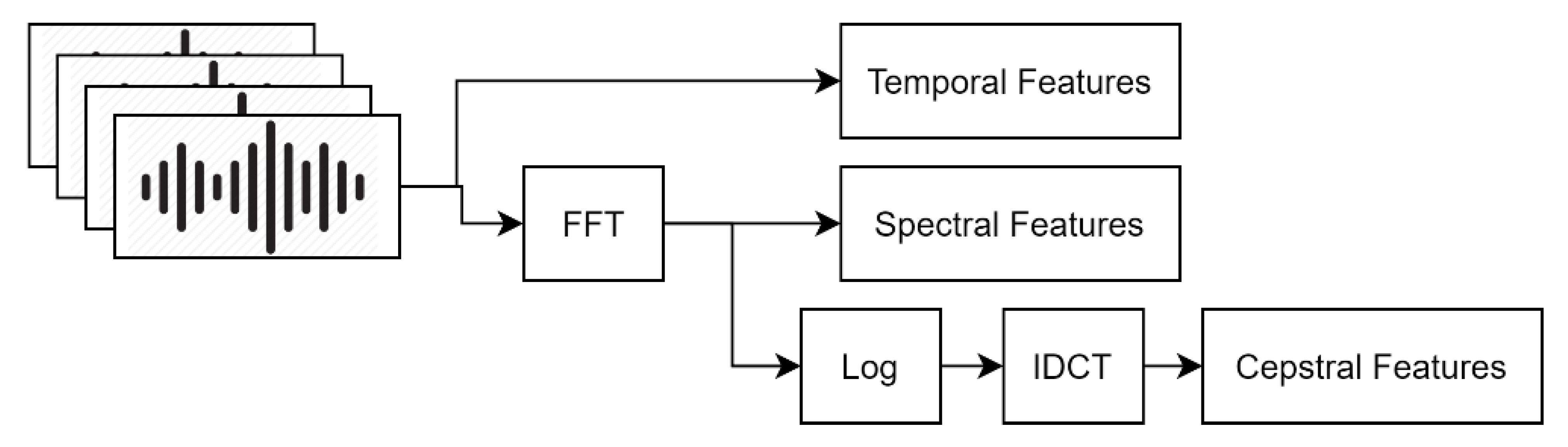
3.2. Feature Extraction Using Fast CWT Scalograms
The CWT has several similarities to the Fourier transforms, such that it utilizes inner products in order to compute the similarity between the signal and an analysing function [
53]. However, in the case of CWT, the analysing function is a wavelet, and the coefficients are the results of the comparison of the signal against shifted, scaled, and dilated versions of the wavelet, which are called constituent wavelets [
53]. Compared with the STFT, wavelets provide better time-localization [
30] and are more beneficial to non-stationary signals [
53].
However, in order to reduce the computational requirements for deriving scalograms, this work proposes the use of the Fast Fourier Transform (FFT) algorithm for CWT coefficients computation [
30]. Such that, if we define the mother wavelet (
Ψ) to be [
30], where
t refers to continuous time:
Then Equation (3), involving the
CWT coefficients, can be rewritten as follows [
30], where
refers to the average of the four-channels of the audio signal:
This shows that
CWT coefficients can be expressed by the convolution of wavelets and signals. Thus, this can be written in the Fourier transform form domain, resulting in Equation (7) [
30]:
where
specifies the Fourier transform of the mother wavelet at scale
t:
Further,
then denotes the Fourier transform of the analysed signal
:
Hence, the discrete versions of the convolutions can be represented as per Equation (10), where n is in discrete time domain:
From the sum in Equation (10), we can observe that CWT coefficients can be derived from the repetitive computation of the convolution of the signal, along with the wavelets, at every value of the scale per location [
30]. This work follows this process in order to extract the DFT of the CWT coefficients at a faster rate compared to the traditional method.
In summary, CWT coefficients are calculated through obtaining both the DFT of the signal, as per Equation (9), and the Morlet analysing function, as per Equation (8), via the FFT. The products of these are then derived and integrated, as per Equation (6), in order to extract the wavelet coefficients. Accordingly, the discrete version of the integration can be represented as a summation, which is observed in Equation (10).
