
A Heterogeneous Learning Framework for Over-the-Top Consumer Analysis Reflecting the Actual Market Environment



Abstract
1. Introduction
1.1. Motivation and Objective
1.2. Contribution
2. Literature Review
2.1. OTT Services
2.2. Review of Classification Using ML
2.3. Problem Statement
2.3.1. Class-Imbalance Problem
2.3.2. Rapid Changes in the OTT Market
3. Research Design
3.1. Model Design: An Overview
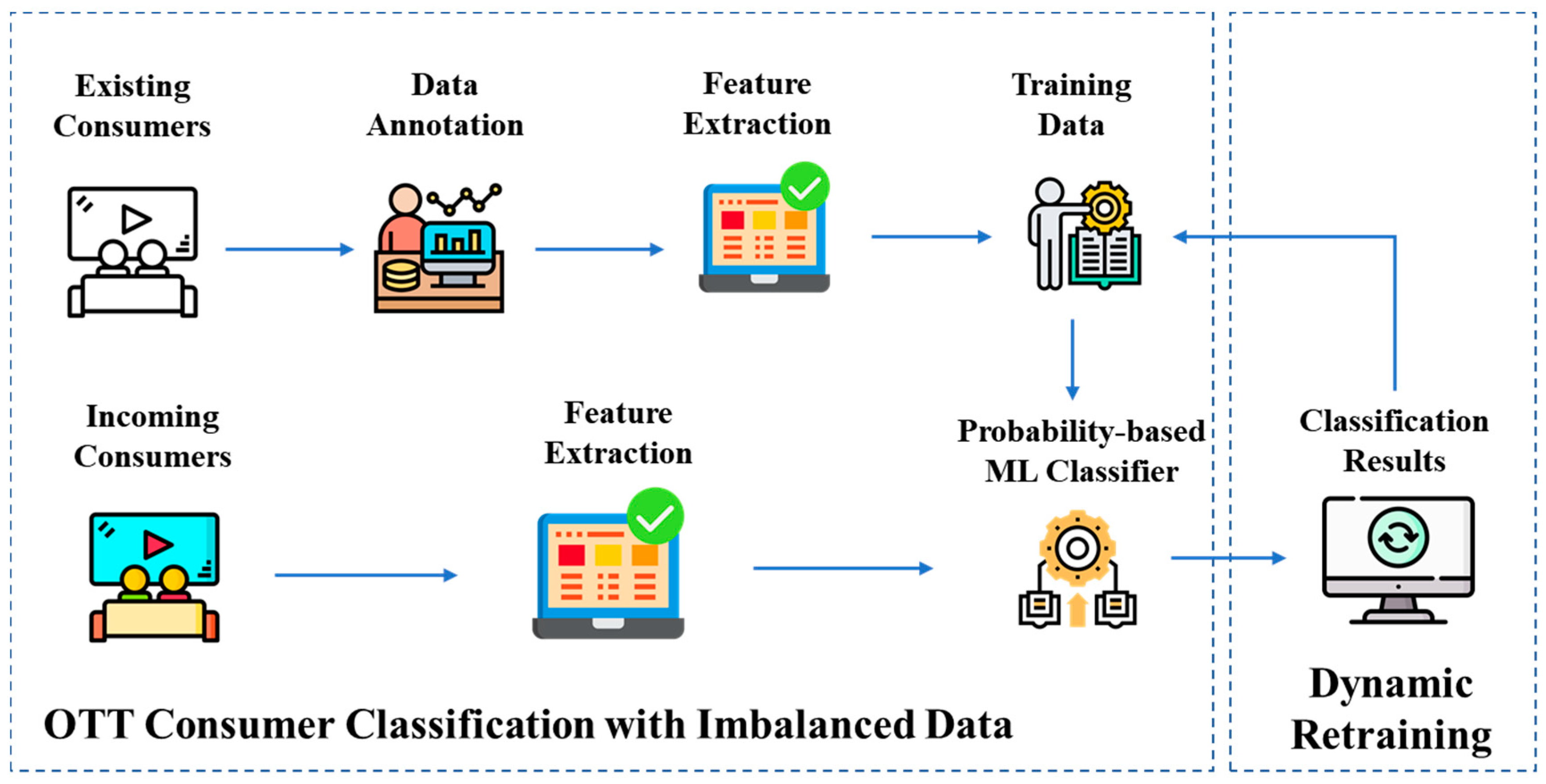
3.2. OTT Consumer Classification with Imbalanced Data
3.3. Dynamic Retraining Module
4. Results and Discussion
4.1. Dataset Description and Evaluation Metrics
4.2. Performance Comparison with Imbalanced Dataset
4.3. Performance Comparison with the Dynamic Retraining Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Joshi, H. Digital Media: Rise of on-Demand Content; Gurgaon, Deloitte Publishing: Gurgaon, India, 2015. [Google Scholar]
- Federal Communications Commission. Annual Assessment of the Status of Competition in the Market for the Delivery of Video Programming. MB Docket No. 14-16. FCC 15-41. 2015. Available online: https://www.federalregister.gov/documents/2015/07/24/2015-18215/annual-assessment-of-the-status-of-competition-in-the-market-for-the-delivery-of-video-programming (accessed on 23 May 2021).
