
A Proposal and Analysis of New Realistic Sets of Benchmark Instances for Vehicle Routing Problems with Asymmetric Costs


Abstract
:1. Introduction
2. Literature Review
2.1. VRP with Asymmetric Costs
2.2. VRP and Map APIs
3. New Sets of Benchmark Instances for the ACVRP
3.1. Existing Benchmark Instances
3.2. New Benchmark Instances
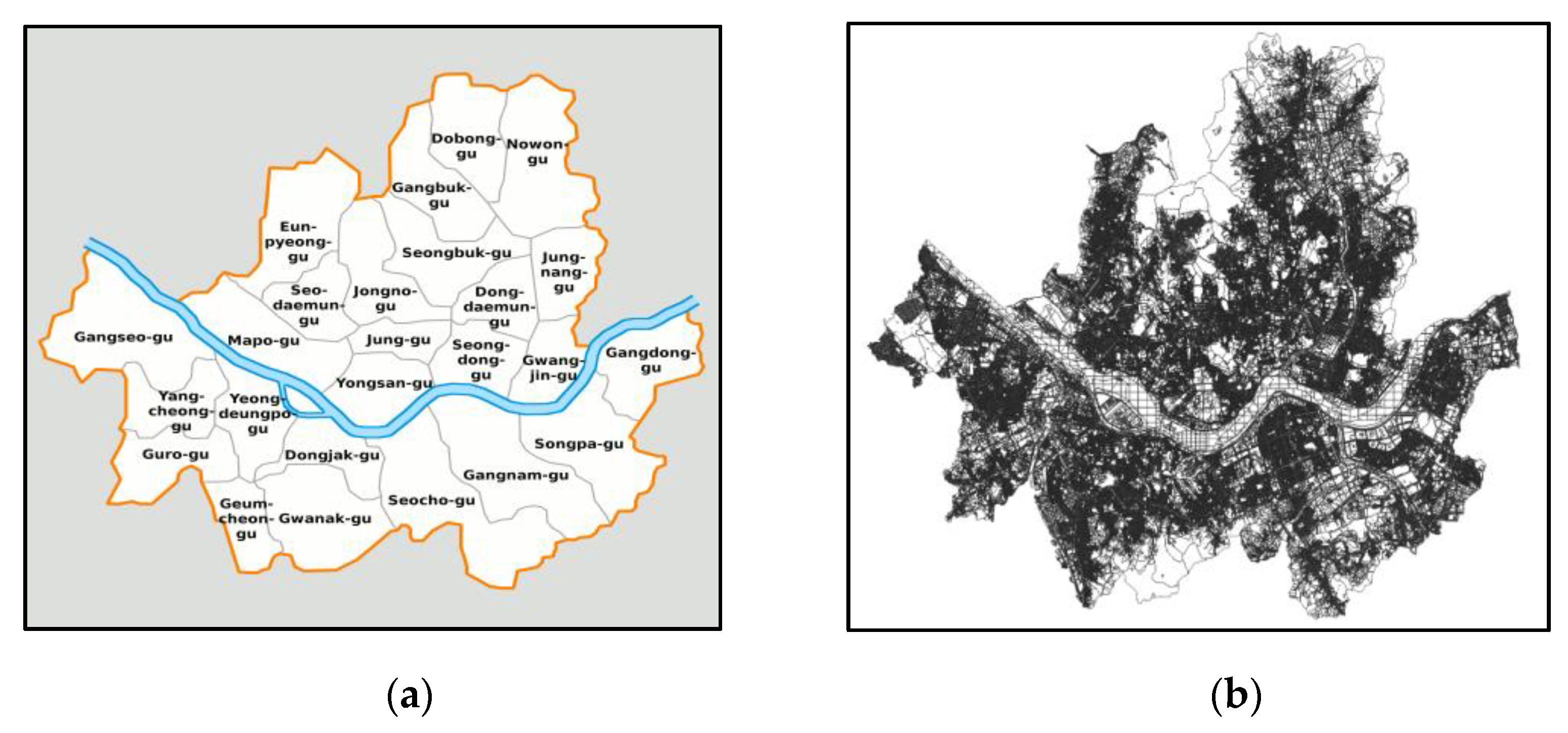
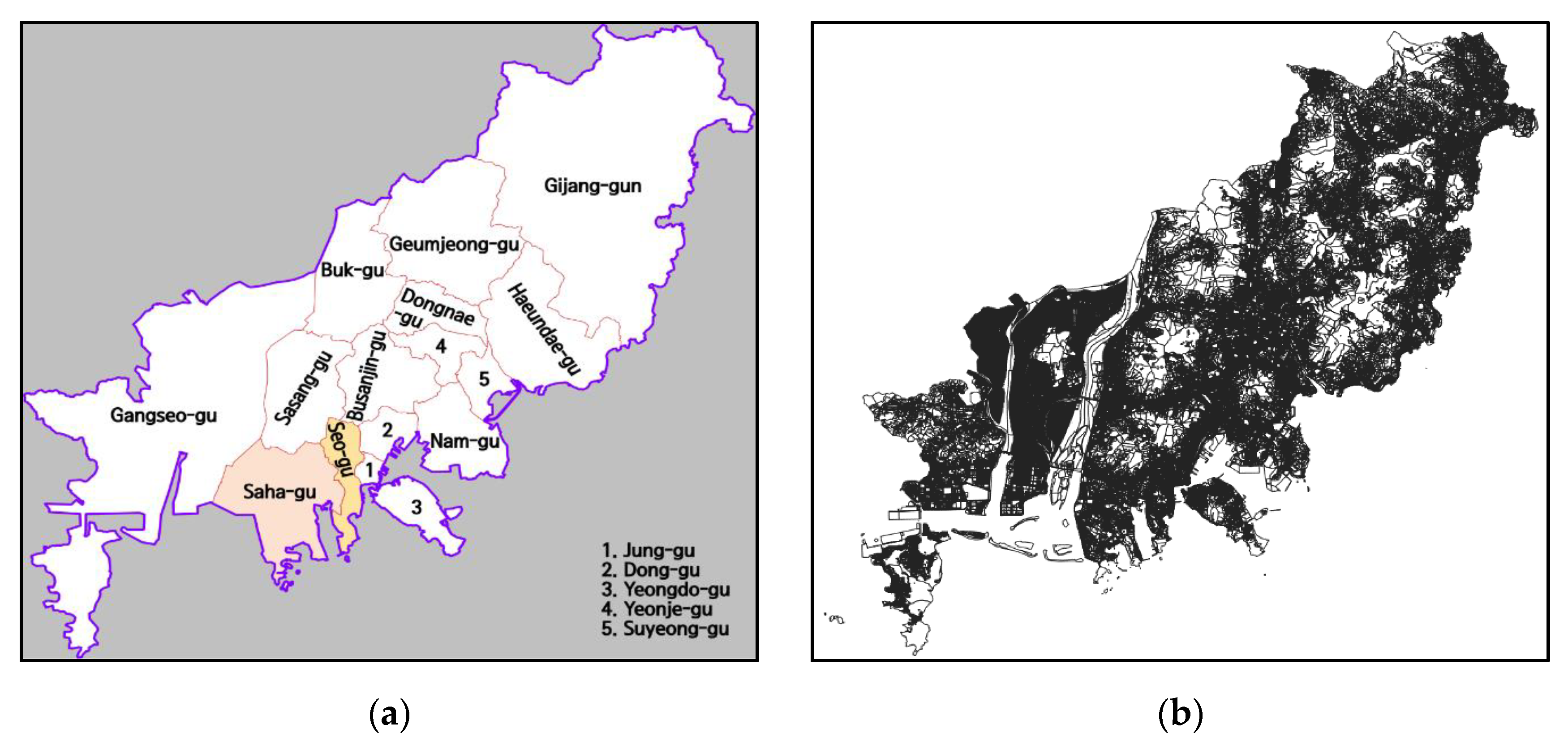
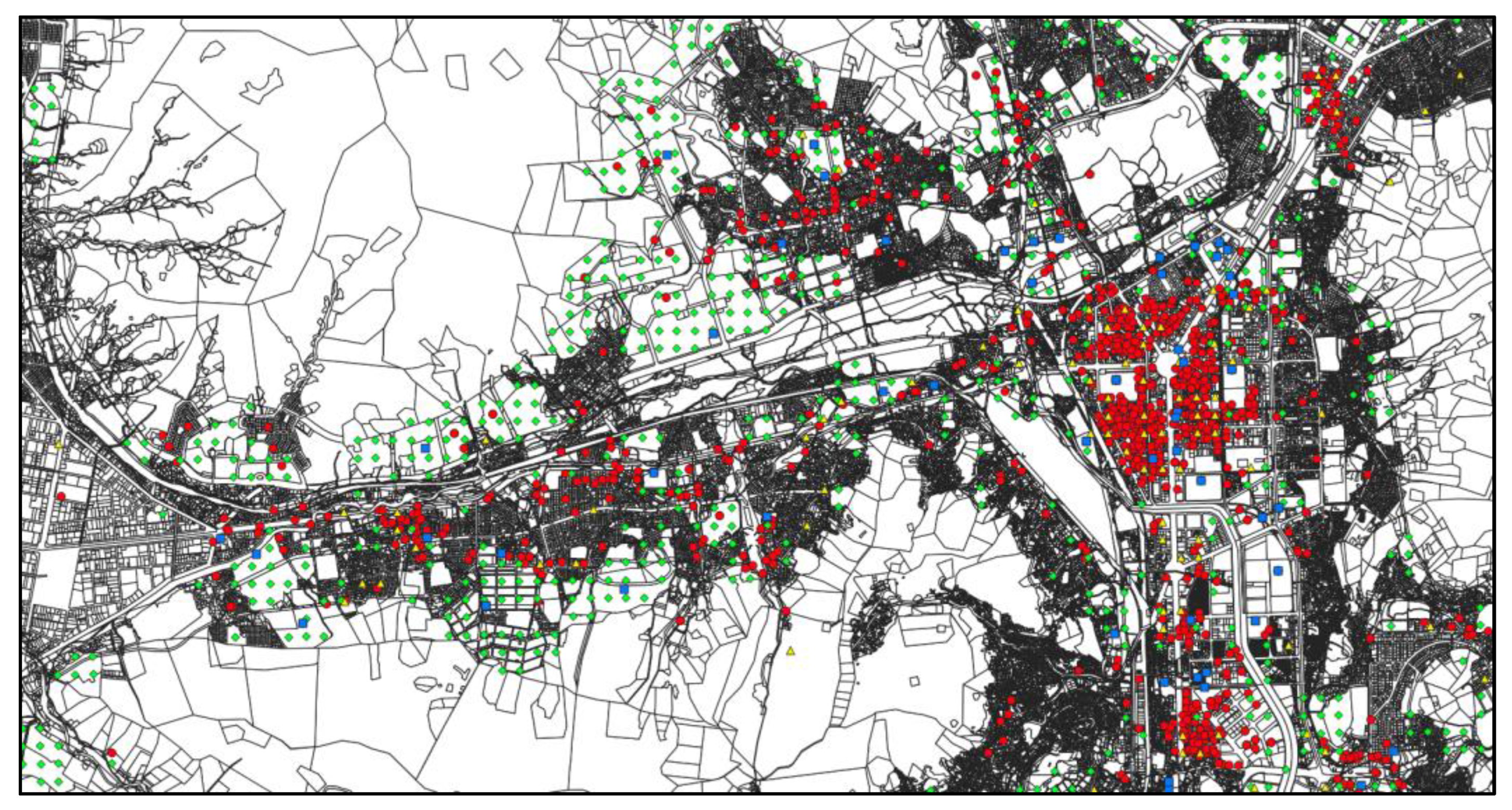
3.2.1. Territory
3.2.2. Depot Locations
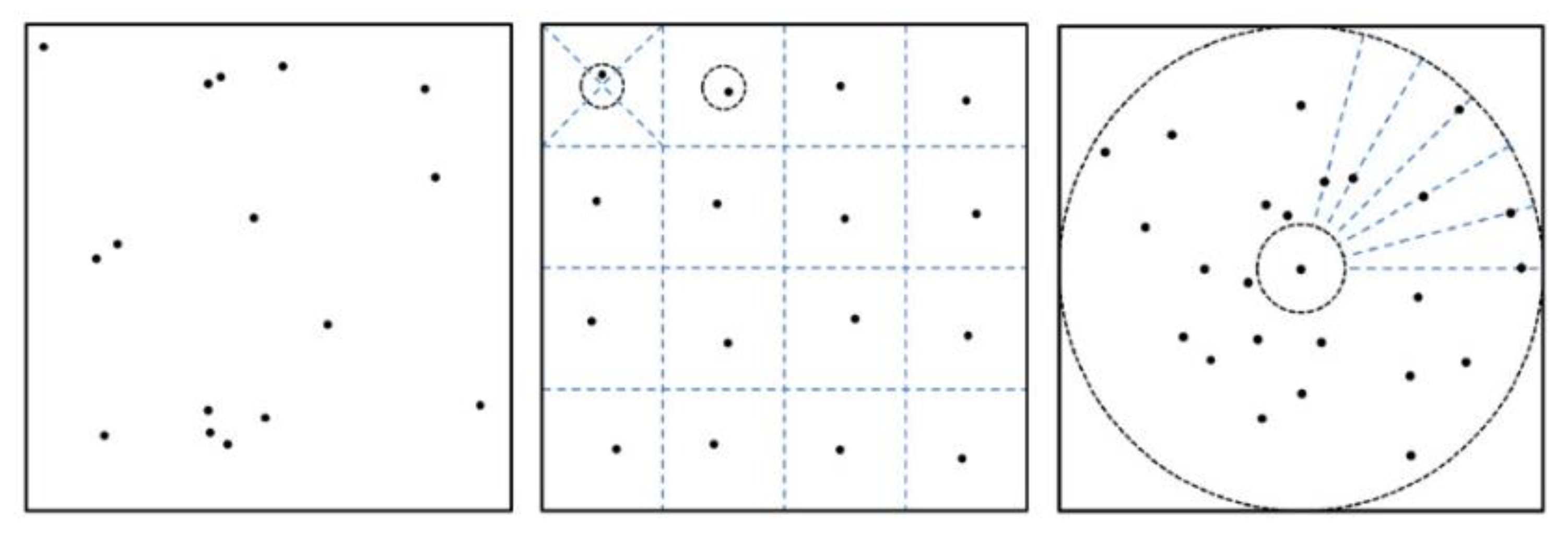
3.2.3. Customer Locations
3.2.4. Vehicle Capacities
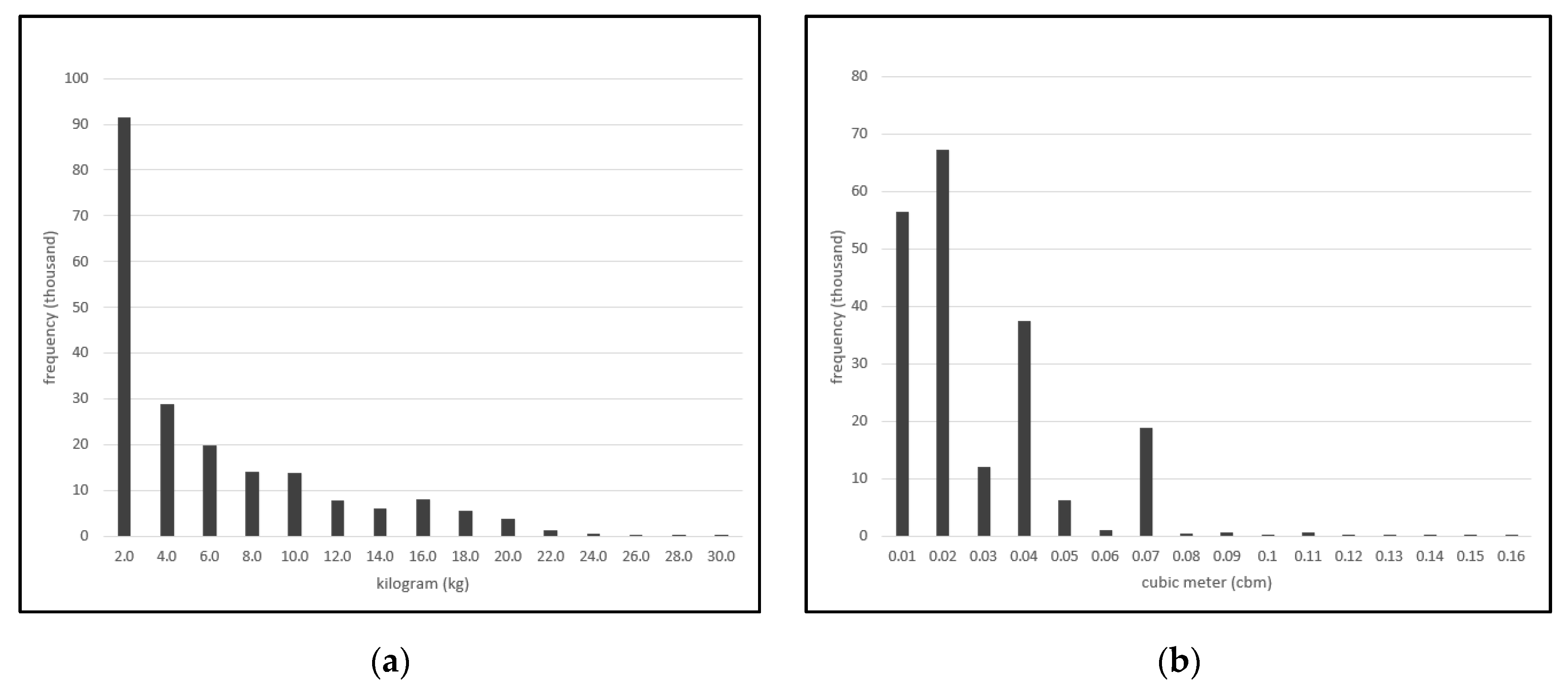
3.2.5. Weight and Volume Per Delivery
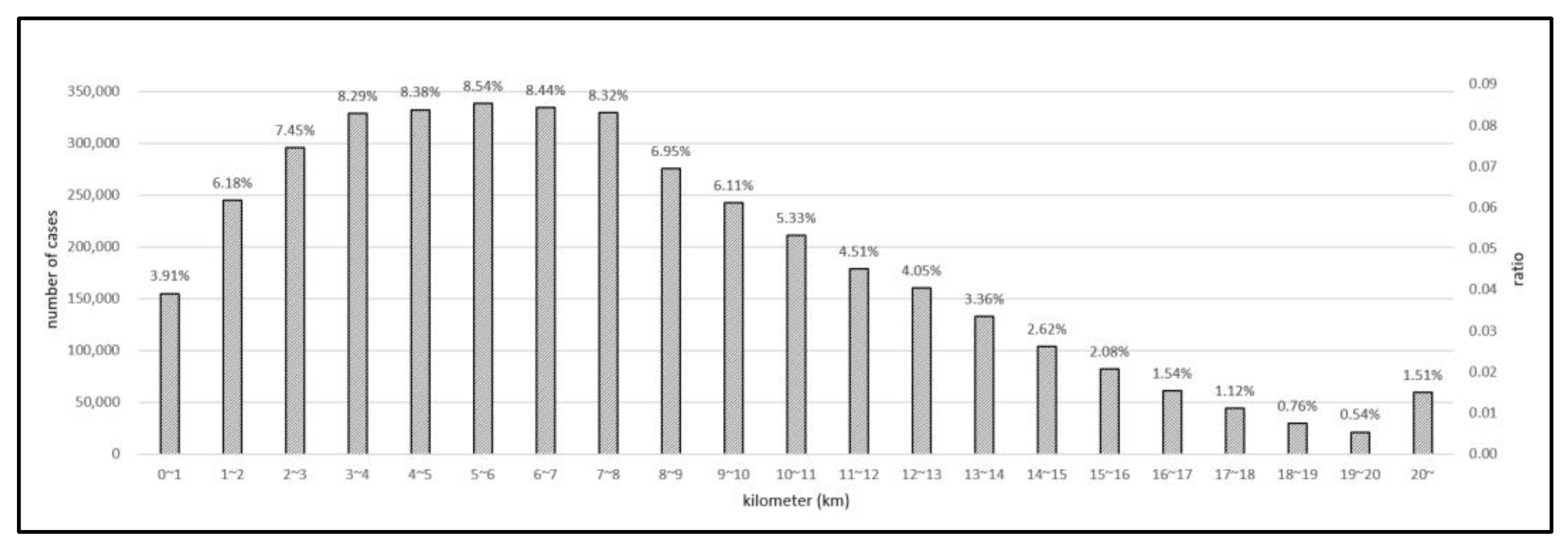
3.2.6. Dimension and Distance from Depot
3.2.7. Cost Matrix
3.2.8. Solution Methods and Results
4. Analysis on Air Distance, Road Distance and Road Time