3.2.1. Feature Representation
Feature computation is carried out in MATLAB, exploiting functionalities provided in the Audio System and Data Communications toolboxes. A total of 20 filter bank channels with 12 cepstral coefficients are used for the cepstral feature extraction, as per the standard after DCT application [
54]. An FFT size of 1024 is utilized, while the lower and upper filter bank frequency limits are set to 300 Hz and 3700 Hz. This frequency range includes the main components of speech signals (specifically, narrowband speech), while filtering out the humming sounds from the alternating current power, as well as high frequency noise [
55]. Further, this range is relevant to the sound classes of speech and scream, and was found to also include the main components of the other classes. While larger frequency ranges could also be considered, this would require much larger FFT sizes to maintain the same frequency resolution, which in turn would increase the computational requirements. The extraction of the feature vectors is carried out by computing the average of the four time-aligned channels in the time domain,
. The coefficients are then extracted accordingly, from which single feature matrices are generated. The feature images are resized into 227 × 227 matrices using a bi-cubic interpolation algorithm with antialiasing [
56], in order to match the input dimensionality of the AlexNet neural network model.
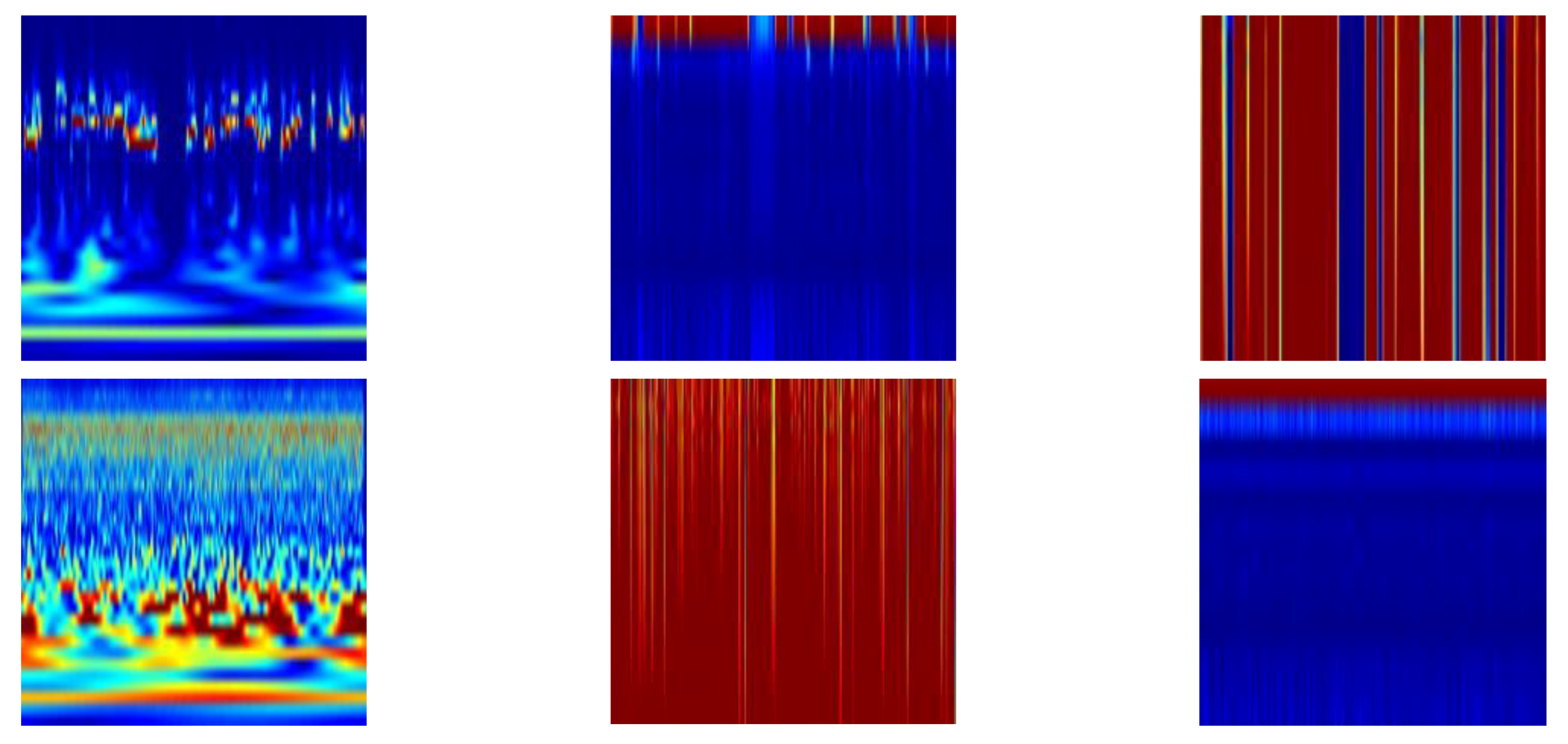
Figure 4 shows samples of feature images for each of the three features compared, using the ‘Speech’ and ‘Kitchen sound’ classes.