- Rake, R.; Gaikwad, V.; Over-the-top (OTT) Market Outlook—2027. Allied Market Research. 2020. Available online: https://www.alliedmarketresearch.com/over-the-top-services-market (accessed on 19 April 2021).
- von Abrams, K. The Global Media Intelligence Report. eMarketer. 2018. Available online: https://www.emarketer.com/content/global-media-intelligence-2018, (accessed on 19 April 2021).
- Benes, R. US Digital Video. eMarketer. 2019. Available online: https://www.emarketer.com/content/us-digital-video-2019, (accessed on 19 April 2021).
- Rose, J.; Zuckerman, N.; Sheerin, A.; Mank, T.; Schmitz, L.-K.L.; Cadicamo, A. Can Subscription Video Providers Hold on to Their New Customers? Boston Consulting Group. 2020. Available online: https://www.bcg.com/publications/2020/can-subscription-video-providers-hold-on-to-their-new-customers (accessed on 19 April 2021).
- Research and Markets. United States Over the Top (OTT) Market —Growth, Trends, Forecasts (2020–2025). 2020. Available online: https://www.researchandmarkets.com/r/e46wk0 (accessed on 19 April 2021).
- Sujata, J.; Sohag, S.; Tanu, D.; Chintan, D.; Shubham, P.; Sumit, G. Impact of Over the Top (OTT) Services on Telecom Service Providers. Indian J. Sci. Techn. 2015, 8, 145–160. [Google Scholar] [CrossRef]
- Dai, W.; Baek, J.W.; Jordan, S. Neutrality between a vertically integrated cable provider and an over-the-top video provider. J. Commun. Netw. 2016, 18, 962–974. [Google Scholar] [CrossRef]
- Hu, M.; Zhang, M.; Wang, Y. Why do audiences choose to keep watching on live video streaming platforms? An explanation of dual identification framework. Comput. Human Behav. 2017, 75, 594–606. [Google Scholar] [CrossRef]
- Rojas, J.S.; Rendon, A.; Corrales, J.C. Consumption Behavior Analysis of Over the Top Services: Incremental Learning or Traditional Methods? IEEE Access 2019, 7, 136581–136591. [Google Scholar] [CrossRef]
- Rojas, J.S.; Pekar, A.; Rendon, A.; Corrales, J.C. Smart User Consumption Profiling: Incremental Learning-Based OTT Service Degradation. IEEE Access 2020, 8, 207426–207442. [Google Scholar] [CrossRef]
- Choi, J.; Kim, Y. Time-Aware Learning Framework for Over-The-Top Consumer Classification Based on Machine- and Deep-Learning Capabilities. Appl. Sci. 2020, 10, 8476. [Google Scholar] [CrossRef]
- Walelgne, E.A.; Asrese, A.S.; Manner, J.; Bajpai, V.; Ott, J. Clustering and predicting the data usage patterns of geographically diverse mobile users. Comput. Netw. 2021, 187. [Google Scholar] [CrossRef]
- Zhao, C.; Xin, Y.; Li, X.; Yang, Y.; Chen, Y. A Heterogeneous Ensemble Learning Framework for Spam Detection in Social Networks with Imbalanced Data. Appl. Sci. 2020, 10, 936. [Google Scholar] [CrossRef]
- Westcott, K.; Loucks, J.; Downs, K.; Arkenberg, C.; Jarvis, D. Digital Media Trends Survey, 14th Edition. Deloitte. 2020. Available online: https://www2.deloitte.com/us/en/insights/industry/technology/digital-media-trends-consumption-habits-survey/summary.html/#endnote-1 (accessed on 19 April 2021).