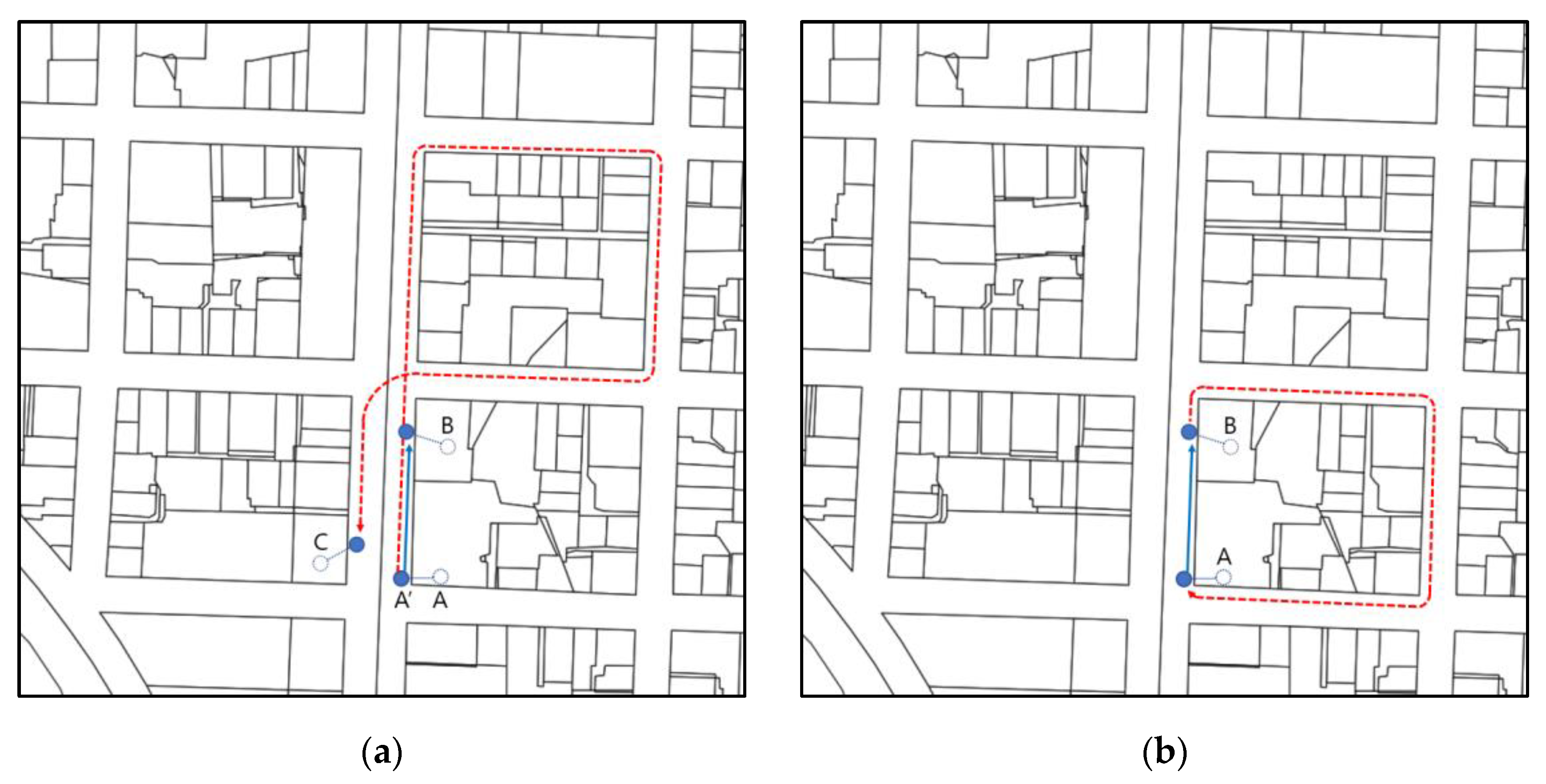
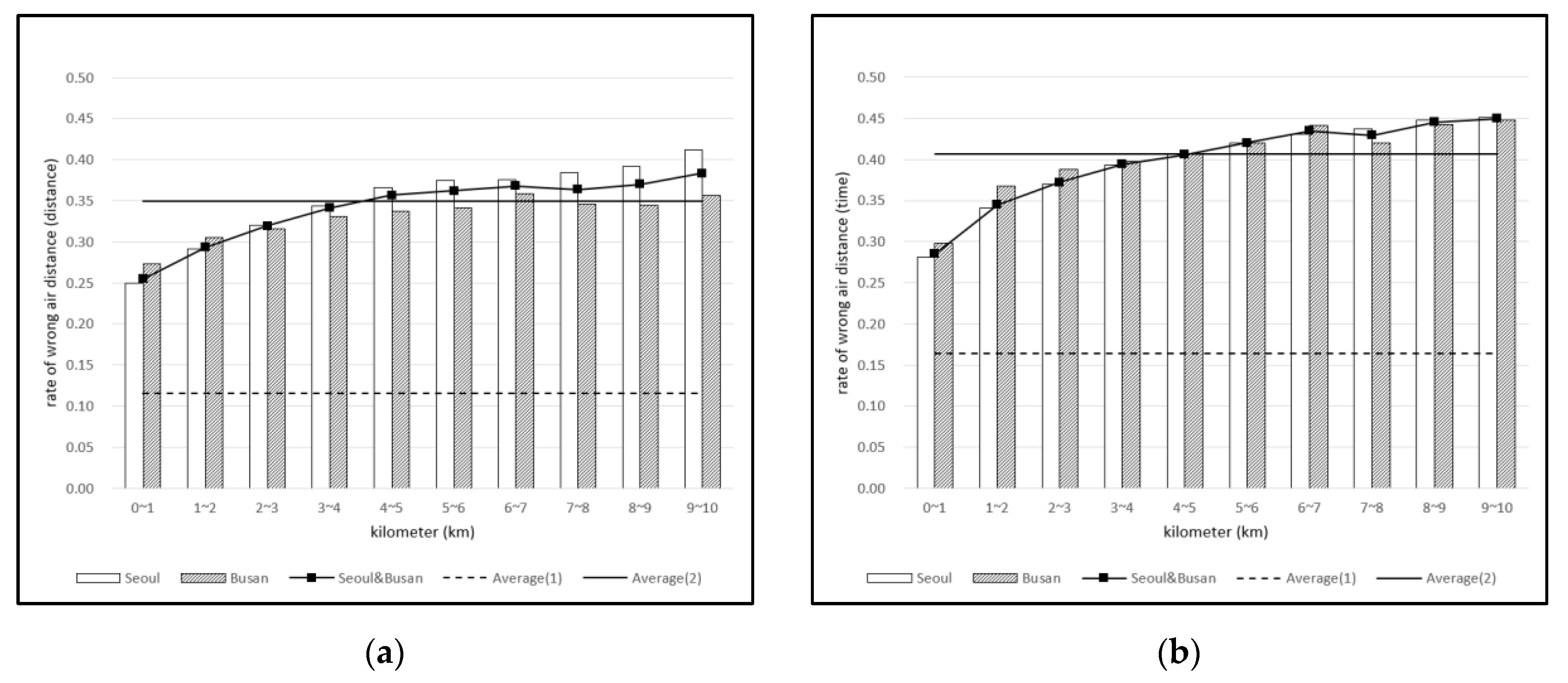
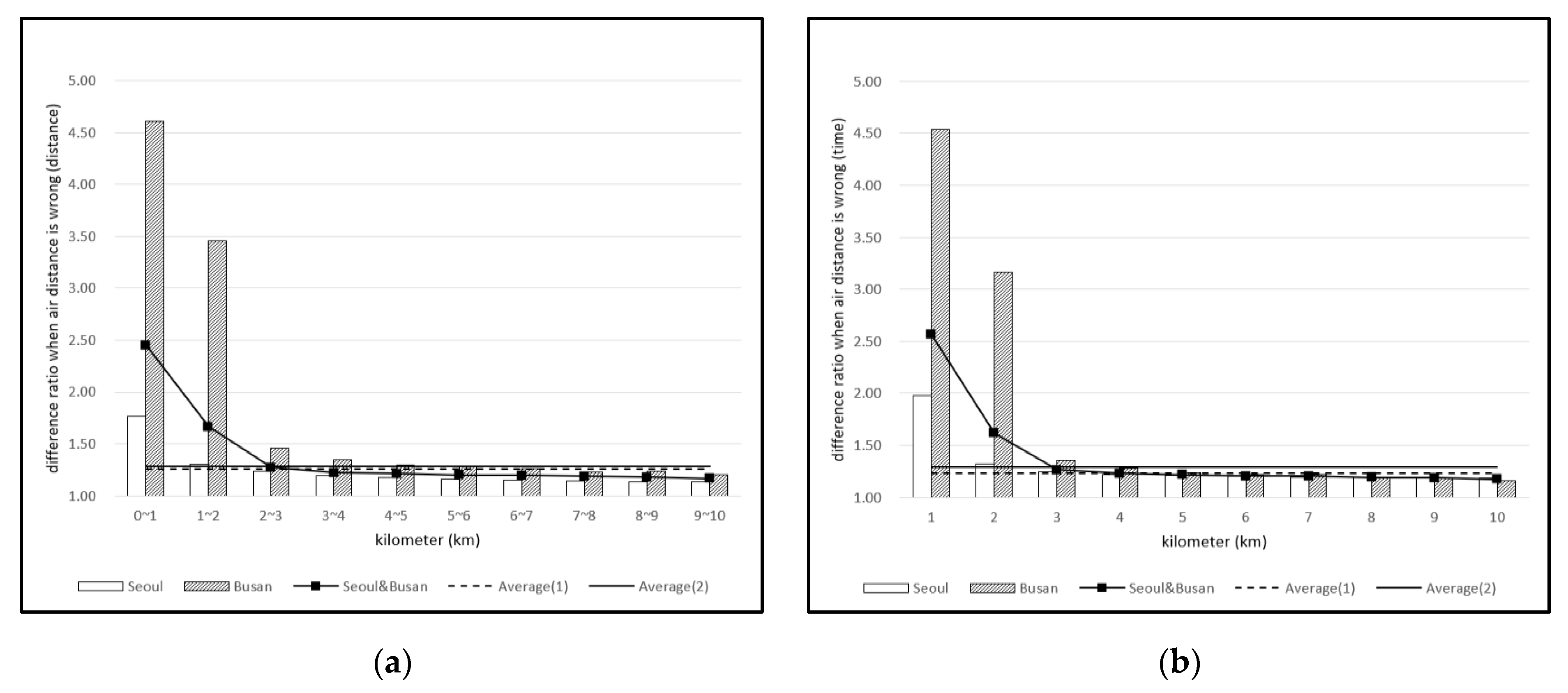
4.1. Closeness Deceived by Air Distance
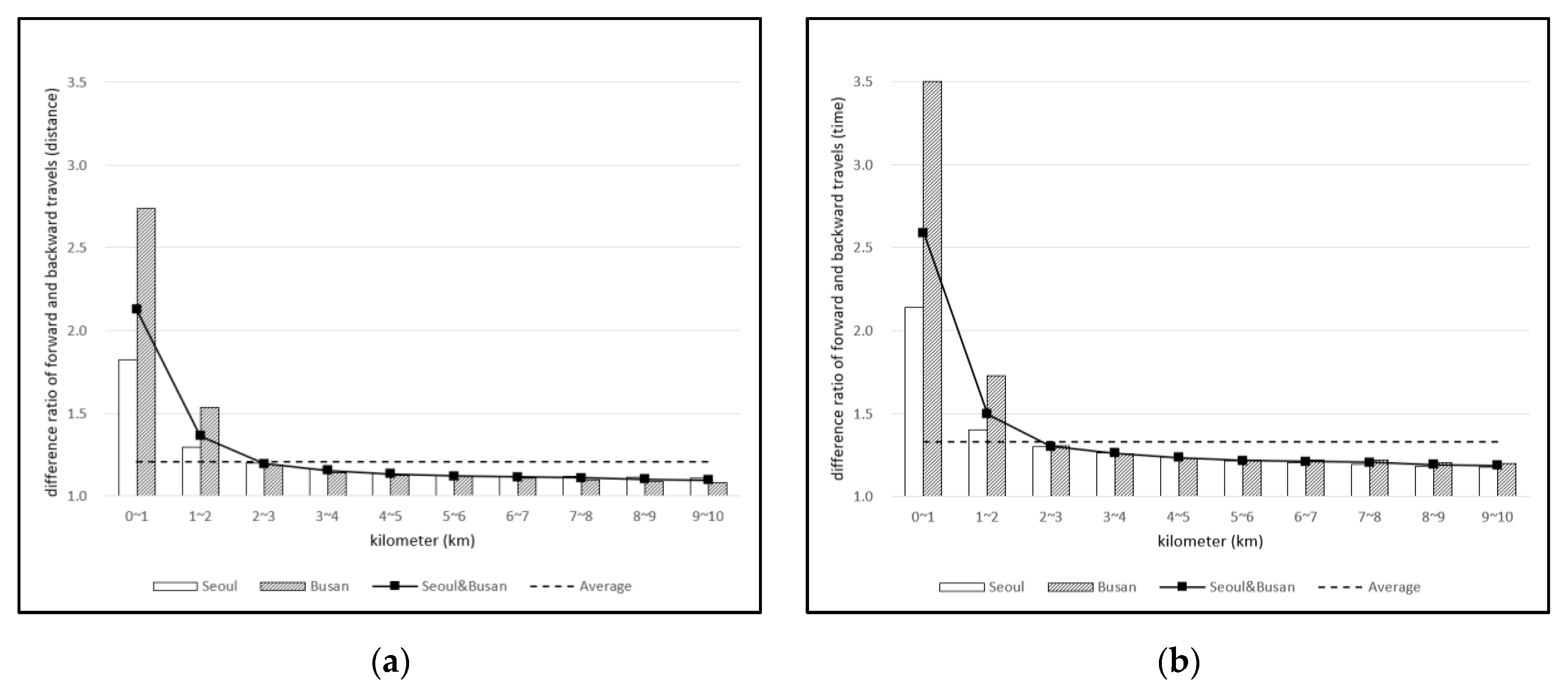
4.2. Assymetric Costs
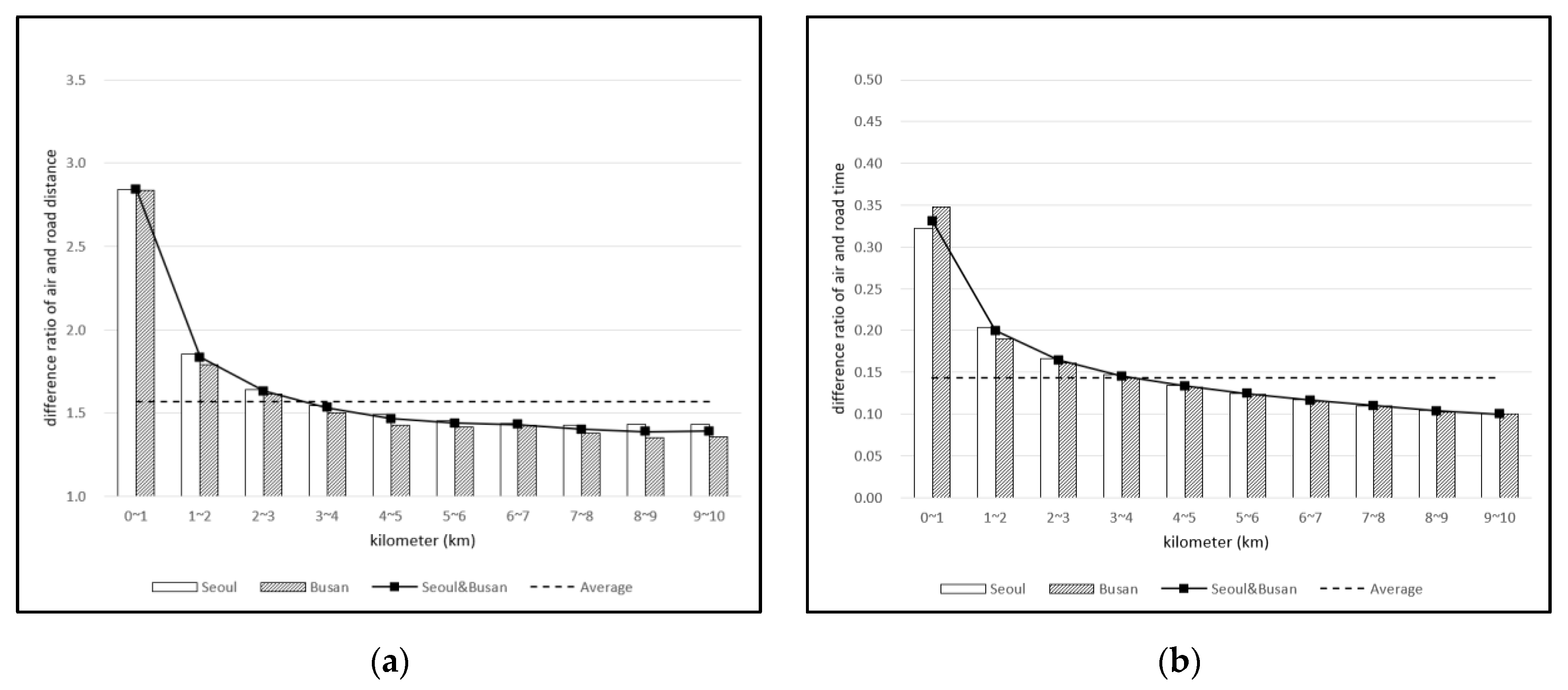
4.3. Air Distance to Road Distance and Road Time Multiplier
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eksioglu, B.; Vural, A.V.; Reisman, A. The vehicle routing problem: A taxonomic review. Comput. Ind. Eng. 2009, 57, 1472–1483. [Google Scholar] [CrossRef]
- Braekers, K.; Ramaekers, K.; Van Nieuwenhuyse, I. The vehicle routing problem: State of the art classification and review. Comput. Ind. Eng. 2016, 99, 300–313. [Google Scholar] [CrossRef]
- Smet, G. De OptaPlanner—Vehicle Routing with Real Road Distances. Available online: https://www.optaplanner.org/blog/2014/09/02/VehicleRoutingWithRealRoadDistances.html (accessed on 28 December 2020).