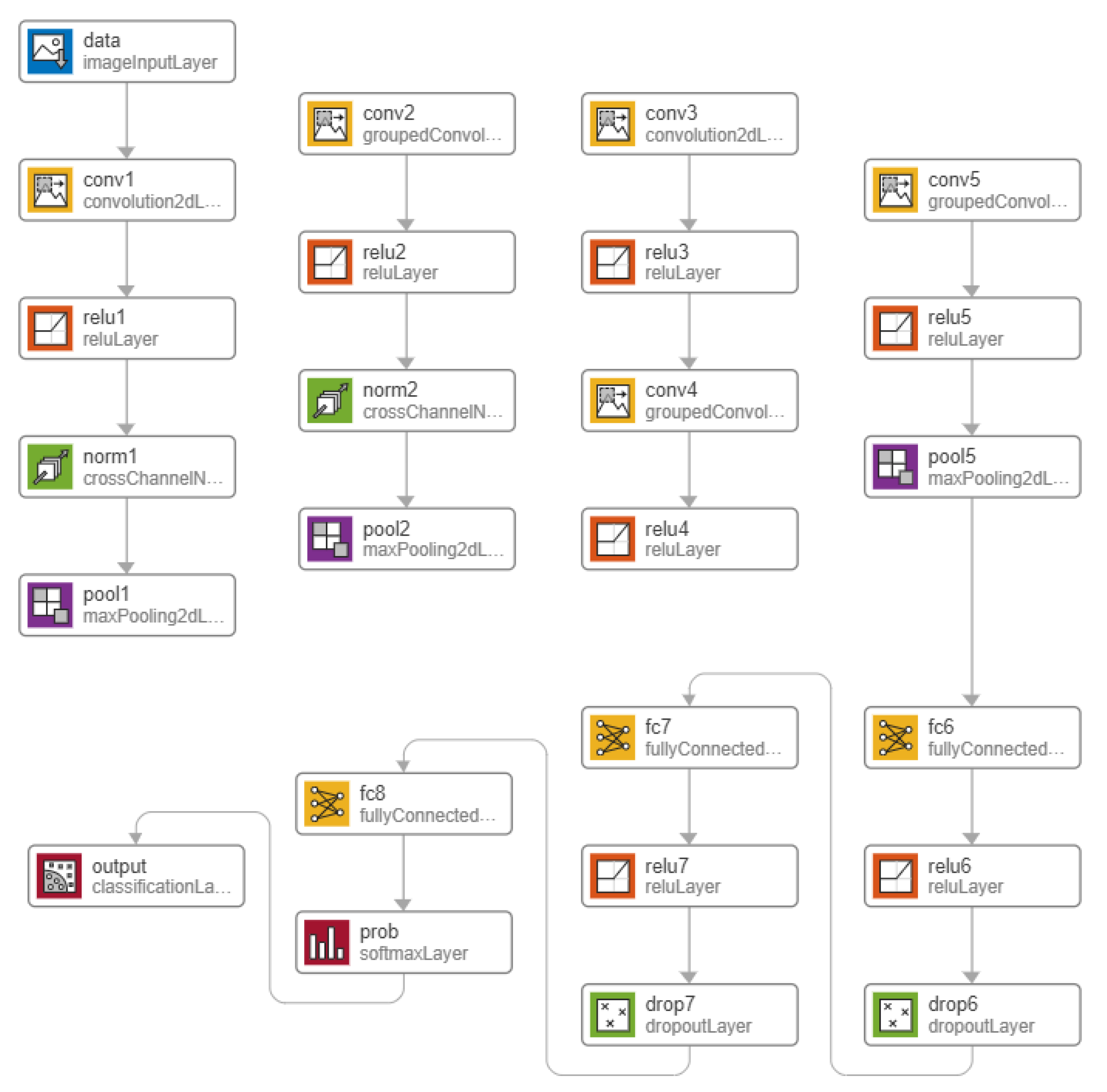
3.3. Modified AlexNet Network Model
Domestic multi-channel acoustic scenes consist of several signals that are captured with microphone arrays of different sizes and geometrical configurations. As discussed previously, CNNs have been widely popular for their advantage with regards to efficiency when used with data of spatial behaviour [
57]. Thus, the experimentation part of this work compares different pre-trained network models for transfer learning. Modifications on the hyper-parameters are then made on the best performing network, the response being observed in three ways:
Effects of changing the network activation function.