- J.D. Power. New Streaming Services Cut into Netflix’s Market Share, While “The Mandalorian” Drives Disney+ Viewership. 2021. Available online: https://discover.jdpa.com/hubfs/Files/Industry%20Campaigns/TMT/New%20Streaming%20Services%20Cut%20into%20Netflixs%20Market%20Share%20While%20The%20Mandalor._.pdf (accessed on 19 April 2021).
- Nielsen. The Nielsen Total Audience Report: August 2020. Available online: https://www.nielsen.com/us/en/insights/report/2020/the-nielsen-total-audience-report-august-2020/ (accessed on 19 April 2021).
- Webb, K. Disney Plus can’t Compete with Netflix when it Comes to Original Content, but its Affordable Price and Iconic Franchises Make it a Great Value for Families. Business Insider. 2020. Available online: https://www.businessinsider.com/disney-plus-review (accessed on 19 April 2021).
- Spangler, T.; Littleton, C. HBO Max and HBO Have 36.3 Million Subscribers, Up 5% From End of 2019, AT&T Says. VARIETY. 2020. Available online: https://variety.com/2020/digital/news/hbo-max-subscribers-subscribers-q2-att-1234714316/ (accessed on 19 April 2021).
- Kim, J.; Kim, S.; Nam, C. Competitive dynamics in the Korean video platform market: Traditional pay TV platforms vs. OTT platforms. Telemat. Informat. 2016, 33, 711–721. [Google Scholar] [CrossRef]
- Park, E.-A. Business strategies of Korean TV players in the age of over-the-top(OTT) video service. Int. J. Commun. 2018, 12, 4646–4667. [Google Scholar]
- Kim, J.; Nam, C.; Ryu, M.H. IPTV vs. emerging video services: Dilemma of telcos to upgrade the broadband. Telecom. Pol. 2019, 44. [Google Scholar] [CrossRef]
- Kim, Y.C. Netflix May Pay for KT’s Network. The Korea Times. 2020. Available online: http://www.koreatimes.co.kr/www/tech/2020/07/133_293720.html (accessed on 19 April 2021).
- PWC. The Promise of 5G. 2018. Available online: https://www.pwc.com/us/en/advisory-services/publications/consumer-intelligence-series/promise-5g.pdf (accessed on 19 April 2021).
- Johnson, M.R.; Woodcock, J. “And Today’s Top Donator is”: How Live Streamers on Twitch.tv Monetize and Gamify Their Broadcasts. Soc. Med. Soc. 2019, 5. [Google Scholar] [CrossRef]
- Floris, A.; Ahmad, A.; Atzori, L. QoE-aware OTT-ISP Collaboration in Service Management: Architecture and Approaches. ACM Trans. Multimedia Comput. Commun. Appl. 2018, 1, 1–23. [Google Scholar] [CrossRef]
- Nevo, A.; Turner, J.L.; Williams, J.W. User-Based Pricing and Demand for Residential Broadband; NBER Working Paper 21321; National Bureau of Economic Research: Cambridge, MA, USA, 2015. [Google Scholar] [CrossRef]
- Oliveira, T.; Fiorese, A.; Sargento, S. Forecasting Over-the-Top Bandwidth Consumption Applied to Network Operators. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 859–864. [Google Scholar] [CrossRef]
- Naudts, B.; Flores, M.; Mijumbi, R.; Verbrugge, S.; Serrat, J.; Colle, D. A dynamic pricing algorithm for a network of virtual resources. Int. J. Netw. Mgmt. 2017, 27, e1960. [Google Scholar] [CrossRef]
- Branch, P.; But, J. Rapid and generalized identification of packetized voice traffic flows. In Proceedings of the 37th Annual IEEE Conference on Local Computer Networks, Clearwater Beach, FL, USA, 22–25 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 85–92. [Google Scholar] [CrossRef]
- Bujlow, T.; Riaz, T.; Pedersen, J.M. A method for classification of network traffic based on C5.0 Machine Learning Algorithm. In Proceedings of the 2012 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 237–241. [Google Scholar] [CrossRef]
- Yuan, R.; Li, Z.; Guan, X.; Xu, L. An SVM-based machine learning method for accurate internet traffic classification. Inf. Sys. Front. 2010, 12, 149–156. [Google Scholar] [CrossRef]
- Shi, H.; Li, H.; Zhang, D.; Cheng, C.; Wu, W. Efficient and robust feature extraction and selection for traffic classification. Comput. Netw. 2017, 119, 1–16. [Google Scholar] [CrossRef]