- Rodríguez, A.; Ruiz, R. A study on the effect of the asymmetry on real capacitated vehicle routing problems. Comput. Oper. Res. 2012, 39, 2142–2151. [Google Scholar] [CrossRef] [Green Version]
- Cho, H.J.; Park, C. The leadership competition of smart platforms in the ICT ecosystem: Comparative analysis of samsung electronics and SK telecom in the appcessory market. Asia Pac. J. Bus. Ventur. Entrep. 2015, 10, 187–202. [Google Scholar]
- Lee, H.; Park, H.C.; Kho, S.Y.; Kim, D.K. Assessing transit competitiveness in Seoul considering actual transit travel times based on smart card data. J. Transp. Geogr. 2019, 80, 102546. [Google Scholar] [CrossRef]
- Caceres-Cruz, J.; Arias, P.; Guimarans, D.; Riera, D.; Juan, A.A. Rich vehicle routing problem: Survey. ACM Comput. Surv. 2014, 47. [Google Scholar] [CrossRef]
- Rodríguez, A.; Ruiz, R. The effect of the asymmetry of road transportation networks on the traveling salesman problem. Comput. Oper. Res. 2012, 39, 1566–1576. [Google Scholar] [CrossRef] [Green Version]
- Cáceres-Cruz, J.; Riera, D.; Buil, R.; Juan, A.A.; Herrero, R. Multi-start approach for solving an asymmetric heterogeneous vehicle routing problem in a real urban context. In Proceedings of the 2nd International Conference on Operations Research and Enterprise Systems (ICORES-2013), Barcelona, Spain, 16–18 February 2013; pp. 168–174. [Google Scholar] [CrossRef]
- Herrero, R.; Rodríguez, A.; Cáceres-Cruz, J.; Juan, A.A. Solving vehicle routing problems with asymmetric costs and heterogeneous fleets. Int. J. Adv. Oper. Manag. 2015, 6, 58–80. [Google Scholar] [CrossRef] [Green Version]