Effects of fine-tuning the weight and bias factors, and parameter variation.
Effects of modifications in the network architecture.
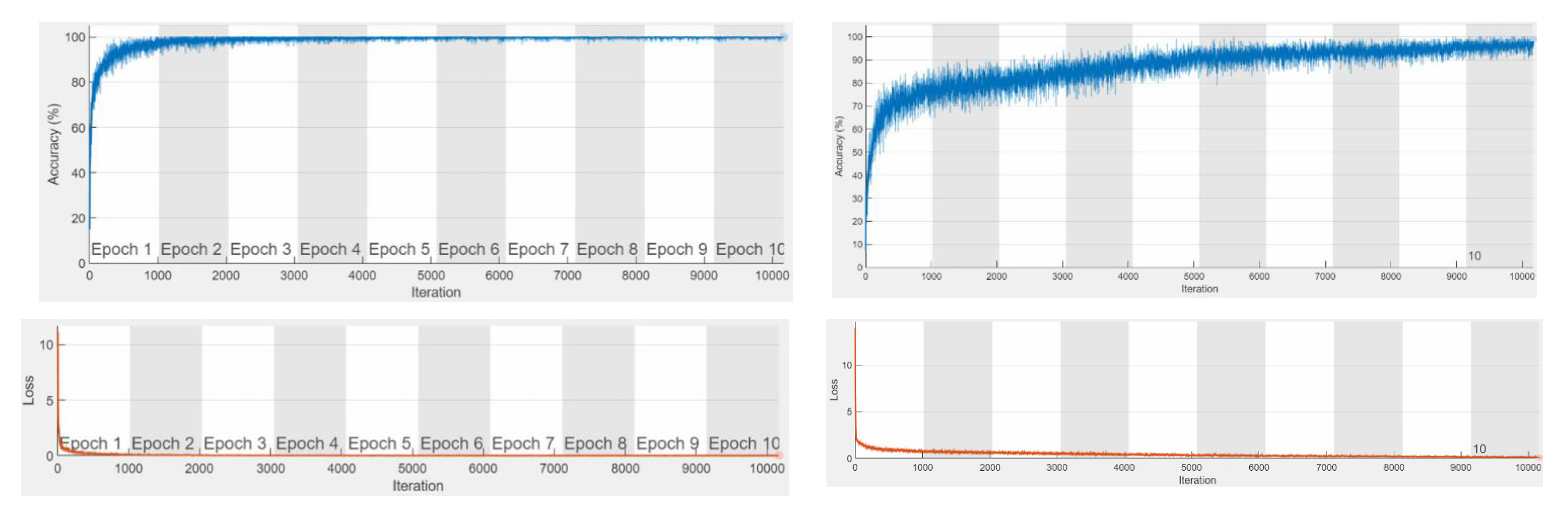
Activation functions in neural networks are a very important aspect of deep learning. These functions heavily influence the performance and computational complexity of the deep learning model [
58]. Further, such functions also affect the network in terms of its convergence speed and ability to perform the task. Aside from exploring different activation functions, we also look at fine-tuning the weights and bias factors of the convolutional layers, as well as investigating the effects of the presence of convolutional layers based on performance.