- Wang, P.; Lin, S.C.; Luo, M. A framework for QoS-aware traffic classification using semi-supervised machine learning in SDNs. In Proceedings of the 2016 IEEE International Conference on Services Computing (SCC), San Francisco, CA, USA, 27 June–2 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 760–765. [Google Scholar] [CrossRef]
- Dong, Y.-n.; Zhao, J.-j.; Jin, J. Novel feature selection and classification of Internet video traffic based on a hierarchical scheme. Comput. Netw. 2017, 119, 102–111. [Google Scholar] [CrossRef]
- Bar-Yanai, R.; Langberg, M.; Peleg, D.; Roditty, L. Realtime classification for encrypted traffic. In Proceedings of the International Symposium on Experimental Algorithms, Ischia Island, Italy, 20–22 May 2010; Festa, P., Ed.; Springer: Berlin, Germany; pp. 373–385. [Google Scholar] [CrossRef]
- Ertam, F.; Avcı, E. A new approach for internet traffic classification: GA-WK-ELM. Measurement 2017, 95, 135–142. [Google Scholar] [CrossRef]
- Davis, J.J.; Foo, E. Automated feature engineering for HTTP tunnel detection. Comput. Secur. 2016, 59, 166–185. [Google Scholar] [CrossRef]
- Zhang, J.; Xiang, Y.; Zhou, W.; Wang, Y. Unsupervised traffic classification using flow statistical properties and IP packet payload. J. Comput. Sys. Sci. 2013, 79, 573–585. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, R. Design of a method for encrypted P2P traffic identification using K-means algorithm. Telecom. Sys. 2013, 53, 163–168. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Siavoshani, M.J.; Zade, R.S.H.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Mobile encrypted traffic classification using deep learning. In Proceedings of the 2018 Network Traffic Measurement and Analysis Conference (TMA), Vienna, Austria, 26–29 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapè, A. MIMETIC: Mobile encrypted traffic classification using multimodal deep learning. Comput. Netw. 2019, 165, 106944. [Google Scholar] [CrossRef]
- Rojas, J.S.; Gallón, Á.R.; Corrales, J.C. Personalized Service Degradation Policies on OTT Applications Based on the Consumption Behavior of Users. In Proceedings of the Computational Science and Its Applications, Melbourne, Australia, 2–5 July 2018; Springer: Cham, Switzerland, 2018; pp. 543–557. [Google Scholar] [CrossRef]
- Stoll, J. Netflix Subscriptions in the U.S. 2020, by Generation. Statista. 2021. Available online: https://www.statista.com/statistics/720723/netflix-members-usa-by-age-group/#statisticContainer (accessed on 19 April 2021).
- AppAnnie. The State of Mobile 2020 Report. 2019. Available online: https://www.appannie.com/en/go/state-of-mobile-2020/ (accessed on 19 April 2021).
- Li, C.; Liu, S. A comparative study of the class imbalance problem in Twitter spam detection. Concurr. Comput. 2018, 30, e4281. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Zhang, J.; Chen, C.; Xiang, Y. Addressing the class imbalance problem in twitter spam detection using ensemble learning. Comput. Sec. 2017, 69, 35–49. [Google Scholar] [CrossRef]
- Yang, Q.; Wu, X. 10 challenging problems in data mining research. Int. J. Inf. Technol. Decis. Mak. 2006, 5, 597–604. [Google Scholar] [CrossRef]
- Inuwa-Dutse, I.; Liptrott, M.; Korkontzelos, I. Detection of spam-posting accounts on Twitter. Neurocomputing 2018, 315, 496–511. [Google Scholar] [CrossRef]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inform. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Sze-To, A.; Wong, A.K. A weight-selection strategy on training deep neural networks for imbalanced classification. In Proceedings of the International Conference Image Analysis and Recognition, Montreal, QC, Canada, 5–7 July 2017; Karray, F., Campilho, A., Cheriet, F., Eds.; Springer: Cham, Switzerland, 2017; pp. 3–10. [Google Scholar] [CrossRef]