- Laporte, G.; Mercure, H.; Nobert, Y. An exact algorithm for the asymmetrical capacitated vehicle routing problem. Networks 1986, 16, 33–46. [Google Scholar] [CrossRef]
- Laporte, G.; Nobert, Y.; Taillefer, S. A branch-and-bound algorithm for the asymmetrical distance-constrained vehicle routing problem. Math. Model. 1987, 9, 857–868. [Google Scholar] [CrossRef] [Green Version]
- Toth, P.; Vigo, D. A heuristic algorithm for the symmetric and asymmetric vehicle routing problems with backhauls. Eur. J. Oper. Res. 1999, 113, 528–543. [Google Scholar] [CrossRef]
- Osaba, E.; Yang, X.S.; Diaz, F.; Onieva, E.; Masegosa, A.D.; Perallos, A. A discrete firefly algorithm to solve a rich vehicle routing problem modelling a newspaper distribution system with recycling policy. Soft Comput. 2017, 21, 5295–5308. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Chae, J.; Song, B.; Choi, D. A model for sustainable courier services: Vehicle routing with exclusive lanes. Sustainability 2020, 12, 1077. [Google Scholar] [CrossRef] [Green Version]
- Calvet, L.; Pagès-Bernaus, A.; Travesset-Baro, O.; Juan, A.A. A simheuristic for the heterogeneous site-dependent asymmetric VRP with stochastic demands. In Lecture Notes Computer Science; Spring: Cham, Switzerland, 2016; Volume 9868, pp. 408–417. [Google Scholar] [CrossRef]
- Ilin, V.; Matijević, L.; Davidović, T.; Pardalos, P. Asymmetric Capacitated Vehicle Routing Problem with Time Window. In Proceedings of the XLV Symposium on Operational Research (SYM-OP-IS 2018), Zlatibor, Serbia, 16–18 September 2018; pp. 174–179. Available online: http://researchrepository.mi.sanu.ac.rs/handle/123456789/3174 (accessed on 22 May 2021).