For the modified AlexNet model, we examine the traditional Rectified Linear Unit (ReLU) activation function, along with three of its variations. The ReLU offers advantages in solving the vanishing gradient problem [
59], which is common with the traditional sigmoid and tanh activation functions. The gradients of neural networks are computed through backpropagation, which calculates the derivatives of the network through every layer. Hence, for activation functions such as the sigmoid, the multiplication of several small derivatives causes a very small gradient value. This, in turn, negatively affects the update of weights and biases across training sessions [
59]. Provided that the ReLU function has a fixed gradient of either 1 or 0, aside from providing a solution to the vanishing gradient problem and overfitting, it also results in lower computational complexity, and therefore significantly faster training. Another benefit of ReLUs is the sparse representation, which is caused by the 0 gradient for negative values [
60]. Over time, it has been proven that sparse representations are more beneficial compared to dense representations [
61].
Nonetheless, despite the numerous advantages of the ReLU activation function, there are still a number of disadvantages. Because the ReLU function only considers positive components, the resulting gradient has a possibility to go towards 0. This is because the weights do not get adjusted during descent for the activations within that area. This means that the neurons that will go into that state would stop responding to any variations in the input or the error, causing several neurons to die, which makes a substantial part of the network passive. This phenomena is called the dying ReLU problem [
62]. Another disadvantage of the ReLU activation function is that values may range from zero to infinity. This implies that the activation may continuously increase to a very large value, which is not an ideal condition for the network [
63]. The following activations attempt to mitigate the disadvantages faced by the traditional ReLU function through modifications and will be explored in this work:
Leaky ReLU: The leaky ReLU is a variation of the traditional ReLU function that attempts to fix the dying ReLU problem by adding an alpha parameter, which creates a small negative slope when x is less than zero [
64].
Clipped ReLU: The clipped ReLU activation function attempts to prevent the activation from continuously increasing to a large value. This is achieved cutting the gradient at a pre-defined ceiling value [
63].
eLU: The exponential linear unit (eLU) is a similar activation function to ReLU. However, instead of sharply decreasing to zero for negative inputs, eLU smoothly decreases until the output is equivalent to the specified alpha value [
65].
Aside from activation functions, variations in the convolutional and fully connected layers will also be examined. The study will be done in terms of both the number of parameters and the number of existing layers within the network.
For parameter modification, we explore the reduction of output variables in the fully connected layers. This method immensely reduces the overall network size [
66]. However, it is important to note that recent works solely reduce the number of parameters from the first two fully connected layers. Hence, here we introduce the concept of uniform scaling, which is achieved by dividing the output parameters of fully connected layers by a common integer, based on the subsequent values.
Modification of the network architecture is also considered through examining the model’s performance when the number of layers within the network is varied. These layers may include convolutional, fully-connected, and activation function layers. Nonetheless, throughout the layer variation process, the model architecture is maintained to be of a series network type. A series network contains layers that are arranged subsequent to one another, containing a single input, and output layer. Directed Acyclic Graph (DAG) networks, on the other hand, have a complex architecture, from which layers may have inputs from several layers, and the outputs of which may be used for multiple layers [
67]. The higher number of hidden neurons and weights, which is apparent on DAG networks, could increase risks of overfitting. Hence, maintaining a series architecture allows for a more customizable and robust network. Further, as per the state-of-the-art, all other compact networks that currently exist present a DAG architecture. Thus, the development of a compact network with a more customizable format, and through using fewer layers, proposes advantages in designing sturdy custom networks.
3.4. Performance Evaluation Metrics
To evaluate the performance of the proposed systems, the following aspects are investigated:
Per class and overall comparison of different cepstral, temporal, and spectro-temporal features classified using various pre-trained neural network and machine learning models.