- Domingos, P. Metacost: A general method for making classifiers cost-sensitive. In Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 155–164. [Google Scholar]
- Chen, C.; Zhang, J.; Xiang, Y.; Zhou, W. Asymmetric self-learning for tackling twitter spam drift. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 208–213. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. AI Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Eibe, F.; Hall, M.A.; Witten, I.H.; Kaufmann, M. The WEKA workbench. Online appendix. In Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, VT, USA, 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual High | Actual Medium | Actual Low | |
|---|---|---|---|
| Predicted High | |||
| Predicted Medium | |||
| Predicted Low |
| Feature Name | Feature Description |
|---|---|
| src_ip_numeric | Decimal representation of the IP address of the user |
| ApplicationName_time_occupation | Time spent by the user for each OTT service |
| Application-Name.Flow.Bytes.Per.Sec | Byte size used per second by the user for each OTT service |
| ML Algorithms | Class | Refined Dataset | Imbalanced Dataset | ||||
|---|---|---|---|---|---|---|---|
| Recall | Precision | F-Measure | Recall | Precision | F-Measure | ||
| J48 | Low | 0.941 | 0.950 | 0.946 | 0.992 | 0.984 | 0.988 |
| Medium | 0.955 | 0.933 | 0.944 | 0.917 | 0.917 | 0.917 | |
| High | 0.948 | 0.955 | 0.952 | 0.915 | 0.966 | 0.940 | |
| KNN | Low | 0.951 | 0.933 | 0.942 | 0.999 | 0.967 | 0.983 |
| Medium | 0.958 | 0.967 | 0.962 | 0.852 | 0.992 | 0.916 | |
| High | 0.946 | 0.962 | 0.954 | 0.863 | 0.997 | 0.925 | |
| PART | Low | 0.925 | 0.872 | 0.898 | 0.991 | 0.961 | 0.976 |
| Medium | 0.886 | 0.905 | 0.895 | 0.825 | 0.945 | 0.881 | |
| High | 0.901 | 0.958 | 0.929 | 0.839 | 0.958 | 0.894 | |
| SVM | Low | 0.961 | 0.965 | 0.963 | 0.999 | 0.940 | 0.968 |
| Medium | 0.973 | 0.961 | 0.967 | 0.843 | 0.988 | 0.909 | |
| High | 0.975 | 0.980 | 0.978 | 0.664 | 0.994 | 0.796 | |
| ML Algorithms | Class | Imbalanced Dataset | Our Framework | ||||
|---|---|---|---|---|---|---|---|
| Recall | Precision | F-Measure | Recall | Precision | F-Measure | ||
| J48 | Low | 0.992 | 0.984 | 0.988 | 0.967 | 0.995 | 0.981 |
| Medium | 0.917 | 0.917 | 0.917 | 0.972 | 0.820 | 0.889 | |
| High | 0.915 | 0.966 | 0.940 | 0.968 | 0.910 | 0.938 | |
| KNN | Low | 0.999 | 0.967 | 0.983 | 0.997 | 0.989 | 0.993 |
| Medium | 0.852 | 0.992 | 0.916 | 0.959 | 0.977 | 0.968 | |
| High | 0.863 | 0.997 | 0.925 | 0.954 | 0.997 | 0.975 | |
| PART | Low | 0.991 | 0.961 | 0.976 | 0.975 | 0.977 | 0.976 |
| Medium | 0.825 | 0.945 | 0.881 | 0.889 | 0.857 | 0.873 | |
| High | 0.839 | 0.958 | 0.894 | 0.903 | 0.911 | 0.907 | |
| SVM | Low | 0.999 | 0.940 | 0.968 | 0.996 | 0.981 | 0.988 |
| Medium | 0.843 | 0.988 | 0.909 | 0.898 | 0.906 | 0.902 | |
| High | 0.664 | 0.994 | 0.796 | 0.856 | 0.946 | 0.899 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Kim, Y. A Heterogeneous Learning Framework for Over-the-Top Consumer Analysis Reflecting the Actual Market Environment. Appl. Sci. 2021, 11, 4783. https://doi.org/10.3390/app11114783
Choi J, Kim Y. A Heterogeneous Learning Framework for Over-the-Top Consumer Analysis Reflecting the Actual Market Environment. Applied Sciences. 2021; 11(11):4783. https://doi.org/10.3390/app11114783
Chicago/Turabian StyleChoi, Jaeun, and Yongsung Kim. 2021. "A Heterogeneous Learning Framework for Over-the-Top Consumer Analysis Reflecting the Actual Market Environment" Applied Sciences 11, no. 11: 4783. https://doi.org/10.3390/app11114783
APA StyleChoi, J., & Kim, Y. (2021). A Heterogeneous Learning Framework for Over-the-Top Consumer Analysis Reflecting the Actual Market Environment. Applied Sciences, 11(11), 4783. https://doi.org/10.3390/app11114783