- Fischetti, M.; Toth, P.; Vigo, D. A branch-and-bound algorithm for the capacitated vehicle routing problem on directed graphs. Oper. Res. 1994, 42, 846–859. [Google Scholar] [CrossRef]
- Pessoa, A.; de Aragao, M.P.; Uchoa, E. Robust Branch-Cut-and-Price Algorithms for Vehicle Routing Problems; Springer: Boston, MA, USA, 2008; Volume 43, ISBN 9780387777788. [Google Scholar]
- Rodríguez, A.; Ruiz, R. ACVRP_Depot Problem Instances. Available online: http://soa.iti.es/problem-instances (accessed on 28 December 2020).
- Distance Matrix API. Available online: https://developers.google.com/maps/documentation/distance-matrix/overview (accessed on 11 March 2021).
- Smet, G. De VRP-REP_the Vehicle Routing Problem Repository. Available online: http://www.vrp-rep.org/datasets/item/2017-0001.html (accessed on 6 January 2021).
- Routing—OpenStreetMap. Available online: https://wiki.openstreetmap.org/wiki/Routing (accessed on 24 March 2021).
- Li, R.; Cheng, C.; Qi, M.; Lai, W. Design of dynamic vehicle routing system based on online map service. In Proceedings of the 2016 13th International Conference on Service Systems and Service Management (ICSSSM), Kunming, China, 24–26 June 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Hashi, E.K.; Hasan, M.R.; Zaman, M.S.U. GIS based heuristic solution of the vehicle routing problem to optimize the school bus routing and scheduling. In Proceedings of the 2016 19th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2016; pp. 56–60. [Google Scholar] [CrossRef]
- Welch, P. Developing a commercial dynamic vehicle routing system—a case study. Open Door Logist. 2017. [Google Scholar] [CrossRef]
- Baidu Map Data Open Platform. Available online: http://lbsyun.baidu.com (accessed on 24 March 2021).
- Li, Y.; Lim, M.K.; Tseng, M.L. A green vehicle routing model based on modified particle swarm optimization for cold chain logistics. Ind. Manag. Data Syst. 2019, 119, 473–494. [Google Scholar] [CrossRef]
- Wang, Y.; Assogba, K.; Fan, J.; Xu, M.; Liu, Y.; Wang, H. Multi-Depot green vehicle routing problem with shared transportation resource: Integration of time-dependent speed and piecewise penalty cost. J. Clean. Prod. 2019, 232, 12–29. [Google Scholar] [CrossRef]
- Qi, C.; Hu, L. Optimization of vehicle routing problem for emergency cold chain logistics based on minimum loss. Phys. Commun. 2020, 40, 101085. [Google Scholar] [CrossRef]
- Lee, K.; Chae, J.; Kim, J. A courier service with electric bicycles in an Urban Area: The case in Seoul. Sustainability 2019, 11, 1255. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Chae, J.; Cha, H.; Song, J. Mendeley Data—New Realistic Sets of Benchmark Instances for Vehicle Routing Problem with Asymmetric Costs. Available online: http://dx.doi.org/10.17632/5db8mtw4wg.2 (accessed on 22 May 2021).
- Seoul Districts. Available online: https://en.wikipedia.org/wiki/File:Map_Seoul_districts_de.png (accessed on 28 March 2021).
- Busan Districts. Available online: https://en.wikipedia.org/wiki/Busan (accessed on 28 March 2021).
- Average Load Factor by Freight Vehicle Capacity. Available online: https://kosis.kr/statHtml/statHtml.do?orgId=116&tblId=DT_MLTM_5414&conn_path=I2 (accessed on 30 March 2021).
- Diana, M.; Pirra, M.; Woodcock, A. Freight distribution in urban areas: A method to select the most important loading and unloading areas and a survey tool to investigate related demand patterns. Eur. Transp. Res. Rev. 2020, 12. [Google Scholar] [CrossRef]
- Gillett, B.E.; Miller, L.R. A Heuristic Algorithm for the Vehicle-Dispatch Problem. Oper. Res. 1974, 22, 340–349. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| To | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Distance between Coordinates | Map API Used | ||||||||||||||||||
| (a) Air Distance (Meters) | (b) Road Distance (Meters) | (c) Road Time (Seconds) | |||||||||||||||||
| A | B | C | D | E | F | A | B | C | D | E | F | A | B | C | D | E | F | ||
| From | A | 0 | 2348 | 2494 | 1261 | 3,72 | 2206 | 0 | 3109 | 5904 | 2528 | 680 | 6331 | 0 | 619 | 1311 | 396 | 228 | 1364 |
| B | 2348 | 0 | 4467 | 1861 | 2004 | 4151 | 3151 | 0 | 8478 | 4348 | 2429 | 8905 | 560 | 0 | 1755 | 679 | 397 | 1808 | |
| C | 2494 | 4467 | 0 | 3749 | 2665 | 317 | 4247 | 6836 | 0 | 5904 | 4407 | 427 | 619 | 1101 | 0 | 881 | 709 | 53 | |
| D | 1261 | 1861 | 3749 | 0 | 1207 | 3466 | 2223 | 4221 | 6928 | 0 | 1792 | 7354 | 648 | 917 | 1543 | 0 | 520 | 1596 | |
| E | 372 | 2004 | 2665 | 1207 | 0 | 2362 | 722 | 2429 | 6049 | 1919 | 0 | 6476 | 152 | 430 | 1351 | 265 | 0 | 1404 | |
| F | 2206 | 4151 | 317 | 3466 | 2362 | 0 | 4674 | 7263 | 427 | 6331 | 4834 | 0 | 692 | 1177 | 74 | 942 | 782 | 0 | |
| City | Depot | Customer Location | Range within | Dimension | Name | Avg Time (DV1M5, Sec) * | BKS (DV1M5) ** |
|---|---|---|---|---|---|---|---|
| Seoul (S) | UDC (L) | Residential Complex (A) | 2.5 km (S) | 100 | SLAS100 | 10 | 76,358 |
| 5 km (M) | 250 | SLAM250 | 58 | 182,120 | |||
| 10 km (L) | 500 | SLAL500 | 149 | 594,420 | |||