Effects of balancing the dataset
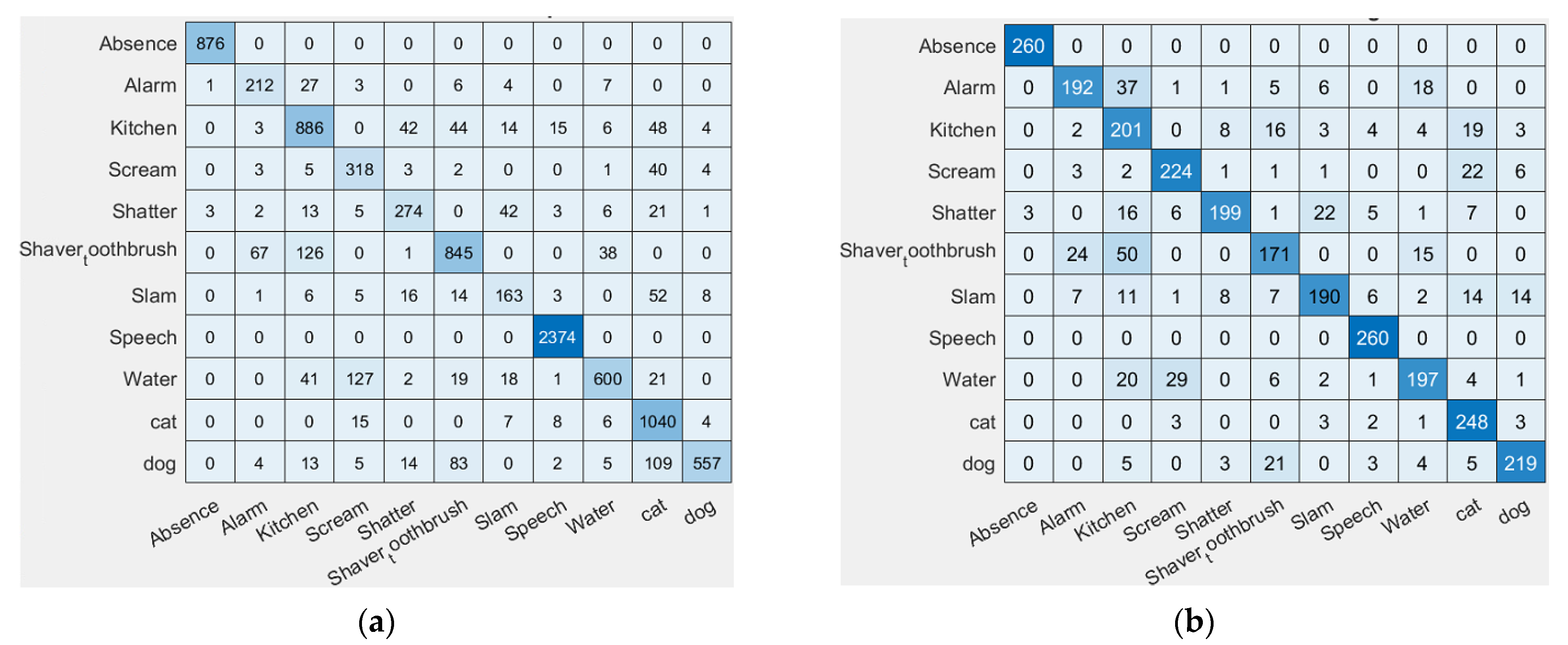
Aside from the standard accuracy, evaluations of the performances of different techniques were also compared and measured in terms of their F1-scores. This is defined to be a measure that takes into consideration both the recall and the precision, which are derived from the ratios of True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN) [
68], which can be extracted from confusion matrices.
The databases used for this research compose of unequal numbers of audio files per category. To account for the data imbalance, two different techniques are used:
Particularly used for the initial development and experiments conducted for this work, in this technique, the dataset was equalized across all levels in order to preserve a balanced dataset. This is done in order to avoid biasing in favour of specific categories with more samples. It is achieved by reducing the amount of data per level to match the minimum amount of data amongst the categories. Selection of the data was done randomly throughout the experiments.
- 2.
Using Weight-sensitive Performance Metrics
Provided that the F1-score serves as the main performance metric used for the experiments conducted, it is crucial to ensure that these metrics are robust and unbiased, especially for multi-classification purposes. When taking the average F1-score for an unbalanced dataset, the amount of data per level may affect and skew the results for the mean F1-score in favour of the classes with the most amount of data. Therefore, we consider three different ways of calculating the mean F1-score, including the Weighted, Micro, and Macro F1-scores, in order to take into account for the dataset imbalance [
69].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}