| Restaurant Business (F) | 2.5 km (S) | 100 | SLFS100 | 11 | 39,488 | ||
| 5 km (M) | 250 | SLFM250 | 66 | 135,313 | |||
| 10 km (L) | 500 | SLFL500 | 149 | 425,651 | |||
| Convenience Store (C) | 2.5 km (S) | 50 | SLCS50 | 6 | 47,043 | ||
| 5 km (M) | 75 | SLCM75 | 7 | 75,004 | |||
| 10 km (L) | 100 | SLCL100 | 11 | 180,753 | |||
| Postal Hub (P) | Residential Complex (A) | 2.5 km (S) | 100 | SPAS100 | 11 | 115,582 | |
| 5 km (M) | 250 | SPAM250 | 57 | 251,667 | |||
| 10 km (L) | 500 | SPAL500 | 139 | 729,496 | |||
| Restaurant Business (F) | 2.5 km (S) | 100 | SPFS100 | 11 | 47,119 | ||
| 5 km (M) | 250 | SPFM250 | 62 | 168,662 | |||
| 10 km (L) | 500 | SPFL500 | 146 | 480,624 | |||
| Convenience Store (C) | 2.5 km (S) | 50 | SPCS50 | 6 | 71,011 | ||
| 5 km (M) | 75 | SPCM75 | 7 | 142,406 | |||
| 10 km (L) | 100 | SPCL100 | 11 | 245,746 | |||
| Large-sized Mall (S) | Residential Complex (A) | 2.5 km (S) | 100 | SSAS100 | 11 | 73,950 | |
| 5 km (M) | 250 | SSAM250 | 37 | 230,226 | |||
| 10 km (L) | 500 | SSAL500 | 135 | 561,442 | |||
| Restaurant Business (F) | 2.5 km (S) | 100 | SSFS100 | 11 | 62,644 | ||
| 5 km (M) | 250 | SSFM250 | 62 | 180,621 | |||
| 10 km (L) | 500 | SSFL500 | 143 | 492,579 | |||
| Convenience Store (C) | 2.5 km (S) | 50 | SSCS50 | 6 | 40,758 | ||
| 5 km (M) | 75 | SSCM75 | 7 | 109,477 | |||
| 10 km (L) | 100 | SSCL100 | 8 | 194,559 | |||
| Busan (B) | UDC(L) | Residential Complex (A) | 20 km (S) | 100 | BLAS100 | 11 | 197,486 |
| 30 km (M) | 250 | BLAM250 | 71 | 612,256 | |||
| 40 km (L) | 500 | BLAL500 | 172 | 1,142,420 | |||
| Restaurant Business (F) | 20 km (S) | 100 | BLFS100 | 10 | 199,864 | ||
| 30 km (M) | 250 | BLFM250 | 71 | 524,744 | |||
| 40 km (L) | 500 | BLFL500 | 178 | 938,741 | |||
| Convenience Store (C) | 20 km (S) | 50 | BLCS50 | 5 | 180,941 | ||
| 30 km (M) | 75 | BLCM75 | 9 | 269,538 | |||
| 40 km (L) | 100 | BLCL100 | 10 | 322,354 | |||
| Postal Hub (P) | Residential Complex (A) | 15 km (S) | 100 | BPAS100 | 11 | 190,075 | |
| 20 km (M) | 250 | BPAM250 | 44 | 467,338 | |||
| 25 km (L) | 500 | BPAL500 | 191 | 904,537 | |||
| Restaurant Business (F) | 15 km (S) | 100 | BPFS100 | 11 | 193,485 | ||
| 20 km (M) | 250 | BPFM250 | 70 | 430,466 | |||
| 25 km (L) | 500 | BPFL500 | 168 | 694,761 | |||
| Convenience Store (C) | 15 km (S) | 50 | BPCS50 | 5 | 158,240 | ||
| 20 km (M) | 75 | BPCM75 | 9 | 252,686 | |||
| 25 km (L) | 100 | BPCL100 | 11 | 289,195 | |||
| Large-sized Mall (S) | Residential Complex (A) | 5 km (S) | 100 | BSAS100 | 10 | 100,103 | |
| 10 km (M) | 250 | BSAM250 | 42 | 266,803 | |||
| 15 km (L) | 500 | BSAL500 | 161 | 609,610 | |||
| Restaurant Business (F) | 5 km (S) | 100 | BSFS100 | 11 | 86,652 | ||
| 10 km (M) | 250 | BSFM250 | 55 | 257,710 | |||
| 15 km (L) | 500 | BSFL500 | 142 | 471,597 | |||
| Convenience Store (C) | 5 km (S) | 50 | BSCS50 | 5 | 89,989 | ||
| 10 km (M) | 75 | BSCM75 | 9 | 136,604 | |||
| 15 km (L) | 100 | BSCL100 | 11 | 217,444 |
| Cost | Vehicle | Capacity | Multiple | Name |
|---|---|---|---|---|
| Distance (D) | 1-ton trucks (V1) | 5 cubic meters | 5 times (M5) | DV1M5 |
| 10 times (M10) | DV1M10 | |||
| 20 times (M20) | DV1M20 | |||
| 2.5-ton trucks (V2) | 12.5 cubic meters | 5 times (M5) | DV2M5 | |
| 10 times (M10) | DV2M10 | |||
| 20 times (M20) | DV2M20 | |||
| Time (T) | 1-ton trucks (V1) | 5 cubic meters | 5 times (M5) | TV1M5 |
| 10 times (M10) | TV1M10 | |||
| 20 times (M20) | TV1M20 | |||
| 2.5-ton trucks (V2) | 12.5 cubic meters | 5 times (M5) | TV2M5 | |
| 10 times (M10) | TV2M10 | |||
| 20 times (M20) | TV2M20 |
| Benchmark | Number | Dimensions | Depot and Customer Nodes | Road Distance | Road Time | Reported BKS *** |
|---|---|---|---|---|---|---|
| Fischetti | 32 * | 34~74 | Real data of pharmaceutical product delivery | O | X | O |
| De Smet | 10 ** | 50~2750 | Administrative districts | O | O | X |
| Rodríguez | 2700 | 50~500 | Random, grid, and radial | O | X | X |
| Proposed instances | 648 | 50~500 | Real data of UDCs, postal hubs, large malls, residential complexes, restaurants, and convenience stores | O | O | O |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Chae, J. A Proposal and Analysis of New Realistic Sets of Benchmark Instances for Vehicle Routing Problems with Asymmetric Costs. Appl. Sci. 2021, 11, 4790. https://doi.org/10.3390/app11114790
Lee K, Chae J. A Proposal and Analysis of New Realistic Sets of Benchmark Instances for Vehicle Routing Problems with Asymmetric Costs. Applied Sciences. 2021; 11(11):4790. https://doi.org/10.3390/app11114790
Chicago/Turabian StyleLee, Keyju, and Junjae Chae. 2021. "A Proposal and Analysis of New Realistic Sets of Benchmark Instances for Vehicle Routing Problems with Asymmetric Costs" Applied Sciences 11, no. 11: 4790. https://doi.org/10.3390/app11114790
APA StyleLee, K., & Chae, J. (2021). A Proposal and Analysis of New Realistic Sets of Benchmark Instances for Vehicle Routing Problems with Asymmetric Costs. Applied Sciences, 11(11), 4790. https://doi.org/10.3390/app11114790